ShuffleNet V1 对花数据集训练
目录
1. shufflenet 介绍
分组卷积
通道重排
2. ShuffleNet V1 网络
2.1 shufflenet 的结构
2.2 代码解释
2.3 shufflenet 代码
3. train 训练
4. Net performance on flower datasets
1. shufflenet 介绍
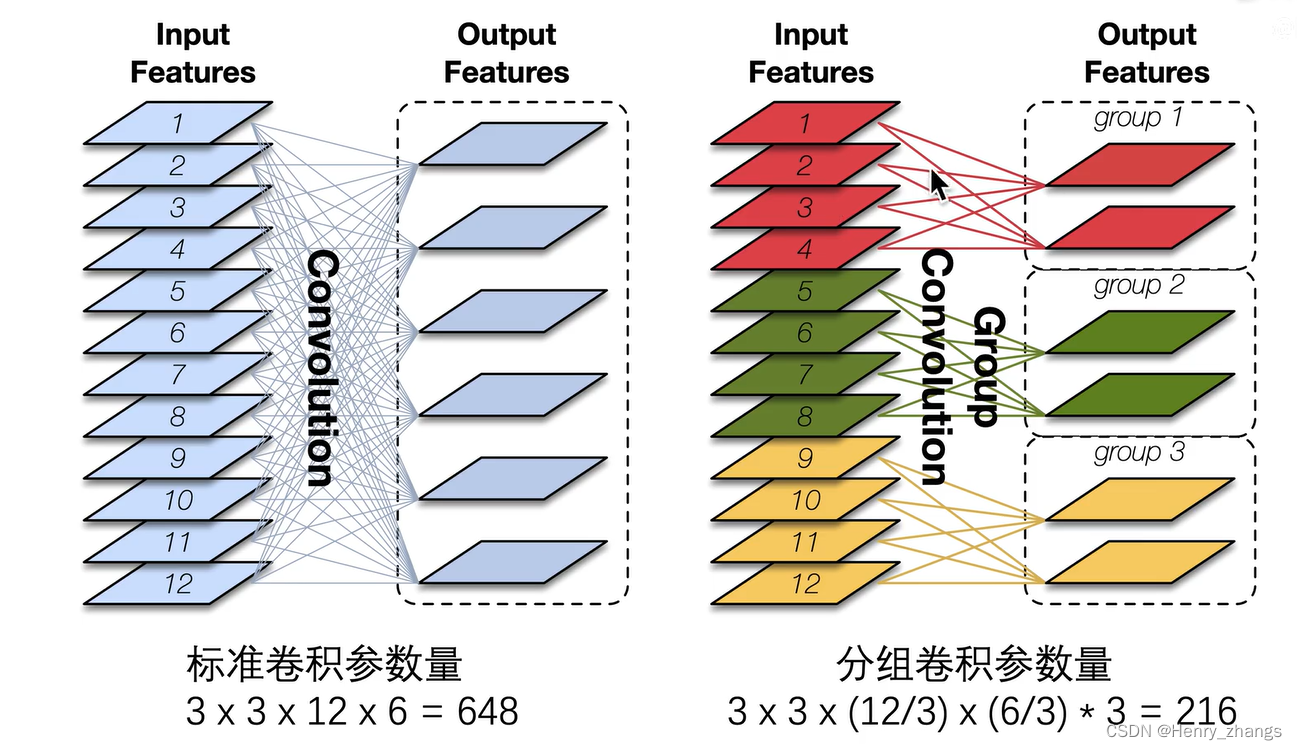
shufflenet的亮点:分组卷积 + 通道重排
mobilenet 提出的深度可分离卷积分为两个step,第一步是深度卷积DW,也就是每一个channel都用一个单独的卷积核卷积,输出一张对应的特征图。第二步是点卷积PW,就是用1*1的卷积核对DW的结果进行通道融合
这样的做法可以有效的减少计算量,然而这样的方式对性能是有一定影响的。而后面的mobilenet 2,3是在bottleneck里面扩充了维度或者更新了激活函数防止维度丢失等等。所以,mobilenet都是在维度信息进行操作的,为了不丢失manifold of interest
分组卷积
而shufflenet 提出了一个新的思路,正常的卷积是卷积的深度=输入的channel个数。深度可分离卷积是卷积对单个channel进行响应。而shufflenet 取折中,将固定个数的channel作为一组,然后进行正常的卷积
类似于单个样本(mobilenet),batch(正常卷积),mini batch(shufflenet)
过程如下:这样相对于正常的卷积也是大大减少了参数
然而仅仅的分组卷积会落入一个类似近亲繁衍的bug中,如图中的a。这样红色的channel始终和红色的操作,失去了特征的多样性,不同channel信息之间的传递被堵塞了
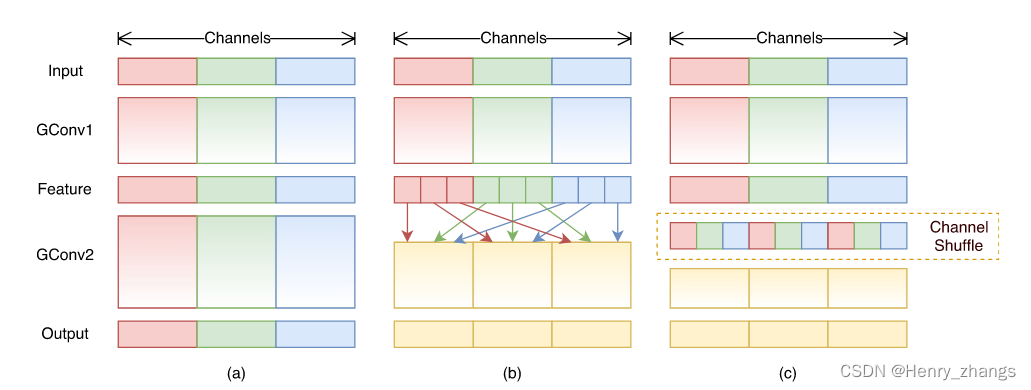
通道重排
而解决这样的方法就是通道重排,例如上图中的b,将不同组分为相同的子块,然后按照顺序打乱。图c和图b是一样的
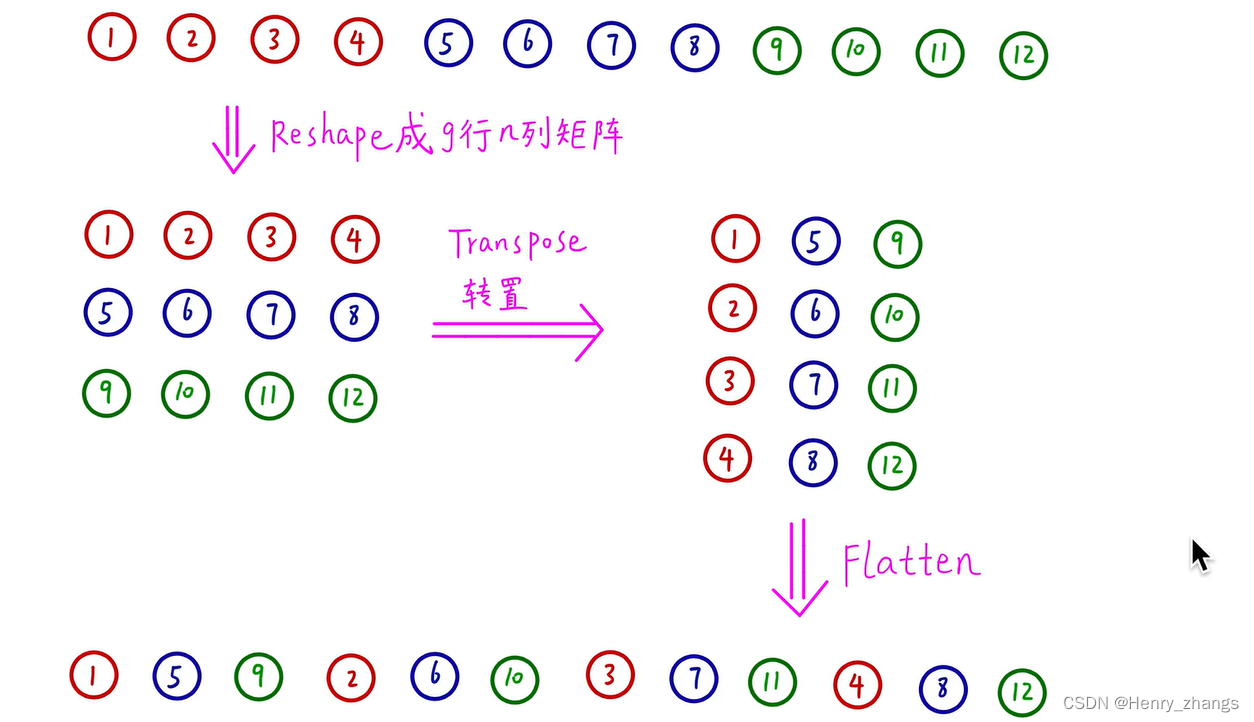
而通道重排可以用矩阵转置的方式实现:
- 将channel放置如下
- 然后按照不同的组(g为分组的个数),reshape 成(g,n)的矩阵
- 将矩阵转置变成n*g的矩阵
- 最后flatten 拉平就行了
2. ShuffleNet V1 网络
搭建shufflenet 网络
2.1 shufflenet 的结构
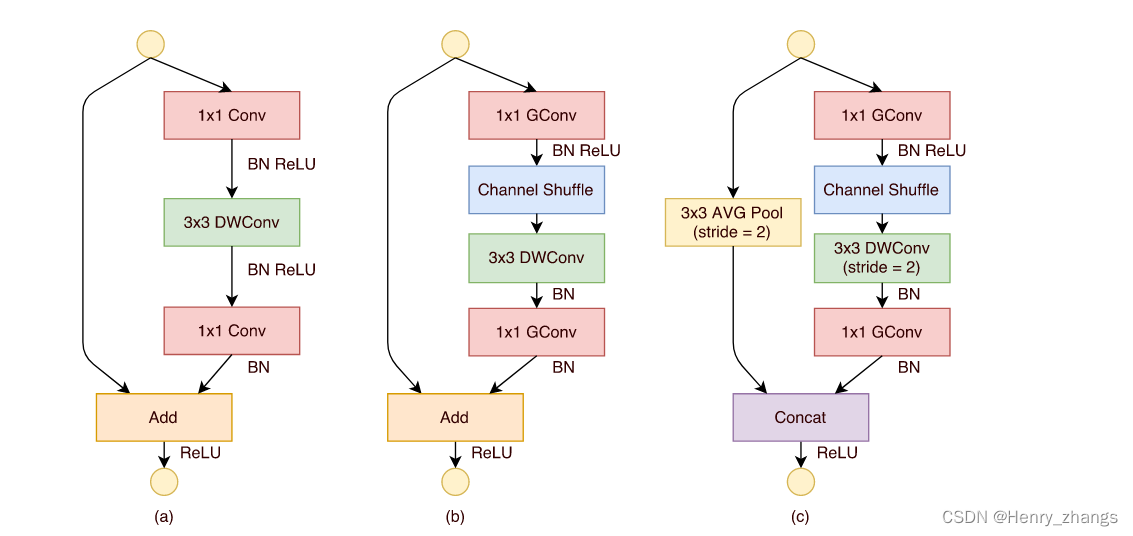
shufflenet 中 bottleneck 如下所示
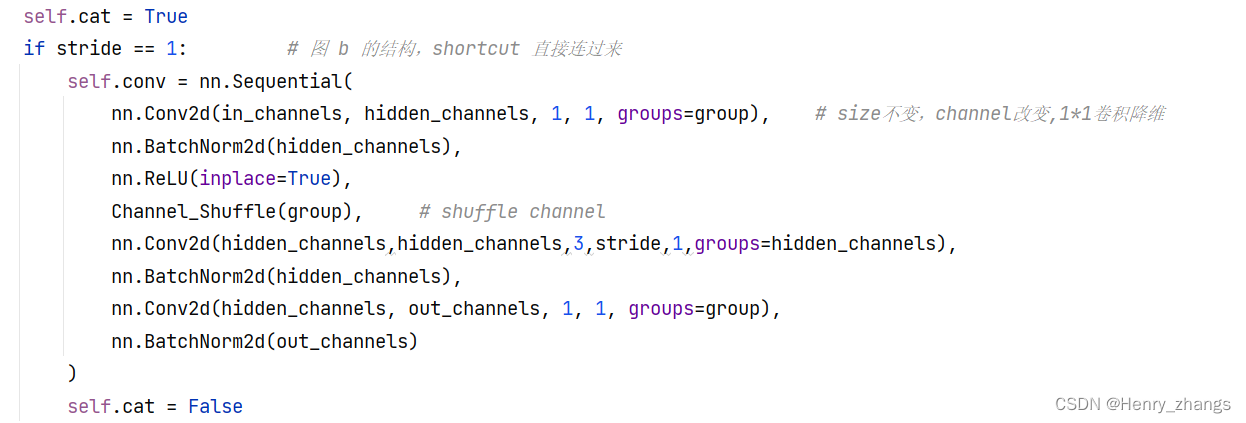
其中,a为正常的bottleneck块,也就是residual残差块
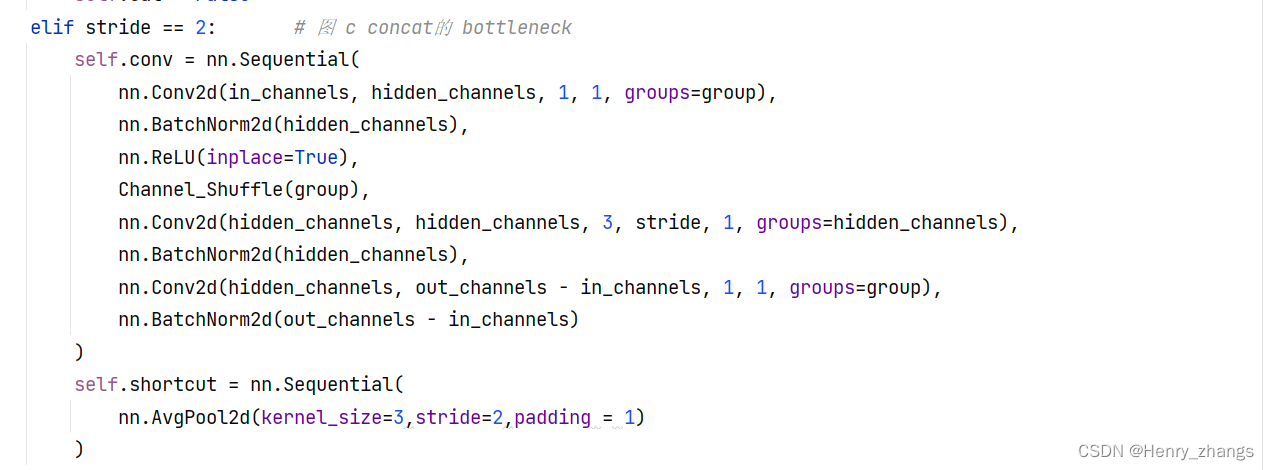
图b和图c全都是为shufflenet中的bottleneck,区别就是c是做下采样的bottleneck。
注:一般的bottleneck的下采样是用卷积核stride=2或者maxpooling实现的,而shufflenet中采用3*3平均池化,stride=2实现
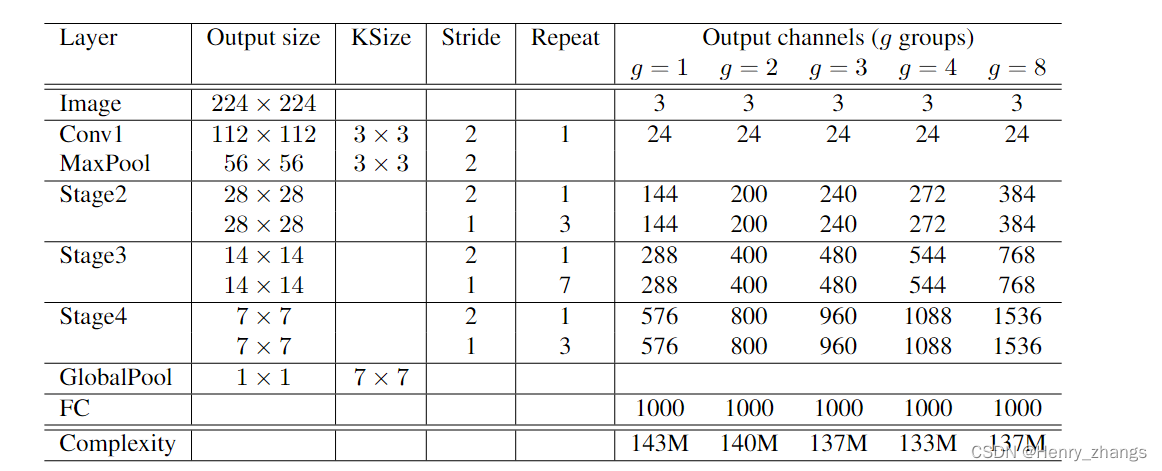
下图为shufflenet V1的网络结构
2.2 代码解释
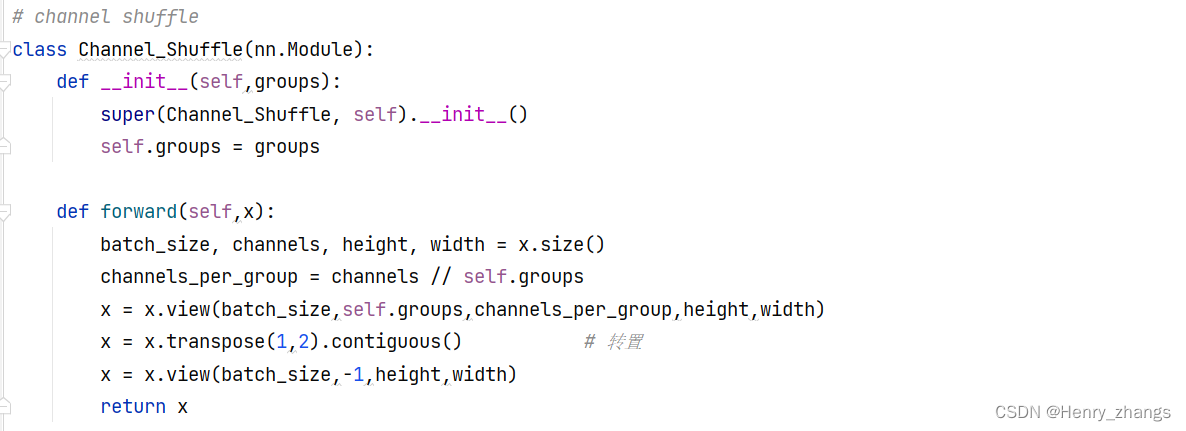
如下定义了一个channel shuffle 的类,因为pytorch中的传递方式是batch*channel*height*width
所以,这里先将x分解成各个部分,然后channel / group 就是每个组里面channel的个数,按照之前提到的方式。显示reshape成g * n的矩阵,然后进行转置,在flatten就行了
然后针对于stage中的第一步stride = 2,和上图c对应实现
针对于stage中的第一步stride = 1,和上图b对应实现
具体的参考结构,可以慢慢理解,代码实现的方法还是很nice的
2.3 shufflenet 代码
代码:
import torch
import torch.nn as nn# channel shuffle
class Channel_Shuffle(nn.Module):def __init__(self,groups):super(Channel_Shuffle, self).__init__()self.groups = groupsdef forward(self,x):batch_size, channels, height, width = x.size()channels_per_group = channels // self.groupsx = x.view(batch_size,self.groups,channels_per_group,height,width)x = x.transpose(1,2).contiguous() # 转置x = x.view(batch_size,-1,height,width)return x# bottleneck 模块
class BLOCK(nn.Module):def __init__(self,in_channels,out_channels, stride,group):super(BLOCK, self).__init__()hidden_channels = out_channels // 2 # 降维self.shortcut = nn.Sequential()self.cat = Trueif stride == 1: # 图 b 的结构,shortcut 直接连过来self.conv = nn.Sequential(nn.Conv2d(in_channels, hidden_channels, 1, 1, groups=group), # size不变,channel改变,1*1卷积降维nn.BatchNorm2d(hidden_channels),nn.ReLU(inplace=True),Channel_Shuffle(group), # shuffle channelnn.Conv2d(hidden_channels,hidden_channels,3,stride,1,groups=hidden_channels),nn.BatchNorm2d(hidden_channels),nn.Conv2d(hidden_channels, out_channels, 1, 1, groups=group),nn.BatchNorm2d(out_channels))self.cat = Falseelif stride == 2: # 图 c concat的 bottleneckself.conv = nn.Sequential(nn.Conv2d(in_channels, hidden_channels, 1, 1, groups=group),nn.BatchNorm2d(hidden_channels),nn.ReLU(inplace=True),Channel_Shuffle(group),nn.Conv2d(hidden_channels, hidden_channels, 3, stride, 1, groups=hidden_channels),nn.BatchNorm2d(hidden_channels),nn.Conv2d(hidden_channels, out_channels - in_channels, 1, 1, groups=group),nn.BatchNorm2d(out_channels - in_channels))self.shortcut = nn.Sequential(nn.AvgPool2d(kernel_size=3,stride=2,padding = 1))self.relu = nn.ReLU(inplace=True)def forward(self,x):out = self.conv(x)x = self.shortcut(x)if self.cat:x = torch.cat([out,x],1) # 图 c的 concatelse:x = out+x # 图 b的 addreturn self.relu(x)# shuffleNet V1
class ShuffleNet_V1(nn.Module):def __init__(self, classes=1000,group=3):super(ShuffleNet_V1, self).__init__()setting = {1:[3,24,144,288,576], # 不同分组个数对应的channel2:[3,24,200,400,800],3:[3,24,240,480,960],4:[3,24,272,544,1088],8:[3,24,384,768,1536]}repeat = [3,7,3] # stage 里面 bottleneck 重复的次数channels = setting[group]self.conv1 = nn.Sequential( # Conv1 没有组卷积,channel太少了,输出只有24nn.Conv2d(channels[0],channels[1],kernel_size=3,stride=2,padding=1), # 输出图像大小 112*112nn.BatchNorm2d(channels[1]),nn.ReLU(inplace=True))self.pool1 = nn.MaxPool2d(kernel_size=3,stride=2,padding=1) # 输出图像size 56*56self.block = BLOCKself.stages = nn.ModuleList([])for i,j in enumerate(repeat): # i =0,1,2 j=3,7,3self.stages.append(self.block(channels[1+i],channels[2+i],stride=2, group=group)) # stage 中第一个block,对应图 cfor _ in range(j):self.stages.append(self.block(channels[2+i], channels[2+i], stride=1, group=group)) # stage 中第二个block,对应图 bself.pool2 = nn.AdaptiveAvgPool2d(1) # global poolingself.fc = nn.Sequential(nn.Dropout(0.2),nn.Linear(channels[-1],classes))# 初始化权重for m in self.modules():if isinstance(m,nn.Conv2d):nn.init.kaiming_normal_(m.weight,mode='fan_out')if m.bias is not None:nn.init.zeros_(m.bias)elif isinstance(m,nn.BatchNorm2d):nn.init.ones_(m.weight)nn.init.zeros_(m.bias)elif isinstance(m,nn.Linear):nn.init.normal_(m.weight,0,0.01)nn.init.zeros_(m.bias)def forward(self,x):x = self.conv1(x)x = self.pool1(x)for stage in self.stages:x = stage(x)x = self.pool2(x)x = x.view(x.size(0),-1)x = self.fc(x)return x
3. train 训练
代码:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms
from model import ShuffleNet_V1
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
from tqdm import tqdm
import json# 定义超参数
DEVICE = 'cuda' if torch.cuda.is_available() else "cpu"
LEARNING_RATE = 0.001
EPOCHS = 10
BATCH_SIZE = 16TRAINSET_PATH = './flower_data/train' # 训练集
TESTSET_PATH = './flower_data/test' # 测试集# 预处理
data_transform = {"train": transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),"test": transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}# 加载训练集
trainSet = ImageFolder(root=TRAINSET_PATH,transform=data_transform['train'])
trainLoader = DataLoader(trainSet,batch_size=BATCH_SIZE,shuffle=True)# 加载测试集
testSet = ImageFolder(root=TESTSET_PATH,transform=data_transform['test'])
testLoader = DataLoader(testSet,batch_size=BATCH_SIZE,shuffle=False)# 数据的个数
num_train = len(trainSet) # 3306
num_test = len(testSet) # 364# 保存数据的label文件
dataSetClasses = trainSet.class_to_idx
class_dict = dict((val, key) for key, val in dataSetClasses.items())
json_str = json.dumps(class_dict, indent=4)
with open('class_indices.json', 'w') as json_file:json_file.write(json_str)# 实例化网络
net = ShuffleNet_V1(classes=5)
net.to(DEVICE)
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(),lr=LEARNING_RATE,weight_decay=4e-5)# train
best_acc = 0.0
for epoch in range(EPOCHS):net.train() # train 模式running_loss = 0.0for images, labels in tqdm(trainLoader):images, labels = images.to(DEVICE), labels.to(DEVICE)optimizer.zero_grad() # 梯度下降outputs = net(images) # 前向传播loss = loss_fn(outputs, labels) # 计算损失loss.backward() # 反向传播optimizer.step() # 梯度更新running_loss += loss.item()net.eval() # 测试模式acc = 0.0with torch.no_grad():for x, y in tqdm(testLoader):x, y = x.to(DEVICE), y.to(DEVICE)outputs = net(x)predicted = torch.max(outputs, dim=1)[1]acc += (predicted == y).sum().item()accurate = acc / num_test # 计算正确率train_loss = running_loss / num_train # 计算损失print('[epoch %d] train_loss: %.3f accuracy: %.3f' %(epoch + 1, train_loss, accurate))if accurate > best_acc:best_acc = accuratetorch.save(net.state_dict(), './ShuffleNet_V1.pth')print('Finished Training....')
这里训练的数据是花数据集,共有五个类别,这里只训练了10个epoch。
100%|██████████| 207/207 [01:34<00:00, 2.19it/s]
100%|██████████| 23/23 [00:05<00:00, 4.09it/s]
[epoch 1] train_loss: 0.089 accuracy: 0.527
100%|██████████| 207/207 [01:45<00:00, 1.97it/s]
100%|██████████| 23/23 [00:05<00:00, 3.84it/s]
[epoch 2] train_loss: 0.076 accuracy: 0.610
100%|██████████| 207/207 [02:03<00:00, 1.68it/s]
100%|██████████| 23/23 [00:05<00:00, 3.89it/s]
[epoch 3] train_loss: 0.067 accuracy: 0.665
100%|██████████| 207/207 [02:42<00:00, 1.28it/s]
100%|██████████| 23/23 [00:07<00:00, 3.26it/s]
0%| | 0/207 [00:00<?, ?it/s][epoch 4] train_loss: 0.061 accuracy: 0.651
100%|██████████| 207/207 [02:47<00:00, 1.23it/s]
100%|██████████| 23/23 [00:07<00:00, 3.27it/s]
[epoch 5] train_loss: 0.058 accuracy: 0.731
100%|██████████| 207/207 [01:54<00:00, 1.81it/s]
100%|██████████| 23/23 [00:06<00:00, 3.60it/s]
[epoch 6] train_loss: 0.055 accuracy: 0.777
100%|██████████| 207/207 [01:53<00:00, 1.83it/s]
100%|██████████| 23/23 [00:06<00:00, 3.46it/s]
[epoch 7] train_loss: 0.053 accuracy: 0.739
100%|██████████| 207/207 [01:52<00:00, 1.84it/s]
100%|██████████| 23/23 [00:06<00:00, 3.57it/s]
[epoch 8] train_loss: 0.051 accuracy: 0.734
100%|██████████| 207/207 [01:53<00:00, 1.83it/s]
100%|██████████| 23/23 [00:06<00:00, 3.52it/s]
[epoch 9] train_loss: 0.048 accuracy: 0.758
100%|██████████| 207/207 [01:53<00:00, 1.82it/s]
100%|██████████| 23/23 [00:06<00:00, 3.56it/s]
[epoch 10] train_loss: 0.045 accuracy: 0.761
Finished Training....
4. Net performance on flower datasets
import osos.environ['KMP_DUPLICATE_LIB_OK'] = 'True'import json
import torch
import numpy as np
import matplotlib.pyplot as plt
from model import ShuffleNet_V1
from torchvision.transforms import transforms
from torch.utils.data import DataLoader
from torchvision.datasets import ImageFolder# 获取 label
try:json_file = open('./class_indices.json', 'r')classes = json.load(json_file)
except Exception as e:print(e)# 预处理
transformer = transforms.Compose([transforms.Resize(256), # 保证比例不变,短边变为256transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.255])])# 加载模型
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
model = ShuffleNet_V1(classes=5)
model.load_state_dict(torch.load('./ShuffleNet_V1.pth'))
model.to(DEVICE)# 加载数据
testSet = ImageFolder(root='./flower_data/test',transform=transformer)
testLoader = DataLoader(testSet, batch_size=12, shuffle=True)# 获取一批数据
imgs, labels = next(iter(testLoader))
imgs = imgs.to(DEVICE)# show
with torch.no_grad():model.eval()prediction = model(imgs) # 预测prediction = torch.max(prediction, dim=1)[1]prediction = prediction.data.cpu().numpy()plt.figure(figsize=(12, 8))for i, (img, label) in enumerate(zip(imgs, labels)):x = np.transpose(img.data.cpu().numpy(), (1, 2, 0)) # 图像x[:, :, 0] = x[:, :, 0] * 0.229 + 0.485 # 去 normalizationx[:, :, 1] = x[:, :, 1] * 0.224 + 0.456 # 去 normalizationx[:, :, 2] = x[:, :, 2] * 0.255 + 0.406 # 去 normalizationy = label.numpy().item() # labelplt.subplot(3, 4, i + 1)plt.axis(False)plt.imshow(x)plt.title('R:{},P:{}'.format(classes[str(y)], classes[str(prediction[i])]))plt.show()结果如下:

相关文章:
ShuffleNet V1 对花数据集训练
目录 1. shufflenet 介绍 分组卷积 通道重排 2. ShuffleNet V1 网络 2.1 shufflenet 的结构 2.2 代码解释 2.3 shufflenet 代码 3. train 训练 4. Net performance on flower datasets 1. shufflenet 介绍 shufflenet的亮点:分组卷积 通道重排 mobilenet …...

测试人员转型是大势所趋:我的10年自动化测试经验分享
做测试十多年,有不少人问过我下面问题: 现在的手工测试真的不行了吗? 测试工程师,三年多快四年的经验,入门自动化测试需要多久? 自学自动化测试到底需要学哪些东西? 不得不说,随着行…...
)
Pandas高级操作,建议收藏(一)
在数据分析和数据建模的过程中需要对数据进行清洗和整理等工作,有时需要对数据增删字段。下面为大家介绍Pandas对数据的复杂查询、数据类型转换、数据排序的使用。 复杂查询 实际业务需求往往需要按照一定的条件甚至复杂的组合条件来查询数据,接下来为大家介绍如何…...
ASIC-WORLD Verilog(1)一日Verilog
写在前面 在自己准备写一些简单的verilog教程之前,参考了许多资料----asic-world网站的这套verilog教程即是其一。这套教程写得极好,奈何没有中文,在下只好斗胆翻译过来(加了自己的理解)分享给大家。 这是网站原文&…...
数据治理工具项目投标书技术部分-V1.6
本资料来源公开网络,仅供个人学习,请勿商用,如有侵权请联系删除 项目背景 二、项目目标 提供一套后勤数据治理工具部署文件及配套文档,主要技术指标如下: (1)具备数据抽取转换装载、元数据管理、…...
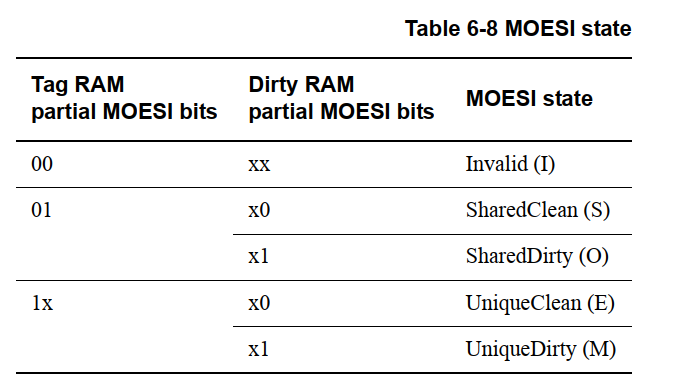
ARMv8如何读取cache line中MOESI 状态以及Tag信息(tag RAM dirty RAM)
本文以Cortex-A53处理器为例,通过访问 处理器中的内部存储单元(tag RAM和dirty RAM),来读取cache line 中的MOESI信息。 Cortex-A53提供了一种通过读取一些系统寄存器,来访问Cache 和 TLB使用的一些内部存储单元的机制…...

学习通学习--脚本
刷客就爱学学习-首页 (xxbwk.top) 所有科目答案可以网上找超星尔雅学习通《形势与政策》2023年春章节测试答案 (3gmfw.cn) 学习通全部答案 萌面人 – 萌面人官网 (mengmianren.com) 自动答题教程 想要使用自动答题功能,只需要一个配置项就可以让OCS脚本拥有自动答…...

C盘的深度清理
随着反复安装和移除软件,c盘虽然给了80或者100G的空间,也经不住垃圾文件的堆积。居然只剩下几兆空间了。真是可气,某些软件虽然移除了。但是他们不负责自己产生的文件夹和文件的深度清理。 1. 清理系统的垃圾 2. 移动或者清理大文件。 某…...
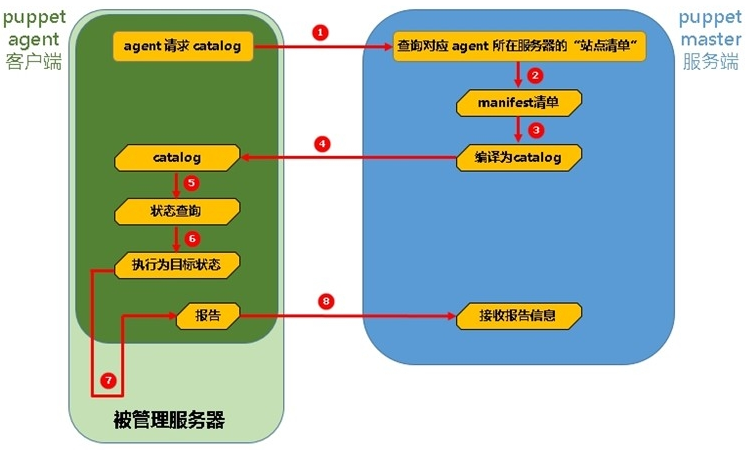
43掌握自动化运维工具 Puppet 的基本用法,包括模块编写、资源管理
Puppet是一种自动化配置管理工具,可以自动化地部署、配置和管理大规模服务器环境。本教程将介绍Puppet的基本用法,包括模块编写和资源管理。 模块编写 在Puppet中,模块是一组相关的类、文件和资源的集合。模块可以用于部署和配置应用程序、服…...

【新2023Q2押题JAVA】华为OD机试 - 硬件产品销售方案
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为od机试,独家整理 已参加机试人员的实战技巧本篇题解:硬件产品销售方案 题目描述 …...
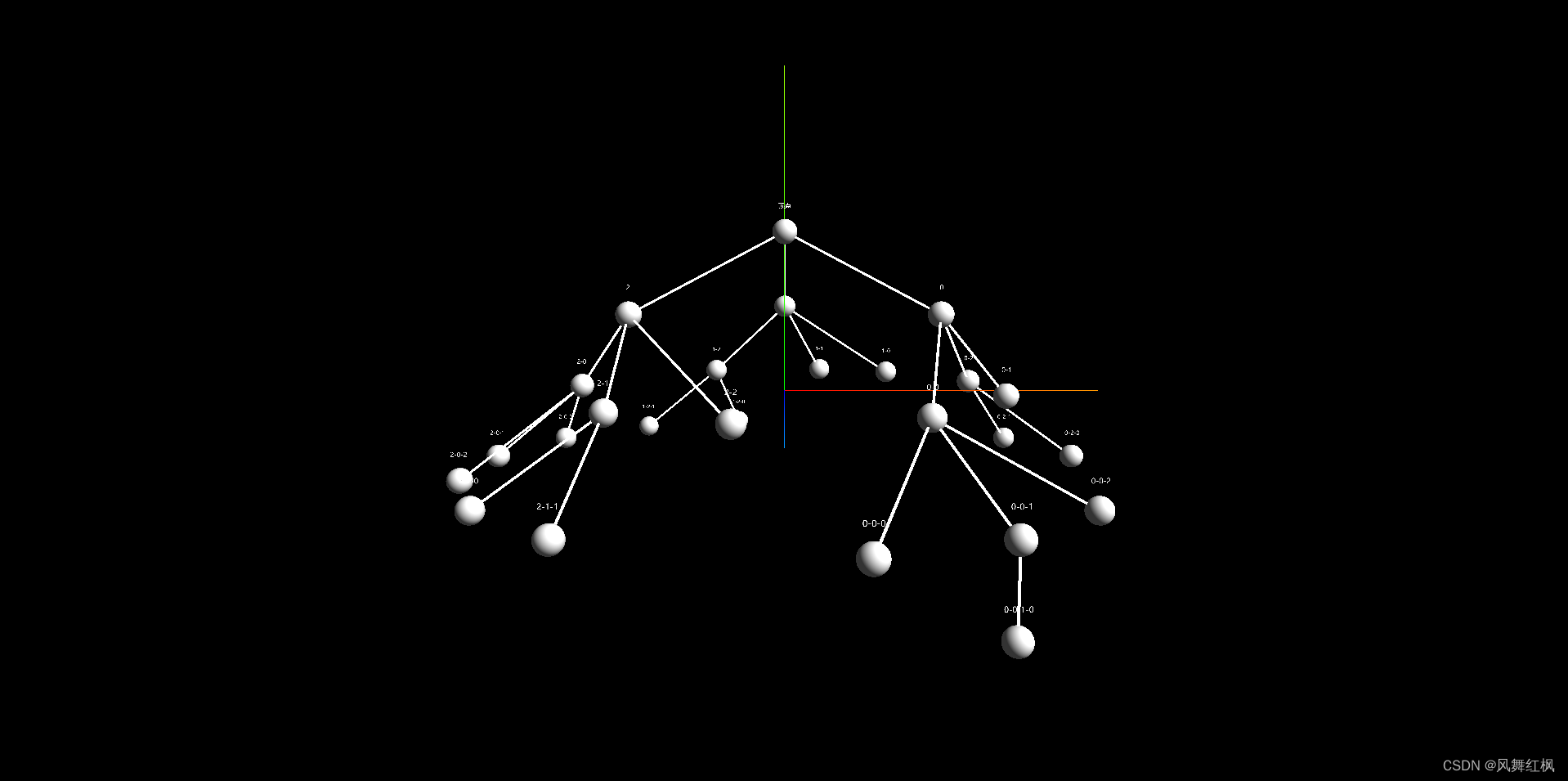
three.js实现3d球体树状结构布局——树状结构的实现
目录系列文章安装依赖基本分析实体类场景相机渲染器辅助线环境光点光源球形几何体球形几何体的材质线几何体线几何体的材质物体文本轨道控制实现效果实现源码参考文档系列文章 three.js实现3d球体树状结构布局——添加入场、出场、点击放大等动画 安装依赖 npm i three three…...
ChatGPT大解密:带您探讨机器学习背后的秘密、利用与发展
一、什么是机器学习?二、ChatGPT 的运作原理三、ChatGPT 生活利用1、自然语言处理2、翻译3、自动回复四、ChatGPT vs 其他相关技术五、ChatGPT 的未来1、未来发展2、职业取代3、客服人员4、翻译人员5、语言学家6、机遇与挑战六、结语这篇文章,将带着各位…...

3ds max2024带来了什么新功能(一)
文章目录1、安装2、操作界面3、快捷键(不冲突了)4、 修改器列表(可以搜索了)5、超级阵列功能(Array)6、超级布尔1、安装 传说3dmax2024有很多牛叉的改进二话不说,先安装按起来!这个…...
HNU-电路与电子学-实验3
实验三 模型机组合部件的实现(二)(实验报告格式案例) 班级 计XXXXX 姓名 wolf 学号 2021080XXXXX 一、实验目的 1.了解简易模型机的内部结构和工作原理。 2.分析模型机的功能&am…...
Hadoop MapReduce各阶段执行过程以及Python代码实现简单的WordCount程序
视频资料:黑马程序员大数据Hadoop入门视频教程,适合零基础自学的大数据Hadoop教程 文章目录Map阶段执行过程Reduce阶段执行过程Python代码实现MapReduce的WordCount实例mapper.pyreducer.py在Hadoop HDFS文件系统中运行Map阶段执行过程 把输入目录下文件…...

GitLab CI/CD 新书发布,助企业降本增效
前言 大家好,我是CSDN的拿我格子衫来, 昨天我的第一本书《GitLab CI/CD 从入门到实战》上架啦,这是业内第一本详细讲解GitLab CI/CD的书籍。 历经无数个日夜,最终开花结果。感触良多,今天就借这篇文章来谈一谈这本书的…...
【分享】如何写出整洁的代码?
文章目录前言1.为什么要保持代码整洁?1.1 所以从一开始就要保持整洁1.2 如何写出整洁的代码?2.命名3.类3.1单一职责3.2 开闭原则3.3 内聚4.函数4.1 只做一件事4.2 函数命名4.3 参数4.4 返回值4.5 怎样写出这样的函数?4.6 代码质量扫描工具5.测试5.1 TDD5.2 FIRST原则5.3 测试…...
视频剪辑:教你如何调整视频画面的大小。
大家应该都会调整图片的大小吧,那你们会调整视频画面的大小吗?我想,应该会有人不还不知道要调整的吧,今天就让小编来教大家一个方法怎样去调整视频画面的大小尺寸。 首先,我们要有以下材料: 一台电脑 【…...

操作系统概述
Overview Q1(Why):为什么要学操作系统?Q2(What):到底什么是操作系统?Q3(How):怎么学操作系统? 一.为什么要学操作系统? 学习操作系统…...
记录重启csdn
有太多收藏的链接落灰了,在此重启~ 1、社会 https://mp.weixin.qq.com/s/Uq0koAbMUk8OFZg2nCg_fg https://mp.weixin.qq.com/s/yCtLdEWSKVVAKhvLHxjeig https://zhuanlan.zhihu.com/p/569162335?utm_mediumsocial&utm_oi938179755602853888&ut…...

Qwen3-ASR-1.7B在数学建模竞赛中的语音数据处理应用
Qwen3-ASR-1.7B在数学建模竞赛中的语音数据处理应用 数学建模竞赛,听起来是不是有点“高大上”?其实说白了,就是给你一个现实世界的问题,让你用数学和计算机的方法去解决。这几年,竞赛题目越来越贴近生活,…...

使用VMware虚拟机搭建Nanobot开发环境
使用VMware虚拟机搭建Nanobot开发环境 1. 引言 你是不是遇到过这样的情况:想尝试最新的AI开发工具,但又担心搞乱自己的主力开发环境?或者团队需要统一开发环境,但每个人的电脑配置都不一样? 使用虚拟机搭建开发环境…...
)
面试官:什么是最左前缀匹配?为什么要遵守?(修订版)
在线 Java 面试刷题(持续更新):https://www.quanxiaoha.com/java-interview面试考察点原理理解:面试官不仅仅想知道你会背 "最左前缀原则",更想考察你是否理解联合索引的 B 树存储结构,能否从数据…...

工业数据采集避坑指南:Java+Utgard实现OPC DA高可靠通信的3个关键技巧
工业数据采集避坑指南:JavaUtgard实现OPC DA高可靠通信的3个关键技巧 在工业自动化领域,OPC DA(OLE for Process Control Data Access)协议作为连接工业设备和信息系统的桥梁,其稳定性直接关系到生产数据的完整性和实时…...

Lychee模型API网关配置:Kong中间件集成指南
Lychee模型API网关配置:Kong中间件集成指南 1. 引言 在AI服务部署过程中,如何有效管理和保护模型API是一个常见挑战。Lychee模型作为强大的多模态处理工具,在生产环境中需要可靠的流量控制和安全防护机制。这就是API网关发挥作用的地方。 …...

腾讯优图4B模型实测:轻量级多模态AI,图片描述、图表分析、目标检测,一个模型全解决
腾讯优图4B模型实测:轻量级多模态AI,图片描述、图表分析、目标检测,一个模型全解决 1. 开箱体验:4B参数的全能选手 当我第一次在CSDN星图镜像广场看到这个只有4B参数的腾讯优图多模态模型时,说实话是持怀疑态度的。毕…...
)
别再只盯着7805了!聊聊LDO选型时那些容易被忽略的关键参数(附实测对比)
LDO选型实战指南:超越7805的五大高阶参数解析 在电子设计领域,低压差线性稳压器(LDO)如同电路系统中的"毛细血管",负责将能量精准输送到每个功能模块。当大多数工程师还在使用上世纪设计的7805时,现代LDO芯片早已进化出…...

告别Activity重建:用onConfigurationChanged优雅处理Android 13+的深色主题与多语言切换
告别Activity重建:用onConfigurationChanged优雅处理Android 13的深色主题与多语言切换 在Android 13及更高版本中,深色主题动态切换和多语言即时切换已成为提升用户体验的关键功能。传统方案通过重建Activity实现配置变更,但会导致界面闪烁、…...

游戏存档备份终极指南:用Ludusavi保护你的游戏进度永不丢失
游戏存档备份终极指南:用Ludusavi保护你的游戏进度永不丢失 【免费下载链接】ludusavi Backup tool for PC game saves 项目地址: https://gitcode.com/gh_mirrors/lu/ludusavi 你是否曾因电脑重装、系统崩溃或更换设备而丢失数百小时的游戏进度?…...

告别手动复制!Mac版PowerPoint备注导出神器:自定义AppleScript脚本全解析
Mac版PowerPoint备注导出神器:AppleScript脚本开发实战指南 每次在会议前整理PPT备注时,你是否也厌倦了手动复制粘贴的繁琐操作?作为一位长期使用Mac和PowerPoint的资深用户,我深刻理解这种效率低下的痛苦。本文将带你深入探索如何…...