airflow源码分析-任务调度器实现分析
Airflow源码分析-任务调度器实现分析
概述
本文介绍Airflow执行器的总体实现流程。通过函数调用的方式说明了Airflow scheduler的实现原理,对整个调度过程的源码进行了分析。
通过本文,可以基本把握住Airflow的调度器的运行原理主线。
启动调度器
可以通过命令来启动调度器:
airflow scheduler
启动airflow的调度器后的总执行流程如下:
- 执行命令后会调用
scheduler_command.py#scheduler(args)函数。 - scheduler(args)函数会打开一个日志文件,然后调用
_run_scheduler_job(args)函数,该函数会:创建一个SchedulerJob对象,把DAG文件的目录传入,启动后就开始解析DAG文件目录中的DAG文件(*.py)文件。 - 然后开始执行
SchedulerJob#run()这个函数,启动job侧。该函数在其父类BaseJob中定义。 BaseJob#run()函数调用其实现类的_execute()函数,这里就是调用SchedulerJob#_execute函数来启动调度服务。
调度器的实现分析
SchedulerJob#_execute函数
-
打印启动调度器的日志:可以在调度器服务的日志文件中看到以下日志:
Starting the scheduler。 -
如果不是独立模式进程,则创建一个
DagFileProcessorAgent对象,用于读取DAG文件。并把该对象保存到:SchedulerJob#processor_agent成员变量中。 -
初始化执行器,并设置执行器的回调函数。创建callback_sink对象,它可能是PipeCallbackSink(DagFileProcessorAgent是非独立模式)或DatabaseCallbackSink(DagFileProcessorAgent是独立模式);创建完成后,对象保存到BaseExecutor#callback_sink变量中(代码中实现的是SchedulerJob#executor函数的返回值)。
-
调用: self.executor.start()函数来启动执行器executor:调用
SchedulerJob#executor.start() -
调用self.register_signals()函数来:注册信号处理程序,以便在需要时可以停止儿子进程。
-
启动DagFileProcessorAgent服务:
SchedulerJob.processor_agent.start() -
调用:
SchedulerJob#_run_scheduler_loop,进入调度服务循环,根据DAG的调度计划,执行DAG中的任务。 -
DAG处理完成后,如果是非独立模式,则停止DagFileProcessorAgent对象,并检查所有文件是否都已经处x理。如果所有文件都已处理,则停用未被调度器触及的DAG。
-
最后,执行器结束工作,关闭处理DAG文件的代理对象和回调函数,并移除会话对象。
调度服务主循环: SchedulerJob#_run_scheduler_loop
-
通过
if not self.processor_agent来检查DAG文件处理服务是否已经启动 -
创建一个定时器调度对象timers:
timers = EventScheduler(),该对象会定时执行定义的函数。用于周期性地运行一些任务。 -
向该timer对象中注册一些回调函数,来定时进行一些任务。这些任务包括检查孤立的任务、检查触发器超时、更新池指标、查找僵尸任务等。
-
通过一个无限循环来不断地进行调度,直到达到指定的运行次数或达到了DAG解析次数的上限。在每次循环中,它会执行以下步骤:
a. 进入调度循环,若使用sqlite,则运行一个单独的的DAG文件解析进程:
processor_agent.run_single_parsing_loop()。b. 调用
SchedulerJob#_do_scheduling进入实际的调度实现代码中。并返回排队的任务数量。c. 启动executor的心跳处理进程:
self.executor.heartbeat()d. 启动executor的事件处理器:
SchedulerJob#_process_executor_eventse. 启动DagFileProcessorAgent的心跳服务:
self.processor_agent.heartbeat()f. 运行定时任务;
-
如果没有工作需要执行,则等待一段时间。
最后,如果达到了指定的运行次数或达到了DAG解析次数的上限,则退出循环。如果使用DagFileProcessorAgent,则在达到解析次数上限时也会退出循环。
调度实现函数:SchedulerJob#_do_scheduling
- 调用prohibit_commit的函数来返回一个上下文管理器:
CommitProhibitorGuard。该上下文管理器可以防止在其作用域之外通过会话对象提交事务,从而严格控制事务的生命周期,以确保在核心调度器循环中的严格控制。如果在上下文管理器之外通过会话对象提交事务,将引发RuntimeError异常。 - 调用
SchedulerJob#_create_dagruns_for_dags函数来根据DagModel中的next_dagrun_create_after列创建任何必要的DagRun。默认情况下,只选择10个DAG,可以通scheduler.max_dagruns_to_create_per_loop设置进行配置。 - 调用函数:
SchedulerJob#_start_queued_dagruns:在DagRuns集合中对象中查找“下n个最老的”正在运行的DAGRun进行调度(默认n = 20,可以通过“scheduler.max_dagruns_per_loop_to_schedule”进行配置),并尝试进度状态(将TIs调度为SCHEDULED,或将DagRuns调度为SUCCESS / FAILURE等)。 - 调用
SchedulerJob#_get_next_dagruns_to_examine检查dagrun的参数。 - 调用
SchedulerJob#_schedule_all_dag_runs函数来决定所有dagrun的调度决定。该函数会遍历所有的dagrun,对每个dagrun调用SchedulerJob#_schedule_dag_run函数来决定是否调度该dagrun。 - 通过临界区(锁定Pool模型的行),将任务排队,然后将其发送到执行器中。详见_critical_section_enqueue_task_instances()文档。
- 返回在此迭代中入队的TIs的数量。
其中,步骤2和步骤3需要注意,因为它们会锁定某些行,并且只有一个调度器可以同时处理这些行,因此它们可能会影响调度器的吞吐量。步骤2中默认选择的20个DAG Run是基于它们最久没有被检查/调度的时间来选择的。步骤3中,通过临界区锁定行的目的是为了防止多个调度器同时修改同一个任务实例,这会导致竞态条件和不一致性。
SchedulerJob#_start_queued_dagruns
该方法用于启动处于排队状态的DagRuns。
-
该方法调用_get_next_dagruns_to_examine方法,获取处于QUEUED状态的DagRuns。
-
然后,该方法使用DagRun.active_runs_of_dags方法计算每个DAG当前正在运行的DagRun数量,并将结果存储在active_runs_of_dags字典中。
-
它遍历了每个处于QUEUED状态的DagRun,检查是否可以将其移动到RUNNING状态。
a. 对于每个DagRun,该方法首先使用DagBag.get_dag方法获取其对应的DAG对象,并将其赋值给dag_run.dag属性。如果DAG不存在,则记录错误并继续处理下一个DagRun。
b. 接下来,该方法使用active_runs_of_dags字典获取DAG当前正在运行的DagRun数量,并将结果存储在active_runs变量中。
c. 该方法检查DAG的max_active_runs属性是否为None,如果不是,则检查DAG当前正在运行的DagRun数量是否超过了该属性的值。如果是,则记录调试日志并不将该DagRun移动到RUNNING状态。否则,该方法会将DagRun的状态设置为RUNNING,并更新其start_date属性。此外,该方法还会将DAG当前正在运行的DagRun数量加1,并调用DagRun.notify_dagrun_state_changed方法通知状态已更改。
d. 最后,该方法调用了_update_state方法,该方法用于设置DagRun的状态为RUNNING,并计算调度延迟(如果DAG是周期性的)。需要注意的是,_update_state方法是一个内部函数,定义在_start_queued_dagruns方法内部。
SchedulerJob#_critical_section_enqueue_task_instances
该方法用于将TaskInstances添加到执行队列中。
该方法包含以下三个步骤:
-
使用优先级选择TaskInstances,并确保它们处于预期状态,并且不会超过最大活动运行数或池限制。
原子地更改上述TaskInstances的状态。 -
将TaskInstances添加到执行器的队列中。需要注意的是,该方法是一个“关键段”,意味着只有一个执行器进程可以同时执行该方法。为了实现这一点,该方法使用了SELECT…FOR UPDATE语句锁定了池表,以确保只有一个进程可以进行修改。
-
该方法还包含了两个辅助方法:_executable_task_instances_to_queued和_enqueue_task_instances_with_queued_state。其中,_executable_task_instances_to_queued方法用于选择可执行的TaskInstances,而_enqueue_task_instances_with_queued_state方法用于将TaskInstances添加到执行器的队列中。
-
最后,该方法返回状态发生了变化的TaskInstance的数量。
注意:该方法使用了一个名为max_tis_per_query的属性,它表示每次查询最多选择的TaskInstance数量。如果该属性的值为0,则选择所有可用的TaskInstances;否则,仅选择最多max_tis_per_query个TaskInstances。此外,该方法还使用了一个名为executor的属性,它表示Airflow的执行器对象,用于将TaskInstances添加到执行队列中。
SchedulerJob#_enqueue_task_instances_with_queued_state
该方法的作用是将状态为"queued"的任务实例添加到执行器(executor)的队列中(queued_tasks字典中)等待执行。
该方法接受两个参数:
- task_instances:待执行的任务实例列表。
- session:数据库会话对象。
-
该方法首先遍历任务实例列表,对于每个状态为"queued"的任务实例,将其命令添加到执行器的队列中等待执行。如果任务实例所属的DAG运行状态为finished,则将任务实例状态设置为"None",并跳过该任务实例的执行。
-
对于每个任务实例,该方法使用任务实例的command_as_list方法获取该任务实例的命令,并设置该任务实例的优先级和队列。然后,该方法调用执行器的queue_command方法将该任务实例的命令添加到执行器的队列中等待执行。
需要注意的是,该方法并不会等待任务实例执行完毕,而是将任务实例的执行交给了执行器处理。而执行器的具体处理逻辑在_process_tasks函数的_executor.execute_async方法中。
该函数的实现代码如下:
def _enqueue_task_instances_with_queued_state(self, task_instances: list[TI], session: Session) -> None:"""Takes task_instances, which should have been set to queued, and enqueues themwith the executor.:param task_instances: TaskInstances to enqueue:param session: The session object"""# actually enqueue themfor ti in task_instances:if ti.dag_run.state in State.finished:ti.set_state(State.NONE, session=session)continuecommand = ti.command_as_list(local=True,pickle_id=ti.dag_model.pickle_id,)priority = ti.priority_weightqueue = ti.queueself.log.info("Sending %s to executor with priority %s and queue %s", ti.key, priority, queue)self.executor.queue_command(ti,command,priority=priority,queue=queue,)
task通过queue_command已经放到了执行器的任务执行队列queued_tasks中,该变量其实是一个有序的字典,由OrderedDict类来定义。这样不同类型的执行器就可以消费该队列,执行任务了。
Task放入执行器队列
执行器会调用以下函数来执行task。每个执行器实现的实现逻辑不同,可以进入每个执行器中继续分析其实现。
def _process_tasks(self, task_tuples: list[TaskTuple]) -> None:for key, command, queue, executor_config in task_tuples:del self.queued_tasks[key]self.execute_async(key=key, command=command, queue=queue, executor_config=executor_config)self.running.add(key)
小结
本文分析了airflow的任务执行总体流程。分析了从dag文件处理,到task的调度和执行的整个流程。
通过本文的分析可以说基本把握住了Airflow的运行原理的主线。可以根据这条主线,继续分析每个执行器的执行原理,以及任务优先级,DAG文件处理的细节。
相关文章:

airflow源码分析-任务调度器实现分析
Airflow源码分析-任务调度器实现分析 概述 本文介绍Airflow执行器的总体实现流程。通过函数调用的方式说明了Airflow scheduler的实现原理,对整个调度过程的源码进行了分析。 通过本文,可以基本把握住Airflow的调度器的运行原理主线。 启动调度器 可…...
和reduceRight())
一文学会数组的reduce()和reduceRight()
reduce()方法和reduceRight()方法依次处理数组的每个成员,最终累计为一个值。 它们的差别是,reduce()是从左到右处理,reduceRight()则是从右到左,其他完全一样。 [1, 2, 3, 4, 5].reduce(function (a, b) {console.log(a, b);ret…...
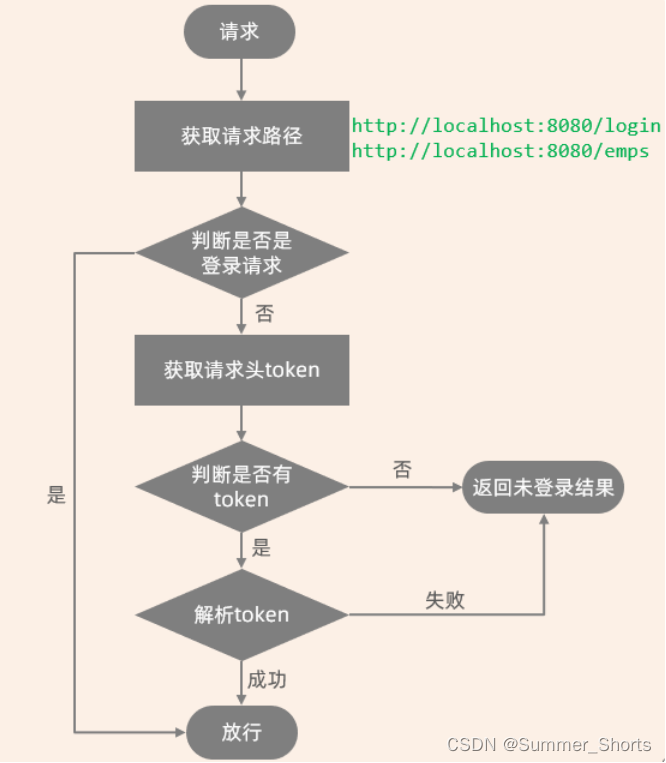
登录校验-Filter
上一篇介绍完了基础应用和细节,现在来完成登录校验功能基本流程: 要进入后台管理系统,必须完成登录操作,此时就需要访问登录接口Login。登录成功服务端会生成一个JWT令牌,并且返回给前端,前端会将JWT令牌存…...

C C++ Java python 分别写出不同表白girlfriend的爱心动态代码实现
C `` #include <stdio.h> #include <stdlib.h> #include <windows.h> void heart_animation() {int i, j, k; for (i = 1; i <= 6; i++) {for (j = -3; j <= 3; j++) {for (k = -4; k <= 4; k++) {if (abs(j) + abs(k) < i * 2) {printf(“I”)…...

ThreeJS-投影、投影模糊(十七)
无投影: 完整的代码: <template> <div id"three_div"></div> </template> <script> import * as THREE from "three"; import { OrbitControls } from "three/examples/jsm/controls/Or…...
)
蓝桥杯赛前冲刺-枚举暴力和排序专题1(包含历年蓝桥杯真题和AC代码)
目录 连号区间数(第四届蓝桥杯省赛CB组,第四届蓝桥杯省赛JAVAB组) 递增三元组(第九届蓝桥杯省赛CB组,第九届蓝桥杯省赛JAVAB组) 特别数的和(第十届蓝桥杯省赛CB组,第十届蓝桥杯省赛JAVAB组) 错误票据&a…...
Github库中的Languages显示与修改
目录 前言 【.gitattributes】文件 修改GitHub语言 前言 上传一个项目到GitHub时,发现显示的语言并非是自己项目所示的语言,这样的情况是经常发生的,为了能到达自己所需快速检索,或者是外部访问者能很好的搜索我们的项目&#…...

RocketMQ消息高可靠详解
文章目录 消息同步策略殊途同归同步基于offset而不是消息本身刷盘策略RocketMQ broker服务端以组为单位提供服务的,拥有着一样的brokerName则认为是一个组。其中brokerId=0的就是master,大于0的则为slave。 消息同步策略 master和slave都可以提供读服务,但是只有master允许…...

【python设计模式】4、建造者模式
哲学思想: 建造者模式的哲学思想是将复杂对象的创建过程分解成多个简单的步骤,并将这些步骤分别封装在一个独立的建造者类中。然后,我们可以使用一个指挥者类来控制建造者的调用顺序,以便在每个步骤完成后正确地构建复杂对象。 …...

【全网独家】华为OD机试Golang解题 - 机智的外卖员
华为Od必看系列 华为OD机试 全流程解析+经验分享,题型分享,防作弊指南华为od机试,独家整理 已参加机试人员的实战技巧华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典使用说明 如果想要在华为od机试中获取高分…...

Sentinel滑动时间窗限流算法原理及源码解析(中)
文章目录 MetricBucketMetricEvent数据统计的维度WindowWrap样本窗口实例 范型T为MetricBucket windowLengthInMs 样本窗口长度 windowStart 样本窗口的起始时间戳 value 当前样本窗口的统计数据 其类型为MetricBucket MetricBucket MetricEvent数据统计的维度 1、首先计算27t位…...
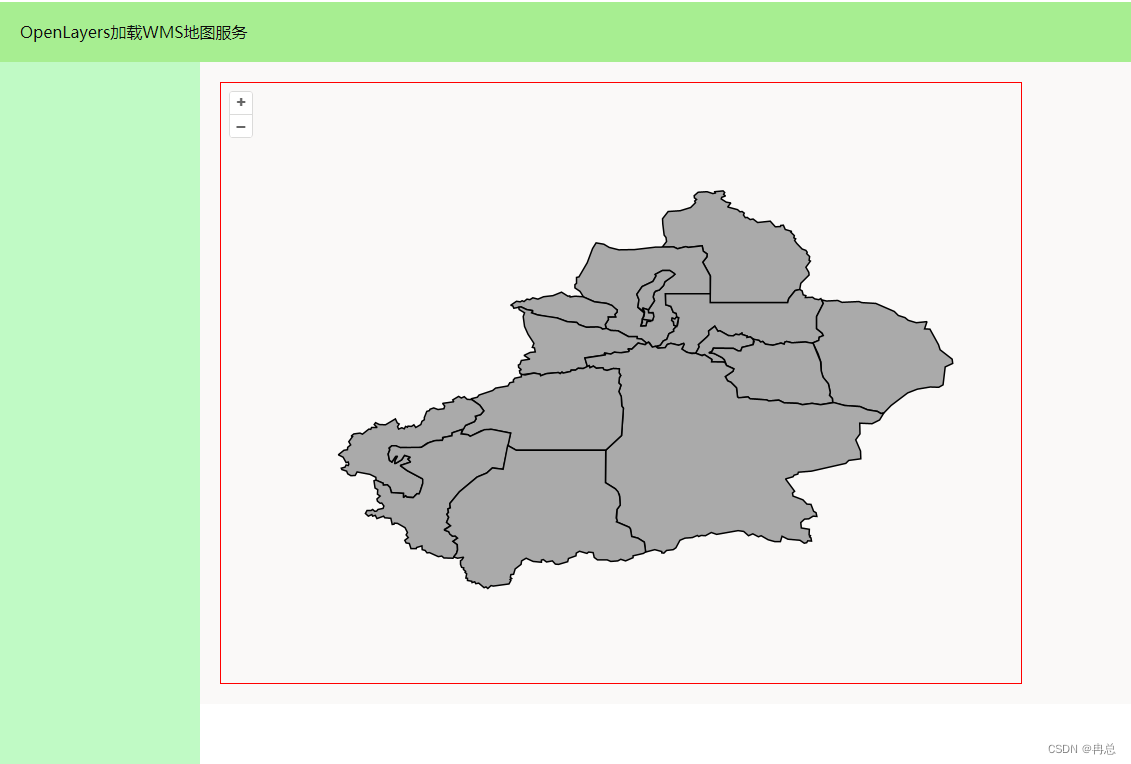
【OpenLayers】VUE+OpenLayers+ElementUI加载WMS地图服务
【OpenLayers】VUEOpenLayersElementUI加载WMS地图服务准备工作安装vue创建vue项目安装OpenLayers安装ElementUI加载wms地图服务准备工作 需要安装好nodejs,nodejs下载地址,下载对应的版本向导式安装即可。 安装完成后,控制台输入node -v&a…...

linux 命名管道 mkfifo
专栏内容:linux下并发编程个人主页:我的主页座右铭:天行健,君子以自强不息;地势坤,君子以厚德载物.目录 前言 概述 原理介绍 接口说明 代码演示 结尾 前言 本专栏主要分享linux下并发编程…...
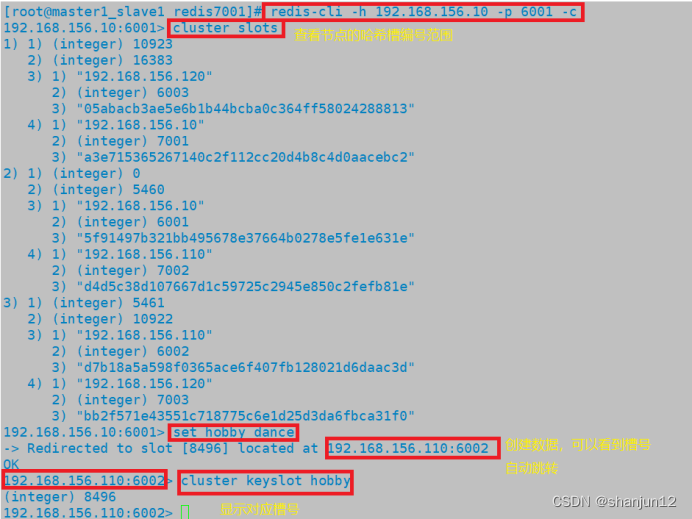
Redis(主从复制、哨兵模式、集群)概述及部署
目录 1.redis高可用 2.redis持久化 1.Redis 提供两种方式进行持久化: 2.RDB 持久化 3.AOF持久化 4.RDB和AOF的优缺点 5.Redis 性能管理 3.redis主从复制 1.Redis主从复制的概念 2.Redis主从复制的作用 3.Redis主从复制的搭建 4.redis哨兵模式 1.哨兵模式…...

windows下软件包安装工具之Scoop安装与使用
Scoop介绍 Scoop是Windows的命令行程序安装器。 Scoop从命令行安装程序,及其容易。它有如下特点: 消除权限弹出窗口隐藏 GUI 向导样式的安装程序防止安装大量程序的 PATH 污染避免安装和卸载程序的意外副作用自动查找并安装依赖项自行执行所有额外的设…...

九龙证券|人工智能+国产软件+智慧城市概念股火了,欧洲资管巨头大举抄底
近一周组织调研个股数量有130多只,迈瑞医疗成为调研组织数量最多的股票。 证券时报数据宝统计,近一周组织调研公司数量有130多家。从调研组织类型来看,证券公司调研相对最广泛,调研80多家公司。 迈瑞医疗获超500家组织调研 迈瑞…...

Nacos下载安装与配置(windows)
一、Nacos下载 官网地址:home (nacos.io) 点击前往Github,跳转至Github下载页面。 点击Tags,跳转至版本选择页面,此处选择2.2.0版本。 点击nacos-server-2.2.0.zip,进行下载。 二、Nacos安装 将下载的压缩包解压至需…...
QT学习笔记(语音识别项目 )
语音识别项目 我们知道 AI 智能音箱已经在我们生活中不少见,也许我们都玩过,智能化非常高,功能 强大,与我们平常玩的那种蓝牙音箱,Wifi 音箱有很大的区别,AI 智能在哪里呢?语音识别技 术和云端…...
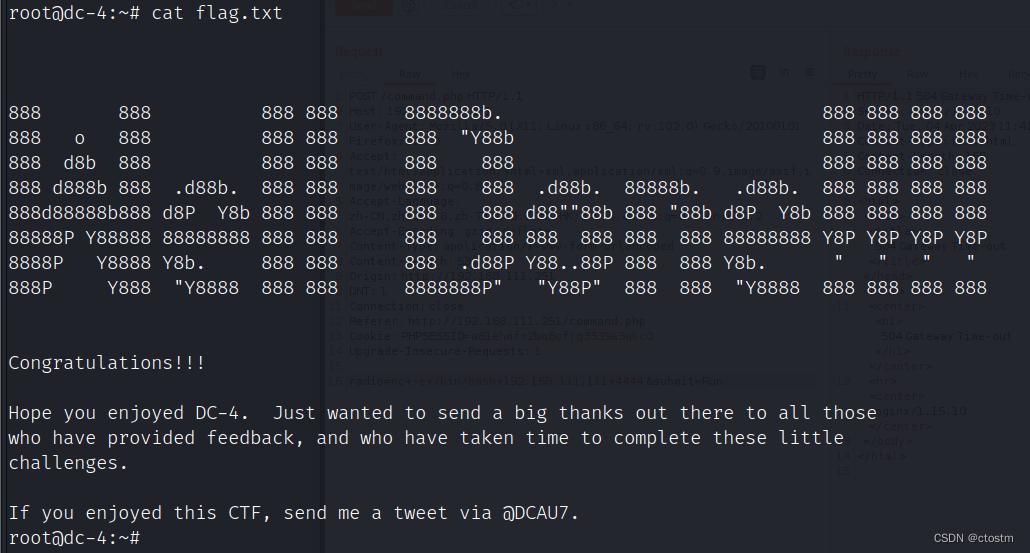
Vulnhub:DC-4靶机
kali:192.168.111.111 靶机:192.168.111.251 信息收集 端口扫描 nmap -A -v -sV -T5 -p- --scripthttp-enum 192.168.111.251 访问目标网站发现需要登录 使用账号admin爆破出密码:happy 登陆后抓包执行反弹shell 提权 在/home/jim/backu…...

序列差分练习题--从模板到灵活运用
本篇包含6道序列差分练习题及题解,难度由模板到提高 语文成绩 题目背景 语文考试结束了,成绩还是一如既往地有问题。 题目描述 语文老师总是写错成绩,所以当她修改成绩的时候,总是累得不行。她总是要一遍遍地给某些同学增加分…...
)
Hutool CronUtil实战:5分钟搞定Spring Boot定时任务(含动态任务配置)
Hutool CronUtil实战:5分钟搞定Spring Boot定时任务(含动态任务配置) 在Java开发领域,定时任务几乎是每个项目都绕不开的基础需求。传统方案如Spring Scheduler虽然简单易用,但在动态任务管理和细粒度控制方面往往力不…...

Win11Debloat:终极Windows系统清理工具,一键提升电脑性能的完整指南
Win11Debloat:终极Windows系统清理工具,一键提升电脑性能的完整指南 【免费下载链接】Win11Debloat 一个简单的PowerShell脚本,用于从Windows中移除预装的无用软件,禁用遥测,从Windows搜索中移除Bing,以及执…...

突破运营商限制:中兴光猫配置文件解密工具完全指南
突破运营商限制:中兴光猫配置文件解密工具完全指南 【免费下载链接】ZET-Optical-Network-Terminal-Decoder 项目地址: https://gitcode.com/gh_mirrors/ze/ZET-Optical-Network-Terminal-Decoder 一、用户痛点解析:你是否正遭遇这些网络管理困境…...

Xenium空间原位转录组:从数据到生物学发现的实战解析
1. Xenium平台与空间原位转录组技术初探 第一次接触Xenium平台的数据时,我被它呈现的空间基因表达图谱震撼到了。想象一下,这就像给组织切片拍了一张"基因表达照片",每个像素点都记录着成百上千个基因的活动状态。10x Genomics推出…...

Win11Debloat终极指南:5分钟让你的Windows系统焕然一新
Win11Debloat终极指南:5分钟让你的Windows系统焕然一新 【免费下载链接】Win11Debloat 一个简单的PowerShell脚本,用于从Windows中移除预装的无用软件,禁用遥测,从Windows搜索中移除Bing,以及执行各种其他更改以简化和…...

TMSpeech:Windows端离线实时语音转文字工具的完整使用指南
TMSpeech:Windows端离线实时语音转文字工具的完整使用指南 【免费下载链接】TMSpeech 腾讯会议摸鱼工具 项目地址: https://gitcode.com/gh_mirrors/tm/TMSpeech 在数字办公和在线会议成为日常的今天,你是否曾因会议内容过多而错过关键信息&#…...

ABC系统实战指南:革新数字电路设计的逻辑综合与形式验证技术突破
ABC系统实战指南:革新数字电路设计的逻辑综合与形式验证技术突破 【免费下载链接】abc ABC: System for Sequential Logic Synthesis and Formal Verification 项目地址: https://gitcode.com/gh_mirrors/ab/abc 在现代集成电路设计流程中,工程师…...

你的爬虫被识别了?可能是浏览器指纹惹的祸!教你用Playwright伪装Canvas/WebGL指纹
浏览器指纹识别:爬虫工程师的终极伪装术 当你的爬虫程序已经完美解决了User-Agent轮换、IP代理池和请求频率控制,却依然被目标网站精准识别并封禁时,你可能正面临着现代反爬技术的终极挑战——浏览器指纹识别。这种技术不依赖于传统的请求特征…...
)
Nginx反向代理实战:不改代码轻松解决前后端跨域问题(附完整配置模板)
Nginx反向代理实战:不改代码轻松解决前后端跨域问题(附完整配置模板) 前后端分离架构已成为现代Web开发的主流模式,但随之而来的跨域问题却让不少开发者头疼。想象一下这样的场景:你的前端运行在https://frontend.com&…...

嵌入式系统的启动流程与初始化详解
嵌入式系统的启动流程与初始化详解 为什么启动流程如此重要 作为科技创业者,我深知在嵌入式产品开发中,启动流程的设计和优化直接影响产品的用户体验和可靠性。一个快速、稳定的启动流程不仅能提升产品的竞争力,还能减少客户的等待时间&#…...