收藏! 38个Python数据科研库
通用的数据科学库,即那些可能被数据科学领域的从业人员用于广义的,非神经网络的,非研究性工作的库:
数据-用于数据管理,处理和其他处理的库
数学-虽然许多库都执行数学任务,但这个小型库却专门这样做
机器学习-自我解释;不包括主要用于构建神经网络或用于自动化机器学习过程的库
自动化机器学习-主要用于自动执行与机器学习相关的过程的库
数据可视化-与建模,预处理等相反,主要提供与数据可视化相关的功能的库。
解释与探索-主要用于探索和解释模型或数据的库
数据
1. Apache Spark
https://github.com/apache/spark
star:27600,贡献:28197,贡献者:1638
Apache Spark-用于大规模数据处理的统一分析引擎
2.Pandas
https://github.com/pandas-dev/pandas
star:26800,贡献:24300,贡献者:2126
Pandas是一个Python软件包,提供了快速,灵活和可表达的数据结构,旨在使使用“关系”或“标记”数据既简单又直观。它旨在成为在Python中进行实用,真实世界数据分析的基本高级构建块。
3.Dask
https://github.com/dask/dask
star:7300,贡献:6149,贡献者:393
任务调度的并行计算
数学
4. Scipy
https://github.com/scipy/scipy
star:7500,贡献:24247,贡献者:914
SciPy发音为“ Sigh Pie”是用于数学,科学和工程的开源软件。它包括用于统计,优化,积分,线性代数,傅立叶变换,信号和图像处理,ODE求解器等的模块。
5. Numpy
GitHub - numpy/numpy: The fundamental package for scientific computing with Python.
star:1500,贡献:24266,提供者:1010
使用Python进行科学计算的基本软件包。
机器学习
6. Scikit-Learn
https://github.com/scikit-learn/scikit-learn
star:42500,贡献:26162,贡献者:1881
Scikit-learn是一个基于SciPy的Python机器学习模块,并以3条款BSD许可分发。
7. XGBoost
GitHub - dmlc/xgboost: Scalable, Portable and Distributed Gradient Boosting (GBDT, GBRT or GBM) Library, for Python, R, Java, Scala, C++ and more. Runs on single machine, Hadoop, Spark, Dask, Flink and DataFlow
star:19900,贡献:5015,贡献者:461
适用于Python,R,Java,Scala,C ++等的可扩展,便携式和分布式梯度增强GBDT,GBRT或GBM库。在单机,Hadoop,Spark,Flink和DataFlow上运行
8. LightGBM
https://github.com/microsoft/LightGBM
star:11600,贡献:2066,贡献者:172
基于决策树算法的快速,分布式,高性能梯度提升GBT,GBDT,GBRT,GBM或MART框架,用于排名,分类和许多其他机器学习任务。
9.Catboost
https://github.com/catboost/catboost
star:5400,贡献:12936,贡献者:188
快速,可扩展,高性能的“决策树上的梯度提升”库,用于对Python,R,Java,C ++进行排名,分类,回归和其他机器学习任务。支持在CPU和GPU上进行计算。
10. Dlib
https://github.com/davisking/dlib
star:9500,贡献:7868,贡献者:146
Dlib是一个现代的C ++工具箱,其中包含机器学习算法和工具,这些工具和工具可以用C ++创建复杂的软件来解决实际问题。可以通过dlib API与Python一起使用
11.Annoy
https://github.com/spotify/annoy
star:7700,贡献:778,贡献者:53
C ++ / Python中的近似最近邻居已针对内存使用情况以及加载/保存到磁盘进行了优化
12.H20ai
https://github.com/h2oai/h2o-3
star:500,贡献贡献:27894,贡献者:137
适用于更智能应用的开源快速可扩展机器学习平台:深度学习,梯度提升和XGBoost,随机森林,广义线性建模逻辑回归,弹性网,K均值,PCA,堆叠集成,自动机器学习AutoML等。
13. StatsModels
https://github.com/statsmodels/statsmodels star:5600,承诺:13446,贡献者:247
Statsmodels:Python中的统计建模和计量经济学
14. mlpack
https://github.com/mlpack/mlpack
star:3400,贡献:24575,贡献者:190
mlpack是一个直观,快速且灵活的C ++机器学习库,具有与其他语言的绑定
15.Pattern
https://github.com/clips/pattern
star:7600,贡献:1434,贡献者:20
用于Python的Web挖掘模块,具有用于抓取,自然语言处理,机器学习,网络分析和可视化的工具。
16.Prophet
https://github.com/facebook/prophet
star:11500,贡献:595,贡献者:106
用于为具有多个季节性且线性或非线性增长的时间序列数据生成高质量预测的工具。
自动化机器学习
17. TPOT
https://github.com/EpistasisLab/tpot
star:7500,贡献:2282,贡献者:66
一个Python自动化机器学习工具,可使用遗传编程来优化机器学习pipeline。
18. auto-sklearnhttps://github.com/automl/auto-sklearn
star:4100,贡献:2343,贡献者:52
auto-sklearn是一种自动化的机器学习工具包,是scikit-learn估计器的直接替代品。
19. Hyperopt-sklearn
https://github.com/hyperopt/hyperopt-sklearn
star:1100,贡献:188,贡献者:18
Hyperopt-sklearn是scikit-learn中机器学习算法中基于Hyperopt的模型选择。
20. SMAC-3
https://github.com/automl/SMAC3
star:529,贡献:1882,贡献者:29
基于顺序模型的算法配置
21. scikit-optimizehttps://github.com/scikit-optimize/scikit-optimize
star:1900,贡献:1540,贡献者:59
Scikit-Optimize或skopt是一个简单高效的库,可最大限度地减少非常昂贵且嘈杂的黑盒功能。它实现了几种基于顺序模型优化的方法。
22. Nevergrad
https://github.com/facebookresearch/nevergrad
star:2700,贡献:663,贡献者:38
用于执行无梯度优化的Python工具箱
23.Optuna
https://github.com/optuna/optuna
star:3500,贡献:7749,贡献者:97
Optuna是一个自动超参数优化软件框架,专门为机器学习而设计。
数据可视化
24. Apache Superset
https://github.com/apache/incubator-superset
star:30300,贡献:5833,贡献者:492
Apache Superset是一个数据可视化和数据探索平台
25. Matplotlib
https://github.com/matplotlib/matplotlib
star:12300,贡献:36716,贡献者:1002
Matplotlib是一个综合库,用于在Python中创建静态,动画和交互式可视化。
26.Plotly
https://github.com/plotly/plotly.py
star:7900,贡献:4604,贡献者:137
Plotly.py是适用于Python的交互式,基于开源和基于浏览器的图形库
27. Seaborn
https://github.com/mwaskom/seaborn
star:7700,贡献:2702,贡献者:126
Seaborn是基于matplotlib的Python可视化库。它提供了用于绘制吸引人的统计图形的高级界面。
28.folium
GitHub - python-visualization/folium: Python Data. Leaflet.js Maps.
star:4900,贡献:1443,贡献者:109
Folium建立在Python生态系统的数据处理能力和Leaflet.js库的映射能力之上。用Python处理数据,然后通过folium在可视化的Leaflet贴图中显示。
29. Bqplot
https://github.com/bqplot/bqplot
star:2900,贡献:3178,贡献者:45
Bqplot是Jupyter的二维可视化系统,基于图形语法的构造。
30. VisPy
https://github.com/vispy/vispy
star:2500,贡献:6352,贡献者:117
VisPy是一个高性能的交互式2D / 3D数据可视化库。VisPy通过OpenGL库利用现代图形处理单元GPU的计算能力来显示非常大的数据集。
31. PyQtgraph
https://github.com/pyqtgraph/pyqtgraph
star:2200,贡献:2200,贡献者:142
用于科学/工程应用的快速数据可视化和GUI工具
32.Bokeh
https://github.com/bokeh/bokeh
star:1400,贡献:18726,贡献者:467
Bokeh是用于现代Web浏览器的交互式可视化库。它提供通用图形的优雅,简洁的构造,并在大型或流数据集上提供高性能的交互性。
33.Altair
https://github.com/altair-viz/altair
star:600,贡献:3031,贡献者:106
Altair是用于Python的声明性统计可视化库。使用Altair,您可以花费更多时间来理解数据及其含义。
解释与探索
34. eli5https://github.com/TeamHG-Memex/eli5
star:2200,贡献贡献:1198,贡献者:15
一个用于调试/检查机器学习分类器并解释其预测的库
35. LIMEh
ttps://github.com/marcotcr/lime star:800,承诺:501,贡献者:41
Lime:解释任何机器学习分类器的预测
36. SHAP
https://github.com/slundberg/shap
star:10400,贡献:1376,贡献者:96
一种博弈论方法,用于解释任何机器学习模型的输出。
37. YellowBrick
https://github.com/DistrictDataLabs/yellowbrick
star:300,贡献:825,贡献者:92
可视化分析和诊断工具,有助于机器学习模型的选择。
38.pandas-profiling
https://github.com/pandas-profiling/pandas-profiling
star:6200名,贡献:704名,贡献者:47名
原文链接:
生态、遥感、水文水资源、大气科学多领域详细操作教程
相关文章:

收藏! 38个Python数据科研库
通用的数据科学库,即那些可能被数据科学领域的从业人员用于广义的,非神经网络的,非研究性工作的库: 数据-用于数据管理,处理和其他处理的库 数学-虽然许多库都执行数学任务,但这个小型库却专门这样做 机…...

SpringBoot过滤器获取Bean-请求重复可读-获取请求体数据-用户IP归属地获取
文章目录一.获取Bean二. Request重复可读三. 过滤器获取Body请求体数据四.用户ip获取一.获取Bean 网上一些论调说Filter无法注入Bean的原因是加载顺序: listener—>filter—>servlet导致的.我不赞同. 原因:默认机制下,在SpringBoot应用启动时,IOC…...

有哪些特别小众而有趣的编程语言呢?
相对较小众的编程语言,还要有趣?发表一些个人看法,如果不对大家口味,大家轻喷,留情留情。 Rust:Rust是一种系统编程语言,致力于提供高性能、可靠性和安全性。Rust具有内存安全和线程安全的特性&…...

vue中使用高德
首先我们要申请高德地图的key,当前升级过后高德地图使用也需要加上安全秘钥 注册账号 访问高德地图开发平台根据实际情况填写就可以🍜(实名认证的时候选择个人就可以,如果是企业级的项目,可能会涉及人员变动…...
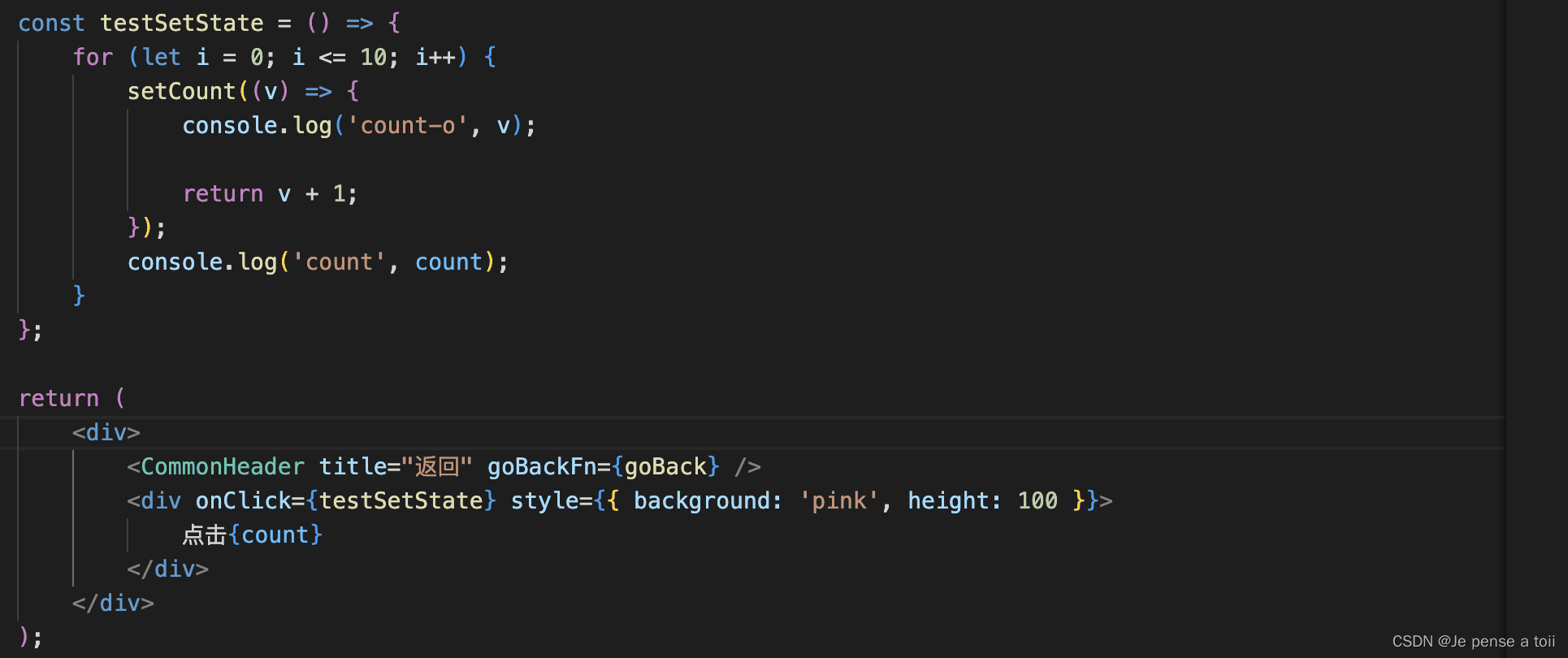
React class组件和hooks setState异步更新数据详解
一、 class组件setState详解 1.class组件setState异步更新数据详解 class Father extends React.Component{state {num:0}addHandler () > { this.setState({num: 100})console.log(state中的值,this.state.num)}render() { return (<div><button onClick{this…...

ToBeWritten之嵌入式操作系统
也许每个人出生的时候都以为这世界都是为他一个人而存在的,当他发现自己错的时候,他便开始长大 少走了弯路,也就错过了风景,无论如何,感谢经历 转移发布平台通知:将不再在CSDN博客发布新文章,敬…...

git 实际开发中使用-解决问题
前言 git代码版本管理工具,打破常规的物理传输,更新,合并,回滚提高了开发效率和可追溯性。 网上的资料会把所有的命令都很全也很多,导致对刚刚了解的同学不友好,很难实际使用。 每个人都有自己使用git的习…...

新星计划·2023-第1期 - Python赛道报名入口 -〖你就是下一个新星〗
↓↓↓报名方式:(下滑到本页面底部)重要提醒:这里是 新星计划2023-第1期 - Python赛道报名入口,一经报名,不可更换。报名入口点击此处跳转 一、新星计划 新星计划是一个以发掘潜力新人、培养优质博主为目…...

Android LowMemoryKiller概述
Agenda Low memory killer 概述 内核空间LMK ULMK‐vmpressure ULMK‐PSI Low memory killer 概述 lowmemorykiller的作用就是当内存比较紧张的时候去及时杀掉一些对用户来说不那么重要的进程,回收内存,保证手机的正常运行。安卓平台lowmemorykiller机…...
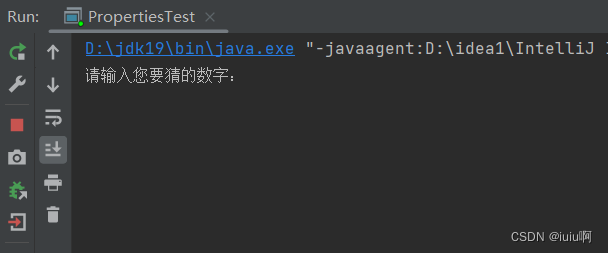
特殊操作流——案例:游戏次数
需求:请求程序实现猜数字小游戏只能试玩三次,如果还想玩,提示:游戏已经结束,想玩请充值(www.itcast.cn) 思路: 写一个游戏类,里面有一个猜数字的小游戏 写一个测试类&am…...
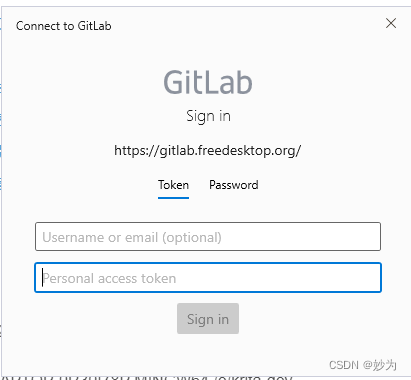
git clone connect to gitlab sign in token弹窗让我输入用户名和密码
系列文章目录 文章目录系列文章目录前言前言 当我使用git bash输入命令:git clone https://gitlab.freedesktop.org/raqm/raqm.git libraqm 弹窗 ASUSLAPTOP-0R30I78P MINGW64 /e/krita-dev $ git clone https://gitlab.freedesktop.org/raqm/raqm.git libraqm C…...

【Blender】如何在Blender中添加HDRI环境贴图
什么是HDRI环境贴图 环境贴图或HDRI贴图是在Blender中照亮3D场景并实现逼真效果的最有效和最快捷的方法之一。 HDRIs本质上是现实世界照明的快照,其中包含高动态范围成像(HDRI)的准确照明细节。HDRI是一个包含亮度信息(从暗…...
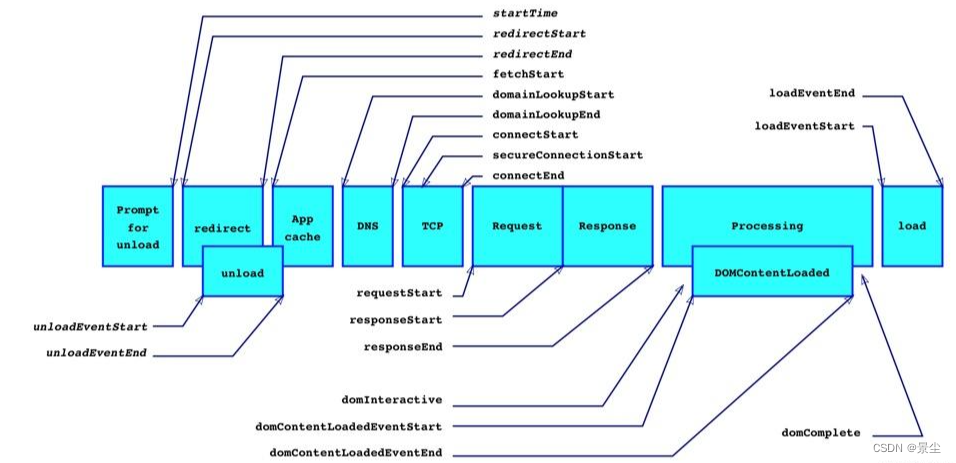
前端监控指的是什么?
前端监控分为三个方面: 异常监控(监控前端页面的报错)性能监控(监控页面的性能)用户行为监控(监控用户的行为,计算PV、UV、在线时间等、数据监控即我们常说的埋点 例子1 在后端突然上线了某个需…...

.net core 面试题 2023
文章目录1. 什么是 ASP.net core2. .net 术语3. 托管资源 和 非托管资源4. GC 和 垃圾回收5. .net中所有类的基类6. 如何实现对象的深拷贝7. 依赖注入,为什么使用依赖注入8. IOC容器的注入方法9. ASP.net core 中 服务生命周期10. scoped的 service 可以注入到 sing…...

和ChatGPT关于Swing music的一场对话(上篇)
什么是 Swing Music ? Swing Music 是一款漂亮的自托管音乐播放器,适用于您的本地音频文件。就像一个更酷的 Spotify …但带上你自己的音乐。 第一次在 reddit 上看到 Swing Music,就被其 UI 吸引了 但源码站点的releases 中只有 windows 和 …...

java版工程项目管理系统源码 Spring Cloud+Spring Boot+Mybatis+Vue+ElementUI+前后端分离 功能清单
ava版工程项目管理系统 Spring CloudSpring BootMybatisVueElementUI前后端分离 功能清单如下: 首页 工作台:待办工作、消息通知、预警信息,点击可进入相应的列表 项目进度图表:选择(总体或单个)项目显示1…...
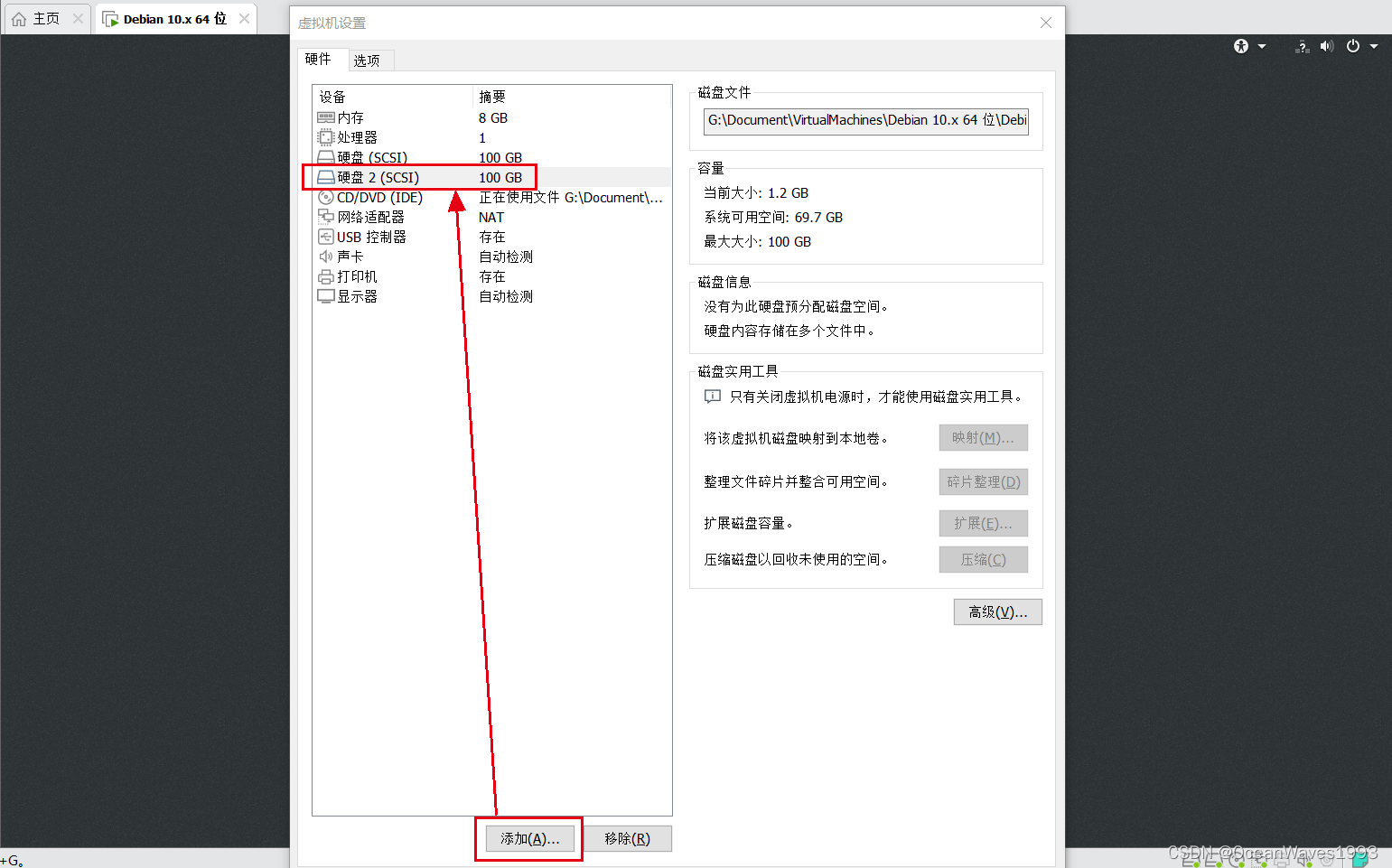
debian 10 扩展分区容量
debian 10 扩展分区容量1、扩展分区原因2、添加一块磁盘3、命令记录3.1、新增加的磁盘是/dev/sdb3.2、使用磁盘/dev/sdb 创建物理卷3.3、 把物理卷/dev/sdb加入到卷组debian-vg中3.4、查看物理卷、逻辑卷3.5、扩展逻辑卷/tmp3.6、逻辑卷组debian-vg 空余空间被用掉10g 还剩90g可…...
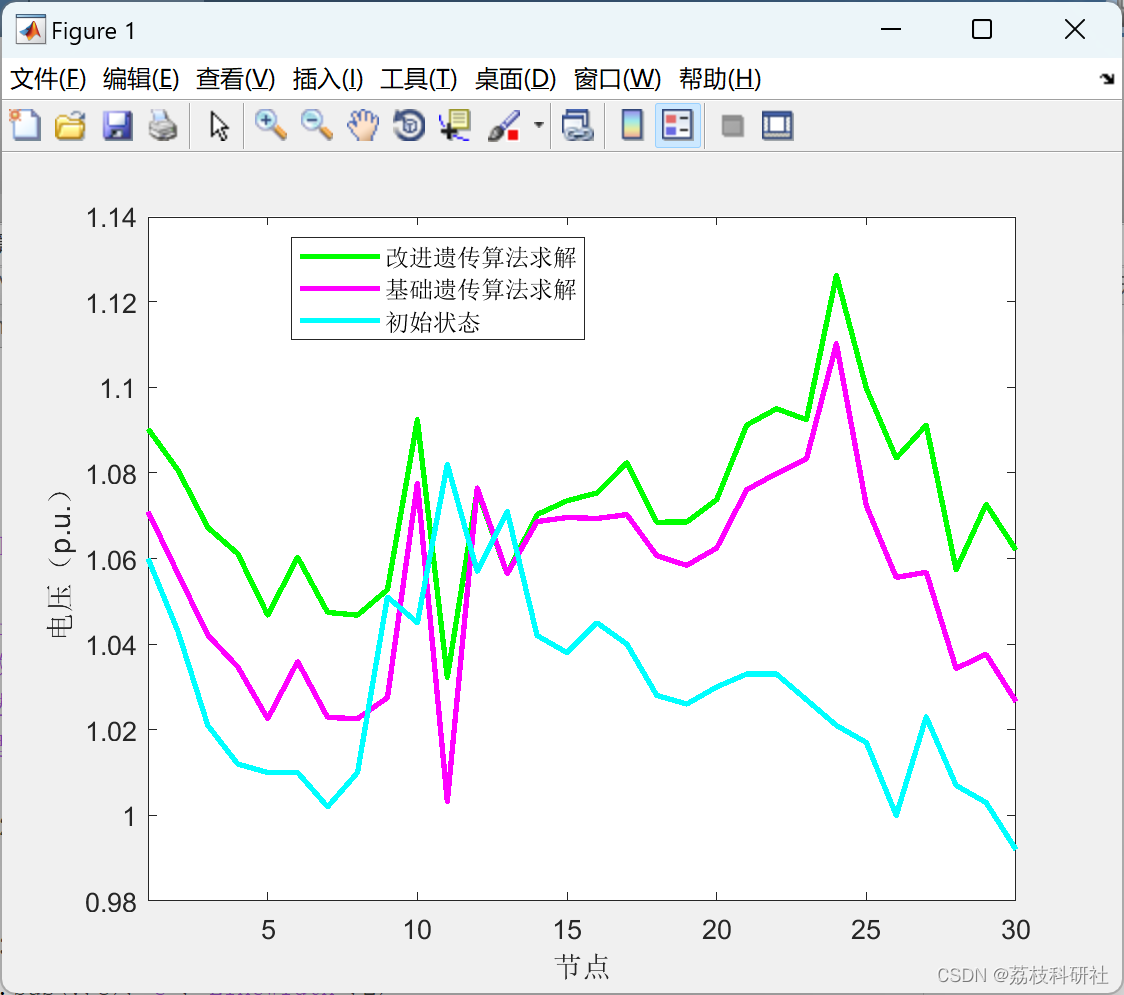
【无功优化】基于改进遗传算法的电力系统无功优化研究【IEEE30节点】(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
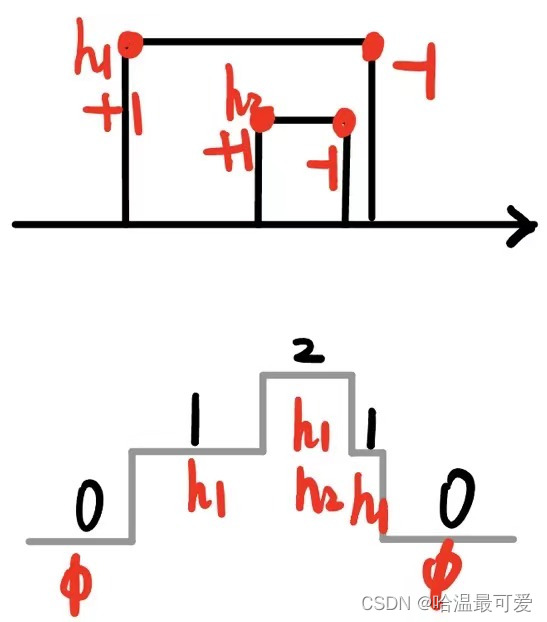
LeetCode 218. 天际线问题
城市的 天际线 是从远处观看该城市中所有建筑物形成的轮廓的外部轮廓。给你所有建筑物的位置和高度,请返回 由这些建筑物形成的 天际线 。 每个建筑物的几何信息由数组 buildings 表示,其中三元组 buildings[i] [lefti, righti, heighti] 表示…...
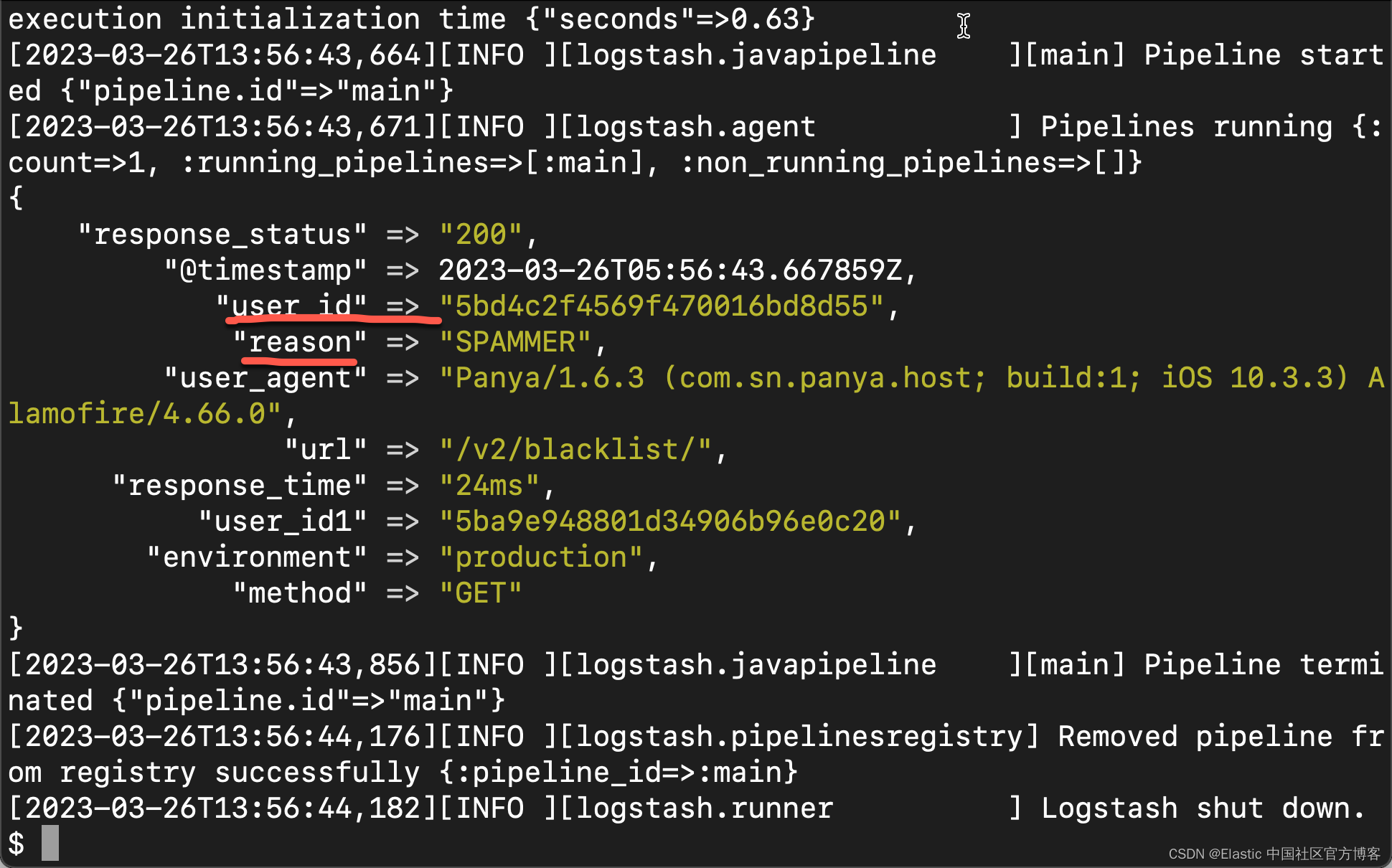
Logstash:使用自定义正则表达式模式
有时 Logstash Grok 没有我们需要的模式。 幸运的是我们有正则表达式库:Oniguruma。在很多时候,如果 Logstash 所提供的正则表达不能满足我们的需求,我们选用定制自己的表达式。 定义 Logstash 是一种服务器端数据处理管道,可同时…...

从IR压降到远程采样:大电流PCB供电设计的实战经验与陷阱规避
1. 项目背景与问题浮现几年前,我参与了一个项目,主电源是一个标准的开放式机架电源,需要为一个位于机箱内相对较远的模块提供5V、约20A的直流电。最初的供电路径设计是依靠PCB走线,我们使用了1盎司铜厚的板材。问题很快就出现了&a…...

Matlab ode45求解微分方程保姆级教程:从单变量到多智能体系统,附完整代码
Matlab ode45求解微分方程:从单变量到多智能体系统的工程实践 微分方程是描述动态系统演化的核心数学工具,而Matlab的ode45求解器则是工程师和科研人员最常用的数值求解利器。本文将带你从最基础的单个微分方程求解出发,逐步深入到多智能体系…...

Loop:Mac窗口管理的终极免费解决方案,告别杂乱桌面
Loop:Mac窗口管理的终极免费解决方案,告别杂乱桌面 【免费下载链接】Loop Window management made elegant. 项目地址: https://gitcode.com/GitHub_Trending/lo/Loop 你是否曾为Mac上杂乱的窗口而烦恼?当多个应用同时打开时ÿ…...

为OpenClaw智能体工作流配置Taotoken作为稳定后端API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为OpenClaw智能体工作流配置Taotoken作为稳定后端API OpenClaw是一个用于构建智能体工作流的流行框架,它允许开发者通过…...

多视角时空对齐 + 跨镜轨迹融合:镜像视界打造无断点跟踪闭环
多视角时空对齐 跨镜轨迹融合:镜像视界打造无断点跟踪闭环在工业安防、智慧仓储、园区管控等全域场景智能化升级进程中,目标跟踪的连续性、精准性、全域性,始终是衡量管控体系效能的核心指标,也是传统视频监控技术难以逾越的行业…...

答辩 PPT 还在熬夜手搓?Paperxie AI 一键救场,毕业季不熬无用夜
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPThttps://www.paperxie.cn/ppt/createhttps://www.paperxie.cn/ppt/create 当论文终稿尘埃落定,本以为能松一口气,却发现答辩 PPT 成了压垮心态的最后一根稻草。对着空白页面不…...

别再为答辩 PPT 秃头了!PaperXie 的 AI PPT 功能,让你把时间花在更重要的地方
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPThttps://www.paperxie.cn/ppt/createhttps://www.paperxie.cn/ppt/create 距离毕业论文答辩只剩半个月,你的 PPT 还停留在 “空白文档” 阶段吗? 我见过太多同学在这个阶段陷…...

Beyond Compare 5完全激活指南:3种简单方法告别30天试用限制
Beyond Compare 5完全激活指南:3种简单方法告别30天试用限制 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 你是否正在使用Beyond Compare 5这款强大的文件对比工具,却因…...

AI时代计算机教育变革:从代码生成到系统设计的教学重构
1. 项目概述:当AI走进计算机课堂,我们面临的真实图景作为一名在计算机教育一线摸爬滚打了十几年的从业者,我亲眼见证了从粉笔黑板到多媒体教室,再到如今云端协作的变迁。但最近两年,以ChatGPT、GitHub Copilot为代表的…...

从零构建开发者效率工具:CLI脚手架与自动化工作流实践
1. 项目概述与核心价值最近在开源社区里,一个名为smouj/smouj的项目引起了我的注意。乍一看这个标题,可能会让人有些摸不着头脑,它不像常见的vue/vue或tensorflow/tensorflow那样直白地揭示了其技术栈。但恰恰是这种看似“神秘”的命名&#…...