Logstash:使用自定义正则表达式模式
有时 Logstash Grok 没有我们需要的模式。 幸运的是我们有正则表达式库:Oniguruma。在很多时候,如果 Logstash 所提供的正则表达不能满足我们的需求,我们选用定制自己的表达式。
定义
- Logstash 是一种服务器端数据处理管道,可同时从多个来源获取数据,对其进行转换,然后将其发送到 “存储”(如 Elasticsearch)。
- Grok 是 Logstash 中的过滤器,用于将非结构化数据解析为结构化和可查询的内容。
- Regular expression 是定义搜索模式的字符序列。
如果你已经在运行 Logstash,则无需安装额外的正则表达式库,因为 Grok 位于正则表达式之上,因此任何正则表达式在 grok 中也有效 —— Elastic 文档。
语法
Grok
Grok 语法如下:
%{SYNTAX:SEMANTIC}- SYNTAX 是默认的 grok 模式
- SEMANTIC 是 key
Oniguruma
oniguruma 语法如下:
(?<field_name>the pattern here)Grok + Oniguruma
你可以像下面这样组合 Grok 和 Oniguruma:
%{SYNTAX:SEMANTIC} (?<field_name>the pattern here)让我们开始吧
样本数据
为了演示我们如何将 Oniguruma 与 Grok 结合使用,我们将在示例中使用下面的日志数据。
production GET /v2/blacklist/ 200 24ms 5ba9e948801d34906b96e0c20 Panya/1.6.3 (com.sn.panya.host; build:1; iOS 10.3.3) Alamofire/4.66.0 {\"user_id\":\"5bd4c2f4569f470016bd8d55\",\"reason\":\"SPAMMER\"}
日志数据结构:
production == environment
GET == method
/v2/blacklist == url
200 == response_status
24ms == response_time
5bc6e716b5d6cb35fc9687c0 == user_id
Panya/1.6.3 (com.sn.panya.host; build:1; iOS 10.3.3) Alamofire/4.66.0 == user_agent
{\"user_id\":\"5bd4c2f4569f470016bd8d55\",\"reason\":\"SPAMMER\"} == req.body目的:
目标是找到一种模式来构造非结构化日志数据。为此,我们将使用 Kibana 里的 Grok Debugger 来进行测试:
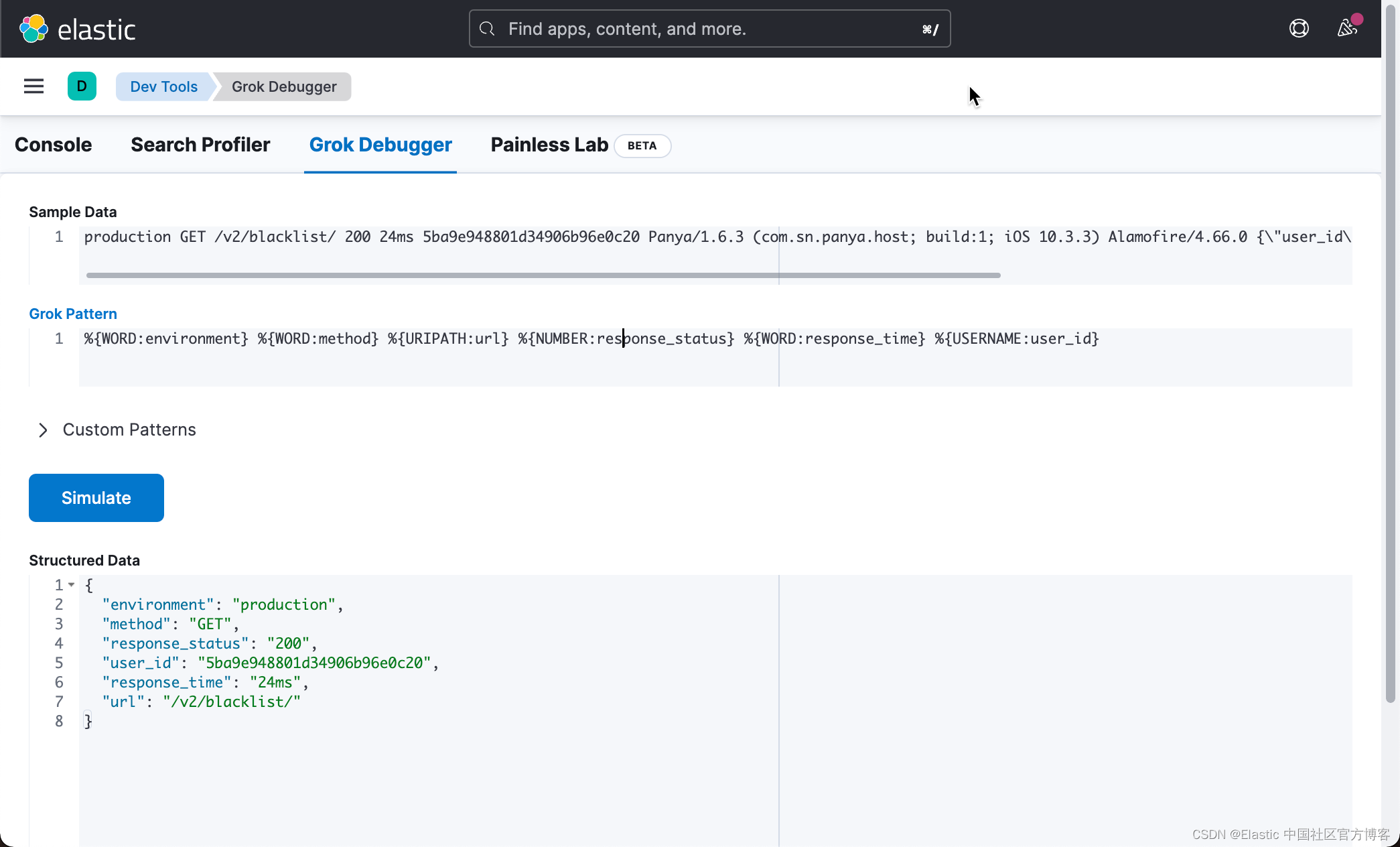
其中,我们的 Grok pattern 定义如下:
%{WORD:environment} %{WORD:method} %{URIPATH:url} %{NUMBER:response_status} %{WORD:response_time} %{USERNAME:user_id}如上所示,上面的 Grok pattern 产生如下的结果:
{"environment": "production","method": "GET","response_status": "200","user_id": "5ba9e948801d34906b96e0c20","response_time": "24ms","url": "/v2/blacklist/"
}这是一个不错的开始,但还不完整。 没有 user_agent 和 req.body 的映射。要提取 user_agent 和 req.body,我们需要仔细检查其结构。
空格分隔符
值 production GET /v2/blacklist/ 200 24ms 5ba9e948801d34906b96e0c20 由空格分隔,这很容易使用。
但是,对于 user_agent,可以有动态数量的空格,具体取决于发送请求的硬件类型。
Panya/1.6.3 (com.sn.panya.host; build:1; iOS 10.3.3) Alamofire/4.66.0 我们如何解释这种持续变化?
提示:看一下 req.body 的结构。
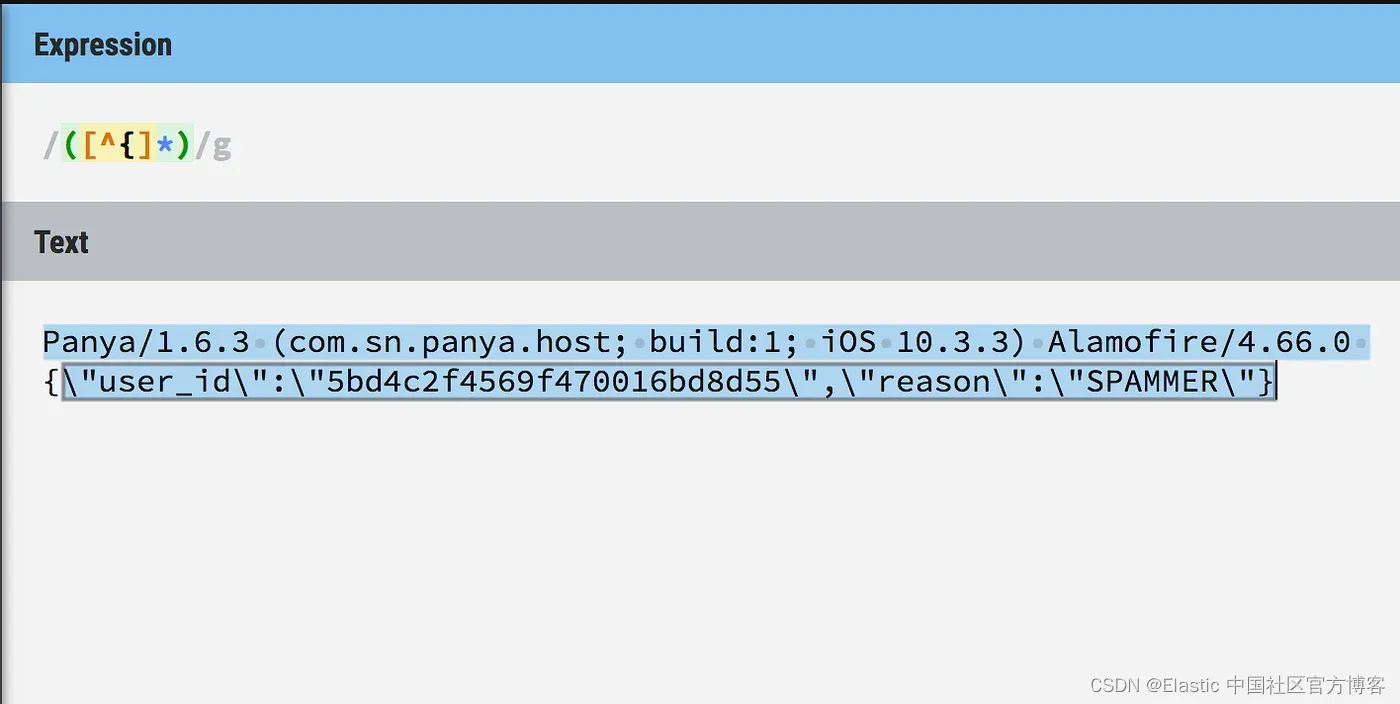
{\”user_id\”:\”5bd4c2f4569f470016bd8d55\”,\”reason\”:\”SPAMMER\”}我们可以看到 req.body 是由花括号 {} 组成的。
利用这些知识,我们可以构建一个自定义正则表达式模式来查找第一个左括号之前的所有内容,然后获取之后的所有内容。
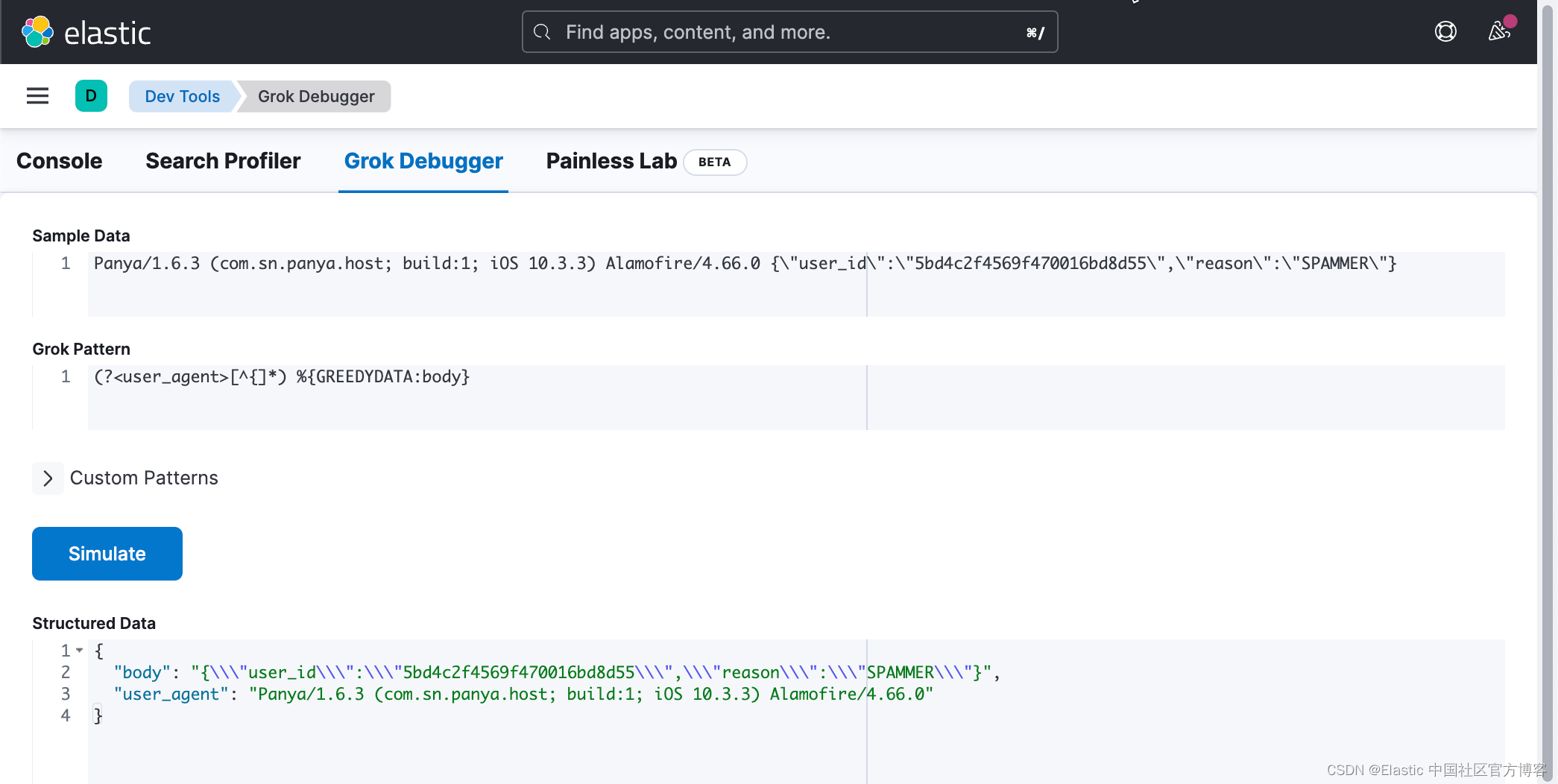
在上面,我们使用 Grok pattern:
(?<user_agent>[^{]*) %{GREEDYDATA:body}你可在这个链接中找到 “regex match everything until character”。
把所有的都放在一起
将其应用于 grok 调试器中的自定义正则表达式模式,我们得到了我们想要的结果:
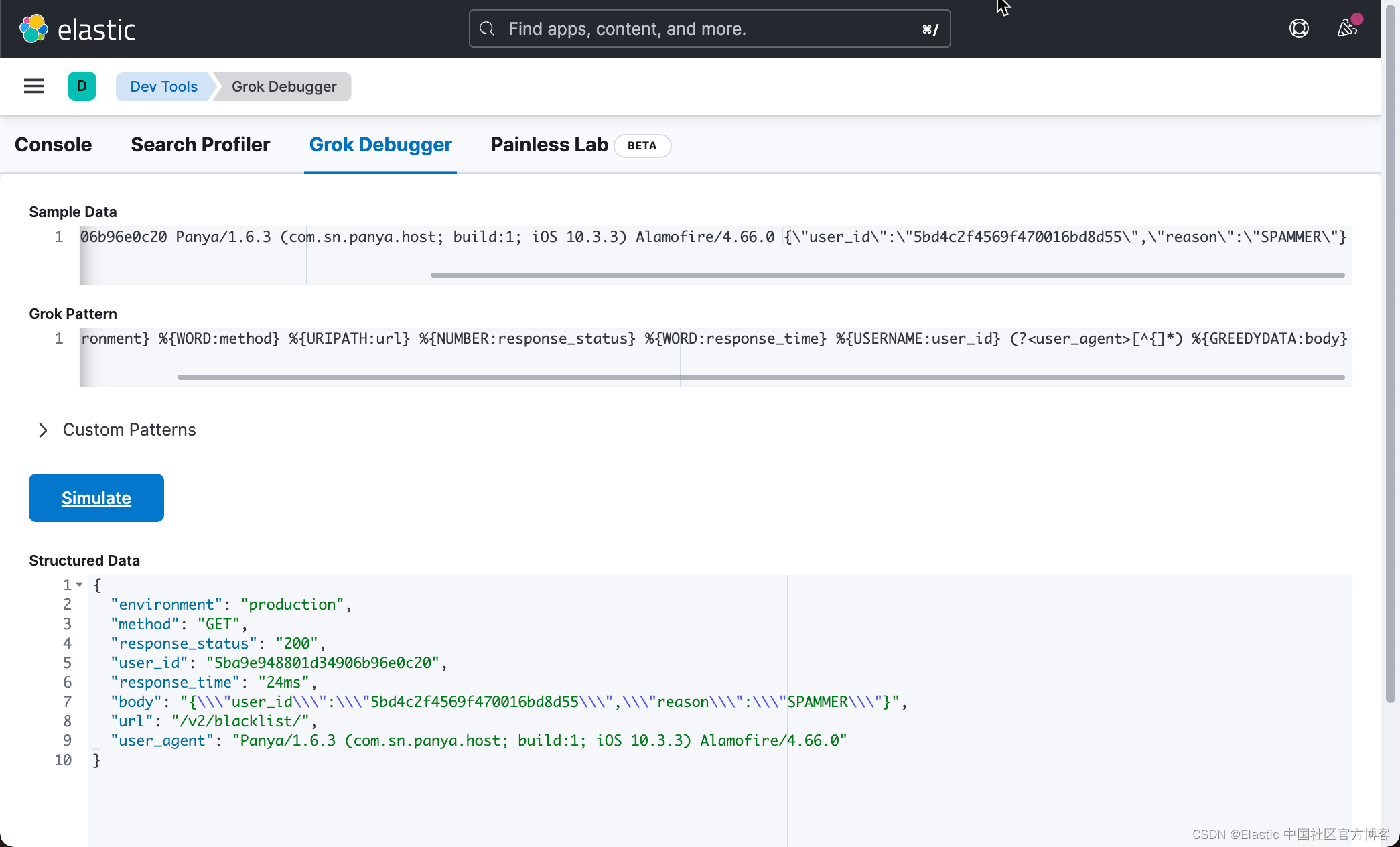
我们的 Grok pattern 为:
%{WORD:environment} %{WORD:method} %{URIPATH:url} %{NUMBER:response_status} %{WORD:response_time} %{USERNAME:user_id} (?<user_agent>[^{]*) %{GREEDYDATA:body}
创建 logstash.conf
为了能够测试我们的 Grok pattern 是否正确,我们创建如下的一个 logstash.conf 文件。我们可以参考之前的文章 “Logstash:在实施之前测试 Logstash 管道/过滤器”。
logstash.conf
input {generator {message => 'production GET /v2/blacklist/ 200 24ms 5ba9e948801d34906b96e0c20 Panya/1.6.3 (com.sn.panya.host; build:1; iOS 10.3.3) Alamofire/4.66.0 {"user_id":"5bd4c2f4569f470016bd8d55","reason":"SPAMMER"}'count => 1}
}filter {grok {match => { "message" => "%{WORD:environment} %{WORD:method} %{URIPATH:url} %{NUMBER:response_status} %{WORD:response_time} %{USERNAME:user_id1} (?<user_agent>[^{]*) %{GREEDYDATA:body}"}}mutate {remove_field => ["message", "event", "host", "@version"]}
} output {stdout {codec => rubydebug}
}我们使用如下的命令来启动 Logstash pipeline:
./bin/logstash -f logstash.conf
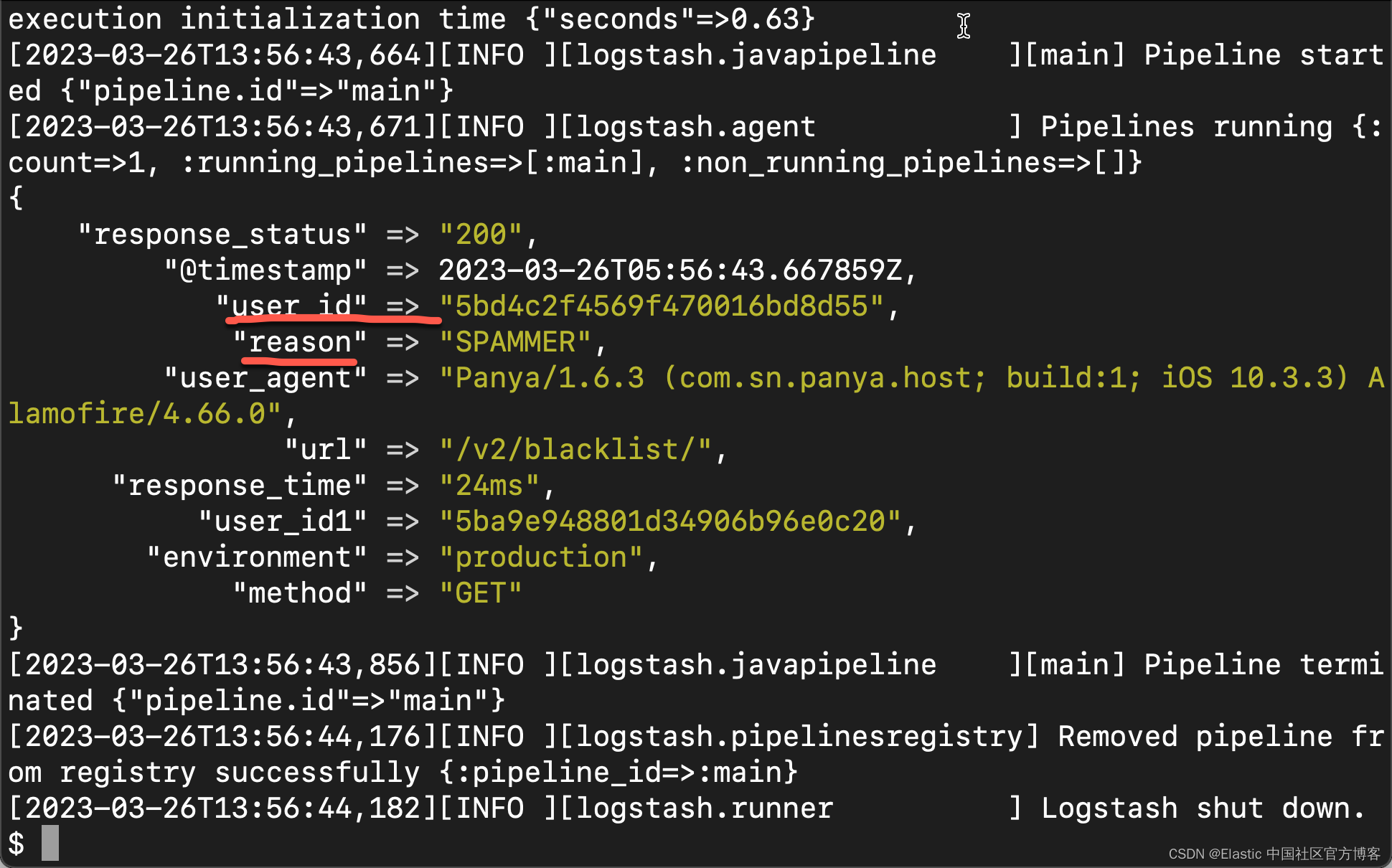
从上面的输出中,我们可以看出来原始的数据已经变为结构化的数据了。我们可以看到美中不足的是 body 这个数据是一个 JSON 格式的数据,还没有被结构化。我们进一步修改我们的 logstash.conf 配置文件:
logstash.conf
input {generator {message => 'production GET /v2/blacklist/ 200 24ms 5ba9e948801d34906b96e0c20 Panya/1.6.3 (com.sn.panya.host; build:1; iOS 10.3.3) Alamofire/4.66.0 {"user_id":"5bd4c2f4569f470016bd8d55","reason":"SPAMMER"}'count => 1}
}filter {grok {match => { "message" => "%{WORD:environment} %{WORD:method} %{URIPATH:url} %{NUMBER:response_status} %{WORD:response_time} %{USERNAME:user_id1} (?<user_agent>[^{]*) %{GREEDYDATA:body}"}}json {source => "body"}mutate {remove_field => ["message", "event", "host", "@version", "body"]}} output {stdout {codec => rubydebug}
}在上面,我们添加了 json 过滤器来处理 body,从而更进一步结构化数据。我们再次运行 Logstash。我们可以看到如下的结果:

从上面,我们可以看到 body 也被结果化了。我们可以看到 user_id 及 reason 两个字段。
相关文章:
Logstash:使用自定义正则表达式模式
有时 Logstash Grok 没有我们需要的模式。 幸运的是我们有正则表达式库:Oniguruma。在很多时候,如果 Logstash 所提供的正则表达不能满足我们的需求,我们选用定制自己的表达式。 定义 Logstash 是一种服务器端数据处理管道,可同时…...

常见的一致性问题及解决
什么是一致性 一致性问题主要是因为分布式系统中的多个节点之间可能存在网络延迟、故障等原因导致的。具体而言,分布式系统中的数据一致性问题可以分为以下几种类型: 强一致性:指在任何时间点,所有节点中的数据都是一致的。这种…...

vue下载文件
注意请求时加入:responseType: bloburl:写全了,因为前后端端口号不同downloadImage(imgUrl) {let formData new FormData();formData.append(fileName, this.getFilename(imgUrl)); // 用于后端下载文件的路径axios.post(http://localhost:8…...
人人都是数据分析师-数据分析之数据图表可视化(下)
当前的BI报表、运营同学的汇报报告中数据图表大多为 表格、折线图、柱状图和饼图,但是实际上还有很多具有代表性的可视化图表,因此将对常见的可视化图表进行介绍,希望这些图表可视化方法能够更好的提供数据的可用性。 人人都是数据分析师-数…...
考勤、充电,绑身份,你的人员定位系统就缺它了!
我们做人脸识别智能发卡充电柜是要解决什么问题? (1)工地、港口等场景,人员流动大,管理难 在工地、港口等场景,人员组成通常比较复杂。有来自施工方、客户、各劳务队、各管理层的人员,以及来自…...
RocketMQ水平扩展及负载均衡详解
文章目录 Broker端水平扩展Broker负载均衡commit logProducer负载均衡Consumer负载均衡集群模式广播模式RocketMQ是一个分布式具有高度可扩展性的消息中间件。本文旨在探索在broker端,生产端,以及消费端是如何做到横向扩展以及负载均衡的。 Broker端水平扩展 Broker负载均衡…...

java接口笔记
关键字:interface 定义形式:interface 接口名 { 接口体 } 细节: 1.接口里的方法可以为抽象方法,静态方法,默认方法(default 关键字) 2.接口里的方法只能是public ,可以不用写&a…...

安利安利-向大家推荐一个超级牛的etcd管理工具-EtcdKeeperFyne
etcd介绍 关于etcd的介绍大家可以看下这篇文章 etcd 开源仓库地址:EtcdKeeperFyne EtcdKeeperFyne 今天主要是向大家推荐一款使用起来特别方便的Etcd管理工具 EtcdKeeperFyne,具体运行起来的界面如下: 推荐原因 使用简单安装简单&…...
)
数字经济系列讲座-数字化平台(商业购物平台)
数字经济系列讲座 文章目录 钱的流向退货成本research questionLiterature review现金流发生在平台内侧平台商业模式转型Modelmodel 假设四种情形标记符利润函数&效用函数&平台效益模型构建利润对比图结论future directions讲座题目 To Adopt or not? The Impacts of…...

python3中collections模块详解
collections模块简介 collections包含了一些特殊的容器,针对Python内置的容器,例如list、dict、set和tuple,提供了另一种选择; namedtuple,可以创建包含名称的tuple; deque,类似于list的容器&a…...

护网面试题2.0
1.CSS和CSRF区别 通俗点讲的话: XSS通过构造恶意语句获取对方cookie, CSRF通过构造恶意链接利用对方cookie,但看不到cookie XSS比CSRF更加容易发生,但CSRF比XSS攻击危害更大 2.XSS原理 XSS(Cross-Site Scripting&…...

学习计算机组成原理第1天(计算机发展历程)
计算机发展历程计算机硬件发展计算机软件的发展经典例题计算机硬件发展 计算机的四代变化 1)第一代计算机(1946-1957年)电子管时代。特点:逻辑元件采用电子管;使用机器语言进行编程;主存用延迟线或磁鼓存储…...

二维字符数组与char** 关系 段错误打印
如下为错误,打印断错误。 具体原因参考 http://c.biancheng.net/view/2022.html 二维字符数组与char** 关系 原因: char a[2][20] ; 这是一个二维字符数组。 二维字符数组,这里相当于是两个一维字符串数组。这两个数组在内存的存放位置可以…...
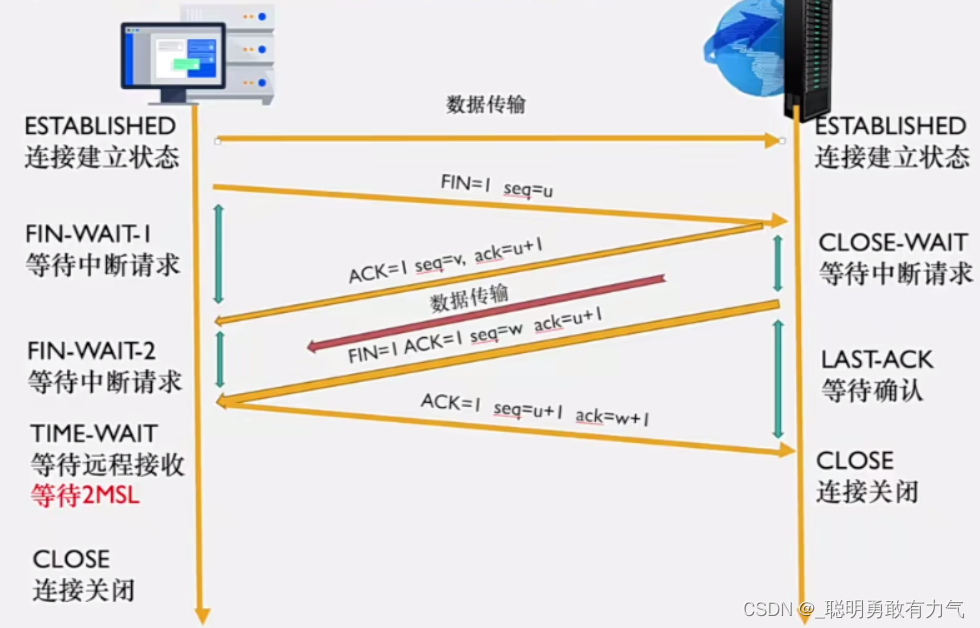
从url输入到页面呈现发生了什么
从url输入到页面呈现发生了什么 1.URL解析 encodeURI / decodeURI 对整个URL的编码:处理空格/中文 let url "http://https://blog.csdn.net/api/ ?lx1&name科比&fromhttp://www.baidu.com/"; console.log(encodeURI(url));encodeURICompone…...
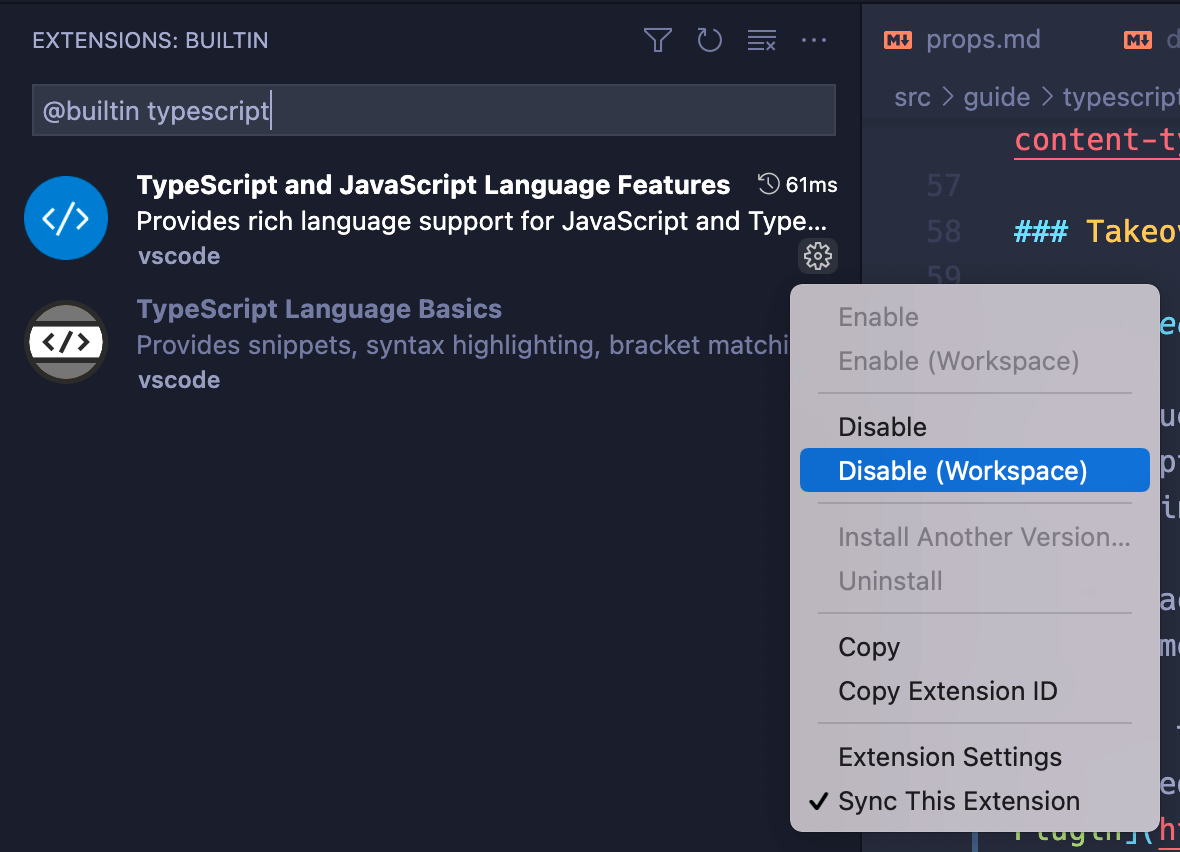
vue之--使用TypeScript
搭配 TypeScript 使用 Vue 像 TypeScript 这样的类型系统可以在编译时通过静态分析检测出很多常见错误。这减少了生产环境中的运行时错误,也让我们在重构大型项目的时候更有信心。通过 IDE 中基于类型的自动补全,TypeScript 还改善了开发体验和效率。…...

HDFD 回收站【Trash】机制
一、回收站 Trash 机制开启 HDFS本身是一个文件系统,默认情况下HDFS不开启回收站,数据删除后将被永久删除 添加并修改两个属性值可开启Trash功能 - (core-site.xml) <property> <name>fs.trash.interval</name> <value>1440&…...

【Redis】简介
简介 Redis是一个开源的内存数据结构存储系统,它支持多种数据结构(如字符串、哈希、列表、集合、有序集合)以及多种功能(如事务、发布/订阅、Lua脚本执行等)。Redis还提供了持久化功能,可以将数据存储到磁…...

【Go进阶】Goroutine 实现原理
目录 1、GMP模型 2、Goroutine调度策略 队列轮转 系统调用 工作量窃取...
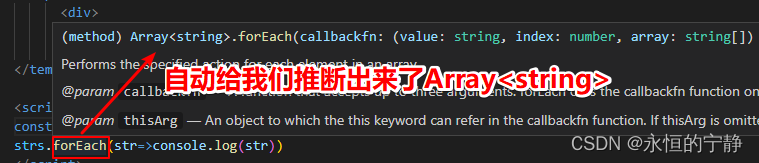
TypeScript学习笔记之二(高级类型)
文章目录一、TypeScript高级类型1.1 class类1.2 class继承1.3 class类成员可见性1.4 readonly1.5 类型兼容性1.5.1 对象之间的类型兼容性1.5.2 接口之间类型兼容性1.5.3 函数之间类型兼容性1.6 交叉类型1.7 交叉类型(&)和继承(extends)的对比二、泛型2.1 泛型约束--指定更具…...
如何远程控制电脑?您只需要这样做
案例:在外面怎么远程控制电脑? “我学校教室有电脑,但我每次上课的时候还是需要带自己的电脑(好重!),只因为有些资料只在自己的电脑上。听说远程控制电脑可以解决这个问题,那如何远…...

3个步骤实现极致跨平台远程控制:BilldDesk Pro突破性体验
3个步骤实现极致跨平台远程控制:BilldDesk Pro突破性体验 【免费下载链接】billd-desk 基于Vue3 WebRTC Nodejs Flutter搭建的远程桌面控制 项目地址: https://gitcode.com/gh_mirrors/bi/billd-desk 还在为远程协作的种种限制而烦恼吗?当你需…...

如何在3天内快速掌握音频驱动面部动画技术?完整实战指南 [特殊字符]
如何在3天内快速掌握音频驱动面部动画技术?完整实战指南 🚀 【免费下载链接】FACEGOOD-Audio2Face http://www.facegood.cc 项目地址: https://gitcode.com/gh_mirrors/fa/FACEGOOD-Audio2Face 想要让虚拟角色拥有逼真的面部表情吗?FA…...

5步掌握跨平台资源下载神器:从音乐到短视频的完整解决方案
5步掌握跨平台资源下载神器:从音乐到短视频的完整解决方案 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 你是否…...

MusePublic插件开发指南:Photoshop艺术生成插件实战
MusePublic插件开发指南:Photoshop艺术生成插件实战 1. 前言 作为设计师,你是否曾经遇到过这样的困境:客户急着要一套海报设计方案,你却在创意构思上卡壳了好几个小时?或者想要尝试新的艺术风格,却苦于手…...

【Python MCP服务器开发终极模板】:20年架构师亲授源码级解析与高并发优化实战
第一章:Python MCP服务器开发模板概览与核心设计哲学Python MCP(Model-Controller-Protocol)服务器开发模板是一套面向协议驱动、可插拔架构的轻量级服务框架,专为构建高内聚、低耦合的模型交互后端而设计。其核心不依赖于特定Web…...

uni-app Android应用华为审核隐私权限提示与上架授权说明实战指南
1. uni-app Android应用华为审核隐私权限问题解析 第一次用uni-app开发Android应用准备上架华为市场时,我被审核驳回的理由整懵了——"缺少权限使用说明"。明明iOS版本在manifest.json配得好好的,怎么到Android就出问题?后来才发现…...

SDXL-Turbo实战教程:从A futuristic car到motorcycle的删改逻辑教学
SDXL-Turbo实战教程:从A futuristic car到motorcycle的删改逻辑教学 获取更多AI镜像 想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,…...

Qwen2.5-VL应用指南:如何用它做智能客服、文档分析和内容创作
Qwen2.5-VL应用指南:如何用它做智能客服、文档分析和内容创作 1. 引言:认识Qwen2.5-VL的强大能力 Qwen2.5-VL是通义千问团队推出的最新视觉-语言多模态模型,相比前代产品有了显著提升。这个7B参数的模型不仅能理解图像内容,还能…...
方案)
打破系统壁垒:从 Android 到 macOS,打造全平台统一终端管理(MDM)方案
目录 什么是统一设备管理? 一、引言 二、为什么跨平台设备管理至关重要 三、统一设备管理平台的核心功能 3.1 多平台生态整合 3.2 全设备生命周期管理 3.3 统一策略配置 3.4 广泛的行业适用性 四、实施统一设备管理的优势 五、企业设备管理的未来趋势 六…...

3个核心功能让Windows优化变得如此简单:Winhance中文版深度体验
3个核心功能让Windows优化变得如此简单:Winhance中文版深度体验 【免费下载链接】Winhance-zh_CN A Chinese version of Winhance. C# application designed to optimize and customize your Windows experience. 项目地址: https://gitcode.com/gh_mirrors/wi/Wi…...