python3中collections模块详解
collections模块简介
collections包含了一些特殊的容器,针对Python内置的容器,例如list、dict、set和tuple,提供了另一种选择;
namedtuple,可以创建包含名称的tuple;
deque,类似于list的容器,可以快速的在队列头部和尾部添加、删除元素;
Counter,dict的子类,计算可hash的对象;
OrderedDict,dict的子类,可以记住元素的添加顺序;
defaultdict,dict的子类,可以调用提供默认值的函数;
Counter
from collections import Counter
In [41]: wordList = [11, 22, 33, 11, 22, 11, 11]
In [42]: c = Counter()
In [43]: for word in wordList:...: c[word] += 1...:
In [44]: c
Out[44]: Counter({11: 4, 22: 2, 33: 1})
对可迭代的对象进行计数或者从另一个映射(counter)进行初始化
In [46]: c = Counter()In [47]: c
Out[47]: Counter()In [48]: c = Counter("gallahad")In [49]: c
Out[49]: Counter({'g': 1, 'a': 3, 'l': 2, 'h': 1, 'd': 1})In [50]: c = Counter({"red": 4, "blue": 2})In [51]: c
Out[51]: Counter({'red': 4, 'blue': 2})In [52]: c = Counter(cats=4, dogs=8)In [53]: c
Out[53]: Counter({'cats': 4, 'dogs': 8})
Counter对象类似于字典,如果某个项缺失会返回0,而不是爆出KeyError错误。
In [55]: c = Counter(["eggs", "ham"])In [56]: c["bacon"]
Out[56]: 0In [57]: c["eggs"]
Out[57]: 1
将一个元素的数目设置为0,并不能将它从counter中删除,使用del可以将这个元素移除
In [59]: c
Out[59]: Counter({'eggs': 1, 'ham': 1})In [60]: c["eggs"] = 0In [61]: c
Out[61]: Counter({'eggs': 0, 'ham': 1})In [62]: del c["eggs"]In [63]: c
Out[63]: Counter({'ham': 1})
Counter对象支持一下三个字典不支持的方法:elements(),most_common(),subtract();
element(),返回一个迭代器,每个元素重复的次数为它的数目,顺序是任意的顺序,如果一个元素的数目少于1,那么elements()就会忽略它;
In [82]: c = Counter(a=1, b=3, c=0, d=-2, e=1)In [83]: c.elements()
Out[83]: <itertools.chain at 0x7ff46baab9b0>In [84]: list(c.elements())
Out[84]: ['a', 'b', 'b', 'b', 'e']
most_common(),返回一个列表,包含counter中n个最大数目的元素,如果忽略n或者为None,
most_common()将会返回counter中的所有元素,元素有着相同数目的将会以任意顺序排列;
In [90]: Counter("abracadabra")
Out[90]: Counter({'a': 5, 'b': 2, 'r': 2, 'c': 1, 'd': 1})In [91]: Counter("abracadabra").most_common(3)
Out[91]: [('a', 5), ('b', 2), ('r', 2)]In [92]: Counter("abracadabra").most_common()
Out[92]: [('a', 5), ('b', 2), ('r', 2), ('c', 1), ('d', 1)]In [93]: Counter("abracadabra").most_common(None)
Out[93]: [('a', 5), ('b', 2), ('r', 2), ('c', 1), ('d', 1)]
subtract(),从一个可迭代对象中或者另一个映射(或counter)中,元素相减,类似于dict.update(),
但是subtracts 数目而不是替换它们,输入和输出都有可能为0或者为负;
In [95]: c = Counter(a=4,b=2,c=0,d=-2)In [96]: d = Counter(a=1,b=2,c=-3,d=4)In [97]: c.subtract(d)In [98]: c
Out[98]: Counter({'a': 3, 'b': 0, 'c': 3, 'd': -6})
update(),从一个可迭代对象中或者另一个映射(或counter)中所有元素相加,类似于dict.upodate,
是数目相加而非替换它们,另外,可迭代对象是一个元素序列,而非(key,value)对构成的序列;
In [100]: c = Counter(a=4,b=2,c=0,d=-2)In [101]: d = Counter(a=1,b=2,c=-3,d=4)In [102]: c.update(d)In [103]: c
Out[103]: Counter({'a': 5, 'b': 4, 'c': -3, 'd': 2})
Counter对象常见的操作,
>>> c
Counter({'a': 5, 'b': 4, 'd': 2, 'c': -3})
>>> sum(c.values())# 统计所有的数目
>>> list(c)# 列出所有唯一的元素
['a', 'c', 'b', 'd']
>>> set(c)# 转换为set
set(['a', 'c', 'b', 'd'])
>>> dict(c)# 转换为常规的dict
{'a': 5, 'c': -3, 'b': 4, 'd': 2}
>>> c.items()# 转换为(elem,cnt)对构成的列表
[('a', 5), ('c', -3), ('b', 4), ('d', 2)]
>>> c.most_common()[:-4:-1]# 输出n个数目最小元素
[('c', -3), ('d', 2), ('b', 4)]
>>> c += Counter()# 删除数目为0和为负的元素
>>> c
Counter({'a': 5, 'b': 4, 'd': 2})
>>> Counter(dict(c.items()))# 从(elem,cnt)对构成的列表转换为counter
Counter({'a': 5, 'b': 4, 'd': 2})
>>> c.clear()# 清空counter
>>> c
Counter()
queue
deque是栈和队列的一种广义实现,deque是"double-end queue"的简称;deque支持线程安全、
有效内存地以近似O(1)的性能在deque的两端插入和删除元素,尽管list也支持相似的操作,
但是它主要在固定长度操作上的优化,从而在pop(0)和insert(0,v)(会改变数据的位置和大小)上有O(n)的时间复杂度。
deque支持如下方法,
append(x), 将x添加到deque的右侧;
appendleft(x), 将x添加到deque的左侧;
clear(), 将deque中的元素全部删除,最后长度为0;
count(x), 返回deque中元素等于x的个数;
extend(iterable), 将可迭代变量iterable中的元素添加至deque的右侧;
extendleft(iterable), 将变量iterable中的元素添加至deque的左侧,往左侧添加序列的顺序与可迭代变量iterable中的元素相反;
pop(), 移除和返回deque中最右侧的元素,如果没有元素,将会报出IndexError;
popleft(), 移除和返回deque中最左侧的元素,如果没有元素,将会报出IndexError;
remove(value), 移除第一次出现的value,如果没有找到,报出ValueError;
reverse(), 反转deque中的元素,并返回None;
rotate(n), 从右侧反转n步,如果n为负数,则从左侧反转,d.rotate(1)等于d.appendleft(d.pop());
maxlen, 只读的属性,deque的最大长度,如果无解,就返回None;
除了以上的方法之外,deque还支持迭代、序列化、len(d)、reversed(d)、copy.copy(d)、copy.deepcopy(d),通过in操作符进行成员测试和下标索引,
索引的时间复杂度是在两端是O(1),在中间是O(n),为了快速获取,可以使用list代替。
>>> from collections import deque
>>> d = deque('ghi')# 新建一个deque,有三个元素
>>> for ele in d:# 遍历deque
... print ele.upper()
...
...
G
H
I
>>> d.append('j')# deque右侧添加一个元素
>>> d.appendleft('f')# deque左侧添加一个元素
>>> d# 打印deque
deque(['f', 'g', 'h', 'i', 'j'])
>>> d.pop()# 返回和移除最右侧元素
'j'
>>> d.popleft()# 返回和移除最左侧元素
'f'
>>> list(d)# 以列表形式展示出deque的内容
['g', 'h', 'i']
>>> d[0]# 获取最左侧的元素
'g'
>>> d[-1]# 获取最右侧的元素
'i'
>>> list(reversed(d))# 以列表形式展示出倒序的deque的内容
['i', 'h', 'g']
>>> 'h' in d# 在deque中搜索
True
>>> d.extend('jkl')# 一次添加多个元素
>>> d
deque(['g', 'h', 'i', 'j', 'k', 'l'])
>>> d.rotate(1)# 往右侧翻转
>>> d
deque(['l', 'g', 'h', 'i', 'j', 'k'])
>>> d.rotate(-1)# 往左侧翻转
>>> d
deque(['g', 'h', 'i', 'j', 'k', 'l'])
>>> deque(reversed(d))# 以逆序新建一个deque
deque(['l', 'k', 'j', 'i', 'h', 'g'])
>>> d.clear()# 清空deque
>>> d.pop()# 不能在空的deque上pop
Traceback (most recent call last):File "<input>", line 1, in <module>
IndexError: pop from an empty deque
>>> d.extendleft('abc')# 以输入的逆序向左扩展
>>> d
deque(['c', 'b', 'a'])
deque的其它应用
限定长度的deque提供了Unix中tail命令相似的功能;
from collections import dequedef tail(filename,n = 10):"Return the last n lines of a file"return deque(open(filename),n)print (tail("temp.txt",10))
defaultdict
defaultdict是内置数据类型dict的一个子类,基本功能与dict一样,
只是重写了一个方法missing(key)和增加了一个可写的对象变量default_factory。
default_factory, 这个属性用于missing()方法,使用构造器中的第一个参数初始化;
使用list作为default_factory,很容易将一个key-value的序列转换为一个关于list的词典;
>>> from collections import *
>>> s = [('yellow',1),('blue',2),('yellow',3),('blue',4),('red',5)]
>>> d = defaultdict(list)
>>> for k,v in s: d[k].append(v)
...
>>> d.items()
[('blue', [2, 4]), ('red', [5]), ('yellow', [1, 3])]
当每一个key第一次遇到时,还没有准备映射,首先会使用default_factory函数自动创建一个空的list,
list.append()操作将value添加至新的list中,当key再次遇到时,通过查表,
返回对应这个key的list,list.append()会将新的value添加至list,这个技术要比dict.setdefault()要简单和快速。
>>> s = "mississippi"
>>> d = defaultdict(int)
>>> for k in s: d[k]+=1
...
>>> d.items()
[('i', 4), ('p', 2), ('s', 4), ('m', 1)]
nametuple
命名的元组,意味给元组中的每个位置赋予含义,意味着代码可读性更强,namedtuple可以在任何常规元素使用的地方使用,
而且它可以通过名称来获取字段信息而不仅仅是通过位置索引。
In [5]: # 导入collections模块的namedtuple类In [6]: from collections import namedtupleIn [7]: # 声明命名元祖子类EmployeeIn [8]: Employee = namedtuple("Employee", ["id", "name", "age"])In [9]: # 为元祖添加值In [10]: E_1 = Employee("11", "Sola", 18)In [11]: E_2 = Employee("22", "Baga", 28)In [12]: print(E_1)
Employee(id='11', name='Sola', age=18)In [13]: print("按索引方式访问Employee的名字为:", end="")
按索引方式访问Employee的名字为:
In [14]: print(E_1[1])
SolaIn [15]: print("按键字段名访问Employee的名字为:", end="")
按键字段名访问Employee的名字为:
In [16]: print(E_1.name)
Sola
命名元祖特定方法
除了从元组继承的方法之外,命名元组还支持另外三个方法和两个属性。为了防止与字段名发生冲突,方法和属性名以下划线开头。分别介绍如下:
(1) _make(iterable):
类方法,从现有序列或可迭代对象生成新实例:
In [18]: bat_data = ["333", "bat_man", 23]In [19]: batman = Employee._make(bat_data)In [20]: print(batman)
Employee(id='333', name='bat_man', age=23)
_asdict
返回一个新的字典,它将字段名映射到对应的值。示例代码如下:
In [23]: batman._asdict()
Out[23]: OrderedDict([('id', '333'), ('name', 'bat_man'), ('age', 23)])
_replace (**kwargs):
In [26]: batman._replace(id=555, age=28)
Out[26]: Employee(id=555, name='bat_man', age=28)
_fields
以字符串元组方式列出字段名的。用于自省和从现有的命名元组创建新的命名元组类型。示例代码如下:
In [28]: print(batman._fields)
('id', 'name', 'age')
我们可以使用_fields属性从现有的命名元组中创建新的命名元组。示例如下:
In [30]: # 构建来自其它命名元祖字段的新的命名元祖In [31]: Point = namedtuple("Point", ["x", "y"])In [32]: Color = namedtuple("Color", "red green blue")In [33]: Pixel = namedtuple("Pixel", Point._fields + Color._fields)In [34]: Pixel
Out[34]: __main__.PixelIn [35]: Pixel(5, 8, 128, 255, 0)
Out[35]: Pixel(x=5, y=8, red=128, green=255, blue=0)
结果的实体性赋值
而命名元组在为csv或sqlite3模块操作而返回的元组结果分配给对应字段名而装配成简单实体时特别有用,自动进行字段的对应赋值。
比如在当前Python程序位置有个employees.csv,其包含内容如下:
张三,26,工程部,开发部,中级
李四,32,项目经理,项目部,高级
通过示例,我们来完成Employee实体的命名元组的自动装配,代码示例如下:
In [81]: cat my.csv
李四, 销售经理, 28, 市场部, 高级
张三, 工程师, 26, 开发部, 中级In [82]: for emp in map(EmployeeEntity._make, csv.reader(open("my.csv", "rt"))):...: print(emp.name, emp.age, emp.title)...:
李四 销售经理 28
张三 工程师 26
OrderDict
>>> d = {"banana":3,"apple":2,"pear":1,"orange":4}
>>> # dict sorted by key
>>> OrderedDict(sorted(d.items(),key = lambda t:t[0]))
OrderedDict([('apple', 2), ('banana', 3), ('orange', 4), ('pear', 1)])
>>> # dict sorted by value
>>> OrderedDict(sorted(d.items(),key = lambda t:t[1]))
OrderedDict([('pear', 1), ('apple', 2), ('banana', 3), ('orange', 4)])
>>> # dict sorted by length of key string
>>>a = OrderedDict(sorted(d.items(),key = lambda t:len(t[0])))
>>>a
OrderedDict([('pear', 1), ('apple', 2), ('orange', 4), ('banana', 3)])
>>> del a['apple']
>>> a
OrderedDict([('pear', 1), ('orange', 4), ('banana', 3)])
>>> a["apple"] = 2
>>> a
OrderedDict([('pear', 1), ('orange', 4), ('banana', 3), ('apple', 2)])
当元素删除时,排好序的词典保持着排序的顺序;但是当新元素添加时,就会被添加到末尾,就不能保持已排序。
参考文章
相关文章:

python3中collections模块详解
collections模块简介 collections包含了一些特殊的容器,针对Python内置的容器,例如list、dict、set和tuple,提供了另一种选择; namedtuple,可以创建包含名称的tuple; deque,类似于list的容器&a…...

护网面试题2.0
1.CSS和CSRF区别 通俗点讲的话: XSS通过构造恶意语句获取对方cookie, CSRF通过构造恶意链接利用对方cookie,但看不到cookie XSS比CSRF更加容易发生,但CSRF比XSS攻击危害更大 2.XSS原理 XSS(Cross-Site Scripting&…...

学习计算机组成原理第1天(计算机发展历程)
计算机发展历程计算机硬件发展计算机软件的发展经典例题计算机硬件发展 计算机的四代变化 1)第一代计算机(1946-1957年)电子管时代。特点:逻辑元件采用电子管;使用机器语言进行编程;主存用延迟线或磁鼓存储…...

二维字符数组与char** 关系 段错误打印
如下为错误,打印断错误。 具体原因参考 http://c.biancheng.net/view/2022.html 二维字符数组与char** 关系 原因: char a[2][20] ; 这是一个二维字符数组。 二维字符数组,这里相当于是两个一维字符串数组。这两个数组在内存的存放位置可以…...
从url输入到页面呈现发生了什么
从url输入到页面呈现发生了什么 1.URL解析 encodeURI / decodeURI 对整个URL的编码:处理空格/中文 let url "http://https://blog.csdn.net/api/ ?lx1&name科比&fromhttp://www.baidu.com/"; console.log(encodeURI(url));encodeURICompone…...
vue之--使用TypeScript
搭配 TypeScript 使用 Vue 像 TypeScript 这样的类型系统可以在编译时通过静态分析检测出很多常见错误。这减少了生产环境中的运行时错误,也让我们在重构大型项目的时候更有信心。通过 IDE 中基于类型的自动补全,TypeScript 还改善了开发体验和效率。…...

HDFD 回收站【Trash】机制
一、回收站 Trash 机制开启 HDFS本身是一个文件系统,默认情况下HDFS不开启回收站,数据删除后将被永久删除 添加并修改两个属性值可开启Trash功能 - (core-site.xml) <property> <name>fs.trash.interval</name> <value>1440&…...

【Redis】简介
简介 Redis是一个开源的内存数据结构存储系统,它支持多种数据结构(如字符串、哈希、列表、集合、有序集合)以及多种功能(如事务、发布/订阅、Lua脚本执行等)。Redis还提供了持久化功能,可以将数据存储到磁…...

【Go进阶】Goroutine 实现原理
目录 1、GMP模型 2、Goroutine调度策略 队列轮转 系统调用 工作量窃取...
TypeScript学习笔记之二(高级类型)
文章目录一、TypeScript高级类型1.1 class类1.2 class继承1.3 class类成员可见性1.4 readonly1.5 类型兼容性1.5.1 对象之间的类型兼容性1.5.2 接口之间类型兼容性1.5.3 函数之间类型兼容性1.6 交叉类型1.7 交叉类型(&)和继承(extends)的对比二、泛型2.1 泛型约束--指定更具…...
如何远程控制电脑?您只需要这样做
案例:在外面怎么远程控制电脑? “我学校教室有电脑,但我每次上课的时候还是需要带自己的电脑(好重!),只因为有些资料只在自己的电脑上。听说远程控制电脑可以解决这个问题,那如何远…...
【51单片机】:LED任务及汇编解释任务
学习目标: 1、用汇编或者c语言实现D1 D3 D5 D7 为一组 ;D2 D4 D6 D8 为一组 ,两组实现 1)一组亮约一秒 另一组灭一秒,这样的互闪现象五次后 25分 2)所有灯灭约一秒后, …...

从生活习惯到肠道微生物,揭秘胃肠道癌症的成因
谷禾健康 编辑 癌症一直是全球人类关注的重点,近年来癌症的发病率迅速增加,例如乳腺癌、前列腺癌和肺癌非常普遍。胃肠道癌在发病率和死亡率方面位居首位,并造成重大的社会经济负担。 胃肠道癌症包括胃癌、肝癌、食道癌、胰腺癌和结直肠癌等…...
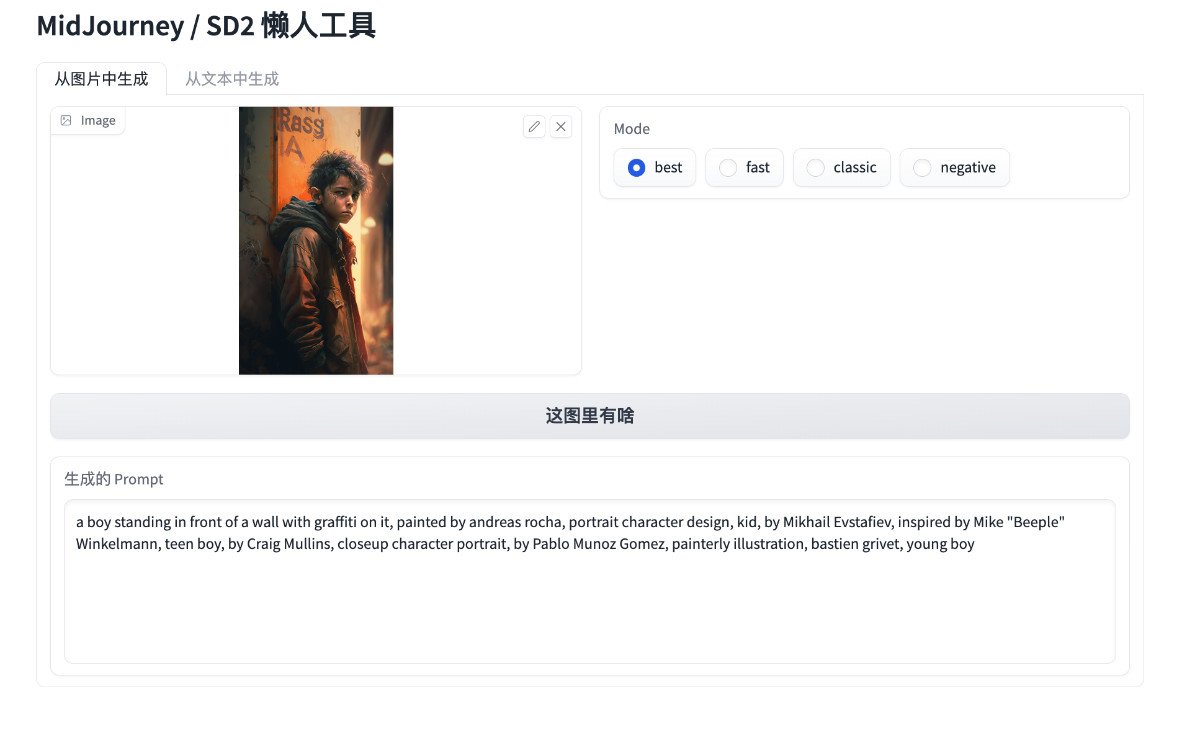
八十行代码实现开源的 Midjourney、Stable Diffusion “咒语”作图工具
本篇文章聊聊如何通过 Docker 和八十行左右的 Python 代码,实现一款类似 Midjourney 官方图片解析功能 Describe 的 Prompt 工具。 让你在玩 Midjourney、Stable Diffusion 这类模型时,不再为生成 Prompt 描述挠头。 写在前面 本文将提供两个版本的工…...

Redis为什么这么快
RedisRedis为什么这么快基于内存单线程实现(Redis 6.0 以前)IO多路复用模型高效的数据结构Redis为何选择单线程Redis的应用场景Redis怎么实现消息队列Redis的主从复制原理主从复制的原理过期键的删除策略Redis为什么这么快 基于内存 Redis是使用内存存…...

JayDeBeApi对数据类型的支持
JayDeBeApi对数据类型的支持 常用的数据类型如下: 字符类型 内置字符类型包括:char, nchar, varchar, nvarchar 和lvarchar CHARACTER(n) 和 CHARACTER VARYING(n)这样的别名同样支持 参考代码:test_string_type.py create ""&…...

一文盘点 Zebec 生态几大利好,让 ZBC 近期“狂飙”
近期,ZBC通证迎来了新一轮上涨趋势,我们看到其从3月11日左右的低点$0.0115上涨至$0.0175,这也是近期的最大涨幅之一。我们看到,推动ZBC上涨的主要因素,是Zebec生态近期频繁的布局所带来的系列利好推动。 本文将对近期的…...

【数据结构】栈和队列(笔记总结)
👦个人主页:Weraphael ✍🏻作者简介:目前学习C和算法 ✈️专栏:数据结构 🐋 希望大家多多支持,咱一起进步!😁 如果文章对你有帮助的话 欢迎 评论💬 点赞&…...

【Java】自定义注解和AOP切面的使用
前言 我们在开发的过程中,一般都需要对方法的入参进行打印,或者Debug调试的时候我们要查看方法入参的参数是否数量和数据正确性。 一般我们需要知道请求的参数、接口路径、请求ip等 但是考虑以后项目上线BUG排查的问题,最好的方式就是使用…...
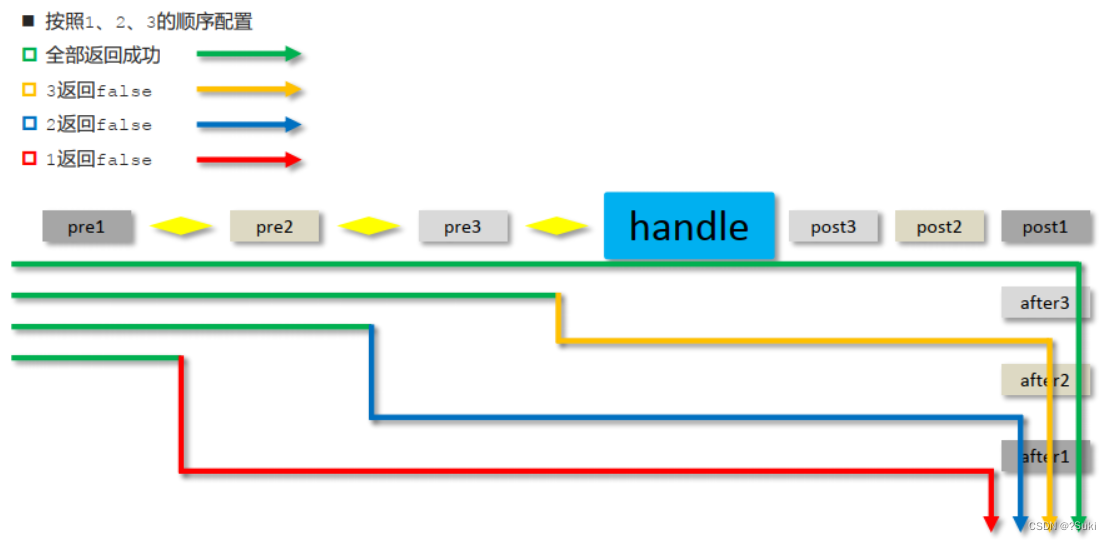
前后台协议联调拦截器
前后台协议联调&拦截器4,前后台协议联调4.1 环境准备4.2 列表功能4.3 添加功能4.4 添加功能状态处理4.5 修改功能4.6 删除功能5,拦截器5.1 拦截器概念5.2 拦截器入门案例5.2.1 环境准备5.2.2 拦截器开发步骤1:创建拦截器类步骤2:配置拦截器类步骤3:S…...

Cadence实战:从原理图到PCB的完整导入流程解析
1. Cadence设计流程概述 刚接触Cadence的硬件工程师常会遇到一个经典问题:为什么原理图设计得漂漂亮亮,导入PCB时却总出各种幺蛾子?这就像做菜时备好了所有食材,下锅时却发现灶台点不着火。我在带新人时发现,90%的导入…...

Granite TimeSeries FlowState R1 多步预测效果展示:长期趋势与不确定性量化
Granite TimeSeries FlowState R1 多步预测效果展示:长期趋势与不确定性量化 时间序列预测,听起来挺专业的,但说白了,就是根据过去的数据,猜猜未来会发生什么。比如,老板问你:“下个月咱们产品…...

FLUX.小红书极致真实V2规模化落地:单节点支持10并发请求,QPS达2.1
FLUX.小红书极致真实V2规模化落地:单节点支持10并发请求,QPS达2.1 1. 项目简介 你是否曾经遇到过这样的困扰:想要生成小红书风格的高质量图片,但要么效果不够真实,要么生成速度太慢,要么显存不够用&#…...

Magisk系统权限架构深度解析:Android设备Root权限优雅解决方案
Magisk系统权限架构深度解析:Android设备Root权限优雅解决方案 【免费下载链接】Magisk The Magic Mask for Android 项目地址: https://gitcode.com/GitHub_Trending/ma/Magisk Magisk作为Android系统权限管理领域的革命性工具,通过独特的系统化…...

Rockchip Android 12编译踩坑记:手把手教你修改BoardConfig.mk生成userdata.img
Rockchip Android 12编译实战:从BoardConfig.mk修改到userdata.img生成的避坑指南 第一次在Rockchip平台上编译Android 12系统时,我遇到了一个令人抓狂的问题——编译过程看似顺利,但生成的固件烧写到设备后,系统始终无法正常启动…...

【OFDM通信】室内NOMA-OFDM-VLC系统仿真【含Matlab源码 15240期】
💥💥💥💥💥💥💥💥💞💞💞💞💞💞💞💞💞Matlab领域博客之家💞&…...

智科毕业设计易上手选题100例
0 选题推荐 - 汇总篇 毕业设计是大家学习生涯的最重要的里程碑,它不仅是对四年所学知识的综合运用,更是展示个人技术能力和创新思维的重要过程。选择一个合适的毕业设计题目至关重要,它应该既能体现你的专业能力,又能满足实际应用…...

Qwen3-Embedding-4B快速上手:5分钟部署,体验119语种向量化
Qwen3-Embedding-4B快速上手:5分钟部署,体验119语种向量化 1. 认识Qwen3-Embedding-4B 1.1 什么是文本向量化? 想象你走进一家大型图书馆,面对成千上万本书籍。如果让你手动查找与"人工智能"相关的书籍,你…...

Qwen3-0.6B-FP8在SolidWorks设计中的应用探索
Qwen3-0.6B-FP8在SolidWorks设计中的应用探索 1. 引言 作为一名机械设计师,你是否曾经遇到过这样的困扰:在SolidWorks中反复调整参数却始终达不到理想效果,或者设计完成后才发现某个关键尺寸存在冲突?传统的设计流程往往依赖设计…...
)
告别龟速下载!一个Shell脚本搞定GFZ非潮汐大气负载数据(附站点坐标文件模板)
极速批量获取GFZ非潮汐大气负载数据的Shell脚本实战指南 在GNSS数据处理和地球物理研究中,获取高精度的非潮汐大气负载(NTAL)数据是分析站点位移的关键环节。德国地学研究中心(GFZ)作为全球权威机构,其提供的NTAL数据产品被广泛应用于科研和工程领域。然…...