【C++学习】map和set的使用
🐱作者:一只大喵咪1201
🐱专栏:《C++学习》
🔥格言:你只管努力,剩下的交给时间!

map和set的使用
- 🌈关联式容器
- ⚡键对值
- 🌈set
- ⚡构造函数
- ⚡增删查改
- 🌈multiset
- 🌈map
- ⚡构造函数
- ⚡增删查改
- ⚡operator[]
- 🌈multimap
- 🌈map和set在题目中的应用
- ⚡统计前K个高频单词
- ⚡求两个数组的交集
- 🌈总结
map和set的底层都是二叉搜索树,只是做了更进一步的限制,使其不会出现单只的情况,搜索的时间复杂度保证在O(log2N),具体的底层结构后面本喵再详细介绍,现在先来认识以下set和map
🌈关联式容器
首先要知道的是序列式容器,这种容器我们之前接触过,比如vector,list,deque等等。
序列式容器:
- 底层为线性的数据结果(物理上或者逻辑上),容器中的元素储存的是元素本身。
- 而且我们之前在使用序列式容器的时候,插入数据和删除数据只管操作就行,不用考虑其他因素。
关联式容器:
- 存储的是<key,value>结构的键对值,在数据检索时比序列式容器效率更高。
- 插入和删除数据时,要考虑该数据和它前后数据之间的关联性。
总的来说,关联式容器存放的数据不同,而且数据前后有一点的关联性。
⚡键对值
- 键对值:用来表示具有一一对应关系的一种结构,该结构中一般只包含两个成员变量key和value,key代表键值,value表示与key对应的信息。
比如:现在要建立一个英汉互译的字典,那字典中就得右英文单词和与之对应的中文含义,而且它们的关系是一一对应的,此时用就可以使用键对值来存放,如<单词,汉语>。
在STL中,定义了一个键对值的类:

- 这个类的名字叫做pair,是一个模板类,可以存放任意类型的键对值,而且能够自定推演。
- 它的成员变量右两个,分别是first和second,结构如:<first,second>。
- 它也右自己的默认成员函数,和普通成员函数。
伪代码形式:
template <class T1, class T2>
struct pair
{typedef T1 first_type;typedef T2 seco_type;T1 first;T2 second;pair():first(T1()),second(T2()){}pair(const T1& a, const T2& b):first(a),second(b){}
};
- 键对值注定是要在类外进行访问的,所以使用struct而不用class。
make_pair():
该函数是用来制作一个pair类型的匿名对象的:
pair<string, string>("string", "字符串");
make_pair("string", "字符串");
上面俩句代码是等价的,都是在创建一个pair类型的匿名对象,让你选择你会选择哪种方式呢?
- make_pair()是为了让我们更加方便的使用键值对。
🌈set
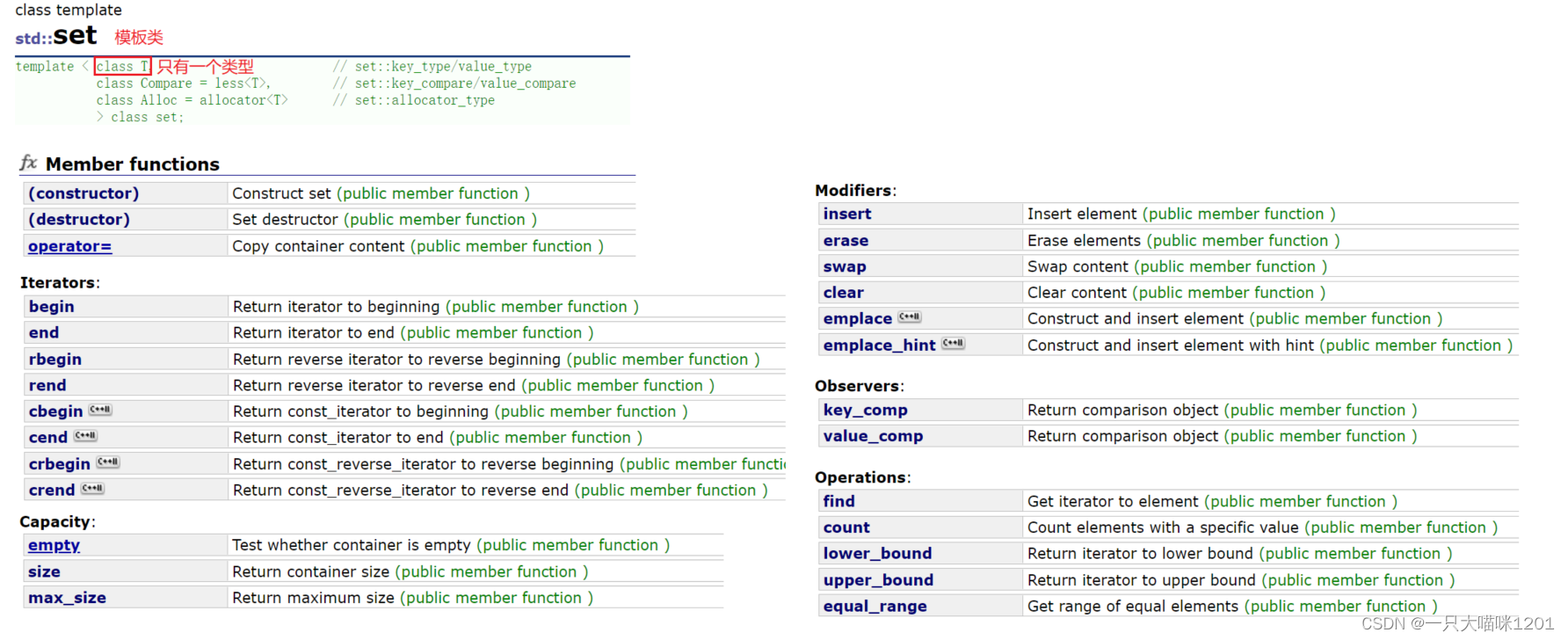
set和之前学习的容器一样,也是一个模板类,但是它的底层是关联式容器,也就是二叉搜索树,并且有很多的成员函数,这些接口相信大家大部分都不陌生。
- set存放的数据只有一个,就是它本身。
⚡构造函数

构造函数有三个,分别是默认构造函数、使用迭代器区间的构造函数、拷贝构造函数。
- 因为底层是二叉搜索树,所有就会涉及到比较,构造函数参数就是比较方式,是一个仿函数,但是默认情况下是有缺省值的。
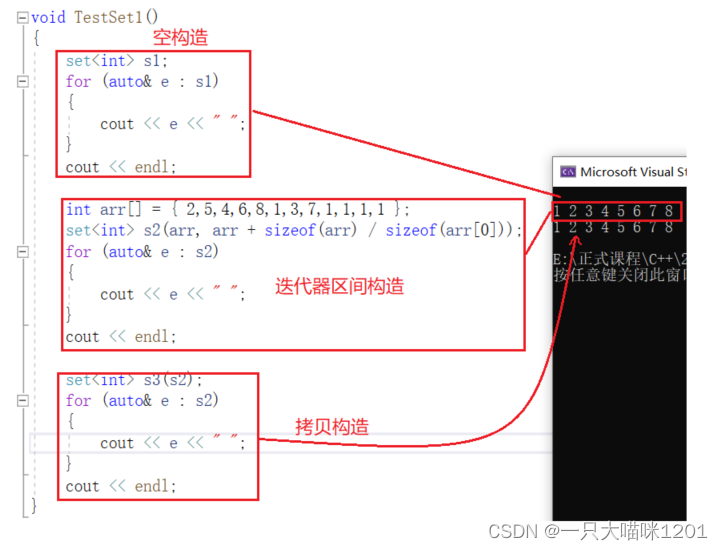
- 使用默认构造函数构造出来的s1是空的,里面什么都没有。
- 使用迭代器区间构造出来的s2,里面是这段区间中的数据。
- 拷贝构造函数构造出来的s3,内容和s2的完全一样。
set的去重功能:
上面使用迭代器区间构造s2的时候,原本的数组中有很多个1,但是构造出来的set中,只有一1。
- set具有降重的功能,当插入的数据已经存在时就不会再插入,这一点在二叉搜索树中就讲解过。

可以看到,数组中有多个重复数字,用这些数字构造出来的set,里面每个数字只存在一个,重复的都被去除了。
迭代器的中序移动:
在打印set中的数据时,我们发现打印出来的结果是升序的,在学习二叉搜索树的时候我们知道,采用中序遍历的方式打印出来的结果就是升序的。
- 迭代器++时,移动的顺序就是中序遍历的顺序,所以使用迭代器遍历时得到的结果和中序遍历是一样的。
⚡增删查改
insert():
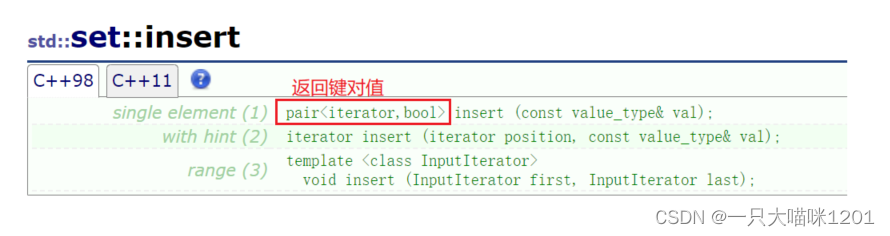
插入函数insert有3个重载函数,其中第一个是插入一个数据,并且返回一个键对值,第二个是指定位置插入,返回插入的位置,第三个是插入一段迭代器区间。
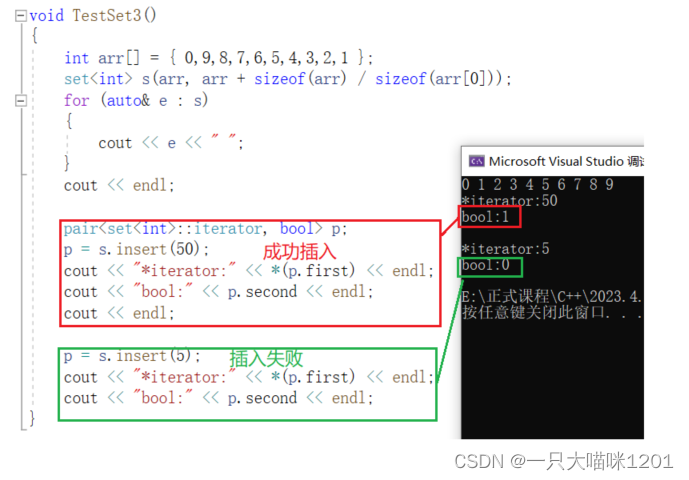
- 在set中插入原本没有的数据50,插入成功,返回键对值中,迭代器指向新插入的位置,布尔值是1。
- 在set中插入原本就存在的数据5,插入石板,返回键对值中,迭代器指向set中5的位置,布尔值是0。
强烈不建议使用指定位置插入。
指定位置向set中插入数据,有可能会破环二叉搜索的结构,除非在插入之前能够确定不会破坏结构。一般情况下我们都不会指定位置插入。
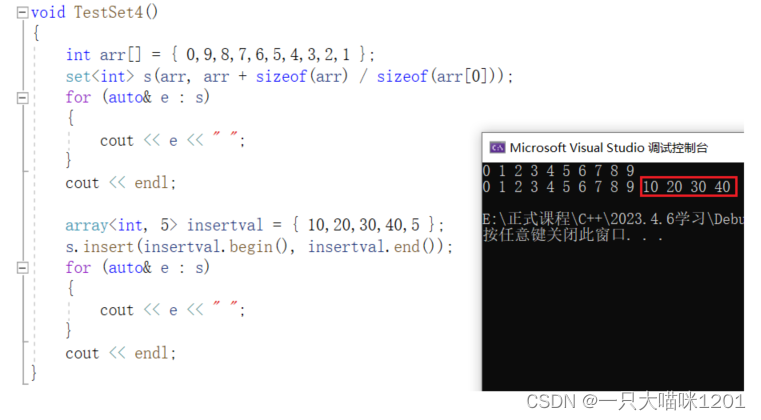
- 迭代器区间中的数据全部插入到了set中。
- set中原本就存在5,所以迭代器区间中的5不会再插入。
find():
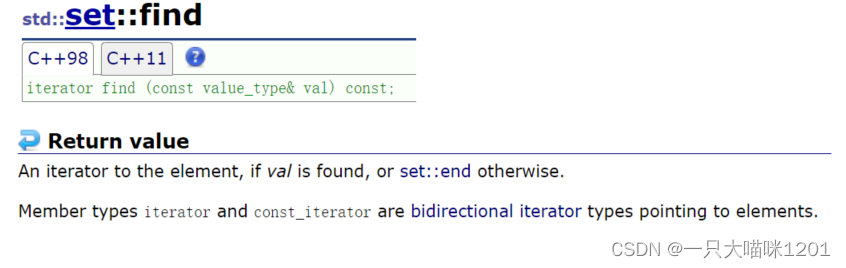
- 根据指定的值在set中插入,如果存在则返回该值所在位置的迭代器,如果不存在,则返回set的结束位置的迭代器end()。

- 5存在于set中,返回该位置的迭代器。
- 50不存在于set中,返回set的end迭代器。
还有一个接口函数可以代替find,该结构名为count():

- 返回指定数据的个数,如果不存在则返回0。
由于set具有降重功能,里面不会存在重复的数据,所以它在这里的功能是和find一样的,只是不过返回的是数字,而不是迭代器。
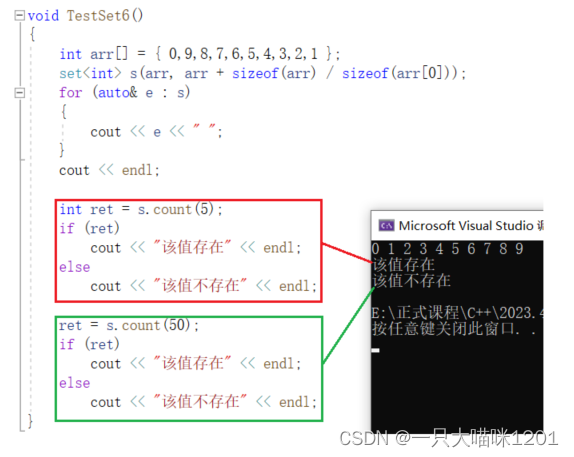
存在时返回值是1,不存在时返回值是0。
erase():

有三个重载函数,第一个删除指定迭代器位置的值,第二个返回删除指定值的个数,第三个删除迭代器区间中所有数据。
- 第二个重载函数,由于set中没有重复值,所以返回的值就是1。
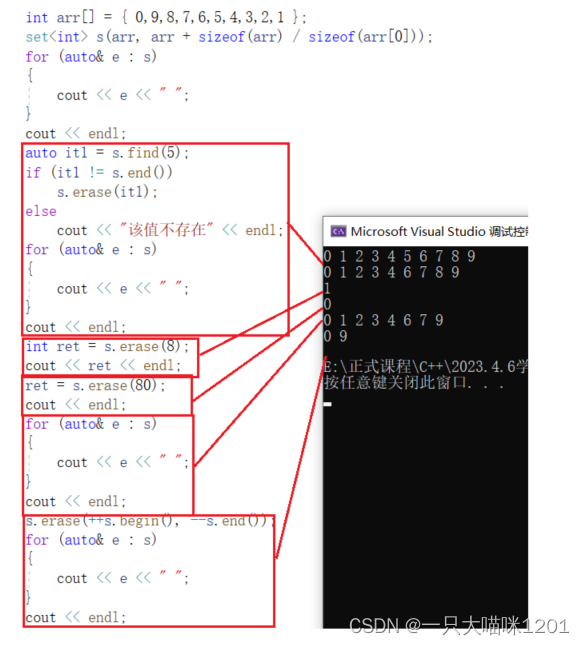
- 使用指定迭代器位置的erase时,需要先使用find找到。
- 使用指定数据的erase时,删除成功返回1,如果不存在则返回0。
- 使用迭代器区间的erase时,将区间内的数据全部删除。
- 迭代器区间用的是set的迭代器区间。
修改:
在二叉搜索树的时候本喵就说过,不支持修改,因为很有可能会破环树的结构,同样的set也不支持修改。
获取上下边界:

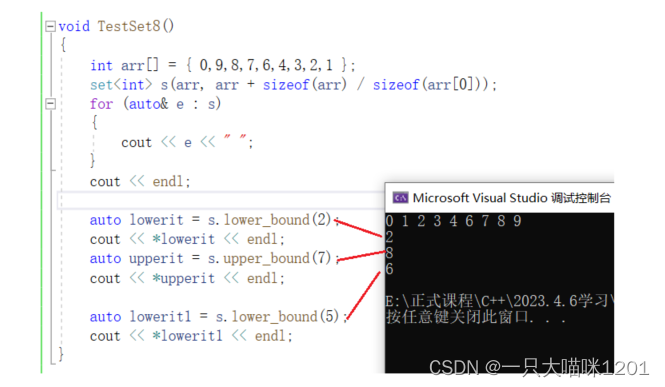
- 下边界给的数据是2时,返回的就是2的迭代器。
- 上边界给的数据是7时,返回的是8的迭代器,也就是返回7的下一个数据所在位置的迭代器,因为C++中的迭代器都是左闭右开区间的。
- 上边界给的数据是5时,返回的是6的迭代器,因为5不存在,所以返回它下一个数据的迭代器。
- lower_boubder(val):返回的iterator >= val所在的位置的迭代器。
- upper_bounder(val):返回的iterator > val所在的位置迭代器。
但是这两个接口用的非常少,仅了解就可以。
其他成员函数的使用,包括迭代器,我们在学习vector,list等容器时已经用的炉火纯青了,本喵就不再介绍了,还有一些很不常用的接口,再以后用到的时候再详细介绍。
🌈multiset
multiset和set在同一个头文件中,而且几乎是一模一样的。
- 区别在于multiset支持数据重复,而set不可以。
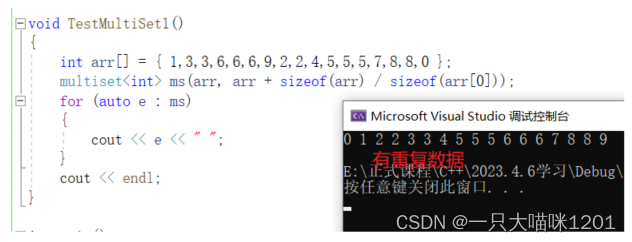
- 重复数据仍然可以插入到multiset中。
- set:排序 + 降重
- multiset:排序(不降重)
count():
在set中count成员函数和find功能类似,但是在multiset中它就有了它的作用。
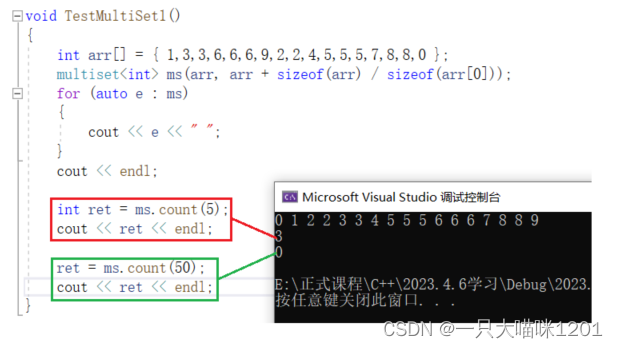
- mutiset中有3个5,返回就是3。
- multiset中没有50,返回就是0。
erase():

erase中的第二个重载函数也是给multiset使用的。
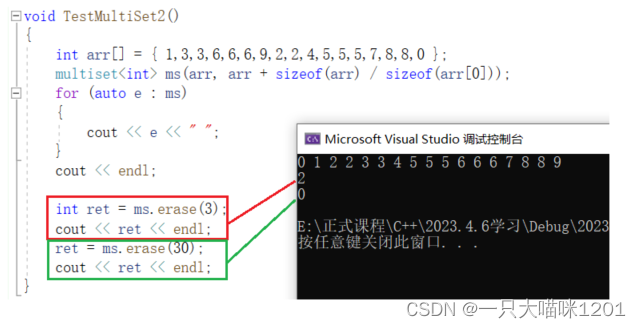
- mutiset中有2个3,全部被删除,所以返回值就是2。
- mutiset中没有30,所以返回值就是0。
find():
使用find查找multiset中的重复元素时,返回的是哪个呢?
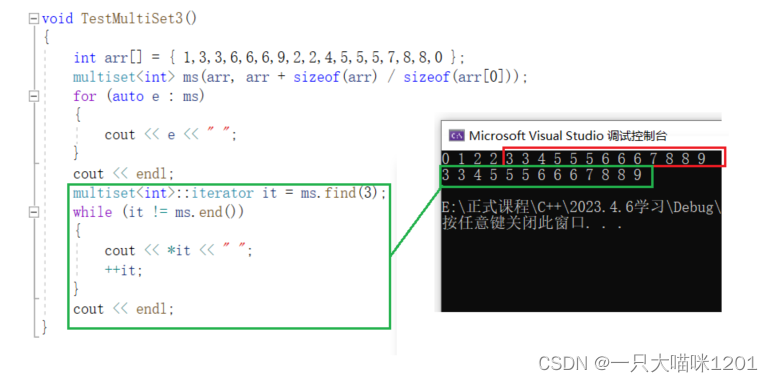
- find找到的是中序遍历的第一个3。
multiset其他方面和set一模一样,本喵就不再介绍了。
🌈map
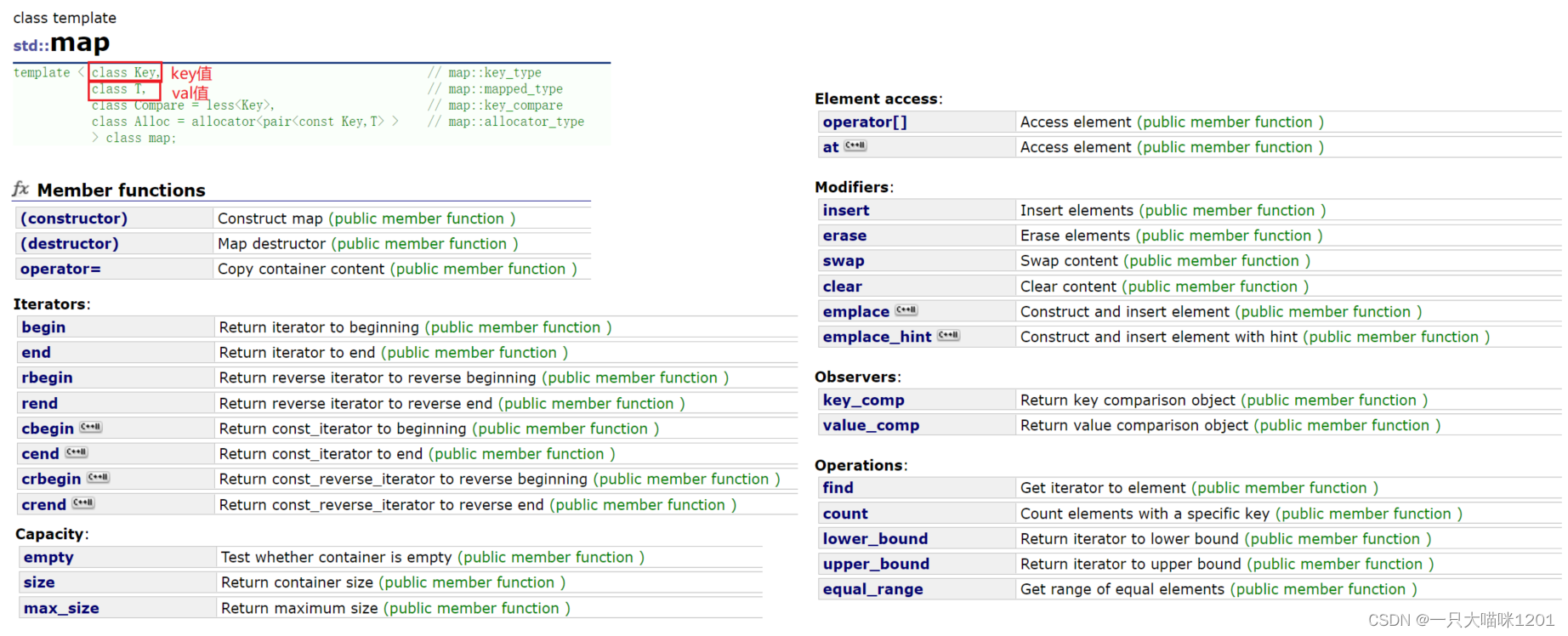
map和set一样,也是一个关联式容器,底层是二叉搜索树。
- map中存放的是键对值,如上图所示,有两个模板参数,这两个参数组成一对键对值。
⚡构造函数

- 没有使用一个键对值进行构造的构造函数,只有一个键对值时,只能先创建在使用insert插入。
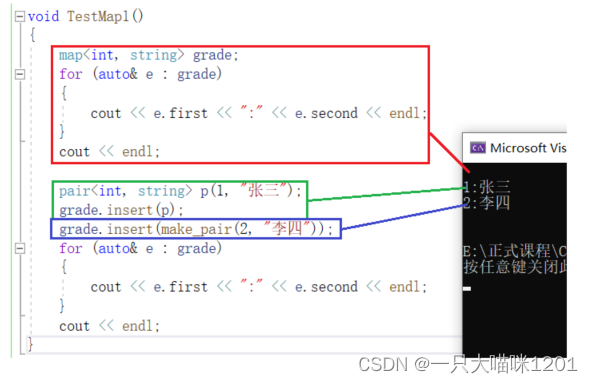
- 使用默认构造函数创建的map是空的。
- 插入键对值时,使用make_pair创建匿名对象更加方便。
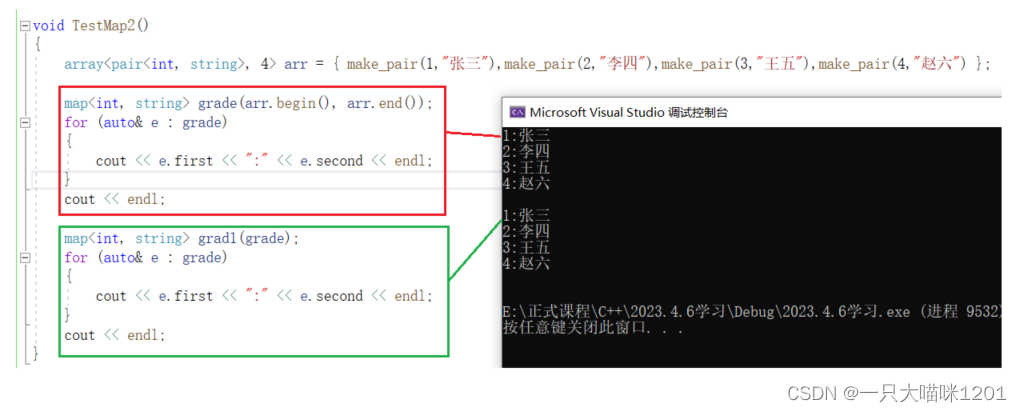
- 使用迭代器区间进行初始化。
- 拷贝构造初始化。
特性:
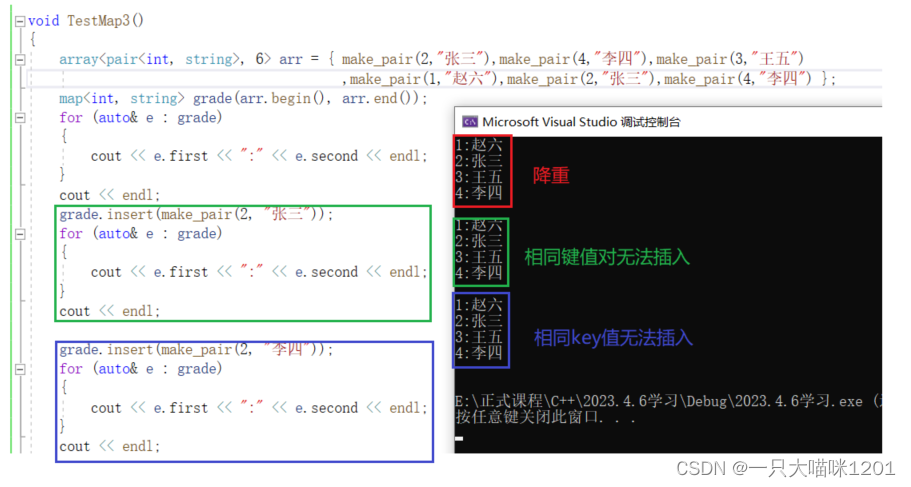
- map具有降重功能,和set一样。
- 不能插入相同的键值对,和set一样,map不支持重复数据。
- 不能插入key值相同,val值不同的键值对。
- map中虽然存放的是键值对,但是它的判断逻辑都只看key值,也就是first所表示的变量。
map也具有排序 + 降重的功能,依据只看key值而不管value值。
⚡增删查改
insert():
用法和set中的一样,只是map插入的是键值对。
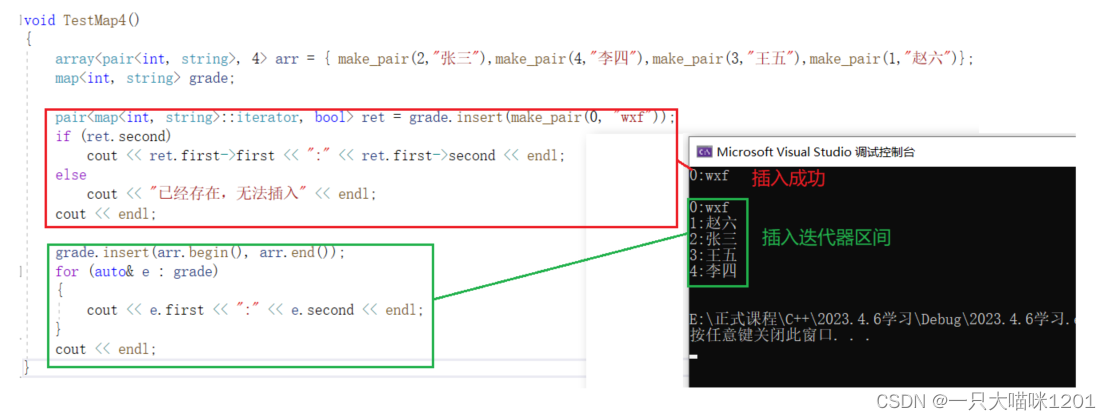
- 插入一个键值对时,返回的也是一个键值对,返回的键值对中,first是插入键值对所在位置的迭代器,second是bool值,成功就返回1,失败就返回0。
- 迭代器区间插入时,map已经有的元素就不再插入了。
同样强烈不建议使用指定位置插入。
find():

- 查找时,只需要指定要查找键值对中的键值key就可以,find是根据key去搜索的。
- 查找到以后返回键值对所在位置,没有找到返回end迭代器。
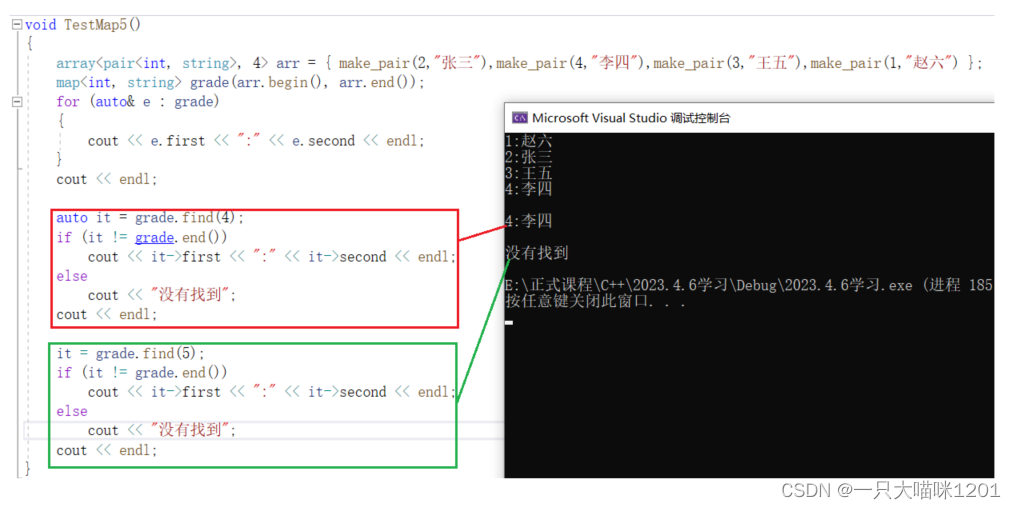
- 键值4存在,它的value值是李四,所以通过返回的迭代器可以找到。
- 键值5不存在,所以返回map的end迭代器。
erase():
和set中的使用情况一样,除了指定迭代器位置和迭代器区间外,只需要指定键值key就可以删除对应的键值对。
map和set一样,不支持修改,因为可能会破坏二叉搜索树的结构。
- 除了插入这样的增加操作时,需要一个键值对,其他操作都是根据键值对中的键值key来处理的。
⚡operator[]
现在使用map来统计KV模型例子中水果的个数:
void TestMap6()
{string arr[] = { "苹果", "西瓜", "香蕉", "草莓", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };map<string, int> countMap;for (auto& e : arr){map<string, int>::iterator it = countMap.find(e);//map没有该水果,插入,数量为1if (it == countMap.end()){countMap.insert(make_pair(e,1));}//map中有该水果,数量加1else{it->second++;}}//查看mapfor (auto& e : countMap){cout << e.first << ":" << e.second << endl;}cout << endl;
}

成功统计出了水果的个数,此时水果名是key值,数量是value值。
还有一种非常不可思议的方式:
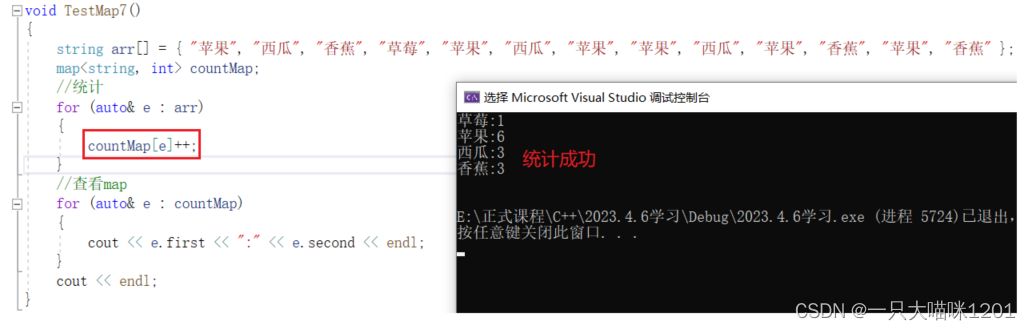
- 原本那么一大堆的判断逻辑,此时一句代码就搞定了。
要想知道原因,就必须了解operator[]成员函数。
- 键对值中的key值充当下标。

文档中解释,调用operator[]相当于在调用上面那一句代码。可以看到这句代码非常长,得需要好好分析。

这句代码可以这样解释,但是还是有些复杂。
Value& operator[](const K& key)
{//1.插入 2.查找pair<map<K, Value>::iterator, bool> ret = insert(make_pair(key, Value()));//3.修改return ret.first->second;}
- 插入:使用insert进行了插入。
- 查找:插入后返回的键对值中有布尔类型,插入就返回true,否则返回false。
- 修改:最终的返回值是插入键对值中的value。
一个operator[]可以实现3个功能,所以可以代替最开始那一堆逻辑。
countMap[e]++;
这句代码是如何实现插入,查找,修改三个功能呢?
- 首先:insert(e),map中如果不存在e,则插入,返回e的second的引用,也就是计数值。如果存在e,则不插入,直接返回e的second的引用。
- 如果是新插入的e,此时e的second的引用是0,加加后变成了1。如果不是新插入的,对e的second的引用进行加加,数量也就被加加了。
- 这里只是用到了operator[]的插入和修改功能,没有使用到查找。
🌈multimap
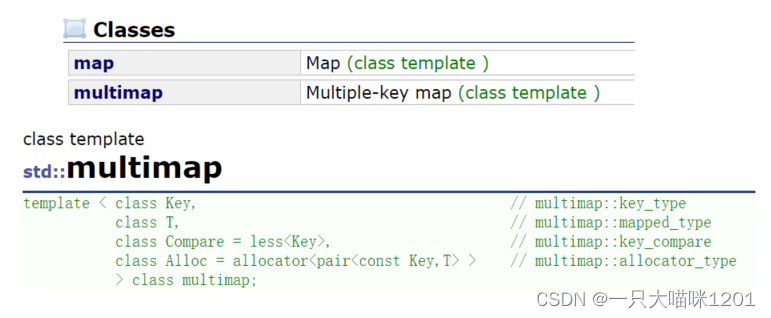
multimap和map也是在一个头文件中,使用和map也一样,就像是multiset和set的关系。
- multimap也是支持数据重复的,而map不可以。

- 重复数据仍然可以插入到multimap中,同样也只是看key值。
- map:排序 + 降重
- multimap:排序(不降重)
mutimap中没有operator[]。
如果有它的话,operator[e]返回的second应该返回哪个呢?毕竟可以找到多个first,所以mutimap不提供operator[]成员函数。
insert():

- multimap的insert中,没有返回键对值的,返回的是插入键对值所在位置的迭代器。其他使用都一样。
map和set以及multiset和multimap的用法非常相似,可以相互参考。
🌈map和set在题目中的应用
⚡统计前K个高频单词

思路分析:
- 将字典放入到map中,统计每个单词的次数。
- 再将键值对中的key值和value交换,并插入到一个vector中。
- 使用sort按照key进行排序。
- 然后将排序后vector中键值对的value(也就是字符串)插入到返回vector。
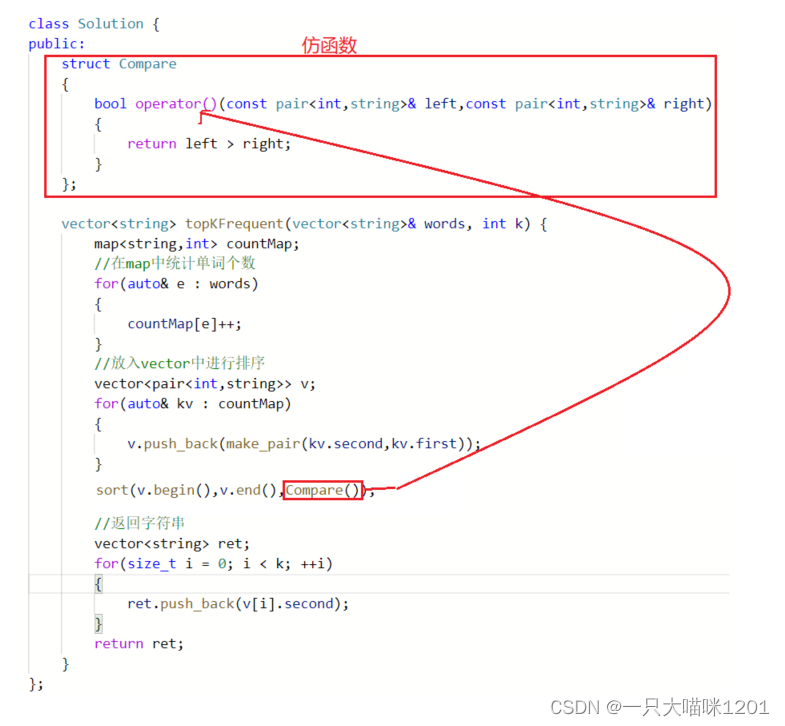
- 统计之后map中的数据形式,pair<“单词”,次数>。
- 将pair<次数,“单词”>放入到vector中,此时key就成了次数,value成了单词。
- 使用sort对vector中的数据进行排序。
- 输出排序后vector中键值对的value,也就是单词。

此时的结果"i"和"love"位置不对,这是因为sort采用的快排,快排是一个不稳定的算法,所以采用一个稳定算法就可以。

算法库中提供了稳定的排序算法。

但是此时函数不行,位置还是不对,这是什么原因呢?

原因就在于pair类型中对大于号的重载:
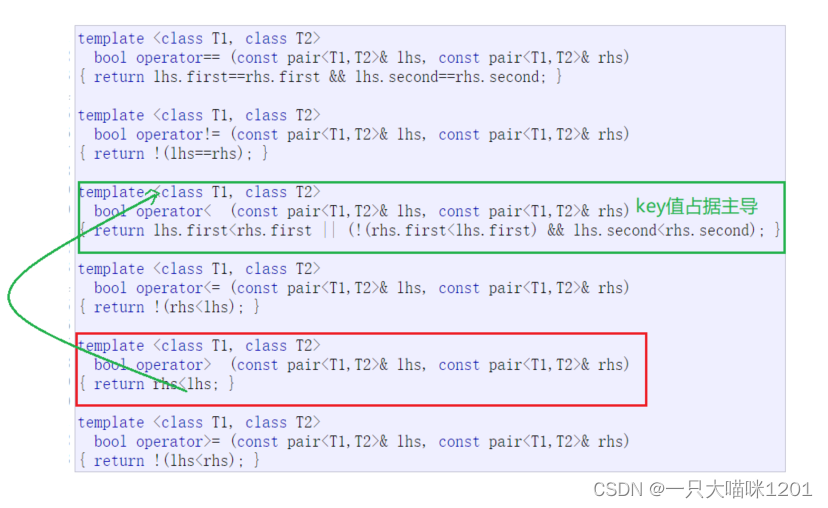
- 库中对operator>()的重载中,主要取决于两个键值对中的key值。
所以需要我们在仿函数中指定更严格的比较方式:

- 当键值对中的first相等时,意味着这两个单词的个数相同。
- 此时在仿函数中指定按照字典序排列。
此时就成功了。
⚡求两个数组的交集

思路分析:
- 首先进行排序 + 去重,将两个数组放在两个set中。
- 两个set中的数据同时进行比较,相等就是交集,输出到返回vector中,不相等时,小的set的迭代器继续向后移动。

上边是思路的示意图。
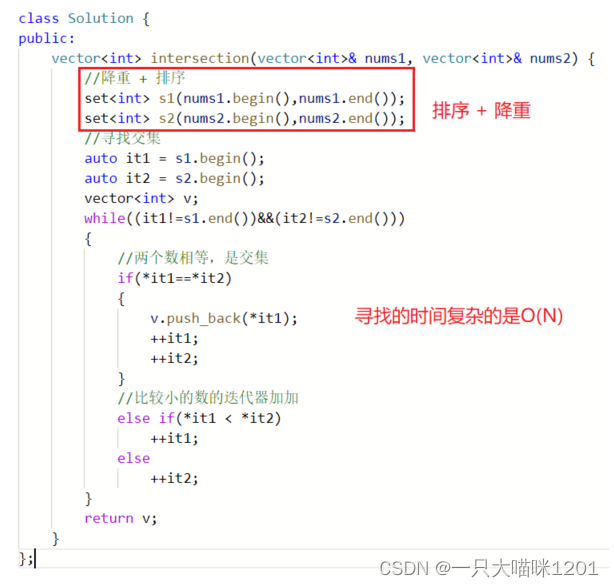

上边代码可以成功通过。
🌈总结
map和set的使用相对于之前的容器来说确实有一点复杂,主要在一些接口上面。要知道set和multiset以及map和mutimap的区别。
相关文章:
【C++学习】map和set的使用
🐱作者:一只大喵咪1201 🐱专栏:《C学习》 🔥格言:你只管努力,剩下的交给时间! map和set的使用🌈关联式容器⚡键对值🌈set⚡构造函数⚡增删查改🌈…...

企业电子招投标采购系统——功能模块功能描述+数字化采购管理 采购招投标
功能模块: 待办消息,招标公告,中标公告,信息发布 描述: 全过程数字化采购管理,打造从供应商管理到采购招投标、采购合同、采购执行的全过程数字化管理。通供应商门户具备内外协同的能力,为外…...
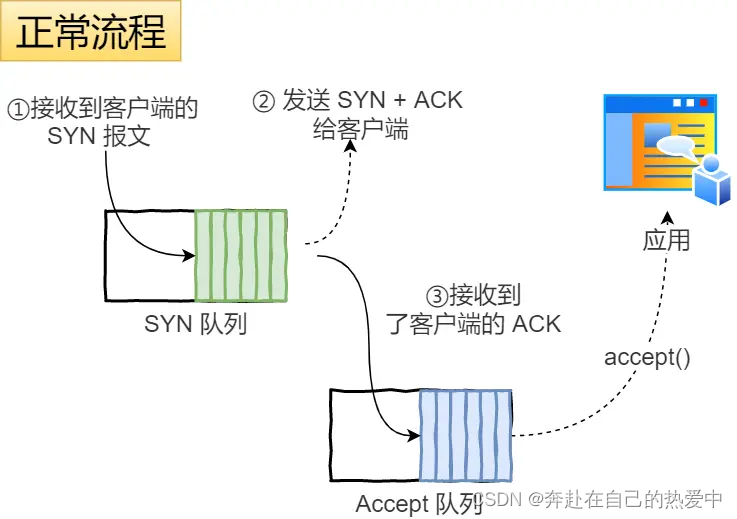
4.6--计算机网络之TCP篇之TCP的连接建立--(复习+深入)---好好沉淀,加油呀
1.TCP 三次握手过程是怎样的? TCP 是面向连接的协议,所以使用 TCP 前必须先建立连接,而建立连接是通过三次握手来进行的 1.一开始,客户端和服务端都处于 CLOSE 状态。先是服务端主动监听某个端口,处于 LISTEN 状态 2…...
Pytorch 数据产生 DataLoader对象详解
目录 1、Pytorch读取数据流程 2、DataLoader参数 3、DataLoader,Sampler和Dataset 4、sampler和batch_sampler 5、源码解析 6、RandomSampler(dataset)、 SequentialSampler(dataset) 7、BatchSampler(Sampler) 8、总结 9、自定义Sampler和BatchSampler 研…...

Linux文件系统介绍
一、简介 文件系统就是分区或磁盘上的所有文件的逻辑集合。 文件系统不仅包含着文件中的数据而且还有文件系统的结构,所有Linux 用户和程序看到的文件、目录、软连接及文件保护信息等都存储在其中。 不同Linux发行版本之间的文件系统差别很少,主要表现在…...

Java高频必背面试题基础篇02
一、Java 语⾔中关键字 static 的作⽤是什么? static 的主要作⽤有两个: (1)为某种特定数据类型或对象分配与创建对象个数⽆关的单⼀的存储空间。 (2)使得某个⽅法或属性与类⽽不是对象关联在⼀起…...
蓝桥杯—stm32g431rbt6串口中断和定时器输出pwm学习
目录 串口中断 定时器中断 输出pwm 串口中断 配置异步模式,使能中断,选择波特率。 串口接收中断开启 HAL_UART_Receive_IT(&huart1,data, 3); 回调函数: void HAL_UART_RxCpltCallback(UART_HandleTypeDef *huart) { if(huar…...
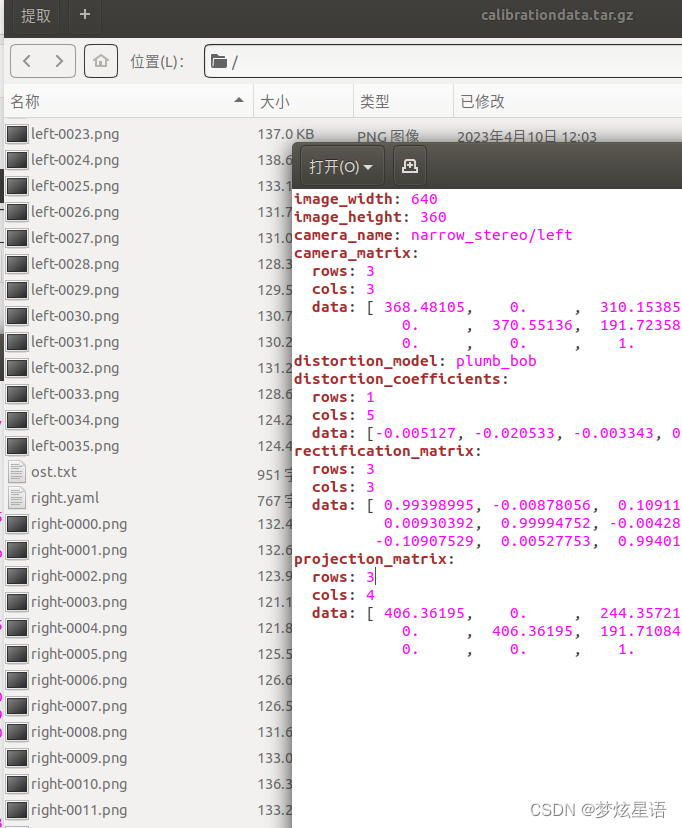
zed驱动的安装 及 遇到问题 及 ros标定
安装zed相机驱动 zed驱动官网 下载.run文件 chmod x ZED_SDK_Ubuntu18_cuda10.2_v4.0.1.zstd.run #换自己的版本号 ./ZED_SDK_Ubuntu18_cuda10.2_v4.0.1.zstd.run #换自己的版本号当遇到 zstd: not found … Decompression failed. 重新安装&a…...

打车代驾顺风车货车租运系统开发功能(司机端)
随着社会经济水平的提高,人们对于打车代驾服务要求也不断提高,更多的人愿意在手机上通过打车代驾APP小程序软件来预约叫车,选择打车代驾服务。打车代驾软件开发是基于广大用户的要求而产生的新型服务方式,满足大众预约出行需要&am…...
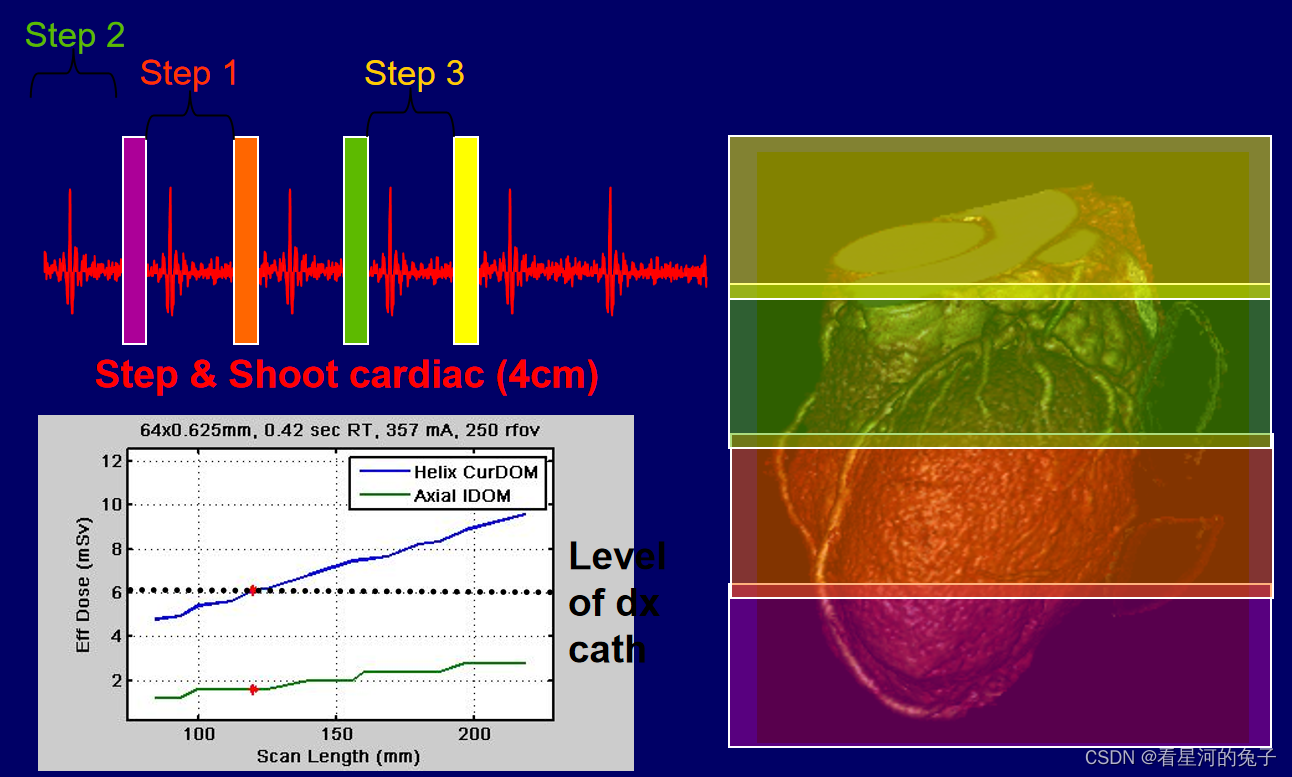
CT剂量及描述方法详细介绍
CT剂量和普通放射剂量的区别 普通放射剂量分布区域大,但一般集中在皮肤入射表面,用患者入射表面剂量(ESD)来表征射线剂量; CT剂量分布在窄带内,边缘与中心分布不均匀;且属于多层扫描; 1、在理想…...

Spring Boot应用优雅关闭
POM依赖 在需要实现优雅关闭的应用工程中增加下述依赖:部分启动器默认就依赖了Actuator启动器,如:spring-cloud-starter-netflix-eureka-server,那么下述依赖是可以省略的。 <dependency><groupId>org.springframewo…...
【实用技巧】7-Zip如何加密压缩文件?
7-Zip是一款免费且实用的压缩软件,除了提供多种压缩格式,还可以对压缩文件进行加密保护,加密后只有输入密码,才能打开压缩包里的文件。如果不知道怎么操作的小伙伴,就来看看小编的分享吧。 操作方法: 1、…...

Anaconda详细安装使用
如果想在conda里面删除某个环境,可以使用 conda remove -n name --all 来删除。 其中 conda info --envs 是查看环境,切换环境 activate base 。 Anaconda Anaconda | The Worlds Most Popular Data Science PlatformAnaconda is the birthplace of Pyt…...

git放弃修改,强制覆盖本地代码
在使用Git的过程中,有些时候我们只想要git服务器中的最新版本的项目,对于本地的项目中修改不做任何理会,就需要用到Git pull的强制覆盖,具体代码如下: $ git fetch --all $ git reset --hard origin/master $ git pu…...

大数据自我进阶(数据仓库)-暂未完全完成
什么时候需要数据仓库? 1.当决策者要进行战略分析或者展示统计的需求。 2.并且数据量非常庞大,而且各个都是数据孤岛。 当满足这2个条件后,就需要搭建数据仓库。 数据仓库的第一步(数据清洗) 为了能准确的分析&am…...

Springmvc中跨服务器文件上传
既然跨服务器,就要开启两个服务器,这里使用两个Tomcat代表两个服务器 文章目录 1.建立图片要上传到的服务器:FileUpload 2.建立上传图片的服务器:Tomcat 9.0.24 3.在Tomcat 9.0.24上部署文件上传的项目,写代码 3.1导入…...

常见漏洞扫描工具AWVS、AppScan、Nessus的使用
HVV笔记——常见漏洞扫描工具AWVS、AppScan、Nessus的使用1 AWVS1.1 安装部署1.2 激活1.3 登录1.4 扫描web应用程序1.4.1 需要账户密码登录的扫描1.4.2 利用录制登录序列脚本扫描1.4.3 利用定制cookie扫描1.5 扫描报告分析1.5.1 AWVS报告类型1.5.2 最常用的报告类型:…...
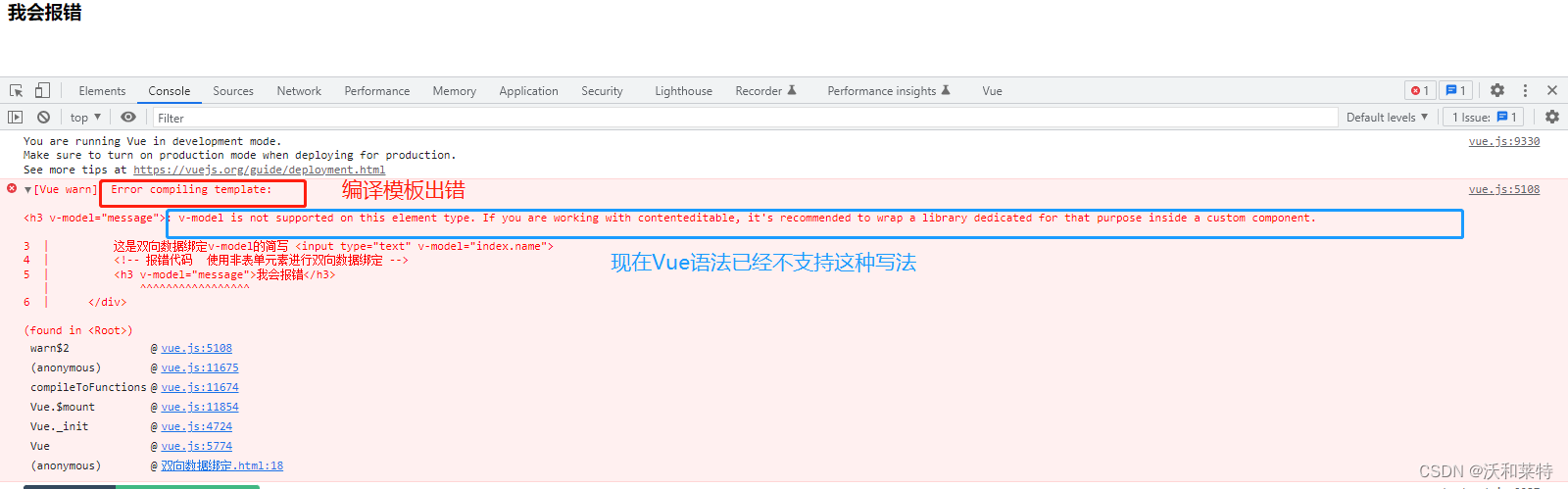
Vue学习——【第二弹】
前言 上一篇文章 Vue学习——【第一弹】 中我们学习了Vue的相关特点及语法,这篇文章接着通过浏览器中的Vue开发者工具扩展来进一步了解Vue的相关工作机制。 Vue的扩展 我们打开Vue的官方文档,点击导航栏中的生态系统,点击Devtools 接着我…...

恐怖的ChatGPT!
大家好,我是飞哥!不知道大家那边咋样。反正我最近感觉是快被ChatGPT包围了。打开手机也全是ChatGPT相关的信息,我的好几个老同学都在问我ChatGPT怎么用,部门内也在尝试用ChatGPT做一点新业务出来。那就干脆我就趁清明假期这一天宝…...
MIPI D-PHYv2.5笔记(12) -- Clock Lane的ULPS
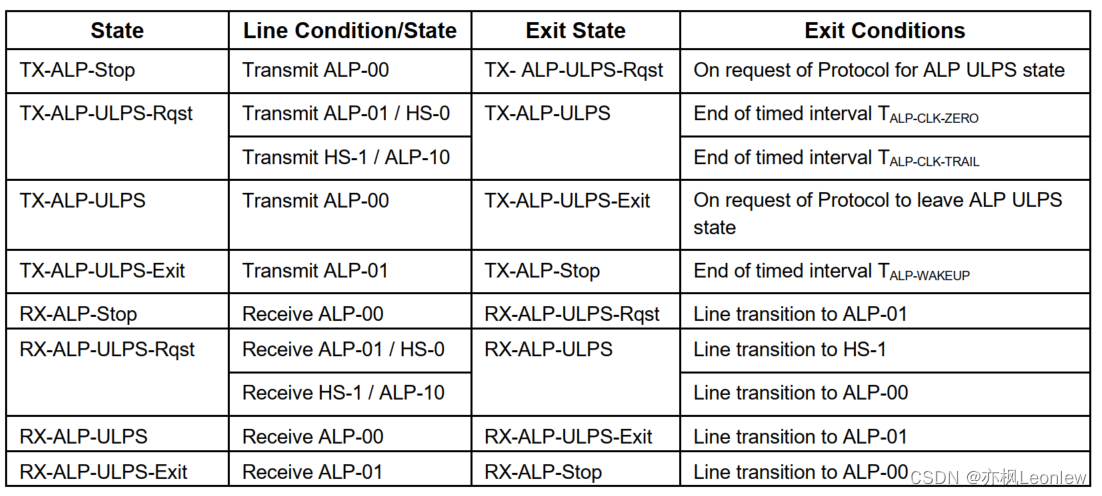
声明:作者是做嵌入式软件开发的,并非专业的硬件设计人员,笔记内容根据自己的经验和对协议的理解输出,肯定存在有些理解和翻译不到位的地方,有疑问请参考原始规范看 LP Mode的Clock Lane ULPS 尽管Clock Lane不包含常规…...

别再傻傻用FFT了!用MATLAB的czt函数5分钟搞定频谱细化,精准定位98Hz和99Hz信号
别再被FFT分辨率坑了!MATLAB工程师的频谱细化实战指南 当你在分析一段包含98Hz和99Hz混合信号的频谱时,是否遇到过这样的尴尬:明明知道有两个频率成分存在,但FFT给出的结果却像被打了马赛克,两个峰值糊成一团…...
)
告别抓瞎:手把手教你解读usbmon抓到的原始数据(附字段含义详解)
USB数据解码实战:从usbmon原始输出到可读通信分析 当你第一次看到usbmon捕获的原始数据时,那串由十六进制数字和神秘符号组成的"天书"确实令人望而生畏。作为一名曾经同样困惑的技术探索者,我完全理解这种面对海量数据却无从下手的…...

别再只盯着RRT了!关节空间六次多项式规划,可能是更简单的机械臂避障方案
关节空间六次多项式规划:机械臂避障的优雅解法 在工业机器人领域,路径规划一直是核心挑战之一。当机械臂需要在充满障碍物的环境中工作时,传统基于笛卡尔空间的规划方法常常面临逆运动学奇异、轨迹不平滑等问题。而基于关节空间的六次多项式规…...

别再只刷固件了!深入Proxmark3硬件层:AT91SAM7S512芯片与Bootrom.bin的救砖原理详解
深入Proxmark3硬件层:AT91SAM7S512芯片与Bootrom.bin的救砖原理详解 当你的Proxmark3设备突然"四灯全亮",USB连接失效,变成一块"砖头"时,大多数教程只会告诉你"短接测试点,用J-Link烧录bootr…...

如何快速掌握unnpk:网易游戏资源解包的完整入门指南
如何快速掌握unnpk:网易游戏资源解包的完整入门指南 【免费下载链接】unnpk 解包网易游戏NeoX引擎NPK文件,如阴阳师、魔法禁书目录。 项目地址: https://gitcode.com/gh_mirrors/un/unnpk 你是否曾经好奇过网易游戏《阴阳师》中那些精美的角色立绘…...

CSPM 信息与文档管理:从混沌到数智化,企业转型的核心命门
在 2026 年 CSPM 最新考纲中,信息与文档管理从边缘考点升级为战略级核心模块,直指企业数字化转型的最大盲区 ——文档混沌、信息孤岛、数据资产流失。本文以犀利视角拆解传统文档管理的致命弊端,结合 AI 大模型、区块链存证、BIM 数字孪生、知…...

基于Spark的分布式量化交易框架:事件驱动架构与实战开发
1. 项目概述与核心价值最近在跟几个做量化交易的朋友聊天,发现一个挺有意思的现象:大家手里或多或少都有一些基于Python的量化策略,但真正能稳定、高效、自动化跑起来的,却不多。问题往往出在几个地方:要么是本地机器性…...

明日方舟自动化:用MAA重构你的游戏体验,告别重复劳动
明日方舟自动化:用MAA重构你的游戏体验,告别重复劳动 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: h…...

Cesium 体积云进阶:从Perlin-Worley噪声到动态云区渲染
1. 从一团云到动态云区的技术跃迁 第一次在Cesium里用Perlin噪声做出那团棉花糖般的云时,我兴奋地截了十几张图发朋友圈。但很快发现一个问题——这团云放在城市上空像块棉花,放在山脉间又像团雾气,怎么看都不像自然界的云层。真正的云应该有…...
