Pytorch 数据产生 DataLoader对象详解
目录
1、Pytorch读取数据流程
2、DataLoader参数
3、DataLoader,Sampler和Dataset
4、sampler和batch_sampler
5、源码解析
6、RandomSampler(dataset)、 SequentialSampler(dataset)
7、BatchSampler(Sampler)
8、总结
9、自定义Sampler和BatchSampler
研究一下dataset是怎样产生的,有了dataset类,才能创建DataLoader对象。
1、Pytorch读取数据流程
Pytorch读取数据虽然特别灵活,但是还是具有特定的流程的,它的操作顺序为:
- 创建一个 Dataset 对象,该对象如果现有的
Dataset不能够满足需求,我们也可以自定义Dataset,通过继承torch.utils.data.Dataset。在继承的时候,需要override三个方法。__init__: 用来初始化数据集;__getitem__:给定索引值,返回该索引值对应的数据;它是python built-in方法,其主要作用是能让该类可以像list一样通过索引值对数据进行访问;__len__:用于len(Dataset)时能够返回大小;
- 创建一个 DataLoader 对象。
- 不停的循环这个 DataLoader 对象。
本篇文章的侧重点在于介绍 DataLoader,因此对于自定义 Dataset,这里不作详细的说明。
2、DataLoader参数
先介绍一下DataLoader(object)的参数:
- dataset(Dataset): 传入的数据集;
- batch_size(int, optional): 每个batch有多少个样本;
- shuffle(bool, optional): 在每个epoch开始的时候,对数据进行重新排序;
- sampler(Sampler, optional): 自定义从数据集中取样本的策略,如果指定这个参数,那么shuffle必须为False;
- batch_sampler(Sampler, optional): 与sampler类似,但是一次只返回一个batch的indices(索引),需要注意的是,一旦指定了这个参数,那么batch_size,shuffle,sampler,drop_last就不能再指定了(互斥——Mutually exclusive);
- num_workers (int, optional): 这个参数决定了有几个进程来处理data loading。0意味着所有的数据都会被load进主进程。(默认为0)
- collate_fn (callable, optional): 将一个list的sample组成一个mini-batch的函数;通俗来说就是将一个batch的数据进行合并操作。默认的
collate_fn是将img和label分别合并成imgs和labels,所以如果你的__getitem__方法只是返回img, label,那么你可以使用默认的collate_fn方法,但是如果你每次读取的数据有img, box, label等等,那么你就需要自定义collate_fn来将对应的数据合并成一个batch数据,这样方便后续的训练步骤。 - pin_memory (bool, optional): 如果设置为True,那么data loader将会在返回它们之前,将tensors拷贝到CUDA中的固定内存(CUDA pinned memory)中.
- drop_last (bool, optional): 如果设置为True:这个是对最后的未完成的batch来说的,比如你的batch_size设置为64,而一个epoch只有100个样本,那么训练的时候后面的36个就被扔掉了…如果为False(默认),那么会继续正常执行,只是最后的batch_size会小一点。
- timeout(numeric, optional): 如果是正数,表明等待从worker进程中收集一个batch等待的时间,若超出设定的时间还没有收集到,那就不收集这个内容了。这个numeric应总是大于等于0。默认为0
- worker_init_fn (callable, optional): 每个worker初始化函数 If not None, this will be called on each worker subprocess with the worker id (an int in [0, num_workers - 1]) as input, after seeding and before data loading. (default: None)如果不是None,则在种子设定之后和数据加载之前,将以worker id([0,num_workers-1]中的int)作为输入,对每个worker子进程调用此函数。(默认值:无)
这里,我们需要重点关注sampler和batch_sampler这两个参数。在介绍这两个参数之前,我们需要首先了解一下DataLoader,Sampler和Dataset三者关系。
3、DataLoader,Sampler和Dataset
在介绍该参数之前,我们首先需要知道DataLoader,Sampler和Dataset三者关系。首先我们看一下DataLoader.next的源代码长什么样,为方便理解我只选取了num_works为0的情况(num_works简单理解就是能够并行化地读取数据)。
class DataLoader(object):...def __next__(self):if self.num_workers == 0: indices = next(self.sample_iter) # Samplerbatch = self.collate_fn([self.dataset[i] for i in indices]) # Datasetif self.pin_memory:batch = _utils.pin_memory.pin_memory_batch(batch)return batch在阅读上面代码前,我们可以假设我们的数据是一组图像,每一张图像对应一个index,那么如果我们要读取数据就只需要对应的index即可,即上面代码中的indices,而选取index的方式有多种,有按顺序的,也有乱序的,所以这个工作需要Sampler完成,现在你不需要具体的细节,后面会介绍,你只需要知道DataLoader和Sampler在这里产生关系。
那么Dataset和DataLoader在什么时候产生关系呢?没错就是下面一行。我们已经拿到了indices,那么下一步我们只需要根据index对数据进行读取即可了。
再下面的if语句的作用简单理解就是,如果pin_memory=True,那么Pytorch会采取一系列操作把数据拷贝到GPU,总之就是为了加速。
综上可以知道DataLoader,Sampler和Dataset三者关系如下:
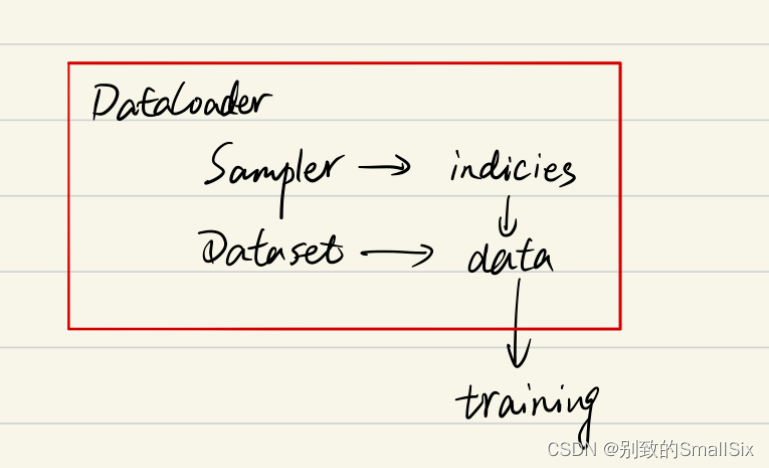
4、sampler和batch_sampler
通过上面对DataLoader参数的介绍,发现参数里面有两种sampler:sampler和batch_sampler,都默认为None。前者的作用是生成一系列的index,而batch_sampler则是将sampler生成的indices打包分组,得到一个又一个batch的index。例如下面示例中,BatchSampler将SequentialSampler(Sampler的一种)生成的index按照指定的batch size分组。
from torch.utils.data import SequentialSampler, BatchSamplerSequentialSampler(range(10))
Out[5]: <torch.utils.data.sampler.SequentialSampler at 0x7fe1631de908>list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=False))
Out[6]: [[0, 1, 2], [3, 4, 5], [6, 7, 8], [9]]a = BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=False)
b = iter(a)
next(b)
Out[9]: [0, 1, 2]
next(b)
Out[10]: [3, 4, 5]
b = iter(a)
next(b)
Out[12]: [0, 1, 2]从这个例子中可以看出,当BatchSampler中的数据取完了,再使用iter(a)得到新的迭代器对象即可,不需要再次实例化类。
Pytorch中已经实现的Sampler有如下几种(均在torch.utils.data下):
SequentialSampler(若shuffle=False,则若未指定sampler,默认使用)RandomSampler(若shuffle=True,则若未指定sampler,默认使用)WeightedSamplerSubsetRandomSampler
Pytorch中已经实现的 batch_sampler为BatchSampler(在torch.utils.data下,默认使用)
需要注意的是DataLoader的部分初始化参数之间存在互斥关系,这个你可以通过阅读源码更深地理解,这里只做总结:
- 如果你自定义了
batch_sampler,那么这些参数都必须使用默认值:batch_size,shuffle,sampler,drop_last - 如果你自定义了
sampler,那么shuffle需要设置为False - 如果
sampler和batch_sampler都为None,那么batch_sampler使用Pytorch已经实现好的BatchSampler,而sampler分两种情况:- 若
shuffle=True,则sampler=RandomSampler(dataset) - 若
shuffle=False,则sampler=SequentialSampler(dataset)
- 若
5、源码解析
首先,大概扫一下DataLoader的代码:
class DataLoader(object):__initialized = Falsedef __init__(self, dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None,num_workers=0, collate_fn=default_collate, pin_memory=False, drop_last=False,timeout=0, worker_init_fn=None):self.dataset = datasetself.batch_size = batch_sizeself.num_workers = num_workers...if sampler is not None and shuffle:raise ValueError('sampler option is mutually exclusive with "shuffle"')...if batch_sampler is None:if sampler is None:if shuffle:sampler = RandomSampler(dataset)else:sampler = SequentialSampler(dataset)batch_sampler = BatchSampler(sampler, batch_size, drop_last)self.sampler = samplerself.batch_sampler = batch_samplerself.__initialized = True...def __iter__(self):return _DataLoaderIter(self)...这里我们主要看__init__()和__iter__():
(1)数据的shuffle和batch处理
- RandomSampler(dataset)
- SequentialSampler(dataset)
- BatchSampler(sampler, batch_size, drop_last)
(2)因为DataLoader只有__iter__()而没有实现__next__()
所以DataLoader是一个iterable而不是iterator。这个iterator的实现在_DataLoaderIter中。
iterable:可迭代的;iterator:迭代器
6、RandomSampler(dataset)、 SequentialSampler(dataset)
这两个类的实现是在dataloader.py的同级目录下的torch/utils/data/sampler.py
sampler.py中实现了一个父类Sampler,以及SequentialSampler,RandomSampler和BatchSampler等五个继承Sampler的子类
这里面的Sampler的实现是用C/C++实现的,这里的细节暂且不表。
我们这里需要知道的是:对每个采样器,都需提供__iter__方法和__len__方法,其中__iter__方法用以表示数据遍历的方式,__len__方法用以返回数据的长度。
import torchclass Sampler(object):r"""Base class for all Samplers.Every Sampler subclass has to provide an __iter__ method, providing a wayto iterate over indices of dataset elements, and a __len__ method thatreturns the length of the returned iterators."""def __init__(self, data_source):passdef __iter__(self):raise NotImplementedErrordef __len__(self):raise NotImplementedErrorclass SequentialSampler(Sampler):r"""Samples elements sequentially, always in the same order.Arguments:data_source (Dataset): dataset to sample from"""def __init__(self, data_source):self.data_source = data_sourcedef __iter__(self):return iter(range(len(self.data_source)))def __len__(self):return len(self.data_source)class RandomSampler(Sampler):r"""Samples elements randomly, without replacement.Arguments:data_source (Dataset): dataset to sample from"""def __init__(self, data_source):self.data_source = data_sourcedef __iter__(self):return iter(torch.randperm(len(self.data_source)).tolist())def __len__(self):return len(self.data_source)if __name__ == "__main__":print(list(RandomSampler(range(10))))print(list(SequentialSampler(range(10))))a = SequentialSampler(range(10))from collections import Iterableprint(isinstance(a, Iterable))from collections import Iteratorprint(isinstance(a, Iterator))for x in SequentialSampler(range(10)):print(x)print(next(a))print(next(iter(a)))输出结果为:
[3, 7, 5, 8, 9, 0, 2, 4, 1, 6]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
True
False
0
1
2
3
4
5
6
7
8
9
TypeError: 'SequentialSampler' object is not an iterator
0可以看出RandomSampler等方法返回的就是DataSet中的索引位置(indices),其中,在子类中的__iter__方法中,需要返回的是iter(xxx)(即iterator)的形式:

#### 以下两个代码是等价的
for data in dataloader:...
#### 等价与
iters = iter(dataloader)
while 1:try:next(iters)except StopIteration:break 此外,torch.randperm()的用法如下:
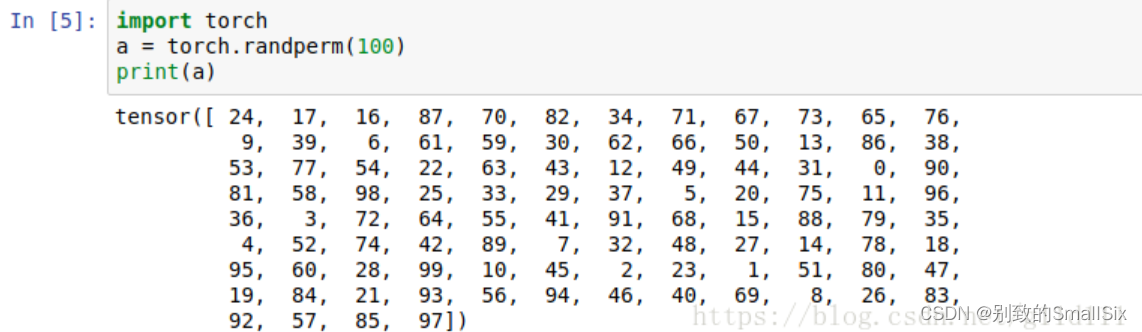
最后,我们再理解一下这些类中间的__iter__函数,该函数的返回值为迭代器对象,可以使用for循环或者next()函数依次访问该迭代器对象中的每一个元素。但是这些类是可迭代类并不是迭代器类,所以上例中的实例对象a只能使用for循环访问__iter__函数返回的迭代器对象,而不能直接使用next()函数,需要使用iter()函数得到__iter__函数返回的迭代器对象。如下所示,可以看到iter(a)后得到的结果为range_iterator,也就是__iter__函数返回的迭代器对象。
a
Out[74]: <__main__.SequentialSampler at 0x7fa26c1d7898>iter(a)
Out[75]: <range_iterator at 0x7fa26c1cf960>7、BatchSampler(Sampler)
BatchSampler是wrap一个sampler,并生成mini-batch的索引(indices)的方式。代码如下所示:
class BatchSampler(Sampler):r"""Wraps another sampler to yield a mini-batch of indices.Args:sampler (Sampler): Base sampler.batch_size (int): Size of mini-batch.drop_last (bool): If ``True``, the sampler will drop the last batch ifits size would be less than ``batch_size``Example:>>> list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=False))[[0, 1, 2], [3, 4, 5], [6, 7, 8], [9]]>>> list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=True))[[0, 1, 2], [3, 4, 5], [6, 7, 8]]"""def __init__(self, sampler, batch_size, drop_last):if not isinstance(sampler, Sampler):raise ValueError("sampler should be an instance of ""torch.utils.data.Sampler, but got sampler={}".format(sampler))if not isinstance(batch_size, _int_classes) or isinstance(batch_size, bool) or \batch_size <= 0:raise ValueError("batch_size should be a positive integeral value, ""but got batch_size={}".format(batch_size))if not isinstance(drop_last, bool):raise ValueError("drop_last should be a boolean value, but got ""drop_last={}".format(drop_last))self.sampler = samplerself.batch_size = batch_sizeself.drop_last = drop_lastdef __iter__(self):batch = []# 一旦达到batch_size的长度,说明batch被填满,就可以yield出去了for idx in self.sampler:batch.append(idx)if len(batch) == self.batch_size:yield batchbatch = []if len(batch) > 0 and not self.drop_last:yield batchdef __len__(self):# 比如epoch有100个样本,batch_size选择为64,那么drop_last的结果为1,不drop_last的结果为2if self.drop_last:return len(self.sampler) // self.batch_sizeelse:return (len(self.sampler) + self.batch_size - 1) // self.batch_sizeif __name__ == "__main__":print(list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=False)))# [[0, 1, 2], [3, 4, 5], [6, 7, 8], [9]]print(list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=True)))# [[0, 1, 2], [3, 4, 5], [6, 7, 8]] 这里主要看__iter__方法,可以看到,代码的思路很清楚明白的展示了batch indices的是如何取出的。要想理解该方法,最重要的是对于yield关键字的理解。之前我已经有一篇文章解释过yield关键字了。这里只说结论:yield就是return返回一个值,并且记住这个返回的位置,下次迭代就从这个位置后开始;同时包含yield的函数为生成器(生成器是迭代器对象),当直接调用该函数的时候,会返回一个生成器。而生成器是迭代器对象,正好对应于前面所述的Sample对象的__iter__(self)函数,返回值需要是迭代器对象。
对于BatchSampler类而言,只含有__iter__含义,但是不含有__next__函数,所以它是一个可迭代类但是不是一个迭代器类。因此只能使用for循环,不能使用next()函数。若想使用next()函数,需要使用iter()函数作用于BatchSampler类的实例,这样就可以得到__iter__函数的返回值即迭代器对象。其实对于含有__iter__的类,使用for循环遍历其数据的时候,内部是内置了__iter__函数了。
8、总结
假设某个数据集有100个样本,batch size=4时,以SequentialSampler和BatchSampler为例,Pytorch读取数据的时候,主要过程是这样的:
SequentialSampler类中的__iter__方法返回iter(range(100))迭代器对象,对其进行遍历时,会依次得到range(100)中的每一个值,也就是100个样本的下标索引。BatchSampler类中__iter__使用for循环访问SequentialSampler类中的__iter__方法返回的迭代器对象,也就是iter(range(100))。当达到batch size大小的时候,就使用yield方法返回。而含有yield方法为生成器也是一个迭代器对象,因此BatchSampler类中__iter__方法返回的也是一个迭代器对象,对其进行遍历时,会依次得到batch size大小的样本的下标索引。DataLoaderIter类会依次遍历类中的BatchSampler类中__iter__方法返回的迭代器对象,得到每个batch的数据下标索引。
9自定义Sampler和BatchSampler
class Sampler(object):r"""Base class for all Samplers.Every Sampler subclass has to provide an :meth:`__iter__` method, providing away to iterate over indices of dataset elements, and a :meth:`__len__` methodthat returns the length of the returned iterators... note:: The :meth:`__len__` method isn't strictly required by:class:`~torch.utils.data.DataLoader`, but is expected in anycalculation involving the length of a :class:`~torch.utils.data.DataLoader`."""def __init__(self, data_source):passdef __iter__(self):raise NotImplementedErrordef __len__(self):return len(self.data_source)所以你要做的就是定义好__iter__(self)函数,不过要注意的是该函数的返回值需要是迭代器对象。例如SequentialSampler返回的是iter(range(len(self.data_source)))。
另外BatchSampler与其他Sampler的主要区别是它需要将Sampler作为参数,打包Sampler中__iter__方法返回的迭代器对象的迭代值,进而每次迭代返回以batch size为大小的index列表。也就是说在后面的读取数据过程中使用的都是batch sampler。
相关文章:
Pytorch 数据产生 DataLoader对象详解
目录 1、Pytorch读取数据流程 2、DataLoader参数 3、DataLoader,Sampler和Dataset 4、sampler和batch_sampler 5、源码解析 6、RandomSampler(dataset)、 SequentialSampler(dataset) 7、BatchSampler(Sampler) 8、总结 9、自定义Sampler和BatchSampler 研…...

Linux文件系统介绍
一、简介 文件系统就是分区或磁盘上的所有文件的逻辑集合。 文件系统不仅包含着文件中的数据而且还有文件系统的结构,所有Linux 用户和程序看到的文件、目录、软连接及文件保护信息等都存储在其中。 不同Linux发行版本之间的文件系统差别很少,主要表现在…...

Java高频必背面试题基础篇02
一、Java 语⾔中关键字 static 的作⽤是什么? static 的主要作⽤有两个: (1)为某种特定数据类型或对象分配与创建对象个数⽆关的单⼀的存储空间。 (2)使得某个⽅法或属性与类⽽不是对象关联在⼀起…...
蓝桥杯—stm32g431rbt6串口中断和定时器输出pwm学习
目录 串口中断 定时器中断 输出pwm 串口中断 配置异步模式,使能中断,选择波特率。 串口接收中断开启 HAL_UART_Receive_IT(&huart1,data, 3); 回调函数: void HAL_UART_RxCpltCallback(UART_HandleTypeDef *huart) { if(huar…...
zed驱动的安装 及 遇到问题 及 ros标定
安装zed相机驱动 zed驱动官网 下载.run文件 chmod x ZED_SDK_Ubuntu18_cuda10.2_v4.0.1.zstd.run #换自己的版本号 ./ZED_SDK_Ubuntu18_cuda10.2_v4.0.1.zstd.run #换自己的版本号当遇到 zstd: not found … Decompression failed. 重新安装&a…...

打车代驾顺风车货车租运系统开发功能(司机端)
随着社会经济水平的提高,人们对于打车代驾服务要求也不断提高,更多的人愿意在手机上通过打车代驾APP小程序软件来预约叫车,选择打车代驾服务。打车代驾软件开发是基于广大用户的要求而产生的新型服务方式,满足大众预约出行需要&am…...
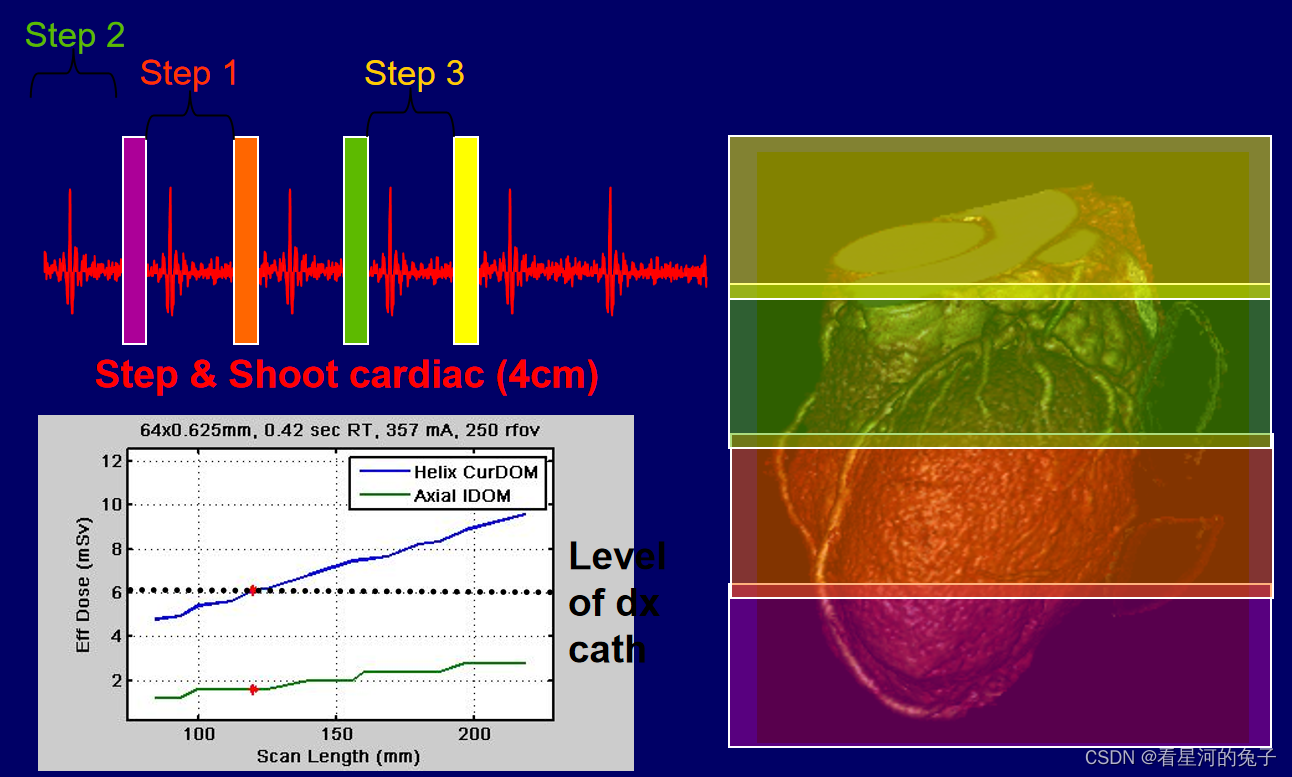
CT剂量及描述方法详细介绍
CT剂量和普通放射剂量的区别 普通放射剂量分布区域大,但一般集中在皮肤入射表面,用患者入射表面剂量(ESD)来表征射线剂量; CT剂量分布在窄带内,边缘与中心分布不均匀;且属于多层扫描; 1、在理想…...

Spring Boot应用优雅关闭
POM依赖 在需要实现优雅关闭的应用工程中增加下述依赖:部分启动器默认就依赖了Actuator启动器,如:spring-cloud-starter-netflix-eureka-server,那么下述依赖是可以省略的。 <dependency><groupId>org.springframewo…...
【实用技巧】7-Zip如何加密压缩文件?
7-Zip是一款免费且实用的压缩软件,除了提供多种压缩格式,还可以对压缩文件进行加密保护,加密后只有输入密码,才能打开压缩包里的文件。如果不知道怎么操作的小伙伴,就来看看小编的分享吧。 操作方法: 1、…...

Anaconda详细安装使用
如果想在conda里面删除某个环境,可以使用 conda remove -n name --all 来删除。 其中 conda info --envs 是查看环境,切换环境 activate base 。 Anaconda Anaconda | The Worlds Most Popular Data Science PlatformAnaconda is the birthplace of Pyt…...

git放弃修改,强制覆盖本地代码
在使用Git的过程中,有些时候我们只想要git服务器中的最新版本的项目,对于本地的项目中修改不做任何理会,就需要用到Git pull的强制覆盖,具体代码如下: $ git fetch --all $ git reset --hard origin/master $ git pu…...

大数据自我进阶(数据仓库)-暂未完全完成
什么时候需要数据仓库? 1.当决策者要进行战略分析或者展示统计的需求。 2.并且数据量非常庞大,而且各个都是数据孤岛。 当满足这2个条件后,就需要搭建数据仓库。 数据仓库的第一步(数据清洗) 为了能准确的分析&am…...

Springmvc中跨服务器文件上传
既然跨服务器,就要开启两个服务器,这里使用两个Tomcat代表两个服务器 文章目录 1.建立图片要上传到的服务器:FileUpload 2.建立上传图片的服务器:Tomcat 9.0.24 3.在Tomcat 9.0.24上部署文件上传的项目,写代码 3.1导入…...

常见漏洞扫描工具AWVS、AppScan、Nessus的使用
HVV笔记——常见漏洞扫描工具AWVS、AppScan、Nessus的使用1 AWVS1.1 安装部署1.2 激活1.3 登录1.4 扫描web应用程序1.4.1 需要账户密码登录的扫描1.4.2 利用录制登录序列脚本扫描1.4.3 利用定制cookie扫描1.5 扫描报告分析1.5.1 AWVS报告类型1.5.2 最常用的报告类型:…...
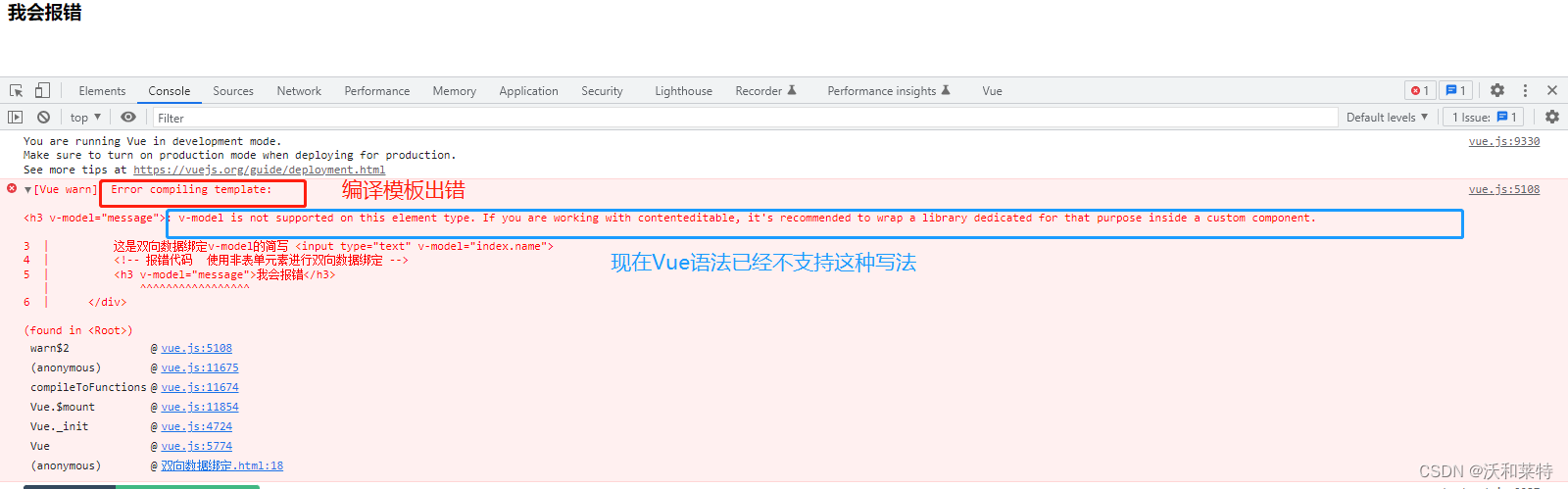
Vue学习——【第二弹】
前言 上一篇文章 Vue学习——【第一弹】 中我们学习了Vue的相关特点及语法,这篇文章接着通过浏览器中的Vue开发者工具扩展来进一步了解Vue的相关工作机制。 Vue的扩展 我们打开Vue的官方文档,点击导航栏中的生态系统,点击Devtools 接着我…...

恐怖的ChatGPT!
大家好,我是飞哥!不知道大家那边咋样。反正我最近感觉是快被ChatGPT包围了。打开手机也全是ChatGPT相关的信息,我的好几个老同学都在问我ChatGPT怎么用,部门内也在尝试用ChatGPT做一点新业务出来。那就干脆我就趁清明假期这一天宝…...
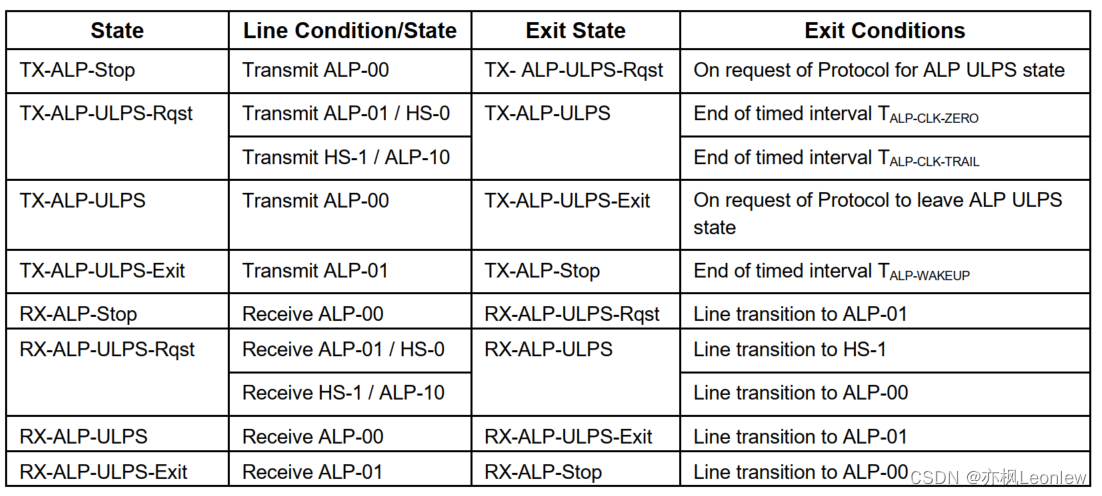
MIPI D-PHYv2.5笔记(12) -- Clock Lane的ULPS
声明:作者是做嵌入式软件开发的,并非专业的硬件设计人员,笔记内容根据自己的经验和对协议的理解输出,肯定存在有些理解和翻译不到位的地方,有疑问请参考原始规范看 LP Mode的Clock Lane ULPS 尽管Clock Lane不包含常规…...
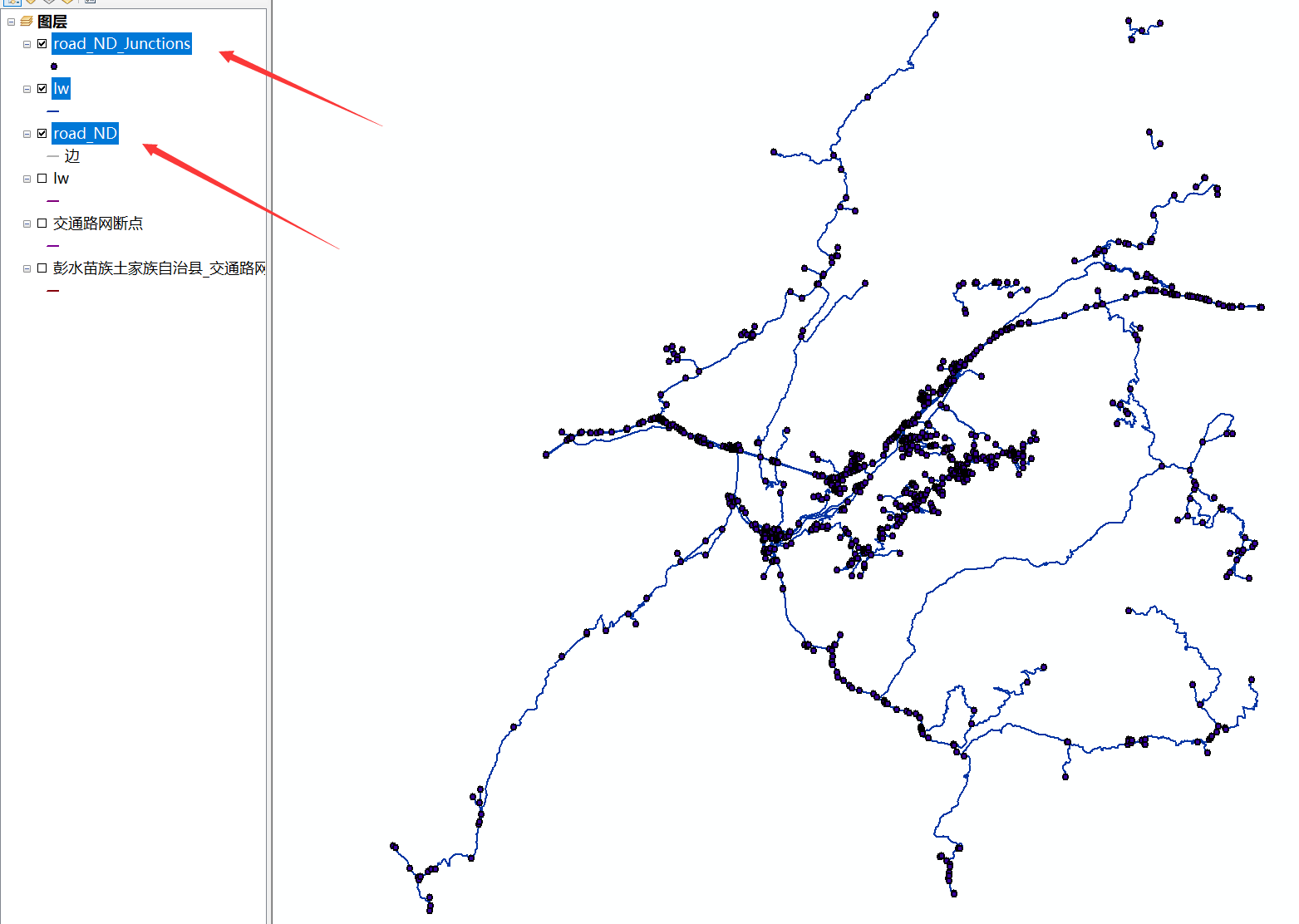
创建网络数据集
目的:主要是用来做路径规划。 第一步:加载用作构建网络数据集的道路网数据到arcmap。 第二步:做打断处理。【如果线数据未做过打断处理,需要做这一步。】 有两种方式【1、编辑器里面的高级编辑器的打断相交线功能;2、…...

从功能到年薪30W+的测试开发工程师,分享我这10年的职业规划路线
求职?择业?跳槽?职业规划? 作为一名初出茅庐的软件测试员,职业发展的道路的确蜿蜒曲折,面对一次次的岗位竞争,挑战一道道的面试关卡,一边带着疑惑,一边又要做出选择&…...
ChatGPT中文免登陆-ChatGPT中文版上线
ChatGPT不支持地区 ChatGPT 是一个开源平台,可在全球范围内使用,不应该存在地区限制。然而,由于某些原因,可能有地区对 ChatGPT 的访问有限制或屏蔽的情况。 如果您发现自己无法访问 ChatGPT,可以尝试以下解决方法&a…...

PyCharm里import报错?别急着pip install,先检查这个Python解释器配置
PyCharm中import报错的终极排查指南:从解释器配置到环境隔离 当你满心欢喜地在PyCharm中敲下import requests准备大展身手时,突然出现的红色波浪线就像一盆冷水浇下来。大多数人的第一反应是打开终端输入pip install requests——但等等,这真…...

YOLO模型如何训练救生衣检测数据集深度学习如何训练救生衣检测数据集
救生衣检测模型YOLO8-300n 提供训练好的模型文件(pt格式)、过程文件和验证图片,带对应的训练数据集10000张 1 111一、救生衣检测模型(YOLOv8-300n)完整方案1. 模型与数据集信息项目详情模型版本YOLOv8n(300…...

告别Claude Code封号烦恼用Taotoken稳定获取Anthropic模型服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 告别Claude Code封号烦恼用Taotoken稳定获取Anthropic模型服务 对于依赖Claude Code进行编程辅助的开发者来说,访问的稳…...

智慧桥梁之桥梁裂缝 钢筋裸露识别 墙面裂缝分割数据集 桥梁病害数据集 yolo格式 图像分割数据集地10171期
病理研究相关数据集简介项目详情数据集类别聚焦病理研究领域,涵盖多种与病理相关的图像类别,可能包含不同器官、组织或疾病类型对应的病理图像,例如常见的炎症、肿瘤等病理状态下的样本图像分类数据集数量总数3210张,但从数据集命…...

Hi3516DV300鸿蒙时钟应用开发:从环境搭建到驱动调试全流程
1. 项目概述:从零到一,在Hi3516DV300上跑通一个鸿蒙时钟最近在捣鼓OpenHarmony,手头正好有一块海思的Hi3516DV300开发板。这块板子性能不错,带屏显,很适合做点有意思的应用。我琢磨着,与其跑个现成的Demo&a…...

HLK-V20语音模块的智能家居实战:如何用STM32控制灯、电机并连接ESP8266上云
HLK-V20语音模块的智能家居实战:STM32联动控制与云端接入全解析 在智能家居DIY领域,语音控制早已从概念走向现实。HLK-V20作为一款高性价比的纯离线语音识别模块,配合STM32的丰富外设控制能力,可以构建出响应迅速、隐私安全的本地…...

如何快速上手PlusPlugins:5分钟从零开始构建跨平台应用
如何快速上手PlusPlugins:5分钟从零开始构建跨平台应用 【免费下载链接】plus_plugins Flutter Community Plus Plugins 项目地址: https://gitcode.com/gh_mirrors/pl/plus_plugins PlusPlugins是Flutter Community提供的一系列实用插件集合,帮助…...

波动率交易神器volatility-trading:基于Euan Sinclair理论的完整工具集
波动率交易神器volatility-trading:基于Euan Sinclair理论的完整工具集 【免费下载链接】volatility-trading A complete set of volatility estimators based on Euan Sinclairs Volatility Trading 项目地址: https://gitcode.com/gh_mirrors/vo/volatility-tr…...
)
What Are You Talking About(HDU- P1075)
伊格纳修斯真是走了狗屎运,昨天居然遇到了火星人!可惜他完全听不懂火星人的语言。临走时,火星人给了他一本火星历史书和一本词典。现在伊格纳修斯想把这本历史书翻译成英语,你能帮帮他吗?输入本题只有一组测试数据&…...
)
NotebookLM多源文档交叉去重实战:基于BERT-Embedding相似度阈值调优(附可复用Python脚本)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM多源文档交叉去重的核心挑战与价值定位 NotebookLM 作为 Google 推出的基于引用的 AI 笔记工具,其核心能力依赖于对用户上传文档的语义理解与跨文档关联。然而当用户导入多个来源…...