【面试】Kafka面试题
文章目录
- 1、Kafka是什么?
- 2、partition的数据文件(offffset,MessageSize,data)
- 3、数据文件分段 segment(顺序读写、分段命令、二分查找)
- 4、负载均衡(partition会均衡分布到不同broker上)
- 5、批量发送
- 6、压缩(GZIP或Snappy)
- 7、消费者设计
- 8、Consumer Group
- 9、如何获取topic主题的列表
- 10、生产者和消费者的命令行是什么?
- 11、consumer是推还是拉?
- 12、讲讲kafka维护消费状态跟踪的方法
- 13、讲一下主从同步。
- 14、为什么需要消息系统,mysql 不能满足需求吗?
- 15、Zookeeper对于Kafka的作用是什么?
- 16、Kafka判断一个节点是否还活着有那两个条件?
- 17、Kafka与传统MQ消息系统之间有三个关键区别
- 18、讲一讲kafka的ack的三种机制
- 19、消费者如何不自动提交偏移量,由应用提交?
- 20、消费者故障,出现活锁问题如何解决?
- 21、如何控制消费的位置?
- 22、kafka分布式(不是单机)的情况下,如何保证消息的顺序消费?
- 23、kafka的高可用机制是什么?
- 24、kafka如何减少数据丢失?
- 25、kafka如何不消费重复数据?比如扣款,我们不能重复的扣?
1、Kafka是什么?
答:
Kafka是一种高吞吐量、分布式、基于发布/订阅的消息系统,最初由LinkedIn公司开发,使用Scala语言编写,目前是Apache的开源项目。
-
broker: Kafka服务器,负责消息存储和转发
-
topic:消息类别,Kafka按照topic来分类消息
-
partition: topic的分区,一个topic可以包含多个partition, topic 消息保存在各个partition上4. offset:消息在日志中的位置,可以理解是消息在partition上的偏移量,也是代表该消息的唯一序号
-
Producer:消息生产者
-
Consumer:消息消费者
-
Consumer Group:消费者分组,每个Consumer必须属于一个group
-
Zookeeper:保存着集群 broker、 topic、 partition等meta 数据;另外,还负责broker故障发现, partition leader选举,负载均衡等功能
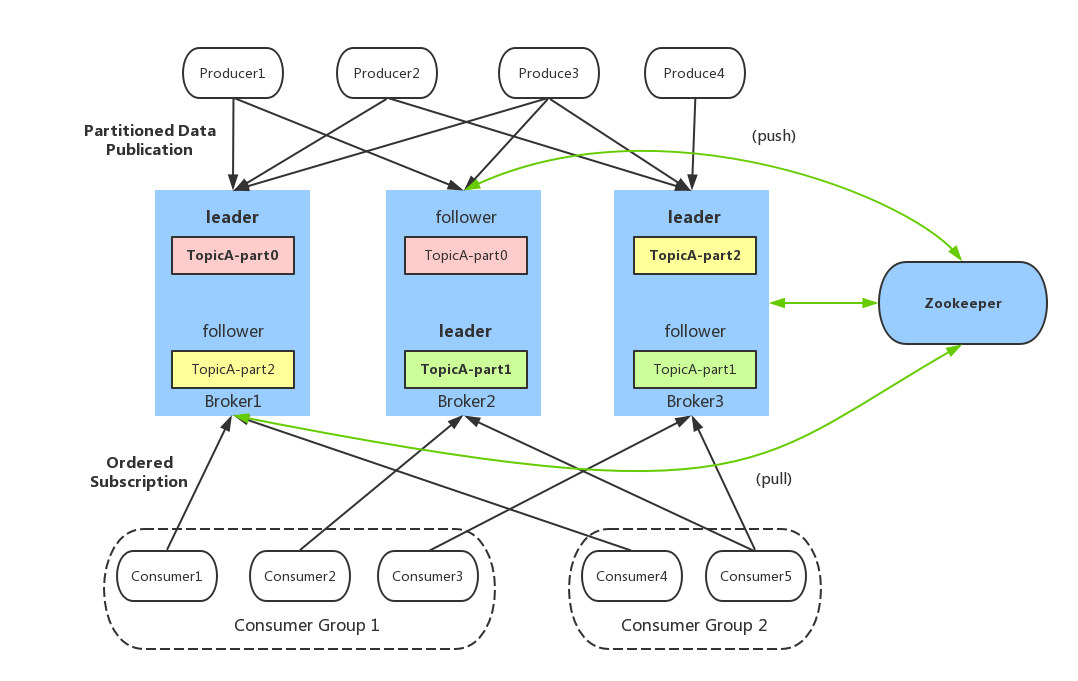
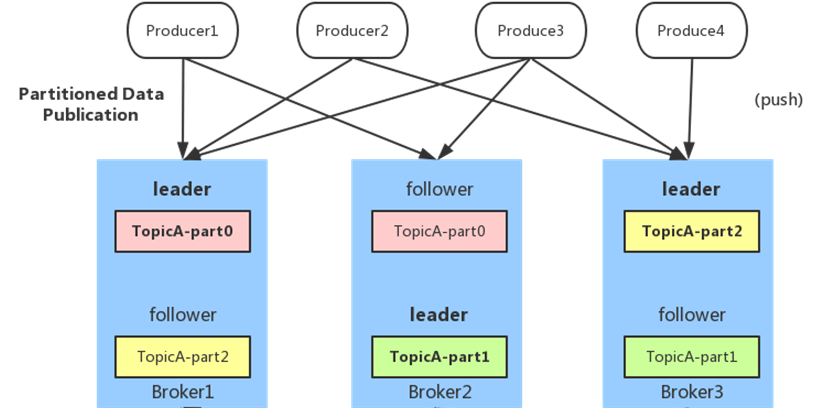
2、partition的数据文件(offffset,MessageSize,data)
答:
partition中的每条Message包含了以下三个属性: offset,MessageSize,data,其中offset表示Message在这个partition中的偏移量,offset不是该Message在partition数据文件中的实际存储位置,而是逻辑上一个值,它唯一确定了partition中的一条Message,可以认为offset是partition中Message的 id; MessageSize表示消息内容data的大小;data为Message的具体内容。
3、数据文件分段 segment(顺序读写、分段命令、二分查找)
答:
Kafka为每个分段后的数据文件建立了索引文件,文件名与数据文件的名字是一样的,只是文件扩展名为index。 index文件中并没有为数据文件中的每条Message建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。

4、负载均衡(partition会均衡分布到不同broker上)
答:
由于消息topic由多个partition组成,且partition会均衡分布到不同broker上。因此,为了有效利用broker集群的性能,提高消息的吞吐量,producer可以通过随机或者hash等方式,将消息平均发送到多个partition上,以实现负载均衡。
5、批量发送
答:
是提高消息吞吐量重要的方式, Producer端可以在内存中合并多条消息后,以一次请求的方式发送了批量的消息给broker,从而大大减少broker存储消息的IO操作次数。但也一定程度上影响了消息的实时性,相当于以时延代价,换取更好的吞吐量。
6、压缩(GZIP或Snappy)
答:
Producer端可以通过GZIP或Snappy格式对消息集合进行压缩。 Producer端进行压缩之后,在Consumer端需进行解压。压缩的好处就是减少传输的数据量,减轻对网络传输的压力,在对大数据处理上,瓶颈往往体现在网络上而不是CPU(压缩和解压会耗掉部分CPU资源)。
7、消费者设计
答:
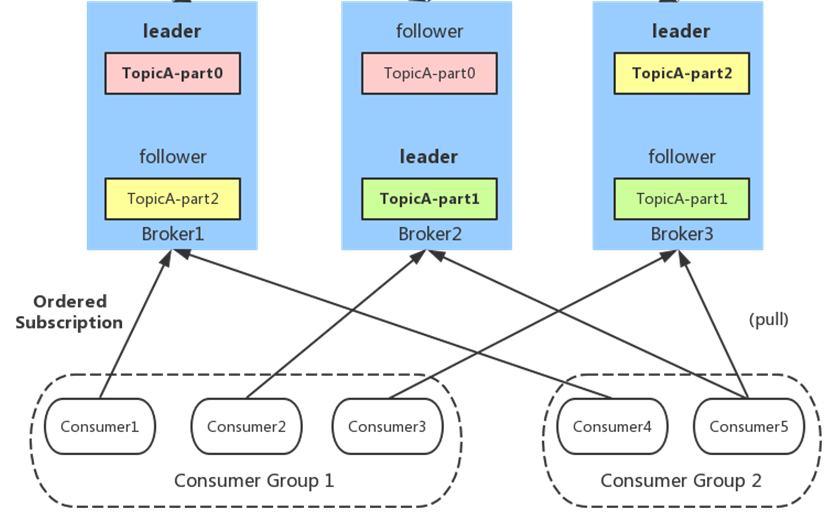
8、Consumer Group
答:
同一Consumer Group中的多个Consumer实例,不同时消费同一个partition,等效于队列模式。 partition内消息是有序的, Consumer通过pull方式消费消息。 Kafka不删除已消费的消息对于partition,顺序读写磁盘数据,以时间复杂度O(1)方式提供消息持久化能力。
9、如何获取topic主题的列表
答:
bin/kafka-topics.sh --list --zookeeper localhost:2181
10、生产者和消费者的命令行是什么?
答:
生产者在主题上发布消息:
bin/kafka-console-producer.sh --broker-list 192.168.43.49:9092 --topic Hello-Kafa
注意这里的 IP 是 server.properties 中的 listeners 的配置。接下来每个新行就是输入一条新消息。
消费者接受消息:
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic Hello-Kafka --from-beginning
11、consumer是推还是拉?
答:
Kafka最初考虑的问题是,customer应该从brokes拉取消息还是brokers将消息推送到consumer,也就是pull还push。在这方面,Kafka遵循了一种大部分消息系统共同的传统的设计:producer将消息推送到broker,consumer从broker拉取消息。
一些消息系统比如Scribe和Apache Flume采用了push模式,将消息推送到下游的consumer。这样做有好处也有坏处:由 broker决定消息推送的速率,对于不同消费速率的consumer就不太好处理了。消息系统都致力于让consumer以最大的速率最快速的消费消息,但不幸的是,push模式下,当 broker推送的速率远大于consumer消费的速率时,consumer恐怕就要崩溃了。最终Kafka还是选取了传统的pull模式。
Pull模式的另外一个好处是consumer可以自主决定是否批量的从broker 拉取数据。Push模式必须在不知道下游consumer消费能力和消费策略的情况下决定是立即推送每条消息还是缓存之后批量推送。如果为了避免consumer崩溃而采用较低的推送速率,将可能导致一次只推送较少的消息而造成浪费。Pull模式下,consumer就可以根据自己的消费能力去决定这些策略。
Pull有个缺点是,如果broker没有可供消费的消息,将导致consumer不断在循环中轮询,直到新消息到t达。为了避免这点,Kafka有个参数可以让consumer阻塞知道新消息到达(当然也可以阻塞知道消息的数量达到某个特定的量这样就可以批量发送)。
12、讲讲kafka维护消费状态跟踪的方法
答:
大部分消息系统在broker端的维护消息被消费的记录:
一个消息被分发到consumer后broker就马上进行标记或者等待customer的通知后进行标记。这样也可以在消息在消费后立马就删除以减少空间占用。
但是这样会不会有什么问题呢?如果一条消息发送出去之后就立即被标记为消费过的,一旦consumer处理消息时失败了(比如程序崩溃)消息就丢失了。
为了解决这个问题,很多消息系统提供了另外一个个功能:当消息被发送出去之后仅仅被标记为已发送状态,当接到consumer已经消费成功的通知后才标记为已被消费的状态。
这虽然解决了消息丢失的问题,但产生了新问题,首先如果consumer处理消息成功了但是向broker发送响应时失败了,这条消息将被消费两次。第二个问题时,broker必须维护每条消息的状态,并且每次都要先锁住消息然后更改状态然后释放锁。这样麻烦又来了,且不说要维护大量的状态数据,比如如果消息发送出去但没有收到消费成功的通知,这条消息将一直处于被锁定的状态,Kafka采用了不同的策略。Topic被分成了若干分区,每个分区在同一时间只被一个consumer消费。
这意味着每个分区被消费的消息在日志中的位置仅仅是一个简单的整数:offset。
这样就很容易标记每个分区消费状态就很容易了,仅仅需要一个整数而已。这样消费状态的跟踪就很简单了。这带来了另外一个好处:consumer可以把offset调成一个较老的值,去重新消费老的消息。这对传统的消息系统来说看起来有些不可思议,但确实是非常有用的,谁规定了一条消息只能被消费一次呢?
13、讲一下主从同步。
答:
Kafka允许topic的分区拥有若干副本,这个数量是可以配置的,你可以为每个topci配置副本的数量。Kafka会自动在每个个副本上备份数据,所以当一个节点down掉时数据依然是可用的., Kafka的副本功能不是必须的,你可以配置只有一个副本,这样其实就相当于只有一份数据。 创建副本的单位是topic的分区,每个分区都有一个leader和零或多个followers。所有的读写操作都由leader处理,一般分区的数量都比broker的数量多的多,各分区的leader均匀的分布在brokers中。
14、为什么需要消息系统,mysql 不能满足需求吗?
答:
1.解耦:
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
2.冗余:
消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的”插入-获取-删除”范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。
3.扩展性:
因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。
4.灵活性 & 峰值处理能力:
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
5.可恢复性:
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
6.顺序保证:
在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。(Kafka 保证一个 Partition 内的消息的有序性)
7.缓冲:
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
8.异步通信:
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
15、Zookeeper对于Kafka的作用是什么?
答:
Zookeeper是一个开放源码的、高性能的协调服务,它用于Kafka的分布式应用。Zookeeper主要用于在集群中不同节点之间进行通信在Kafka中,它被用于提交偏移量,因此如果节点在任何情况下都失败了,它都可以从之前提交的偏移量中获取除此之外,它还执行其他活动,如:leader检测、分布式同步、配置管理、识别新节点何时离开或连接、集群、节点实时状态等等。
16、Kafka判断一个节点是否还活着有那两个条件?
答:
(1)节点必须可以维护和ZooKeeper 的连接,Zookeeper通过心跳机制检查每个节点的连接
(2)如果节点是个follower,他必须能及时的同步leader的写操作,延时不能太久
17、Kafka与传统MQ消息系统之间有三个关键区别
答:
(1).Kafka持久化日志,这些日志可以被重复读取和无限期保留
(2).Kafka是一个分布式系统:它以集群的方式运行,可以灵活伸缩,在内部通过复制数据提升容错能力和高可用性
(3).Kafka支持实时的流式处理
18、讲一讲kafka的ack的三种机制
答:
request.required.acks有三个值0 1 -1(all)
0:生产者不会等待broker的ack,这个延迟最低但是存储的保证最弱当server挂掉的时候就会丢数据。
1:服务端会等待ack值leader副本确认接收到消息后发送ack但是如果leader挂掉后他不确保是否复制完成新leader也会导致数据丢失。
-1(all):服务端会等所有的follower的副本受到数据后才会受到leader发出的ack,这样数据不会丢失。
19、消费者如何不自动提交偏移量,由应用提交?
答:
将auto.commit.offset设为false,然后在处理一批消息后commitSync() 或者异步提交commitAsync()
即:

20、消费者故障,出现活锁问题如何解决?
答:
出现 “活锁 ” 的情况, 是它持续的发送心跳, 但是没有处理 。为了预防消费者在这种情况 下一 直持有分区,我们使用max.poll.interval.ms活跃检测 机制 。 在此基础上,如果你调用的poll的频率大于最大间隔,则客户端将主动地离开组,以便其 他消费者接管该分区。发生这种情况时,你会看到offset提交失败(调用commitSync()引发的CommitFailedException)。 这是一种安全机制,保障只有活动成员能够提交offset。所以要留在组中,你必须持续调用poll。
消费者提供两个配置设置来控制poll循环:
max.poll.interval.ms:增大poll的间隔,可以为消费者提供更多的时间去处理返回的消息(调用poll(long)返回的消 息,通常返回的消息都是一 批)。缺点是此值越大将会延迟组重新平衡。
max.poll.records:此设置限制每次调用poll返回的消息数,这样可以更容易的预测每次poll间隔要处理的最大值。通过调整此值,可以减少poll间隔,减少重新平衡分组的对于消息处理时间不可预测地的情况,这些选项是不够的。
处理这种情况的推荐方法是将消息处理移到另一个线程中,让消费者继续调用poll。 但是必须注意确保已提交的offset不超过实际位置。另外,你必须禁用自动提交,并只有在线程完成处理后才为记录手动提交偏移量(取决于你 )。还要注意 ,你需要pause暂停分区,不会从poll接收到新消息,让线程处理完之前返回的消息(如果你的处理能力比拉取消息的慢,那创建新线 程将导致你机器内存溢出) 。
21、如何控制消费的位置?
答:
kafka 使用 seek(TopicPartition, long)指定新的消费位置。用于查找服务器保留的最早和最新的offset的特殊的方法也可用(seekToBeginning(Collection) 和seekToEnd(Collection))
22、kafka分布式(不是单机)的情况下,如何保证消息的顺序消费?
答:
Kafka分布式的单位是partition,同一个partition用一个write ahead log组织,所以可以保证FIFO的顺序。不同partition之间不能保证顺序。但是绝大多数用户都可以通过message key来定义,因为同一个key的Message可以保证只发送到同一个partition。
Kafka中发送1条消息的时候,可以指定(topic, partition, key) 3个参数。partiton和key是可选的。如果你指定了partition,那就是所有消息发往同1个partition,就是有序的。
并且在消费端,Kafka保证,1个partition只能被1个consumer消费。或者你指定key(比如order id),具有同1个key的所有消息,会发往同1个partition。
23、kafka的高可用机制是什么?
答:
这个问题比较系统,回答出kafka的系统特点,leader和follower的关系,消息读写的顺序即可。
24、kafka如何减少数据丢失?
25、kafka如何不消费重复数据?比如扣款,我们不能重复的扣?
答:
其实还是得结合业务来思考,我这里给几个思路:
比如你拿个数据要写库,你先根据主键查一下,如果这数据都有了,你就别插入了,update一下好吧。
比如你是写Redis,那没问题了,反正每次都是set,天然幂等性。
比如你不是上面两个场景,那做的稍微复杂一点,你需要让生产者发送每条数据的时候,里面加一个全局唯一的id,类似订单 id之类的东西,然后你这里消费到了之后,先根据这个id去比如Redis里查一下,之前消费过吗?如果没有消费过,你就处理,然后这个id写Redis。如果消费过了,那你就别处理了,保证别重复处理相同的消息即可。
比如基于数据库的唯一键来保证重复数据不会重复插入多条。因为有唯一键约束了,重复数据插入只会报错,不会导致数据库中出现脏数据。
总结
篇幅有限,其他内容就不在这里一 一展示了,整理不易,欢迎大家一起交流,喜欢小编分享的文章记得关注我点赞哟,感谢支持!重要的事情说三遍,转发+转发+转发,一定要记得转发哦!!!
相关文章:
【面试】Kafka面试题
文章目录1、Kafka是什么?2、partition的数据文件(offffset,MessageSize,data)3、数据文件分段 segment(顺序读写、分段命令、二分查找)4、负载均衡(partition会均衡分布到不同broker…...

【C++学习】map和set的使用
🐱作者:一只大喵咪1201 🐱专栏:《C学习》 🔥格言:你只管努力,剩下的交给时间! map和set的使用🌈关联式容器⚡键对值🌈set⚡构造函数⚡增删查改🌈…...

企业电子招投标采购系统——功能模块功能描述+数字化采购管理 采购招投标
功能模块: 待办消息,招标公告,中标公告,信息发布 描述: 全过程数字化采购管理,打造从供应商管理到采购招投标、采购合同、采购执行的全过程数字化管理。通供应商门户具备内外协同的能力,为外…...
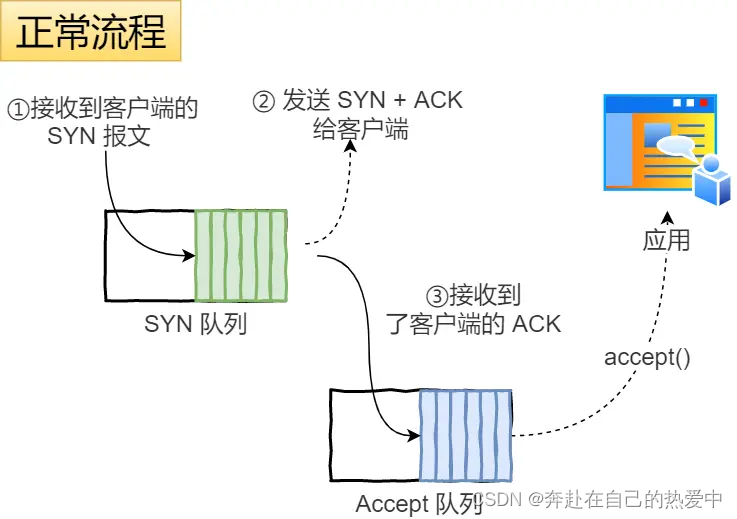
4.6--计算机网络之TCP篇之TCP的连接建立--(复习+深入)---好好沉淀,加油呀
1.TCP 三次握手过程是怎样的? TCP 是面向连接的协议,所以使用 TCP 前必须先建立连接,而建立连接是通过三次握手来进行的 1.一开始,客户端和服务端都处于 CLOSE 状态。先是服务端主动监听某个端口,处于 LISTEN 状态 2…...
Pytorch 数据产生 DataLoader对象详解
目录 1、Pytorch读取数据流程 2、DataLoader参数 3、DataLoader,Sampler和Dataset 4、sampler和batch_sampler 5、源码解析 6、RandomSampler(dataset)、 SequentialSampler(dataset) 7、BatchSampler(Sampler) 8、总结 9、自定义Sampler和BatchSampler 研…...

Linux文件系统介绍
一、简介 文件系统就是分区或磁盘上的所有文件的逻辑集合。 文件系统不仅包含着文件中的数据而且还有文件系统的结构,所有Linux 用户和程序看到的文件、目录、软连接及文件保护信息等都存储在其中。 不同Linux发行版本之间的文件系统差别很少,主要表现在…...

Java高频必背面试题基础篇02
一、Java 语⾔中关键字 static 的作⽤是什么? static 的主要作⽤有两个: (1)为某种特定数据类型或对象分配与创建对象个数⽆关的单⼀的存储空间。 (2)使得某个⽅法或属性与类⽽不是对象关联在⼀起…...
蓝桥杯—stm32g431rbt6串口中断和定时器输出pwm学习
目录 串口中断 定时器中断 输出pwm 串口中断 配置异步模式,使能中断,选择波特率。 串口接收中断开启 HAL_UART_Receive_IT(&huart1,data, 3); 回调函数: void HAL_UART_RxCpltCallback(UART_HandleTypeDef *huart) { if(huar…...
zed驱动的安装 及 遇到问题 及 ros标定
安装zed相机驱动 zed驱动官网 下载.run文件 chmod x ZED_SDK_Ubuntu18_cuda10.2_v4.0.1.zstd.run #换自己的版本号 ./ZED_SDK_Ubuntu18_cuda10.2_v4.0.1.zstd.run #换自己的版本号当遇到 zstd: not found … Decompression failed. 重新安装&a…...

打车代驾顺风车货车租运系统开发功能(司机端)
随着社会经济水平的提高,人们对于打车代驾服务要求也不断提高,更多的人愿意在手机上通过打车代驾APP小程序软件来预约叫车,选择打车代驾服务。打车代驾软件开发是基于广大用户的要求而产生的新型服务方式,满足大众预约出行需要&am…...
CT剂量及描述方法详细介绍
CT剂量和普通放射剂量的区别 普通放射剂量分布区域大,但一般集中在皮肤入射表面,用患者入射表面剂量(ESD)来表征射线剂量; CT剂量分布在窄带内,边缘与中心分布不均匀;且属于多层扫描; 1、在理想…...

Spring Boot应用优雅关闭
POM依赖 在需要实现优雅关闭的应用工程中增加下述依赖:部分启动器默认就依赖了Actuator启动器,如:spring-cloud-starter-netflix-eureka-server,那么下述依赖是可以省略的。 <dependency><groupId>org.springframewo…...
【实用技巧】7-Zip如何加密压缩文件?
7-Zip是一款免费且实用的压缩软件,除了提供多种压缩格式,还可以对压缩文件进行加密保护,加密后只有输入密码,才能打开压缩包里的文件。如果不知道怎么操作的小伙伴,就来看看小编的分享吧。 操作方法: 1、…...

Anaconda详细安装使用
如果想在conda里面删除某个环境,可以使用 conda remove -n name --all 来删除。 其中 conda info --envs 是查看环境,切换环境 activate base 。 Anaconda Anaconda | The Worlds Most Popular Data Science PlatformAnaconda is the birthplace of Pyt…...

git放弃修改,强制覆盖本地代码
在使用Git的过程中,有些时候我们只想要git服务器中的最新版本的项目,对于本地的项目中修改不做任何理会,就需要用到Git pull的强制覆盖,具体代码如下: $ git fetch --all $ git reset --hard origin/master $ git pu…...

大数据自我进阶(数据仓库)-暂未完全完成
什么时候需要数据仓库? 1.当决策者要进行战略分析或者展示统计的需求。 2.并且数据量非常庞大,而且各个都是数据孤岛。 当满足这2个条件后,就需要搭建数据仓库。 数据仓库的第一步(数据清洗) 为了能准确的分析&am…...

Springmvc中跨服务器文件上传
既然跨服务器,就要开启两个服务器,这里使用两个Tomcat代表两个服务器 文章目录 1.建立图片要上传到的服务器:FileUpload 2.建立上传图片的服务器:Tomcat 9.0.24 3.在Tomcat 9.0.24上部署文件上传的项目,写代码 3.1导入…...

常见漏洞扫描工具AWVS、AppScan、Nessus的使用
HVV笔记——常见漏洞扫描工具AWVS、AppScan、Nessus的使用1 AWVS1.1 安装部署1.2 激活1.3 登录1.4 扫描web应用程序1.4.1 需要账户密码登录的扫描1.4.2 利用录制登录序列脚本扫描1.4.3 利用定制cookie扫描1.5 扫描报告分析1.5.1 AWVS报告类型1.5.2 最常用的报告类型:…...
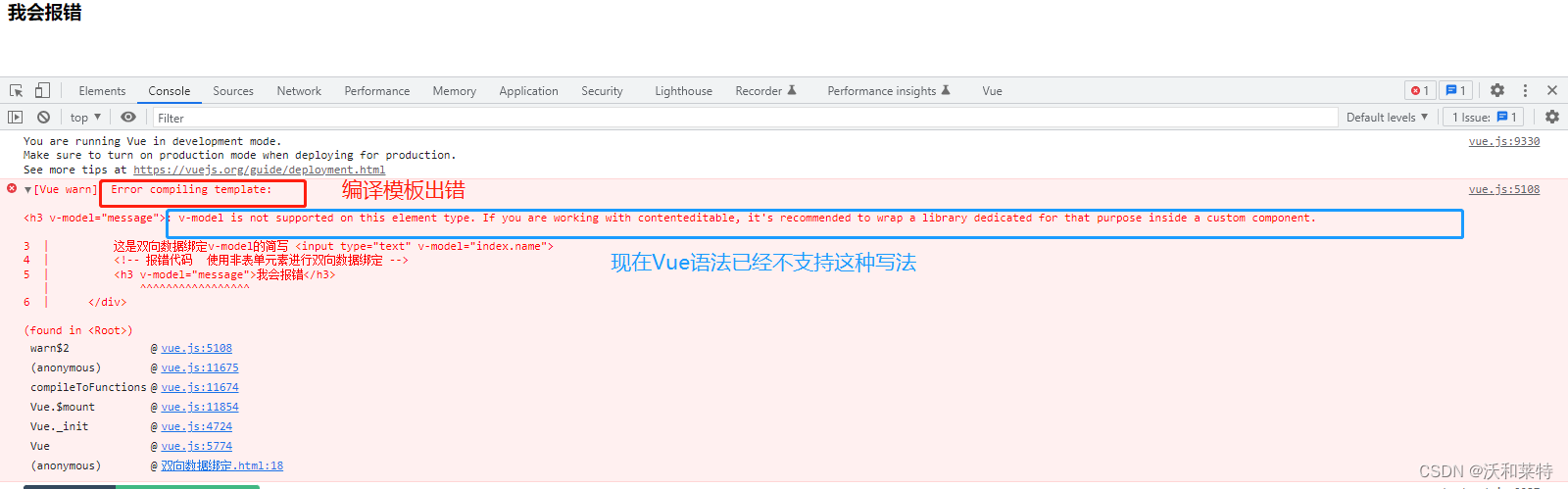
Vue学习——【第二弹】
前言 上一篇文章 Vue学习——【第一弹】 中我们学习了Vue的相关特点及语法,这篇文章接着通过浏览器中的Vue开发者工具扩展来进一步了解Vue的相关工作机制。 Vue的扩展 我们打开Vue的官方文档,点击导航栏中的生态系统,点击Devtools 接着我…...

恐怖的ChatGPT!
大家好,我是飞哥!不知道大家那边咋样。反正我最近感觉是快被ChatGPT包围了。打开手机也全是ChatGPT相关的信息,我的好几个老同学都在问我ChatGPT怎么用,部门内也在尝试用ChatGPT做一点新业务出来。那就干脆我就趁清明假期这一天宝…...

深度解析:三合一技术方案破解Cursor AI编辑器限制的终极指南
深度解析:三合一技术方案破解Cursor AI编辑器限制的终极指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached yo…...

手把手教你为YOLOv8 TensorRT推理写一个C++接口:从DLL封装到QT界面调用
深度解析:构建高效YOLOv8 TensorRT推理C接口的工程实践 在工业视觉和边缘计算领域,将深度学习模型封装为可复用的软件组件已成为提升开发效率的关键。本文将以YOLOv8模型为例,深入探讨如何设计一个专业级的TensorRT推理C接口,重点…...
)
告别Excel!用Python复现地理探测器,手把手教你分析空间数据(附完整代码)
告别Excel!用Python复现地理探测器,手把手教你分析空间数据(附完整代码) 空间数据分析在地理信息科学、生态学和城市规划等领域扮演着关键角色。传统的地理探测器分析往往依赖Excel工具包,但这种方式存在诸多限制&…...

从 JetBrains 全家桶用户视角,聊聊 DataGrip 那些被低估的『协同』技巧:共享查询、布局同步与团队规范
从 JetBrains 全家桶用户视角,聊聊 DataGrip 那些被低估的『协同』技巧:共享查询、布局同步与团队规范 在团队开发环境中,数据库操作往往被视为个人技能而非团队资产。当开发者频繁切换于 IntelliJ IDEA、PyCharm 和 DataGrip 之间时…...

B站视频转文字终极指南:3步快速提取视频字幕和文案
B站视频转文字终极指南:3步快速提取视频字幕和文案 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 还在为B站视频内容无法搜索而烦恼吗࿱…...

Watchify常见问题解决方案:解决监视失败的7个实用技巧
Watchify常见问题解决方案:解决监视失败的7个实用技巧 【免费下载链接】watchify watch mode for browserify builds 项目地址: https://gitcode.com/gh_mirrors/wa/watchify Watchify作为Browserify的监视模式工具,能在文件变化时自动重新构建&a…...

【NotebookLM高阶假设工程】:为什么87%的研究者卡在第2步?3类典型失效模式+实时调试SOP
更多请点击: https://intelliparadigm.com 第一章:NotebookLM假设构建辅助 NotebookLM 是 Google 推出的基于用户上传文档进行可信问答与推理的 AI 工具,其核心能力之一是支持“假设构建”(Hypothesis Generation)——…...

基于Spark的分布式量化交易框架:事件驱动架构与实战开发
1. 项目概述与核心价值最近在跟几个做量化交易的朋友聊天,发现一个挺有意思的现象:大家手里或多或少都有一些基于Python的量化策略,但真正能稳定、高效、自动化跑起来的,却不多。问题往往出在几个地方:要么是本地机器性…...

Blender 3MF插件终极指南:如何在Blender中实现3D打印文件的完美导入导出
Blender 3MF插件终极指南:如何在Blender中实现3D打印文件的完美导入导出 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 想要在Blender中高效处理3D打印文件吗…...
)
FPGA新手必看:用Verilog手搓一个SPI Master控制器(Mode 0/3实战)
FPGA实战:从零构建SPI Master控制器的Verilog实现指南 1. 初识SPI协议与FPGA开发环境搭建 对于刚接触FPGA和数字电路设计的工程师来说,SPI(Serial Peripheral Interface)协议是一个理想的起点。这种同步串行通信协议广泛应用于传感…...