day018 第六章 二叉树 part05
一、513.找树左下角的值
这个题目的主要思路是使用广度优先搜索(BFS)遍历整棵树,最后返回最后一层的最左边的节点的值。具体的实现可以使用队列来存储每一层的节点,并且在遍历每一层节点时,不断更新最左边的节点的值。时间复杂度为O(n),其中n是节点的个数。
二、112.路径总和
这个题目的主要思路是使用深度优先搜索(DFS)遍历整棵树,同时记录到达每个节点时的路径和,如果到达叶子节点时路径和等于给定的目标和,则返回true。具体的实现可以使用递归来实现DFS,同时在每个节点处更新路径和,并且在到达叶子节点时判断路径和是否等于目标和。时间复杂度为O(n),其中n是节点的个数。
三、113.路径总和ii
这个题目的主要思路和112题类似,也是使用DFS遍历整棵树,同时记录到达每个节点时的路径和,并且在到达叶子节点时判断路径和是否等于给定的目标和。不同的是,这个题目需要返回所有满足条件的路径,而不仅仅是返回true或false。具体的实现可以在DFS的过程中使用一个数组来存储当前的路径,并且在到达叶子节点时,如果路径和等于目标和,则将整个路径加入结果列表中。时间复杂度为O(n^2),其中n是节点的个数,主要是因为每次需要复制一份路径数组。
四、106.从中序与后序遍历序列构造二叉树
这个题目的主要思路是使用递归来构建整棵树。具体的实现可以先找到后序遍历序列中的最后一个节点作为根节点,然后在中序遍历序列中找到根节点的位置,从而确定左子树和右子树的范围。然后递归的构建左子树和右子树即可。时间复杂度为O(n),其中n是节点的个数。
五、105.从前序与中序遍历序列构造二叉树
这个题目的主要思路和106题类似,也是使用递归来构建整棵树。具体的实现可以先找到前序遍历序列中的第一个节点作为根节点,然后在中序遍历序列中找到根节点的位置,从而确定左子树和右子树的范围。然后递归的构建左子树和右子树即可。时间复杂度为O(n),其中n是节点的个数。
一、513.找树左下角的值
public int findBottomLeftValue(TreeNode root) {Queue<TreeNode> queue = new LinkedList<>();queue.offer(root);int res = root.val;while (!queue.isEmpty()) {int size = queue.size();for (int i = 0; i < size; i++) {TreeNode node = queue.poll();if (i == 0) {res = node.val;}if (node.left != null) {queue.offer(node.left);}if (node.right != null) {queue.offer(node.right);}}}return res;
}
二、112.路径总和
public boolean hasPathSum(TreeNode root, int sum) {if (root == null) {return false;}if (root.left == null && root.right == null) {return sum == root.val;}return hasPathSum(root.left, sum - root.val) || hasPathSum(root.right, sum - root.val);
}
三、113.路径总和ii
public List<List<Integer>> pathSum(TreeNode root, int sum) {List<List<Integer>> res = new ArrayList<>();List<Integer> path = new ArrayList<>();dfs(root, sum, path, res);return res;
}private void dfs(TreeNode root, int sum, List<Integer> path, List<List<Integer>> res) {if (root == null) {return;}path.add(root.val);if (root.left == null && root.right == null && sum == root.val) {res.add(new ArrayList<>(path));}dfs(root.left, sum - root.val, path, res);dfs(root.right, sum - root.val, path, res);path.remove(path.size() - 1);
}
四、106.从中序与后序遍历序列构造二叉树
public TreeNode buildTree(int[] inorder, int[] postorder) {if (inorder == null || postorder == null || inorder.length != postorder.length) {return null;}int n = inorder.length;Map<Integer, Integer> map = new HashMap<>();for (int i = 0; i < n; i++) {map.put(inorder[i], i);}return buildTree(inorder, 0, n - 1, postorder, 0, n - 1, map);
}private TreeNode buildTree(int[] inorder, int inStart, int inEnd, int[] postorder, int postStart, int postEnd, Map<Integer, Integer> map) {if (inStart > inEnd || postStart > postEnd) {return null;}int rootVal = postorder[postEnd];TreeNode root = new TreeNode(rootVal);int index = map.get(rootVal);int leftSize = index - inStart;root.left = buildTree(inorder, inStart, index - 1, postorder, postStart, postStart + leftSize - 1, map);root.right = buildTree(inorder, index + 1, inEnd, postorder, postStart + leftSize, postEnd - 1, map);return root;
}
五、105.从前序与中序遍历序列构造二叉树
public TreeNode buildTree(int[] preorder, int[] inorder) {if (preorder == null || inorder == null || preorder.length != inorder.length) {return null;}int n = preorder.length;Map<Integer, Integer> map = new HashMap<>();for (int i = 0; i < n; i++) {map.put(inorder[i], i);}return buildTree(preorder, 0, n - 1, inorder, 0, n - 1, map);
}private TreeNode buildTree(int[] preorder, int preStart, int preEnd, int[] inorder, int inStart, int inEnd, Map<Integer, Integer> map) {if (preStart > preEnd || inStart > inEnd) {return null;}int rootVal = preorder[preStart];TreeNode root = new TreeNode(rootVal);int index = map.get(rootVal);int leftSize = index - inStart;root.left = buildTree(preorder, preStart + 1, preStart + leftSize, inorder, inStart, index - 1, map);root.right = buildTree(preorder, preStart + leftSize + 1, preEnd, inorder, index + 1, inEnd, map);return root;
}
相关文章:

day018 第六章 二叉树 part05
一、513.找树左下角的值 这个题目的主要思路是使用广度优先搜索(BFS)遍历整棵树,最后返回最后一层的最左边的节点的值。具体的实现可以使用队列来存储每一层的节点,并且在遍历每一层节点时,不断更新最左边的节点的值。…...
如何下载ChatGPT-ChatGPT如何写作
CHATGPT能否改一下文章 ChatGPT 作为一种自然语言处理技术,生成的文章可能存在表达不够准确或文风不符合要求等问题。在这种情况下,可以使用编辑和修改来改变输出的文章,使其符合特定的要求和期望。 具体来说,可以采用以下步骤对…...

微策略再次买入
原创:刘教链* * *隔夜,比特币再次小幅回升至28k上方。微策略(Microstrategy)创始人Michael Saylor发推表示,微策略再次出手,买入1045枚比特币。此次买入大概花费2930万美元,平均加仓成本28016美…...

express框架
Express 是基于 Node.js 平台,快速、开放、极简的 Web 开发框架. 创建一个基本的express web服务器 // 1.导入express const express require(express); // 2.创建web服务器 const app express(); // 3.启动web服务器 app.listen(80, ()>{console.log(expres…...

完蛋的goals
...

Javase学习文档------面象对象初探
引入面向对象 面向对象的由来: 面向对象编程(Object-Oriented Programming, OOP)是一种编程范型,其由来可以追溯到20世纪60年代。在此之前,主流编程语言采用的是“过程化编程”模式,即面向过程编程模式。在这种模式下&…...

ChatGPT能够干翻谷歌吗?
目前大多数人对于ChatGPT的喜爱,主要源自于其强大的沟通能力,当我们向ChatGPT提出问题时,它不仅能够为我们提供结论,而且还能够与我们建立沟通,向ChatGPT提出任何问题,感觉都像是在与一个真实的人类进行交谈…...

PCL 使用点云创建数字高程模型DEM
目录 一、DEM1、数字高程模型二、代码实现三、结果展示1、点云2、DEM四、相关链接一、DEM 1、数字高程模型 数字高程模型(Digital Elevation Model),简称DEM,是通过有限的地形高程数据实现对地面地形的数字化模拟(即地形表面形态的数字化表达),它是用一组有序数值阵列形…...
我体验了首个接入GPT-4的代码编辑器,太炸裂了
最近一款名为Cursor的代码编辑器已经传遍了圈内,受到众多编程爱好者的追捧。 它主打的亮点就是,通过 GPT-4 来辅助你编程,完成 AI 智能生成代码、修改 Bug、生成测试等操作。 确实很吸引人,而且貌似也能大大节省人为的重复工作&…...
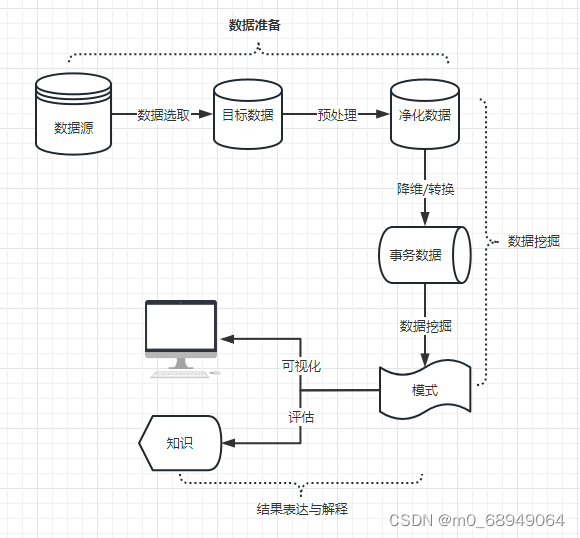
互联网数据挖掘与分析讲解
一、定义 数据挖掘(英语:Data mining),又译为资料探勘、数据采矿。它是数据库知识发现(英语:Knowledge-Discovery in Databases,简称:KDD)中的一个步骤。数据挖掘一般是指从大量的数…...

linux之cut的使用
cut是一个选取命令,就是将一段数据经过分析,取出我们想要的。一般来说,选取信息通常是针对“行”来进行分析的,并不是整篇信息分析的 其语法格式为: cut [-bn] [file] 或 cut [-c][file] 或 cut [-df] [file]使用说明:…...
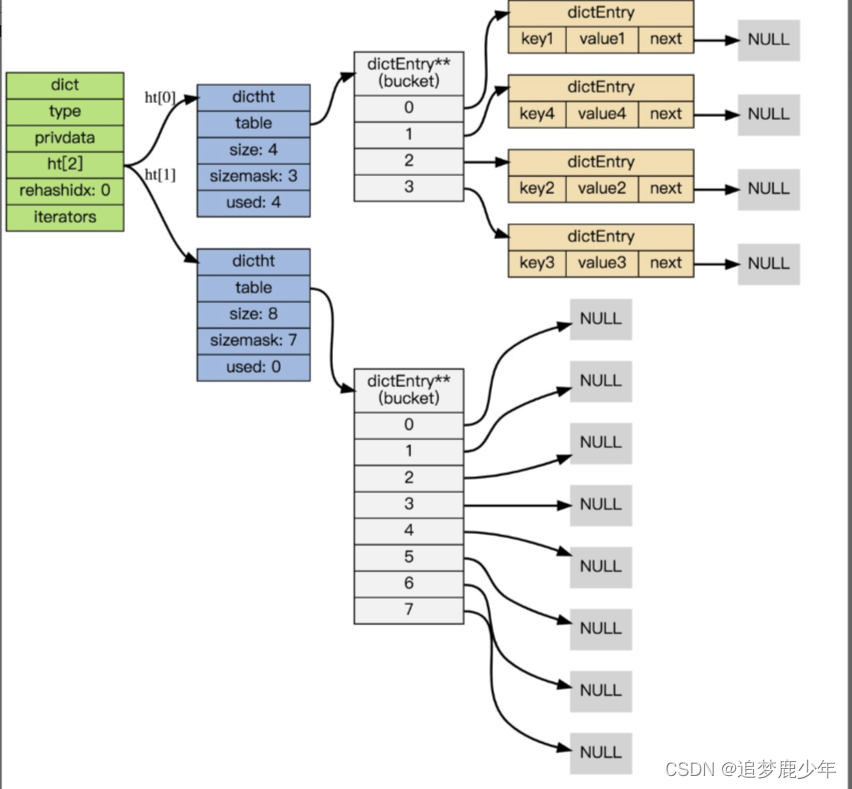
Redis第十讲 Redis之Hash数据结构Dict-rehash扩容操作
Rehash 执行过程 字典的 rehash 操作实际上就是执行以下任务: 创建一个比 ht[0]->table 更大的 ht[1]->table ;将 ht[0]->table 中的所有键值对迁移到 ht[1]->table ;将原有 ht[0] 的数据清空,并将 ht[1] 替换为新的 ht[0] ; 经过以上步骤之后, 程序就在不改…...
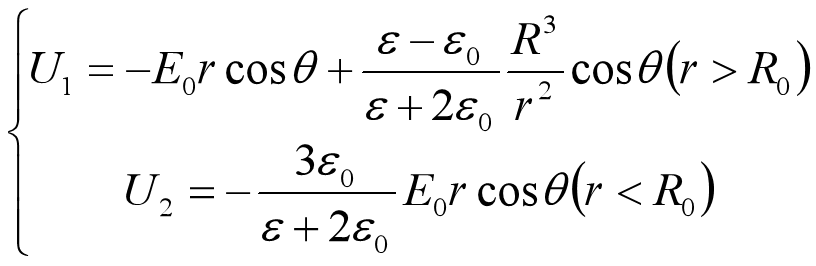
电动力学问题中的Matlab可视化
电磁场的经典描述 小说一则 电磁场的经典描述就是没有啥玩意量子力学的经典电动力学下对电磁场的描述,以后有空写个科幻小说,写啥呢,就写有天张三遇见了一个外星人,外星人来自这样一个星球,星球上的物质密度特别低,导致外星人的测量会明显的影响物质的运动,外星人不能同时得到…...

云原生周刊:编程即将终结?
近日哈佛大学计算机科学的前教授 Matt Welsh,分享了他对计算机科学、分布式计算的未来以及 ChatGPT 和 GitHub Copilot 是否代表编程结束的开始的看法。 威尔士说,编程语言仍然很复杂。再多的工作也无法让它变得简单。 “在我看来,任何改进…...

C++ STL,resize 和 reserve 的区别
结论放前边:resize和reserve都可以给容器扩容,区别在于resize会进行填充,使容器处于满员的状态,即sizecapacity,而reserve不会填充,有size<capacity. 1. size 和 capacity 的区别 size和capacity是容器…...

Java——详解ReentrantLock与AQS的关联以及AQS的数据结构和同步状态State
前言 Java中大部分同步类(Lock、Semaphore、ReentrantLock等)都是基于AbstractQueuedSynchronizer(简称为 AQS)实现的。 AQS 是一种提供了原子式管理同步状态、阻塞和唤醒线程功能以及队列模型的简单框架。 本文会先介绍应用层&a…...

vue3+vite+ts 接入QQ登录
说明 前提资料准备 在QQ互联中心注册成为开发者 站点:https://connect.qq.com/创建应用,如图 js sdk方式 下载对应的sdk包 sdk下载:https://wiki.connect.qq.com/sdk%e4%b8%8b%e8%bd%bd 使用 下载离线js sdk 打开:https:…...
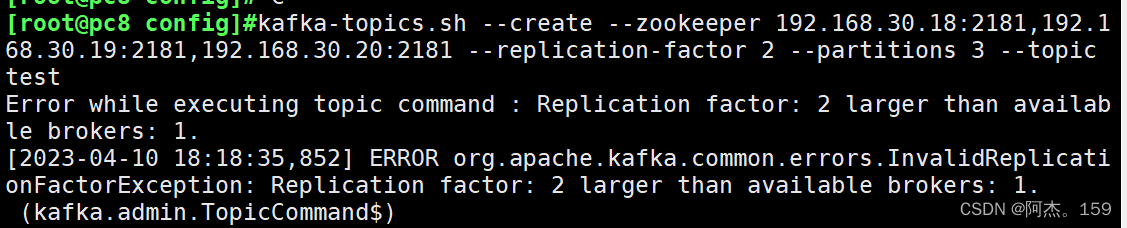
消息队列kafka及zookeeper机制
目录 一、zookeeper 1、zookeeper简介 2、zookeeper特点 3、zookeeper工作模式及机制 4、zookeeper应用场景及选举机制 5、zookeeper集群部署 ①实验环境 ②安装zookeeper 二、消息队列kafka 1、为什么要有消息队列 2、使用消息队列的好处 3、kafka简介 4、kafka…...
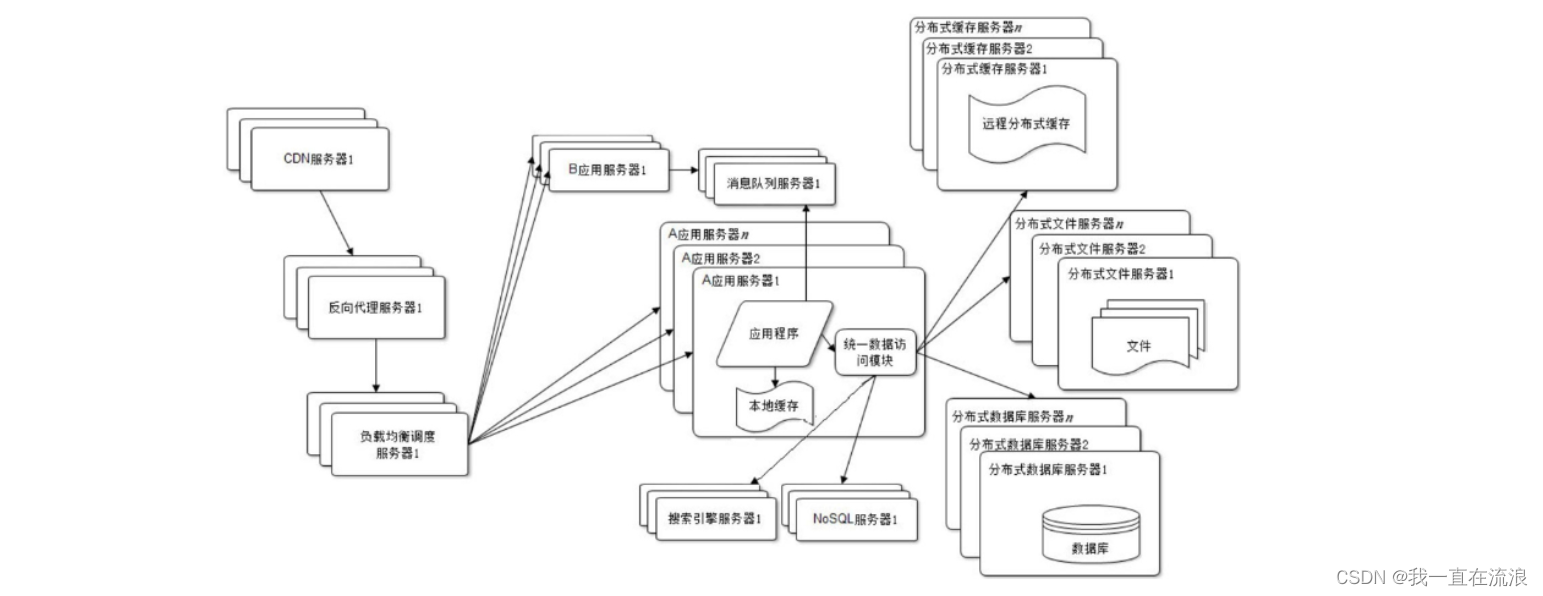
分布式 - 分布式体系架构:IT架构的演进过程
文章目录01. 应用与数据一体模式02. 应用服务和数据服务的分离03. 缓存与性能的提升04. 服务器集群处理并发05. 数据库读写分离06. 反向代理和 CDN07. 分布式文件系统和分布式数据库系统08. NoSQL和搜索引擎09. 业务拆分10. Redis缓存在应用服务器上是进程内缓存还是进程外缓存…...

CSDN 周赛42期
CSDN 周赛42期1、题目名称:鬼画符门之宗门大比2、题目名称:K皇把妹3、题目名称:影分身4、题目名称:开心的金明小结1、题目名称:鬼画符门之宗门大比 给定整数序列A。 求在整数序列A中连续权值最大的子序列的权值。 &…...
)
NotebookLM评论反馈功能全链路拆解(从Prompt响应延迟到语义锚定失效的7个致命断点)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM评论反馈功能的架构全景与设计初衷 NotebookLM 的评论反馈功能并非简单的 UI 层叠加,而是贯穿数据流、状态管理与协同语义理解的深度集成模块。其核心目标是让用户在阅读、引用或…...

别只盯着密码爆破:身份认证漏洞的3个“非主流”攻击面与防御思考
身份认证安全的隐秘战场:超越密码爆破的三大高阶攻防实践 在网络安全领域,身份认证机制如同数字世界的门锁系统。当大多数安全从业者将注意力集中在传统的密码爆破防御时,攻击者早已将目光转向那些被忽视的认证薄弱环节。本文将深入剖析三个常…...

从原理图到PCB的桥梁:手把手教你用Cadence导出STM32项目的网表与BOM清单
从原理图到PCB的桥梁:手把手教你用Cadence导出STM32项目的网表与BOM清单 在电子设计自动化(EDA)流程中,从原理图设计到PCB布局的过渡阶段往往是最容易被忽视却又至关重要的环节。许多工程师在完成精美的原理图后,常常因…...

Spring Boot条件装配原理
Spring Boot条件装配原理 引言 条件装配是Spring Boot自动配置的核心机制,通过Conditional及其派生注解,Spring能够根据当前环境、classpath、配置属性等因素智能地决定是否创建某个Bean。本文将深入剖析条件装配的实现原理、各种条件注解的使用方法以及…...

切削液防锈成分消耗机理、三类防锈剂参数与补加管控实测
一、防锈成分消耗核心机理物理消耗:工件表面携带(占比 35%)、切屑比表面积吸附(占比 40%);化学消耗:金属界面化学吸附(15%)、高温裂解(5%)、细菌降…...

Projects-from-Scratch学习路径:如何系统性地掌握Web开发全栈技术
Projects-from-Scratch学习路径:如何系统性地掌握Web开发全栈技术 【免费下载链接】Projects-from-Scratch Read and do projects. 项目地址: https://gitcode.com/gh_mirrors/pr/Projects-from-Scratch Projects-from-Scratch是一个精心策划的开源项目列表&…...

八大网盘直链解析工具:高效跨平台文件下载全攻略
八大网盘直链解析工具:高效跨平台文件下载全攻略 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 …...

终极指南:3分钟掌握Switch游戏安装的完整解决方案
终极指南:3分钟掌握Switch游戏安装的完整解决方案 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer Awoo Installer是一款专为Nintendo S…...

nncase神经网络编译器:从PyTorch模型到K210边缘AI部署全流程详解
1. 项目概述:边缘AI推理的“翻译官”如果你正在嵌入式设备上折腾AI模型部署,大概率会遇到一个让人头疼的问题:辛辛苦苦在PC上训练好的模型,无论是TensorFlow的.pb还是PyTorch的.pth,到了资源捉襟见肘的K210、RV1109这类…...

3步搞定抖音资源下载:免费高效的douyin-downloader完整指南
3步搞定抖音资源下载:免费高效的douyin-downloader完整指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback …...