【YOLOX】用YOLOv5框架YOLOX
【YOLOX】用YOLOv5框架YOLOX
- 一、新建common_x.py
- 二、修改yolo.py
- 三、新建yolox.yaml
- 四、训练
最近在跑YOLO主流框架的对比实验,发现了一个很奇怪的问题,就是同一个数据集,在不同YOLO框架下训练出的结果差距竟然大的离谱。我使用ultralytics公司出品的v5、v3框架跑出的结果精度差距是合理的,然而用该Up主写的Yolov4代码,竟与ultralytics公司出品的v5、v3框架跑出的结果精度能低20-30%,帧率低的离谱。并且YOLOX也是一样结果。虽然不知道为什么,但确实无法进行对比实验,于是只能将Yolov4结构与YoloX结构在Yolov5框架中实现。Yolov4在Yolov5框架中的实现我参考了这个博主的博客,大家有需求可以参考:yolov4_u5版复现。是一系列文章。
下面我来实现将YoloX结构移植到Yolov5框架中,以下是结合网络结构以及YoloX源码进行实现:
一、新建common_x.py
该python文件存放的是YOLOX中用到的模块,主要包括BaseConv、CSPLayer、Dark,代码如下:
import torch
import torch.nn as nnclass SiLU(nn.Module):"""export-friendly version of nn.SiLU()"""@staticmethoddef forward(x):return x * torch.sigmoid(x)def get_activation(name="silu", inplace=True):if name == "silu":module = nn.SiLU(inplace=inplace)elif name == "relu":module = nn.ReLU(inplace=inplace)elif name == "lrelu":module = nn.LeakyReLU(0.1, inplace=inplace)else:raise AttributeError("Unsupported act type: {}".format(name))return moduleclass BaseConv(nn.Module):"""A Conv2d -> Batchnorm -> silu/leaky relu block"""def __init__(self, in_channels, out_channels, ksize, stride, groups=1, bias=False, act="silu"):super().__init__()# same paddingpad = (ksize - 1) // 2self.conv = nn.Conv2d(in_channels,out_channels,kernel_size=ksize,stride=stride,padding=pad,groups=groups,bias=bias,)self.bn = nn.BatchNorm2d(out_channels)self.act = get_activation(act, inplace=True)def forward(self, x):return self.act(self.bn(self.conv(x)))def fuseforward(self, x):return self.act(self.conv(x))class DWConv(nn.Module):"""Depthwise Conv + Conv"""def __init__(self, in_channels, out_channels, ksize, stride=1, act="silu"):super().__init__()self.dconv = BaseConv(in_channels,in_channels,ksize=ksize,stride=stride,groups=in_channels,act=act,)self.pconv = BaseConv(in_channels, out_channels, ksize=1, stride=1, groups=1, act=act)def forward(self, x):x = self.dconv(x)return self.pconv(x)class Bottleneck(nn.Module):# Standard bottleneckdef __init__(self,in_channels,out_channels,shortcut=True,expansion=0.5,depthwise=False,act="silu",):super().__init__()hidden_channels = int(out_channels * expansion)Conv = DWConv if depthwise else BaseConvself.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)self.conv2 = Conv(hidden_channels, out_channels, 3, stride=1, act=act)self.use_add = shortcut and in_channels == out_channelsdef forward(self, x):y = self.conv2(self.conv1(x))if self.use_add:y = y + xreturn yclass ResLayer(nn.Module):"Residual layer with `in_channels` inputs."def __init__(self, in_channels: int):super().__init__()mid_channels = in_channels // 2self.layer1 = BaseConv(in_channels, mid_channels, ksize=1, stride=1, act="lrelu")self.layer2 = BaseConv(mid_channels, in_channels, ksize=3, stride=1, act="lrelu")def forward(self, x):out = self.layer2(self.layer1(x))return x + outclass SPPBottleneck(nn.Module):"""Spatial pyramid pooling layer used in YOLOv3-SPP"""def __init__(self, in_channels, out_channels, kernel_sizes=(5, 9, 13), activation="silu"):super().__init__()hidden_channels = in_channels // 2self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=activation)self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=ks, stride=1, padding=ks // 2)for ks in kernel_sizes])conv2_channels = hidden_channels * (len(kernel_sizes) + 1)self.conv2 = BaseConv(conv2_channels, out_channels, 1, stride=1, act=activation)def forward(self, x):x = self.conv1(x)x = torch.cat([x] + [m(x) for m in self.m], dim=1)x = self.conv2(x)return xclass CSPLayer(nn.Module):"""C3 in yolov5, CSP Bottleneck with 3 convolutions"""def __init__(self,in_channels,out_channels,n=1,shortcut=True,expansion=0.5,depthwise=False,act="silu",):"""Args:in_channels (int): input channels.out_channels (int): output channels.n (int): number of Bottlenecks. Default value: 1."""# ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()hidden_channels = int(out_channels * expansion) # hidden channelsself.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)self.conv2 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)self.conv3 = BaseConv(2 * hidden_channels, out_channels, 1, stride=1, act=act)module_list = [Bottleneck(hidden_channels, hidden_channels, shortcut, 1.0, depthwise, act=act)for _ in range(n)]self.m = nn.Sequential(*module_list)def forward(self, x):x_1 = self.conv1(x)x_2 = self.conv2(x)x_1 = self.m(x_1)x = torch.cat((x_1, x_2), dim=1)return self.conv3(x)class Dark(nn.Module):def __init__(self, c1, c2, n=1, act="silu"):super().__init__()self.cv1 = BaseConv(c1, c2, 3, 2, act=act)self.cv2 = CSPLayer(c2, c2, n=n, depthwise=False, act=act)def forward(self, x):return self.cv2(self.cv1(x))二、修改yolo.py
由于YOLOX里面使用的是Decoupled Head解藕头,所以需要重新设计Detect部分,这里参考了这位博主的博客:YOLO v5 引入解耦头部。
这里有一个需要注意的点是:在 class DecoupledHead 当中的 self.gd=0.5 ,这个参数对应中间隐藏层的输出通道数,原博主这里默认的256,yolox源代码里面这里是乘了 width_multiple 用来控制宽度,因此为了同样实现 -s 模型,我把他乘了对应的系数 self.gd 其对应于 yaml 文件中的 width_multiple 参数控制实现yolox的不同版本。因此,如果想要实现 yolox 的 -m -x -l版本,修改yaml的 width_multiple 参数的时候,不要忘记改这里的 self.gd。 这里因为还得修改函数接口等,就暂时以这种形式实现,后续有时间把这修改一下。
将以下代码,放入yolo.py:
class DecoupledHead(nn.Module):def __init__(self, ch=256, nc=80, anchors=()):super().__init__()self.nc = nc # number of classes# 中间隐藏层的输出通道数比例self.gd = 0.5self.nl = len(anchors) # number of detection layersself.na = len(anchors[0]) // 2 # number of anchorsc_ = int(ch * self.gd)self.merge = Conv(ch, c_, 1, 1)self.cls_convs1 = Conv(c_, c_, 3, 1, 1)self.cls_convs2 = Conv(c_, c_, 3, 1, 1)self.reg_convs1 = Conv(c_, c_, 3, 1, 1)self.reg_convs2 = Conv(c_, c_, 3, 1, 1)self.cls_preds = nn.Conv2d(c_, self.nc * self.na, 1)self.reg_preds = nn.Conv2d(c_, 4 * self.na, 1)self.obj_preds = nn.Conv2d(c_, 1 * self.na, 1)def forward(self, x):x = self.merge(x)x1 = self.cls_convs1(x)x1 = self.cls_convs2(x1)x1 = self.cls_preds(x1)x2 = self.reg_convs1(x)x2 = self.reg_convs2(x2)x21 = self.reg_preds(x2)x22 = self.obj_preds(x2)out = torch.cat([x21, x22, x1], 1)return outclass Decoupled_Detect(nn.Module):stride = None # strides computed during buildonnx_dynamic = False # ONNX export parameterexport = False # export modedef __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layersuper().__init__()self.nc = nc # number of classesself.no = nc + 5 # number of outputs per anchorself.nl = len(anchors) # number of detection layersself.na = len(anchors[0]) // 2 # number of anchorsself.grid = [torch.zeros(1)] * self.nl # init gridself.anchor_grid = [torch.zeros(1)] * self.nl # init anchor gridself.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)self.m = nn.ModuleList(DecoupledHead(x, nc, anchors) for x in ch)self.inplace = inplace # use in-place ops (e.g. slice assignment)def forward(self, x):z = [] # inference outputfor i in range(self.nl):x[i] = self.m[i](x[i]) # convbs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()if not self.training: # inferenceif self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)y = x[i].sigmoid()if self.inplace:y[..., 0:2] = (y[..., 0:2] * 2 + self.grid[i]) * self.stride[i] # xyy[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # whelse: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953xy, wh, conf = y.split((2, 2, self.nc + 1), 4) # y.tensor_split((2, 4, 5), 4) # torch 1.8.0xy = (xy * 2 + self.grid[i]) * self.stride[i] # xywh = (wh * 2) ** 2 * self.anchor_grid[i] # why = torch.cat((xy, wh, conf), 4)z.append(y.view(bs, -1, self.no))return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)def _make_grid(self, nx=20, ny=20, i=0):d = self.anchors[i].devicet = self.anchors[i].dtypeshape = 1, self.na, ny, nx, 2 # grid shapey, x = torch.arange(ny, device=d, dtype=t), torch.arange(nx, device=d, dtype=t)if check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibilityyv, xv = torch.meshgrid(y, x, indexing='ij')else:yv, xv = torch.meshgrid(y, x)grid = torch.stack((xv, yv), 2).expand(shape) - 0.5 # add grid offset, i.e. y = 2.0 * x - 0.5anchor_grid = (self.anchors[i] * self.stride[i]).view((1, self.na, 1, 1, 2)).expand(shape)return grid, anchor_grid
修改yolo.py中的parse_model函数:
在下面添加BaseConv、CSPLayer、Dark模块
 添加Decoupled_Detect模块
添加Decoupled_Detect模块

三、新建yolox.yaml
新建yolox.yaml
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # expand model depth
width_multiple: 0.5 # expand layer channels# anchors
anchors:- [12,16, 19,36, 40,28] # P3/8- [36,75, 76,55, 72,146] # P4/16- [142,110, 192,243, 459,401] # P5/32# yolov4l backbone
backbone:# [from, number, module, args][[-1, 1, Focus, [64, 3, 1]], # 0[-1, 3, Dark, [128]], # 1-P1/2[-1, 9, Dark, [256]],[-1, 9, Dark, [512]], # 3-P2/4[-1, 3, Dark, [1024]],]# yolov4l head
# na = len(anchors[0])
head:[[-1, 1, BaseConv, [512, 1, 1]], # 11[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 3], 1, Concat, [1]],[-1, 3, CSPLayer, [512]], # 16[-1, 1, BaseConv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 2], 1, Concat, [1]],[-1, 3, CSPLayer, [256]], # 21[-1, 1, BaseConv, [256, 3, 2]],[[-1, 9], 1, Concat, [1]], # cat[-1, 3, CSPLayer, [512]], # 25[-1, 1, BaseConv, [512, 3, 2]], # route backbone P3[[-1, 5], 1, Concat, [1]], # cat[-1, 3, CSPLayer, [1024]], # 29[[12,15,18], 1, Decoupled_Detect, [nc, anchors]], # Detect(P3, P4, P5)]
四、训练
以上配置完之后,其他操作与训练Yolov5步骤一致,最终训练出来的效果,要比原YoloX训练结果好不少,看起来更加合理,与Yolov5训练结果差距也是在合理范围内。
相关文章:
【YOLOX】用YOLOv5框架YOLOX
【YOLOX】用YOLOv5框架YOLOX一、新建common_x.py二、修改yolo.py三、新建yolox.yaml四、训练最近在跑YOLO主流框架的对比实验,发现了一个很奇怪的问题,就是同一个数据集,在不同YOLO框架下训练出的结果差距竟然大的离谱。我使用ultralytics公司…...

【python机器学习实验】——逻辑回归与感知机进行线性分类,附可视化结果!
【python机器学习实验】——逻辑回归与感知机进行线性分类,附可视化结果! 下载链接 下载链接 下载链接 可视化效果图: 感知机模型结果为例: 首先,我们有训练数据和测试数据,其每一行为(x,y,label)的形式…...

wps删除的文件怎么恢复
在办公中,几乎每个人都会用到WPS办公软件。它可以帮助我们快速有效地处理各种Word文档、ppt幻灯片、excel表格等。但有文件就会有清理,如果我们不小心删除了wps文件呢?那些wps删除的文件怎么恢复?针对这种情况,小编为大家带来一些恢复WPS文…...
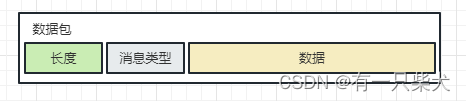
NIO消息黏包和半包处理
1、前言 我们在进行NIO编程时,通常会使用缓冲区进行消息的通信(ByteBuffer),而缓冲区的大小是固定的。那么除非你进行自动扩容(Netty就是这么处理的),否则的话,当你的消息存进该缓冲…...

day018 第六章 二叉树 part05
一、513.找树左下角的值 这个题目的主要思路是使用广度优先搜索(BFS)遍历整棵树,最后返回最后一层的最左边的节点的值。具体的实现可以使用队列来存储每一层的节点,并且在遍历每一层节点时,不断更新最左边的节点的值。…...
如何下载ChatGPT-ChatGPT如何写作
CHATGPT能否改一下文章 ChatGPT 作为一种自然语言处理技术,生成的文章可能存在表达不够准确或文风不符合要求等问题。在这种情况下,可以使用编辑和修改来改变输出的文章,使其符合特定的要求和期望。 具体来说,可以采用以下步骤对…...

微策略再次买入
原创:刘教链* * *隔夜,比特币再次小幅回升至28k上方。微策略(Microstrategy)创始人Michael Saylor发推表示,微策略再次出手,买入1045枚比特币。此次买入大概花费2930万美元,平均加仓成本28016美…...

express框架
Express 是基于 Node.js 平台,快速、开放、极简的 Web 开发框架. 创建一个基本的express web服务器 // 1.导入express const express require(express); // 2.创建web服务器 const app express(); // 3.启动web服务器 app.listen(80, ()>{console.log(expres…...

完蛋的goals
...

Javase学习文档------面象对象初探
引入面向对象 面向对象的由来: 面向对象编程(Object-Oriented Programming, OOP)是一种编程范型,其由来可以追溯到20世纪60年代。在此之前,主流编程语言采用的是“过程化编程”模式,即面向过程编程模式。在这种模式下&…...

ChatGPT能够干翻谷歌吗?
目前大多数人对于ChatGPT的喜爱,主要源自于其强大的沟通能力,当我们向ChatGPT提出问题时,它不仅能够为我们提供结论,而且还能够与我们建立沟通,向ChatGPT提出任何问题,感觉都像是在与一个真实的人类进行交谈…...

PCL 使用点云创建数字高程模型DEM
目录 一、DEM1、数字高程模型二、代码实现三、结果展示1、点云2、DEM四、相关链接一、DEM 1、数字高程模型 数字高程模型(Digital Elevation Model),简称DEM,是通过有限的地形高程数据实现对地面地形的数字化模拟(即地形表面形态的数字化表达),它是用一组有序数值阵列形…...
我体验了首个接入GPT-4的代码编辑器,太炸裂了
最近一款名为Cursor的代码编辑器已经传遍了圈内,受到众多编程爱好者的追捧。 它主打的亮点就是,通过 GPT-4 来辅助你编程,完成 AI 智能生成代码、修改 Bug、生成测试等操作。 确实很吸引人,而且貌似也能大大节省人为的重复工作&…...
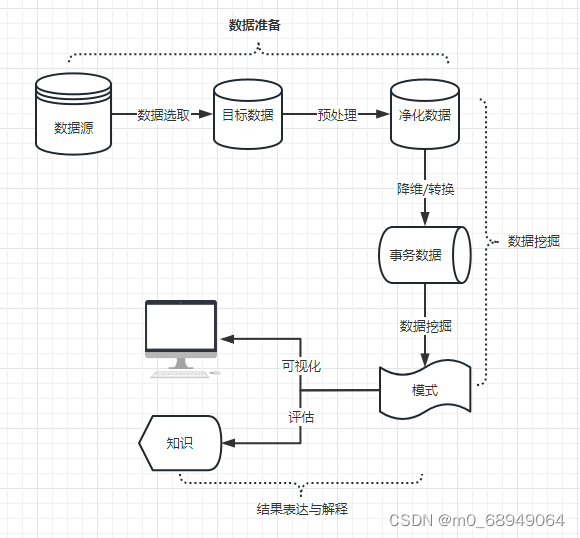
互联网数据挖掘与分析讲解
一、定义 数据挖掘(英语:Data mining),又译为资料探勘、数据采矿。它是数据库知识发现(英语:Knowledge-Discovery in Databases,简称:KDD)中的一个步骤。数据挖掘一般是指从大量的数…...

linux之cut的使用
cut是一个选取命令,就是将一段数据经过分析,取出我们想要的。一般来说,选取信息通常是针对“行”来进行分析的,并不是整篇信息分析的 其语法格式为: cut [-bn] [file] 或 cut [-c][file] 或 cut [-df] [file]使用说明:…...
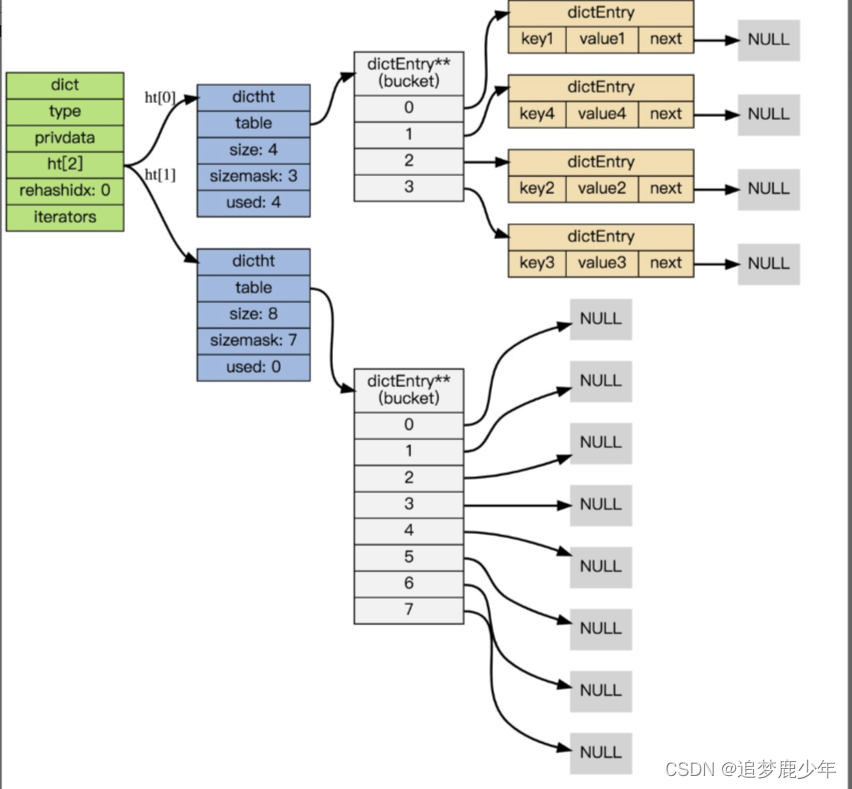
Redis第十讲 Redis之Hash数据结构Dict-rehash扩容操作
Rehash 执行过程 字典的 rehash 操作实际上就是执行以下任务: 创建一个比 ht[0]->table 更大的 ht[1]->table ;将 ht[0]->table 中的所有键值对迁移到 ht[1]->table ;将原有 ht[0] 的数据清空,并将 ht[1] 替换为新的 ht[0] ; 经过以上步骤之后, 程序就在不改…...
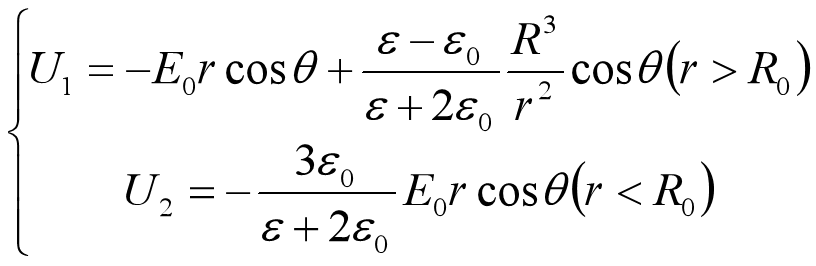
电动力学问题中的Matlab可视化
电磁场的经典描述 小说一则 电磁场的经典描述就是没有啥玩意量子力学的经典电动力学下对电磁场的描述,以后有空写个科幻小说,写啥呢,就写有天张三遇见了一个外星人,外星人来自这样一个星球,星球上的物质密度特别低,导致外星人的测量会明显的影响物质的运动,外星人不能同时得到…...

云原生周刊:编程即将终结?
近日哈佛大学计算机科学的前教授 Matt Welsh,分享了他对计算机科学、分布式计算的未来以及 ChatGPT 和 GitHub Copilot 是否代表编程结束的开始的看法。 威尔士说,编程语言仍然很复杂。再多的工作也无法让它变得简单。 “在我看来,任何改进…...

C++ STL,resize 和 reserve 的区别
结论放前边:resize和reserve都可以给容器扩容,区别在于resize会进行填充,使容器处于满员的状态,即sizecapacity,而reserve不会填充,有size<capacity. 1. size 和 capacity 的区别 size和capacity是容器…...

Java——详解ReentrantLock与AQS的关联以及AQS的数据结构和同步状态State
前言 Java中大部分同步类(Lock、Semaphore、ReentrantLock等)都是基于AbstractQueuedSynchronizer(简称为 AQS)实现的。 AQS 是一种提供了原子式管理同步状态、阻塞和唤醒线程功能以及队列模型的简单框架。 本文会先介绍应用层&a…...

FPGA静态侧信道攻击防御与传感器绕过技术解析
1. FPGA安全防御机制与静态侧信道攻击概述在现代数字安全领域,现场可编程门阵列(FPGA)因其可重构性和高性能特性,已成为加密加速、信号处理等关键应用的核心组件。然而,FPGA面临的物理安全威胁与日俱增,特别是针对硬件的侧信道攻击…...

终极Elsevier审稿追踪指南:5分钟实现智能投稿监控的完整方案
终极Elsevier审稿追踪指南:5分钟实现智能投稿监控的完整方案 【免费下载链接】Elsevier-Tracker 项目地址: https://gitcode.com/gh_mirrors/el/Elsevier-Tracker 还在为Elsevier期刊投稿后的漫长等待而焦虑吗?每天反复登录系统查看审稿进度&…...
)
告别云台乱晃!手把手教你用Arduino+SG90舵机实现‘鸡头稳定’效果(附PID模拟器使用心得)
从鸡头稳定到智能云台:ArduinoPID算法实战指南 你是否注意过鸡在行走时头部能保持惊人的稳定?这种被称为"鸡头稳定"的生物现象,启发了工程师们设计出能自动补偿晃动的智能云台系统。本文将带你用Arduino、SG90舵机和MPU6050传感器&…...

从官方例程到实战:剖析lwip+FreeRTOS在Zynq7020上的TCP热拔插实现与任务调度优化
1. 官方例程热拔插实现机制拆解 第一次在Zynq7020上看到TCP热拔插功能时,确实让我这个老嵌入式工程师也眼前一亮。官方例程里那个看似简单的link_detect_thread任务,实际上藏着不少精妙设计。我们先从PHY芯片的状态检测说起——这个看似基础的操作&#…...

【NotebookLM林业科研提效指南】:3大AI笔记工作流重构传统林学研究范式
更多请点击: https://codechina.net 第一章:NotebookLM林业科学研究 NotebookLM 是 Google 推出的基于 AI 的研究协作者工具,专为文献理解与知识整合设计。在林业科学研究中,它可高效处理林学专著、野外调查报告、遥感解译文档、…...
)
【免费下载】 AD7124中文手册(非常完整)
AD7124中文手册(非常完整) 【下载地址】AD7124中文手册非常完整 AD7124-8是一款高性能模拟前端,设计用于在各种苛刻环境中实现精确的数据采集。这款芯片的特点在于其内置的高精度24位Σ-Δ模数转换器(ADC),能够灵活配置以支持8个差…...

Discourse Docker持续集成:自动化构建与部署完整指南 [特殊字符]
Discourse Docker持续集成:自动化构建与部署完整指南 🚀 【免费下载链接】discourse_docker A Docker image for Discourse 项目地址: https://gitcode.com/gh_mirrors/dis/discourse_docker Discourse Docker持续集成是现代论坛部署的最佳实践&a…...
)
避坑指南:Tina Linux下MIPI DSI与LVDS屏调试的那些‘坑’(以V853/D1s为例)
Tina Linux下MIPI DSI与LVDS屏调试实战避坑指南(V853/D1s开发板为例) 1. 高速差分接口调试的"死亡陷阱" 当V853开发板首次连接那块7英寸MIPI屏时,我遭遇了职业生涯最诡异的显示故障——屏幕上半部正常显示,下半部却呈现…...

解放Windows潜能:APK安装器让安卓应用在电脑上完美运行
解放Windows潜能:APK安装器让安卓应用在电脑上完美运行 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾梦想过在Windows电脑上直接运行手机应用&am…...

基于GeoDa与R语言的空间数据回归实践技术应用
空间数据是常见的数据形式之一,因此空间数据回归也是最常用的方法之一。由于空间数据之间往往有相关性,它们不满足经典统计学的数据独立性假设,所以回归的理论和建模方式与普通回归模型相比既陌生又复杂。GeoDa与R语言是建立空间回归模型最合…...