【深度强化学习】(5) DDPG 模型解析,附Pytorch完整代码
大家好,今天和各位分享一下深度确定性策略梯度算法 (Deterministic Policy Gradient,DDPG)。并基于 OpenAI 的 gym 环境完成一个小游戏。完整代码在我的 GitHub 中获得:
https://github.com/LiSir-HIT/Reinforcement-Learning/tree/main/Model
1. 基本原理
深度确定性策略梯度算法是结合确定性策略梯度算法的思想,对 DQN 的一种改进,是一种无模型的深度强化学习算法。
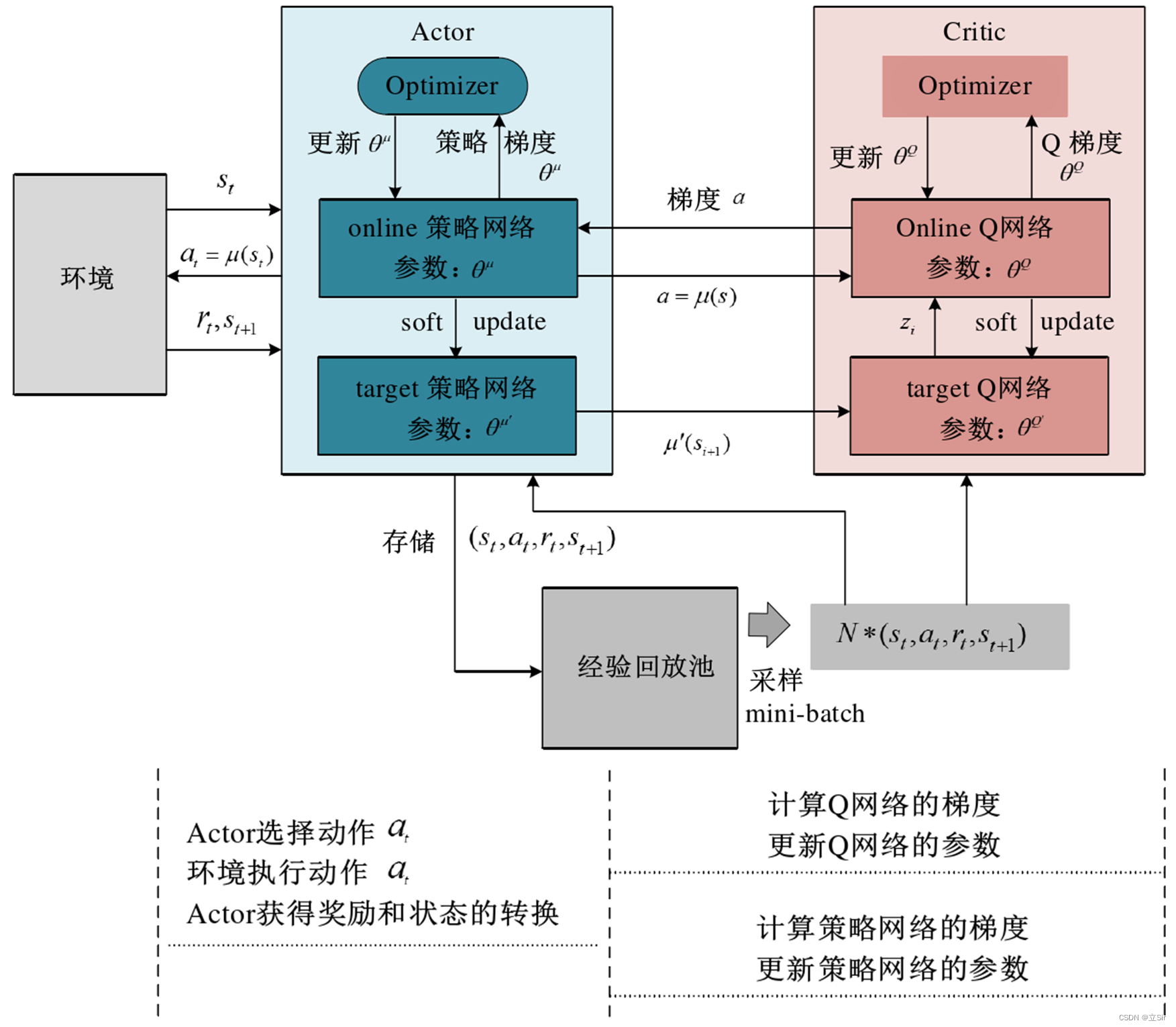
DDPG 算法使用演员-评论家(Actor-Critic)算法作为其基本框架,采用深度神经网络作为策略网络和动作值函数的近似,使用随机梯度法训练策略网络和价值网络模型中的参数。DDPG 算法的原理如下图所示。
DDPG 算法架构中使用双重神经网络架构,对于策略函数和价值函数均使用双重神经网络模型架构(即 Online 网络和 Target 网络),使得算法的学习过程更加稳定,收敛的速度加快。同时该算法引入经验回放机制,Actor 与环境交互生产生的经验数据样本存储到经验池中,抽取批量数据样本进行训练,即类似于 DQN 的经验回放机制,去除样本的相关性和依赖性,使得算法更加容易收敛。
2. 公式推导
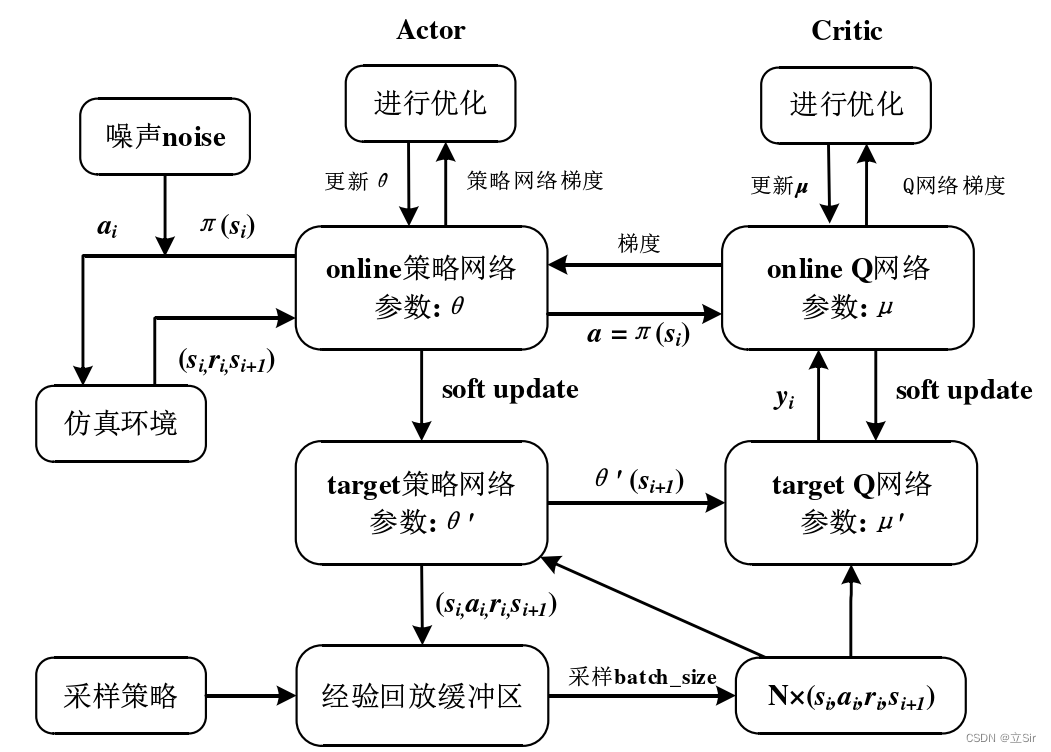
为了便于大家理解 DDPG 的推导过程,算法框架如下图所示:

DDPG 共包含 4 个神经网络,用于对 Q 值函数和策略的近似表示。Critic 目标网络用于近似估计下一时刻的状态-动作的 Q 值函数 ,其中,下一动作值是通过 Actor 目标网络近似估计得到的
。于是可以得到当前状态下 Q 值函数的目标值:
Critic 训练网络输出当前时刻状态-动作的 Q 值函数 ,用于对当前策略评价。为了增加智能体在环境中的探索,DDPG 在行为策略上添加了高斯噪声函数。Critic 网络的目标定义为:
通过最小化损失值(均方误差损失)来更新 Critic 网络的参数,Critic 网络更新时的损失函数为:
其中,,
代表行为策略上的探索噪声。
Actor 目标网络用于提供下一个状态的策略,Actor 训练网络则是提供当前状态的策略,结合 Critic 训练网络的 Q 值函数可以得到 Actor 在参数更新时的策略梯度:
对于目标网络参数 和
的更新,DDPG 通过软更新机制(每次 learn 的时候更新部分参数)保证参数可以缓慢更新,从而提高学习的稳定性:
DDPG 中既有基于价值函数的方法特征,也有基于策略的方法特征,使深度强化学习可以处理连续动作,并且具有一定的探索能力。
算法流程图如下:
3. 代码实现
DDPG 的伪代码如下:

模型代码如下:
import torch
from torch import nn
from torch.nn import functional as F
import numpy as np
import collections
import random# ------------------------------------- #
# 经验回放池
# ------------------------------------- #class ReplayBuffer:def __init__(self, capacity): # 经验池的最大容量# 创建一个队列,先进先出self.buffer = collections.deque(maxlen=capacity)# 在队列中添加数据def add(self, state, action, reward, next_state, done):# 以list类型保存self.buffer.append((state, action, reward, next_state, done))# 在队列中随机取样batch_size组数据def sample(self, batch_size):transitions = random.sample(self.buffer, batch_size)# 将数据集拆分开来state, action, reward, next_state, done = zip(*transitions)return np.array(state), action, reward, np.array(next_state), done# 测量当前时刻的队列长度def size(self):return len(self.buffer)# ------------------------------------- #
# 策略网络
# ------------------------------------- #class PolicyNet(nn.Module):def __init__(self, n_states, n_hiddens, n_actions, action_bound):super(PolicyNet, self).__init__()# 环境可以接受的动作最大值self.action_bound = action_bound# 只包含一个隐含层self.fc1 = nn.Linear(n_states, n_hiddens)self.fc2 = nn.Linear(n_hiddens, n_actions)# 前向传播def forward(self, x):x = self.fc1(x) # [b,n_states]-->[b,n_hiddens]x = F.relu(x)x = self.fc2(x) # [b,n_hiddens]-->[b,n_actions]x= torch.tanh(x) # 将数值调整到 [-1,1]x = x * self.action_bound # 缩放到 [-action_bound, action_bound]return x# ------------------------------------- #
# 价值网络
# ------------------------------------- #class QValueNet(nn.Module):def __init__(self, n_states, n_hiddens, n_actions):super(QValueNet, self).__init__()# self.fc1 = nn.Linear(n_states + n_actions, n_hiddens)self.fc2 = nn.Linear(n_hiddens, n_hiddens)self.fc3 = nn.Linear(n_hiddens, 1)# 前向传播def forward(self, x, a):# 拼接状态和动作cat = torch.cat([x, a], dim=1) # [b, n_states + n_actions]x = self.fc1(cat) # -->[b, n_hiddens]x = F.relu(x)x = self.fc2(x) # -->[b, n_hiddens]x = F.relu(x)x = self.fc3(x) # -->[b, 1]return x# ------------------------------------- #
# 算法主体
# ------------------------------------- #class DDPG:def __init__(self, n_states, n_hiddens, n_actions, action_bound,sigma, actor_lr, critic_lr, tau, gamma, device):# 策略网络--训练self.actor = PolicyNet(n_states, n_hiddens, n_actions, action_bound).to(device)# 价值网络--训练self.critic = QValueNet(n_states, n_hiddens, n_actions).to(device)# 策略网络--目标self.target_actor = PolicyNet(n_states, n_hiddens, n_actions, action_bound).to(device)# 价值网络--目标self.target_critic = QValueNet(n_states, n_hiddens, n_actions).to(device)# 初始化价值网络的参数,两个价值网络的参数相同self.target_critic.load_state_dict(self.critic.state_dict())# 初始化策略网络的参数,两个策略网络的参数相同self.target_actor.load_state_dict(self.actor.state_dict())# 策略网络的优化器self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=actor_lr)# 价值网络的优化器self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=critic_lr)# 属性分配self.gamma = gamma # 折扣因子self.sigma = sigma # 高斯噪声的标准差,均值设为0self.tau = tau # 目标网络的软更新参数self.n_actions = n_actionsself.device = device# 动作选择def take_action(self, state):# 维度变换 list[n_states]-->tensor[1,n_states]-->gpustate = torch.tensor(state, dtype=torch.float).view(1,-1).to(self.device)# 策略网络计算出当前状态下的动作价值 [1,n_states]-->[1,1]-->intaction = self.actor(state).item()# 给动作添加噪声,增加搜索action = action + self.sigma * np.random.randn(self.n_actions)return action# 软更新, 意思是每次learn的时候更新部分参数def soft_update(self, net, target_net):# 获取训练网络和目标网络需要更新的参数for param_target, param in zip(target_net.parameters(), net.parameters()):# 训练网络的参数更新要综合考虑目标网络和训练网络param_target.data.copy_(param_target.data*(1-self.tau) + param.data*self.tau)# 训练def update(self, transition_dict):# 从训练集中取出数据states = torch.tensor(transition_dict['states'], dtype=torch.float).to(self.device) # [b,n_states]actions = torch.tensor(transition_dict['actions'], dtype=torch.float).view(-1,1).to(self.device) # [b,1]rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1,1).to(self.device) # [b,1]next_states = torch.tensor(transition_dict['next_states'], dtype=torch.float).to(self.device) # [b,next_states]dones = torch.tensor(transition_dict['dones'], dtype=torch.float).view(-1,1).to(self.device) # [b,1]# 价值目标网络获取下一时刻的动作[b,n_states]-->[b,n_actors]next_q_values = self.target_actor(next_states)# 策略目标网络获取下一时刻状态选出的动作价值 [b,n_states+n_actions]-->[b,1]next_q_values = self.target_critic(next_states, next_q_values)# 当前时刻的动作价值的目标值 [b,1]q_targets = rewards + self.gamma * next_q_values * (1-dones)# 当前时刻动作价值的预测值 [b,n_states+n_actions]-->[b,1]q_values = self.critic(states, actions)# 预测值和目标值之间的均方差损失critic_loss = torch.mean(F.mse_loss(q_values, q_targets))# 价值网络梯度self.critic_optimizer.zero_grad()critic_loss.backward()self.critic_optimizer.step()# 当前状态的每个动作的价值 [b, n_actions]actor_q_values = self.actor(states)# 当前状态选出的动作价值 [b,1]score = self.critic(states, actor_q_values)# 计算损失actor_loss = -torch.mean(score)# 策略网络梯度self.actor_optimizer.zero_grad()actor_loss.backward()self.actor_optimizer.step()# 软更新策略网络的参数 self.soft_update(self.actor, self.target_actor)# 软更新价值网络的参数self.soft_update(self.critic, self.target_critic)4. 案例演示
基于 OpenAI 的 gym 环境完成一个推车游戏,目标是将小车推到山顶旗子处。动作维度为1,属于连续值;状态维度为 2,分别是 x 坐标和小车速度。
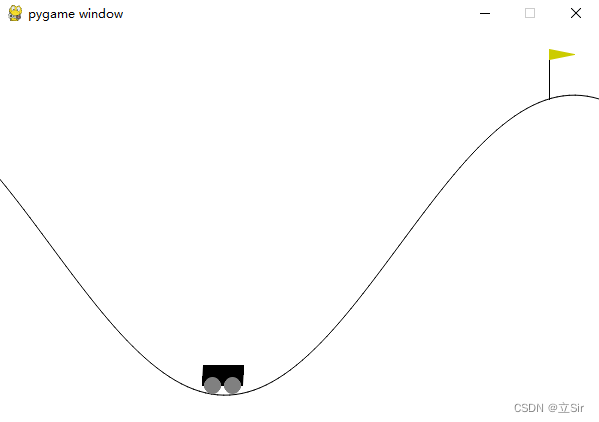

代码如下:
import numpy as np
import torch
import matplotlib.pyplot as plt
import gym
from parsers import args
from RL_brain import ReplayBuffer, DDPG
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')# -------------------------------------- #
# 环境加载
# -------------------------------------- #env_name = "MountainCarContinuous-v0" # 连续型动作
env = gym.make(env_name, render_mode="human")
n_states = env.observation_space.shape[0] # 状态数 2
n_actions = env.action_space.shape[0] # 动作数 1
action_bound = env.action_space.high[0] # 动作的最大值 1.0# -------------------------------------- #
# 模型构建
# -------------------------------------- ## 经验回放池实例化
replay_buffer = ReplayBuffer(capacity=args.buffer_size)
# 模型实例化
agent = DDPG(n_states = n_states, # 状态数n_hiddens = args.n_hiddens, # 隐含层数n_actions = n_actions, # 动作数action_bound = action_bound, # 动作最大值sigma = args.sigma, # 高斯噪声actor_lr = args.actor_lr, # 策略网络学习率critic_lr = args.critic_lr, # 价值网络学习率tau = args.tau, # 软更新系数gamma = args.gamma, # 折扣因子device = device)# -------------------------------------- #
# 模型训练
# -------------------------------------- #return_list = [] # 记录每个回合的return
mean_return_list = [] # 记录每个回合的return均值for i in range(10): # 迭代10回合episode_return = 0 # 累计每条链上的rewardstate = env.reset()[0] # 初始时的状态done = False # 回合结束标记while not done:# 获取当前状态对应的动作action = agent.take_action(state)# 环境更新next_state, reward, done, _, _ = env.step(action)# 更新经验回放池replay_buffer.add(state, action, reward, next_state, done)# 状态更新state = next_state# 累计每一步的rewardepisode_return += reward# 如果经验池超过容量,开始训练if replay_buffer.size() > args.min_size:# 经验池随机采样batch_size组s, a, r, ns, d = replay_buffer.sample(args.batch_size)# 构造数据集transition_dict = {'states': s,'actions': a,'rewards': r,'next_states': ns,'dones': d,}# 模型训练agent.update(transition_dict)# 保存每一个回合的回报return_list.append(episode_return)mean_return_list.append(np.mean(return_list[-10:])) # 平滑# 打印回合信息print(f'iter:{i}, return:{episode_return}, mean_return:{np.mean(return_list[-10:])}')# 关闭动画窗格
env.close()# -------------------------------------- #
# 绘图
# -------------------------------------- #x_range = list(range(len(return_list)))plt.subplot(121)
plt.plot(x_range, return_list) # 每个回合return
plt.xlabel('episode')
plt.ylabel('return')
plt.subplot(122)
plt.plot(x_range, mean_return_list) # 每回合return均值
plt.xlabel('episode')
plt.ylabel('mean_return')相关文章:
【深度强化学习】(5) DDPG 模型解析,附Pytorch完整代码
大家好,今天和各位分享一下深度确定性策略梯度算法 (Deterministic Policy Gradient,DDPG)。并基于 OpenAI 的 gym 环境完成一个小游戏。完整代码在我的 GitHub 中获得: https://github.com/LiSir-HIT/Reinforcement-Learning/tree/main/Mod…...

unity,Color.Lerp函数
介绍 Color.Lerp函数是Unity引擎中的一个静态函数,用于在两个颜色值之间进行线性插值,从而实现颜色渐变效果 方法 Color.Lerp函数是Unity引擎中的一个静态函数,用于在两个颜色值之间进行线性插值,从而实现颜色渐变效果。该函数的…...
洛谷P8799 [蓝桥杯 2022 国 B] 齿轮 C语言/C++
[蓝桥杯 2022 国 B] 齿轮 题目描述 这天,小明在组装齿轮。 他一共有 nnn 个齿轮,第 iii 个齿轮的半径为 rir_{i}ri, 他需要把这 nnn 个齿轮按一定顺序从左到右组装起来,这样最左边的齿轮转起来之后,可以传递到最右边的齿轮&a…...

景区在线售票系统功能开发介绍
目前游客线上订票已经普及,景区开通线上购票渠道,方便游客购票,对于还没有开通线上购票的景区来说,需要提前了解一下景区线上售票系统的一些功能,下面给大家详细介绍一下景区在线售票需要哪些功能。 1、在线售票 包含门…...

webService的底层调用方式
webservice中采用协议Http,是指什么意思 WebService使用的是 SOAP (Simple Object Access Protocol)协议 Soap协议只是用来封装消息用的。封装后的消息你可以通过各种已有的协议来传输,比如http,tcp/ip,smtp,等等,你甚至还一次用自定义的协议…...
关于文件的一些小知识下
🍍个人主页🍍:🔜勇敢的小牛儿🚩 🔱推荐专栏🔱:C语言知识点 ⚠️座右铭⚠️:敢于尝试才有机会 🐒今日鸡汤🐒: 你受的苦 吃的亏 担的责 扛的罪 忍的…...

使用Cheat Engine与DnSpy破解Unity游戏
题目连接: https://play.picoctf.org/practice/challenge/361?originalEvent72&page3我们是windows系统,所以点击windows game下载游戏 双击运行pico.exe 屏幕上方的一串英文是叫我们找flag,我在这个小地图里走来走去也没flagÿ…...
溯源取证-内存取证基础篇
使用工具: volatility_2.6_lin64_standalone 镜像文件: CYBERDEF-567078-20230213-171333.raw 使用环境: kali linux 2022.02 我们只有一个RAW映像文件,如何从该映像文件中提取出我们想要的东西呢? 1.Which volatili…...
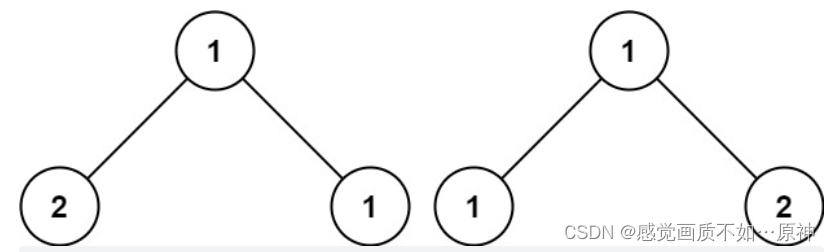
Leetcode.100 相同的树
题目链接 Leetcode.100 相同的树 easy 题目描述 给你两棵二叉树的根节点 p和 q,编写一个函数来检验这两棵树是否相同。 如果两个树在结构上相同,并且节点具有相同的值,则认为它们是相同的。 示例 1: 输入:p [1,2,3…...

每个程序员都应该知道的8大算法
在编程开发中,算法是用于解决特定问题或完成特定任务的一组指令或过程。算法可以用任何编程语言表示,可以像一系列基本操作一样简单,也可以像涉及不同数据结构和逻辑的多步骤过程一样复杂。 算法的主要目标是接收输入、处理它并提供预期的输…...
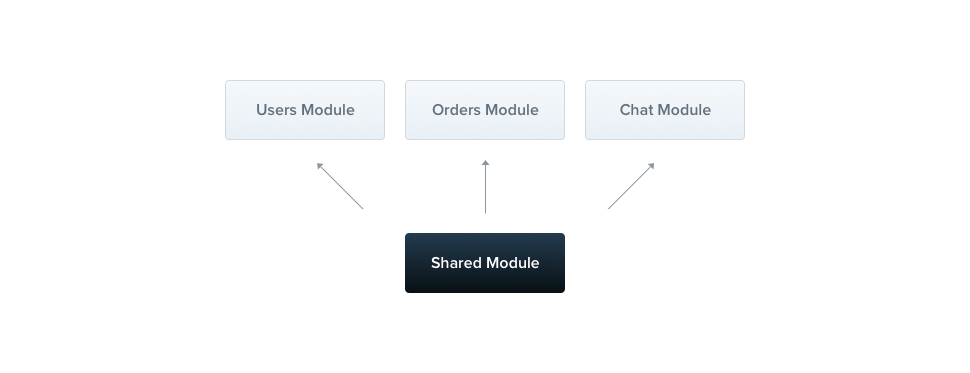
Nestjs实战超干货-概况-模块-Modules
模块 模块就是一个声明了装饰器Module()的类。装饰器Module()提供了元数据,以便让Nest组织应用程序结构。 每个应用程序至少有一个模块,即根模块。根模块是 Nest 用来构建应用程序图的起点,应用程序图是 Nest 用来解析模块和提供者关系和依赖…...

template
模板 模板注意事项 模板的函数体和声明一定要在一起,即放在同一个.h文件中,而不能将其分开到cpp和h文件中模板的编译技巧就是尽量多编译,模板很难查找错误模板的报错一般只有第一行有作用模板指定类型从左到右依次指定 模板推导 #pragma #…...
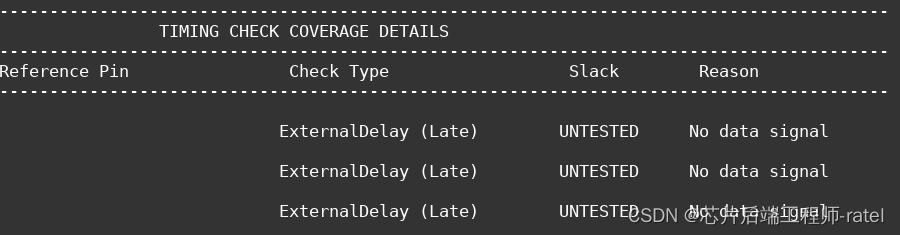
innovus中时序路径debug及命令使用详解?
写在前面:发现place结果所有与outport相关的timing check都找不到? 刚开始怀疑是sdc约束问题,check了input sdc文件及enc.dat/mmmc/mode/func.sdc 看一下是否设置了set_false_path.当然也可以用命令报出来: report_timing -unconstrained …...

C语言爱心代码大全集—会Ctrl+C就可以表白了
一、C语言爱心代码大全,会CtrlC就可以表白了! 博主整理了一个C语言爱心代码大全,里面有C语言爱心代码会动的动态效果和C语言爱心代码大全静态效果,只需复制粘贴就可以用啦! 1、动态C语言爱心代码效果图如下ÿ…...
python+vue+django耕地信息管理系统的设计与实现
基普通用户模块含有个人中心、耕地信息管理、转让许可申请管理、租赁许可申请管理等功能;普通管理员模块含有个人中心、用户管理、公示公告管理、耕地信息管理、耕地信息统计、转让许可申请管理、租赁许可申请管理、转让协议管理、租赁协议管理等功能;管…...
【云原生】Dockerfile制作WordPress镜像,实现compose编排部署
文章目录👹 关于作者前言环境准备目录结构dockerfile制作镜像yum 脚本Dockerfile-mariadb 镜像Dockerfile-service 镜像docker compose 编排提升✊ 最后👹 关于作者 大家好,我是秋意临。 😈 CSDN作者主页 😎 博客主页…...

五款好用又有趣的WIN10软件推荐
如果你想让你的电脑使用更方便、更有趣、更专业,那么你一定要看看这篇文章,因为我要给你推荐五款好用又有趣的WIN10软件 1.全局搜索——火柴 火柴是一款全局搜索软件,可以让你快速找到你想要的文件、程序、网页等,只需按下AltSp…...

朴素贝叶斯算法
# -*-coding:utf-8-*- """ Author: sunchang Desc: 代码4-7 朴素贝叶斯实现对异常账户检测 """ import numpy as np class NaiveBayesian: def __init__(self, alpha): self.classP dict() self.classP_f…...

【常见CSS扫盲雪碧图】从源码细看CSS雪碧图原理及实现,千字详解【附源码demo下载】
【写在前面】其实估计很多人都听过雪碧图,或者是CSS-Sprite,在很多门户网站就会经常有用到的,之所有引出雪碧图这个概念还得从前端加载多个图片时候页面闪了一下说起,这样给人的视觉效果体验很差,也就借此机会和大家说…...

Java多线程:ThreadLocal源码剖析
ThreadLocal源码剖析 ThreadLocal其实比较简单,因为类里就三个public方法:set(T value)、get()、remove()。先剖析源码清楚地知道ThreadLocal是干什么用的、再使用、最后总结,讲解ThreadLocal采取这样的思路。 三个理论基础 在剖析ThreadLo…...

OctoBase源码解析:深入理解Rust实现的本地优先数据库引擎 [特殊字符]
OctoBase源码解析:深入理解Rust实现的本地优先数据库引擎 🐙 【免费下载链接】OctoBase 🐙 OctoBase is the open-source database behind AFFiNE, local-first, yet collaborative. A light-weight, scalable, data engine written in Rust.…...
)
【更新至2025年】2001-2025年上市公司年报文本数据(txt格式)
【更新至2025年】2001-2025年上市公司年报文本数据(txt格式) 1、时间:2001-2025年 2、来源:巨潮资讯网 3、范围:A股上市公司 4、样本量:共7.2W份 5、说明:上市公司年报文本数据可以挖掘文本…...

Adafruit Metro ESP32-S3开发板深度评测:从硬件解析到低功耗物联网实践
1. 项目概述:为什么选择Metro ESP32-S3作为你的下一个开发平台?如果你正在寻找一块既能快速原型开发,又能直接用于产品部署,同时兼顾了强大无线连接、丰富生态和极低功耗的开发板,那么Adafruit Metro ESP32-S3绝对是一…...

从零构建AI智能体:核心架构、ReAct模式与实战指南
1. 项目概述:从零构建AI智能体的核心价值最近在GitHub上看到一个挺有意思的项目,叫pguso/ai-agents-from-scratch。光看名字,很多朋友可能就心动了——“从零开始构建AI智能体”,听起来就像是把那些神秘的大模型应用开发黑盒给彻底…...

Obsidian Quiz Generator:用AI与间隔重复打造动态知识库
1. 项目概述:当笔记遇上主动回忆如果你和我一样,是 Obsidian 的用户,并且对知识管理、学习效率有追求,那么你一定遇到过这个困境:笔记越记越多,知识库越来越庞大,但真正能“记住”并“调用”的知…...

数字电路模块化设计的艺术:Logisim-evolution中的层次化抽象实践
数字电路模块化设计的艺术:Logisim-evolution中的层次化抽象实践 【免费下载链接】logisim-evolution Digital logic design tool and simulator 项目地址: https://gitcode.com/gh_mirrors/lo/logisim-evolution 在数字电路设计的世界里,复杂系统…...

设计师核心能力框架:从思维策略到工程落地的系统化成长路径
1. 项目概述:一个设计师的“内功”修炼场如果你是一名设计师,或者对设计工作感兴趣,那么你一定有过这样的时刻:面对一个设计任务,脑子里有无数想法,但打开软件却不知从何下手;或者看到别人的优秀…...
)
【绝密级】航天科研院所NotebookLM部署红线清单:绕过敏感数据泄露风险的6层沙箱隔离架构(附工信部备案编号参考)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM航天科学研究 NotebookLM 是 Google 推出的基于 AI 的研究协作者工具,其核心能力在于对用户上传的私有文档进行深度语义理解与上下文关联推理。在航天科学研究场景中,…...

古星图导航测试:波利尼西亚航海术的AI复现
跨越千年的航海智慧与现代测试的碰撞在科技高度发达的今天,GPS、北斗等卫星导航系统已成为我们出行、航海、航空等领域不可或缺的工具。然而,在数千年前,太平洋上的波利尼西亚人却凭借着对星空的深刻理解和独特的航海技术,在广袤无…...

开发上下文管理工具:原理、实现与工程实践
1. 项目概述:一个为开发者量身定制的上下文管理工具如果你和我一样,每天要在多个项目、多种技术栈、甚至多个开发环境之间反复横跳,那你一定对“上下文切换”这个词深恶痛绝。我说的不是操作系统的上下文切换,而是我们开发者大脑里…...