朴素贝叶斯算法
# -*-coding:utf-8-*-
"""
Author: sunchang
Desc:
代码4-7 朴素贝叶斯实现对异常账户检测
"""
import numpy as np
class NaiveBayesian:
def __init__(self, alpha):
self.classP = dict()
self.classP_feature = dict()
self.alpha = alpha # 平滑值
# 加载数据集
def createData(self):
data = np.array(
[
[320, 204, 198, 265],
[253, 53, 15, 2243],
[53, 32, 5, 325],
[63, 50, 42, 98],
[1302, 523, 202, 5430],
[32, 22, 5, 143],
[105, 85, 70, 322],
[872, 730, 840, 2762],
[16, 15, 13, 52],
[92, 70, 21, 693],
]
)
labels = np.array([1, 0, 0, 1, 0, 0, 1, 1, 1, 0])#是否是异常用户的标签(1:异常 0:正常)
return data, labels
# 计算高斯分布函数值
#求P(xi|yk)
def gaussian(self, mu, sigma, x):
return 1.0 / (sigma * np.sqrt(2 * np.pi)) * np.exp(-(x - mu) ** 2 / (2 * sigma ** 2))
# 计算某个特征列对应的均值和标准差
def calMuAndSigma(self, feature):
mu = np.mean(feature)
sigma = np.std(feature) # np.var()方差 np.std()标准差
return (mu, sigma)
# 训练朴素贝叶斯算法模型
def train(self, data, labels):
numData = len(labels) #样本个数
numFeaturs = len(data[0]) #X维度个数
# 是异常用户的概率
#p(y1)
self.classP[1] = (
(sum(labels) + self.alpha) * 1.0 / (numData + self.alpha * len(set(labels)))#创建一个无序不重复元素集,删除重复数据
)
# 不是异常用户的概率
#Py(0)
self.classP[0] = 1 - self.classP[1]
# 用来存放每个label下每个特征标签下对应的高斯分布中的均值和方差
# { label1:{ feature1:{ mean:0.2, var:0.8 }, feature2:{} }, label2:{...} }
#{0: {0: (346.4, 484.05479028721527), 1: (140.0, 192.22174694867383), 2: (49.6, 76.44501291778293), 3: (1766.8, 1975.568819353049)}}
#{1:{0: (275.2, 316.0249357250152), 1: (216.8, 264.3689845651339), 2: (232.6, 310.2009671164808), 3: (699.8, 1035.9788414827783)}}
self.classP_feature = dict()
# 遍历每个特征标签
for c in set(labels):
self.classP_feature[c] = {}
for i in range(numFeaturs):#(0,1,2,3)
feature = data[np.equal(labels, c)][:, i]
self.classP_feature[c][i] = self.calMuAndSigma(feature)
# 预测新用户是否是异常用户
def predict(self, x):
label = -1 # 初始化类别
maxP = 0 #初始最大概率0
# 遍历所有的label值
for key in self.classP.keys():#self.classP {1: 0.5, 0: 0.5}
label_p = self.classP[key]
currentP = 1.0
feature_p = self.classP_feature[key]
j = 0
for fp in feature_p.keys():
currentP *= self.gaussian(feature_p[fp][0], feature_p[fp][1], x[j]) #currentP=P(yk|x) =分子= p(xi|yk)迭乘
j += 1
# 如果计算出来的概率大于初始的最大概率,则进行最大概率赋值 和对应的类别记录
if currentP * label_p > maxP:
maxP = currentP * label_p
label = key
return label
if __name__ == "__main__":
nb = NaiveBayesian(1.0)
data, labels = nb.createData()
nb.train(data, labels)
label = nb.predict(np.array([134, 84, 235, 349]))
print("未知类型用户对应的行为数据为:[134,84,235,349],该用户的可能类型为:{}".format(label))
相关文章:

朴素贝叶斯算法
# -*-coding:utf-8-*- """ Author: sunchang Desc: 代码4-7 朴素贝叶斯实现对异常账户检测 """ import numpy as np class NaiveBayesian: def __init__(self, alpha): self.classP dict() self.classP_f…...

【常见CSS扫盲雪碧图】从源码细看CSS雪碧图原理及实现,千字详解【附源码demo下载】
【写在前面】其实估计很多人都听过雪碧图,或者是CSS-Sprite,在很多门户网站就会经常有用到的,之所有引出雪碧图这个概念还得从前端加载多个图片时候页面闪了一下说起,这样给人的视觉效果体验很差,也就借此机会和大家说…...

Java多线程:ThreadLocal源码剖析
ThreadLocal源码剖析 ThreadLocal其实比较简单,因为类里就三个public方法:set(T value)、get()、remove()。先剖析源码清楚地知道ThreadLocal是干什么用的、再使用、最后总结,讲解ThreadLocal采取这样的思路。 三个理论基础 在剖析ThreadLo…...

96、数据的存储
运行实例: 在debug和release两种模式下,进行代码运行,debug下 i 的地址是大于arr[9] 的地址的,release 下i 的地址是小于arr[9] 的地址。原因是:release状态进行了优化处理。 C语言中基本的内置类型 整形数据类型 char …...
)
@EventListener注解详细使用(IT枫斗者)
EventListener注解详细使用 简介 EventListener是一种事件驱动编程在spring4.2的时候开始有的,早期可以实现ApplicationListener接口, 为我们提供的一个事件监听、订阅的实现,内部实现原理是观察者设计模式;为的就是业务系统逻辑的解耦,提高…...

[c++17新增语言特性] --- [[nodiscard]]和[[maybe_unused]]
1 [[nodiscard]] 介绍和应用示例 [[nodiscard]] 是C++17引入的一个属性(Attribute),它用于向编译器提示一个函数的返回值应该被检查,避免其被忽略或误用。它可以被用于函数、结构体、类、枚举和 typedef 等声明上,表示如果函数返回值未被使用,或者结构体、类、枚举和 type…...

Centos7安装和使用docker的笔记
最近项目要求用容器部署,所以需要将docker的用法搞清楚,在操作过程中,积累了一些操作方法和技巧,作为笔记,为后面使用做个参考。 首先安装docker需要给centos增加源(参考https://www.runoob.com/docker/cen…...
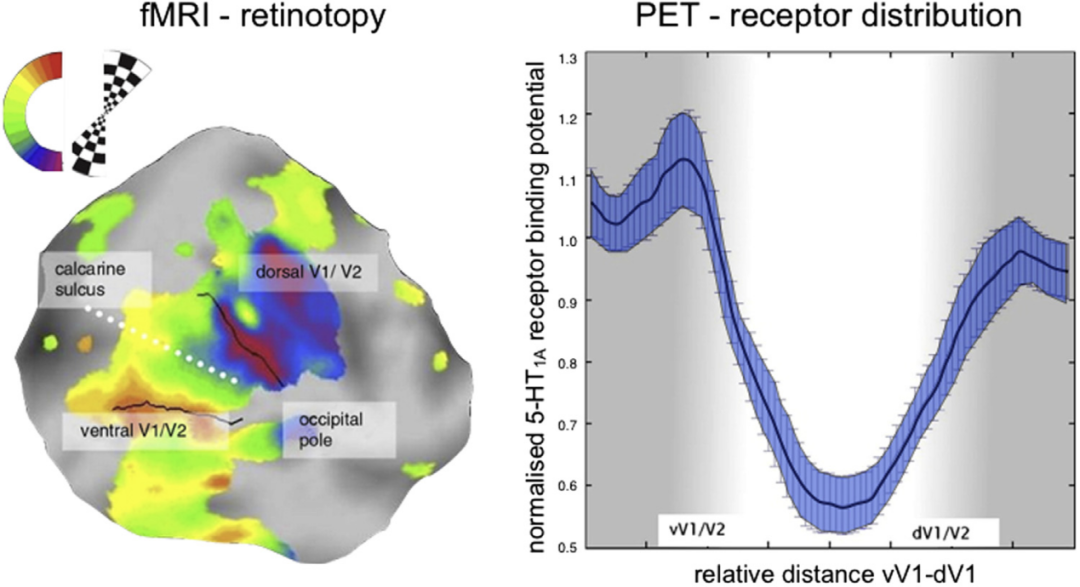
结构像与功能像
导读现代神经成像技术使我们能够研究活体大脑的结构和功能。活体神经成像的益处是显而易见的,而且在基础和临床神经科学中,神经成像已经取得了巨大进展。本文概述了利用活体神经成像研究大脑结构和功能的工作和成就。介绍了几种不同类型的结构MRI成像方法…...

【IAR工程】STM8S基于ST标准库读取DS1302数据
【IAR工程】STM8S基于ST标准库读取DS1302数据✨申明:本文章仅发表在CSDN网站,任何其他网站,未注明来源,见此内容均为盗链和爬取,请多多尊重和支持原创!🍁对于文中所提供的相关资源链接将作不定期更换。&…...

【SpringBoot】实现后端服务器发送QQ邮件验证码的功能
步骤一、添加邮件相关依赖二、配置邮件服务器三、发送邮件PS:SMTP 发送失败的解决方案一、添加邮件相关依赖 在 pom.xml 文件中添加 JavaMail 和 Spring Mail 相关的依赖。示例代码如下: <dependency><groupId>com.sun.mail</groupId&g…...

vue在input中输入后,按回车,提交数据
vue在input中输入后,按回车,提交数据 1.展示效果如下: 2.代码展示: <div><el-input v-model"toAddNameText" keyup.enter.native"toAddName()" placeholder"回车,即新增该竖杆名称…...

【YOLOX】用YOLOv5框架YOLOX
【YOLOX】用YOLOv5框架YOLOX一、新建common_x.py二、修改yolo.py三、新建yolox.yaml四、训练最近在跑YOLO主流框架的对比实验,发现了一个很奇怪的问题,就是同一个数据集,在不同YOLO框架下训练出的结果差距竟然大的离谱。我使用ultralytics公司…...

【python机器学习实验】——逻辑回归与感知机进行线性分类,附可视化结果!
【python机器学习实验】——逻辑回归与感知机进行线性分类,附可视化结果! 下载链接 下载链接 下载链接 可视化效果图: 感知机模型结果为例: 首先,我们有训练数据和测试数据,其每一行为(x,y,label)的形式…...

wps删除的文件怎么恢复
在办公中,几乎每个人都会用到WPS办公软件。它可以帮助我们快速有效地处理各种Word文档、ppt幻灯片、excel表格等。但有文件就会有清理,如果我们不小心删除了wps文件呢?那些wps删除的文件怎么恢复?针对这种情况,小编为大家带来一些恢复WPS文…...
NIO消息黏包和半包处理
1、前言 我们在进行NIO编程时,通常会使用缓冲区进行消息的通信(ByteBuffer),而缓冲区的大小是固定的。那么除非你进行自动扩容(Netty就是这么处理的),否则的话,当你的消息存进该缓冲…...

day018 第六章 二叉树 part05
一、513.找树左下角的值 这个题目的主要思路是使用广度优先搜索(BFS)遍历整棵树,最后返回最后一层的最左边的节点的值。具体的实现可以使用队列来存储每一层的节点,并且在遍历每一层节点时,不断更新最左边的节点的值。…...
如何下载ChatGPT-ChatGPT如何写作
CHATGPT能否改一下文章 ChatGPT 作为一种自然语言处理技术,生成的文章可能存在表达不够准确或文风不符合要求等问题。在这种情况下,可以使用编辑和修改来改变输出的文章,使其符合特定的要求和期望。 具体来说,可以采用以下步骤对…...

微策略再次买入
原创:刘教链* * *隔夜,比特币再次小幅回升至28k上方。微策略(Microstrategy)创始人Michael Saylor发推表示,微策略再次出手,买入1045枚比特币。此次买入大概花费2930万美元,平均加仓成本28016美…...

express框架
Express 是基于 Node.js 平台,快速、开放、极简的 Web 开发框架. 创建一个基本的express web服务器 // 1.导入express const express require(express); // 2.创建web服务器 const app express(); // 3.启动web服务器 app.listen(80, ()>{console.log(expres…...

完蛋的goals
...
)
从“上管掉电”到稳定驱动:手把手教你计算EG2104自举电容的容值与选型(附PWM占空比影响分析)
从“上管掉电”到稳定驱动:手把手教你计算EG2104自举电容的容值与选型(附PWM占空比影响分析) 在高压半桥驱动电路设计中,自举电容的选型往往成为工程师最易忽视却最关键的环节。EG2104作为一款经典的高低压侧驱动芯片,…...
)
为什么顶尖纳米实验室已停用传统文献管理工具?NotebookLM私有知识中枢部署避坑清单(限内部研究员参考)
更多请点击: https://codechina.net 第一章:NotebookLM纳米技术研究 NotebookLM 是 Google 推出的基于 AI 的研究协作者工具,其核心能力在于对用户上传的私有文档进行深度语义理解与上下文推理。在纳米技术这一高度跨学科、文献密集的研究领…...

Thanos剪枝算法:高效压缩大型语言模型的技术解析
1. 项目概述:Thanos剪枝算法解析在深度学习领域,大型语言模型(LLM)的参数量已突破千亿级别,这对计算资源和内存提出了极高要求。模型剪枝技术通过移除神经网络中的冗余连接,能在保持模型性能的同时显著降低…...

使用Python开发了CLI爬虫智能体
最近CLI智能体很火,这是一种在命令行工作的AI工具,比如Claude Code、OpenClaw等,非常适合编程、自动化、爬虫等场景。 我花了半天时间,用Python开发了一个CLI爬虫智能体,可以实现自动化采集Tiktok上公开的商品数据信息…...

轻松管理AD域:一款基于.NET的Web工具推荐
轻松管理AD域:一款基于.NET的Web工具推荐 【下载地址】AD域管理Web版工具 本资源提供了一个基于微软官方文档,使用.NET技术开发的Web AD域管理工具。该工具采用简单的HTML和一般处理程序(Generic Handler)来实现,旨在为…...
)
别只盯着SysTick_Config:用CubeMX配置STM32的SysTick中断并驱动OLED(附代码)
从CubeMX到OLED:SysTick中断在HAL库中的实战应用 引言 在嵌入式开发领域,精确的时间控制往往是项目成功的关键。对于STM32开发者而言,SysTick定时器作为Cortex-M内核的标准配置,提供了简单可靠的时间基准解决方案。不同于传统寄存…...
:谷歌AI团队内部培训手册泄露版)
NotebookLM具身智能落地实战(从零部署到ROS2集成):谷歌AI团队内部培训手册泄露版
更多请点击: https://intelliparadigm.com 第一章:NotebookLM具身智能研究 NotebookLM 是 Google 推出的基于用户自有文档进行语义理解与推理的 AI 助手,其核心能力在于“文档感知”(document-grounded reasoning)。当…...

35岁程序员亲历:AI时代如何避免踩坑?收藏这份避坑指南,小白也能看懂大模型!
作者作为一名有十多年经验的程序员,分享了自己在AI快速发展背景下,利用GPT Pro和Deep Research进行产品调研的经历。文章指出,仅依靠AI工具并不足以成功,更重要的是要找到真实的市场痛点和需求。作者通过实际案例分析了纯工具类、…...

ECB02蓝牙模块与手机通信避坑指南:从AT指令调试到数据收发实战
ECB02蓝牙模块与手机通信实战:从AT指令调试到数据收发的全流程解析 当你第一次拿到ECB02蓝牙模块时,可能会被这个小巧的硬件和复杂的AT指令集弄得手足无措。作为一名嵌入式开发者,我清楚地记得自己初次尝试让手机与模块通信时的挫败感——明明…...
)
QT ToolButton的5个隐藏技巧与3个常见坑,新手避雷指南(基于Qt 6.5)
QT ToolButton的5个隐藏技巧与3个常见坑,新手避雷指南(基于Qt 6.5) 在模仿现代软件工具栏设计时,QT的ToolButton组件往往是实现专业级交互的关键。但许多开发者第一次使用时会发现,这个看似简单的按钮藏着不少"陷…...