【暴力量化】查找最优均线
搜索逻辑
代码主要以支撑概率和压力概率来判断均线的优劣
判断为压力: 当日线与测试均线发生金叉或即将发生金叉后继续下行
判断为支撑: 当日线与测试均线发生死叉或即将发生死叉后继续上行
判断结果的天数: 小于6日均线,用金叉或死叉后2个交易日的结果判断;大于等于6日的n日均线,用n/2个交易日判断
判断逻辑: 使用判断点(金叉 or 死叉)后n/2个交易日的收盘价的一次回归线的斜率,大于0为上行,小于0为下行
补充: 把判断点由近似点改成准确点(即日线与均线发生交叉)后,1-压力概率 即为金叉概率,1-压力概率 即为死叉概率
数据处理
数据来源: tushare 或 通信达,我使用的是通信达导出的2015年至今的日线数据
数据处理: 把每只股票的数据按照日期从小到大排列后,取出收盘价即可
如果你有分钟数据,也可以搜索分钟级别的均线压力和支撑
数据处理代码
def readData(self,r_path):'''1、r_path: 通信达导出的日线数据所在的目录2、生成函数,每次获取一支股票2015年至今的收盘数据'''files = os.listdir(r_path)for f_path in files:f_path = os.path.join('日线_data',f_path)df = pd.read_csv(f_path,header=None,index_col=False,encoding='gbk',names=['trade_date','open','high','low','close','vol','amount']).dropna()df = df.sort_values('trade_date').reset_index(drop=True)yield df['close']
查找代码
判断金叉和死叉的逻辑
判断金叉和死叉的代码逻辑一开始属实让我难理解,看四五遍才清除,下面给一个我觉得比较清楚的示例
# 计算均线
ma = data.rolling(5).mean() # 计算5日均线
cmp = data > ma * 0.97 # 有时不触及均线也会有支撑和压力,但不会有金叉和死叉,所以要适当抬高或降低均线,自己设置
'''计算金叉和死叉,金叉用于计算压力,死叉用于计算支撑金叉计算逻辑cmp: F F F T T T F F F(~cmp).shift(1): T T T F F F T T Tgolden_idx: F F F T F F F F F # 金叉结果反过来就是死叉
'''
golden_idx = cmp & (~cmp).shift(1) #金叉
cmp = data > ma * 1.03 # 计算死叉,抬高均线
death_idx = ~cmp & cmp.shift(1) # 死叉
整体搜索代码
def find_best_ma(self,r_path,days:tuple):assert days[0] <= days[1],'计算均线日期错误,格式(起始,结束)'assert days[0] > 1,'最小天数要大于1'datas = self.readData(r_path)# 保存结果result = pd.DataFrame({'MA':[*range(days[0],days[1]+1)],'支撑成功率':np.zeros(days[1]-days[0]+1),'支撑成功次数':np.zeros(days[1]-days[0]+1),'支撑总次数':np.zeros(days[1]-days[0]+1),'压力成功率':np.zeros(days[1]-days[0]+1),'压力成功次数':np.zeros(days[1]-days[0]+1),'压力总次数':np.zeros(days[1]-days[0]+1)})result = result.set_index('MA')for data in datas:data_len = len(data) # 数据长度for day in range(days[0],days[1]+1):# 计算均线ma = data.rolling(day).mean()'''计算金叉和死叉,金叉用于计算压力,死叉用于计算支撑金叉计算逻辑cmp: F F F T T T F F F(~cmp).shift(1): T T T F F F T T Tgolden_idx: F F F T F F F F F'''cmp = data > ma * 0.97 # 有时不触及均线也会有支撑和压力,但不会有金叉和死叉,所以要适当抬高或降低均线golden_idx = cmp & (~cmp).shift(1)cmp = data > ma * 1.03 # 计算死叉,抬高均线death_idx = ~cmp & cmp.shift(1)# 转成索引golden_idx = golden_idx[golden_idx].indexdeath_idx = death_idx[death_idx].index# 把长度加进总数里result.loc[day,['压力总次数']] += len(golden_idx)result.loc[day,['支撑总次数']] += len(golden_idx)'''设置参考天数,用于判断后续涨跌如果均线小于等于5天,则用后2天判断如果均线大于5天,则n天均线准确率用后n/2天的涨势判断'''pre_day = 2 if day <=5 else int(day/2)'''支撑成功判断:死叉当天到后续pre_day天计算回归,斜率大于0死叉成功判断:死叉当天到后续pre_day天计算回归,斜率大于0'''for idx in golden_idx:if idx >= data_len-1:result.loc[day,['压力总次数']] -= 1continue # 位置太靠后,没有结果参考,跳过if data_len-idx < pre_day:pre_day = data_len-idx # 后续数据不足以参考天数,改为用后面剩的几天判断y = data[idx:idx + pre_day + 1]x = range(1,len(y)+1)k,b = np.polyfit(x,y,deg=1) # 线性回归预测if k < 0:result.loc[day,['压力成功次数']] += 1 # 小于0则说明均线有压力for idx in death_idx:if idx >= data_len-1:result.loc[day,['支撑总次数']] -= 1continue # 位置太靠后,没有结果参考,跳过if data_len-idx < pre_day:pre_day = data_len-idx # 后续数据不足以参考天数,改为用后面剩的几天判断y = data[idx:idx + pre_day + 1]x = range(1,len(y)+1)k,b = np.polyfit(x,y,deg=1) # 线性回归预测if k > 0:result.loc[day,['支撑成功次数']] += 1 # 小于0则说明均线有压力result['压力成功率'] = round(result['压力成功次数']/result['压力总次数'],4) # 更新一次结果result['支撑成功率'] = round(result['支撑成功次数']/result['支撑总次数'],4) # 更新一次结果os.system('cls')max = result.idxmax()max_support = result['支撑成功率'].max()max_presure = result['压力成功率'].max()print(tabulate(result.head(15), headers='keys', tablefmt='psql'),flush=True) print('当前最优值',flush=True)print('支撑\t','MA {}\t'.format(max['支撑成功率']),max_support,flush=True)print('压力\t','MA {}\t'.format(max['压力成功率']),max_presure,end='',flush=True) result.to_csv('最优均线.csv',encoding='utf-8-sig')
效果展示,以5到30天均线搜索为例

相关文章:
【暴力量化】查找最优均线
搜索逻辑 代码主要以支撑概率和压力概率来判断均线的优劣 判断为压力: 当日线与测试均线发生金叉或即将发生金叉后继续下行 判断为支撑: 当日线与测试均线发生死叉或即将发生死叉后继续上行 判断结果的天数: 小于6日均线,用金叉或…...
Java读取mysql导入的文件时中文字段出现�??的乱码如何解决
今天在写程序时遇到了一个乱码问题,困扰了好久,事情是这样的, 在Mapper层编写了查询语句,然后服务处调用,结果控制器返回一堆乱码 然后查看数据源头处: 由重新更改解码的字符集,在数据库中是正…...
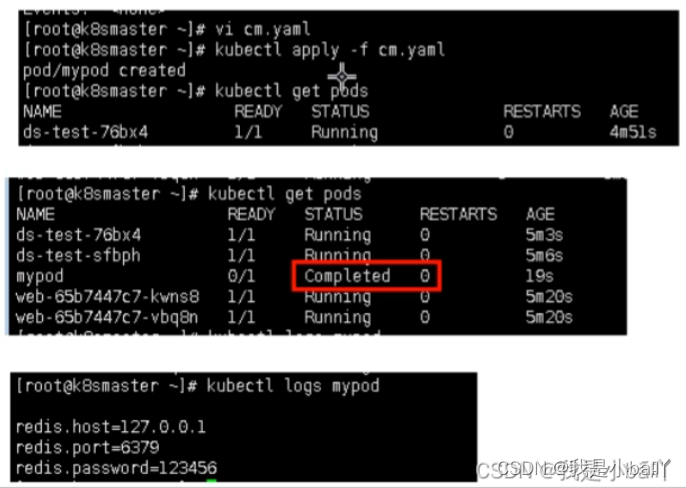
k8s核心概念—Pod Controller Service介绍——20230213
文章目录一、Pod1. pod概述2. pod存在意义3. Pod实现机制4. pod镜像拉取策略5. pod资源限制6. pod重启机制7. pod健康检查8. 创建pod流程9. pod调度二、Controller1. 什么是Controller2. Pod和Controller关系3. deployment应用场景4. 使用deployment部署应用(yaml&a…...

Tensorflow的数学基础
Tensorflow的数学基础 在构建一个基本的TensorFlow程序之前,关键是要掌握TensorFlow所需的数学思想。任何机器学习算法的核心都被认为是数学。某种机器学习算法的策略或解决方案是借助于关键的数学原理建立的。让我们深入了解一下TensorFlow的数学基础。 Scalar 标…...

IT培训就是“包就业”吗?内行人这么看
大部分人毕业后选择参加职业技能培训,都是为了学完之后能找到好工作,而“就业服务”也成为各家培训机构对外宣传的重点内容。那么,所谓的“就业服务”就是“包就业”和“包底薪”吗?学完就一定能拿到offer吗?今天&…...

【算法】【数组与矩阵模块】顺时针旋转打印矩阵
目录前言问题介绍解决方案代码编写java语言版本c语言版本c语言版本思考感悟写在最后前言 当前所有算法都使用测试用例运行过,但是不保证100%的测试用例,如果存在问题务必联系批评指正~ 在此感谢左大神让我对算法有了新的感悟认识! 问题介绍 …...

Java中的锁概述
java中的锁java添加锁的两种方式:synchronized:关键字 修饰代码块,方法 自动获取锁、自动释放锁Reentrantlock:类 只能修饰代码块 手动加锁、释放锁java中锁的名词一些锁的名词指的是锁的特性,设计,状态&am…...

微电影行业痛点解决方案
在当下新媒体时代,微电影作为“微文化”的载体,具有“微”的特点,经过短短数年的快速发展,并获得了受众广泛的关注和喜爱,对人们的休闲娱乐方式也产生较大的影响。但在迅猛发展的同时也存在一些行业痛点,诸…...
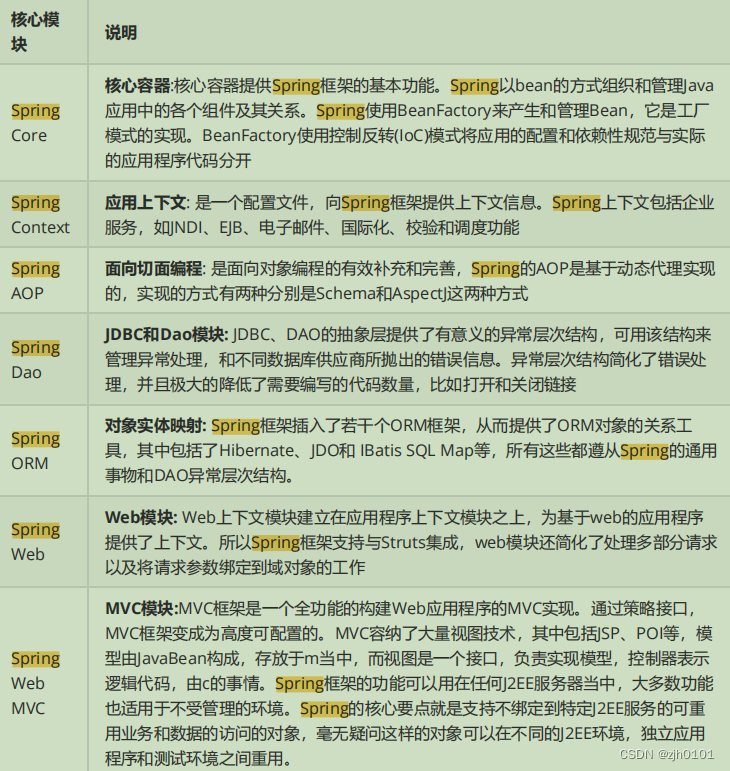
使用Spring框架的好处是什么
使用Spring框架的好处是什么? 1、轻量:Spring 是轻量的,基本的版本大约2MB。 2、控制反转:Spring通过控制反转实现了松散耦合,对象们给出它们的依赖,而不是创建或查找依赖的对象们。 3、面向切面的编程(AOP…...
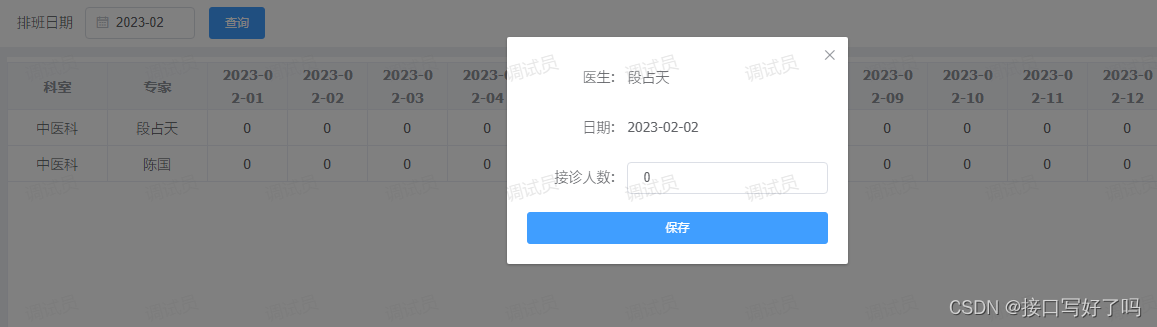
【表格单元格可编辑】vue-elementul简单实现table表格点击单元格可编辑,点击单元格变成弹框修改数据
前言 这是继我另一个帖子就是单元格点击变成输入框后添加的功能 因为考虑到有些时候修改单元格的信息可能点击后要修改很多,那一个输入框不好用 所以这时候就需要一个弹框可以把所有表单都显示出来修改 所以这里就专门又写了一个demo,用于处理这种情况 …...

vue3.0 响应式数据
目录1.什么是响应式2. 选项式 API 的响应式数据3.组合式 API 的响应式数据3.1 reactive() 函数3.2 toref() 函数3.3 toRefs() 函数3.4ref() 函数总结1.什么是响应式 这个术语在今天的各种编程讨论中经常出现,但人们说它的时候究竟是想表达什么意思呢?本质…...

uni-app ①
文章目录一、uni-app简介学习 uniapp 本质uniapp 优势uni-app 和 vue 的关系uni-app 和小程序有什么关系uniapp 与 web 代码编写区别课程内容学习重点知识点一、uni-app 简介 uni-app 是一个使用 Vue.js 进行 开发所有前端应用的框架。开发者编写一套代码,即可发布…...

20个 Git 命令玩转版本控制
想要在团队中处理代码时有效协作并跟踪更改,版本控制发挥着至关重要的作用。Git 是一个版本控制系统,可以帮助开发人员跟踪修订、识别文件版本,并在必要的时候恢复旧版本。Git 对于有一定编程经验的用户来说虽然不算太难,但是想要…...
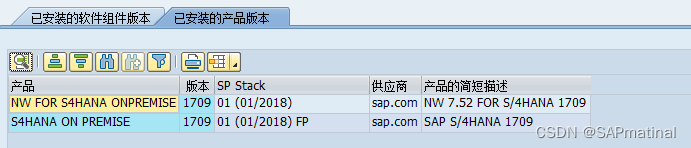
SAP NetWeaver版本和SAP Kernel版本的确定
SAP NetWeaver(SAP NW)描述了用于“业务启用”的所有软件和服务。SAP业务套件(如ERP中央组件(ECC)或供应商关系管理(SRM))包含该特定业务解决方案的软件组件。 以下是SAP NetWeaver…...
面试23K字节测试开发岗被血虐,到底具有怎样的技术才算高级水平?
前几天我朋友跟我吐苦水,这波面试又把他打击到了,做了6年软件测试。。。 下面这条招聘是在腾讯招聘官网截图下来的,首先我们对高级水平下一个定义吧,那它应该是对标这个职级该有的能力 什么样的工程师才能算高级?至少…...

智云通CRM:买对了吗——大客户采购的方案实施
一旦采购合同签署后,供应商就要履行合同,按时交付产品进场使用,或实施服务方案。不过,无论对供应商还是客户来说,双方的合作并没有就此结束。 在这个阶段,客户会评估此次合作的供应商做事是否靠谱&#x…...
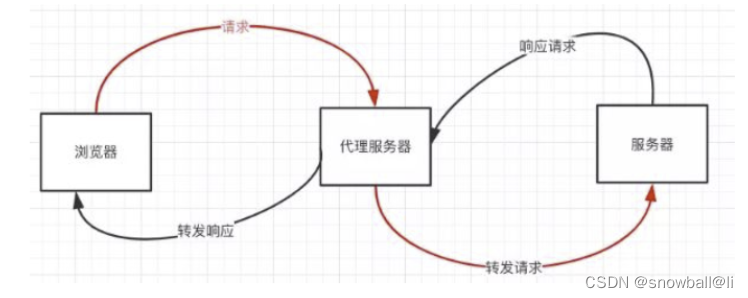
前后端开发过程中的跨域问题总结
1.何为跨域问题 出于浏览器的同源策略限制。同源策略是一种约定,它是浏览器最核心也最基本的安全功能,如果缺少了同源策略,则浏览器的正常功能不能使用。可以说web是构建在同源策略基础之上的,浏览器只是针对同源策略的一种实现。…...
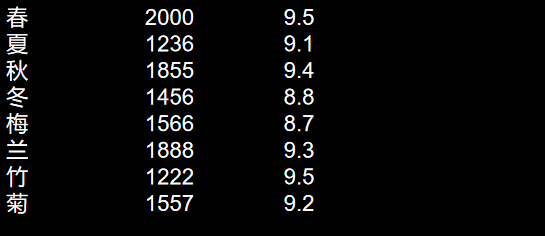
爬虫:栖落的电影网站,利用requests和re模块
这是栖落的电影网站地址:https://xxx.xxx 进入网页,显示: 爬取目标:电影的名称、观影人数和评分。 易知本网站的url url "https://xxx.xxx" 本网站会识别出headers中的python请求而拒绝访问,所以需要更改…...

使用burpsuite抓包 + sql工具注入 dvwa靶场
使用burpsuite抓包 sql工具注入 dvwa靶场 记录一下自己重新开始学习web安全之路②。 一、准备工作 1.工具准备 sqlmap burpsuite 2.浏览器准备 火狐浏览器 设置代理。 首先,先设置一下火狐浏览器的代理 http代理地址为127.0.0.0.1 ,端口为8080 …...
树与图中的dfs和bfs—— AcWing 846. 树的重心 AcWing 847. 图中点的层次
一、AcWing 846. 树的重心1.1题目1.2思路分析题意:什么是树的重心?树的重心是指,删除某个结点后剩下的最大连通子树的结点数目最小,如下图是根据样列生成的树,若删除结点1,则剩下三个子树最大的是中间那颗结…...

告别月薪四千,2026网工转网安:学习路线、岗位方向与避坑全指南
告别月薪四千,2026 网工转网安:学习路线、岗位方向与避坑全指南 相信很多在做网络运维的朋友,搞了几年基础工作后,都会遇到这样的瓶颈:日常主要和交换机、路由器打交道,处理配置、排障这些重复内容&#x…...

终极Windows安卓应用安装指南:告别模拟器,拥抱轻量级体验
终极Windows安卓应用安装指南:告别模拟器,拥抱轻量级体验 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否厌倦了笨重的安卓模拟器&#x…...

掌握高效窗口管理:专业级分辨率调整工具完全指南
掌握高效窗口管理:专业级分辨率调整工具完全指南 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 在当今多任务处理和多屏工作环境中,你是否经常遇到窗口大小不合适、分辨率限制或游戏画面…...
)
使用 LikeShop 搭建商城的完整流程(从0到上线)
先说结论用 LikeShop 搭建商城,本质可以拆成 5 步:👉 部署系统 → 配置基础 → 上架商品 → 打通交易 → 引流运营只要这 5 步跑通,就可以实现“可正常卖货”的商城。一、准备阶段(很多人会忽略)在动手之前…...

告别手动下载!3步轻松批量获取网易云音乐FLAC无损音乐
告别手动下载!3步轻松批量获取网易云音乐FLAC无损音乐 【免费下载链接】NeteaseCloudMusicFlac 根据网易云音乐的歌单, 下载flac无损音乐到本地.。 项目地址: https://gitcode.com/gh_mirrors/nete/NeteaseCloudMusicFlac 你是不是也遇到过这样的烦恼&#x…...
)
嵌入式老C代码别重写!IAR项目混编C/C++的保姆级指南(extern “C“详解)
嵌入式老C代码别重写!IAR项目混编C/C的保姆级指南(extern "C"详解) 当你在IAR Embedded Workbench中启动一个新项目,面对那些历经千锤百炼的C语言驱动和BSP代码,是否曾为"推倒重来还是继续维护"而…...

别再搞混了!改进DH与标准DH参数在IRB1200建模中的关键差异与选择
别再搞混了!改进DH与标准DH参数在IRB1200建模中的关键差异与选择 当你在为ABB IRB1200这类六轴工业机器人构建运动学模型时,是否曾被两种不同的DH参数表示法困扰?标准DH(Denavit-Hartenberg)和改进DH(Modif…...

QQ音乐加密文件解密终极指南:qmcdump工具完整教程
QQ音乐加密文件解密终极指南:qmcdump工具完整教程 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 你是否曾经…...

手把手教你用C8051F330自制BLheli电调:从测绘XP-12A到暴力测试70涵道
从零构建BLheli电调:C8051F330硬件逆向与70涵道暴力测试全指南 当你拆开一台现成的航模电调,看到里面密密麻麻的元件时,是否想过自己也能从头打造一个?本文将带你深入电调硬件设计的核心,从测绘商业电调XP-12A开始&…...

AzurLaneAutoScript:碧蓝航线终极自动化解决方案
AzurLaneAutoScript:碧蓝航线终极自动化解决方案 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 还在为碧蓝航线…...