TensorRT创建Engine并推理engine
1. 验证集数据集
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 84/all 1000 28423 0.451 0.374 0.376 0.209pedestrians 1000 17833 0.737 0.855 0.88 0.609riders 1000 185 0.545 0.492 0.521 0.256
partially-visible-person 1000 9335 0.456 0.338 0.336 0.125ignore-regions 1000 409 0.37 0.138 0.121 0.0485crowd 1000 661 0.146 0.0454 0.0237 0.00837
Speed: 0.1ms pre-process, 1.4ms inference, 1.6ms NMS per image at shape (12, 3, 640, 640)
2. 视频流推理
Speed: 0.3ms pre-process, 9.0ms inference, 0.9ms NMS per image at shape (1, 3, 640, 640)
计算FPS
要计算FPS(每秒帧数),我们需要将每张图像的时间(包括预处理、推理和NMS)倒数,得到每秒可以处理的图像数量,然后乘以批量大小。
默认batch_size = 1,则每张图像的总时间为0.3毫秒+9.0毫秒+0.9毫秒=10.2毫秒。
因此,FPS将是1 /(10.2毫秒)= 98.04 FPS。
3. 使用TensorRT在Tesla A40 12Q上的推理是

3. 理解runtime和engine
runtime是TensorRT运行时环境,它提供了创建和管理TensorRT引擎的API。在运行时环境中,可以加载和运行TensorRT引擎,使用TensorRT API管理内存分配和复制,以及在GPU上执行各种TensorRT操作。
engine是一个已经被序列化和优化的TensorRT模型。TensorRT引擎是用NVIDIA TensorRT库创建的,它将深度学习模型转换为可在GPU上高效执行的格式。要使用TensorRT引擎,需要将其反序列化为可执行的形式。可以使用deserializeCudaEngine函数从序列化的引擎数据中生成TensorRT引擎。
3. 原版build.cu
#include "NvInfer.h"
#include "NvOnnxParser.h" // onnxparser
#include "logger.h"
#include "common.h"
#include "buffers.h"
#include "cassert"/*
1. Create builder
2. Create Network*/int main(int argc, char **argv)
{if (argc != 2) // 命令行参数要等于2 {std::cerr << "usage: ./build [onnx_file_path]" << argv[0] << std::endl;return -1;}// onnx_file_pathconst char* onnx_file_path = argv[1];// 1. Create Builderauto builder = std::unique_ptr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(sample::gLogger.getTRTLogger()));// nvinfer::IBuilder *builder = nvinfer1::createInferBuilder(logger);if (!builder){std::cerr << "create builder failed" << std::endl;return -1;}// 2. Set the input and output names of the networkauto network = std::unique_ptr<nvinfer1::INetworkDefinition>(builder->createNetworkV2(1));if (!network){std::cerr << "create network failed" << std::endl;return -1;}// 3. Parse Onnx configurationauto parser = std::unique_ptr<nvonnxparser::IParser>(nvonnxparser::createParser(*network, sample::gLogger.getTRTLogger()));auto parsed = parser->parseFromFile(onnx_file_path, static_cast<int>(sample::gLogger.getReportableSeverity()));if (!parsed){std::cerr << "parse onnx file failed" << std::endl;return -1;}// 4. Set Image input size // This program only have one input which is one Image at once (1, 3, 640, 640)auto input = network->getInput(0);auto profile = builder->createOptimizationProfile();// set KMIN, KMAX, KOPTprofile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMIN, nvinfer1::Dims4{1, 3, 640, 640});profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMAX, nvinfer1::Dims4{1, 3, 640, 640});profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kOPT, nvinfer1::Dims4{1, 3, 640, 640});// 5. Build Network configauto config = std::unique_ptr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig());if (!config){std::cerr << "create IBuilderConfig failed" << std::endl;return -1;}// config->setFlag() setting precisionconfig->setFlag(nvinfer1::BuilderFlag::kFP16);// set max batch sizebuilder->setMaxBatchSize(1); // infer one image once// set max workspaceconfig->setMemoryPoolLimit(nvinfer1::MemoryPoolType::kWORKSPACE, 1 << 30); // 2^30 = 1GB// Set profileStreamauto profileStream = samplesCommon::makeCudaStream();if (!profileStream){std::cerr << "Create CUDA stream failed" << std::endl;return -1;}config->setProfileStream(*profileStream);// 6. runing planauto plan = std::unique_ptr<nvinfer1::IHostMemory>(builder->buildSerializedNetwork(*network, *config));if (!plan){std::cerr << "build engine failed" << std::endl;return -1;}// serialized enginestd::ofstream engine_file("./weights/my_Engine", std::ios::binary);assert(engine_file.is_open() && "Failed to open Engine file");engine_file.write((char *)plan->data(), plan->size());std::cout<<"Building Engine Successfully"<< std::endl;return 0;
}
4. 解析build.cu的main函数
4.1 命令行参数调整
int argc, char **argv是为了从命令行获取输入参数,以便程序可以根据这些参数进行相应的操作。
argc 是命令行的参数
argv 是指向字符串数组的指针
argv 数组的第一个元素 argv[0] 是程序的名称,而其他元素 argv[1]、argv[2]、……、argv[argc-1] 则是传递给程序的参数。
这里因为在命令行执行可执行文件的时候需要附上onnx的路径, 所以这样子搞一下
if (argc != 2) // 命令行参数要等于2
{std::cerr << "usage: ./build [onnx_file_path]" << argv[0] << std::endl;return -1;
}// onnx_file_path
const char* onnx_file_path = argv[1];
4.2 创建Builder
第一步都是创建builder,这里使用了TRT自带的全局的Logger, 来自logger.h头文件, 所有使用它的地方都会输出到同一个Logger中。
使用智能指针不用手动去释放了
// ================1. 创建Builder========================auto builder = std::unique_ptr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(sample::gLogger.getTRTLogger()));/*不带智能指针版本:nvinfer1::IBuilder *builder = nvinfer1::createInferBuilder(logger);*/if (!builder){std::cerr << "创建Builder失败" << std::endl;return -1;}
4.3 创建network: builder->Network
显式地创建batch size为1的网络
batch size指定的是每次推理时的输入数据量,一个batch包含的数据量越多,GPU并行处理的能力就越强,同时可以减少数据拷贝的次数,提高推理效率。但是,在某些情况下,例如对于视频数据,我们可能需要单独对每一帧进行推理,因此batch size为1可能更适合。
将ONNX文件的配置解析成TensorRT中的网络结构。通过将网络和解析器一起传递给解析器,可以检查ONNX文件是否正确解析,并将其转换为TensorRT网络,以便可以继续对其进行优化和部署。如果ONNX文件无法解析,后续步骤也就没有意义了。
// 2. Set the input and output names of the network
auto network = std::unique_ptr<nvinfer1::INetworkDefinition>(builder->createNetworkV2(1));
if (!network)
{std::cerr << "create network failed" << std::endl;return -1;
}// 3. Parse Onnx configuration
auto parser = std::unique_ptr<nvonnxparser::IParser>(nvonnxparser::createParser(*network, sample::gLogger.getTRTLogger()));
auto parsed = parser->parseFromFile(onnx_file_path, static_cast<int>(sample::gLogger.getReportableSeverity()));
if (!parsed)
{std::cerr << "parse onnx file failed" << std::endl;return -1;
}
4.4 network中设置网络的输入
这段代码设置输入尺寸, 要知道这个engine只有一个输入, 就是Image。
getInput(0)拿到第1个输入节点名字(char *), 然后再创建节点profile, 用profile去设置Image尺寸
profile是一种优化配置, 这里用profile设置最小、最大和优化尺寸,可以让TensorRT针对这些特定的尺寸进行优化,以获得更好的性能和效率。这些优化配置可以在创建TensorRT引擎时使用,以便在推理过程中使用最优的配置。
除了控制输入尺寸, TensorRT还有其他的各种手段来优化提高网络的性能, 内存管理, 层次化排序, 算法优化, 量化等等
// 4. Set Image input size
// This program only have one input which is one Image at once (1, 3, 640, 640)
auto input = network->getInput(0);
auto profile = builder->createOptimizationProfile();
// set KMIN, KMAX, KOPT
profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMIN, nvinfer1::Dims4{1, 3, 640, 640});
profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMAX, nvinfer1::Dims4{1, 3, 640, 640});
profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kOPT, nvinfer1::Dims4{1, 3, 640, 640});
4.5 创建config: builder->config
创建config, 然后通过config设置精度是FP16,如果不设置的话他默认是FP32,设置为INT8需要额外设置cailbrator
通过再设置最大的workspace, 1<<30的意思就是2^30 = 1GB
通过builder设置最大的batch size
使用makeCudaStream去创建一个profile流, 用于计算每个层之间的运算时间, 并且执行引擎的时候动态调整每层的大小, 获得更好的性能,这里需要跟config关联
auto config = std::unique_ptr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig());if (!config){std::cerr << "create IBuilderConfig failed" << std::endl;return -1;}// config->setFlag() setting precisionconfig->setFlag(nvinfer1::BuilderFlag::kFP16);// set max batch sizebuilder->setMaxBatchSize(1); // infer one image once// set max workspaceconfig->setMemoryPoolLimit(nvinfer1::MemoryPoolType::kWORKSPACE, 1 << 30); // 2^30 = 1GB// Set profileStreamauto profileStream = samplesCommon::makeCudaStream();if (!profileStream){std::cerr << "Create CUDA stream failed" << std::endl;return -1;}config->setProfileStream(*profileStream);
4.6 创建Engine并序列化保存Engine
engine的创建分为两个阶段,分别是构建阶段和序列化阶段。在构建阶段中,会根据输入的网络结构和优化配置创建一个engine对象。而在序列化阶段,将engine对象序列化为一块二进制数据并保存到硬盘上,以便在实际运行中反序列化得到engine对象并使用。
在构建阶段中,由于一些原因(比如内存资源限制),并不是每次都能成功创建一个engine对象。而当创建成功时,可以将这个engine对象看做是一个“计划”(plan),代表了使用TensorRT对网络进行优化之后的运行计划。因此,在代码中通常将engine对象命名为“plan”,以表示这个对象代表了一个运行计划。
// 6. runing plan
auto plan = std::unique_ptr<nvinfer1::IHostMemory>(builder->buildSerializedNetwork(*network, *config));
if (!plan)
{std::cerr << "build engine failed" << std::endl;return -1;
}// serialized engine
std::ofstream engine_file("./weights/my_Engine", std::ios::binary);
assert(engine_file.is_open() && "Failed to open Engine file");
engine_file.write((char *)plan->data(), plan->size());std::cout<<"Building Engine Successfully"<< std::endl;
return 0;
5. 原版runtime.cu
#include "NvInfer.h"
#include "NvOnnxParser.h"
#include "logger.h"
#include "common.h"
#include "buffers.h"
#include "utils/preprocess.h"
#include "utils/postprocess.h"
#include "utils/types.h"// 加载模型文件
std::vector<unsigned char> load_engine_file(const std::string &file_name)
{std::vector<unsigned char> engine_data;std::ifstream engine_file(file_name, std::ios::binary);assert(engine_file.is_open() && "Unable to load engine file.");engine_file.seekg(0, engine_file.end);int length = engine_file.tellg();engine_data.resize(length);engine_file.seekg(0, engine_file.beg);engine_file.read(reinterpret_cast<char *>(engine_data.data()), length);return engine_data;
}int main(int argc, char **argv)
{if (argc < 3){std::cerr << "用法: " << argv[0] << " <engine_file> <input_path_path>" << std::endl;return -1;}auto engine_file = argv[1]; // 模型文件auto input_video_path = argv[2]; // 输入视频文件// ========= 1. 创建推理运行时runtime =========auto runtime = std::unique_ptr<nvinfer1::IRuntime>(nvinfer1::createInferRuntime(sample::gLogger.getTRTLogger()));if (!runtime){std::cout << "runtime create failed" << std::endl;return -1;}// ======== 2. 反序列化生成engine =========// 加载模型文件auto plan = load_engine_file(engine_file);// 反序列化生成engineauto mEngine = std::shared_ptr<nvinfer1::ICudaEngine>(runtime->deserializeCudaEngine(plan.data(), plan.size()));if (!mEngine){return -1;}// ======== 3. 创建执行上下文context =========auto context = std::unique_ptr<nvinfer1::IExecutionContext>(mEngine->createExecutionContext());if (!context){std::cout << "context create failed" << std::endl;return -1;}// ========== 4. 创建输入输出缓冲区 =========samplesCommon::BufferManager buffers(mEngine);auto cap = cv::VideoCapture(input_video_path);int width = int(cap.get(cv::CAP_PROP_FRAME_WIDTH));int height = int(cap.get(cv::CAP_PROP_FRAME_HEIGHT));int fps = int(cap.get(cv::CAP_PROP_FPS));// 写入MP4文件,参数分别是:文件名,编码格式,帧率,帧大小cv::VideoWriter writer("./output/record.mp4", cv::VideoWriter::fourcc('H', '2', '6', '4'), fps, cv::Size(width, height));cv::Mat frame;int frame_index{0};// 申请gpu内存cuda_preprocess_init(height * width);while (cap.isOpened()){// 统计运行时间auto start = std::chrono::high_resolution_clock::now();cap >> frame;if (frame.empty()){std::cout << "文件处理完毕" << std::endl;break;}frame_index++;// 输入预处理(实现了对输入图像处理的gpu 加速)process_input(frame, (float *)buffers.getDeviceBuffer(kInputTensorName));// ========== 5. 执行推理 =========context->executeV2(buffers.getDeviceBindings().data());// 拷贝回hostbuffers.copyOutputToHost();// 从buffer manager中获取模型输出int32_t *num_det = (int32_t *)buffers.getHostBuffer(kOutNumDet); // 检测到的目标个数int32_t *cls = (int32_t *)buffers.getHostBuffer(kOutDetCls); // 检测到的目标类别float *conf = (float *)buffers.getHostBuffer(kOutDetScores); // 检测到的目标置信度float *bbox = (float *)buffers.getHostBuffer(kOutDetBBoxes); // 检测到的目标框// 执行nms(非极大值抑制),得到最后的检测框std::vector<Detection> bboxs;yolo_nms(bboxs, num_det, cls, conf, bbox, kConfThresh, kNmsThresh);// 结束时间auto end = std::chrono::high_resolution_clock::now();auto elapsed = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();auto time_str = std::to_string(elapsed) + "ms";auto fps_str = std::to_string(1000 / elapsed) + "fps";// 遍历检测结果for (size_t j = 0; j < bboxs.size(); j++){cv::Rect r = get_rect(frame, bboxs[j].bbox);cv::rectangle(frame, r, cv::Scalar(0x27, 0xC1, 0x36), 2);cv::putText(frame, std::to_string((int)bboxs[j].class_id), cv::Point(r.x, r.y - 10), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0x27, 0xC1, 0x36), 2);}cv::putText(frame, time_str, cv::Point(50, 50), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0xFF, 0xFF, 0xFF), 2);cv::putText(frame, fps_str, cv::Point(50, 100), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0xFF, 0xFF, 0xFF), 2);// cv::imshow("frame", frame);// 写入视频文件writer.write(frame);std::cout << "处理完第" << frame_index << "帧" << std::endl;if (cv::waitKey(1) == 27)break;}// ========== 6. 释放资源 =========// 因为使用了unique_ptr,所以不需要手动释放return 0;
}
6. 解析版runtime.cu
6.1 加载Engine
典型的读取二进制文件
static_cast 是C++中的一种类型转换操作,用于在编译时执行类型转换。对于某些类型,例如 int 和 float,static_cast 可以执行从一种类型到另一种类型的转换。但是,对于指针类型,static_cast 只允许在安全的情况下进行转换。
对于指向无符号字符类型的指针 unsigned char * 和指向字符类型的指针 char *,它们在内存表示和语义上是相同的,因此可以通过 static_cast 在这两种类型之间进行转换。但是,在标准C++语言中, static_cast 无法将 unsigned char * 类型直接转换为 char * 类型,因为它们之间没有隐式转换的关系。因此,在这种情况下,需要使用 reinterpret_cast 执行指针类型转换。
// 加载模型文件
std::vector<unsigned char> load_engine_file(const std::string &file_name)
{std::vector<unsigned char> engine_data;std::ifstream engine_file(file_name, std::ios::binary);assert(engine_file.is_open() && "Unable to load engine file.");engine_file.seekg(0, engine_file.end);int length = engine_file.tellg();engine_data.resize(length);engine_file.seekg(0, engine_file.beg);engine_file.read(reinterpret_cast<char *>(engine_data.data()), length);return engine_data;
}
6.2 保证输入是三个,因为runtime的可执行文件要加上engine path 和 推理文件 path
if (argc < 3){std::cerr << "用法: " << argv[0] << " <engine_file> <input_path_path>" << std::endl;return -1;}auto engine_file = argv[1]; // 模型文件auto input_video_path = argv[2]; // 输入视频文件
6.3 创建推理运行时runtime
auto runtime = std::unique_ptr<nvinfer1::IRuntime>(nvinfer1::createInferRuntime(sample::gLogger.getTRTLogger()));
if (!runtime)
{std::cout << "runtime create failed" << std::endl;return -1;
}
6.4 反序列化生成engine
这里的engine可能会被多次引用所以用std::shared_ptr
// ======== 2. 反序列化生成engine =========
// 加载模型文件
auto plan = load_engine_file(engine_file);
// 反序列化生成engine
auto mEngine = std::shared_ptr<nvinfer1::ICudaEngine>(runtime->deserializeCudaEngine(plan.data(), plan.size()));
if (!mEngine)
{return -1;
}
6.5 创建上下文context
简单点说,context是从engine获得推理任务的定义,然后通过runtime这个运行是的环境管理设备,进行推理任务
// ======== 3. 创建执行上下文context =========
auto context = std::unique_ptr<nvinfer1::IExecutionContext>(mEngine->createExecutionContext());
if (!context)
{std::cout << "context create failed" << std::endl;return -1;
}
6.6 创建输入输出缓存区
在这里,首先创建了一个 BufferManager 对象 buffers,它负责为模型的输入和输出数据分配和管理缓冲区。 BufferManager 类是由 TensorRT 示例代码提供的一个实用类.
每一步操作都从buffer拿数据搞完了再放回去
buffer是与TensorRT engine相关联的。在TensorRT中,输入和输出数据需要通过BufferManager来分配和管理,其中BufferManager会创建和存储一系列的缓冲区来存储输入和输出Tensor。在运行时,我们需要将输入数据放入输入Tensor的缓冲区中,然后通过执行上下文执行推理,推理结果也会被存储在输出Tensor的缓冲区中。因此,BufferManager是一个用于在运行时分配和管理输入和输出Tensor缓冲区的实用工具。
// ========== 4. 创建输入输出缓冲区 =========
samplesCommon::BufferManager buffers(mEngine);
6.7 拿到图像的信息创建vedio
拿到图像的宽高, 拿来申请内存, 确保有足够的内存处理每一帧图像
创建writer, 写入视频
// 拿到图像信息,宽,高,fpsauto cap = cv::VideoCapture(vedio_path);int width = int(cap.get(cv::CAP_PROP_FRAME_WIDTH));int height = int(cap.get(cv::CAP_PROP_FRAME_HEIGHT));int fps = int(cap.get(cv::CAP_PROP_FPS));// 写入MP4文件,参数分别是:文件名,编码格式,帧率,帧大小cv::VideoWriter writer("./output/record.mp4", cv::VideoWriter::fourcc('H', '2', '6', '4'), fps, cv::Size(width, height));cv::Mat frame;int frame_index{0};// 申请GPU内存, 保证足够内存存储每一帧图像数据cuda_preprocess_init(height * width);
6.8 while循环处理每一帧
使用tensorrtx的处理
预处理->执行推理->拷贝回host->后处理(NMS)->恢复bboxs
while (cap.isOpened()){// 统计运行时间auto start = std::chrono::high_resolution_clock::now();cap >> frame;if (frame.empty()){std::cout << "文件处理完成" << std::endl;break;}frame_index++;// 输入预处理: 把buffers(缓存区的数据)放到GPU上进行预处理操作process_input(frame, (float *)buffers.getDeviceBuffer(kInputTensorName));// 5. 执行推理context->executeV2(buffers.getDeviceBindings().data());// 拷贝回hostbuffers.copyOutputToHost();/*从buffer manager中获取模型输出, 检测数量, 类别, 置信度, bounding boxesgetHostBuffer() 是一个 (void *) 类型, 需要转换成对应类型的**/int32_t *num_det = (int32_t *)buffers.getHostBuffer(kOutNumDet);int32_t *cls = (int32_t *)buffers.getHostBuffer(kOutDetCls);float *conf = (float *)buffers.getHostBuffer(kOutDetScores);float *bbox = (float *)buffers.getHostBuffer(kOutDetBBoxes);// 执行nmsstd::vector<Detection> bboxs;yolo_nms(bboxs, num_det, cls, conf, bbox, kConfThresh, kNmsThresh);// 结束时间, 计算消耗时间auto end = std::chrono::high_resolution_clock::now();auto elapsed = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();auto time_str = std::to_string(elapsed) + "ms";auto fps_str = std::to_string(1000 / elapsed) + "fps";// 遍历检测结果for (size_t j = 0; j < bboxs.size(); j++){cv::Rect r = get_rect(frame, bboxs[j].bbox);cv::rectangle(frame, r, cv::Scalar(0x27, 0xC1, 0x36), 2);cv::putText(frame, std::to_string((int)bboxs[j].class_id), cv::Point(r.x, r.y - 10), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0x27, 0xC1, 0x36), 2);}cv::putText(frame, time_str, cv::Point(50, 50), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0xFF, 0xFF, 0xFF), 2);cv::putText(frame, fps_str, cv::Point(50, 100), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0xFF, 0xFF, 0xFF), 2);writer.write(frame);std::cout << "处理完第" << frame_index << "帧" << std::endl;// 不用释放资源}相关文章:
TensorRT创建Engine并推理engine
1. 验证集数据集 Class Images Labels P R mAP.5 mAP.5:.95: 100%|██████████| 84/all 1000 28423 0.451 0.374 0.376 0.209pedestrians 1000 17833 0.737 0.855 0.88 …...

生成式人工智能所面临的问题有哪些?
在生成式人工智能中工作需要混合技术、创造性和协作技能。通过发展这些技能,您将能够在这个令人兴奋且快速发展的领域应对具有挑战性的问题。 生成式人工智能是指一类机器学习技术,旨在生成与训练数据相似但不完全相同的新数据。 换句话说,…...
代码随想录算法训练营第四十三天 | 1049. 最后一块石头的重量 II、494. 目标和、474. 一和零
打卡第43天,01背包应用。 今日任务 1049.最后一块石头的重量 II494.目标和474.一和零 1049. 最后一块石头的重量 II 有一堆石头,用整数数组 stones 表示。其中 stones[i] 表示第 i 块石头的重量。 每一回合,从中选出任意两块石头࿰…...

PostCSS 让js可以处理css
GitHub 中文readmie PostCSS 中文网(建设中) PostCSS 不是样式预处理器 是 CSS 语法转换的工具,但不严格遵循css规范,只要符合css语法规则就可以被处理。这也让提前实现新提案成为可能。 使用 webpack 中使用 postcss-loader …...

【C语言进阶:自定义类型详解】位段
本节重点内容: 什么是位段位段的内存分配位段的跨平台问题位段的应用⚡什么是位段 位段的声明和结构是非常类似的,但是有两个不同: 位段的成员必须是 int、unsigned int 或signed int 。位段的成员名后边有一个冒号和一个数字。 struct A…...
十三、RNN循环神经网络实战
因为我本人主要课题方向是处理图像的,RNN是基本的序列处理模型,主要应用于自然语言处理,故这里就简单的学习一下,了解为主 一、问题引入 已知以前的天气数据信息,进行预测当天(4-9)是否下雨 日期温度气压是否下雨4-…...
五子棋透明棋盘界面设计(C语言)
五子棋透明棋盘设计,漂亮的界面制作。程序设置双人对奕,人机模式,对战演示三种模式。设置悔棋,记录功能,有禁手设置。另有复盘功能设置。 本文主要介绍透明的玻璃板那样的五子棋棋盘的制作。作为界面设计,…...
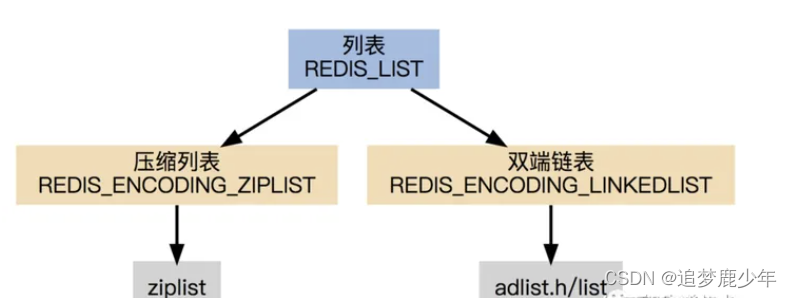
Redis第六讲 Redis之List底层数据结构实现
List数据结构 List是一个有序(按加入的时序排序)的数据结构,Redis采用quicklist(双端链表) 和 ziplist 作为List的底层实现。可以通过设置每个ziplist的最大容量,quicklist的数据压缩范围,提升数据存取效率 list-max-ziplist-size -2 // 单个ziplist节点最大能存储 8kb ,…...
真题,含答案解析)
电子学会2023年3月青少年软件编程python等级考试试卷(四级)真题,含答案解析
目录 一、单选题(共25题,共50分) 二、判断题(共10题,共20分) 三、编程题(共3题,共30分)...

【MATLAB】一篇文章带你了解beatxbx工具箱使用
目录 一篇文章带你了解beatxbx工具箱使用 一篇文章带你了解beatxbx工具箱使用 clc;clear; tic; % step1 初始化 % 个体数量 NIND = 35; % 最大遗传代数 MAXGEN = 180; % 变量的维数 NVAR = 2; % 变量的二进制位数 % 上下界 bounds=[-10 10-10 10]; precision=0.0001; %运算精度…...

【LinuxC Sqlite数据库小项目】基于Sqlite的打卡系统------适合初学者练手的小项目
最近小哥老是想浪,不想好好学习,这不行啊,得想点办法,多少做点努力,于是就自己给自己写了个打卡程序; 该程序基于Sqlite数据库,实现一个简单的打卡功能,该函数具有自动初始化的功能…...

在掌握C#基础上再学习C语言
C#和C语言虽然名字相似,但它们在很多方面都有很大的区别。 首先,C#是一种面向对象的语言,而C语言是过程化的语言。这意味着C#具有更丰富的语言特性,如类、接口、继承和多态性等,而C语言则更侧重于直接对计算机硬件进行…...

HTML5 <body> 标签
HTML <body> 标签 实例 一个简单的 HTML 文档,包含尽可能少的必需的标签: <!DOCTYPE html> <html> <head> <meta charset"utf-8"> <title>文档标题</title> </head><body> 文档内容…...

(链表)反转链表
文章目录前言:问题描述:解题思路:代码实现:总结:前言: 此篇是针对链表的经典练习。 问题描述: 给定一个单链表的头结点pHead(该头节点是有值的,比如在下图,它的val是1…...
deb文件如何安装到iphone方法分享
Cydia或同类APT管理软件在线安装 Cydia或同类APT管理软件在线安装,这个是最佳的安装方式,因为通常无需考虑依赖关系,但缺点是对网络的要求比较高;命令行中以dpkg-iXXX.deb的形式安装,好处是可以以通配符一次性安装多个deb,而且也可以直接看到脚本的运行状况和安装成功/失…...

mongodb和mysql双写数据一致性问题
文章目录 我们是如何用MongoDB的如何保证双写一致性?先写数据库,再写MongoDB先写MongoDB,再写数据库用户修改操作如何保存数据如何清理新增的垃圾数据定时删除随机删除我们是如何用MongoDB的 MongoDB是一个高可用、分布式的文档数据库,用于大容量数据存储。文档存储一般用…...

Databend 开源周报第 88 期
Databend 是一款现代云数仓。专为弹性和高效设计,为您的大规模分析需求保驾护航。自由且开源。即刻体验云服务:https://app.databend.com 。 Whats On In Databend 探索 Databend 本周新进展,遇到更贴近你心意的 Databend 。 Support Eager…...
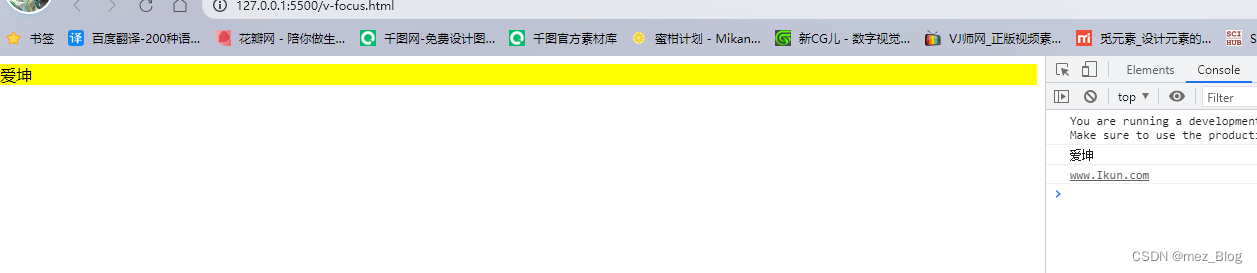
Vue3学习笔记(9.4)
Vue3自定义指令 除了默认设置的核心指令(v-model和v-show),Vue也允许注册自定义指令。 下面我们注册一个全局指令v-focus,该指令的功能是在页面加载时,元素获得焦点: <!--* Author: RealRoad10834252…...
 错误)
导入 Excel 文件时,抛出 413 (Request Entity Too Large) 错误
Excel文件大小:8MB 异常信息:413 (Request Entity Too Large) 环境:IIS10PHP7.2.33 依次检查如下几项: 一、php.ini Maximum amount of memory a script may consume (128MB) 限制代码消耗的最大内存,默认128…...

Verilog学习笔记1——关键词、运算符、数据类型、function/task、initial/always、generate
文章目录前言一、关键词二、运算符三、数据类型1、基本类型:reg、wire、integer、parameter四、条件语句五、循环语句1、for2、generate六、function和task七、initial和always1、initial和always相同点和区别2、always和assign语句区别前言 2023.4.4 2023.4.7 补充…...

Legado-Harmony:免费开源阅读器打造个性化电子书库终极指南
Legado-Harmony:免费开源阅读器打造个性化电子书库终极指南 【免费下载链接】legado-Harmony 开源阅读鸿蒙版仓库 项目地址: https://gitcode.com/gh_mirrors/le/legado-Harmony legado-Harmony是一款专为鸿蒙系统设计的免费开源阅读应用,为用户提…...

React可访问性开发:如何构建符合A11y标准的React组件
React可访问性开发:如何构建符合A11y标准的React组件 【免费下载链接】react-faq A collection of links to help answer your questions about React.js 项目地址: https://gitcode.com/gh_mirrors/re/react-faq React作为现代前端开发的主流框架࿰…...

基于MCP协议构建AI Agent与Atlassian生态的智能集成实践
1. 项目概述与核心价值最近在折腾AI Agent的生态,特别是如何让它们更好地融入我们日常的开发与项目管理流程。一个绕不开的话题就是MCP(Model Context Protocol),它本质上为AI模型提供了一个标准化的方式来发现、调用和使用外部工…...

本地部署Qwen大模型:从量化加载到性能优化的完整实践指南
1. 项目概述:从开源大模型到个人AI助手的跃迁最近在折腾本地部署大语言模型,发现了一个宝藏项目——QwenLM/Qwen。这可不是一个简单的模型仓库,而是一个由通义千问团队打造的开源大语言模型家族。简单来说,它让你能在自己的电脑或…...

实战指南:深度解析markmap思维导图转换架构与多格式输出优化
实战指南:深度解析markmap思维导图转换架构与多格式输出优化 【免费下载链接】markmap Build mindmaps with plain text 项目地址: https://gitcode.com/gh_mirrors/ma/markmap markmap是一个强大的开源工具,能够将结构化的Markdown文本转换为交互…...

酒吧数字化方案:Java德州扑克小酒馆扫码点餐预约系统源码
在消费升级与数字化转型的大背景下,中小型德州扑克小酒馆的运营模式正逐步从“人工主导”向“数字化赋能”转变。不同于传统酒吧,德州扑克小酒馆以“休闲娱乐餐饮服务”为核心,其运营痛点集中在点餐效率低、预约管理乱、桌台调度难、合规管控…...

实测Taotoken多模型聚合调用的响应延迟与稳定性观感
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 实测Taotoken多模型聚合调用的响应延迟与稳定性观感 在项目开发中,我们常常需要接入不同的大模型来满足多样化的需求。…...

开源阅读鸿蒙版:打造你的专属数字图书馆,重获阅读自由
开源阅读鸿蒙版:打造你的专属数字图书馆,重获阅读自由 【免费下载链接】legado-Harmony 开源阅读鸿蒙版仓库 项目地址: https://gitcode.com/gh_mirrors/le/legado-Harmony 你是否厌倦了在多个阅读应用间来回切换?是否对层出不穷的广告…...
)
告别卡顿!在Windows上用VirtualBox+Ubuntu 20.04搭建涂鸦Wi-Fi SoC开发环境(保姆级避坑指南)
告别卡顿!在Windows上用VirtualBoxUbuntu 20.04搭建涂鸦Wi-Fi SoC开发环境(保姆级避坑指南) 嵌入式开发环境搭建往往是工程师面临的第一个挑战。当你在Windows系统上尝试运行Linux虚拟机进行涂鸦Wi-Fi SoC开发时,可能会遇到各种性…...

Postman导入导出避坑指南:为什么你的环境变量导入后不生效?
Postman环境变量导入失效深度解析与解决方案 当你在团队协作或项目迁移时,精心配置的Postman环境变量导入后却神秘消失——这种挫败感每个开发者都经历过。本文将揭示Postman变量系统的底层机制,通过三个典型故障场景还原真实问题根源,并提供…...