TensorRT的Python接口解析
TensorRT的Python接口解析

文章目录
- TensorRT的Python接口解析
- 4.1. The Build Phase
- 4.1.1. Creating a Network Definition in Python
- 4.1.2. Importing a Model using the ONNX Parser
- 4.1.3. Building an Engine
- 4.2. Deserializing a Plan
- 4.3. Performing Inference
点此链接加入NVIDIA开发者计划
本章说明 Python API 的基本用法,假设您从 ONNX 模型开始。 onnx_resnet50.py示例更详细地说明了这个用例。
Python API 可以通过tensorrt模块访问:
import tensorrt as trt
4.1. The Build Phase
要创建构建器,您需要首先创建一个记录器。 Python 绑定包括一个简单的记录器实现,它将高于特定严重性的所有消息记录到stdout 。
logger = trt.Logger(trt.Logger.WARNING)
或者,可以通过从ILogger类派生来定义您自己的记录器实现:
class MyLogger(trt.ILogger):def __init__(self):trt.ILogger.__init__(self)def log(self, severity, msg):pass # Your custom logging implementation herelogger = MyLogger()
然后,您可以创建一个构建器:
builder = trt.Builder(logger)
4.1.1. Creating a Network Definition in Python
创建构建器后,优化模型的第一步是创建网络定义:
network = builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))为了使用 ONNX 解析器导入模型,需要EXPLICIT_BATCH标志。有关详细信息,请参阅显式与隐式批处理部分。
4.1.2. Importing a Model using the ONNX Parser
现在,需要从 ONNX 表示中填充网络定义。您可以创建一个 ONNX 解析器来填充网络,如下所示:
parser = trt.OnnxParser(network, logger)
然后,读取模型文件并处理任何错误:
success = parser.parse_from_file(model_path)
for idx in range(parser.num_errors):print(parser.get_error(idx))if not success:pass # Error handling code here
4.1.3. Building an Engine
下一步是创建一个构建配置,指定 TensorRT 应该如何优化模型:
config = builder.create_builder_config()这个接口有很多属性,你可以设置这些属性来控制 TensorRT 如何优化网络。一个重要的属性是最大工作空间大小。层实现通常需要一个临时工作空间,并且此参数限制了网络中任何层可以使用的最大大小。如果提供的工作空间不足,TensorRT 可能无法找到层的实现:
config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, 1 << 20) # 1 MiB指定配置后,可以使用以下命令构建和序列化引擎:
serialized_engine = builder.build_serialized_network(network, config)将引擎保存到文件以供将来使用可能很有用。你可以这样做:
with open(“sample.engine”, “wb”) as f:f.write(serialized_engine)
4.2. Deserializing a Plan
要执行推理,您首先需要使用Runtime接口反序列化引擎。与构建器一样,运行时需要记录器的实例。
runtime = trt.Runtime(logger)然后,您可以从内存缓冲区反序列化引擎:
engine = runtime.deserialize_cuda_engine(serialized_engine)如果您需要首先从文件加载引擎,请运行:
with open(“sample.engine”, “rb”) as f:serialized_engine = f.read()
4.3. Performing Inference
引擎拥有优化的模型,但要执行推理需要额外的中间激活状态。这是通过IExecutionContext接口完成的:
context = engine.create_execution_context()
一个引擎可以有多个执行上下文,允许一组权重用于多个重叠的推理任务。 (当前的一个例外是使用动态形状时,每个优化配置文件只能有一个执行上下文。)
要执行推理,您必须为输入和输出传递 TensorRT 缓冲区,TensorRT 要求您在 GPU 指针列表中指定。您可以使用为输入和输出张量提供的名称查询引擎,以在数组中找到正确的位置:
input_idx = engine[input_name]
output_idx = engine[output_name]
使用这些索引,为每个输入和输出设置 GPU 缓冲区。多个 Python 包允许您在 GPU 上分配内存,包括但不限于 PyTorch、Polygraphy CUDA 包装器和 PyCUDA。
然后,创建一个 GPU 指针列表。例如,对于 PyTorch CUDA 张量,您可以使用data_ptr()方法访问 GPU 指针;对于 Polygraphy DeviceArray ,使用ptr属性:
buffers = [None] * 2 # Assuming 1 input and 1 output
buffers[input_idx] = input_ptr
buffers[output_idx] = output_ptr
填充输入缓冲区后,您可以调用 TensorRT 的execute_async方法以使用 CUDA 流异步启动推理。
首先,创建 CUDA 流。如果您已经有 CUDA 流,则可以使用指向现有流的指针。例如,对于 PyTorch CUDA 流,即torch.cuda.Stream() ,您可以使用cuda_stream属性访问指针;对于 Polygraphy CUDA 流,使用ptr属性。
接下来,开始推理:
context.execute_async_v2(buffers, stream_ptr)通常在内核之前和之后将异步memcpy()排入队列以从 GPU 中移动数据(如果数据尚不存在)。
要确定内核(可能还有memcpy() )何时完成,请使用标准 CUDA 同步机制,例如事件或等待流。例如,对于 Polygraphy,使用:
stream.synchronize()如果您更喜欢同步推理,请使用execute_v2方法而不是execute_async_v2 。
更多精彩内容:
https://www.nvidia.cn/gtc-global/?ncid=ref-dev-876561
相关文章:
TensorRT的Python接口解析
TensorRT的Python接口解析 文章目录TensorRT的Python接口解析4.1. The Build Phase4.1.1. Creating a Network Definition in Python4.1.2. Importing a Model using the ONNX Parser4.1.3. Building an Engine4.2. Deserializing a Plan4.3. Performing Inference点此链接加入…...

【信管11.5】合同、采购、招投标相关法规
合同、采购、招投标相关法规关于法律法规相关的内容,其实并没什么可以多说的,我也只是列出来,大家挑着背吧。当然,这里也不都是完完全全的法律条文,有一些也可能是一些归纳总结。更具体的内容大家可以参考教材以及查阅…...

使用 CSS 变量更改多个元素样式
使用 CSS 变量更改多个元素样式 var() 函数用于插入自定义的属性值,如果一个属性值在多处被使用,该方法就很有用。 custom-property-name 是必需的, 自定义属性的名称,必需以 – 开头。 value 可选。备用值,在属性不存在的时候使…...
设计模式)
面试题(二十五)设计模式
1. 设计模式 1.1 说一说设计模式的六大原则 参考答案 单一职责原则 一个类,应当只有一个引起它变化的原因;即一个类应该只有一个职责。 就一个类而言,应该只专注于做一件事和仅有一个引起变化的原因,这就是所谓的单一职责原则…...
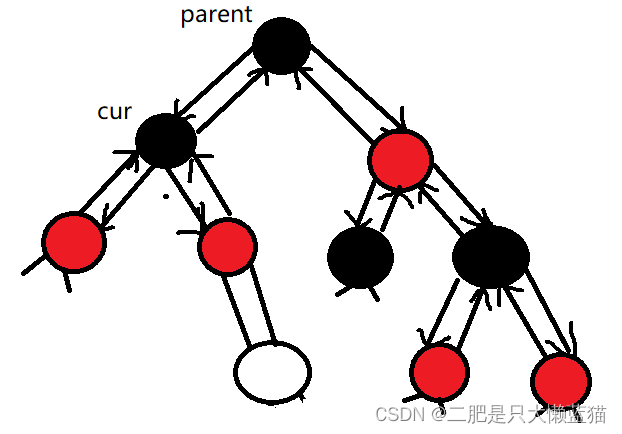
使用红黑树模拟实现map和set
在STL的源代码中,map和set的底层原理都是红黑树。但这颗红黑树跟我们单独写的红黑树不一样,它需要改造一下: 改造红黑树 节点的定义 因为map和set的底层都是红黑树。而且map是拥有键值对pair<K,V>的,而set是没有键值对&a…...

【django项目开发】用户登录后缓存权限到redis中(十)
这里写目录标题一、权限的数据的特点二、首先settings.py文件中配置redis连接redis数据库一、权限的数据的特点 需要去数据库中频繁的读和写,为了项目提高运行效率,可以把用户的权限在每次登录的时候都缓存到redis中。这样的话,权限判断的中…...
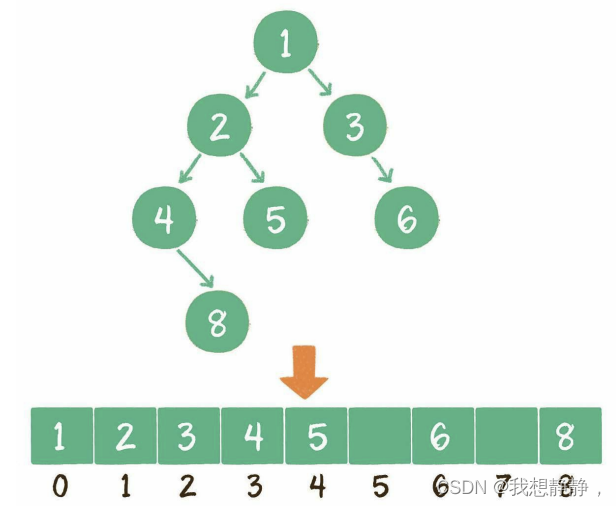
算法总结c++
文章目录基本概念时间复杂度空间复杂度基本结构1. 数组前缀和差分数组快慢指针(索引)左右指针(索引)盛水容器三数之和最长回文子串2. 链表双指针删除链表的倒数第 n 个结点翻转链表递归将两个升序链表合并为一个新的 升序 链表链表翻转3. 散列表twoSum无…...
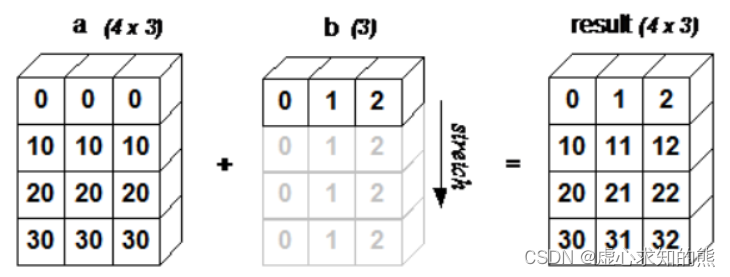
Python 之 NumPy 切片索引和广播机制
文章目录一、切片和索引1. 一维数组2. 二维数组二、索引的高级操作1. 整数数组索引2. 布尔数组索引三、广播机制1. 广播机制规则2. 对于广播规则另一种简单理解一、切片和索引 ndarray 对象的内容可以通过索引或切片来访问和修改(),与 Pytho…...
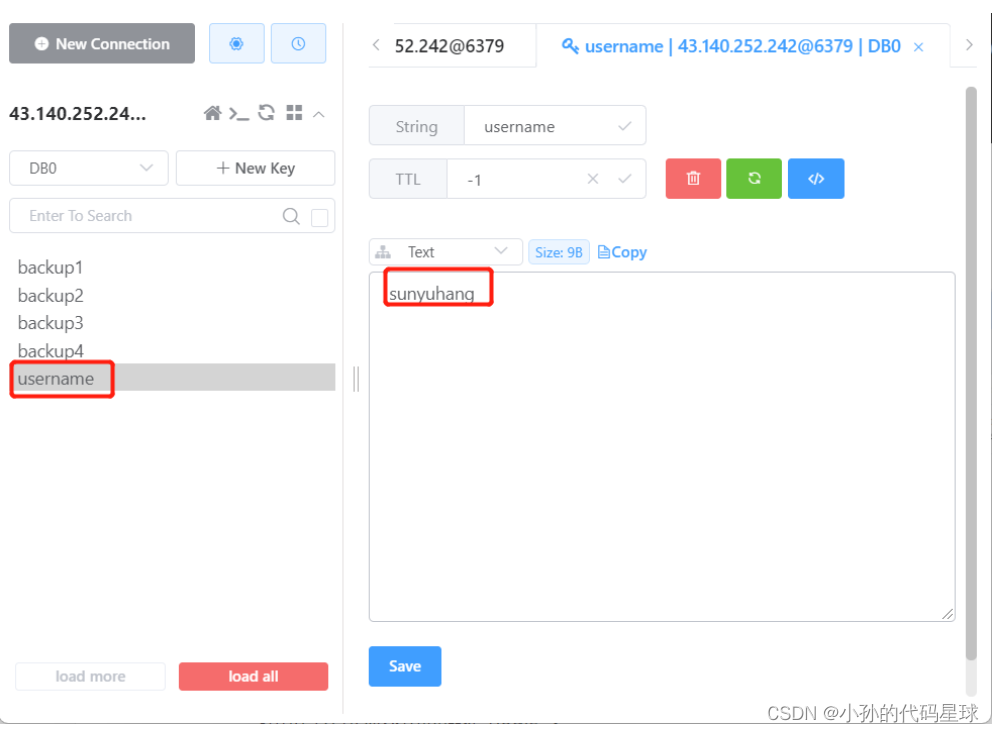
Redis【包括Redis 的安装+本地远程连接】
Redis 一、为什么要用缓存? 缓存定义 缓存是一个高速数据交换的存储器,使用它可以快速的访问和操作数据。 程序中的缓存 在我们程序中,如果没有使用缓存,程序的调用流程是直接访问数据库的; 如果多个程序调用一个数…...
深度学习训练营_第P3周_天气识别
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍦 参考文章:Pytorch实战 | 第P3周:彩色图片识别:天气识别**🍖 原作者:K同学啊|接辅导、项目定制**␀ 本次实验有两个新增任务&…...
)
“华为杯”研究生数学建模竞赛2006年-【华为杯】C题:维修线性流量阀时的内筒设计问题(附获奖论文及matlab代码)
赛题描述 油田采油用的油井都是先用钻机钻几千米深的孔后,再利用固井机向四周的孔壁喷射水泥砂浆得到水泥井管后形成的。固井机上用来控制砂浆流量的阀是影响水泥井管质量的关键部件,但也会因磨损而损坏。目前我国还不能生产完整的阀体,固井机仍依赖进口。由于损坏的内筒已…...

数据结构:带环单链表基础OJ练习笔记(leetcode142. 环形链表 II)(leetcode三题大串烧)
目录 一.前言 二.leetcode160. 相交链表 1.问题描述 2.问题分析与求解 三.leetcode141. 环形链表 1.问题描述 2.代码思路 3.证明分析 下一题会用到的重要小结论: 四.leetcode142. 环形链表 II 1.问题描述 2.问题分析与求解 Judgecycle接口…...

数模美赛如何找数据 | 2023年美赛数学建模必备数据库
2023美赛资料分享/思路答疑群:322297051 欧美相关统计数据(一般美赛这里比较多) 1、http://www.census.gov/ 美国统计局(统计调查局或普查局)官方网站 The Census Bureau Web Site provides on-line access to our …...

SSTI漏洞原理及渗透测试
模板引擎(Web开发中) 是为了使 用户界面 和 业务数据(内容)分离而产生的,它可以生成特定格式的文档, 利用模板引擎来生成前端的HTML代码,模板引擎会提供一套生成HTML代码的程序,之后…...
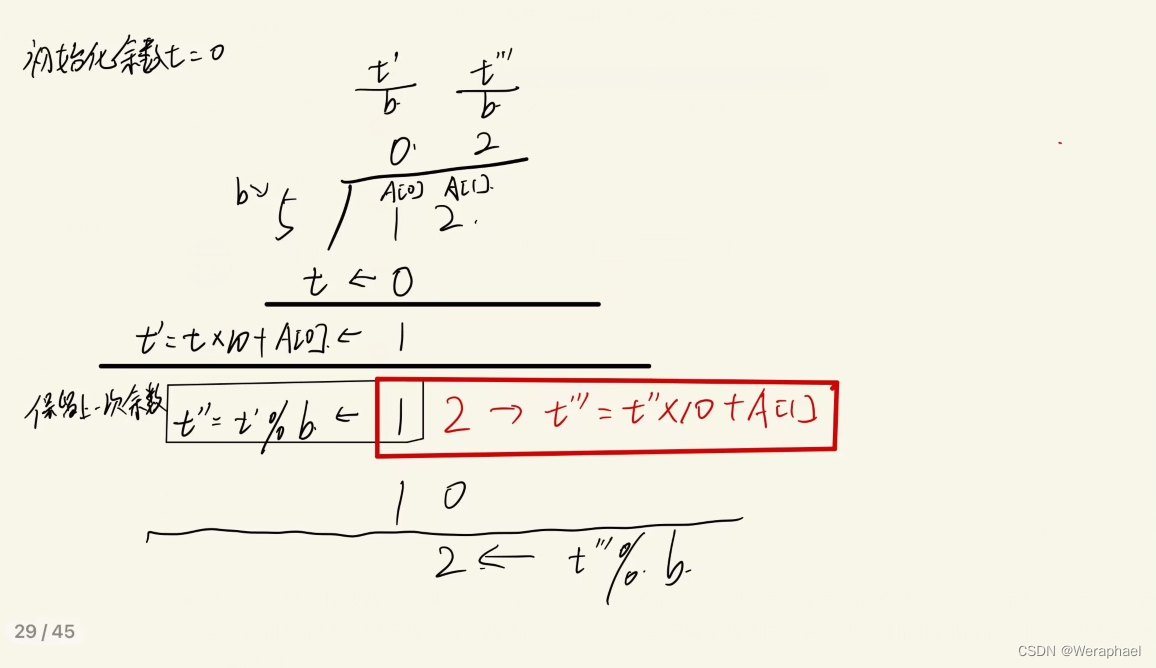
【算法基础】高精度除法
👦个人主页:Weraphael ✍🏻作者简介:目前是C语言 算法学习者 ✈️专栏:【C/C】算法 🐋 希望大家多多支持,咱一起进步!😁 如果文章对你有帮助的话 欢迎 评论💬…...
, loss.backward(), optimizer.step()的理解及使用)
optimizer.zero_grad(), loss.backward(), optimizer.step()的理解及使用
optimizer.zero_grad,loss.backward,optimizer.step用法介绍optimizer.zero_grad():loss.backward():optimizer.step():用法介绍 这三个函数的作用是将梯度归零(optimizer.zero_grad())&#x…...

融资、量产和一栈式布局,这家Tier 1如此备战高阶智驾决赛圈
作者 | Bruce 编辑 | 于婷从早期的ADAS,到高速/城市NOA,智能驾驶的竞争正逐渐升级,这对于车企和供应商的核心技术和产品布局都是一个重要的考验。 部分智驾供应商已经在囤积粮草,响应变化。 2023刚一开年,智能驾驶领域…...
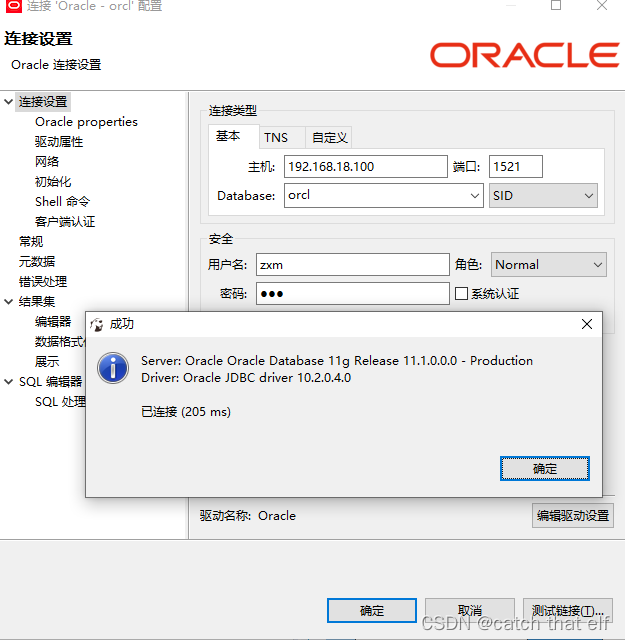
centos7.8安装oralce11g
文章目录环境安装文件准备添加用户操作系统环境配置解压安装问题解决创建用户远程连接为了熟悉rman备份操作,参照大神的博客在centos中安装了一套oracle11g,将安装步骤记录如下环境安装文件准备 这里准备一台centos7.8 虚拟机 配置ip 192.168.18.100 主…...

【蓝桥杯集训·每日一题】AcWing 3956. 截断数组
文章目录一、题目1、原题链接2、题目描述二、解题报告1、思路分析2、时间复杂度3、代码详解三、知识风暴一维前缀和一、题目 1、原题链接 3956. 截断数组 2、题目描述 给定一个长度为 n 的数组 a1,a2,…,an。 现在,要将该数组从中间截断,得到三个非空子…...
万丈高楼平地起:Linux常用命令
目录 系统管理命令 man命令 ls命令 cd命令 useradd命令 passwd命令 free命令 whoami命令 ps命令 date命令 pwd命令 shutdown命令 文件目录管理命令 touch命令 cat命令 mkdir命令 rm命令 cp命令 mv命令 find命令 more指令 less指令 head指令 tail指令 …...

动手写一个 JVM 调优学习项目:6 个真实场景带你掌握性能优化
动手写一个 JVM 调优学习项目:6 个真实场景带你掌握性能优化 项目地址: https://gitee.com/jiucenglou/jvm-tuning-lab 技术栈: Java 8 Maven 适合人群: Java 开发者、性能调优初学者、面试准备者 🤔 为什么写这个项目? 在实际开发和面试中…...

告别本地卡顿!用Pycharm 2023.3远程连接Spark集群,5步搞定开发环境
告别本地卡顿!用Pycharm 2023.3远程连接Spark集群,5步搞定开发环境 当你的笔记本风扇开始像喷气发动机一样轰鸣,而PySpark脚本才处理到第3万条数据时,就该考虑换个战场了。去年我用一台16GB内存的MacBook Pro分析800万条电商日志&…...

别再死记公式了!用“信号与系统”的视角,5分钟看懂卡尔曼滤波与互补滤波的本质区别
从频域视角解析卡尔曼滤波与互补滤波的本质差异 在机器人控制和姿态估计领域,数据融合算法始终是工程师们关注的焦点。当我们面对陀螺仪和加速度计这两种各具特色的传感器数据时,如何有效融合它们的长处,同时规避各自的短板,成为构…...
)
用C++‘数1’这道题,带你彻底搞懂整数位分离的循环技巧(附避坑点)
用C‘数1’这道题,带你彻底搞懂整数位分离的循环技巧(附避坑点) 在编程学习的道路上,整数位分离是一个看似简单却暗藏玄机的基础操作。许多初学者在解决"统计数字中1的个数"这类问题时,往往能写出大致正确的…...

基于SpringBoot的B2C生鲜电商平台毕设源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot与Vue框架的B2C生鲜电商平台以解决当前生鲜电商领域存在的核心问题包括供应链管理效率低下导致的商品损耗率居高不下用户端体…...

别再手动算归一化了!用Origin9.1的‘列公式’功能一键搞定数据预处理
用Origin9.1列公式功能高效实现数据归一化:从原理到实战 科研数据处理中,归一化是消除量纲影响、提升分析结果可比性的关键步骤。传统手动计算不仅耗时费力,还容易因公式输入错误导致结果偏差。Origin9.1的"列公式"功能(…...

Verilog分频器进阶:从6分频到1.5分频的实战设计与波形分析
1. 分频器基础与设计思路 在数字电路设计中,时钟信号就像人的心跳一样重要。分频器的作用,就是把这个"心跳"调整到我们需要的节奏。简单来说,分频器就是把输入时钟的频率降低N倍,得到一个新的时钟信号。比如6分频&#…...

深入解析:parseInt 到底有几个参数?
🔢 深入解析:parseInt 到底有几个参数? 🤔 parseInt 的签名 parseInt 函数接收 两个 参数: parseInt(string, radix)string (必填):要被解析的值。如果参数不是字符串,会先转换为字符串。rad…...

Python 爬虫数据处理:富文本爬虫内容格式化还原
前言 互联网平台发布的文章、资讯、公众号推文、论坛帖子、商品详情、教程文案等内容,普遍以富文本形式存在,融合文字、段落层级、换行缩进、加粗引用、列表排版、超链接、分段结构等多种格式元素。普通爬虫仅能抓取原始 HTML 源码或纯文本内容…...

从愚人节实验室踩踏事件看资源分配、排队制度与群体行为管理
1. 项目概述:一个愚人节引发的实验室“踩踏事件” 在任何一个技术驱动的组织里,无论是大型研究院、芯片设计公司,还是一个初创的硬件团队,资源分配永远是一个微妙而充满博弈的话题。设备、工具、甚至是某个紧俏的软件许可证&#…...