C++-c语言词法分析器
一、运行截图
- 对于 Test.c 的词法分析结果

- 对于词法分析器本身的源代码的分析结果
二、主要功能
经过不断的修正和测试代码,分析测试结果,该词法分析器主要实现了以下功能:
1. 识别关键字
- 实验要求:if else while do for main return int float double char。以及:
- 数据类型关键字 void unsigned long enum static short signed struct union;
- 控制语句关键字 continue break switch case default goto;
- 存储类型关键字 auto static extern register;
- 其他关键字 const volatile sizeof typedef;
- 预编译指令 #xxx。
2. 识别运算符
- 实验要求:= + - * / % < <= > >= != ==
- 算术运算符 ++ –
- 逻辑运算符 && || !
- 位运算符 & | ^ ~ << >>
- 赋值运算符 += -= *= /= %= <<= >>= &= ^= |=
- 杂项运算符 , ? : -> .
3. 识别界限符
- 实验要求:; ( ) { }
- 其他:[ ]
4. 识别常量
- 实验要求:无符号十进制整型常量,正规式为:(1-9)(0-9)*
- 无符号二进制整型常量,正规式为: 0(B|b)(0-1)*
- 无符号八进制整型常量,正规式为: 0(0-7)*
- 无符号十六进制整型常量,正规式为: 0(X|x)(0-9|a-f|A-F)*
- 字符串常量,正规式为: “(all char)*”
- 字符常量,正规式为: ‘(all char)*’
5. 识别标识符
- 实验要求:以字母开头,正规式为:letter(letter|digit)*
- 以下划线开头,正规式为:_ (letter|digit|$ | _) *
- 以美元符号开头,正规式为:$ (letter|digit|$ | _ ) *
6. 识别其他符号
- 实验要求:空格符(’ ‘),制表符(’\t’),换行符(‘\n’)
- 单行注释(“//”)
- 多行注释(“/*”)
- 转义字符(‘\’)
特别的,在预处理阶段,识别单/多行注释时,遇到了一个小问题,由于要支持字符串常量和字符常量,而该常量中可能包含//,/*,导致将字符串内容识别为注释,另外,由于需要支持转义字符‘\’的存在,正确识别的字符串,也成为了一大问题,在多次修改匹配代码后,终于将问题解决。
7. 词法高亮
利用词法分析的token结果,按不同的类型码,对源代码文件进行着色输出。
运算符和界限符:黄色。
关键字:淡蓝色。
无符号二,八,十,十六进制整型常量:淡红色。
标识符:淡绿色。
字符串常量:淡黄色。
8. 词法错误处理
当朴素匹配或者正规匹配失败,或者匹配结束后,回退字符之前,出现非法字符时,对相应的错误进行记录并在分析完毕后进行输出。
目前已处理错误:未找到匹配的界限符()]}),多行注释未找到结束符(*/),出现未定义的字符(@¥`)。
值得注意的一点,当遇到未处理的词法错误时,程序存在可能的崩溃隐患。
三、项目内容
1. 测试代码 Test.c
/*** used to test keywords* //ohhhhhhhhhhhhhhh*/
void $Func$ForKey_2(int a, unsigned b)
{
start: if (1){}else{}while (1) { continue; }do{}while (1);for (;;){ }}switch (1){case 1: break;default: break;}enum { run };goto start;
}struct FStruct{int val = 0000x1234;};
union FUnion{int val = 0B1 + 0b1 + 01 + 0X1 + 0x1;};
extern i;// used to test operator
void __FuncForOperation5(const float c, long d, signed e, short f)
{typedef int Moota;register int i = 1234 + sizeof(Moota) + sizeof("/**/hello world//\\") + sizeof('\a');volatile int j = i + 1 - 1 * 1 / 1 % 1 <= 1 < 1 > 1 >= 1 != 1 == 1;auto int m = (i++) + (++i) + (i && i || i & i & i | i ^ i << 1) + i >> 1 + ~i;m += 1;m -= 2;m *= 3;m / 4;m %= 5;m <<= 6;m >>= 7;m &= 8;m |= 9;m ^= 10;m = m ? 1 : 0;struct FStruct* Ohhh;Ohhh->val;struct FStruct Emmm;Emmm.val;
}/*
int main(void)
{$Func$ForKey_2(1, 1);__FuncForOperation5(1, 1, 1, 1);return 0;
}
2. 项目代码 LexicalAnalyzer.cpp
/** Copyright Moota, Private. All Rights Reserved. */#include <iostream>
#include <map>
#include <stack>
#include <vector>
#include <string>
#include <fstream>
#include "Windows.h"/*** 词法分析器* 可以识别的单词种类包括以下部分(括号代表实验要求之外的单词)* * (1) 关键字* if else while do for main return int float double char* (数据类型关键字 void unsigned long enum static short signed struct union)* (控制语句关键字 continue break switch case default goto)* (存储类型关键字 auto static extern register)* (其他关键字 const volatile sizeof typedef)* (预编译指令 #xxx)* * (2) 运算符* = + - * / % < <= > >= != ==* (算术运算符 ++ --)* (关系运算符)* (逻辑运算符 && || !)* (位运算符 & | ^ ~ << >>)* (赋值运算符 += -= *= /= %= <<= >>= &= ^= |=)* (杂项运算符 , ? : -> .)* * (3) 界限符* ; ( ) { }* ([ ])* * (4) 常量* 正规式为 digit1 digit2*,只考虑无符号十进制整型常量,digit1包括1-9,digit2包括0-9)* (无符号二进制整型常量 0(B|b)(0-1)*)* (无符号八进制整型常量 0(0-7)*)* (无符号十六进制整型常量 0(X|x)(0-9|a-f|A-F)*)* (字符串常量 "(all char)*" )* (字符常量 '(all char)*' )* * (5) 标识符* 正规式为 letter(letter|digit)*,区分大小写* (_(letter|digit|$)*)* ($(letter|digit|$)*)* * (6) 其他符号* 空格符(' '),制表符('\t'),换行符('\n'),单行多行注释("//","\/\*") 应该在词法分析阶段被忽略*/
class FLexicalAnalyzer
{
public:FLexicalAnalyzer(){SetConsoleTitle(L"Lexical Analyzer V1.2.6");ShowWindow(GetForegroundWindow(), SW_MAXIMIZE);SetConsoleOutputCP(65001);}private:// 工具函数// 字符是否小写static inline bool IsLower(char Data){return 'a' <= Data and Data <= 'z';}// 字符是否大写static inline bool IsUpper(char Data){return 'A' <= Data and Data <= 'Z';}// 字符是否是字母字符static inline bool IsLetter(char Data){return IsLower(Data) || IsUpper(Data);}// 字符是否是数字字符static inline bool IsDigit(char Data){return '0' <= Data and Data <= '9';}// 读取文件std::string ReadFile(const std::string& FilePath){std::string Result;std::ifstream InputFile(FilePath, std::ios::in);if (!InputFile.is_open()){std::cerr << "The file failed to open, perhaps you need to change the file path." << "\n";return Result;}char Ch;while (InputFile.peek() != EOF){InputFile.get(Ch);Result += Ch;}InputFile.close();TokenizeData.FilePath = FilePath;return Result;}// 保存文件static void SaveFile(const std::string& Data, const std::string& FilePath){std::ofstream OutputFile(FilePath, std::ios::out);OutputFile << Data;OutputFile.close();}private:std::map<std::string, int> KeywordMap; // 关键字符号表std::map<std::string, int> RegularMap; // 正规(常量,标识符)符号表std::map<std::string, int> SpecialMap; // 特殊(运算符,界限符)符号表// 单词序列数据struct FTokenData{std::string Token; // 单词符号int Code = 0; // 类别码};// 词法分析数据struct FTokenizeData{std::string FilePath; // 文件地址std::string Result; // 最终结果std::string Data; // 待分析数据size_t Size = 0; // 数据长度size_t Index = 0; // 当前字符索引char Start = ' '; // 当前字符FTokenData TokenData; // 当前符号信息std::stack<int> Delimiter[3]; // 界限符栈size_t Lines = 0; // 词法分析当前行std::vector<std::string> Errors; // 词法分析错误池std::vector<std::string> Warnings; // 词法分析警告池} TokenizeData;/*** 初始化各个符号表*/void Initialize(){KeywordMap["main"] = 1;KeywordMap["if"] = 2;KeywordMap["else"] = 3;KeywordMap["while"] = 4;KeywordMap["do"] = 5;KeywordMap["for"] = 6;KeywordMap["return"] = 7;RegularMap["letter(letter|digit)*"] = 8;RegularMap["digit digit*"] = 9;RegularMap["\"(all char)*\""] = 200;RegularMap["\'(all char)*\'"] = 201;RegularMap["_(letter|digit|$)*"] = 202;RegularMap["$(letter|digit|$)*"] = 203;RegularMap["0(B|b)(0-1)*"] = 204;RegularMap["0(0-7)*"] = 205;RegularMap["0(X|x)(0-9 a-f)*"] = 206;SpecialMap["+"] = 10;SpecialMap["-"] = 11;SpecialMap["*"] = 12;SpecialMap["/"] = 13;SpecialMap["%"] = 14;SpecialMap[">"] = 15;SpecialMap[">="] = 16;SpecialMap["<"] = 17;SpecialMap["<="] = 18;SpecialMap["=="] = 19;SpecialMap["!="] = 20;SpecialMap["="] = 21;SpecialMap[";"] = 22;SpecialMap["("] = 23;SpecialMap[")"] = 24;SpecialMap["{"] = 25;SpecialMap["}"] = 26;SpecialMap["["] = 100;SpecialMap["]"] = 101;SpecialMap[","] = 102;SpecialMap[":"] = 103;SpecialMap["++"] = 104;SpecialMap["--"] = 105;SpecialMap["&&"] = 106;SpecialMap["||"] = 107;SpecialMap["!"] = 108;SpecialMap["&"] = 109;SpecialMap["|"] = 110;SpecialMap["^"] = 111;SpecialMap["~"] = 112;SpecialMap["<<"] = 113;SpecialMap[">>"] = 114;SpecialMap["+="] = 115;SpecialMap["-="] = 116;SpecialMap["*="] = 117;SpecialMap["/="] = 118;SpecialMap["%="] = 119;SpecialMap["<<="] = 120;SpecialMap[">>="] = 121;SpecialMap["&="] = 122;SpecialMap["|="] = 123;SpecialMap["^="] = 124;SpecialMap["?"] = 125;SpecialMap["->"] = 126;SpecialMap["."] = 127;KeywordMap["int"] = 27;KeywordMap["float"] = 28;KeywordMap["double"] = 29;KeywordMap["char"] = 30;KeywordMap["void"] = 31;KeywordMap["unsigned"] = 32;KeywordMap["long"] = 33;KeywordMap["const"] = 34;KeywordMap["continue"] = 35;KeywordMap["break"] = 36;KeywordMap["enum"] = 37;KeywordMap["switch"] = 38;KeywordMap["case"] = 39;KeywordMap["static"] = 40;KeywordMap["auto"] = 41;KeywordMap["short"] = 42;KeywordMap["signed"] = 43;KeywordMap["struct"] = 44;KeywordMap["union"] = 45;KeywordMap["goto"] = 46;KeywordMap["default"] = 47;KeywordMap["extern"] = 48;KeywordMap["register"] = 49;KeywordMap["volatile"] = 50;KeywordMap["sizeof"] = 51;KeywordMap["typedef"] = 52;KeywordMap["#"] = 53;std::cout << "///\n";}/*** 数据预处理* 主要处理制表符('\t')* 空格符将在词法分析时自动进行忽略* 换行符将在词法分析时作为报错的依据*/std::string Preprocess(const std::string& Data){std::string Result;const size_t Size = Data.size();size_t Lines = 0;for (size_t i = 0; i < Size; ++i){if (Data[i] == '"'){Result += Data[i];++i;while (i < Size && Data[i] != '"'){if (Data[i] == '\\'){Result += Data[i];++i;}if (i < Size){Result += Data[i];++i;}}if (Data[i] == '"'){Result += Data[i];}}else if (Data[i] == '\''){Result += Data[i];++i;while (i < Size && Data[i] != '\''){if (Data[i] == '\\'){Result += Data[i];++i;}Result += Data[i];++i;}if (Data[i] == '\''){Result += Data[i];}}else if (Data[i] == '/' && (i + 1) < Size && Data[i + 1] == '/')// 处理单行注释{while (i < Size && Data[i] != '\n'){++i;}if (Data[i] == '\n'){++Lines;Result += Data[i];}}else if (Data[i] == '/' && (i + 1) < Size && Data[i + 1] == '*')// 处理多行注释{i = i + 2;bool IsFound = false;while (i < Size){if (Data[i] == '\n'){++Lines;}if (Data[i] == '*' && (i + 1) < Size && Data[i + 1] == '/'){IsFound = true;i = i + 2;break;}++i;}if (Data[i] == '\n'){++Lines;}if (!IsFound){TokenizeData.Errors.push_back("ERR: " + TokenizeData.FilePath + " " + std::to_string(Lines) + " " + "no matching '*/' symbol was found.");}}else if (Data[i] == '\n'){++Lines;Result += Data[i];}else if (Data[i] == '\t')// 处理制表符{Result += ' ';}else{Result += Data[i];}}return Result;}/*** 获取下一个有效字符,忽略空格符*/bool GetValidChar(){bool Result = false;while (TokenizeData.Index < TokenizeData.Size){TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];if (TokenizeData.Start != ' '){Result = true;break;}}return Result;}/*** 识别以字母为开始符号的* 1. 关键字-letter(letter)** 2. 识别标识符-letter(letter|digit)**/void TokenizeAlpha(){do{TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];}while (IsLetter(TokenizeData.Start) || IsDigit(TokenizeData.Start) || TokenizeData.Start == '$'|| TokenizeData.Start == '_');const auto Found = KeywordMap.find(TokenizeData.TokenData.Token);if (Found != KeywordMap.end()){TokenizeData.TokenData.Code = Found->second;}else{TokenizeData.TokenData.Code = RegularMap["letter(letter|digit)*"];}TokenizeData.Index--;}/*** 识别以数字为开始符号的* 1. 无符号十进制整型常量-digit digit**/void TokenizeDigit(){if ('1' <= TokenizeData.Start && TokenizeData.Start <= '9'){do{TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];}while (IsDigit(TokenizeData.Start));TokenizeData.TokenData.Code = RegularMap["digit digit*"];TokenizeData.Index--;}else{TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];if (TokenizeData.Start == 'B' || TokenizeData.Start == 'b'){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];do{TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];}while (TokenizeData.Start == 0 || TokenizeData.Start == 1);TokenizeData.TokenData.Code = RegularMap["0(B|b)(0-1)*"];TokenizeData.Index--;}else if (TokenizeData.Start == 'X' || TokenizeData.Start == 'x'){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];do{TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];}while (IsDigit(TokenizeData.Start) || ('a' <= TokenizeData.Start and TokenizeData.Start <= 'f') || ('A' <= TokenizeData.Start and TokenizeData.Start <= 'F'));TokenizeData.TokenData.Code = RegularMap["0(X|x)(0-9 a-f)*"];TokenizeData.Index--;}else if ('0' <= TokenizeData.Start and TokenizeData.Start <= '7'){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];do{TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];}while ('0' <= TokenizeData.Start and TokenizeData.Start <= '7');TokenizeData.TokenData.Code = RegularMap["0(0-7)*"];TokenizeData.Index--;}else{TokenizeData.TokenData.Code = RegularMap["digit digit*"];TokenizeData.Index--;}}}/*** 识别以非数字非字母为开始符号的* 1. 运算符* 2. 界限符*/void TokenizeSpecial(){for (auto& Special : SpecialMap){if (TokenizeData.Start == Special.first[0]){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.TokenData.Code = Special.second;break;}}if (TokenizeData.Start == '('){TokenizeData.Delimiter[0].push(TokenizeData.Start);}if (TokenizeData.Start == '['){TokenizeData.Delimiter[1].push(TokenizeData.Start);}else if (TokenizeData.Start == '{'){TokenizeData.Delimiter[2].push(TokenizeData.Start);}else if (TokenizeData.Start == ')'){if (!TokenizeData.Delimiter[0].empty()){TokenizeData.Delimiter[0].pop();}else{TokenizeData.Errors.push_back("ERR: " + TokenizeData.FilePath + " " + std::to_string(TokenizeData.Lines) + " there is an unmatched ')' symbol.");}}else if (TokenizeData.Start == ']'){if (!TokenizeData.Delimiter[1].empty()){TokenizeData.Delimiter[1].pop();}else{TokenizeData.Errors.push_back("ERR: " + TokenizeData.FilePath + " " + std::to_string(TokenizeData.Lines) + " there is an unmatched ']' symbol.");}}else if (TokenizeData.Start == '}'){if (!TokenizeData.Delimiter[2].empty()){TokenizeData.Delimiter[2].pop();}else{TokenizeData.Errors.push_back("ERR: " + TokenizeData.FilePath + " " + std::to_string(TokenizeData.Lines) + " there is an unmatched '}' symbol.");}}else if (TokenizeData.Start == '!'){TokenizeData.TokenData.Code = SpecialMap["!"];TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];if (TokenizeData.Start == '='){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.TokenData.Code = SpecialMap["!="];}else{TokenizeData.Index--;}}else if (TokenizeData.Start == '='){TokenizeData.TokenData.Code = SpecialMap["="];TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];if (TokenizeData.Start == '='){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.TokenData.Code = SpecialMap["=="];}else{TokenizeData.Index--;}}else if (TokenizeData.Start == '<'){TokenizeData.TokenData.Code = SpecialMap["<"];TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];if (TokenizeData.Start == '='){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.TokenData.Code = SpecialMap["<="];}else if (TokenizeData.Start == '<'){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.TokenData.Code = SpecialMap["<<"];TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];if (TokenizeData.Start == '='){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.TokenData.Code = SpecialMap["<<="];}else{TokenizeData.Index--;}}else{TokenizeData.Index--;}}else if (TokenizeData.Start == '>'){TokenizeData.TokenData.Code = SpecialMap[">"];TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];if (TokenizeData.Start == '='){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.TokenData.Code = SpecialMap[">="];}else if (TokenizeData.Start == '>'){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.TokenData.Code = SpecialMap[">>"];TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];if (TokenizeData.Start == '='){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.TokenData.Code = SpecialMap[">>="];}else{TokenizeData.Index--;}}else{TokenizeData.Index--;}}else if (TokenizeData.Start == '+'){TokenizeData.TokenData.Code = SpecialMap["+"];TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];if (TokenizeData.Start == '='){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.TokenData.Code = SpecialMap["+="];}else if (TokenizeData.Start == '+'){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.TokenData.Code = SpecialMap["++"];}else{TokenizeData.Index--;}}else if (TokenizeData.Start == '-'){TokenizeData.TokenData.Code = SpecialMap["-"];TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];if (TokenizeData.Start == '='){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.TokenData.Code = SpecialMap["-="];}else if (TokenizeData.Start == '-'){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.TokenData.Code = SpecialMap["--"];}else if (TokenizeData.Start == '>'){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.TokenData.Code = SpecialMap["->"];}else{TokenizeData.Index--;}}else if (TokenizeData.Start == '*'){TokenizeData.TokenData.Code = SpecialMap["*"];TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];if (TokenizeData.Start == '='){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.TokenData.Code = SpecialMap["*="];}else{TokenizeData.Index--;}}else if (TokenizeData.Start == '/'){TokenizeData.TokenData.Code = SpecialMap["/"];TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];if (TokenizeData.Start == '='){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.TokenData.Code = SpecialMap["/="];}else{TokenizeData.Index--;}}else if (TokenizeData.Start == '%'){TokenizeData.TokenData.Code = SpecialMap["%"];TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];if (TokenizeData.Start == '='){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.TokenData.Code = SpecialMap["%="];}else{TokenizeData.Index--;}}else if (TokenizeData.Start == '&'){TokenizeData.TokenData.Code = SpecialMap["&"];TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];if (TokenizeData.Start == '='){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.TokenData.Code = SpecialMap["&="];}else if (TokenizeData.Start == '&'){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.TokenData.Code = SpecialMap["&&"];}else{TokenizeData.Index--;}}else if (TokenizeData.Start == '|'){TokenizeData.TokenData.Code = SpecialMap["|"];TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];if (TokenizeData.Start == '='){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.TokenData.Code = SpecialMap["|="];}else if (TokenizeData.Start == '|'){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.TokenData.Code = SpecialMap["||"];}else{TokenizeData.Index--;}}else if (TokenizeData.Start == '^'){TokenizeData.TokenData.Code = SpecialMap["^"];TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];if (TokenizeData.Start == '='){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.TokenData.Code = SpecialMap["^="];}else{TokenizeData.Index--;}}else if (TokenizeData.Start == '"'){TokenizeData.TokenData.Code = RegularMap["\"(all char)*\""];TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];while (true){if (TokenizeData.Start == '"'){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];break;}if (TokenizeData.Start == '\\'){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];}TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];}TokenizeData.Index--;}else if (TokenizeData.Start == '\''){TokenizeData.TokenData.Code = RegularMap["\'(all char)*\'"];TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];while (true){if (TokenizeData.Start == '\''){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];break;}if (TokenizeData.Start == '\\'){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];}TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];}TokenizeData.Index--;}else if (TokenizeData.Start == '_'){TokenizeData.TokenData.Code = RegularMap["_(letter|digit|$)*"];do{TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];}while (IsLetter(TokenizeData.Start) || IsDigit(TokenizeData.Start) || TokenizeData.Start == '$' || TokenizeData.Start == '_');TokenizeData.Index--;}else if (TokenizeData.Start == '$'){TokenizeData.TokenData.Code = RegularMap["$(letter|digit|$)*"];do{TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];}while (IsLetter(TokenizeData.Start) || IsDigit(TokenizeData.Start) || TokenizeData.Start == '$' || TokenizeData.Start == '_');TokenizeData.Index--;}else if (TokenizeData.Start == '#'){TokenizeData.TokenData.Code = KeywordMap["#"];TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];while (IsLetter(TokenizeData.Start)){TokenizeData.TokenData.Token += TokenizeData.Start;TokenizeData.Start = TokenizeData.Data[TokenizeData.Index++];}TokenizeData.Index--;}if (TokenizeData.TokenData.Code == 0){TokenizeData.TokenData.Token = TokenizeData.Start;TokenizeData.Errors.push_back("ERR: " + TokenizeData.FilePath + " " + std::to_string(TokenizeData.Lines) + " there is an undefined " +TokenizeData.TokenData.Token + " character whose ascii code is " + std::to_string(static_cast<int>(TokenizeData.TokenData.Token[0])) + ".");}}/*** 单词分析*/std::string Tokenize(const std::string& Data){TokenizeData.Data = Data;TokenizeData.Index = 0;TokenizeData.Size = Data.size();while (GetValidChar()){TokenizeData.TokenData = {"", 0};if (TokenizeData.Start == '\n'){TokenizeData.Lines++;}else if (IsLetter(TokenizeData.Start)){TokenizeAlpha();}else if (IsDigit(TokenizeData.Start)){TokenizeDigit();}else{TokenizeSpecial();}if (!TokenizeData.TokenData.Token.empty()){TokenizeData.Result += "(" + TokenizeData.TokenData.Token + "," + std::to_string(TokenizeData.TokenData.Code) + ")" + "\n";}}return TokenizeData.Result;}/** 打印彩色字* 0=黑色 1=蓝色 2=绿色 3=湖蓝色* 4=红色 5=紫色 6=黄色 7=白色* 8=灰色 9=淡蓝色 10=淡绿色 11=淡浅绿色* 12=淡红色 13=淡紫色 14=淡黄色 15=亮白色* @param ForeColor 字体颜色* @param BackColor 字体背景颜色*/static void SetFontColor(int ForeColor, int BackColor){SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), static_cast<WORD>(ForeColor + BackColor * 0x10));}//模板一下,方便调用,T表示任何可以被cout输出的类型template <typename T>static void CoutWithColor(T t, int ForeColor = 7, int BackColor = 0){SetFontColor(ForeColor, BackColor);std::cout << t;SetFontColor(7, 0);Sleep(4);}/*** 识别单词高亮*/static void Highlight(const std::string& SourceCode, const std::string& TokenData){const size_t CodeSize = SourceCode.size();const size_t ContentSize = TokenData.size();size_t Index = 0;size_t Lines = 0;CoutWithColor(std::to_string(Lines) + "\t", 7);++Lines;for (size_t i = 0; i < CodeSize; ++i){if (SourceCode[i] == '\n'){CoutWithColor(SourceCode[i] + std::to_string(Lines) + "\t", 7);++Lines;}else if (SourceCode[i] == ' ' || SourceCode[i] == '\t'){CoutWithColor(SourceCode[i], 7);}else if (SourceCode[i] == '/' && (i + 1) < CodeSize && SourceCode[i + 1] == '/'){std::string Temp;while (i < CodeSize && SourceCode[i] != '\n'){Temp += SourceCode[i++];}i--;CoutWithColor(Temp, 2);}else if (SourceCode[i] == '/' && (i + 1) < CodeSize && SourceCode[i + 1] == '*'){std::string Temp;Temp += SourceCode[i];Temp += SourceCode[i + 1];i = i + 2;while (i < CodeSize){if (SourceCode[i] == '\n'){CoutWithColor(Temp, 2);CoutWithColor(SourceCode[i] + std::to_string(Lines) + "\t", 7);++Lines;++i;Temp = "";}else if (SourceCode[i] == '*' && (i + 1) < CodeSize && SourceCode[i + 1] == '/'){Temp += SourceCode[i++];Temp += SourceCode[i++];break;}else{Temp += SourceCode[i++];}}CoutWithColor(Temp, 2);i--;}else{std::string Doc;while (Index < ContentSize && TokenData[Index] != '\n'){Doc += TokenData[Index++];}if (TokenData[Index] == '\n'){Index++;}size_t Mid = 0;std::string Token;int Code = 0;// 寻找 , 分隔符for (size_t Pos = Doc.size() - 1; Pos != 0; --Pos){if (Doc[Pos] != ','){Mid = Pos - 1;}else{break;}}// 截取 Tokenfor (size_t Start = 1; Start < Mid; ++Start){Token += Doc[Start];}// 截取 Codefor (size_t Start = Mid + 1; Start < (Doc.size() - 1); ++Start){Code = Code * 10 + (Doc[Start] - '0');}// 判断类型颜色int ForeColor = 15;if ((10 <= Code and Code <= 26) or (100 <= Code and Code <= 127)) // 运算符和界限符{ForeColor = 6;}else if ((1 <= Code and Code <= 7) or (27 <= Code and Code <= 53)) // 关键字{ForeColor = 9;}else if (Code == 9 or (204 <= Code and Code <= 206)) // 无符号二,八,十,十六进制整型常数{ForeColor = 12;}else if (Code == 8 or Code == 202 or Code == 203) // 标识符{ForeColor = 10;}else if (Code == 200 or Code == 201) // 字符串常量{ForeColor = 14;}CoutWithColor(Token, ForeColor);i += Token.size() - 1;}}CoutWithColor("\n", 7);}/*** 显示词法分析结果*/void ShowResult() const{std::cout << "///\n";CoutWithColor("VER: Copyright moota, private. all rights reserved.\n", 7);CoutWithColor("INF: Lexical analysis is finished, " + std::to_string(TokenizeData.Warnings.size()) + " warnings, " +std::to_string(TokenizeData.Errors.size()) + " errors.\n", 14);for (auto& Info : TokenizeData.Warnings){CoutWithColor(Info + "\n", 9);}for (auto& Info : TokenizeData.Errors){CoutWithColor(Info + "\n", 12);}}public:/*** 调试词法分析器*/void Main(){// 初始词法分析器Initialize();// 读取处理文件const std::string Doc = ReadFile("Test.c");SaveFile(Doc, "TestRead.txt");// 预处理读入数据const std::string PreDoc = Preprocess(Doc);SaveFile(PreDoc, "TestPre.txt");// 识别单词符号const std::string Token = Tokenize(PreDoc);SaveFile(Token, "TestToken.txt");// 识别单词高亮Highlight(Doc, Token);// 显示词法分析结果ShowResult();getchar();}
};int main()
{FLexicalAnalyzer LexicalAnalyzer;LexicalAnalyzer.Main();return 0;
}相关文章:
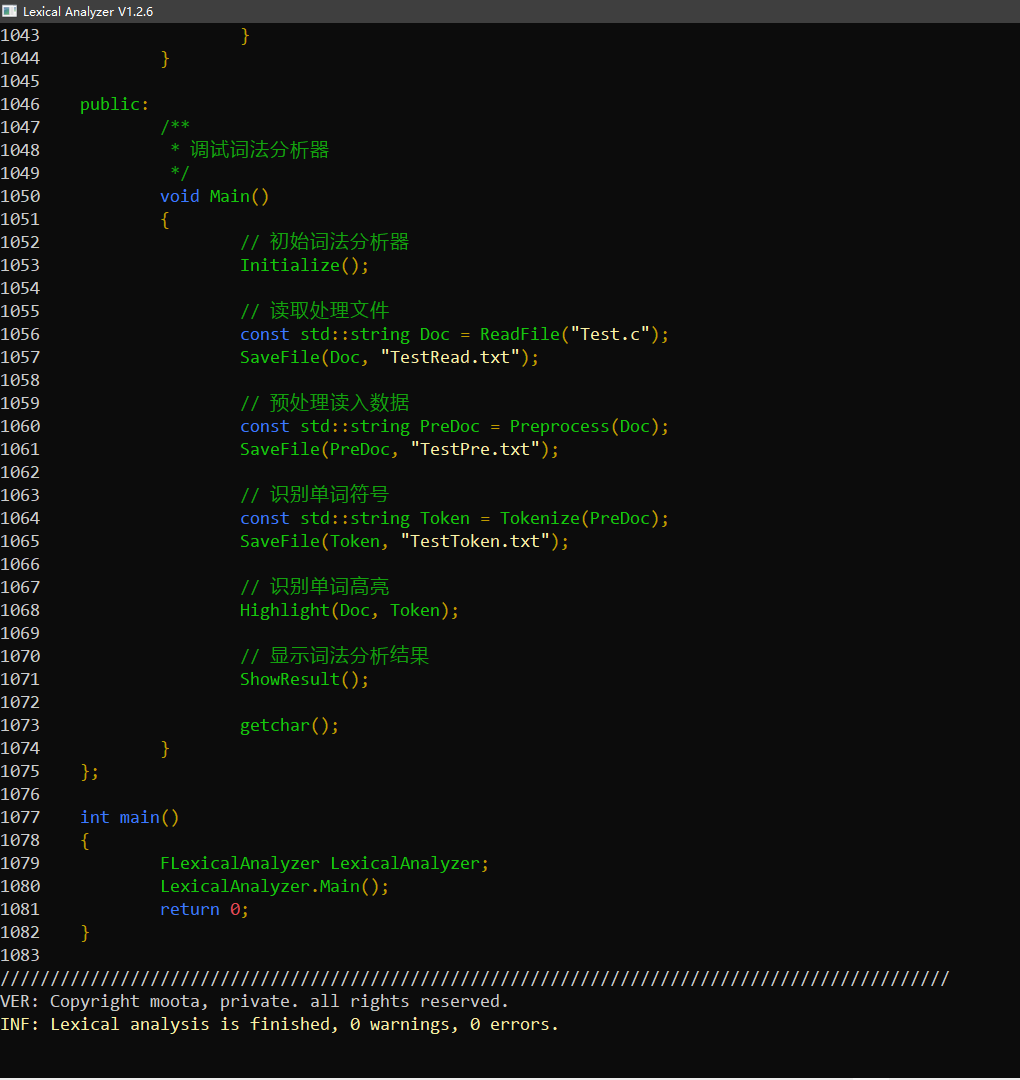
C++-c语言词法分析器
一、运行截图 对于 Test.c 的词法分析结果 对于词法分析器本身的源代码的分析结果 二、主要功能 经过不断的修正和测试代码,分析测试结果,该词法分析器主要实现了以下功能: 1. 识别关键字 实验要求:if else while do for main…...

Maven工具复习
Maven从入门到放弃Maven概述Maven 的配置Maven的基本使用IDEA 配置MAVENMaven坐标IDEA 创建MavenIDEA 导入Maven关于右侧Maven小标签(也就是Maven面板)找不到问题的解决办法关于不小心把IDEA主菜单搞消失的解决办法依赖管理Maven概述 Maven是一个工具提供了一套标准的项目结构…...
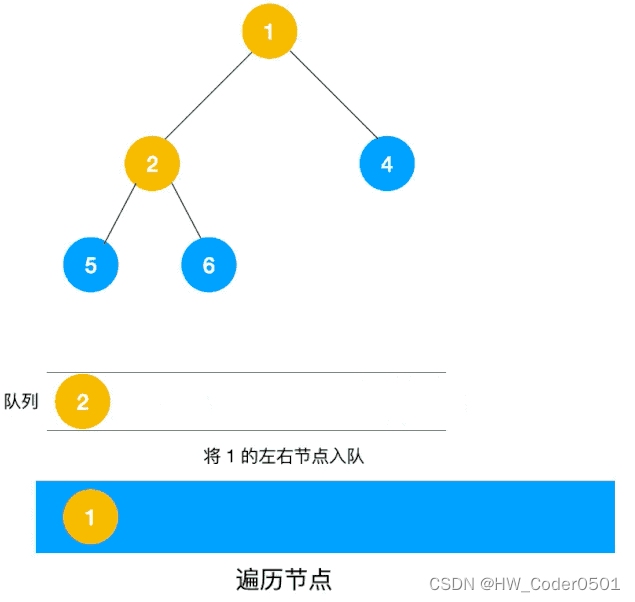
算法总结-深度优先遍历和广度优先遍历
深度优先遍历(Depth First Search,简称DFS) 与广度优先遍历(Breath First Search,简称BFS)是图论中两种非常重要的算法,生产上广泛用于拓扑排序,寻路(走迷宫),搜索引擎,爬虫等。 一、深度优先遍历 深度优先…...

【Linux】Centos安装mvn命令(maven)
🍁博主简介 🏅云计算领域优质创作者 🏅华为云开发者社区专家博主 🏅阿里云开发者社区专家博主 💊交流社区:运维交流社区 欢迎大家的加入! 文章目录一、下载maven包方法一:官…...
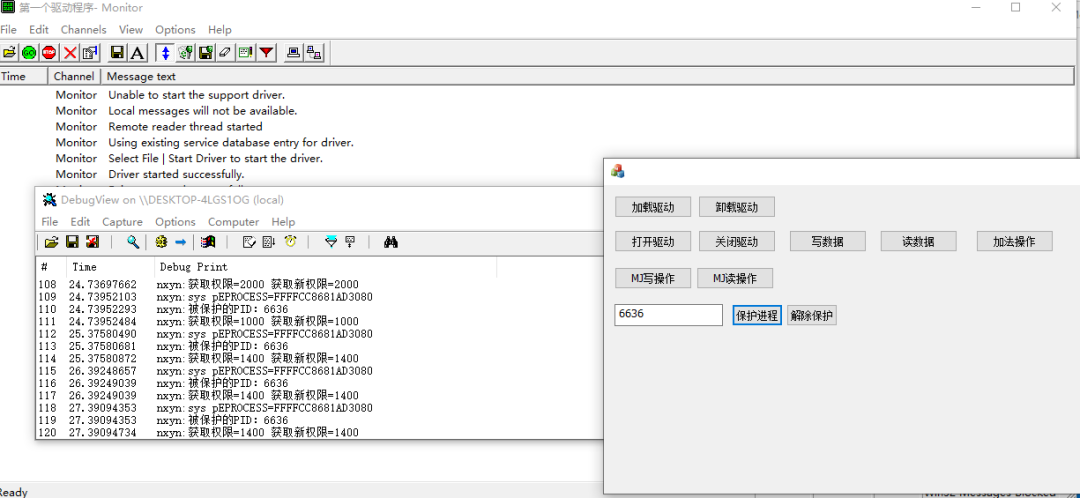
驱动保护 -- 通过PID保护指定进程
一、设计界面 1、添加一个编辑框输入要保护的进程PID,并添加两个按钮,一个保护进程,一个解除保护 2、右击编辑框,添加变量 二、驱动层代码实现 1、声明一个受保护的进程PID数组 static UINT32 受保护的进程PID[256] { 0 }; 2…...

spring常用注解(全)
一、前言 Spring的一个核心功能是IOC,就是将Bean初始化加载到容器中,Bean是如何加载到容器的,可以使用Spring注解方式或者Spring XML配置方式。 Spring注解方式减少了配置文件内容,更加便于管理,并且使用注解可以大大…...

Axios请求(对于ajax的二次封装)——Axios请求的响应结构、默认配置
Axios请求(对于ajax的二次封装)——Axios请求的响应结构、默认配置知识回调(不懂就看这儿!)场景复现核心干货axios请求的响应结构响应格式详解实际请求中的响应格式axios请求的默认配置全局axios默认值(了解…...
【软件设计师】计算机系统—CPU习题联系)
(三)【软件设计师】计算机系统—CPU习题联系
文章目录一、2014年上半年第1题二、2014年下半年第3题三、2017年上半年第1题四、2009年下半年第1题五、2010年上半年第5题六、2011年下半年第5题七、2011年下半年第6题八、2012年下半年第1题九、2019年上半年第1题十、2010年上半年第1题十一、2011年上半年第1题十二、2016年下半…...
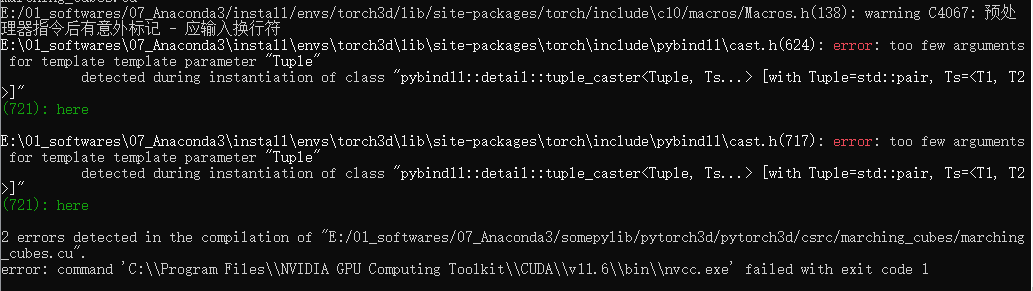
win下配置pytorch3d
一、配置好的环境:py 3.9 pytorch 1.8.0 cuda 11.1_cudnn 8_0 pytorch3d 0.6.0 CUB 1.11.0 你可能觉得pytorch3d 0.6.0版本有点低,但是折腾不如先配上用了,以后有需要再说。 (后话:py 3.9 pytorch 1.12.1 cuda …...

JS字符串对象
、 JS字符串对象 1.1 内置对象简介 在 JavaScript 中,对象是非常重要的知识点。对象可以分为两种:一种是“自定义对象”外一种是“内置对象”。自定义对象,指的是需要我们自己定义的对象,和“自定义函数”是一些道理;内置对象,…...
)
Linux系统对文件及目录的权限管理(chmod、chown)
1、身份介绍 在linux系统中,对文件或目录来说访问者的身份有三种: ①、属主用户,拥有者(owner)文件的创建者 ②、属组用户,和文件的owner同组的用户(group); ③、其他用…...

半透明反向代理 (基于策略路由)
定义 半透明反向代理一般是指 代理本身对于客户端透明,对于服务端可见。 从客户端视角看,客户端访问的还是服务端,客户端不知道代理的存在。 从服务端视角看,服务端只能看到代理,看不到真实的客户端。 示意图 客户端…...

课前测5-超级密码
目录 课前测5-超级密码 程序设计 程序分析 课前测5-超级密码 【问题描述】 上次设计的“高级密码”被你们破解了,一丁小朋友很不服气! 现在,他又设计了一套更加复杂的密码,称之为“超级密码”。 说实话,这套所谓的“超级密码”其实也并不难: 对于一个给定的字符…...

QML控件--Menu
文章目录一、控件基本信息二、控件使用三、属性成员四、成员函数一、控件基本信息 二、控件使用 import QtQuick 2.10 import QtQuick.Window 2.10 import QtQuick.Controls 2.3ApplicationWindow{visible: true;width: 1280;height: 720;Button {id: fileButtontext: "Fi…...

002:Mapbox GL更改大气、空间及星星状态
第002个 点击查看专栏目录 本示例的目的是介绍演示如何在vue+mapbox中更改大气、空间及星星状态 。 直接复制下面的 vue+mapbox源代码,操作2分钟即可运行实现效果 文章目录 示例效果配置方式示例源代码(共71行)相关API参考:专栏目标示例效果 配置方式 1)查看基础设置:…...

2022年第十三届蓝桥杯题解(全)C/C++
A题就是一个简单的进制转化,代码实现如下: #include <bits/stdc.h>using namespace std;const int N 1e5 10;int main() {int x 2022;int a 1;int res 0;while(x) {res (x % 10) * a;a a * 9;x / 10;}cout << res;return 0; } B题有…...

【cmake学习】find_package 详解
find_package 主要用于查找指定的 package,主要支持两种搜索方法: Config mode:查找 xxx-config.cmake或 xxxConfig.cmake的文件,如OpenCV库的OpenCVConfig.cmakeModule mode:查找Findxxx.cmake文件,如Ope…...
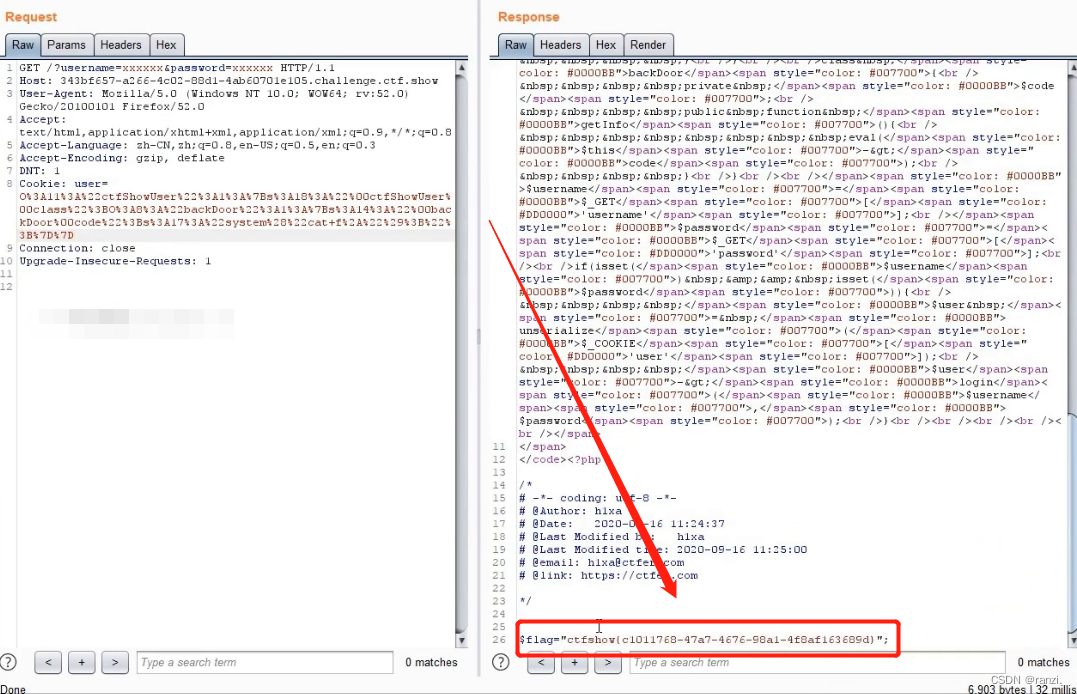
WEB攻防-通用漏洞PHP反序列化POP链构造魔术方法原生类
目录 一、序列化和反序列化 二、为什么会出现反序列化漏洞 三、序列化和反序列化演示 <演示一> <演示二> <演示二> 四、漏洞出现演示 <演示一> <演示二> 四、ctfshow靶场真题实操 <真题一> <真题二> <真题三> &l…...
)
Baumer工业相机堡盟工业相机如何通过BGAPISDK里的图像处理库进行图像转换(C++)
Baumer工业相机堡盟工业相机如何通过BGAPI SDK进行图像转换(C)Baumer工业相机Baumer工业相机的SDK里图像格式转换的技术背景Baumer工业相机通过BGAPI SDK进行图像转换调用BGAPI SDK的图像转换库ImageProcessor调用BGAPI SDK建立图像调用BGAPI SDK转换图像…...
, 获得店铺的所有商品,获取推荐商品列表, 获取购买到的商品订单列表))
JD开放平台接口(获得JD商品详情, 按关键字搜索商品,按图搜索京东商品(拍立淘), 获得店铺的所有商品,获取推荐商品列表, 获取购买到的商品订单列表)
参数说明 通用参数说明 url说明 https://api-gw.onebound.cn/平台/API类型/ 平台:淘宝,京东等, API类型:[item_search,item_get,item_search_shop等]version:API版本key:调用key,测试key:test_api_keysecret:调用secret,测试secret:(不用填写…...

基于大语言模型的抖音智能评论机器人:从原理到部署实践
1. 项目概述:当抖音遇上AI,一个自动回复机器人的诞生最近在刷抖音的时候,我经常看到一些账号的评论区里,作者回复得特别快,而且内容还挺有意思,有时候甚至能接上一些很刁钻的梗。一开始我还以为是真人24小时…...
基于RP2040与NeoPixel的交互式LED气泡桌:硬件选型、电路设计与动画编程全解析
1. 项目概述:打造一个会呼吸的光影气泡桌 几年前,我在一个艺术展上看到一个用灯光和烟雾营造氛围的装置,当时就被那种动态光影与物理形态结合的美感深深吸引。作为一个喜欢动手的嵌入式开发者,我一直在想,能不能做一个…...

从入门到精通:trtexec命令行工具在TensorRT模型部署中的实战指南
1. trtexec工具基础入门 第一次接触trtexec时,我也被这个命令行工具的参数数量吓到了。但实际用下来发现,它就像瑞士军刀一样,虽然功能多但每个都很实用。trtexec是TensorRT安装包自带的命令行工具,主要用来做三件事:…...

别再手动配置时钟树了!用STM32CubeMX 6.10 + Keil MDK 5分钟搞定LED闪烁工程
5分钟极速开发:STM32CubeMX图形化工具颠覆传统嵌入式开发模式 第一次接触STM32开发时,面对密密麻麻的寄存器手册和复杂的时钟树配置,我花了整整三天才让一个LED灯闪烁起来。直到发现STM32CubeMX这个神器——它彻底改变了嵌入式开发的入门门槛…...
)
Discord Bot自动分发+CSV任务编排+状态回写看板——Midjourney批量工作流工业级落地(仅限内部团队验证过)
更多请点击: https://intelliparadigm.com 第一章:Discord Bot自动分发CSV任务编排状态回写看板——Midjourney批量工作流工业级落地(仅限内部团队验证过) 该方案已在 3 个百人级创意协作团队中稳定运行超 180 天,日均…...

在扁平化组织里,技术人如何建立“非职权影响力”?
一、为什么测试人更需要非职权影响力软件测试工程师的岗位设置本身就带有一种结构性矛盾:你对产品质量负责,却很少拥有对等的决策权。开发写代码,你找bug;产品定需求,你验证逻辑;项目经理排期,你…...

面向高校的基于算法的发明专利申请写作方法
发明专利作为国家和高校认可的成果形式之一,其申请和授权一直受到教师和学生们的高度重视;基于算法的发明专利作为发明专利的重要分支,每年都有大量的算法专利被授权或者拒绝。虽然高校的教师对论文写作非常熟悉,但是发明专利的写…...

RAG落地方案
1. RAG分析1.1 为什么需要 Rerank?要理解 Rerank 的价值,得先理解向量检索到底"差"在哪。RAG 的第一阶段检索,通常用的是双塔(Bi-Encoder)架构的 Embedding 模型。它的工作方式是把 Query 和每个文档分别独立…...

别再傻傻分不清了!数字IC面试必问的Latch与Flip-Flop,我用Verilog代码给你讲明白
数字IC面试突围:Latch与Flip-Flop的Verilog避坑指南 1. 从门电路到时序逻辑:存储单元的本质差异 在数字电路设计中,存储单元如同城市交通的信号灯系统。锁存器(Latch)就像持续亮着的红灯——只要信号有效(电…...

GraphQL-WS服务器配置:完整参数详解与最佳实践
GraphQL-WS服务器配置:完整参数详解与最佳实践 【免费下载链接】graphql-ws Coherent, zero-dependency, lazy, simple, GraphQL over WebSocket Protocol compliant server and client. 项目地址: https://gitcode.com/gh_mirrors/gr/graphql-ws GraphQL-WS…...