MAE论文阅读《Masked Autoencoders Are Scalable Vision Learners》
文章目录
- 动机
- 方法
- 写作方面参考
Paper: https://arxiv.org/pdf/2111.06377.pdf
动机
首先简要介绍下BERT,NLP领域的BERT是基于Transformer架构,并采取无监督预训练的方式去训练模型。它提出的预训练方法在本质上是一种masked autoencoding,也就是MLM(masked language modeling):去除数据的一部分然后学习恢复。
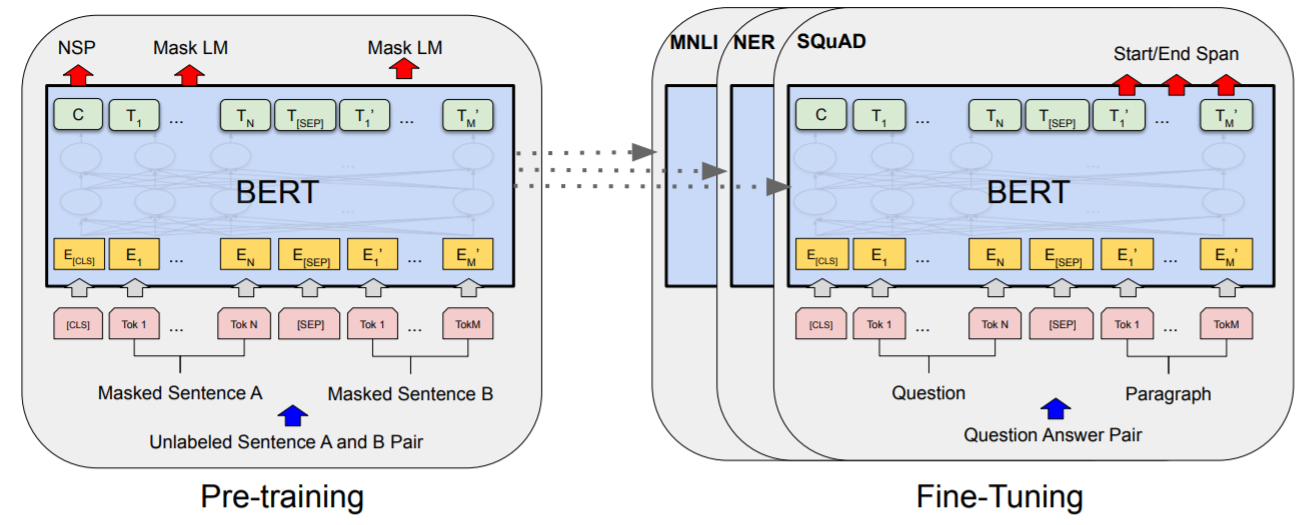
自从ViT火了之后,Transformer架构也可以应用于CV领域中了,一些研究者就开始尝试研究ViT的无监督学习,比如Mocov3用对比学习的方法无监督训练ViT,此外也有一些研究开始借鉴BERT中的MLM方法,比如BEiT提出了用于图像的无监督学习方法: MIM(masked image modeling)。但尽管如此,NLP领域已经在BERT的这种masked autoencoding方法下取得了巨大的进展,而CV领域中在无监督预训练这一块远远落后,主流的无监督训练还是对比学习。其中这种masked autoencoding方法并不是没在图像领域应用过,很早便就出现了,比如Denoising Autoencoders。但是至今却未取得像在NLP领域中的巨大发展。MAE论文对这个问题做了以下分析(参考:视觉无监督学习新范式:MAE):
- 图像的主流模型是CNN,而NLP的主流模型是transformer,CNN和transformer的架构不同导致NLP的BERT很难直接迁移到CV。但是vision transformer的出现已经解决这个问题;
- 图像和文本的信息密度不同,文本是高语义的人工创造的符号,而图像是一种自然信号,两者采用masked autoencoding建模任务难度就不一样,从句子中预测丢失的词本身就是一种复杂的语言理解任务,但是图像存在很大的信息冗余,一个丢失的图像块很容易利用周边的图像区域进行恢复。也就是说:丢失一个单词去恢复句子很难,用MLM这样的方式去学习这样一个难的任务可以学到一些有意义的信息;但是丢失一个patch去恢复图像却很简单,这只用线性插值就可以实现了,用MIM这样的方式去学习这么简单的任务,几乎学不到什么有价值的信息。
- 用于重建的decoder在图像和文本任务发挥的角色有区别,从句子中预测单词属于高语义任务,encoder和decoder的gap小,所以BERT的decoder部分微不足道(只需要一个MLP),而对图像重建像素属于低语义任务(相比图像分类),decoder需要发挥更大作用:将高语义的中间表征恢复成低语义的像素值。
因此,本文提出了一种简单有效的用于ViT无监督预训练的方法,称为MAE(masked autoencoder)。MAE也属于MIM的范畴,可以将MAE看作是BERT的CV版本:

方法
MAE方法很简单,整体架构如下。针对以上的分析,MAE采用了MIM的思想,随机mask掉部分patchs然后进行重建,并有两个核心的设计: 1)设计了一个非对称的encoder-decoder结构,这个非对称体现在两方面:一方面decoder采用比encoder更轻量级设计,encoder首先使用linear将patch映射为embedding,然后采用的是ViT模型,decoder是一个包含几个transformer blocks轻量级模块,最后一层是一个linear层采用的是一个;另外一方面encoder只处理visible patchs,而decoder处理所有的patchs(插入masked patchs)。2)MAE采用很高的masking ratio(比如75%甚至更高),这样构建的学习任务大大降低了信息冗余,或者说增加了学习难度,使得encoder能学习到更高级的特征。此外,由于encoder只处理visible patchs,所以很高的masking ratio可以大大降低计算量。

MAE采用随机mask策略,对于mask ratio的选择如下:

其中的linear probing和Fine tune的区别是:linear probing把encoder冻结只加一个linear分类器训练,Fine tune是不冻结encoder完全放开训练。注意,decoder部分只是辅助无监督预训练的,具体到下游任务时就不需要它了。
不同mask ratio的效果:

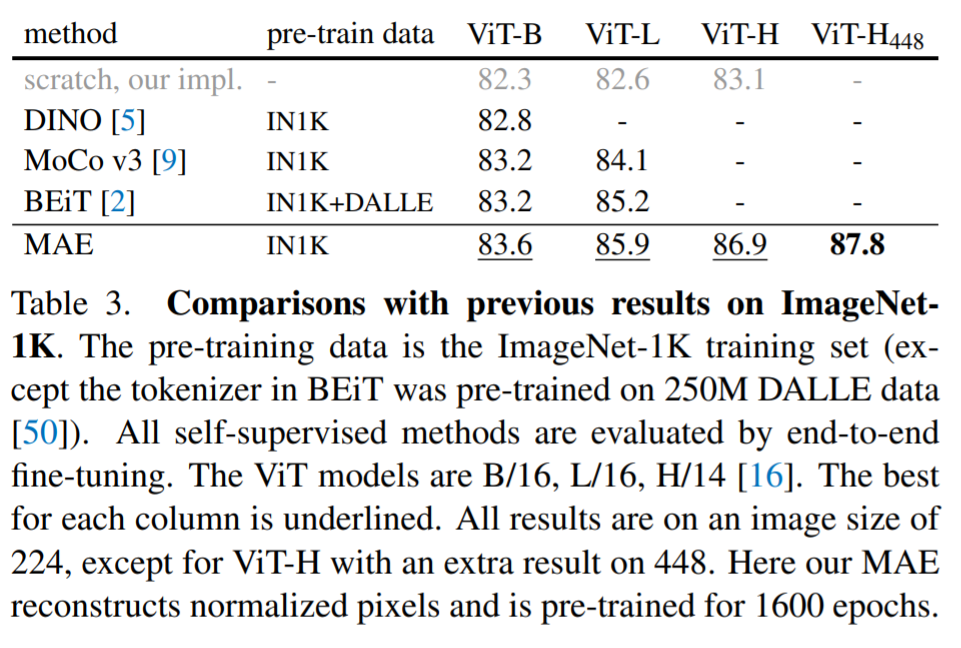
在ImageNet-1K上与其他自监督方法对比:
最后的loss只计算masked patchs。
写作方面参考
论文名《Masked Autoencoders Are Scalable Vision Learners》也是一个常用的强有力的句式:xxx are xxx。并且这样的表达会给人一种很客观,站在读者角度上的感觉。
当你做的模型比较大时,用scalable;当你做的模型比较快时,用efficient。
画图的一些细节: MAE的计算量主要出现在encoder部分,所以作者将encoder部分画的比decoder部分大。论文图中的每一个小细节,体现的都是文章的思想。
相关文章:
MAE论文阅读《Masked Autoencoders Are Scalable Vision Learners》
文章目录动机方法写作方面参考Paper: https://arxiv.org/pdf/2111.06377.pdf 动机 首先简要介绍下BERT,NLP领域的BERT是基于Transformer架构,并采取无监督预训练的方式去训练模型。它提出的预训练方法在本质上是一种masked autoencoding,也就…...

代码随想录算法训练营第三十四天-贪心算法3| 1005.K次取反后最大化的数组和 134. 加油站 135. 分发糖果
1005. Maximize Sum Of Array After K Negations 参考视频:贪心算法,这不就是常识?还能叫贪心?LeetCode:1005.K次取反后最大化的数组和_哔哩哔哩_bilibili 贪心🔍 的思路,局部最优ÿ…...
)
比较系统的学习 pandas (2)
pandas 数据读取与输出方法和常用参数 1、读取 CSV文件 pd.read_csv("pathname",step,encoding"gbk",header"infer",name[],skip_blank_linesTrue,commentNone) path : 文件路径 step : 指定分隔符,默认为 逗号 enco…...

怎么查看电脑主板最大支持多少内存?
很多电脑,内存不够用,但应速度慢;还有一些就是买了很大的内存条,但是还是反应慢;这是为什么呢?我今天明白了,原来每个电脑都有自己的适配内存,就是每个电脑能支持多大的内存…...

数据结构——线段树
线段树的结构 线段树是一棵二叉树,其结点是一条“线段”——[a,b],它的左儿子和右儿子分别是这条线段的左半段和右半段,即[a, (ab)/2 ]和[(ab)/2 ,b]。线段树的叶子结点是长度为1的单位线段[a,a1]。下图就是一棵根为[1,10]的线段树࿱…...

【C++进阶】实现C++线程池
文章目录1. thread_pool.h2. main.cpp1. thread_pool.h #pragma once #include <iostream> #include <vector> #include <queue> #include <thread> #include <mutex> #include <condition_variable> #include <future> #include &…...

Redis常用五种数据类型
一、Redis String字符串 1.简介 String类型在redis中最常见的一种类型 string类型是二制安全的,可以存放字符串、数值、json、图像数据 value存储最大数据量是512M 2. 常用命令 set < key>< value>:添加键值对 nx:当数据库中…...
)
C++ Primer第五版_第十一章习题答案(1~10)
文章目录练习11.1练习11.2练习11.3练习11.4练习11.5练习11.6练习11.7练习11.8练习11.9练习11.10练习11.1 描述map 和 vector 的不同。 map 是关联容器, vector 是顺序容器。 练习11.2 分别给出最适合使用 list、vector、deque、map以及set的例子。 list:…...

GEE:使用LandTrendr进行森林变化检测详解
作者:_养乐多_ 本文介绍了一段用于地表变化监测的代码,该代码主要使用谷歌地球引擎(GEE)中的 Landsat 时间序列数据,采用了 Kennedy 等人(2010) 发布的 LandTrendr 算法,对植被指数进行分割,通过计算不同时间段内植被指数的变化来检测植被变化。 目录 一、加入矢量边界 …...
docker项目实施
鲲鹏916架构openEuler-arm64成功安装docker并跑通tomcat容器_闭关苦炼内功的技术博客_51CTO博客鲲鹏916架构openEuler-arm64成功安装docker并跑通tomcat容器,本文是基于之前这篇文章鲲鹏920架构arm64版本centos7安装docker下面开始先来看下系统版本卸载旧版本旧版本…...
springboot实现邮箱验证码功能
引言 邮箱验证码是一个常见的功能,常用于邮箱绑定、修改密码等操作上,这里我演示一下如何使用springboot实现验证码的发送功能; 这里用qq邮箱进行演示,其他都差不多; 准备工作 首先要在设置->账户中开启邮箱POP…...
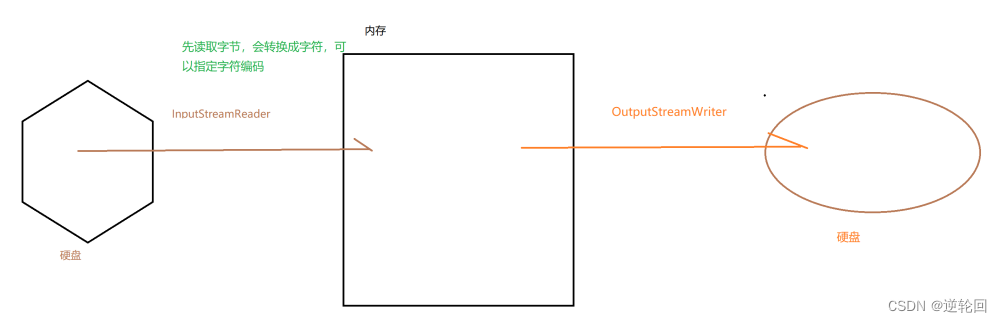
Java 进阶(5) Java IO流
⼀、File类 概念:代表物理盘符中的⼀个⽂件或者⽂件夹。 常见方法: 方法名 描述 createNewFile() 创建⼀个新文件。 mkdir() 创建⼀个新⽬录。 delete() 删除⽂件或空⽬录。 exists() 判断File对象所对象所代表的对象是否存在。 getAbsolute…...
“终于我从字节离职了...“一个年薪40W的测试工程师的自白...
”我递上了我的辞职信,不是因为公司给的不多,也不是因为公司待我不好,但是我觉得,我每天看中我憔悴的面容,每天晚上拖着疲惫的身体躺在床上,我都不知道人生的意义,是赚钱吗?是为了更…...

设计模式之策略模式(C++)
作者:翟天保Steven 版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处 一、策略模式是什么? 策略模式是一种行为型的软件设计模式,针对某个行为,在不同的应用场景下&…...

从工厂普工到Python女程序员,聊聊这一路我是如何逆袭的?
我来聊聊我是如何从一名工厂普工,到国外程序员的过程,这里面充满了坎坷。过去我的工作是在工厂的流水线上,我负责检测电池的正负极。现如今我每天从早上6:20起床,6点四五十分出发到地铁站,7:40到公司。我会给自己准备一…...

全国青少年信息素养大赛2023年python·选做题模拟二卷
目录 打印真题文章进行做题: 全国青少年电子信息智能创新大赛 python选做题模拟二卷 一、单选题 1. numbers = [1, 11, 111, 9], 运行numbers.sort() 后,运行numbers.reverse() numbers会变成?( )...

分布式事务Seata原理
Seata 是一款开源的分布式事务解决方案,致力于提供高性能与简单易用的分布式事务服务,为用户提供了 AT、TCC、SAGA 和 XA 几种不同的事务模式。Seata AT模式是基于XA事务演进而来,需要数据库支持。AT 模式的特点就是对业务无入侵式࿰…...
用ChatGPT怎么赚钱?普通人用这5个方法也能赚到生活费
ChatGPT在互联网火得一塌糊涂,因为它可以帮很多人解决问题。比如:帮编辑人员写文章,还可以替代程序员写代码,帮策划人员写文案策划等等。ChatGPT这么厉害,能否用它来赚钱呢?今天和大家分享用ChatGPT赚钱的5…...
( “树” 之 DFS) 110. 平衡二叉树 ——【Leetcode每日一题】
110. 平衡二叉树 给定一个二叉树,判断它是否是高度平衡的二叉树。 本题中,一棵高度平衡二叉树定义为: 一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1 。 示例 1: 输入:root [3,9,20,null,null,15,7] …...
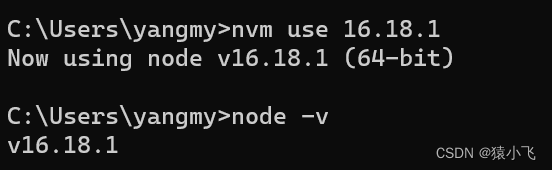
nvm软件使用-同一个环境下控制多个不同node版本
1.使用场景 nvm是一个用于管理Node.js版本的工具,它可以让你在同一台机器上安装和切换不同的Node.js版本。使用nvm的好处有以下几点: 1.1.nvm可以让你轻松地测试你的代码在不同的Node.js版本下的兼容性和性能,避免因为版本差异导致的问题。…...

在扁平化组织里,技术人如何建立“非职权影响力”?
一、为什么测试人更需要非职权影响力软件测试工程师的岗位设置本身就带有一种结构性矛盾:你对产品质量负责,却很少拥有对等的决策权。开发写代码,你找bug;产品定需求,你验证逻辑;项目经理排期,你…...

微软UFO项目:统一AI模型调用的抽象层设计与工程实践
1. 项目概述:当“统一”成为AI开发的新范式最近在折腾大模型应用开发的朋友,可能都绕不开一个痛点:模型太多,工具链太杂。想用闭源的GPT-4处理文本,用开源的Llama搞本地推理,再用DALL-E 3生成图片ÿ…...

ARM PMUv3架构详解与性能监控实战
1. ARM PMUv3架构概述 性能监控单元(Performance Monitor Unit, PMU)是现代处理器中用于硬件性能分析的关键组件。作为ARMv8架构的标准组成部分,PMUv3通过事件计数器和配置寄存器实现了对微架构事件的监测能力。在实际开发中,我们经常需要利用PMU来定位性…...

当深度学习赋能异步电机矢量控制:从模型优化到性能跃迁
1. 异步电机矢量控制的传统挑战 我第一次接触异步电机矢量控制是在2015年做工业机器人项目时。当时为了调试一个简单的速度环,整整花了两周时间反复调整PI参数。这种经历让我深刻体会到传统控制方法的局限性——就像用螺丝刀修理精密手表,虽然最终能调好…...

MPLAB® Harmony嵌入式框架实战:从架构解析到项目开发避坑指南
1. 项目概述:从零到一,理解MPLAB Harmony的价值如果你是一位嵌入式开发者,尤其是长期与Microchip的PIC或SAM系列MCU打交道的朋友,那么“MPLAB Harmony”这个名字你一定不陌生。它可能出现在官方文档的角落里,在论坛的讨…...

别再只看耐压和电流了!手把手教你用SOA曲线给MOS管做‘体检’,避开炸管风险
从炸管到精准选型:动态SOA曲线在MOS管可靠性设计中的实战指南 1. 被忽视的"死亡区域":为什么静态参数无法保护你的MOS管 凌晨三点的实验室里,张工程师盯着第5块烧毁的电路板百思不得其解——明明选用了额定电流30A、耐压60V的MOS管…...

【实战排错】Vivado 综合卡死与“PID not specified”的深度诊断与修复
1. 故障现象与初步排查 最近在跑Vivado综合时,突然遇到一个让人头疼的问题:综合进程莫名其妙卡死,日志里还跳出"PID not specified"的错误提示。这种情况相信不少FPGA工程师都遇到过,特别是项目紧急的时候,这…...

大语言模型对抗性攻击与防御:Decepticon框架原理与实践
1. 项目概述:当AI学会“伪装”,一场攻防博弈的新范式最近在安全圈和AI研究领域,一个名为“Decepticon”的项目引起了我的注意。这个项目来自PurpleAILAB,名字本身就充满了对抗的意味——“Decepticon”直译是“霸天虎”࿰…...

UTF8-CPP跨版本兼容性指南:从C++98到C++20的完整支持
UTF8-CPP跨版本兼容性指南:从C98到C20的完整支持 【免费下载链接】utfcpp UTF-8 with C in a Portable Way 项目地址: https://gitcode.com/gh_mirrors/ut/utfcpp UTF8-CPP是一个轻量级的C库,专注于以可移植的方式提供UTF-8编码和解码功能&#x…...

基于Keel-Kit的GitOps自动化:轻量级镜像更新与部署实践
1. 项目概述:一个为现代应用交付而生的“舵手工具箱”如果你和我一样,长期在云原生和微服务架构的浪潮里扑腾,那你一定对“应用交付”这四个字背后的复杂性深有体会。从代码提交到最终服务上线,中间横亘着构建、打包、部署、配置、…...