【Elastic (ELK) Stack 实战教程】10、ELK 架构升级-引入消息队列 Redis、Kafka
目录
一、ELK 架构面临的问题
1.1 耦合度过高
1.2 性能瓶颈
二、ELK 对接 Redis 实践
2.1 配置 Redis
2.1.1 安装 Redis
2.1.2 配置 Redis
2.1.3 启动 Redis
2.2 配置 Filebeat
2.3 配置 Logstash
2.4 数据消费
2.5 配置 kibana
三、消息队列基本概述
3.1 什么是消息队列
3.2 消息队列的分类
3.3 消息队列使用场景
3.3.1 解耦
3.3.2 异步
3.3.3 削峰
四、Kafka 概述及集群部署
4.1 Kafka 集群安装
4.2 Zookeeper 集群安装
五、Kafka-eagle 图形界面安装
5.1 安装 JDK
5.2 安装 Kafka-eagle
5.3 配置 Kafka-eagle
5.4 启动 Kafka-eagle
5.5 开启 eagle 监控
5.6 访问 Kafka-eagle
5.7 遇到的小坑
六、ELK 对接 Kafka
6.1 配置 Filebeat
6.2 配置 Logstash
6.3 配置 kibana
一、ELK 架构面临的问题
1.1 耦合度过高
场景说明:假设目前系统日志输出很频繁,十分钟大约 5Gb,那么一个小时就是 30Gb;而应用服务器的存储空间一般默认 40Gb,所以通常会对应用服务器日志按小时轮转。如果我们的Logstash 故障了 1 小时,那么 Filebeat 就无法向 Logstash 发送日志,但我们的应用服务器每小时会对日志进行切割,那么也就意味着我们会丢失 1 小时的日志数据。
解决方法:使用消息队列,只要你的 filebeat 能够收集日志,队列能够存储足够长时间的数据,那后面 logstash 故障了,也不用担心,等 Logstash 修复后,日志依然能正常写入,也不会造成数据丢失,这样就完成了解耦。
1.2 性能瓶颈
场景说明:使用 filebeat 或 logstash 直接写入ES,那么日志频繁的被写入 ES 的情况下,可能会造成 ES 出现超时、丢失等情况。因为 ES 需要处理数据,存储数据,所以性能会变的很缓慢。
解决办法:使用消息队列,filebeat 或 Logstash 直接写入消息队列中就可以了,因为队列可以起到一个缓冲作用,最后我们的 logstash 根据 ES 的处理能力进行数据消费,匀速写入 ES 集群,这样能有效缓解 ES 写入性能的瓶颈。
二、ELK 对接 Redis 实践
使用 Redis 充当消息队列服务:
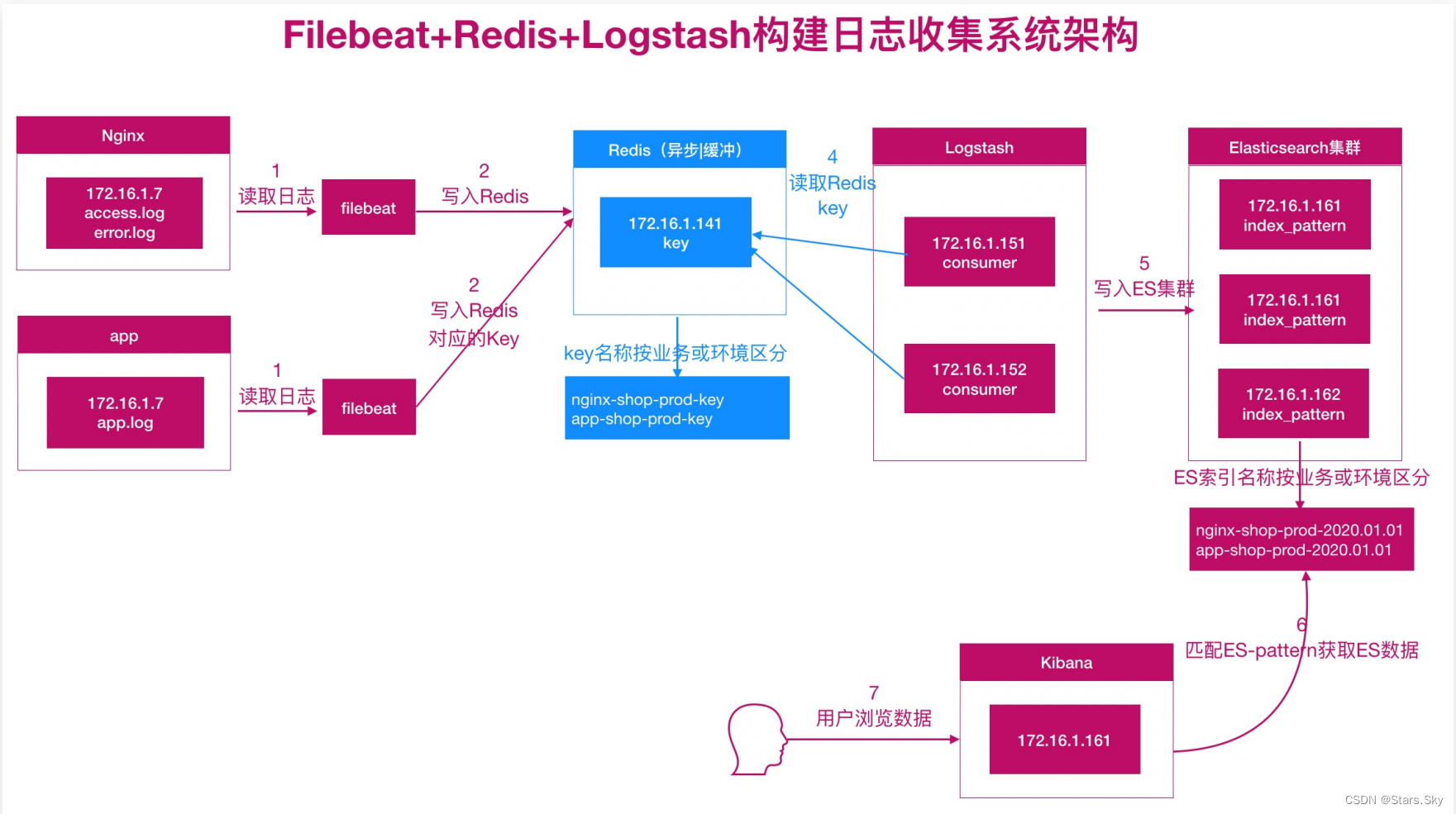
2.1 配置 Redis
2.1.1 安装 Redis
生产环境中使用二进制安装 Redis: CentOS 7 详细安装 Redis 6 图文教程_centos 7安装redis6需要哪些环境依赖_Stars.Sky的博客-CSDN博客
此次实验环境中我们使用 yum 安装更方便快捷:
[root@es-node2 ~]# yum install -y redis
2.1.2 配置 Redis
[root@es-node2 ~]# vim /etc/redis.conf
bind 0.0.0.0
requirepass Qwe123456
2.1.3 启动 Redis
[root@es-node2 ~]# systemctl enable --now redis
2.2 配置 Filebeat
[root@se-node3 ~]# vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log # 收集日志的类型enabled: true # 启用日志收集paths:- /var/log/nginx/access.log # 日志所在路径tags: ["access"]- type: log # 收集日志的类型enabled: true # 启用日志收集paths:- /var/log/nginx/error.log # 日志所在路径tags: ["error"]output.redis:hosts: ["192.168.170.133:6379"] # redis地址password: "Qwe123456" #redis密码timeout: 5 #连接超时时间db: 0 #写入db0库中keys: #存储的key名称- key: "nginx_access"when.contains:tags: "access"- key: "nginx_error"when.contains:tags: "error"[root@se-node3 ~]# systemctl restart filebeat.service
2.3 配置 Logstash
[root@es-node1 ~]# vim /etc/logstash/conf.d/test6.conf
input {redis {host => ["192.168.170.133"]port => "6379"password => "Qwe123456"data_type => "list"key => "nginx_access"db => "0"}redis {host => ["192.168.170.133"]port => "6379"password => "Qwe123456"data_type => "list"key => "nginx_error"db => "0"}
}filter {if "access" in [tags][0] {grok {match => { "message" => "%{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] \"%{WORD:method} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:response} (?:%{NUMBER:bytes}|-) %{QS:hostname} (?:%{QS:referrer}|-) (?:%{NOTSPACE:post_args}|-) %{QS:useragent} (?:%{QS:x_forward_for}|-) (?:%{URIHOST:upstream_host}|-) (?:%{NUMBER:upstream_response_code}|-) (?:%{NUMBER:upstream_response_time}|-) (?:%{NUMBER:response_time}|-)" }}useragent {source => "useragent"target => "useragent"}geoip {source => "clientip"}date {match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]target => "@timestamp"timezone => "Asia/Shanghai"}mutate {convert => ["bytes","integer"]convert => ["response_time", "float"]convert => ["upstream_response_time", "float"]remove_field => ["message"]add_field => { "target_index" => "redis-logstash-nginx-access-%{+YYYY.MM.dd}" } }# 提取 referrer 具体的域名 /^"http/if [referrer] =~ /^"http/ {grok {match => { "referrer" => '%{URIPROTO}://%{URIHOST:referrer_host}' }}}# 提取用户请求资源类型以及资源 ID 编号if "sky.com" in [referrer_host] {grok {match => { "referrer" => '%{URIPROTO}://%{URIHOST}/(%{NOTSPACE:sky_type}/%{NOTSPACE:sky_res_id})?"' }}}}else if "error" in [tags][0] {date {match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]target => "@timestamp"timezone => "Asia/Shanghai"}mutate {add_field => { "target_index" => "redis-logstash-nginx-error-%{+YYYY.MM.dd}" }}}
}output {stdout {codec => rubydebug}elasticsearch {hosts => ["192.168.170.132:9200","192.168.170.133:9200","192.168.170.134:9200"]index => "%{[target_index]}"template_overwrite => true}
}[root@es-node1 ~]# logstash -f /etc/logstash/conf.d/test6.conf -r 2.4 数据消费
在上面描述的场景中,Filebeat 收集的日志文件数据会被存储到 Redis。接着,Logstash 从 Redis 中获取数据并将其传输到 Elasticsearch。这是一个流水线式的处理过程,数据在流动过程中被消费。
Redis 作为一个中间存储,当 Logstash 成功地从 Redis 中读取数据并将其传输到 Elasticsearch 时,Logstash 会将这些数据从 Redis 中删除。这是因为你的配置文件中使用了 data_type => "list",这意味着当 Logstash 从 Redis 中获取数据时,它会使用类似于 LPOP 或 RPOP 的命令将数据从列表中弹出。这样一来,Redis 中的数据会被不断地消费,因此当你使用 keys * 命令查询时可能看不到数据。
如果你希望检查 Redis 中是否有数据流入,你可以在 Filebeat 向 Redis 发送数据的同时进行查询。但是,请注意,当 Logstash 正在消费数据时,这些数据很可能会迅速从 Redis 中删除。所以,你可能需要在 Filebeat 和 Logstash 之间调整数据发送速率,以便在 Redis 中查看数据。不过,这种做法并不是长期监控 Redis 数据的推荐方法,因为它可能会影响到整个流水线的性能。
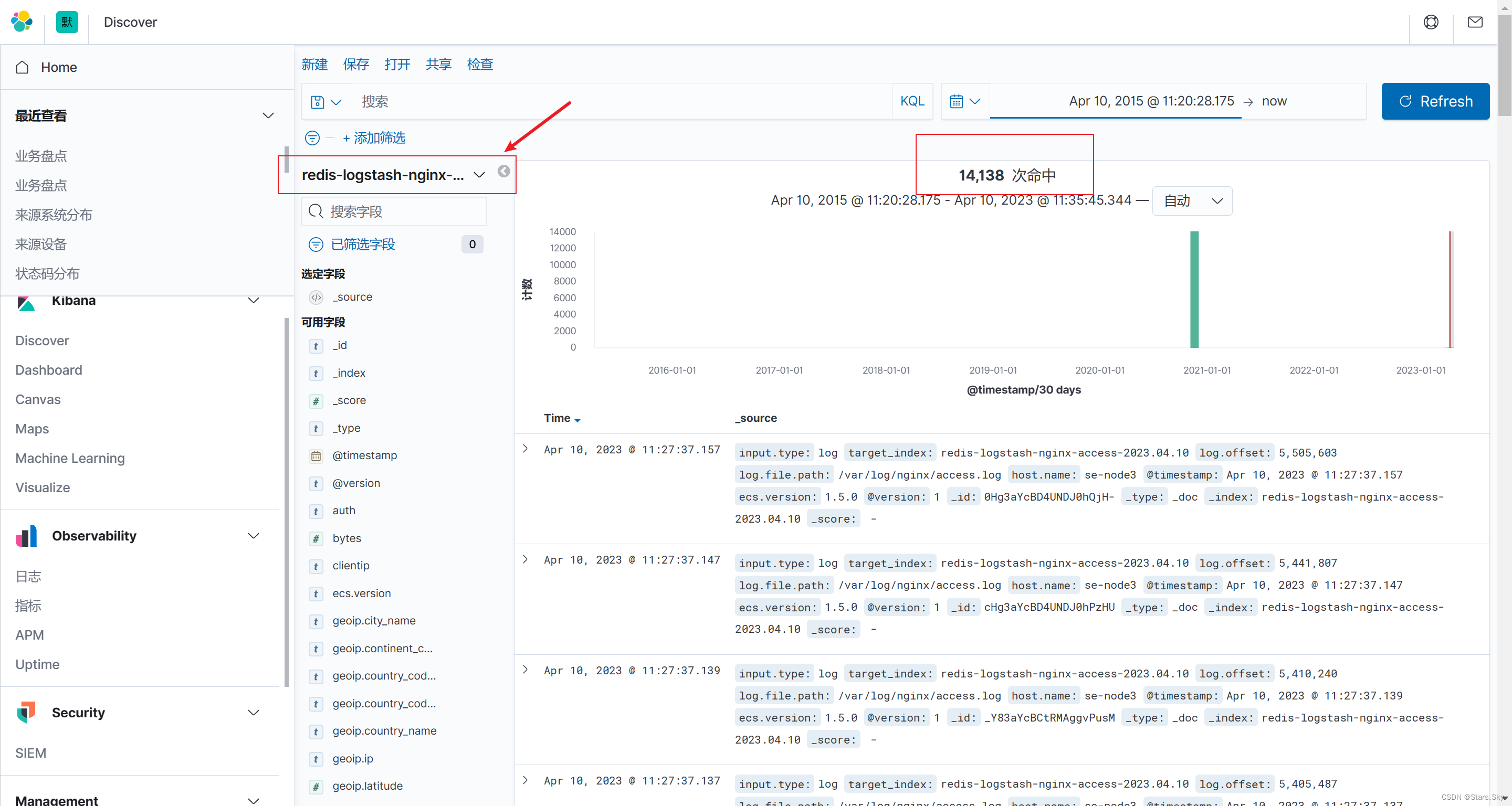
2.5 配置 kibana
创建 kibana 索引:
三、消息队列基本概述
3.1 什么是消息队列
-
消息 Message:比如两个设备进行数据的传输,所传输的任何数据,都可以称为消息。
-
队列 Queue: 是一种先进先出的数据结构,类似排队买票机制。
而消息队列 MQ:是用来保存消息的一个容器;消息队列需要提供两个功能接口供外部调用。
-
生产者 Producer:把数据放到消息队列叫生产者。
-
消费者 Consumer:从消息队列里取数据叫做消费者。
3.2 消息队列的分类
MQ 主要分为两类:点对点、发布/订阅。
-
点对点:消息队列 Queue、发送者 sender、接收者 Receiver。
一个生产者生产的消息只能有一个消费者,消息一旦被消费,消息就不在消息队列中了。比如打电话,当消息发送到消息队列后只能被一个接收者接收,当接收完毕消息则销毁。
-
发布/订阅:消息队列 Queue、发布者 PubTisher、订阅者 subscriber、主题 Topic。
每个消息可以有多个消费者,彼此互不影响。比如我使用公众号发布一篇文章,关注我的人都能看到,即发布到消息队列的消息能被多个接收者(订阅者)接收。
3.3 消息队列使用场景
消息队列最主要有三个场景,总结为 6 个字:解耦、异步、削峰。
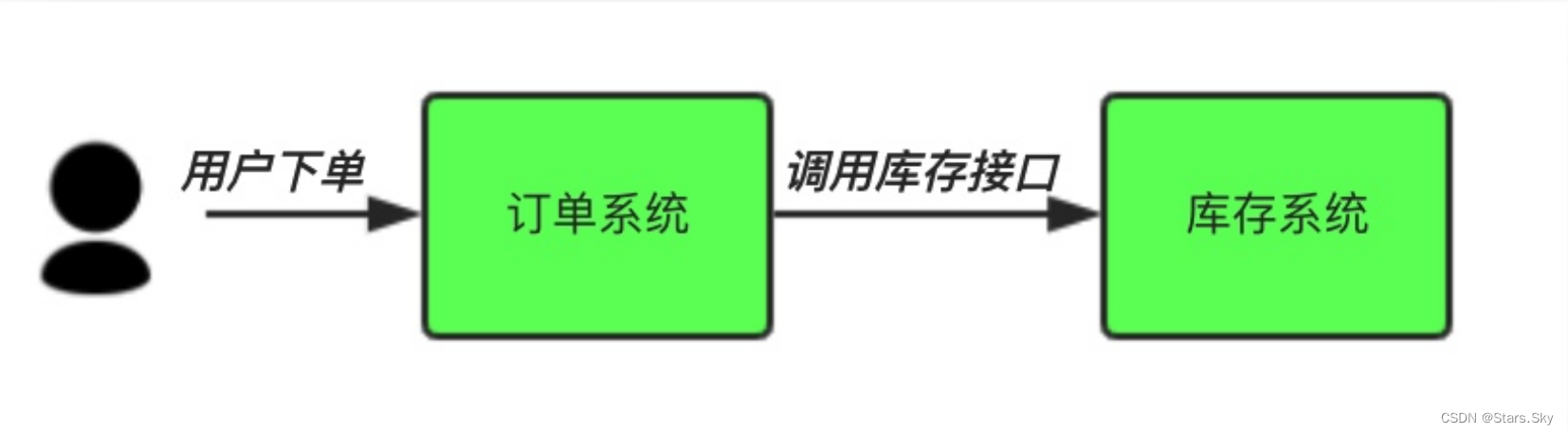
3.3.1 解耦
场景说明:用户下单后,订单系统需要通知库存系统。传统的做法是,订单系统调用库存系统的接口。
传统模式的缺点:
-
假如库存系统无法访问,则订单减库存将失败,从而导致订单失败;
-
订单系统与库存系统耦合。
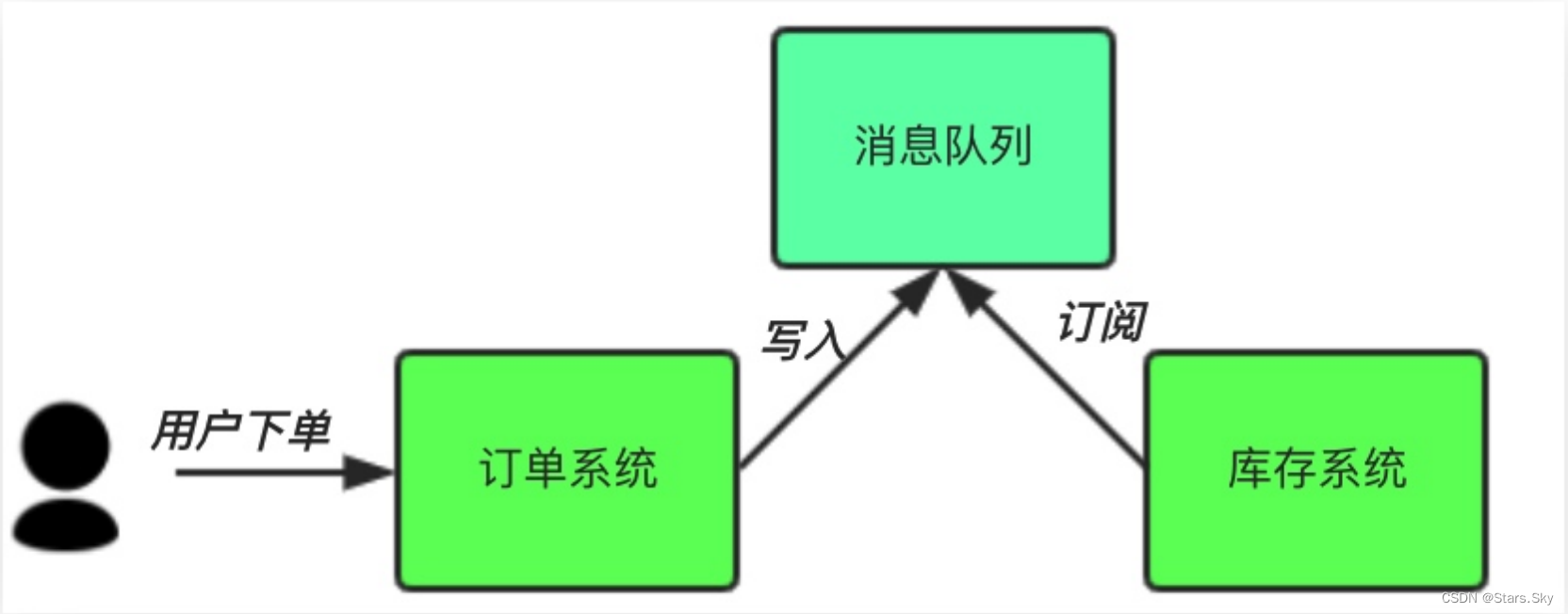
中间件模式:
-
订单系统:用户下单后,订单系统完将消息写入消息队列,返回用户订单下单成功。
-
库存系统:订阅下单的消息,获取下单信息,库存系统根据下单信息,进行库存操作。
-
假如:在下单时库存系统不能正常使用。也不影响正常下单,因为下单后,订单系统写入消息队列就不再关心其他的后续操作了。实现订单系统与库存系统的应用解耦。程序解耦 。
3.3.2 异步
场景说明:用户注册后,需要发注册邮件和注册短信。将注册信息写入数据库成功后,发送注册邮件,再发送注册短信。以上三个任务全部完成后,返回给客户端。
传统模式的缺点:系统的性能(并发量,吞吐量,响应时间)会有瓶颈。
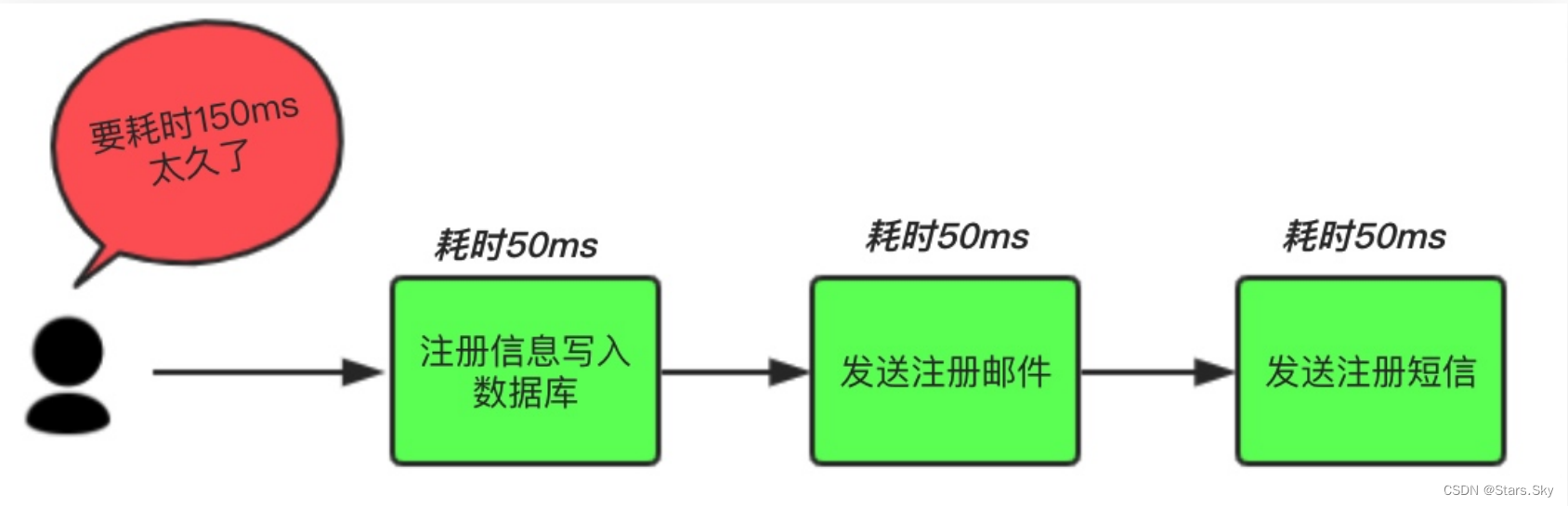
中间件模式:将不是必须的业务逻辑,异步处理。改造后的架构如下:
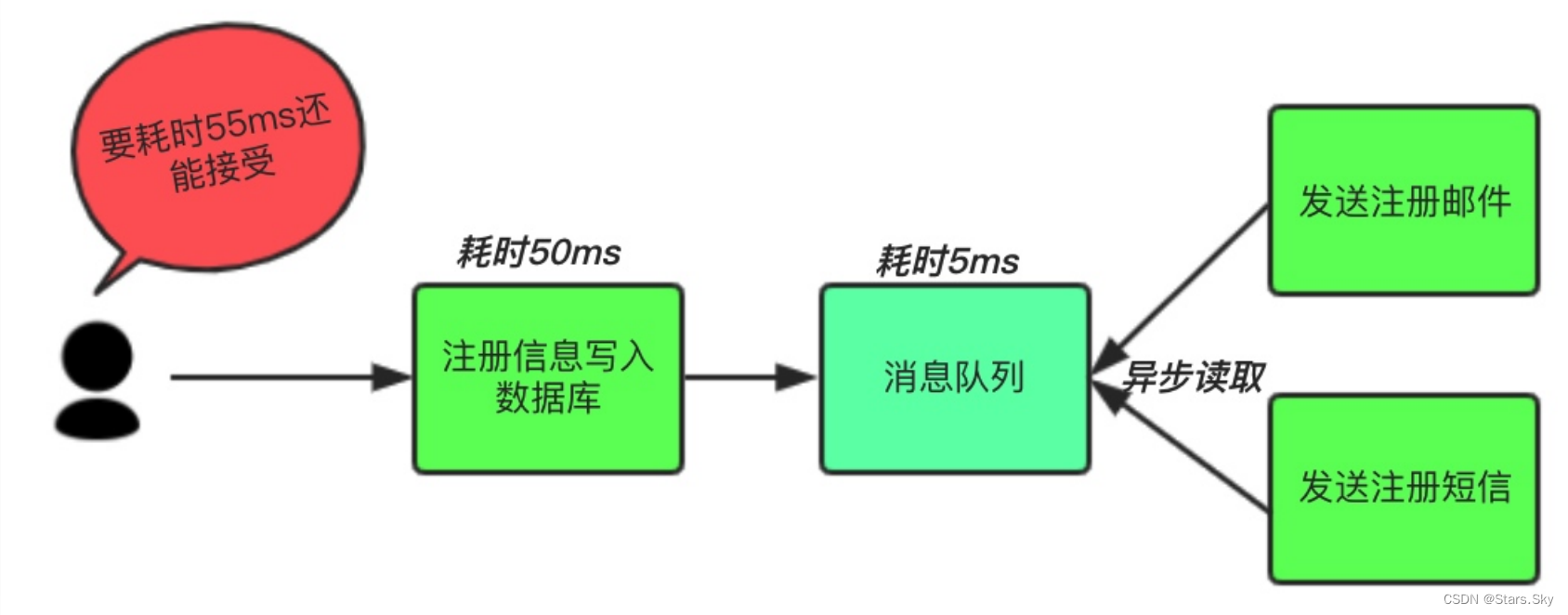
按照以上约定,用户的响应时间相当于是注册信息写入数据库的时间,也就是 50 毫秒。注册邮件,发送短信写入消息队列后,直接返回,因此写入消息队列的速度很快,基本可以忽略,因此用户的响应时间可能是 50ms 或 55ms。
3.3.3 削峰
场景说明:秒杀活动,一般会因为流量过大,导致流量暴增,应用挂掉。
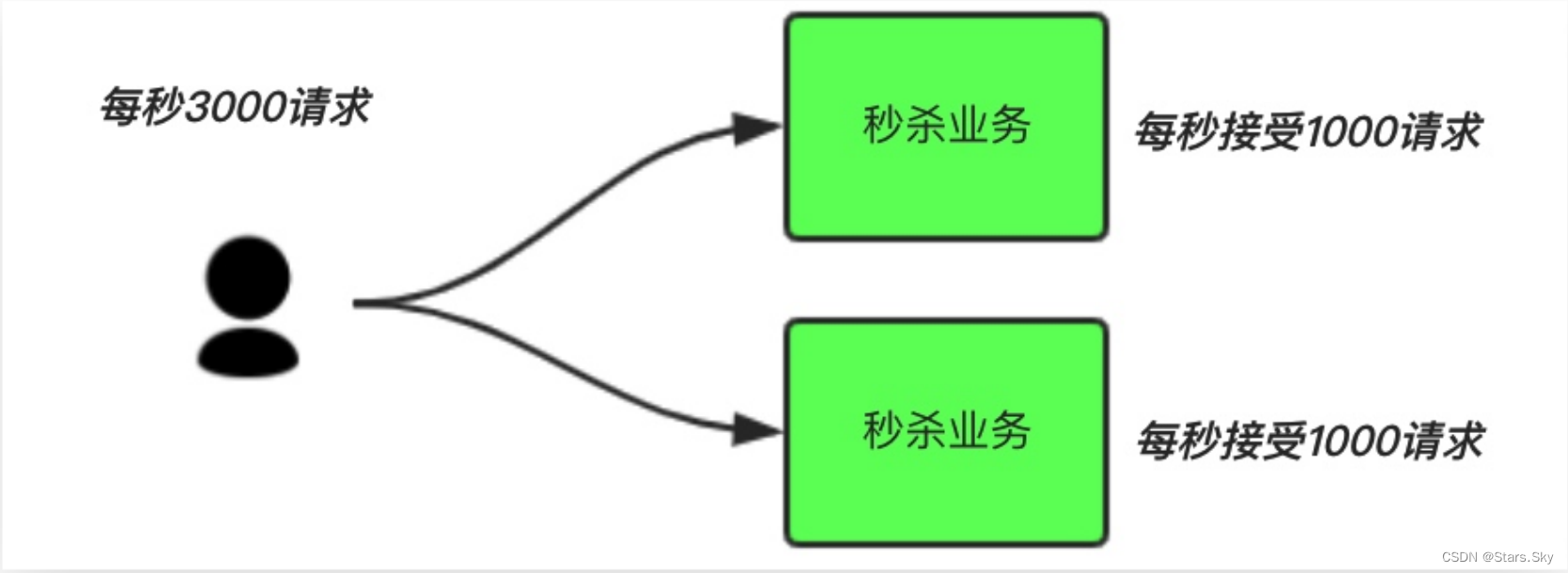
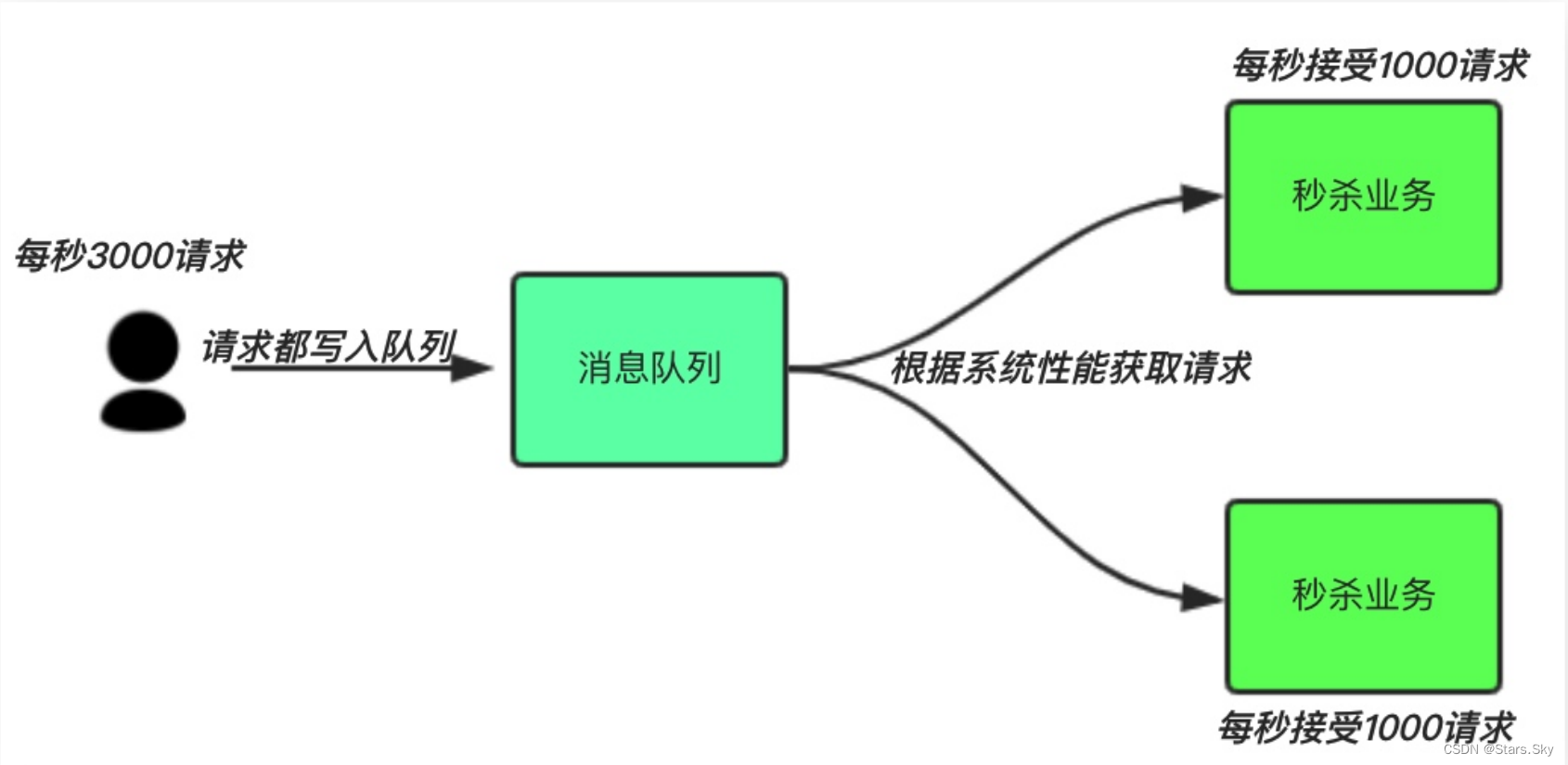
中间件模式:
-
用户的请求,服务器接收后,首先写入消息队列。假如消息队列长度超过最大数量限制,则直接抛弃用户请求或跳转到错误页面。
-
秒杀业务可以根据自身能处理的能力获取消息队列数据,然后做后续处理。这样即使有 8000 个请求也不会造成秒杀业务奔溃。
四、Kafka 概述及集群部署
PS:我是在原来的 es-node1 和 es-node3 这两天机器上安装了 kafka、Zookeeper。
4.1 Kafka 集群安装
可以查看我的这篇文章了解 kafka 及 kafka 集群的安装与使用:【Kafka 3.x 初级】01、Kafka 概述及入门_Stars.Sky的博客-CSDN博客
4.2 Zookeeper 集群安装
可以查看我的这篇文章了解 Zookeeper 及 zookeeper 集群的安装与使用:
【Zookeeper 初级】02、Zookeeper 集群部署_Stars.Sky的博客-CSDN博客
五、Kafka-eagle 图形界面安装
官方安装文档:2.Install on Linux/macOS - Kafka Eagle (kafka-eagle.org)
Kafka-eagle 下载地址:Tags · smartloli/kafka-eagle-bin · GitHub
5.1 安装 JDK
可以查看我的这篇文章:Linux 部署 JDK+MySQL+Tomcat 详细过程_移植mysql+tomcat_Stars.Sky的博客-CSDN博客
5.2 安装 Kafka-eagle
[root@es-node2 ~]# tar -zxvf kafka-eagle-bin-3.0.2.tar.gz -C /usr/local/
[root@es-node2 ~]# cd /usr/local/kafka-eagle-bin-3.0.2/
[root@es-node2 /usr/local/kafka-eagle-bin-3.0.2]# tar -zxvf efak-web-3.0.2-bin.tar.gz [root@es-node2 ~]# vim /etc/profile
export KE_HOME=/usr/local/kafka-eagle-bin-3.0.2/efak-web-3.0.2
export PATH=$KE_HOME/bin:$PATH
[root@es-node2 ~]# source /etc/profile
5.3 配置 Kafka-eagle
[root@es-node2 ~]# vim /usr/local/kafka-eagle-bin-3.0.2/efak-web-3.0.2/conf/system-config.properties
######################################
# 填写 zookeeper 集群环境信息,我们只有一套 zookeeper 集群,所以把 cluster2 注释掉
efak.zk.cluster.alias=cluster1
cluster1.zk.list=es-node1:2181,es-node3:2181/kafka
#cluster2.zk.list=xdn10:2181,xdn11:2181,xdn12:2181######################################
# kafka sqlite jdbc driver address
######################################
# kafka sqlite 数据库地址(需要修改存储路径)
efak.driver=org.sqlite.JDBC
efak.url=jdbc:sqlite:/usr/local/kafka-eagle-bin-3.0.2/efak-web-3.0.2/db/ke.db
efak.username=root
efak.password=www.kafka-eagle.org######################################
# kafka mysql jdbc driver address
######################################
# mysql 数据库地址(需要提前创建好 ke 库,咱不是有 mysql 的存储方式,所以这段内容注释掉)
#efak.driver=com.mysql.cj.jdbc.Driver
#efak.url=jdbc:mysql://127.0.0.1:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
#efak.username=root
#efak.password=1234565.4 启动 Kafka-eagle
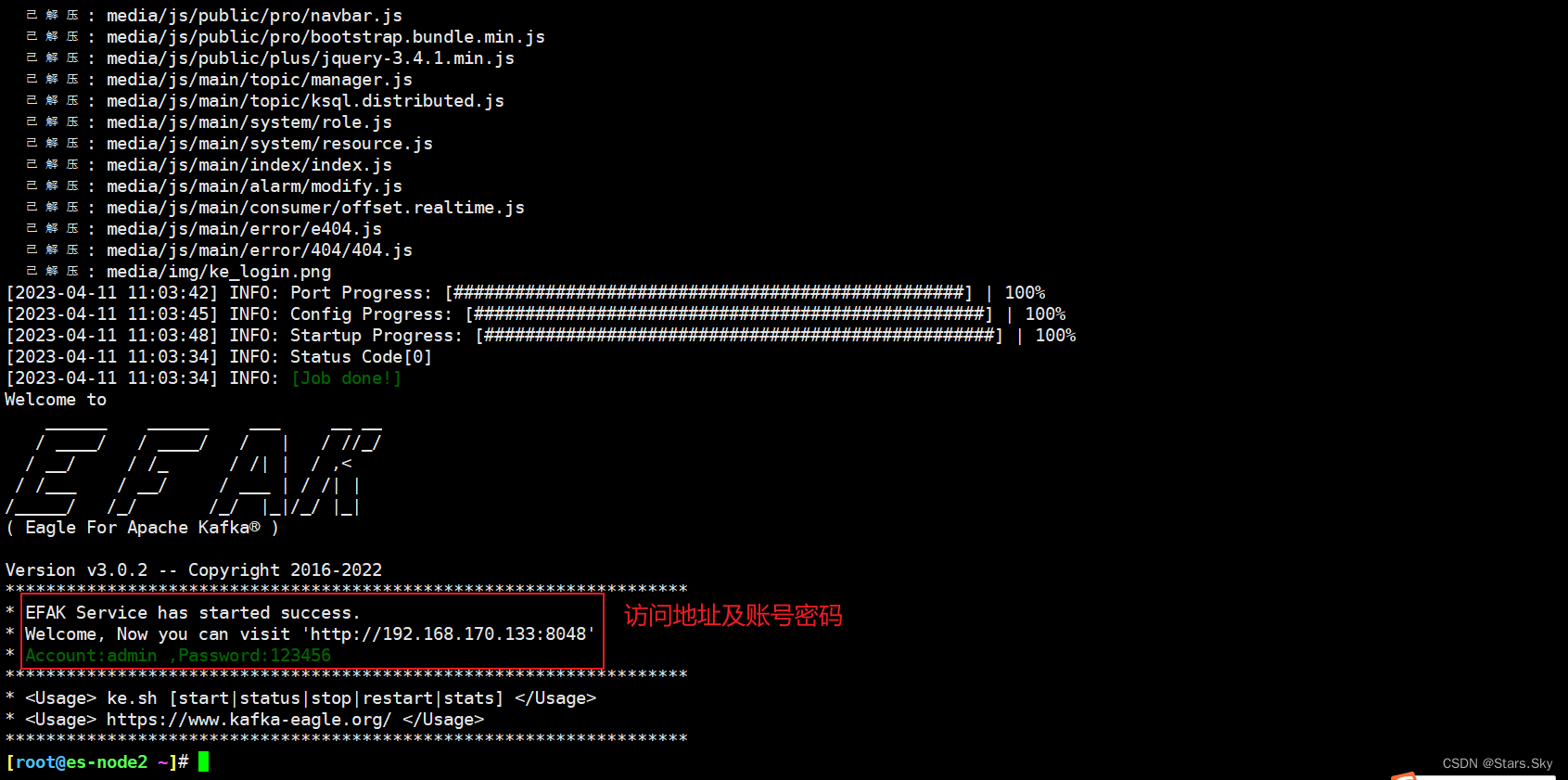
[root@es-node2 ~]# /usr/local/kafka-eagle-bin-3.0.2/efak-web-3.0.2/bin/ke.sh start
5.5 开启 eagle 监控
通过 JMX 获取数据,监控 Kafka 客户端、生产端、消息数、请求数、处理时间等数据可视化的性能。
# 开启 Kafka 的 JMX(所有 Kafka 集群节点都需要)
[root@es-node1 /opt/kafka]# vim /opt/kafka/bin/kafka-server-start.sh
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; thenexport KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"export JMX_PORT="9999"
fi# 重启 Kafka
[root@es-node1 /opt/kafka]# kf.sh stop
[root@es-node1 /opt/kafka]# kf.sh start
5.6 访问 Kafka-eagle
http://192.168.170.133:8048
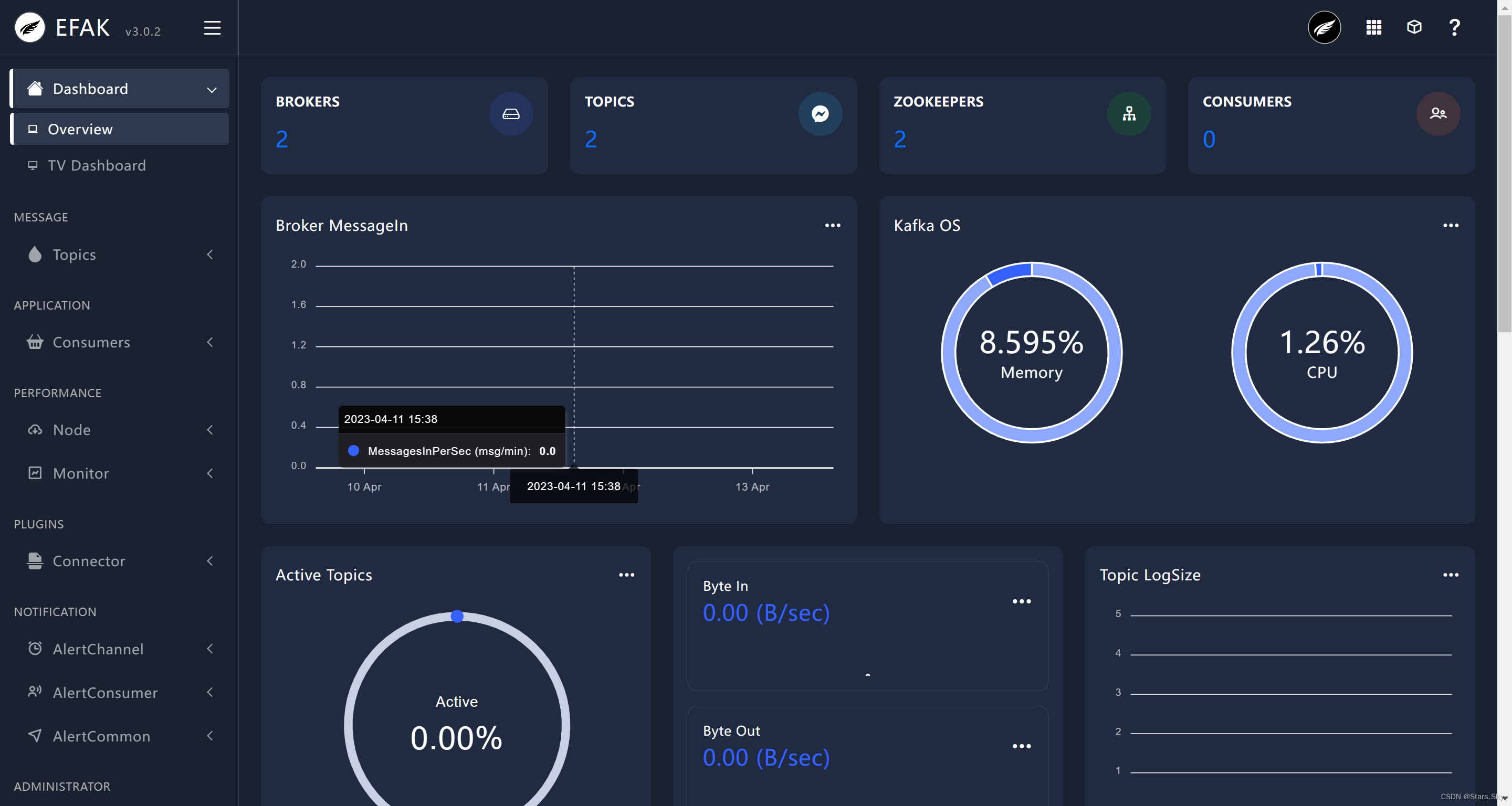
点击 右边列表的 TV Dashboard:
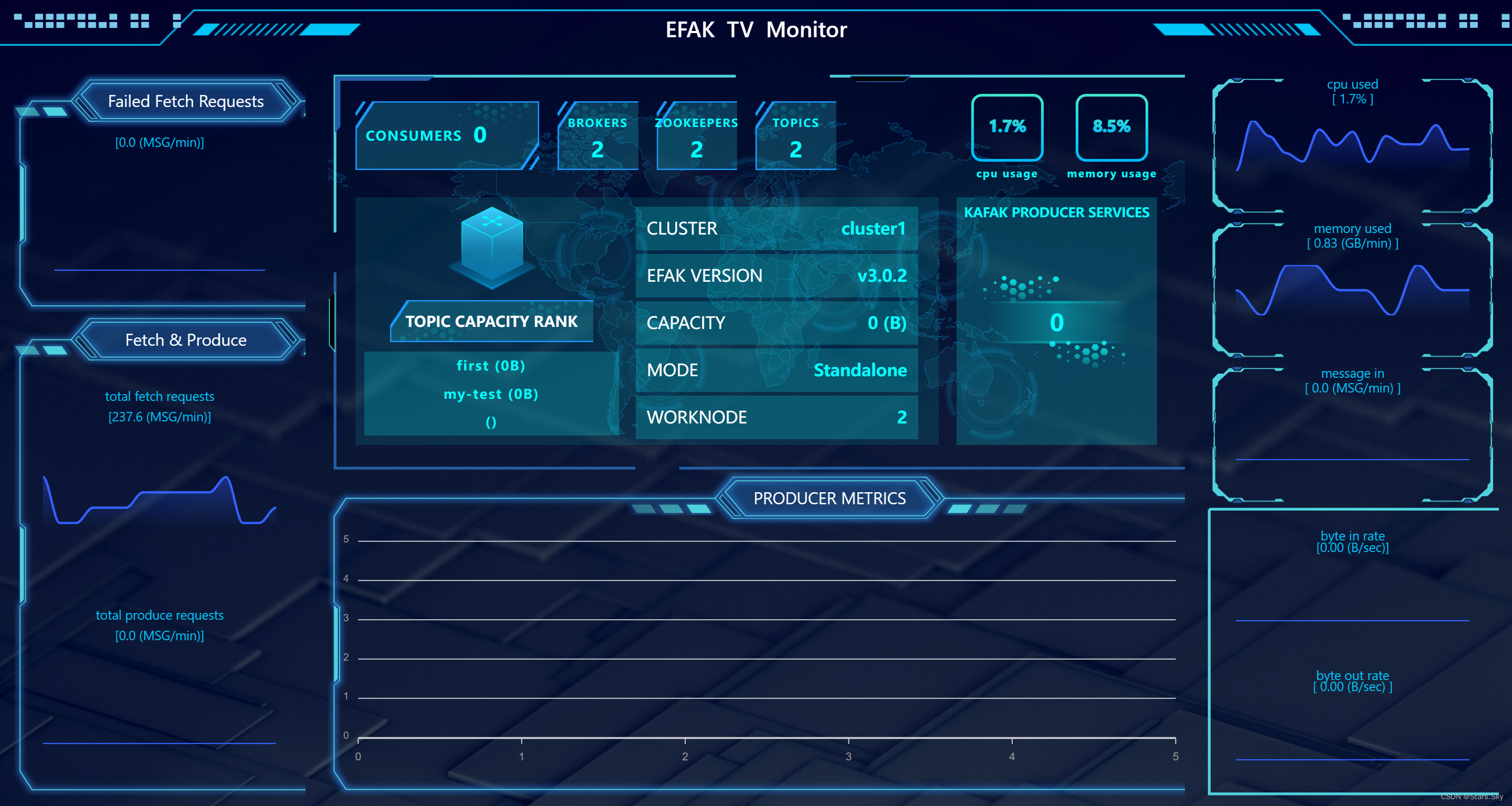
5.7 遇到的小坑
如果 eagle 仪表盘上监控不到任何信息,则查看 eagle 错误日志:
[root@es-node2 ~]# cd /usr/local/kafka-eagle-bin-3.0.2/efak-web-3.0.2/logs/
[root@es-node2 /usr/local/kafka-eagle-bin-3.0.2/efak-web-3.0.2/logs]# tail -f error.log
[2023-04-11 15:17:00] KafkaServiceImpl.Thread-351 - ERROR - Get kafka consumer has error,msg is Failed create new KafkaAdminClient[2023-04-11 15:17:00] MetricsSubTask.Thread-351 - ERROR - Collector consumer topic data has error, msg is java.lang.NullPointerExceptionat org.smartloli.kafka.eagle.core.factory.KafkaServiceImpl.getKafkaConsumer(KafkaServiceImpl.java:749)at org.smartloli.kafka.eagle.web.quartz.MetricsSubTask.bscreenConsumerTopicStats(MetricsSubTask.java:113)at org.smartloli.kafka.eagle.web.quartz.MetricsSubTask.metricsConsumerTopicQuartz(MetricsSubTask.java:73)at org.smartloli.kafka.eagle.web.quartz.MetricsSubTask.run(MetricsSubTask.java:68)

解决办法: 确保你自己 kafka 配置文件的 zookeeper.connect=192.168.170.132:2181,192.168.170.134:2181/kafka 与 eagle 配置文件中的 cluster1.zk.list=192.168.170.132:2181,192.168.170.134:2181/kafka 保持一致,再重新启动 eagle 即可。
六、ELK 对接 Kafka
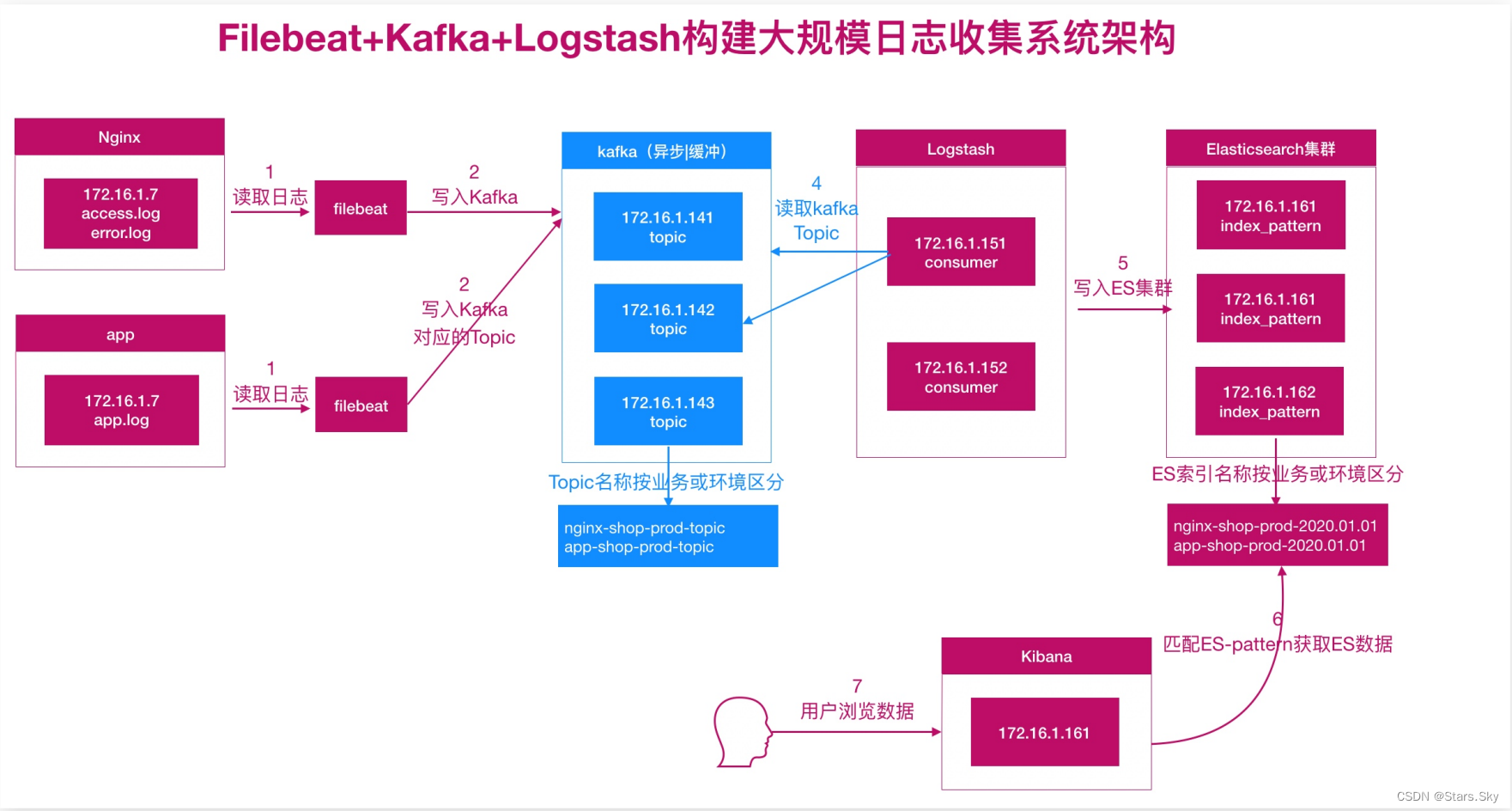
6.1 配置 Filebeat
[root@es-node3 ~]# vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log # 收集日志的类型enabled: true # 启用日志收集paths:- /var/log/nginx/access.log # 日志所在路径tags: ["access"]- type: log # 收集日志的类型enabled: true # 启用日志收集paths:- /var/log/nginx/error.log # 日志所在路径tags: ["error"]output.kafka:hosts: ["192.168.170.132:9092", "192.168.170.134:9092"]topic: nginx_kafka_prodrequired_acks: 1 # 保证消息可靠,0不保证,1等待写入主分区(默认),-1等待写入副本分区compression: gzip # 压缩max_message_bytes: 10000 # 每条消息最大的长度,多余的被删除[root@es-node3 ~]# systemctl restart filebeat.service
6.2 配置 Logstash
[root@es-node1 ~]# vim /etc/logstash/conf.d/test6.conf
input {kafka {bootstrap_servers => "192.168.170.132:9092,192.168.170.134:9092"topics => ["nginx_kafka_prod"] # topic 名称group_id => "logstash" # 消费者组名称client_id => "node1" # 消费者组实例名称consumer_threads => "2" # 理想情况下,您应该拥有与分区数一样多的线程,以实现完美的平衡,线程多于分区意味着某些线程将处于空闲状态#topics_pattern => "app_prod*" # 通过正则表达式匹配要订阅的主题codec => "json"}
}filter {if "access" in [tags][0] {grok {match => { "message" => "%{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] \"%{WORD:method} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:response} (?:%{NUMBER:bytes}|-) %{QS:hostname} (?:%{QS:referrer}|-) (?:%{NOTSPACE:post_args}|-) %{QS:useragent} (?:%{QS:x_forward_for}|-) (?:%{URIHOST:upstream_host}|-) (?:%{NUMBER:upstream_response_code}|-) (?:%{NUMBER:upstream_response_time}|-) (?:%{NUMBER:response_time}|-)" }}useragent {source => "useragent"target => "useragent"}geoip {source => "clientip"}date {match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]target => "@timestamp"timezone => "Asia/Shanghai"}mutate {convert => ["bytes","integer"]convert => ["response_time", "float"]convert => ["upstream_response_time", "float"]remove_field => ["message", "agent", "tags"]add_field => { "target_index" => "kafka-logstash-nginx-access-%{+YYYY.MM.dd}" } }# 提取 referrer 具体的域名 /^"http/if [referrer] =~ /^"http/ {grok {match => { "referrer" => '%{URIPROTO}://%{URIHOST:referrer_host}' }}}# 提取用户请求资源类型以及资源 ID 编号if "sky.com" in [referrer_host] {grok {match => { "referrer" => '%{URIPROTO}://%{URIHOST}/(%{NOTSPACE:sky_type}/%{NOTSPACE:sky_res_id})?"' }}}}else if "error" in [tags][0] {date {match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]target => "@timestamp"timezone => "Asia/Shanghai"}mutate {add_field => { "target_index" => "kafka-logstash-nginx-error-%{+YYYY.MM.dd}" }}}
}output {stdout {codec => rubydebug}elasticsearch {hosts => ["192.168.170.132:9200","192.168.170.133:9200","192.168.170.134:9200"]index => "%{[target_index]}"template_overwrite => true}
}
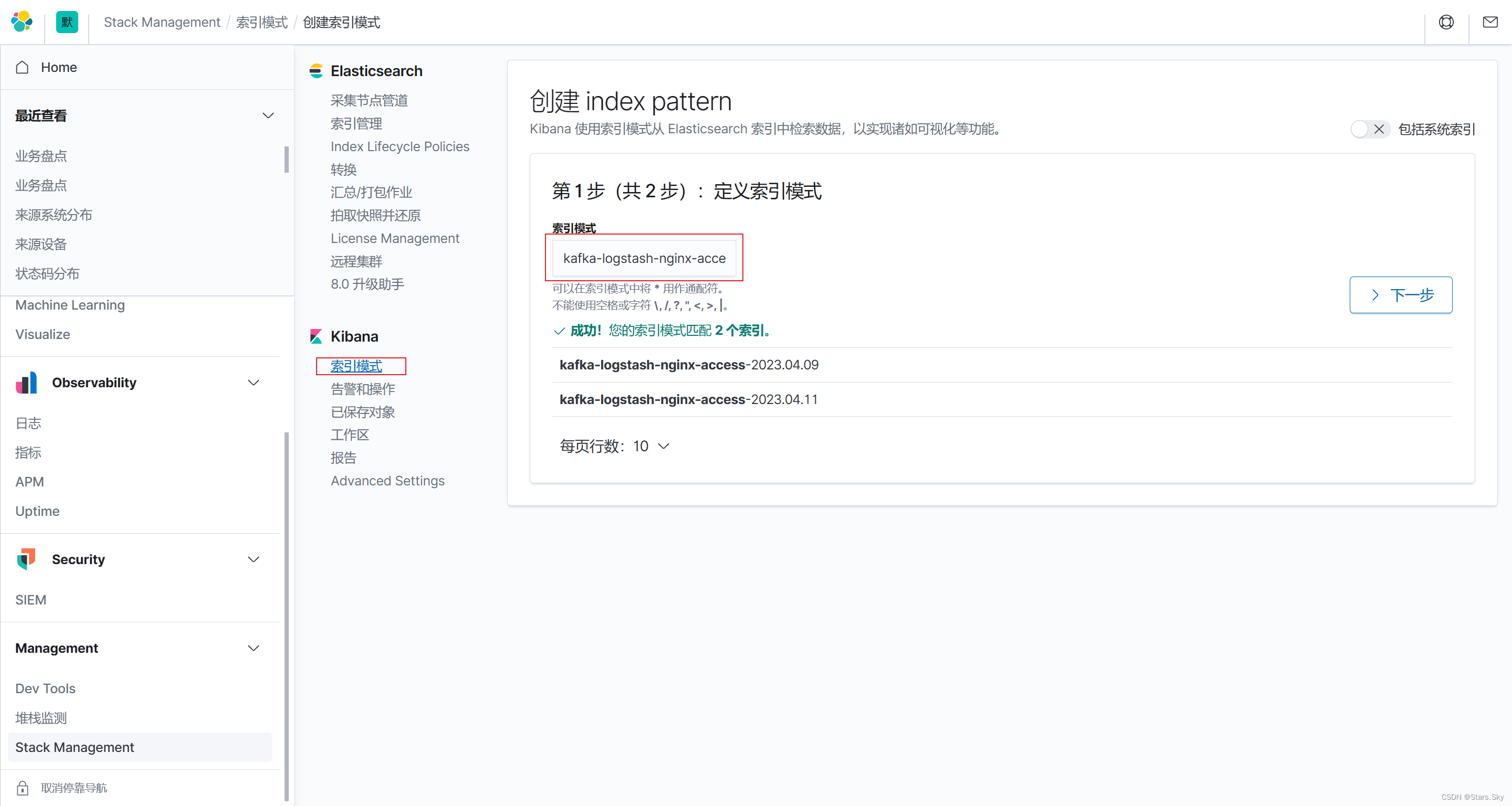
6.3 配置 kibana
创建 Kibana 索引:
上一篇文章:【Elastic (ELK) Stack 实战教程】09、Kibana 分析站点业务日志_Stars.Sky的博客-CSDN博客
下一篇文章:【Elastic (ELK) Stack 实战教程】11、使用 ElastAlert 实现 ES 钉钉群日志告警_Stars.Sky的博客-CSDN博客
相关文章:
【Elastic (ELK) Stack 实战教程】10、ELK 架构升级-引入消息队列 Redis、Kafka
目录 一、ELK 架构面临的问题 1.1 耦合度过高 1.2 性能瓶颈 二、ELK 对接 Redis 实践 2.1 配置 Redis 2.1.1 安装 Redis 2.1.2 配置 Redis 2.1.3 启动 Redis 2.2 配置 Filebeat 2.3 配置 Logstash 2.4 数据消费 2.5 配置 kibana 三、消息队列基本概述 3.1 什么是…...

优先、双端队列-我的基础算法刷题之路(八)
本篇博客旨在整理记录自已对优先队列、双端队列的一些总结,以及刷题的解题思路,同时希望可给小伙伴一些帮助。本人也是算法小白,水平有限,如果文章中有什么错误之处,希望小伙伴们可以在评论区指出来,共勉 &…...
 方法、Python 质数判断)
Python3 os.symlink() 方法、Python 质数判断
Python3 os.symlink() 方法 概述 os.symlink() 方法用于创建一个软链接。 语法 symlink()方法语法格式如下: os.symlink(src, dst)参数 src -- 源地址。 dst -- 目标地址。 返回值 该方法没有返回值。 实例 以下实例演示了 symlink() 方法的使用࿱…...

P1972 [SDOI2009] HH的项链
[SDOI2009] HH的项链 题目描述 HH 有一串由各种漂亮的贝壳组成的项链。HH 相信不同的贝壳会带来好运,所以每次散步完后,他都会随意取出一段贝壳,思考它们所表达的含义。HH 不断地收集新的贝壳,因此,他的项链变得越来…...
力扣解法汇总1026. 节点与其祖先之间的最大差值
目录链接: 力扣编程题-解法汇总_分享记录-CSDN博客 GitHub同步刷题项目: https://github.com/September26/java-algorithms 原题链接:力扣 描述: 给定二叉树的根节点 root,找出存在于 不同 节点 A 和 B 之间的最大值…...
010:Mapbox GL移动鼠标mousemove,显示坐标信息
第010个 点击查看专栏目录 本示例的目的是介绍演示如何在vue+mapbox中移动鼠标mousemove,显示坐标信息。 直接复制下面的 vue+mapbox源代码,操作2分钟即可运行实现效果 文章目录 示例效果配置方式示例源代码(共81行)相关API参考:专栏目标示例效果 配置方式 1)查看基础…...

【两阶段鲁棒优化】利用列-约束生成方法求解两阶段鲁棒优化问题(Python代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

百度暑期实习 C++ 一面
1.数组 链表 数组是一种线性数据结构,其中相同类型的元素连续存储在一段内存中,并且可以通过索引来访问每个元素。数组的优点是随机访问元素非常快速,但缺点是插入或删除元素可能需要移动其他元素。 链表也是一种线性数据结构,但…...

计算机网络第一章(概述)【湖科大教书匠】
1. 各种网络 网络(Network)由若干**结点(Node)和连接这些结点的链路(Link)**组成多个网络还可以通过路由器互连起来,这样就构成了一个覆盖范围更大的网络,即互联网(互连网)。因此,互联网是"网络的网络(Network of Networks)"**因特…...

【JS】vis.js使用之vis-timeline使用攻略,vis-timeline在vue3中实现时间轴、甘特图
vis.js使用之vis-timeline使用攻略,vis-timeline实现时间轴、甘特图1、vis-timeline简介2、安装插件及依赖3、简单示例4、疑难问题集合1. 中文zh-cn本地化2. 关于自定义class样式无法被渲染3. 关于双向数据绑定vis.js是一个基于浏览器的可视化库,它提供了…...

机器学习——数据处理
机器学习简介 机器学习是人工智能的一个实现途径深度学习是机器学习的一个方法发展而来 机器学习:从数据中自动分析获得模型,并利用模型对未知数据进行预测。 数据集的格式: 特征值目标值 比如上图中房子的各种属性是特征值,然…...
多种文字翻译软件-翻译常用软件
整篇文档翻译软件 整篇文档翻译软件是一种实现全文翻译的自动翻译工具,它能够快速、准确地将整篇文档的内容翻译成目标语言。与单词、句子翻译不同,整篇文档翻译软件不仅需要具备准确的语言识别和翻译技术,还需要考虑上下文语境和文档格式等多…...
)
Baumer工业相机堡盟工业相机如何通过BGAPI SDK将相机图像数据用二进制的方式保存到本地(C++)
Baumer工业相机堡盟工业相机如何通过BGAPI SDK将相机图像数据用二进制的方式保存到本地(C)Baumer工业相机Baumer工业相机将图像保存为二进制图像的技术背景代码分析第一步:先转换Byte*图像为二进制图像第二步:在回调函数里进行Buf…...

JavaScript模块的导出和导入之export和module.exports的区别
export和module.exports (需要前面的export没有“s”,后面的module.exports 有“s”) 使用两者根本区别是 **exports **返回的是模块函数 **module.exports **返回的是模块对象本身,返回的是一个类 使用上的区别是exports的方法可以直接调用module.exports需要new…...
基于朴素贝叶斯分类器的钞票真伪识别模型
基于朴素贝叶斯分类器的钞票真伪识别模型 内容 本实验通过实现钞票真伪判别案例来展开学习朴素贝叶斯分类器的原理及应用。 本实验的主要技能点: 1、 朴素贝叶斯分类器模型的构建 2、 模型的评估与预测 3、 分类概率的输出 源码下载 环境 操作系统…...

【Python】【进阶篇】二十二、Python爬虫的BS4解析库
目录二十二、Python爬虫的BS4解析库22.1 BS4下载安装22.2 BS4解析对象22.3 BS4常用语法1) Tag节点22.4 遍历节点22.5 find_all()与find()1) find_all()2) find()22.6 CSS选择器二十二、Python爬虫的BS4解析库 Beautiful Soup 简称 BS4(其中 4 表示版本号࿰…...

UDS统一诊断服务【五】诊断仪在线0X3E服务
文章目录前言一、诊断仪在线服务介绍二、数据格式2.1,请求报文2.2,子功能2.3,响应报文前言 本文介绍UDS统一诊断服务的0X3E服务,希望能对你有所帮助 一、诊断仪在线服务介绍 诊断仪在线服务比较简单,其功能就是告诉服…...
我的创作纪念日:Unity CEO表示生成式AI将是Unity近期发展重点,发布神秘影片预告
PICK 未来的AI技术将会让人类迎来下一个生产力变革,这其中也包括生成型AI的突破性革新。各大公司也正在竞相推出AIGC工具,其中微软的Copilot、Adobe的Firefly、Github的chatGPT等引起了人们的关注。然而,游戏开发领域似乎还没有一款真正针对性…...

秩亏自由网平差的直接解法
目录 一、原理概述二、案例分析三、代码实现四、结果展示一、原理概述 N = B T P B N=B^TPB N=<...

大数据开发必备面试题Spark篇合集
1、Hadoop 和 Spark 的相同点和不同点? Hadoop 底层使用 MapReduce 计算架构,只有 map 和 reduce 两种操作,表达能力比较欠缺,而且在 MR 过程中会重复的读写 hdfs,造成大量的磁盘 io 读写操作,所以适合高时…...

如何让老旧游戏手柄重获新生:XOutput输入转换器完整指南
如何让老旧游戏手柄重获新生:XOutput输入转换器完整指南 【免费下载链接】XOutput DirectInput to XInput wrapper 项目地址: https://gitcode.com/gh_mirrors/xo/XOutput 你是否拥有一些老旧但质量优秀的游戏手柄、摇杆或方向盘,却发现在现代游戏…...

从本地到云端:手把手教你用Talend Open Studio实现MySQL到AWS S3的数据同步
从本地到云端:手把手教你用Talend Open Studio实现MySQL到AWS S3的数据同步 在数字化转型浪潮中,企业数据正以惊人的速度从传统数据库向云端迁移。根据行业调研数据显示,85%的企业正在或计划将核心业务数据迁移至云平台,而其中数据…...

缠论分析工具终极指南:如何在通达信中实现可视化技术分析
缠论分析工具终极指南:如何在通达信中实现可视化技术分析 【免费下载链接】Indicator 通达信缠论可视化分析插件 项目地址: https://gitcode.com/gh_mirrors/ind/Indicator 还在为复杂的缠论分析而头疼吗?想要在通达信软件中轻松识别分型、笔、线…...

终极指南:如何用免费C工具快速管理天龙八部单机版游戏数据
终极指南:如何用免费C#工具快速管理天龙八部单机版游戏数据 【免费下载链接】TlbbGmTool 某网络游戏的单机版本GM工具 项目地址: https://gitcode.com/gh_mirrors/tl/TlbbGmTool 还在为《天龙八部》单机版的数据管理而烦恼吗?TlbbGmTool是一款专为…...

VS Code 轻量自动化实战:Trae 集成 3 步配置与 5 个高频任务模板
1. 三步集成不是魔法,是可控的上下文锚点 大多数人第一次在 VS Code 里配 Trae,会直接打开官方文档翻到「安装」章节,复制粘贴几行命令,重启编辑器,然后对着空白的侧边栏发呆——它没反应。不是插件没装好,也不是网络问题。是我试过三次才意识到:Trae 的「激活」不靠重…...

CANN/cannbot-skills模型推理融合算子优化
【免费下载链接】cannbot-skills CANNBot 是面向 CANN 开发的用于提升开发效率的系列智能体,本仓库为其提供可复用的 Skills 模块。 项目地址: https://gitcode.com/cann/cannbot-skills name: model-infer-fusion description: 基于 PyTorch 框架的昇腾 NPU…...

5分钟搞定U盘验货!这款绿色工具真香到离谱
兄弟们,你有没有买过那种“1TB只要39块还包邮”的U盘? 醒醒!那玩意儿大概率是扩容盘——实际容量可能只有64GB,超出部分写进去的数据全是空气,轻则文件损坏,重则项目代码全丢,救都救不回来&…...

会议纪要整理不清?如何将会议成果转化为可落地任务
身边不少HR朋友都有过纪要整理的困扰,一场会议或面谈后,花费大量时间整理,最终产出的纪要却零散杂乱,无法提炼可落地的任务,导致会议效果大打折扣。结合半年多的实测体验,整理出一套零基础也能上手的高效方…...

《CVPR2025-DEIM创新改进项目实战:从原理到部署的深度学习优化全攻略》005、DEIM模型架构总览——编码器-解码器与动态门控设计
CVPR2025-DEIM创新改进项目实战:DEIM模型架构总览——编码器-解码器与动态门控设计 从一次诡异的梯度爆炸说起 去年冬天调DEIM的早期原型,模型在训练到第47个epoch时突然loss飙到NaN。检查了三天,最后发现是门控模块的sigmoid输出在极端情况下饱和,导致梯度回传时门控信号…...
选购指南)
来姨妈不舒适有没有补充营养的经期产品推荐?ULOV(最美是你)选购指南
# 来姨妈不舒适有没有补充营养的经期产品推荐?ULOV(最美是你)选购指南来姨妈不舒适有没有补充营养的经期产品推荐?这是14-40岁女性高频搜索的真实困惑。传统红糖水、热饮或普通果汁难以兼顾舒缓不适与科学补养,而市面多…...