GraphSAGE的基础理论
文章目录
- GraphSAGE原理(理解用)
- GraphSAGE工作流程
- GraphSAGE的实用基础理论(编代码用)
- 1. GraphSAGE的底层实现(pytorch)
- PyG中NeighorSampler实现节点维度的mini-batch + GraphSAGE样例
- PyG中的SAGEConv实现
- 2. GraphSAGE的实例
- 引用
GraphSAGE原理(理解用)
引入:
GCN的缺点:
- 从大型网络中学习的困难:GCN在嵌入训练期间需要所有节点的存在。这不允许批量训练模型。
- 推广到看不见的节点的困难:GCN假设单个固定图,要求在一个确定的图中去学习顶点的embedding。但是,在许多实际应用中,需要快速生成看不见的节点的嵌入。而GCN无法直接泛化到在训练过程没有出现过的顶点,即属于一种直推式(transductive)的学习。
GraphSAGE:其核心思想是通过学习一个对邻居顶点进行聚合表示的函数来产生目标顶点的embedding向量。
GraphSAGE工作流程
- 对图中每个顶点的邻居顶点进行采样。模型不使用给定节点的整个邻域,而是统一采样一组固定大小的邻居。
- 根据聚合函数聚合邻居顶点蕴含的信息。
- 得到图中各顶点的向量表示供下游任务使用。
-
对图中每个顶点的邻居顶点进行采样
- 考虑计算效率的情况下:对每个顶点采样一定数量的邻居顶点作为待聚合信息的顶点。设采样数量为k,若顶点邻居数少于k,则采用有放回的抽样方法,直到采样出k个顶点。若顶点邻居数大于k,则采用无放回的抽样。
- 不考虑计算效率的情况下:完全可以对每个顶点利用其所有的邻居顶点进行信息聚合,这样是信息无损的。
具体来说:
在第 kkk 层时,对每个顶点 vvv,首先使用顶点 vvv 的邻居顶点的 k−1k-1k−1 层的 embedding 表示来产生其邻居顶点的第 kkk 层聚合表示 hN(v)kh_{N(v)}^khN(v)k,之后将 hN(v)kh_{N(v)}^khN(v)k 和顶点 vvv 的第 k−1k-1k−1 层表示 hvk−1h_v^{k-1}hvk−1进行拼接(concat),经过一个非线性变换产生顶点 vvv 的第 kkk 层 embedding 表示。一般而言,可用公式可表示为(只是为了说明流程,具体还要看聚合函数的选取):hN(v)k=aggregatek({huk−1,∀u∈N(v)})h_{N(v)}^k = aggregate_k(\{h_u^{k-1}, \forall u \in N(v)\})hN(v)k=aggregatek({huk−1,∀u∈N(v)})hvk=σ(Wk⋅concat(hvk−1,hN(v)k))h_v^k = \sigma (W^k \cdot concat(h_v^{k-1},h_{N(v)}^k) ) hvk=σ(Wk⋅concat(hvk−1,hN(v)k))
-
根据聚合函数聚合邻居顶点蕴含的信息
聚合函数的选取:
- MEAN aggregator:
hvk=σ(W⋅MEAN({hvk−1}∪{huk−1,∀u∈N(v)}))h_v^k = \sigma (W \cdot MEAN(\{h_v^{k-1}\}\cup\{h_u^{k-1},\forall u \in N(v)\}))hvk=σ(W⋅MEAN({hvk−1}∪{huk−1,∀u∈N(v)})) - Pooling aggregator:
hN(v)k=pooling_method({σ(Whuk+b),∀u∈N(v)})h_{N(v)}^k = pooling\_method(\{\sigma(Wh_u^k+b), \forall u \in N(v)\})hN(v)k=pooling_method({σ(Whuk+b),∀u∈N(v)})注意这里是hN(v)k,而不是hvk;其中pooling_method∈{max,mean}注意这里是h_{N(v)}^k,而不是h_v^k;其中pooling\_method \in \{max,mean\}注意这里是hN(v)k,而不是hvk;其中pooling_method∈{max,mean} - LSTM aggregator:
将中心节点的邻居节点随机打乱作为输入序列,将 所得向量表示 hN(v)kh_{N(v)}^khN(v)k 与 中心节点的向量hvk−1h_v^{k-1}hvk−1 表示分别经过非线性变换后拼接,得到中心节点在该层的向量表示。LSTM 本身用于序列数据,而邻居节点没有明显的序列关系,因此输入到 LSTM 中的邻居节点需要随机打乱顺序
- MEAN aggregator:
-
参数的学习
-
无监督学习
基于图的损失函数希望邻近的顶点具有相似的向量表示,同时让分离的顶点的表示尽可能不同。 目标函数如下:JG(zu)=−log(σ(zuTzv))−Q⋅Evn∼Pn(v)log(σ(−zuTzvn))J_G(z_u) = -log(\sigma(z_u^Tz_v))-Q\cdot E_{v_n ∼ P_n(v) }log(\sigma(-z_u^Tz_{v_n}))JG(zu)=−log(σ(zuTzv))−Q⋅Evn∼Pn(v)log(σ(−zuTzvn))其中 vvv 是在定长随机游走中在 uuu 附近同时出现的节点,σσσ 是 sigmoid函数sigmoid函数sigmoid函数 ,PnP_nPn是一个负抽样分布,QQQ定义了负抽样的数量。
与DeepWalk不同的是,这里的顶点表示向量是通过聚合顶点的邻接点特征产生的,而不是简单的进行一个embedding lookup操作得到。
-
监督学习
监督学习形式根据任务的不同直接设置目标函数即可,如最常用的节点分类任务使用交叉熵损失函数。
-
GraphSAGE的实用基础理论(编代码用)
1. GraphSAGE的底层实现(pytorch)
PyG中NeighorSampler实现节点维度的mini-batch + GraphSAGE样例
参考博客:https://blog.csdn.net/weixin_39925939/article/details/121458145
PyG中的SAGEConv实现
原论文中实现方法:xi′=W⋅concat(Aggregatej∈N(i)xj,xi)x_i' = W \cdot concat(Aggregate_{j\in N(i)}x_j,x_i)xi′=W⋅concat(Aggregatej∈N(i)xj,xi)
PyG中实现方法:xi′=W1xi+W2⋅Aggregatej∈N(i)xjx_i' = W_1x_i + W_2 \cdot Aggregate_{j\in N(i)}x_jxi′=W1xi+W2⋅Aggregatej∈N(i)xj
这两种方式是一样的,但是不同的是:
SAGEConv代码中的邻居就是你传入的邻居,不管是使用NeighborSampler等方式对邻居进行采样过的邻居还是未采样的所有邻居,它只管接收你传入的邻居,邻居采样不在这里实现。
-
init函数
参数说明:
in_channels: Union[int, Tuple[int, int]]:输入原始特征或者隐含层embedding的维度。如果是-1,则根据传入的x来推断特征维度。注意in_channels可以是一个整数,也可以是两个整数组成的tuple,分别对应source节点和target节点的特征维度。
- source节点: 中心节点的邻居节点。{xj,∀j∈N(i)}\{x_j, \forall j\in N(i)\}{xj,∀j∈N(i)}
- target节点:中心节点。xix_ixi
- in_channels[0]:参数W2W_2W2的shape[0],点乘source节点聚合后的特征矩阵
- in_channels[1]:参数W1W_1W1的shape[0],点乘对应target节点的特征矩阵
out_channels:输出embedding的维度normalize:是否对输出进行 l2l_2l2归一化,默认为Falsebias:偏差,默认为Trueroot_weight:输出是否会加上节点自身特征转换维度后的值,默认是True。kwargs.setdefault('aggr', 'mean'):邻域聚合方式,默认aggr='mean',其余方式还有aggr='max',aggr='add'
class SAGEConv(MessagePassing): def __init__(self, in_channels: Union[int, Tuple[int, int]],out_channels: int, normalize: bool = False,root_weight: bool = True,bias: bool = True, **kwargs): # yapf: disablekwargs.setdefault('aggr', 'mean')super(SAGEConv, self).__init__(**kwargs)self.in_channels = in_channelsself.out_channels = out_channelsself.normalize = normalizeself.root_weight = root_weightif isinstance(in_channels, int):in_channels = (in_channels, in_channels)self.lin_l = Linear(in_channels[0], out_channels, bias=bias)if self.root_weight:self.lin_r = Linear(in_channels[1], out_channels, bias=False)self.reset_parameters() -
forward函数
参数说明:
x:Union[Tensor, OptPairTensor]:可以是Tensor,也可以是OptPairTensor(pyg定义的tuple of Tensor)。
当图是
bipartite的时候,x是OptPairTensor,为了和init函数中定义的in_channel对应,要使得:source节点(邻居节点)特征对应x[0],在代码中赋值给x_l,in_channel[0](W2W_2W2)定义为lin_ltarget节点(中心节点)特征对应x[1],在代码中赋值给x_r,in_channel[1](W1W_1W1)定义为lin_r
edge_index: Adj: Adj是pyg定义的邻接矩阵类型,可以是Tensor,也可以是SparseTensor。
def forward(self, x: Union[Tensor, OptPairTensor], edge_index: Adj,size: Size = None) -> Tensor:""""""if isinstance(x, Tensor):x: OptPairTensor = (x, x)# propagate_type: (x: OptPairTensor)out = self.propagate(edge_index, x=x, size=size)out = self.lin_l(out)x_r = x[1]if self.root_weight and x_r is not None:out += self.lin_r(x_r)if self.normalize:out = F.normalize(out, p=2., dim=-1)return out -
消息传递函数(message函数)
forward函数中使用
self.propagate时调用,传入的edge_index不算显式参数。参数说明:
- edge_index为Tensor
edge_index为Tensor的时候,propagate调用message和aggregate实现消息传递和更新。这里message函数对邻居特征没有任何处理,只是进行了传递,所以最终propagate函数只是对邻居特征进行了aggregate - edge_index为SparseTensor
edge_index为SparseTensor的时候,propagate函数会在message_and_aggregate被定义的情况下被优先调用,代替message和aggregate。
这里message_and_aggregate直接调用类似矩阵计算matmul(adj_t, x[0], reduce=self.aggr)。x[0]是source节点的特征。matmul来自于torch_sparse,除了类似常规的矩阵相乘外,还给出了可选的reduce,这里可以实现add,mean和max聚合。
def message(self, x_j: Tensor) -> Tensor:return x_jdef message_and_aggregate(self, adj_t: SparseTensor,x: OptPairTensor) -> Tensor:adj_t = adj_t.set_value(None, layout=None)return matmul(adj_t, x[0], reduce=self.aggr) - edge_index为Tensor
2. GraphSAGE的实例
import torch
import torch.nn.functional as F
from torch_geometric.nn.conv import SAGEConvclass SAGE(torch.nn.Module):def __init__(self, in_channels, hidden_channels, out_channels, dropout=0.):super(SAGE, self).__init__()self.convs = torch.nn.ModuleList()self.convs.append(SAGEConv(in_channels, hidden_channels))self.convs.append(SAGEConv(hidden_channels, out_channels))self.dropout = dropoutdef reset_parameters():for conv in self.convs:conv.reset_parameters()def forward(self, x, edge_index):x = self.convs[0](x, edge_index)x = F.relu(x)x = F.dropout(x, p=self.dropout, training=self.training)x = self.convs[1](x, edge_index)return x.log_softmax(dim=-1)#读取数据
from torch_geometric.datasets import Planetoid
import torch_geometric.transforms as Ttransform = T.ToSparseTensor()
# 这里加上了ToSparseTensor(),所以边信息是以adj_t形式存储的,如果没有这个变换,则是edge_index
dataset = Planetoid(name='Cora', root=r'./dataset/Cora', transform=transform)
data = dataset[0]
data.adj_t = data.adj_t.to_symmetric()model = SAGE(in_channels=dataset.num_features, hidden_channels=128, out_channels=dataset.num_classes)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)def train():model.train()optimizer.zero_grad()out = model(data.x, data.adj_t)[data.train_mask] #前面我们提到了,SAGE是实现了edge_index和adj_t两种形式的loss = F.nll_loss(out, data.y[data.train_mask])loss.backward()optimizer.step()return loss.item()@torch.no_grad()
def test():model.eval()out = model(data.x, data.adj_t)y_pred = out.argmax(axis=-1)correct = y_pred == data.ytrain_acc = correct[data.train_mask].sum().float()/data.train_mask.sum()valid_acc = correct[data.val_mask].sum().float()/data.val_mask.sum()test_acc = correct[data.test_mask].sum().float()/data.test_mask.sum()return train_acc, valid_acc, test_acc #跑10个epoch看一下模型效果
for epoch in range(20):loss = train()train_acc, valid_acc, test_acc = test()print(f'Epoch: {epoch:02d}, 'f'Loss: {loss:.4f}, 'f'Train_acc: {100 * train_acc:.3f}%, 'f'Valid_acc: {100 * valid_acc:.3f}% 'f'Test_acc: {100 * test_acc:.3f}%')引用
文章参考了:
- https://blog.csdn.net/weixin_39925939/article/details/121343538
- https://zhuanlan.zhihu.com/p/79637787
- https://zhuanlan.zhihu.com/p/336195862
相关文章:

GraphSAGE的基础理论
文章目录GraphSAGE原理(理解用)GraphSAGE工作流程GraphSAGE的实用基础理论(编代码用)1. GraphSAGE的底层实现(pytorch)PyG中NeighorSampler实现节点维度的mini-batch GraphSAGE样例PyG中的SAGEConv实现2. …...

Windows 安装 GDAL C++库
Windows 安装 GDAL C库1. 方法1:下载配置网友编译的GDAL版本1.1 下载1.2 配置1.3 测试1.4 缺点2. 方法2:自己编译3. 参考1. 方法1:下载配置网友编译的GDAL版本 1.1 下载 CSDN: GDAL,geos联合编译的库,版本为1.8.0&am…...

二叉树基础概念
1.二叉树种类 1.1 满二叉树 满二叉树:如果一棵二叉树只有度为 0 0 0 的结点和度为 2 2 2 的结点,并且度为0的结点在同一层上,则这棵二叉树为满二叉树。 如图所示: 这棵二叉树为满二叉树,也可以说深度为 k k k&…...

【MySQL】(1)数据库基础,库与表的增删查改,数据库的备份与还原
文章目录服务器,数据库,表关系MySQL 数据存储逻辑SQL 分类存储引擎库的操作查看数据库创建数据库查看创建语句删除数据库选择(切换)数据库查看当前选择的数据库修改数据库字符集和排序规则表的操作创建表查询表查询表结构插入数据…...

Python基础-01 变量
注释 注释的分类 在Python中,支持单行及多行注释 单行注释 使用#对代码进行说明,#右边的所有内容就是注释的内容,起辅助说明作用 # #右边的都是注释,解析器会忽略 print(hello world) #在控制台里打印一段话多行注释 多行注释中,允许换行,使用三个单引号开始,三个单引号结…...
springcloud2.1.0整合seata1.5.2+nacos2.10(附源码)
springcloud2.1.0整合seata1.5.2nacos2.10(附源码) 1.创建springboot2.2.2springcloud2.1.0的maven父子工程如下,不过多描述: 搭建过程中也出现很多问题,主要包括: 1.seataServer.properties配置文件的组…...

map原理
map源码结构体: type hmap struct {count int // 元素的个数B uint8 // buckets 数组的长度就是 2^B 个overflow uint16 // 溢出桶的数量buckets unsafe.Pointer // 2^B个桶对应的数组指针oldbuckets unsafe.Pointer // 发生扩容时࿰…...
概览)
[Ext JS]3.6 Ext JS 表格(Grid)概览
Grid, 翻译过来是网格, 也就是表格。 Grid 的基本构成 面板 :Ext.grid.Panel表格视图 :Ext.view.Table。 不直接使用, 通过面板的viewConfig配置项进行配置。比如可以用来配置表格中行是否跳色显示列: Ext.grid.column.Column。 表格中的列定义store , 表格的数据示例代码…...
关于使用云渲染的五大优势
在不影响质量或性能的情况下节省时间、金钱和资源,对于需要在通常较短且严格的期限内创建高质量 3D 内容的专业人士来说,云渲染都是最好的选择!云渲染作为数字媒体生产的最新趋势,与传统的渲染农场和机器相比具有许多优势…...

CSS基础样式
1.高度和宽度 .c1{height:300px;width:500px; } 注意事项: 宽度,支持百分比 行内标签:默认无效 块级标签:默认有效(右侧区域就算是空白,也不给占用) 2.块级和行内标签 css样式:标签…...

第03章_流程控制语句
第03章_流程控制语句 讲师:尚硅谷-宋红康(江湖人称:康师傅) 官网:http://www.atguigu.com 本章专题与脉络 流程控制语句是用来控制程序中各语句执行顺序的语句,可以把语句组合成能完成一定功能的小逻辑模…...
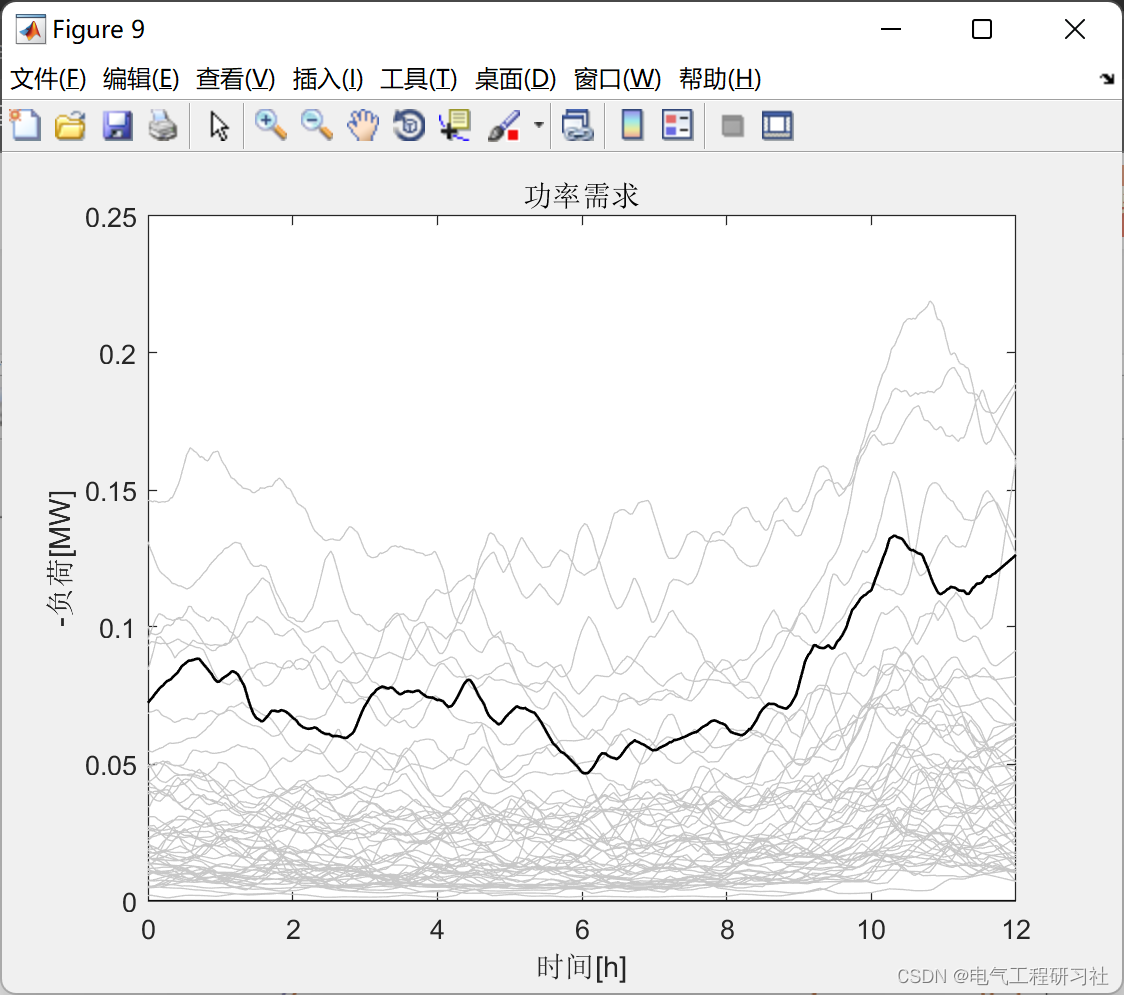
配电网电压调节及通信联系研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

stegano(图片隐写、摩斯密码)
附件是PDF,我们在选择内容时发现光标溢出了文本 说明这里还存在一些我们看不到的内容 直接CtrlA全选,CtrlC复制后新建一个纯文本文件 将复制的东西粘贴过去 粘贴后发现果然多出来了一些东西,提取出来 BABA BBB BA BBA ABA AB B AAB ABAA A…...
wsl安装torch_geometric
在官网选择需要的版本 选择安装途径,选择runfile 执行第一行,会下载一个文件到目录下 需要降低C的版本,否则 执行sudo sh cuda_11.1.0_455.23.05_linux.run,会出现 查看对应的文件,会有 可以加上override参数之后,…...
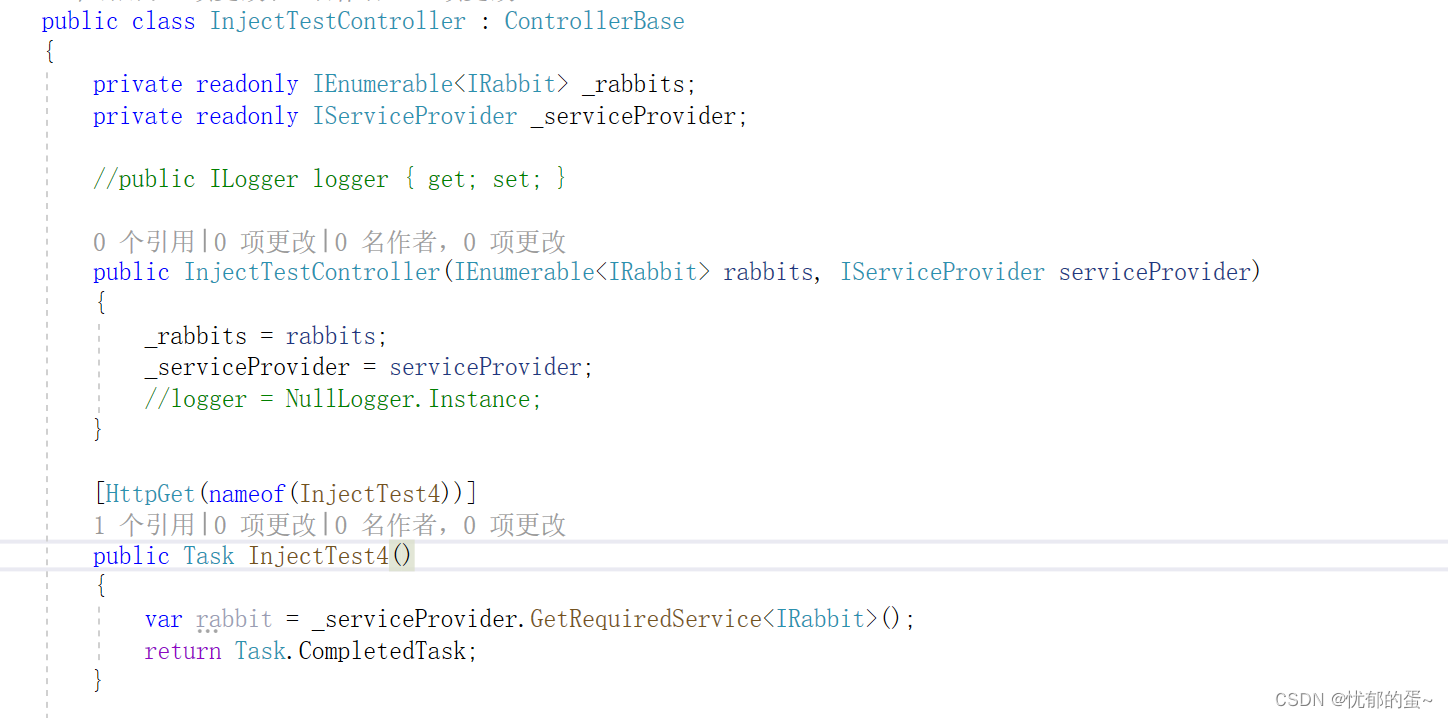
ASP.NET Core - 依赖注入(二)
2,NET Core 依赖注入的基本用法 话接上篇,这一章介绍 .NET Core 框架自带的轻量级 Ioc 容器下服务使用的一些知识点,大家可以先看看上一篇文章 [ASP.NET Core - 依赖注入(一)] 2.3 服务解析 通过 IServiceCollection 注册了服务之后…...

Scala之集合(1)
目录 集合介绍: 不可变集合继承图:编辑 可变集合继承图 数组: 不可变数组: 样例代码: 遍历集合的方法: 1.for循环 2.迭代器 3.转换成List列表: 4.使用foreach()函数&a…...

公网使用SSH远程登录macOS服务器【内网穿透】
文章目录前言1. macOS打开远程登录2. 局域网内测试ssh远程3. 公网ssh远程连接macOS3.1 macOS安装配置cpolar3.2 获取ssh隧道公网地址3.3 测试公网ssh远程连接macOS4. 配置公网固定TCP地址4.1 保留一个固定TCP端口地址4.2 配置固定TCP端口地址5. 使用固定TCP端口地址ssh远程前言…...
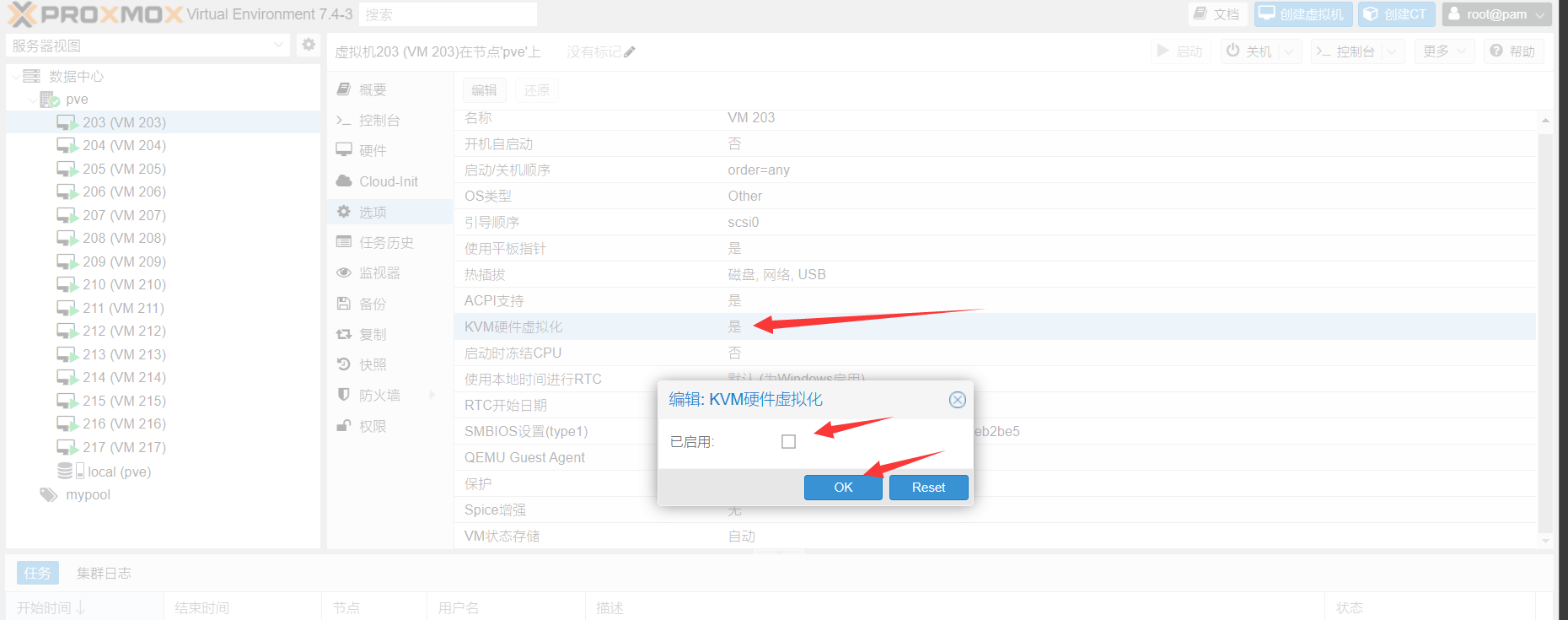
PVE相关的各种一键脚本(一键安装PVE)(一键开设KVM虚拟化的NAT服务器-自带内外网端口转发)
PVE 原始仓库:https://github.com/spiritLHLS/pve 前言 建议debian在使用前尽量使用最新的系统 非debian11可使用 debian一键升级 来升级系统 当然不使用最新的debian系统也没问题,只不过得不到官方支持 请确保使用前机器可以重装系统,…...
)
CSDN目录博客(zhaoshuangjian)
总目录 一、Java1.1 高并发1.2 多线程1.3 集合1.4 I/O1.5 异常1.6 事务1.7 锁机制1.8 JVM 二、数据库2.1 mysql2.1.1 mysql索引2.1.1 mysql锁2.1.1 mysql事务2.1.1 2.2 oracle2.3 postgresql2.4 达梦2.5 人大金仓kingbase 三、设计模式四、中间件4.1 缓存中间件-redis4.2 缓存中…...
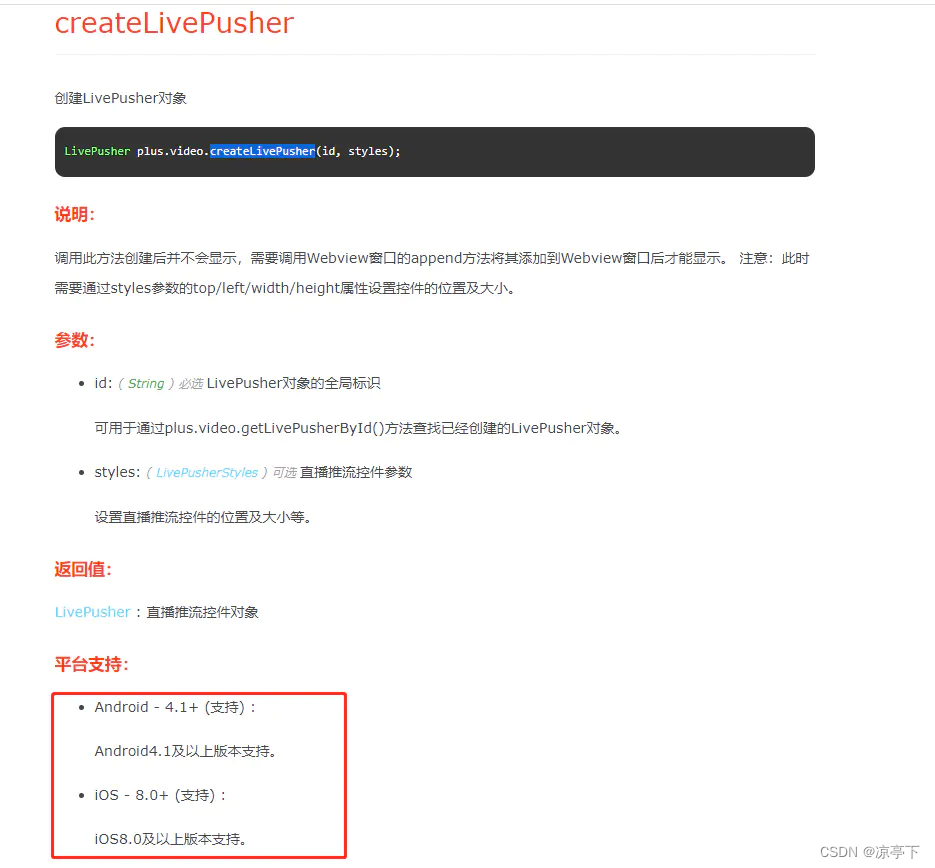
uniapp人脸识别解决方案
APP端: 因为APP端无法使用uni的camera组件,最开始考虑使用内嵌webview的方式,通过原生dom调用video渲染画面然后通过canvas截图。但是此方案兼容性在ios几乎为0,如果app只考虑安卓端的话可以采用此方案。后面又想用live-pusher组件…...

别再只调库了!手写KNN算法识别MNIST数字,从距离计算到加权投票的完整实现与性能对比
从零构建KNN算法:MNIST手写数字识别的底层实现与深度优化 在机器学习入门阶段,K最近邻(KNN)算法往往是第一个接触的经典分类方法。大多数教程止步于调用sklearn的几行代码,却忽略了算法底层的精妙设计。本文将带您从数…...

【实战】Latex|在保留ACM-Reference-Format格式的前提下,实现参考文献按引用顺序排列
1. 问题背景与核心痛点 当你使用ACM官方模板撰写论文时,参考文献格式要求必须采用ACM-Reference-Format样式。这个格式有个让人头疼的特性:它会强制按作者姓氏字母顺序排列参考文献,而不是按照文中实际引用顺序。想象一下,你精心设…...

Perplexity学校信息检索的“黑箱”终于被打开:基于37所样本校实测的响应延迟、召回率与可信度三维评估报告
更多请点击: https://codechina.net 第一章:Perplexity学校信息检索的“黑箱”终于被打开:基于37所样本校实测的响应延迟、召回率与可信度三维评估报告 实测方法论:三维度穿透式评估框架 我们对全国37所高校(含985/2…...

FreeRTOS+LwIP 2.2.0实战:tcpip_thread消息队列与定时器如何协同工作?
FreeRTOS与LwIP 2.2.0深度协同:消息队列与定时器的精妙舞步 在嵌入式网络开发中,实时操作系统与轻量级TCP/IP协议栈的协同工作一直是开发者关注的焦点。FreeRTOS作为嵌入式领域广泛使用的实时操作系统,与LwIP这一轻量级TCP/IP协议栈的组合&am…...

如何用Inkscape实现专业级光学设计?终极免费光线追踪插件完整指南
如何用Inkscape实现专业级光学设计?终极免费光线追踪插件完整指南 【免费下载链接】inkscape-raytracing An extension for Inkscape that makes it easier to draw optical diagrams. 项目地址: https://gitcode.com/gh_mirrors/in/inkscape-raytracing 你…...

国产ARM主板实战:从设计选型到性能优化的嵌入式开发指南
1. 项目概述:从“能用”到“好用”的国产ARM主板之路最近几年,如果你关注过硬件开发、嵌入式系统或者国产化替代的圈子,一定会频繁听到“国产ARM主板”这个词。它不再是实验室里的样品,而是越来越多地出现在工业控制、边缘计算、智…...

2026四大主流收银系统深度横评:商拓、柚子、商琦云与银阁仕实战对比
在零售和餐饮行业数字化转型的浪潮中,收银系统早已超越了简单的“算账工具”范畴,成为了门店运营的中枢神经。很多店主在选型时容易陷入一个误区:只盯着硬件价格或者界面好不好看,却忽略了系统在高峰期的稳定性、数据链路的打通能…...

终极Python GUI设计器:Pygubu Designer完全指南
终极Python GUI设计器:Pygubu Designer完全指南 【免费下载链接】pygubu-designer A simple GUI designer for the python tkinter module 项目地址: https://gitcode.com/gh_mirrors/py/pygubu-designer 还在为Python GUI开发而烦恼吗?厌倦了手写…...

如何构建高效科研知识库:Obsidian文献管理系统的3种创新策略
如何构建高效科研知识库:Obsidian文献管理系统的3种创新策略 【免费下载链接】obsidian_vault_template_for_researcher This is an vault template for researchers using obsidian. 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian_vault_template_for_r…...

Helix QAC 2023.1更新:编码标准覆盖率如何提升C/C++项目合规性
1. 项目概述:一次聚焦于“合规性”的精准升级最近在梳理团队今年的代码质量工具链时,Helix QAC 2023.1的更新通知引起了我的注意。作为一名常年与C/C代码质量、功能安全标准(如MISRA、AUTOSAR C14)打交道的开发者,我对…...