Huggingface微调BART的代码示例:WMT16数据集训练新的标记进行翻译
BART模型是用来预训练seq-to-seq模型的降噪自动编码器(autoencoder)。它是一个序列到序列的模型,具有对损坏文本的双向编码器和一个从左到右的自回归解码器,所以它可以完美的执行翻译任务。

如果你想在翻译任务上测试一个新的体系结构,比如在自定义数据集上训练一个新的标记,那么处理起来会很麻烦,所以在本文中,我将介绍添加新标记的预处理步骤,并介绍如何进行模型微调。
因为Huggingface Hub有很多预训练过的模型,可以很容易地找到预训练标记器。但是我们要添加一个标记可能就会有些棘手,下面我们来完整的介绍如何实现它,首先加载和预处理数据集。
加载数据集
我们使用WMT16数据集及其罗马尼亚语-英语子集。load_dataset()函数将从Huggingface下载并加载任何可用的数据集。
importdatasetsdataset=datasets.load_dataset("stas/wmt16-en-ro-pre-processed", cache_dir="./wmt16-en_ro")

在上图1中可以看到数据集内容。我们需要将其“压平”,这样可以更好的访问数据,让后将其保存到硬盘中。
defflatten(batch):batch['en'] =batch['translation']['en']batch['ro'] =batch['translation']['ro']returnbatch# Map the 'flatten' functiontrain=dataset['train'].map( flatten )test=dataset['test'].map( flatten )validation=dataset['validation'].map( flatten )# Save to disktrain.save_to_disk("./dataset/train")test.save_to_disk("./dataset/test")validation.save_to_disk("./dataset/validation")
下图2可以看到,已经从数据集中删除了“translation”维度。

标记器
标记器提供了训练标记器所需的所有工作。它由四个基本组成部分:(但这四个部分不是所有的都是必要的)
Models:标记器将如何分解每个单词。例如,给定单词“playing”:i) BPE模型将其分解为“play”+“ing”两个标记,ii) WordLevel将其视为一个标记。
Normalizers:需要在文本上发生的一些转换。有一些过滤器可以更改Unicode、小写字母或删除内容。
Pre-Tokenizers:为操作文本提供更大灵活性处理的函数。例如,如何处理数字。数字100应该被认为是“100”还是“1”、“0”、“0”?
Post-Processors:后处理具体情况取决于预训练模型的选择。例如,将 [BOS](句首)或 [EOS](句尾)标记添加到 BERT 输入。
下面的代码使用BPE模型、小写Normalizers和空白Pre-Tokenizers。然后用默认值初始化训练器对象,主要包括
1、词汇量大小使用50265以与BART的英语标记器一致
2、特殊标记,如和,
3、初始词汇量,这是每个模型启动过程的预定义列表。
fromtokenizersimportnormalizers, pre_tokenizers, Tokenizer, models, trainers# Build a tokenizerbpe_tokenizer=Tokenizer(models.BPE())bpe_tokenizer.normalizer=normalizers.Lowercase()bpe_tokenizer.pre_tokenizer=pre_tokenizers.Whitespace()trainer=trainers.BpeTrainer(vocab_size=50265,special_tokens=["<s>", "<pad>", "</s>", "<unk>", "<mask>"],initial_alphabet=pre_tokenizers.ByteLevel.alphabet(),)
使用Huggingface的最后一步是连接Trainer和BPE模型,并传递数据集。根据数据的来源,可以使用不同的训练函数。我们将使用train_from_iterator()。
defbatch_iterator():batch_length=1000foriinrange(0, len(train), batch_length):yieldtrain[i : i+batch_length]["ro"]bpe_tokenizer.train_from_iterator( batch_iterator(), length=len(train), trainer=trainer )bpe_tokenizer.save("./ro_tokenizer.json")BART微调
现在可以使用使用新的标记器了。
fromtransformersimportAutoTokenizer, PreTrainedTokenizerFasten_tokenizer=AutoTokenizer.from_pretrained( "facebook/bart-base" );ro_tokenizer=PreTrainedTokenizerFast.from_pretrained( "./ro_tokenizer.json" );ro_tokenizer.pad_token=en_tokenizer.pad_tokendeftokenize_dataset(sample):input=en_tokenizer(sample['en'], padding='max_length', max_length=120, truncation=True)label=ro_tokenizer(sample['ro'], padding='max_length', max_length=120, truncation=True)input["decoder_input_ids"] =label["input_ids"]input["decoder_attention_mask"] =label["attention_mask"]input["labels"] =label["input_ids"]returninputtrain_tokenized=train.map(tokenize_dataset, batched=True)test_tokenized=test.map(tokenize_dataset, batched=True)validation_tokenized=validation.map(tokenize_dataset, batched=True)
上面代码的第5行,为罗马尼亚语的标记器设置填充标记是非常必要的。因为它将在第9行使用,标记器使用填充可以使所有输入都具有相同的大小。
下面就是训练的过程:
fromtransformersimportBartForConditionalGenerationfromtransformersimportSeq2SeqTrainingArguments, Seq2SeqTrainermodel=BartForConditionalGeneration.from_pretrained( "facebook/bart-base" )training_args=Seq2SeqTrainingArguments(output_dir="./",evaluation_strategy="steps",per_device_train_batch_size=2,per_device_eval_batch_size=2,predict_with_generate=True,logging_steps=2, # set to 1000 for full trainingsave_steps=64, # set to 500 for full trainingeval_steps=64, # set to 8000 for full trainingwarmup_steps=1, # set to 2000 for full trainingmax_steps=128, # delete for full trainingoverwrite_output_dir=True,save_total_limit=3,fp16=False, # True if GPU)trainer=Seq2SeqTrainer(model=model,args=training_args,train_dataset=train_tokenized,eval_dataset=validation_tokenized,)trainer.train()
过程也非常简单,加载bart基础模型(第4行),设置训练参数(第6行),使用Trainer对象绑定所有内容(第22行),并启动流程(第29行)。上述超参数都是测试目的,所以如果要得到最好的结果还需要进行超参数的设置,我们使用这些参数是可以运行的。
推理
推理过程也很简单,加载经过微调的模型并使用generate()方法进行转换就可以了,但是需要注意的是对源 (En) 和目标 (RO) 序列使用适当的分词器。
总结
虽然在使用自然语言处理(NLP)时,标记化似乎是一个基本操作,但它是一个不应忽视的关键步骤。HuggingFace的出现可以方便的让我们使用,这使得我们很容易忘记标记化的基本原理,而仅仅依赖预先训练好的模型。但是当我们希望自己训练新模型时,了解标记化过程及其对下游任务的影响是必不可少的,所以熟悉和掌握这个基本的操作是非常有必要的。
本文代码:https://avoid.overfit.cn/post/6a533780b5d842a28245c81bf46fac63
作者:Ala Alam Falaki
相关文章:
Huggingface微调BART的代码示例:WMT16数据集训练新的标记进行翻译
BART模型是用来预训练seq-to-seq模型的降噪自动编码器(autoencoder)。它是一个序列到序列的模型,具有对损坏文本的双向编码器和一个从左到右的自回归解码器,所以它可以完美的执行翻译任务。 如果你想在翻译任务上测试一个新的体系…...
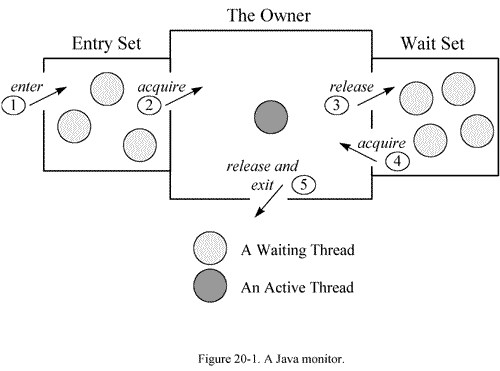
synchronized 的 monitor 机制
synchronized 的 monitor 机制 前言 本文基于 jdk 8 编写。author JellyfishMIX - github / blog.jellyfishmix.comLICENSE GPL-2.0 monitor monitor 是 synchronized 中用以实现线程之间的互斥与协作的主要手段,它可以看成是对象或者 class 持有的锁。每一个对象…...
NumPy 初学者指南中文第三版:1~5
原文:NumPy: Beginner’s Guide - Third Edition 协议:CC BY-NC-SA 4.0 译者:飞龙 一、NumPy 快速入门 让我们开始吧。 我们将在不同的操作系统上安装 NumPy 和相关软件,并看一些使用 NumPy 的简单代码。 本章简要介绍了 IPython…...
ChatGLM-6B论文代码笔记
ChatGLM-6B 文章目录 ChatGLM-6B前言一、原理1.1 优势1.2 实验1.3 特点:1.4 相关知识点 二、实验2.1 环境基础2.2 构建环境2.3 安装依赖2.4 运行2.5 数据2.6 构建前端页面 3 总结 前言 Github:https://github.com/THUDM/ChatGLM-6B 参考链接:…...
机器学习入门实例-加州房价预测-1(数据准备与可视化)
问题描述 数据来源:California Housing Prices dataset from the StatLib repository,1990年加州的统计数据。 要求:预测任意一个街区的房价中位数 缩小问题:superwised multiple regressiong(用到人口、收入等特征) univariat…...

【ROS2指南-20】了解ROS2组件的用法
在单个进程中组合多个节点 目录 背景 运行演示 发现可用组件 使用 ROS 服务 (1.) 与发布者和订阅者的运行时组合 使用 ROS 服务 (1.) 与服务器和客户端的运行时组合 使用 ROS 服务的编译时组合 (2.) 使用 dlopen 的运行时组合 使用启动动作组合 高级主题 卸载组件 重新…...
使用AI进行“文本纠错”
AI在现实中的应用有很多,你有没有想过,它还可以进行文本纠错呢?传统的校对既耗时又枯燥,通过“AI纠错”,不仅能更快完成,还能提高准确度。那么AI“文本纠错”背后的原理是什么呢?和我一起看看吧…...

第九章 法律责任与法律制裁
第九章 法律责任与法律制裁_副本 目录 第一节 法律责任的概念 一 法律责任的含义二 法律责任的特点 第二节 法律责任的分类与竞合 一 法律责任的分类 (一)根据责任行为所违反的法律的性质 民事责任:刑事责任行政责任违宪责任 (二…...

如何选择好用的海康视频恢复软件?综合考虑这几点
海康视频恢复通常是指从海康威视监控设备中恢复删除或丢失的视频。在使用海康设备进行监控时,一些重要的视频可能会被误删除或其他原因导致丢失,如果没有及时备份,数据就可能会“永久”丢失?其实不然,我们可以选择好用…...

前端学习:HTML颜色(什么是RGB、HEX、HSL)
一、什么是RGB、HEX、HSL? 无论是RGB、HEX、HSL,它们的作用只有一个:用数字表达出一种颜色。 1.RGB RGB通过输入的数值,将红色、绿色和蓝色的光源以一定的量混合在一起,形成颜色。 软件中通常让你输入Red、Green、B…...
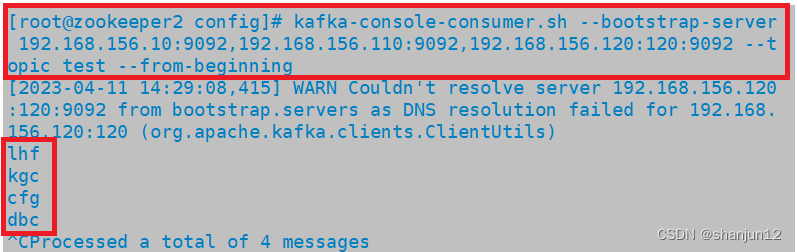
zookeeper + kafka集群搭建详解
目录 1.消息队列介绍 1.为什么需要消息队列 (MO) 2.使用消息队列的好处 3.消息队列的两种模式 2.Kafka相关介绍 1.Kafka定义 2.Kafka简介 3. Kafka的特性 3.Kafka系统架构 1. Broker(服务器) 2. Topic(一个队…...

【数据结构与算法】 - 双向链表 - 详细实现思路及代码
目录 一、概述 二、双向链表 三、双向链表实现步骤 📌3.1 C语言定义双向链表结点 📌3.2 双向链表初始化 📌3.3 双向链表插入数据 📌3.4 双向链表删除数据 📌3.5 双向链表查找数据 📌3.6 双向链…...

面试官在线点评4份留学生简历! 这些坑你中了几个?如何写项目描述才能被大厂发面试?转专业简历该咋写 | 还有优秀简历展示!
我们给大家展示一下 从材料的准备 也就是说到底包含哪些具体的项目 为什么说这些项目是不错的 第二呢就是说在陈述上 在整个这个简历的结构 他的完备性他的准确性 他的正确性 以及最后他的具体的这种项目的描述 那讲完了这个好的简历呢 我们另外搜集了几份简历 那这些简历呢其实…...
一觉醒后ChatGPT 被淘汰了
OpenAI 的 Andrej Karpathy 都大力宣传,认为 AutoGPT 是 prompt 工程的下一个前沿。 近日,AI 界貌似出现了一种新的趋势:自主人工智能。 这不是空穴来风,最近一个名为 AutoGPT 的研究开始走进大众视野。特斯拉前 AI 总监、刚刚回归…...

spring框架的事务
1.什么是事务? 事务:是数据库操作的最小工作单元,是作为单个逻辑工作单元执行的一系列操作;这些操作作为一个整体一起向系统提交,要么都执行、要么都不执行;事务是一组不可再分割的操作集合(工作逻辑单元…...

Spring配置数据源
Spring配置数据源数据源的作用环境准备手动创建c3p0数据源封装抽取关键信息,手动创建c3p0数据源使用Spring容器配置数据源数据源的作用 数据源(连接池)是提高程序性能如出现的 事先实例化数据源,初始化部分连接资源 使用连接资源时从数据源中获取 使用完…...

【前端之旅】Vue入门笔记
一名软件工程专业学生的前端之旅,记录自己对三件套(HTML、CSS、JavaScript)、Jquery、Ajax、Axios、Bootstrap、Node.js、Vue、小程序开发(Uniapp)以及各种UI组件库、前端框架的学习。 【前端之旅】Web基础与开发工具 【前端之旅】手把手教你安装VS Code并附上超实用插件…...
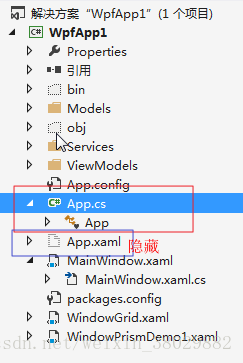
WPF教程(二)--Application WPF程序启动方式
1.Application介绍 WPF与WinForm一样有一个 Application对象来进行一些全局的行为和操作,并且每个 Domain (应用程序域)中仅且只有一个 Application 实例存在。和 WinForm 不同的是WPF Application默认由两部分组成 : App.xaml 和 App.xaml.…...

snmp 自定义子代理mib库
测试环境:centos8 1、安装软件 yum install -y net-snmp net-snmp-utils yum install -y net-snmp-perl net-snmp-devel net-snmp-libs 2、创建用户 net-snmp-create-v3-user 输入用户名 soft 输入密码 123456 输入密码 654321 service snmpd restart 3、创建…...

一文说透安全沙箱技术
在数字经济的东风中,数据安全至关重要。目前已经颁布了包括《数据安全法》、《个人信息保护法》和《数据安全管理办法》在内的国家政策,以促进整个数据要素的发展。 而近年来,随着移动应用程序的普及和小程序技术的崛起,安全沙箱…...

EPUBCheck测试框架深度解析:单元测试和集成测试最佳实践
EPUBCheck测试框架深度解析:单元测试和集成测试最佳实践 【免费下载链接】epubcheck The conformance checker for EPUB publications 项目地址: https://gitcode.com/gh_mirrors/ep/epubcheck EPUBCheck作为EPUB出版物的官方一致性检查工具,其强…...

PL2303老芯片终极解决方案:3步让Windows 10/11识别你的停产串口设备
PL2303老芯片终极解决方案:3步让Windows 10/11识别你的停产串口设备 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 你是否在Windows 10或Windows 11系统上…...

工业自动化实战:Modbus转Profinet网关配置与机器人PLC通信集成
1. 项目概述与核心需求解析最近在做一个产线自动化升级的项目,客户现场有一套六轴关节机器人,控制器是国产的ES-R6系列,需要和产线主控的西门子S7-1200 PLC进行实时数据交互。机器人负责上下料和精密装配,PLC则统筹整条线的启停、…...

从‘看到’到‘看懂’:VSRN模型如何像人一样进行视觉语义推理?一个生动的案例拆解
从‘看到’到‘看懂’:VSRN模型如何像人一样进行视觉语义推理?一个生动的案例拆解 想象这样一个场景:你看到一张照片,画面中一只棕色的狗在绿色的草地上追逐飞盘。几乎瞬间,你的大脑就完成了从视觉感知到语义理解的完整…...

3大核心技术深度解析:cursor-free-vip如何高效破解Cursor AI编辑器限制
3大核心技术深度解析:cursor-free-vip如何高效破解Cursor AI编辑器限制 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve …...

模糊PID vs 传统PID:用Simulink仿真对比直流电机控制,结果差距有多大?
模糊PID与传统PID的直流电机控制擂台赛:Simulink仿真深度解析 在工业自动化领域,直流电机控制一直是工程师们关注的焦点。面对复杂的工况变化,传统PID控制器虽然结构简单、易于实现,但在非线性、时变系统中往往表现不佳。而模糊PI…...

如何永久保存微信聊天记录:WeChatMsg开源工具的完整解决方案
如何永久保存微信聊天记录:WeChatMsg开源工具的完整解决方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we…...

3分钟快速上手:FanControl风扇控制软件的终极静音散热方案
3分钟快速上手:FanControl风扇控制软件的终极静音散热方案 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendin…...

RISC-V开发板深度测评指南:从硬件解析到生态实战
1. 项目概述:一次深度参与RISC-V生态的实战机会最近,电子发烧友社区联合多家厂商发起的第二届RISC-V开发板测评大赛,吸引了圈内不少工程师和爱好者的目光。其中,昊芯(Haawking)作为一家专注于RISC-V处理器I…...

突发外交事件3分钟响应!Perplexity国际新闻搜索应急配置清单,含12条预设Prompt与可信度评分模型
更多请点击: https://kaifayun.com 第一章:突发外交事件3分钟响应!Perplexity国际新闻搜索应急配置清单,含12条预设Prompt与可信度评分模型 面对突发外交事件(如边境冲突升级、高层会谈临时取消、制裁公告突袭发布&am…...