【一道面试题】关于HashMap的一系列问题
HashMap底层数据结构在1.7与1.8的变化
1.7是基于数组+链表实现的,1.8是基于数组+链表+红黑树实现的,链表长度达到8时会树化
使用哈希表的好处
使用hash表是为了提升查找效率,比如我现在要在数组中查找一个A对象,在这种情况下是无法根据数组下标查找的,这样我们就需要从数组头部开始,将A对象与数组元素依次比较,直到找到A对象,这样显然是比较麻烦的,如果使用了hash表,我们只需要计算出A元素的hash值,通过hash值找到其在数组中的索引,就可以很快的找到A元素了,当然一个索引对应的很可能不止一个元素,所以需要使用数组+链表的形式,但如果链表的长度过长,查找时还是需要沿着链表一一比对,这样也是比较消耗性能的,为了避免链表长度过长造成的查找效率下降,有两种解决方案:1是数组扩容,2是链表树化
HashMap底层数组的扩容
底层数组默认长度是16,当数组使用超过最大长度的0.75(这个0.75被称为负载因子),则会对该数组进行扩容,扩容为原来长度的两倍,扩容结束之后,由于数组的长度发生了变化(元素位置的确定是由元素哈希值对数组长度取模),因此会重新计算集合元素在数组中的存储位置,因此扩容前存在的链表结构很可能会消失,这样也就在一定程度上解决了链表长度过长的问题
负载因子为什么选择0.75
- 在空间占用与查询时间之间取得较好的权衡
- 大于这个值,空间节省了,但链表就会比较长影响性能
- 小于这个值,冲突减少了,但扩容就会更频繁,空间占用也更多
链表树化
链表的树化有两个必要条件,一是数组长度大于等于64,二是链表长度必须超过8,如果链表长度超过了8但是数组长度小于64,那么会直接对数组进行扩容(此时不考虑阈值的问题)而非将链表树化,也就是说在数组长度小于64时,链表长度是可能大于8的;当上述两个条件都满足时,链表会树化为红黑树,红黑树的一个特点是父节点左侧的都是比它小的元素,父节点右侧的都是比它大的元素,因此在元素较多的情况下,红黑树的查找效率就比链表要高很多了,这也就是jdk1.8使用数组+链表+红黑树的意义
链表的树化,我们还需要思考几个问题
-
为什么不一上来就树化?
在链表短时没有必要进行树化,在链表比较短的情况下,无论是查询还是更新,其性能都要高于红黑树,而且红黑树的内存占用比链表高,红黑树是由TreeNode组成的,而链表是由Node组成的,TreeNode的成员变量要比Node多很多,因此没有必要一上来就树化
-
树化阈值为什么选择8?
首先需要说明的是,虽然HashMap底层数据结构使用的是数组+链表+红黑树,但是正常情况下是几乎不可能出现红黑树的,如果hash 值足够随机,则在 hash 表内按泊松分布,在负载因子 0.75 的情况下,长度超过 8 的链表出现概率是 0.00000006(一亿分之六),之所以树化阈值选择 8 就是为了让树化几率足够小
正常情况下链表几乎不可能树化,红黑树存在的意义主要是用来避免 DoS 攻击的,是用来应对偶然情况的一种保底策略
红黑树退化成链表
链表会树化成红黑树,红黑树也会退化成链表,红黑树退化的场景:
- 数组扩容时会对红黑树进行拆分,若拆分后树的元素小于等于6则退化为链表
- remove任意一个树节点之前,若root(根节点)、root.left(根节点的左孩子)、root.right(根节点的右孩子)、root.left.left(根节点的左孙子) 有一个为 null ,那么remove完成后,树也会退化为链表
索引的计算过程
对象先调用其自身的hashCode方法计算出hash值,再由HashMap的hash方法对这个hash值进行二次hash,二次hash的结果再使用位与运算(hash值 & (数组长度 – 1)),得到这个对象在hash表中的索引
这个过程中也有几个问题需要思考
-
数组容量为何要设计为2的n次幂?
- 如果数组容量是2的n次幂,则位与运算与取模运算的结果是相同的,可以用位与运算代替取模运算,且效率更高;
- 在数组扩容时,如果数组容量是2的n次幂,那么扩容时重新计算索引效率更高,只需要将链表中每个元素与oldCap(扩容前的容量)做位与运算,如果结果为0,那么说该元素在扩容后会保留在原位置,如果结果不为零,那么该元素在扩容后位置会发生变化,这样遍历下来,就可以把原来的链表拆分成两个链表,一是位置不需要移动的,二是位置需要移动的,在扩容后,位置需要移动的链表的新位置的索引=旧位置+oldCap
- 容量设计为2的n次幂虽然可以提高计算索引时的效率,但是会导致hash的分布性变差,比如说我现在要存放一组较小的偶数,那么这些偶数就会集中在数组的偶数索引位置上(在没有经过二次hash的情况下),因此为了避免这种情况,需要进行二次hash;如果我们选择质数作为数组容量,那么hash的分布性是很好的,我们完全不需要进行二次hash,即使这样,HashMap仍然选择2的n次幂作为数组容量,是出于更看重效率的角度出发的
-
为什么要进行二次hash?
之所以要进行二次hash,是为了让hash分布的更为均匀,避免一组数据的hash值集中在某些索引上导致链表过长
Put元素流程
HashMap 是懒惰创建数组的,首次插入元素时才会去创建数组,假如说现在要插入一个元素A,流程如下:
-
计算出元素A的索引值
-
如果该索引上没有元素,则创建元素A的Node节点占位并返回
-
如果该索引上已经有元素了,则
- 如果该索引位置上的元素是TreeNode,则走红黑树的添加或更新逻辑
- 如果该索引位置上的元素是Node,则走链表的添加或更新逻辑,添加完毕后如果链表长度超过树化阈值,走树化逻辑
是添加还是更新,需要比对元素A与其他元素的hash值,hash值不同走添加逻辑,hash值相同则调用元素的equals方法进行比对,返回false走添加逻辑,返回true走更新逻辑
-
返回前检查容量是否超过阈值,一旦超过则对数组进行扩容
上述过程中,1.7 的实现与 1.8 的实现有所不同:
- 1.7 使用头插法,新增的元素会插入到链表头部;1.8 使用尾插法,新增的元素会插入到链表尾部
- 1.7 是数组使用长度超过阈值,且再次put时,put的索引位置上已经有元素了才会去对数组扩容; 1.8 是使用长度超过阈值就会扩容
- 1.8 在扩容计算 Node 索引时,会进行优化(这个优化上面提到过,1.7是没有这个优化的)
多线程下HashMap存在的问题
- 数据丢失:假如现在HashMap索引为1的位置上是空的,现在有t1和t2两个线程同时希望在该位置上插入元素,假设此时t1希望插入元素A,那么首先t1线程需要检查该位置上是否已经存在元素,经过检查后发现不存在元素,正当t1线程准备插入元素时,发生了线程切换,CPU执行权给到了t2线程,t2线程将要插入元素B,那么它首先还是会去检查该位置是否存在元素,结果当然是也不存在,于是t2线程便在该位置上插入了元素B然后返回,如果此时执行权再次给到t1线程,那么t1线程插入元素A就会把原来位置上的元素B给覆盖,这样就丢失了一次数据更新
- 并发扩容死链(存在于jdk1.7中):在1.7中,由于使用头插法,当两个线程同时对数组进行扩容时很有可能会产生死链(环形链表),此时一旦有任意查找元素的动作,线程将会进入死循环,导致CPU飙升;1.8使用尾插法避免了这一问题
HashMap的key是否为null,作为key的对象应该有哪些要求
- HashMap 的 key 可以为 null,Map 的其他实现则不然
- 作为 key 的对象,必须实现 hashCode 和 equals 方法,并且要保证 key 的内容不能修改(不可变),一旦key被修改了,那么其hash值就会发生变化,那么就无法找到其在hash表中的索引了
- key 的 hashCode 应该有良好的散列性
HashMap和HashTable的区别
- HashMap线程不安全,HashTable线程安全(大多使用Synchronize修饰),所以相对来说HashMap要更快一些,这是最主要也是最重要的区别
- HashMap的key和value都允许为null,而HashTable键值对都不能为空,否则会报空指针异常
- HashMap在计算Hash值时需要二次Hash,而HashTable不需要,原因在于HashTable不使用2的n次幂来作为数组长度,Hash分布更加均匀
- 接上一点,既然说了HashTable不使用2的n次幂来作为数组长度,那就需要提一下HashTable的扩容规则了,HashTable的数组扩容是扩容为原来的两倍加一,而HashMap是扩容为原来的两倍
- Java8中HashMap使用数组+链表+红黑树的形式,而Java8中HashTable仍然是数组+链表
相关文章:

【一道面试题】关于HashMap的一系列问题
HashMap底层数据结构在1.7与1.8的变化 1.7是基于数组链表实现的,1.8是基于数组链表红黑树实现的,链表长度达到8时会树化 使用哈希表的好处 使用hash表是为了提升查找效率,比如我现在要在数组中查找一个A对象,在这种情况下是无法…...

论文笔记: Monocular Depth Estimation: a Review of the 2022 State of the Art
中文标题:单目深度估计:回顾2022年最先进技术 本文对比了物种最近的基于深度学习的单目深度估计方法: GPLDepth(2022)[15]: Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepthAdabins(2021)[1]: Adabins:…...
Springmvc补充配置
Controller配置总结 控制器通常通过接口定义或注解定义两种方法实现 在用接口定义写控制器时,需要去Spring配置文件中注册请求的bean;name对应请求路径,class对应处理请求的类。 <bean id"/hello" class"com.demo.Controller.HelloCo…...

MySQL 的 datetime等日期和时间处理SQL函数及格式化显示
MySQL 的 datetime等日期和时间处理SQL函数及格式化显示MySQL 时间相关的SQL函数:MySQL的SQL DATE_FORMAT函数:用于以不同的格式显示日期/时间数据。DATE_FORMAT(date, format) 根据格式串 format 格式化日期或日期和时间值 date,返回结果串。…...

基于微信云开发的防诈反诈宣传教育答题小程序
基于微信云开发的防诈反诈宣传教育答题小程序一、前言介绍作为当代大学生,诈骗事件的发生屡见不鲜,但却未能引起大家的重视。高校以线上宣传、阵地展示为主,线下学习、实地送法为辅,从而构筑立体化反诈骗防线。在线答题考试是一种…...
Map和Set
Map和set是一种专门用来进行搜索的容器或者数据结构,其搜索的效率与其具体的实例化子类有关。数据的一般查找方式有两种:直接遍历和二分查找。但这两种查找方式都有很大的局限性,也不便于对数据进行增删查改等操作。对于这一类数据的查找&…...
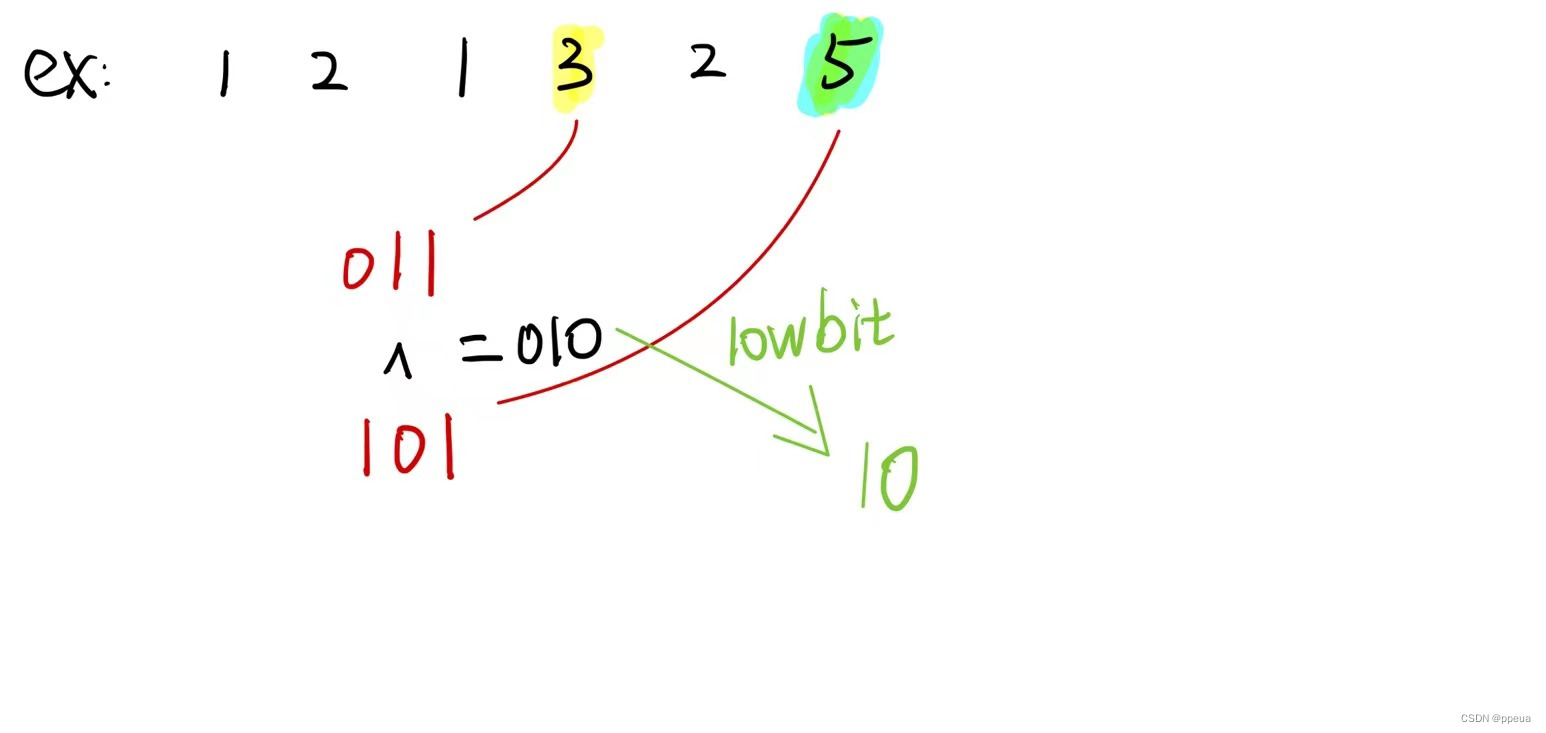
【位运算问题】Leetcode 136、137、260问题详解及代码实现
Halo,这里是Ppeua。平时主要更新C语言,C,数据结构算法......感兴趣就关注我吧!你定不会失望。 🌈个人主页:主页链接 🌈算法专栏:专栏链接 我会一直往里填充内容哒! &…...

同花顺2023届春招内推
同花顺2023届春招开始啦! 同花顺是国内首家上市的互联网金融信息服务平台,如果你对互联网金融感兴趣,如果你有志向在人工智能方向发挥所长,如果你也是一个激情澎湃的小伙伴,欢迎加入我们!岗位类别…...
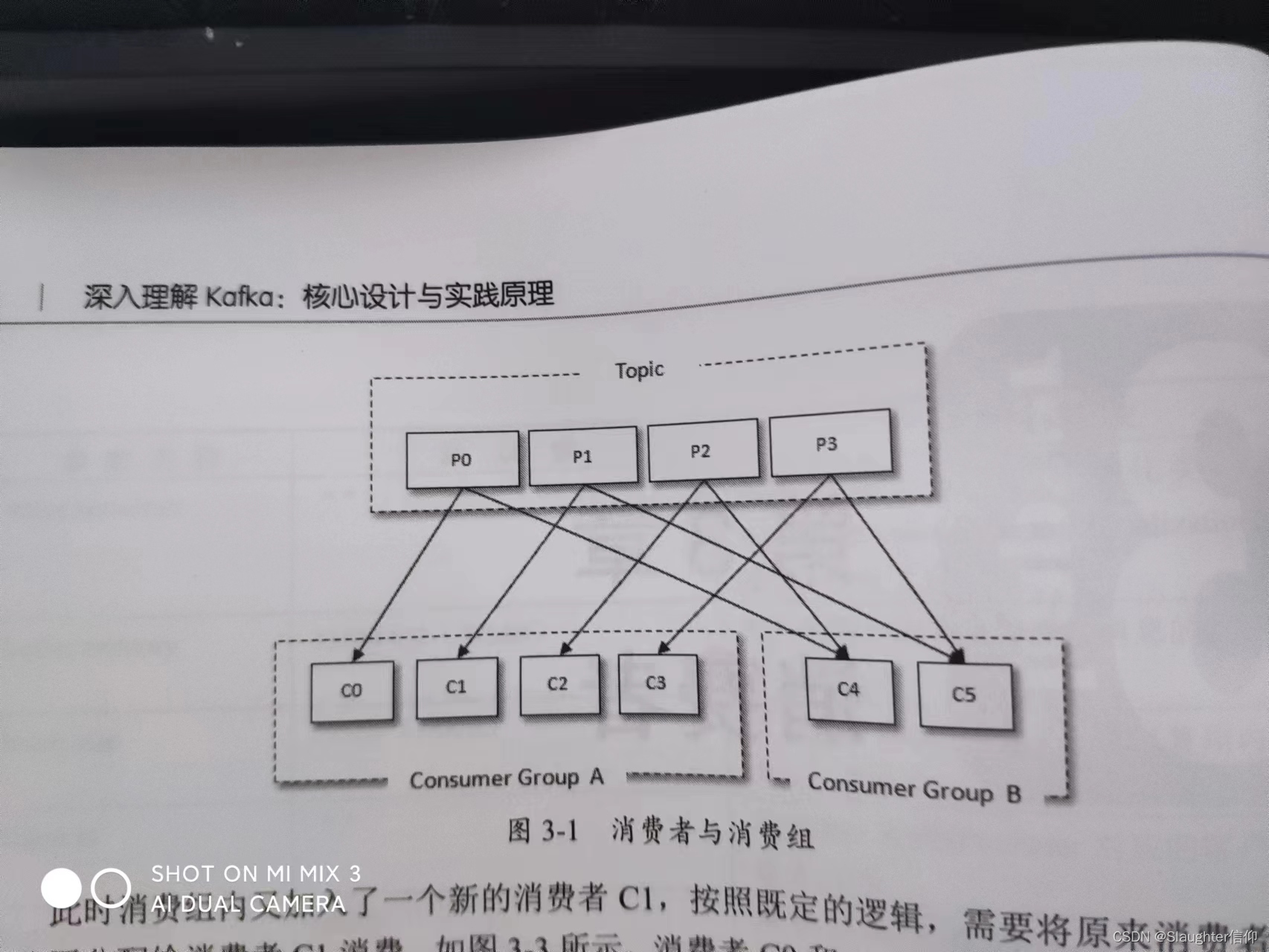
深入Kafka核心设计与实践原理读书笔记第三章消费者
消费者 消费者与消费组 消费者Consumer负责定于kafka中的主题Topic,并且从订阅的主题上拉取消息。与其他消息中间件不同的在于它有一个消费组。每个消费者对应一个消费组,当消息发布到主题后,只会被投递给订阅它的消费组的一个消费者。 如…...

IDEA 中使用 Git 图文教程详解
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...

【Linux系统】进程概念
目录 1 冯诺依曼体系结构 2 操作系统(Operator System) 概念 设计OS的目的 定位 总结 系统调用和库函数概念 3 进程 3.1 基本概念 3.2 描述进程-PCB 3.2 组织进程 3.3 查看进程 3.4 通过系统调用获取进程标示符 3.5 进程状态 在了解进程概念前我们还得了解下冯诺…...
)
上课睡觉(2023寒假每日一题 4)
有 NNN 堆石子,每堆的石子数量分别为 a1,a2,…,aNa_1,a_2,…,a_Na1,a2,…,aN。 你可以对石子堆进行合并操作,将两个相邻的石子堆合并为一个石子堆,例如,如果 a[1,2,3,4,5]a[1,2,3,4,5]a[1,2,3,4,5],合并第 2,32…...

【Selenium学习】Selenium 中常用的基本方法
1.send_keys 方法模拟键盘键入此方法类似于模拟键盘键入。以在百度首页搜索框输入“Selenium”为例,代码如下:# _*_ coding:utf-8 _*_ """ name:zhangxingzai date:2023/2/13 form:《Selenium 3Python 3自动化测试项目实战》 …...
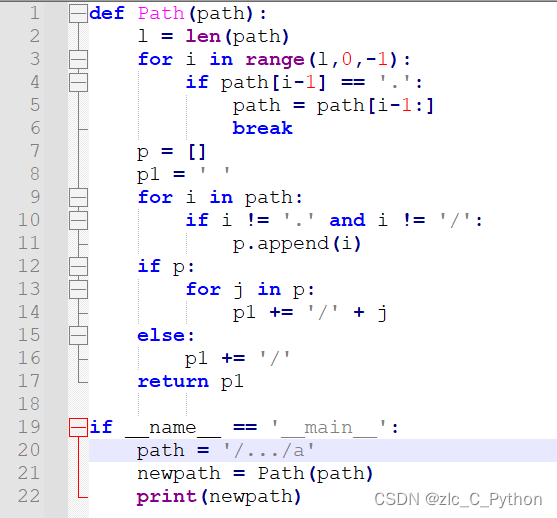
python练习——简化路径
项目场景: 给你一个字符串 path ,表示指向某一文件或目录的 Unix 风格 绝对路径 (以 /开头),请你将其转化为更加简洁的规范路径。在 Unix 风格的文件系统中,一个点(.)表示当前目录本…...
 | 刷完必过)
2023新华为OD机试题 - 火星文计算2(JavaScript) | 刷完必过
火星文计算 2 题目 已知火星人使用的运算符号为#;$ 其与地球人的等价公式如下 x#y=4*x+3*y+2 x$y=2*x+y+3 x y是无符号整数 地球人公式按照 c 语言规则进行计算 火星人公式中#符优先级高于$ 相同的运算符按从左到右的顺序运算 输入 火星人字符串表达式结尾不带回车换行 输入…...

前端插件重磅来袭
“你值得拥有”专栏系列上新啦,今日推出“手写前端插件”项目,作为一个前端中高级工程师,手写前端树形菜单插件、弹出层插件、日历插件、分页插件、选项卡插件、进度条插件等是必备的技能,让你的前端技术百尺竿头更进一步…...

深入工厂|高精密多层板是如何被智造出来的?
或许有很多人从网络上见过各种教程,告诉你单层板是什么,多层板是什么,他们该如何做出来,但是在具体制造时却全凭想象,今天,就让我们来实地看看,精密的多层板是如何被制造出来的!今天…...

代理模式动态代理
什么是代理模式? 代理模式是开发中常见的一种设计模式,使用代理模式可以很好的对程序进行横向扩展。代理,顾名思义就是一个真实对象会存在一个代理对象,并且代理对象可以替真实对象完成相应操作,外部通过代理对象来访…...

Mysql之二进制日志
目录 二进制日志 12-37 二进制日志格式 基于行的二进制日志 基于语句的二进制日志 混合格式二进制日志 复制日志 12-42 故障安全 (Crash-Safe) 复制 多源复制 二进制日志 12-37 二进制日志: • 包含数据和模式更改及其时间戳 – 基于语句 或 基于行 的日志…...
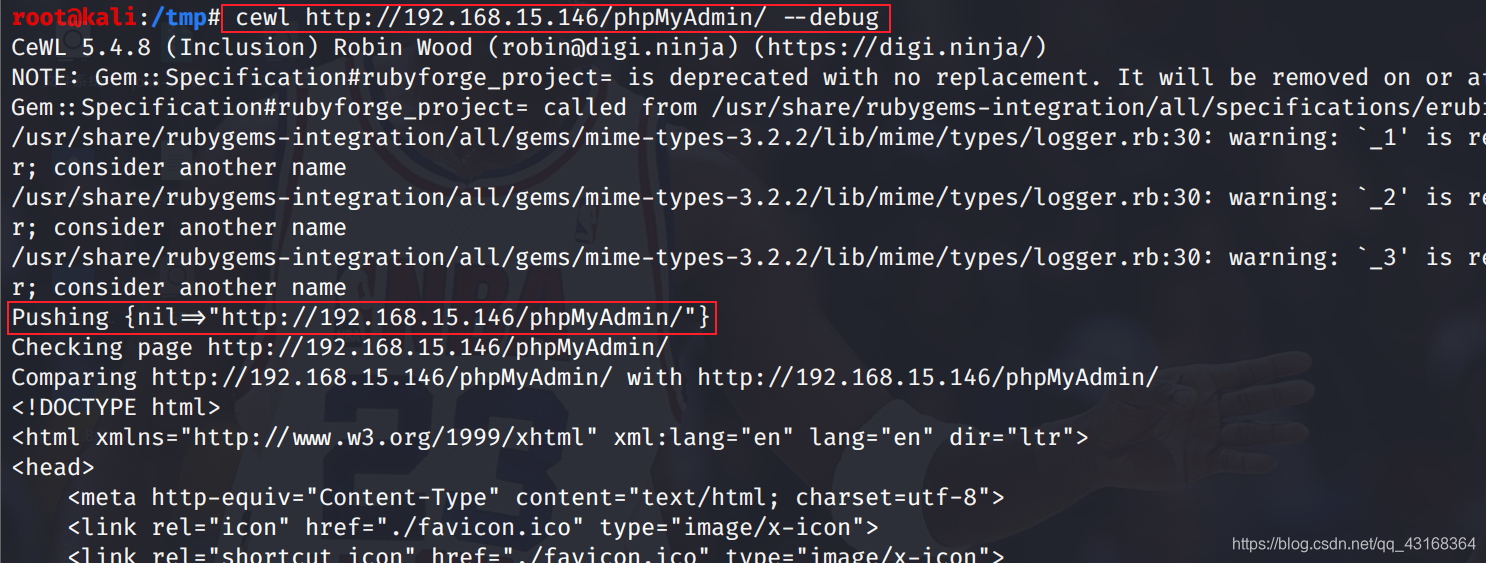
kail工具的使用--- cewl
1.介绍 Cewl是一款采用Ruby开发的应用程序,可以给他的爬虫指定URL地址和爬取深度,还可以添加外部链接,接下来Cewl会给你返回一个字典文件,你可以把字典用到类似John the Ripper这样的密码破解工具中。 2.使用 输入以下命令之后…...

前新造车一哥重拾辉煌,日本车最高兴,难怪国产车转向节油混动
新造车当中,零跑再度冲破5万辆,而理想则冲破4万辆,不过最让人惊讶的则是理想i6月销破2.4万辆,占理想销量比例接近六成,这不仅证明这家车企转型纯电技术的成功,更是对电车行业电混技术的巨大打击,…...

PPT转视频工具,就得保留全部动画效果 —— 使用YOCO有感
在做课件视频这件事上,我踩过不少坑。一开始我以为,PPT转视频无非就是“把页面录下来”,后来才发现,真正决定视频质量的,不是画面清不清,而是PPT里的“动画逻辑”有没有被完整保留。而这一点,恰…...

学不会游戏逆向,是你没有把握核心
学不会游戏逆向,是你没有把握核心...

STM32遥控灭火消防小车设计与实现
1. 项目概述这款基于STM32设计的遥控灭火消防小车是我在嵌入式系统开发领域的一次创新尝试。作为一名从事智能硬件开发多年的工程师,我深刻理解火灾救援中"黄金三分钟"的重要性。传统消防设备往往受限于响应速度和操作灵活性,而这款小车正是为…...
在生存分析中的实战应用)
利用rms包实现限制性立方样条回归(RCS)在生存分析中的实战应用
1. 为什么需要限制性立方样条回归? 在医学数据分析中,我们经常遇到变量与结局之间并非简单的直线关系。比如研究年龄与癌症风险时,可能发现中年人群风险最高,而年轻人和老年人风险相对较低——这种U型关系用传统线性回归会严重失真…...

数字孪生简介
数字孪生简介摘要数字孪生(Digital Twin)作为连接物理世界与数字世界的核心技术,正在重塑全球产业格局。本报告系统梳理了数字孪生技术的概念演进、技术架构、行业应用及发展趋势,深入分析了其在智能制造、航空航天、智慧城市、医…...

FinalBurn Neo终极指南:如何打造完美的复古游戏体验
FinalBurn Neo终极指南:如何打造完美的复古游戏体验 【免费下载链接】FBNeo FinalBurn Neo - We are Team FBNeo. 项目地址: https://gitcode.com/gh_mirrors/fb/FBNeo FinalBurn Neo(简称FBNeo)是一款开源街机游戏模拟器,…...

002、环境搭建:Python虚拟环境、LangChain安装与核心依赖解析
002、环境搭建:Python虚拟环境、LangChain安装与核心依赖解析从一次深夜调试说起 上周三凌晨两点,我被一个诡异的错误钉在屏幕前:明明本地测试通过的LangChain智能体,在同事的机器上死活跑不起来。报错信息指向一个版本冲突——py…...

AI安全高阶:生成式AI的安全风险与防御体系
AI安全高阶:生成式AI的安全风险与防御体系📝 本章学习目标:本章深入探讨高阶主题,适合有一定基础的读者深化理解。通过本章学习,你将全面掌握"AI安全高阶:生成式AI的安全风险与防御体系"这一核心…...

专业级批量二维码扫描工具V2.0|高精度图片二维码批量识别软件
温馨提示:文末有联系方式软件概述 一款专为高效处理多图场景设计的二维码批量识别解决方案——扩展批量二维码识别工具 V2.0 专业版。 无需逐张打开图片,即可全自动解析各类常见格式图像(JPG/PNG/BMP等)中嵌入的二维码信息&#x…...