POSTGRESQL LINUX 与 PG有关的内存参释义

开头还是介绍一下群,如果感兴趣polardb ,mongodb ,mysql ,postgresql ,redis 等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友会分到2群(共700多人左右 1 + 2)。
POSTGRESQL 与LINUX 系统是密切联系的,与其他的数据库相比对于操作系统的依赖可以加更加二字。那么关于POSTGRESQL 与LINUX 在内存方面的内存参数有什么关联性,今天这篇需要说一说。
多进程间通信常用的技术手段包括共享内存、消息队列、信号量等等基于POSTGRESQL 需要操作系统提供IPC 的功能,来进行信息的共享内存和信号量的共享,在PG 9.3之前的版本是使用system v 的信号量,所以以下的设置对于PG 来说是比较重要的,但在后续的版本中,使用system_v 的方式被转移到了 POSIX 信号量。
而在使用system_v 的时候是需要操作系统支持的,如果POSTGRESQL 超过使用这个在操作系统中的限制的情况下,POSTGRESQL 数据库会产生错误。
所以这里为了避免在POSTGRESQL 工作中产生报错等问题对于 LINUX 的操作系统的 system V IPC 的配置进行一些调整。
这里有一个通用性的设置,对于部分其他的数据库也有效
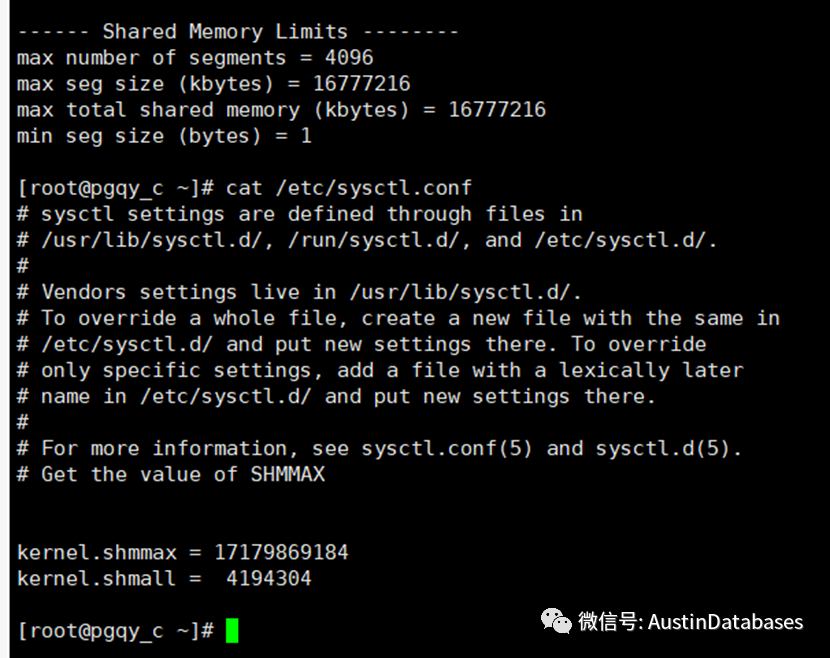
kernel.shmmax =物理内存的一半
kernel.shmmni = 4096 这个内核参数用于设置系统范围内共享内存段的最大数量
kernel.shmall = 其值应不小于shmmax/page_size缺省值就是2097152
通过 ipcs -lm
举例 32G 内存的主机可以将上面的配置参数设置为
kernel.shmmax =17179869184
kernel.shmall = 4194304
或者使用命令将参数打入到配置文件中
sudo sysctl -w kernel.shmmax=17179869184
sudo sysctl -w kernel.shmall=4194304
下面的脚本可以对于这两个值,进行自动的计算,根据两个值,将值填入到/etc/systcl.conf 中
#!/bin/bash | |
# simple shmsetup script | |
page_size=`getconf PAGE_SIZE` | |
phys_pages=`getconf _PHYS_PAGES` | |
shmall=`expr $phys_pages / 2` | |
shmmax=`expr $shmall \* $page_size` | |
echo kernel.shmmax = $shmmax | |
echo kernel.shmall = $shmall |
Simple shmsetup script for PostgreSQL · GitHub
在Linux 使用中 overcommit 的含义是允许操作系统分配超出自身物理内存的内存给应用进行使用,在超分内存的情况下,主要使用的概念就是虚拟内存,这里超分的内存包括了物理内存和 swap的内存,这意味着进程可以启动,分配比可用内存更多的内存,并且一切都正常工作。一旦分配了大量内存的进程开始在内存中分页,从而开始增加其实际内存占用,它将强制使用超过可用内存的内存交换量,如果它已经耗尽了交换,那么就没有更多的内存了,那就不得不求助于内存耗尽杀手(OOM杀手)来释放内存。与之有关的两个参数是
Overcommit_memory
Overcommit_ratio
Overcommit_memory
0 – overcommit 0 是默认值默认情况下,内核通过估计可用内存量和过大的失败请求来执行启发式内存过度使用处理。但是,由于内存是使用启发式而不是精确算法分配的,因此使用此设置可能会导致内存过载。
cat /proc/sys/vm/overcommit_memory
通过如上的命令来对当前的overcommit进行值的确认
1 – always overcommit
如果值为1 的情况下,不会考虑内存的实际情况,而是一直进行分配,这样很可能会超分,导致问题。当该参数设置为1时,内核不执行内存过度使用处理。这增加了内存过载的可能性,但提高了内存密集型任务的性能
2 – never overcommit 当该参数设置为2时,内核将拒绝大于或等于总可用交换空间和overcommit_ratio中指定的物理RAM百分比之和的内存请求。这可以降低内存过度使用的风险,但仅建议交换区域大于物理内存的系统使用。
如果设置为2 ,内存进行超分也是可以的,实际就要看第二个参数了 Overcommit_memory , overcommit_memory 才是是否可以进行超分的关键和限制
我们通过下面的命令可以进行相关overcommit部分的实际分配的监控
free -m | awk '$1 ~/[Mm]em/ {print $2}' ; sysctl -a 2>/dev/null | grep vm.over; grep -i commitlimit /proc/meminfo

Vm.swappiness
Vm.swappiness的意义在于内存和磁盘虚拟文件之间的配比,每种数据库的设置建议值是不一样的,MYSQL 的建议值是 1, ORACLE的建议值在10 ,这里如果你的POSTGRESQL 是基于OLTP 的业务的情况下,不建议此值超过10,建议在5左右。
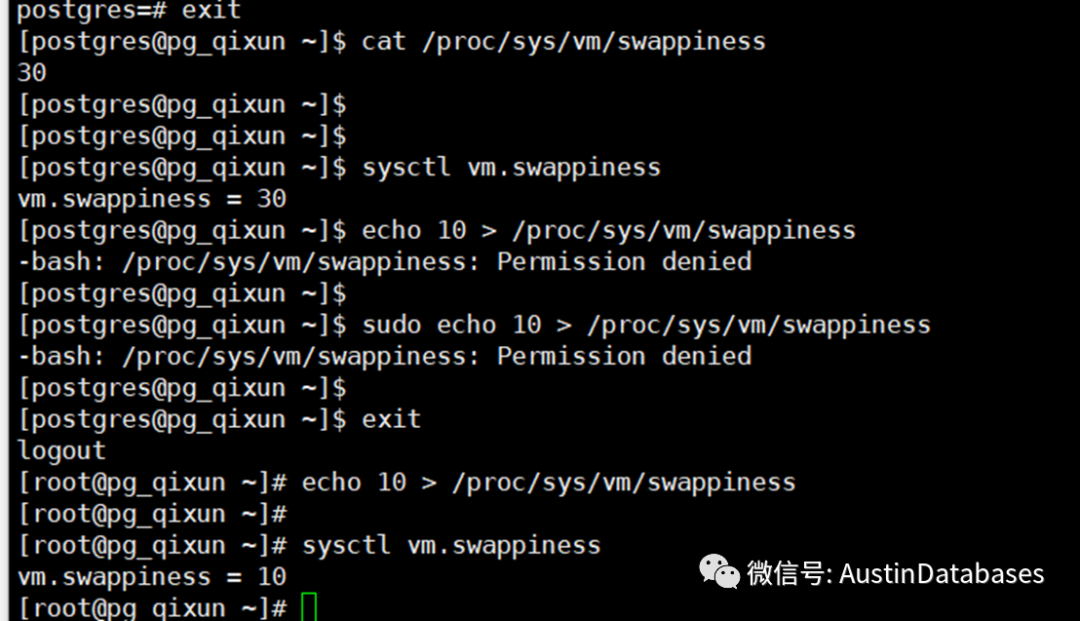
这里系统默认的值在 30 ,我们可以将这个值进行修改
echo 10 > /proc/sys/vm/swappiness
sysctl vm.swappiness
vm.dirty_background_ratio的主要功能是总体内存的百分比的脏数据可以保留在内存中。
举例如果 vm.dirty_background_ratio = 10 总体内存8G 则800MB 可以驻留脏数据,后面脏数据在写入到磁盘
sysctl -a | grep dirty
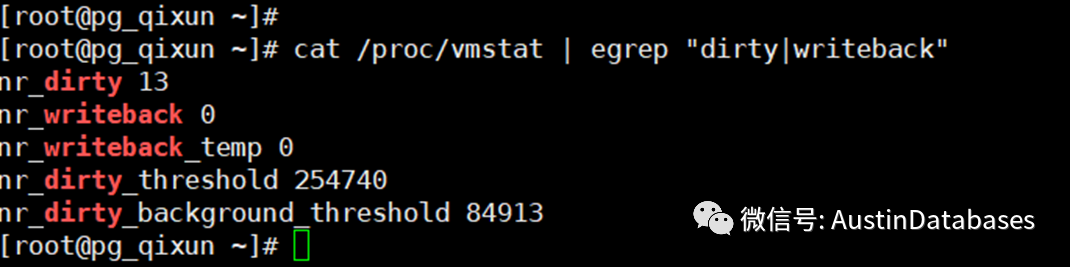
vm.dirty_ratio是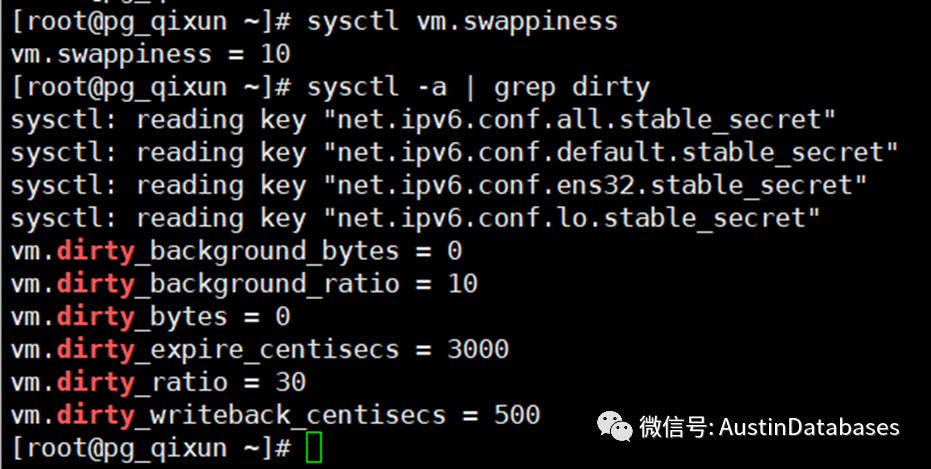 一种强制当脏数据超过设置的百分比,必须将内存的数据刷新到磁盘上,在刷新的过程中其他的IO操作会被暂时停止,直到这些脏数据写入到磁盘上,如果达到这个比率可能会导致IO的卡顿。
一种强制当脏数据超过设置的百分比,必须将内存的数据刷新到磁盘上,在刷新的过程中其他的IO操作会被暂时停止,直到这些脏数据写入到磁盘上,如果达到这个比率可能会导致IO的卡顿。

__________________________________________________________________
已经连着4期说爱好,目前没有人反馈说去掉这个,所以本期继续说说,汽车知识,今天普及一下汽车油耗高的问题,油耗高的问题和数据库性能的问题其实看似不搭噶,实际上两种问题是相似的地方,这个地方就是,混合型,复杂性的问题导致这样的情况发生。
那么汽车油耗高,原因有那些
1 车型原因,车重,你不能要求沃尔沃 S90的油耗 和 奔驰 SMART 的油耗一样的少,因为车辆的车重不一样,那么油耗必然是不一样得,所以问油耗高,先看看车重
2 迎风面的问题,这个问题可以这样看,同样重量的轿车和SUV ,为什么SUV 的油耗高,这很简单哈,因为汽车在开动的时候,是要和风阻来做抵抗的,所以你的车的迎风面越大,那么就越费油,开的越快,迎风面面积越大,那么你的车越费油
3 轮胎的问题,轮胎的胎压越低,低于铭牌的标准,同时你的车胎越宽,那么必然会越费油 ,同时还有一个问题就是轮胎的软硬度导致你油耗的高低。越硬的轮胎越省油,同时防爆胎是费油的这点毫无疑问。(不明白为什么,自己百度一下什么是防爆胎)
4 脚法的问题,实际上很多车型一样的车,你开 6个油,别人开 10个油,这是很有可能的,这就和驾驶习惯有关,如你喜欢大脚起步,还是和裹着小脚老太太的速度起步,还有刹车的频率,频率越高,油耗越高,所以如果你是小脚老太太的脚法,+ 不怎么使用刹车,那么你很有可能是马路上的一个风景 ---- 马路移动路障
5 车速的控制,每个车都有自己省油的速度,但如果你问什么速度普遍省油,那么一般来说 日系车 在60公里-80公里是省油的可能性大,而欧系的一般在70-90公里是省油的(这是有原因的避免 车系的互喷,就不解释了)
6 开窗,夏天在开车如果车速超过60 开窗户,将会没30分钟,增加你一个油耗。
当然这里说原因还没有总结完,不过你能看完上面的这堆,并理解和执行,那么你的车的油耗会较低。

相关文章:
POSTGRESQL LINUX 与 PG有关的内存参释义
开头还是介绍一下群,如果感兴趣polardb ,mongodb ,mysql ,postgresql ,redis 等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友会分到2群(共…...

Docker的常见命令
前言:使用Docker得学会的几个常见命令 常见命令前置学习: docker --help这个命令必须得会因为,很多命令是记不住的,得使用他们的官方help下面是一些实例 docker load --help常见命令集合: 一: docker images #查看全部镜像 docker rmi #删除某个镜像(例如:docker rmi redis…...
详细介绍性能测试的方法(含文档)
性能测试是软件测试中的一个重要环节,其目的是评估系统在不同负荷下的性能表现,包括响应时间、吞吐量、并发数等指标。通常可以通过以下几种方法进行性能测试: 1、负载测试 负载测试是模拟多用户同时访问系统,测试系统在高并发、…...

深入剖析 Qt QHash :原理、应用与技巧
目录标题 引言QHash 基础用法基础用法示例基础用法综合示例 QHash 的高级用法迭代器:遍历 QHash 中的元素(Iterators: Traversing Elements in QHash )QHash和其他容器的对比QHash 和 std::unordered\_map QHash的底层原理和内存管理QHash 的…...
技术分享 | MySQL级联复制下进行大表的字段扩容
作者:雷文霆 爱可生华东交付服务部 DBA 成员,主要负责Mysql故障处理及相关技术支持。爱好看书,电影。座右铭,每一个不曾起舞的日子,都是对生命的辜负。 本文来源:原创投稿 *爱可生开源社区出品,…...
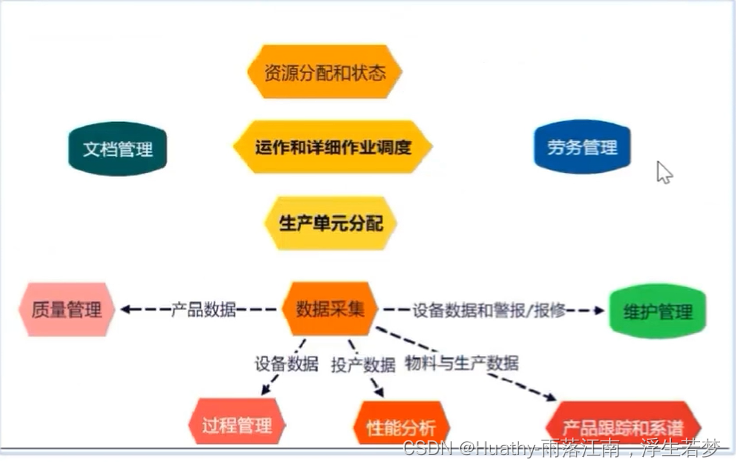
工业互联网业务知识
文章目录 背景第四次工业革命带动制造业产业升级主要工业大国不同路径 架构ISA95体系架构变革趋势基础通用架构数据采集平台 工业互联网应用软件工业互联网全要素连接产品视角:产销服务企业的业务流程企业数字化改造:车间级全要素连接 工业互联网的产品体…...
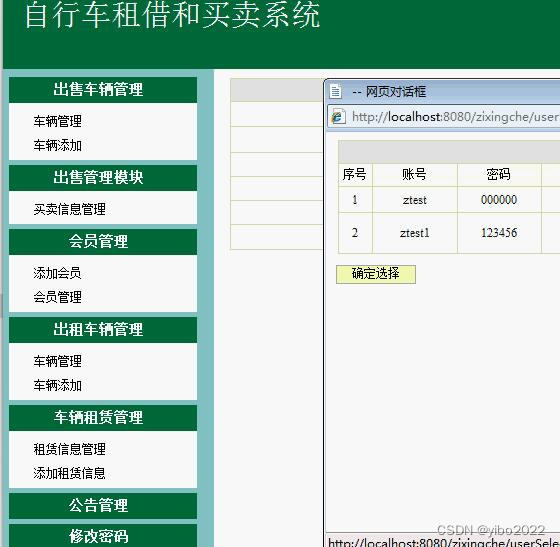
jsp+java自行车租赁租借和买卖系统
自行车租借和买卖系统 系统包括四个模块。1,系统模块,2,车辆管理模块,3.租借车管理模块,4,买卖车管理模块。 1,系统模块包括: 连接数据库,工作人员登录,退出。 2&#…...
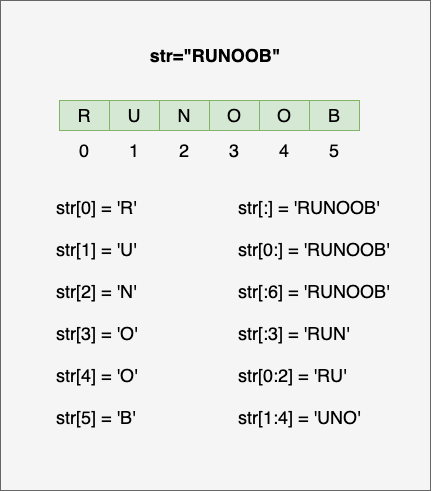
Python3 字符串
Python3 字符串 字符串是 Python 中最常用的数据类型。我们可以使用引号( 或 " )来创建字符串。 创建字符串很简单,只要为变量分配一个值即可。例如: var1 Hello World! var2 "Runoob" Python 访问字符串中的值 Python 不支持单字符…...

Day943.持续集成流水线 -系统重构实战
持续集成流水线 Hi,我是阿昌,今天学习记录的是关于持续集成流水线的内容。 从团队协作的角度上来看,在版本发布过程中,经常出现测试依赖开发手工生成制品、版本发布也从开发本地出版本的问题。而且项目架构如果从单体演进至组件…...

How to use CCS to debug a running M4F core that was started by Linux?
参考FAQ:AM62x & AM64x: How to use CCS to debug a running M4F core that was started by Linux? 问题记录: 1.使用SD卡启动模式,板上运行Linux。 当Linux系统启动后,9表示M4F core: am64xx-evm login: root rootam64xx…...

216、组合总数III
难度:中等 找出所有相加之和为 n 的 k 个数的组合,且满足下列条件: 只使用数字1到9 每个数字 最多使用一次 返回 所有可能的有效组合的列表 。该列表不能包含相同的组合两次,组合可以以任何顺序返回。 示例 1: 输入: k 3, n 7…...

简单的重装系统教程
郁闷,最近电脑一直蓝屏重启,用 2 分钟就蓝屏一次,遂产生重装系统的想法。 准备 U盘(8G或以上) PE 工具: 微PE工具箱快速指引 | 微PE优盘使用说明书 (wepe.com.cn) 系统镜像: 官网 Windows 10 官网 Windows 11 M…...

机器学习---集成学习报告
1.原理以及举例 1.1原理 集成学习(Ensemble Learning)是一种机器学习策略,它通过结合多个基学习器(base learners)的预测来提高模型的性能。集成学习的目标是创建一个比单个基学习器更准确、更稳定的最终预测模型。这…...

教你如何将PDF文件转换成PPT演示文稿
在工作和学习中,我们可能需要将一些PDF文件转换成PPT演示文稿,以便于更好地展示和分享。虽然PPT和PDF是两种不同的文档格式,但是我们可以使用一些专业的软件或在线工具来实现这种转换。下面就让我们来教你如何将PDF文件转换成PPT演示文稿。 …...

涨点技巧: 谷歌强势推出优化器Lion,引入到Yolov5/Yolov7,内存更小、效率更高,秒杀Adam(W)
1.Lion优化器介绍 论文:https://arxiv.org/abs/2302.06675 代码:automl/lion at master google/automl GitHub 1.1 简单、内存高效、运行速度更快 1)与 AdamW 和各种自适应优化器需要同时保存一阶和二阶矩相比,Lion 只需要动量,将额外的内存占用减半; 2)由于 Lion…...
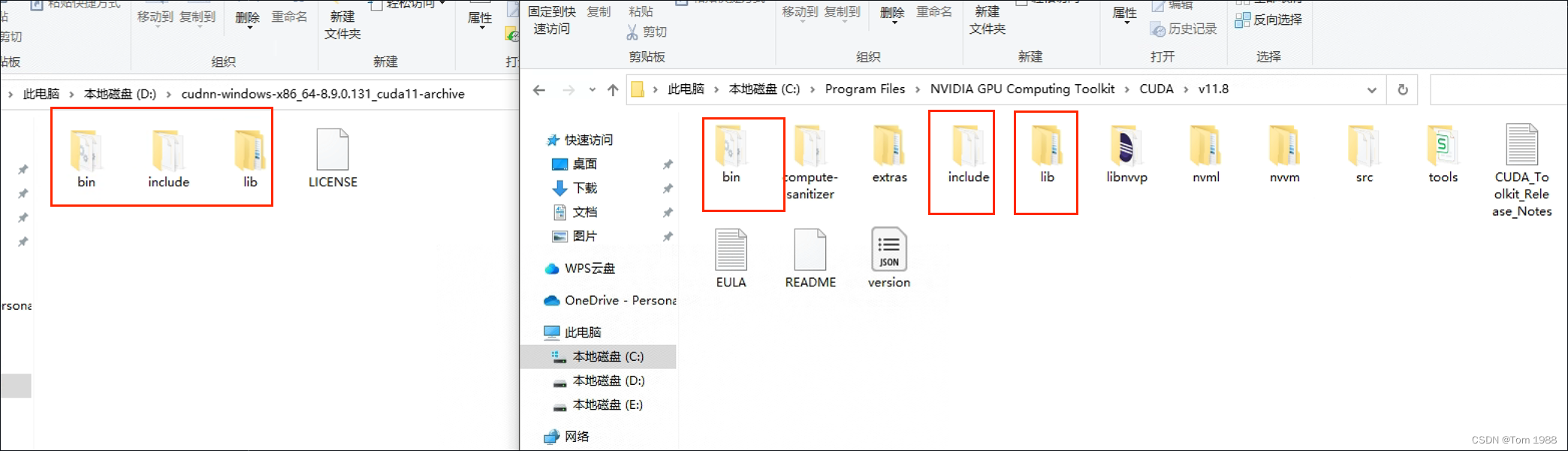
Windows GPU版本的深度学习环境安装
本文记录了cuda、cuDNN的安装配置。 参考文章: cuda-installation-guide-microsoft-windows 12.1 documentation Installation Guide :: NVIDIA cuDNN Documentation 一、cuda安装 注意事项: 1、cuda安装最重要的是查看自己应该安装的版本。 表格…...
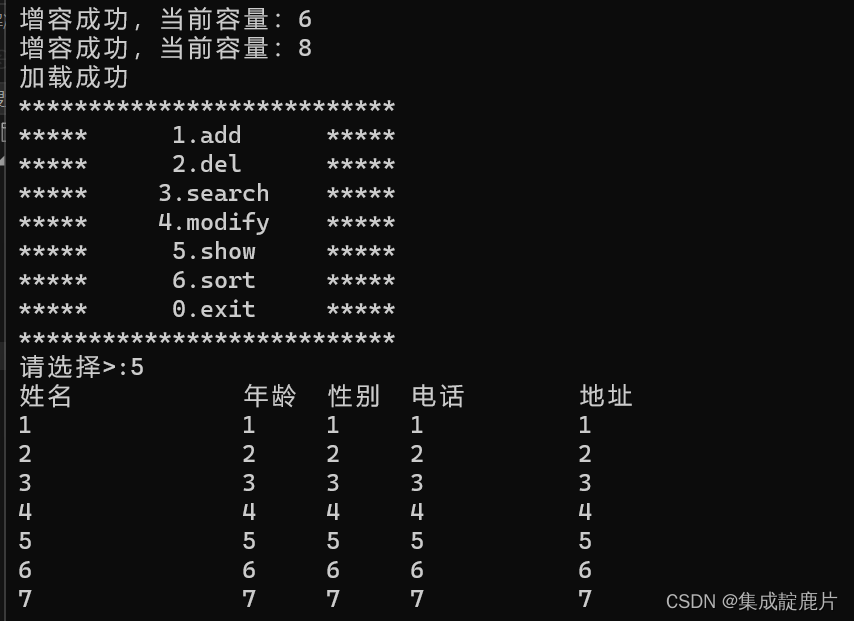
C语言实践——通讯录(3)(文件版)
首先感谢上一篇博客的大佬们的点赞,非常感谢!!! 目录 前言 一、需要添加的功能 1.增加保存数据函数——可以保存数据到文件中 主要逻辑: 注意事项: 代码实现: 2.修改初始化函数——新…...

GPT撑腰,微软再战谷歌 | 大厂集体抢滩ChatGPT:谁真的有实力,谁在试点商业化?
国内互联网大厂已经很久没有这样的盛况了! 在各自领域成长为头部的互联网大厂们,近年来正在向“自留地”的纵深发展,正面交锋的机会并不多。直到大洋彼岸传来GPT的声音后,一下子抓住了大厂们的G点,他们仿佛听到了新一轮…...
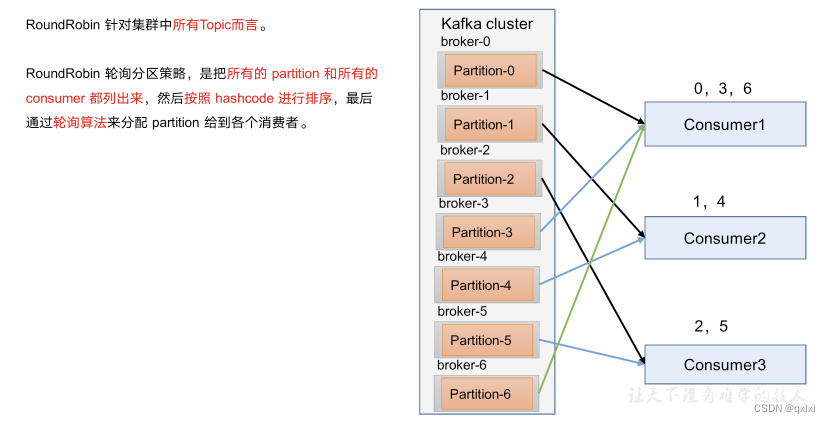
【消息队列】细说Kafka消费者的分区分配和重平衡
消费方式 我们直到在性能设计中异步模式,一般要么是采用pull,要么采用push。而两种方式各有优缺点。 pull :说白了就是通过消费端进行主动拉去数据,会根据自身系统处理能力去获取消息,上有Broker系统无需关注消费端的…...
——打印输出(详细语法参考 + 参数说明 + 具体示例)| 附:Python输出表情包)
【Python从入门到人工智能】14个必会的Python内置函数(7)——打印输出(详细语法参考 + 参数说明 + 具体示例)| 附:Python输出表情包
你仔细想想,你和谁在一起的时候,最放得开、最自然、最舒服,又毫无顾忌,可以做回真实的你。那个人才是你心里最特别,最重要的人。 🎯作者主页: 追光者♂🔥 🌸个人简介: 💖[1] 计算机专业硕士研究生💖 🌟[2] 2022年度博客之星人工智能领域TOP4�…...
)
新手避坑指南:用CCS10和LaunchXL-F28379D点亮第一个LED(GPIO输出两种方法详解)
从零点亮LED:LaunchXL-F28379D开发板GPIO实战避坑手册 刚拿到LaunchXL-F28379D开发板时,那种既兴奋又忐忑的心情我至今记忆犹新。作为TI C2000系列中的明星产品,这块板子强大的DSP性能与丰富的外设令人跃跃欲试,但面对密密麻麻的英…...

图像采集卡与相机内置采集:架构差异、性能对比与选型指南
1. 项目概述:从“外挂”到“内置”的采集路径之争在视觉系统集成或工业检测项目里,选型阶段总会遇到一个基础但关键的问题:图像采集卡和相机内置的采集功能,到底该用哪个?这可不是一个简单的“哪个更好”的问题&#x…...

从地图导航到网络路由:深入理解Floyd-Warshall算法的动态规划内核与空间优化技巧
从地图导航到网络路由:深入理解Floyd-Warshall算法的动态规划内核与空间优化技巧 当我们使用地图导航寻找两点间最快路线时,或在数据中心配置网络路由协议时,背后可能都在运行一个经典的图论算法——Floyd-Warshall。这个诞生于1962年的算法以…...

Go 入门 08:goroutine 与 channel
Go 入门 08:goroutine 与 channel 并发是 Go 的招牌特性。Rob Pike 提出 “Don’t communicate by sharing memory; share memory by communicating”——不要通过共享内存来通信,而要通过通信来共享内存。这正是 goroutine channel 的核心哲学。 一、g…...

无王无帝定乾坤,来自田间第一人 海棠山铁哥布大道兴世
无王无帝定乾坤 ——来自田间第一人“山河起落,不在帝王;世道兴衰,系于百姓。”一、王权落幕,大道升起 古往今来,世人总把天下兴亡系于龙椅之上。 却不知—— 真正扭转乾坤的力量,深藏在乡野沃土࿰…...

深度解析nxdumptool:专业级Switch游戏卡带转储工具完全指南
深度解析nxdumptool:专业级Switch游戏卡带转储工具完全指南 【免费下载链接】nxdumptool Generates XCI/NSP/HFS0/ExeFS/RomFS/Certificate/Ticket dumps from Nintendo Switch gamecards and installed SD/eMMC titles. 项目地址: https://gitcode.com/gh_mirror…...

LeaguePrank终极指南:3分钟掌握英雄联盟个人信息自定义
LeaguePrank终极指南:3分钟掌握英雄联盟个人信息自定义 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 你是否厌倦了英雄联盟中千篇一律的个人资料展示?想要在召唤师峡谷中展示独特的自我形象ÿ…...

如何免费下载抖音无水印视频:开源工具完整使用指南
如何免费下载抖音无水印视频:开源工具完整使用指南 【免费下载链接】douyin_downloader 抖音短视频无水印下载 win编译版本下载:https://www.lanzous.com/i9za5od 项目地址: https://gitcode.com/gh_mirrors/dou/douyin_downloader 还在为抖音视频…...

Windows远程桌面终极解锁指南:RDP Wrapper Library完整使用教程
Windows远程桌面终极解锁指南:RDP Wrapper Library完整使用教程 【免费下载链接】rdpwrap RDP Wrapper Library 项目地址: https://gitcode.com/gh_mirrors/rd/rdpwrap 还在为Windows家庭版无法使用远程桌面功能而烦恼吗?RDP Wrapper Library是您…...

避坑指南:解决RK3588编译ZLMediaKit时OpenSSL等依赖库路径找不到的问题
RK3588交叉编译ZLMediaKit实战:系统性解决OpenSSL依赖路径问题 第一次在RK3588开发板上尝试编译ZLMediaKit时,我遇到了一个看似简单却令人抓狂的问题——CMake死活找不到OpenSSL库。屏幕上不断跳出的Could NOT find OpenSSL错误提示,让我意识…...