【Neo4j数据库】图数据库_Neo4j增加节点(关系)、查询、删除数据库等操作解析(Cypher语句)
【Neo4j数据库】图数据库_Neo4j增加节点(关系)、查询、删除操作解析(Cypher语句)
文章目录
- 【Neo4j数据库】图数据库_Neo4j增加节点(关系)、查询、删除操作解析(Cypher语句)
- 1. 介绍
- 2. 节点的创建和查询
- 2.1 创建节点
- 2.2 查询节点
- 3. 创建关系
- 3.1 创建没有任何属性的关系
- 3.2 创建关系,并设置关系的属性
- 3.3 创建双向关系
- 3.4 查询关系
- 3.5 查询有向关系的节点
- 3.6 为关系命名
- 3.7 查询特定的关系类型
- 4. 删除(两种方法)
- 4.1 命令行直接删除节点
- 4.2 删除数据库文件
- 5. 常用查询关键词
- 5.1 count
- 5.2 limit
- 5.3 Distinct
- 5.4 Order by
- 5.5 根据id查找
- 5.6 In的用法
- 5.7 Exists
- 5.8 With
- 5.9 Contains
- 5.10 Union all (Union)
- 6. 补充
- 6.1 创建一个完整的Path
- 6.2 为节点增加一个属性
- 6.3 为节点增加标签
- 6.4 为关系增加属性
- 6.5 MERGE
- 6.6 跟实体相关的函数
- 参考
1. 介绍
Cypher语言的关键字不区分大小写,但是属性值,标签,关系类型和变量是区分大小写的。
Neo4j 中不存在表的概念,只有标签(labels),节点(Node),关联(Relation),路径(path),标签里存的节点,节点和关联可以简单理解为图里面的点和边,路径是用节点和关联表示的如:(a)-[r]->(b),表示一条从节点 a 经关联 r 到节点 b 的路径。
在数据查询中,
- 节点一般用小括号()
- 关系中用括号[]
2. 节点的创建和查询
注意:执行多条cypher语句时,语句之间用分号隔开,browser中的设置菜单下,勾选 Enable multi statement query editor,默认是没有选中的。
2.1 创建节点
// 创建Person 标签,刘德华等若干节点,各自有name,birthday ,born,englishname等属性。
create (n:Person { name: ‘刘德华’, birthday:‘1961年9月27日’,born: 1961 ,englishname:‘Andy Lau’})
create (n:Person { name: ‘朱丽倩’, birthday:‘1966年4月6日’,born: 1966 ,englishname:‘Carol’}) ;
create (n:Person { name: ‘刘向蕙’, birthday:‘2012年5月9日’,born: 2012 ,englishname:‘Hanna’}) ;
create (n:Person { name: ‘任贤齐’, birthday:‘1966年6月23日’,born: 1966 ,englishname:‘Richie Jen’}) ;
create (n:Person { name: ‘金城武’, birthday:‘1973年10月11日’,born: 1973,englishname:‘Takeshi Kaneshiro’}) ;
create (n:Person { name: ‘林志玲’, birthday:‘1974年11月29日’,born: 1974,englishname:‘zhilin’}) ;// 创建Movie 标签,彩云曲等若干节点,各自有title,released 等属性
create (n:Movie { title: ‘彩云曲’,released: 1981})
create (n:Movie { title: ‘神雕侠侣’,released: 1983})
create (n:Movie { title: ‘暗战’,released: 2000})
create (n:Movie { title: ‘拆弹专家’,released: 2017})
2.2 查询节点
// 查询整个图形数据库
match(n) return n;
// 查询具有指定标签的节点
match(n:Movie) return n;
// where 谓词查询
*根据name查询
match (n:Person) where n.name=‘林志玲’ return n
*根据节点的制定属性查询
match(n{name:‘林志玲’}) return n;
// 根据节点属性的条件查询
match(n) where n.born<1967 return n;
3. 创建关系
关系的构成:StartNode - [Variable:RelationshipType{Key1:Value1,Key2:Value2}] -> EndNode,
- 在创建关系时,必须指定关系类型。
3.1 创建没有任何属性的关系
MATCH (a:Person),(b:Movie) WHERE a.name = ‘刘德华’ AND b.title = ‘暗战’ CREATE (a)-[r:DIRECTED]->(b) RETURN r;
// 查询关系
MATCH p=()-[r:DIRECTED]->() RETURN p LIMIT 25
3.2 创建关系,并设置关系的属性
MATCH (a:Person),(b:Movie) WHERE a.name = ‘刘德华’ AND b.title = ‘神雕侠侣’ CREATE (a)-[r:出演 { roles:[‘杨过’] }]->(b) RETURN r;
// 查询关系
MATCH p=()-[r:出演]->() RETURN p LIMIT 25
3.3 创建双向关系
// 刘德华的女是刘向蕙,刘向蕙的父亲是刘德华
MATCH (a:Person),(c:Person)
WHERE a.name = ‘刘德华’ AND c.name = ‘刘向蕙’
CREATE (a)-[r:父亲 { nickname:‘甜心’ }]->(c), (c)-[d:女儿 { nickname:‘爹地’ }]->(a)
RETURN r;
然后,查询:
MATCH p=()-[r:父亲]->() RETURN p LIMIT 25//关系建错了,删除后重新建立
match(a:Person)-[r:女儿]- >(b:Person)delete r;
match(a:Person)-[r:父亲]- >(b:Person)delete r//重新建立双向关系
MATCH (a:Person),(c:Person)
WHERE a.name = ‘刘德华’ AND c.name = ‘刘向蕙’
CREATE (a)-[r:父亲 { nickname:‘爹地’ }]->(c), (c)-[d:女儿 { nickname:‘甜心’ }]->(a)
RETURN r;
接着,查看关系:
match p=()-[r:父亲]- >() return p limit 2
然后,再多创建几个关系
MATCH (a:Person),(c:Movie)
WHERE a.name = ‘刘德华’ AND c.title = ‘彩云曲’
CREATE (a)-[r:出演 { partner:‘张国荣’ }]->(c), (c)-[d:演员 { rolename:‘阿华哥’ }]->(a)
RETURN r;MATCH (a:Person),(c:Movie)
WHERE a.name = ‘刘德华’ AND c.title = ‘拆弹专家’
CREATE (a)-[r:出演 { partner:‘赵薇,高圆圆’ }]->(c), (c)-[d:演员 { rolename:‘华仔’ }]->(a)
RETURN r;MATCH (a:Person),(c:Movie)
WHERE a.name = ‘刘德华’ AND c.title = ‘神雕侠侣’
CREATE (a)-[r:出演 { partner:‘刘亦菲’ }]->(c), (c)-[d:演员 { rolename:‘杨过’ }]->(a)
RETURN r;
继续添加关系
MATCH (a:Person),(c:Person)
WHERE a.name = ‘刘德华’ AND c.name = ‘任贤齐’
CREATE (a)-[d:朋友 { sex:‘男’ }]->(c)
RETURN d;MATCH (a:Person),(c:Person)
WHERE a.name = ‘刘德华’ AND c.name = ‘金城武’
CREATE (a)-[d:朋友 { sex:‘男’ }]->(c)
RETURN d;//这里没有给关系设置属性sex
MATCH (a:Person),(c:Person)
WHERE a.name = ‘刘德华’ AND c.name = ‘林志玲’
CREATE (a)-[d:朋友]->(c)
RETURN d;
查询Person关系:
MATCH (n:Person) RETURN n
3.4 查询关系
- 在Cypher中,关系分为三种:符号“–”,表示有关系,忽略关系的类型和方向;符号“–>”和“<–”,表示有方向的关系;
// 查询整个数据图形
match(n) return n;
// 查询跟指定节点有关系的节点
match(n)–(m:Movie) return n
3.5 查询有向关系的节点
// 查询和刘德华有关系的电影
MATCH (:Person { name: ‘刘德华’ })–>(movie)RETURN movie;
3.6 为关系命名
// 通过[r]为关系定义一个变量名,通过函数 type 获取关系的类型
MATCH (:Person { name: ‘刘德华’ })-[r]->(movie) RETURN r,type(r);
3.7 查询特定的关系类型
// 通过[Variable:RelationshipType{Key:Value}]指定关系的类型和属性。
MATCH (:Person { name: ‘刘德华’ })-[r:出演{partner:‘张国荣’}]->(Movie) RETURN r,type(r);// 查询和刘德华和张国荣合作过的电影
MATCH (:Person { name: ‘刘德华’ })-[r:出演{partner:‘张国荣’}]->(m:Movie) RETURN m;// 查询被刘德华称呼为甜心的女儿
MATCH (:Person { name: ‘刘德华’ })-[r:女儿{nickname:‘甜心’}]->(m:Person) return m// 查询刘德华的老婆是谁
Match (n:Person{name: ‘刘德华’})-[:wife]->(a:Person) return a// 查询刘德华出演过的电影
match(:Person{name:‘l刘德华’})-[r:‘出演’]- >(a:Movie) return a
4. 删除(两种方法)
4.1 命令行直接删除节点
如果数据库中的数据量并不大,节点数相对较少,我们可以通过命令行直接删除节点
1)删除节点:
create (n:City { name: ‘北京’})
Match (n:City{name:‘北京’}) delete n
2)删除关系
Match (a:Person{name:‘刘德华’})-[r:父亲]->(b:Person{name:‘刘向蕙’}) delete r
Match (a:Person{name:‘刘向蕙’})-[r:女儿]->(b:Person{name:‘刘德华’}) delete r
3)删除对应节点及其所有关系,也就是说,只要符合键值对 { property-name:value } 条件的节点都会被删除
match (n {<property-name>:<value>} ) detach delete (n)
// 示例:
//创建节点
merge(t:Test{id:01,name:"hh"})
merge(t:test{id:02,name:"hh"})//name为hh的两个节点及其关系都会删除
match (n{name:"hh"}) detach delete (n)
4)删除所有节点及其所有关系
此命令不用筛选条件,直接将数据库中的所有节点及关系全部删除
match (n) detach delete (n)
4.2 删除数据库文件
如果数据库中的数据量很大,节点数非常多,通过命令行删除会比较慢,那么我们可以通过物理方式直接删除数据库。
- 此类操作直接删除了数据库,数据当然都被清空了
方法:
- 首先,我们需要关闭 Neo4j 数据库的运行;
- 然后找到 Neo4j 数据库的存放目录,也就是 <NEO4J_HOME>/data/ 。如果忘记了 NEO4J_HOME 可以去环境变量中查看
最后,针对不同的 neo4j 版本,进行不同的删除操作。- 3.x版:Neo4j 的 3.x 版本下有一个 databases 文件夹,进入这个文件夹,里面有一个 graph.db 的文件夹和一个 store_lock 文件。
这个 graph.db 文件夹就是我们当前使用的数据库,直接删除即可。 - 4.x版:Neo4j 的 4.x 版本下有一个 databases 文件夹和一个 transactions 文件夹,两个文件夹下都有 graph.db。
我们将这两个文件夹下的 graph.db 都删除即可。
- 3.x版:Neo4j 的 3.x 版本下有一个 databases 文件夹,进入这个文件夹,里面有一个 graph.db 的文件夹和一个 store_lock 文件。
5. 常用查询关键词
5.1 count
查询Person 一共有多少人
Match (n:Person ) return count(n)
查询标签(Person)中born=1966的一共有多少节点(人):
三种写法(第三种不能用似乎):
1、Match (n:Person) where n.born=1966 return count(n)
2、Match (n:Person{born:1966}) return count(n) //特别注意类型,如果存的类似是数字类型,使用字符串就查不出来
3. Match (n:Person) return count(n.born=1966) //貌似无效,查出来是错的?
5.2 limit
Match (n:Person) return n limit 3
5.3 Distinct
两个1966,只显示一个:
Match (n:Person) return distinct(n.born)
5.4 Order by
Match(n:Person) return n order by n.born (默认升序)
Match(n:Person) return n order by n.born asc (升序)
Match(n:Person) return n order by n.born desc (降序)
5.5 根据id查找
match (n) where id(n)=548 return n
5.6 In的用法
Match (n) where ID(n) IN[353,145,547] return n
Match (n) where ID(n) IN[145,175,353,547,548] return n
5.7 Exists
节点存在 name这个属性的记录:
Match (n) where exists(n.title) return n
5.8 With
查询name以‘刘’开头的节点:
Match (n) where n.name starts with ‘刘’ return n
5.9 Contains
查询title中含有 ‘侠侣’的节点:
Match (n:Movie) where n.title Contains ‘侠侣’ return n
5.10 Union all (Union)
求并集,不去重(去重用Union, as 取别名):
Match(n:Person) where n.born=1966 return n.name as nameUnion allMatch(n:Movie) where n.released=1983 return n.title as name
6. 补充
6.1 创建一个完整的Path
CREATE p =(m:Person{ name:‘刘亦菲’,title:“演员” })-[:签约]->(neo)<-[:签约]-(n:Person { name: ‘赵薇’,title:“投资人” })
RETURN p
6.2 为节点增加一个属性
- 通过节点的ID获取节点,Neo4j推荐通过where子句和ID函数来实现。
match (n)
where id(n)=358
set n.name = ‘华谊兄弟’
return n;
6.3 为节点增加标签
match (n)
where id(n)=358
set n:公司
return n;
6.4 为关系增加属性
match (n)-[r]->(m)
where id(n)=357 and id(m)=358
set r.经纪人=‘程晨’
return n;
接着,让刘德华也和华谊兄弟签约
MATCH (a:Person),(c:公司)
WHERE a.name = ‘刘德华’ AND c.name = ‘华谊兄弟’
CREATE (a)-[d:签约 { 经纪人:‘刘得得’ }]->©
RETURN d;
6.5 MERGE
Merge子句的作用有两个:
- 当模式(Pattern)存在时,匹配该模式;
- 当模式不存在时,创建新的模式,功能是match子句和create的组合。在merge子句之后,可以显式指定on creae和on match子句,用于修改绑定的节点或关系的属性。
通过merge子句,你可以指定图形中必须存在一个节点,该节点必须具有特定的标签,属性等。
- 如果不存在,那么merge子句将创建相应的节点。
- 通过merge子句匹配搜索模式,匹配模式是:一个节点有Person标签,并且具有name属性;如果数据库不存在该模式,那么创建新的节点;如果存在该模式,那么绑定该节点;
1)基础。
MERGE (m:Person { name: ‘迈克尔·杰克逊’ })
RETURN m;
2)在merge子句中指定on create子句
如果需要创建节点,那么执行on create子句,修改节点的属性;
MERGE (m:Person { name: ‘杰森·斯坦森’ })
ON CREATE SET m.registertime = timestamp()
RETURN m.name, m.registertime
3)在merge子句中指定on match子句
如果节点已经存在于数据库中,那么执行on match子句,修改节点的属性;节点属性不存在则新增。
MERGE (m:Person)
ON MATCH SET m.registertime = timestamp()
RETURN m.name, m.registertime
4)在merge子句中同时指定on create 和 on match子句,(没有对应属性则修改不成功,不会新增属性)
MERGE (m:Person{ name: ‘李连杰’ })
ON CREATE SET m.registertime = timestamp()
ON MATCH SET m.offtime = timestamp()
RETURN m.name, m.registertime,m.offtime
6)merge子句用于match或create一个关系
MATCH (m:Person { name: ‘刘德华’ }),(n:Movie { title: ‘神雕侠侣’ })
MERGE (m)-[r:导演]->(n)
RETURN m.name, type(r), n.title
7)merge子句用于match或create多个关系
赵薇既是神雕侠侣的导演,也是神雕侠侣的演员
MATCH (m:Person { name: ‘赵薇’ }),(n:Movie { title: ‘神雕侠侣’ })
MERGE (m)-[r:导演]->(n)<-[r2:出演]-(m)
RETURN m.name, type(r),type(r2), n.title
8)merge子句用于子查询
先添加基础数据,创建城市节点:
create (n:City { name: ‘北京’,othername:‘帝都’})
create (n:City { name: ‘香港’,othername:‘HongKong’})
create (n:City { name: ‘台湾’,othername:‘湾湾’})
9)为Person标签的每个节点都增加一个属性 bornin,
match (n:Person)
set n.bornin = ‘’
return n;match (n)
where id(n)=175
set n.bornin = ‘香港’
return n;match (n)
where n.name=‘金城武’
set n.bornin = ‘台湾’
return n;
10)需求:查找刘德华和金城武的信息和所在地的othername(相当于mysql 连表查询)
MATCH (p:Person)
where p.name=‘刘德华’ or p.name=‘金城武’
MERGE (c:City { name: p.bornin })
RETURN p.name,p.born,p.bornin , c.othername;
11)创建刘德华出生地是香港这条关系
MATCH (a:Person),(c:City)
WHERE a.name = ‘刘德华’ AND c.name = ‘香港’
CREATE (a)-[r:出生地]->(c)
RETURN r;
12)需求:给Person中每个节点都创建一个出生地的关系,没有则返回null
MATCH (p:Person)
MERGE (c:City { name: p.bornin })
MERGE §-[r:出生地]->(c )
RETURN p.name, p.bornin, c.othername;
13)删除这些关系
Match (a:Person)-[r:出生地]->(c:City{name:’’}) delete r
Match (a:City)-[r:出生地]->(c:Person) delete r
14)查询Person标签中不存在name属性的节点
Match (n:Person) where not exists(n.name) return n
Match (n:Person) where not exists(n.name) delete ncreate (n:Prize { name: ‘金马奖’});
create (n:Prize { name: ‘奥斯卡金奖’});
create (n:Prize { name: ‘金鸡奖’});
create (n:Prize { name: ‘香港电影金像奖’});
6.6 跟实体相关的函数
1)通过id函数,返回节点或关系的ID
查询Person标签中和刘德华有关系的 id(节点和关系)
MATCH (:Person { name: ‘刘德华’ })-[r]->(movie)
RETURN id(r);
2)通过type函数,查询关系的类型
查询Person标签中和刘德华相关的关系(以下三种结果相同)
MATCH (:Person { name: ‘刘德华’ })-[r]->(a)
MATCH (:Person { name: ‘刘德华’ })-[r]->(b)
MATCH (:Person { name: ‘刘德华’ })-[r]->()
RETURN type(r);
3)通过lables函数,查询节点的标签
查询和刘德华有关系的节点
MATCH (:Person { name: ‘刘德华’ })-[r]->p
RETURN p;
4)通过keys函数,查看节点或关系的属性键
MATCH (a)
WHERE a.name = ‘刘德华’
RETURN keys(a)
5)通过properties()函数,查看节点或关系的属性
MATCH (a)
WHERE a.name = ‘刘德华’
RETURN properties(a)
参考
【1】https://blog.csdn.net/qq_42582489/article/details/125545454
【2】https://blog.csdn.net/qq_35793394/article/details/107833467
【3】https://blog.csdn.net/poxiaomeng187/article/details/82496157
相关文章:
、查询、删除数据库等操作解析(Cypher语句))
【Neo4j数据库】图数据库_Neo4j增加节点(关系)、查询、删除数据库等操作解析(Cypher语句)
【Neo4j数据库】图数据库_Neo4j增加节点(关系)、查询、删除操作解析(Cypher语句) 文章目录 【Neo4j数据库】图数据库_Neo4j增加节点(关系)、查询、删除操作解析(Cypher语句)1. 介绍2…...
命令)
Linux移动文件和文件夹(目录)命令
命令mv 英文move 翻译移动 mv命令可以移动文件或文件夹(目录),也可以重命令(覆盖)文件。 1. 移动文件/重命名 单纯地移动某一个文件直接使用: mv <源文件名称/地址> <新文件名称/地址>这个方法…...

Pandas的应用-5
Pandas是一个强大的数据处理库,它提供了高性能、易于使用的数据结构和数据分析工具。本文将介绍Pandas常用的数据结构和常用的数据分析技术,包括DataFrame的应用、窗口计算、相关性判定、Index的应用、范围索引、分类索引、多级索引以及日期时间索引。 …...

java继承类怎么写
继承类是通过把父类的方法和属性继承到一个类中,而子类的方法和属性是子类自己定义的。 Java中有一个很重要的概念叫做继承,这也是 Java语言的精髓所在。Java语言提供了一种机制,叫做派生类。在 Java中,如果没有实现了某个派生类方…...

面向对象程序设计
OOP 【面向对象程序设计】(OOP)与【面向过程程序设计】在思维方式上存在着很大的差别。【面向过程程序设计】中,算法是第一位的,数据结构是第二位的,这就明确地表述了程序员的工作方式。首先要确定如何操作数据&#…...
)
Linux 用户身份切换(su,sudo)
文章目录 Linux 用户身份切换su使用案例 sudo使用案例 visudo与/etc/sudoers单一用户可使用root所有命令,与sudoers文件语法利用wheel用户组以免密码的功能处理visudo有限制的命令操作通过别名创建visudosudo的时间间隔问题sudo搭配su的使用方式 Linux 用户身份切换…...

求倒置数问题
文章目录 求倒置数程序设计程序分析求倒置数 【问题描述】数组A【0,…,n-1】是一个n个不同整数数构成的数组。如果i<j,但是A[i]〉A[j],则这对元素(A[i],A[j])被称为一个倒置(inversion)。设计一个O(nlogn)算法来计算数组中的倒置数量 【输入形式】输入两行,第一行…...
)
sed(学习)
1、清除环境变量 profile~/.bash_profile sed -i s#export LD_LIBRARY_PATH.*##g $profile 2、设置环境变量(替换值) sed -i s#export LD_LIBRARY_PATH.*#export LD_LIBRARY_PATH/opt/testlinux/lib#g ~/.bash_profile 3、修改配置文件 sdk_dir/root/test log_dir/…...

B - GCD Subtraction
文章目录 AtCoder Regular Contest 159B - GCD Subtraction AtCoder Regular Contest 159 B - GCD Subtraction 问题:每次A,B都减去gcd(A,B),求其中一个减到0至少需要多少次主要思路: 首先第一步应该想到每次减去的数,先减去的数…...

解决Failed to load ApplicationContext问题的思路
中文翻译: 加载ApplicationContext失败 第一步:首先检查测试类的注解 以及 依赖 SpringBootTest <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scop…...

基于CAMX大气臭氧来源解析模拟与臭氧成因分析实践技术应用
查看原文>>>基于CAMX大气臭氧来源解析模拟与臭氧成因分析实践技术应用 目录 专题一、大气臭氧污染来源及成因分析技术讲解;CAMx模式初识及臭氧来源解析模拟本地案例配置说明 专题二、CAMx模式编译安装及空气质量模拟案例配置 专题三、CAMx扩展和探测工…...
)
异常的讲解 (1)
目录 异常入门的案例 异常介绍 基本概念 异常的小结 常见的运行时异常 1.NullPointerException空指针异常 2.ArithmeticException数学运算异常 3.ArraylndexOutOfBoundsException数组下标越界异常 4.ClassCastException类型转换异常 5.NumberFormatException数字格式不…...
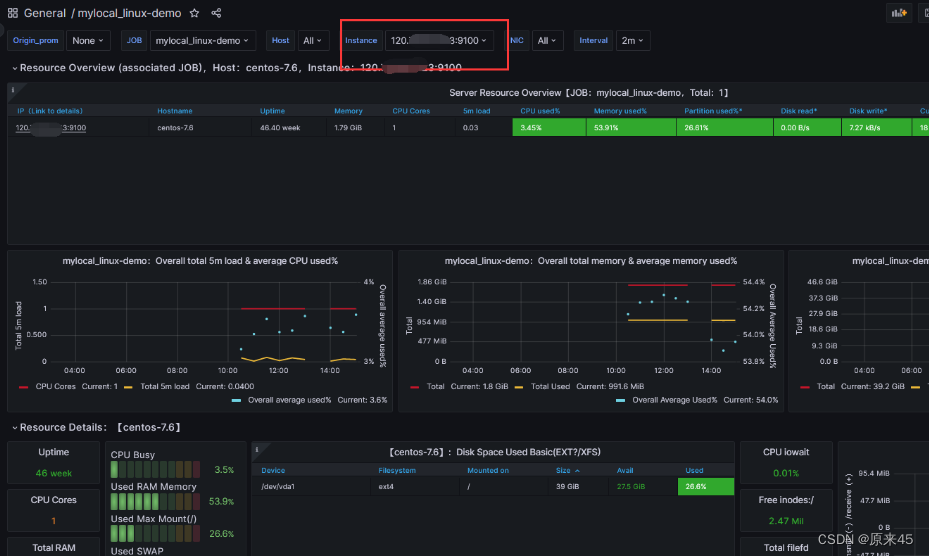
Prometheus - Grafana 监控 MySQLD Linux服务器 demo版
目录 首先是下载Prometheus 下载和安装 配置Prometheus 查看监控数据 监控mysql demo 部署 mysqld_exporter 组件 配置 Prometheus 获取监控数据 -------------------------------------- 安装和使用Grafana 启动Grafana -------------------------------------- 配…...
应届生,实力已超6年,太卷了!
你好,我是田哥 今晚上,给一位朋友做模拟面试,原本说好的90分钟左右,结果整了2个多小时。 很多人估计也很好奇,我们这两个多小时聊聊什么,下面我给大致总结一下: 面试技巧 面试中,我们…...

0-1背包问题
文章目录 0-1背包问题JavaPython0-1背包问题 【问题描述】 给定n种物品和一背包。物品i的重量是wi,其价值为vi,背包的容量为C。问应如何选择装入背包的物品,使得装入背包中物品的总价值最大? 【输入形式】 第一行输入物品的个数n和背包容量C。 第二行输入每个物品的价值v[i…...
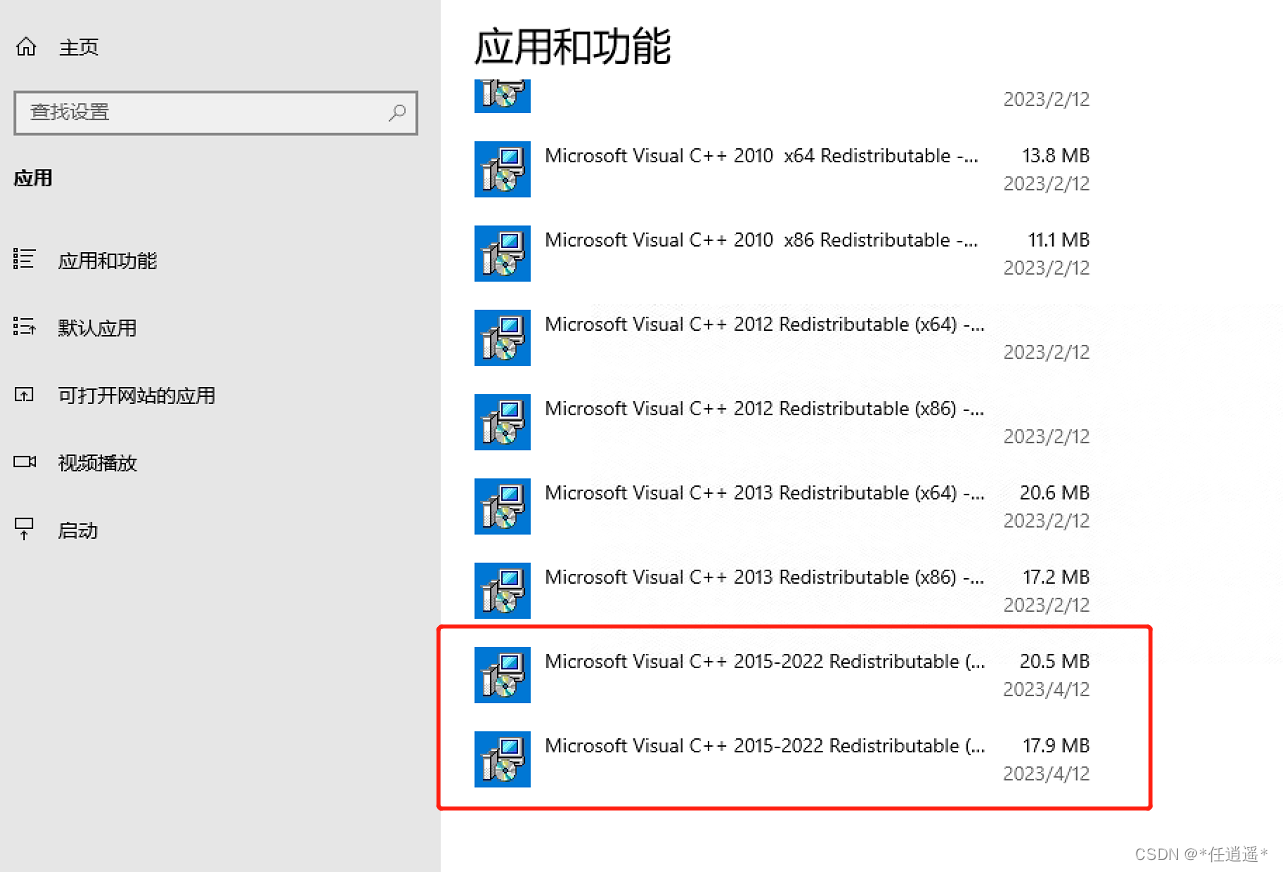
VUE前端项目环境搭建
背景: 想要使用vue搭建一个前端项目,写个小网站练练手,因为没有前端经验,所以从网上找了一个vue得开源模板使用,经过一番挑选选中了字节公司花裤衩大佬开源得项目,地址如下: 开源项目地址&…...

VMware安装Win2000安装程序闪退重启等问题的解决方法
VMware安装Win2000安装程序闪退重启等问题的解决方法 【症状】 1、比较新的VMware版本如16.2.5,Win2000安装时,安装程序在安装Distributed Transaction Coordinator时闪退重启 2、比较新的VMware版本如17.0.1,还会发生显示跳跃性卡顿的现象…...
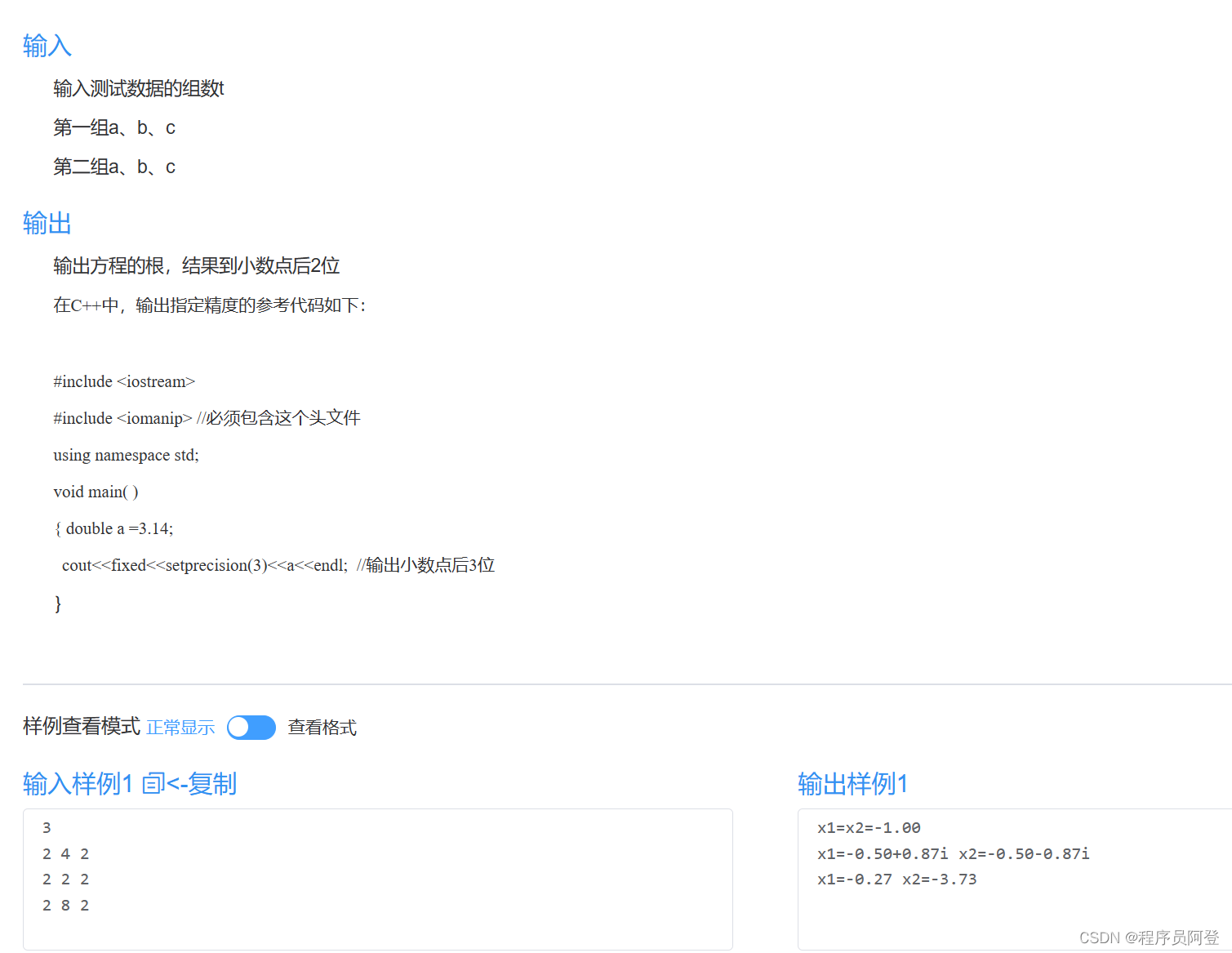
【id:45】【20分】A. Equation(类与对象+构造)
题目描述 建立一个类Equation,表达方程ax2bxc0。类中至少包含以下方法: 1、无参构造(abc默认值为1.0、1.0、0)与有参构造函数,用于初始化a、b、c的值; 2、set方法,用于修改a、b、c的值 3、ge…...

数据库事务
什么是事务 在数据库中,事务(Transaction)是指一组数据库操作,这些操作要么全部成功执行,要么全部失败回滚,是保证数据库操作一致性的基本单位。事务具有原子性(Atomicity)、一致性…...
Macbook(苹果电脑) VSCode 创建简单c++程序 配置C++开发环境
1.打开 Terminal 终端(Command空格,输入Terminal)。 1.1 输入如下指令,查看是否显示版本信息。 clang --version 1.2 如果出现版本信息,则跳过,否则输入 xcode-select --install 2. 为 VS Code 安装插件 …...

工作流的常见模式 [ 2 ]
协调者 - 工作者模式(Orchestrator-Workers)概念好,我们接下来继续来看第4种工作模式。第4种工作模式呢它叫协调者工作者模式。什么是协调者和工作者模式呢?跟大家讲解这个模式,我们需要结合实际当中的例子,…...

MLT框架的“Producer”到底有多智能?深入loader.dict与avformat揭秘媒体文件自动解析
MLT框架的“Producer”智能解析机制:从loader.dict到avformat的深度探索 当你在MLT框架中写下Producer(profile, nullptr, "video.mp4")这样一行看似简单的代码时,背后其实隐藏着一套精妙的媒体文件自动解析系统。这个系统能够根据文件扩展名、…...

长期使用Taotoken聚合API在服务稳定性方面的体验分享
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken聚合API在服务稳定性方面的体验分享 作为一家长期依赖大模型能力进行产品开发的团队,我们在过去数月里…...

告别跑飞!S32K3xx Standby模式唤醒后程序复位?手把手教你用WKPU和RTC保留关键数据
S32K3xx低功耗实战:WKPU与RTC协同解决Standby模式数据丢失难题 引言 在嵌入式系统设计中,低功耗优化一直是工程师们面临的永恒挑战。S32K3xx系列微控制器凭借其出色的电源管理能力,成为汽车电子、工业控制等领域的热门选择。然而,…...

完整教程:org-modern的25个核心配置选项详解
完整教程:org-modern的25个核心配置选项详解 【免费下载链接】org-modern :unicorn: Modern Org Style 项目地址: https://gitcode.com/gh_mirrors/or/org-modern org-modern是一款为Emacs Org模式提供现代风格的插件,通过字体锁定和文本属性实现…...

YOLOv8从零部署到实战:一站式环境配置与核心功能解析
1. YOLOv8环境搭建全攻略 第一次接触YOLOv8时,我也被各种依赖项搞得头晕眼花。经过多次实践,我总结出一套最稳妥的安装方案,特别适合刚入门的新手。YOLOv8作为当前最先进的目标检测框架之一,其安装过程确实比传统CV库复杂些&#…...

树莓派NOOBS安装指南:从SD卡准备到系统配置全流程详解
1. 项目概述:为什么选择NOOBS作为树莓派入门首选如果你刚拿到一块树莓派,看着这块小小的电路板,第一反应可能是兴奋,紧接着就是困惑:我该怎么让它“活”过来?对于嵌入式开发、物联网原型搭建,甚…...

教你一招轻松定生物医学论文插图
写生物医学论文时,信号通路图、细胞调控机制图、病理机制图是展示研究逻辑的核心视觉语言,几乎是投稿刚需。但不少科研人都踩过绘图的坑:找不到专业的受体、离子通道、磷酸化符号等矢量图标,只能用基础形状拼凑,结果图…...
)
STM32F429三重ADC+DMA实战:从CubeMX配置到7.2MHz采样率代码调试全流程(避坑指南)
STM32F429三重ADCDMA极限采样实战:从CubeMX配置到7.2MHz数据采集全解析 在工业测量、医疗设备或高频信号分析领域,对高速数据采集的需求日益增长。当常规的单ADC方案无法满足采样率要求时,STM32F429的三重ADC交替采样模式配合DMA传输…...

【免费下载】 最靠谱的Cadence Allegro PCB SI 板级仿真教程
最靠谱的Cadence Allegro PCB SI 板级仿真教程 【下载地址】最靠谱的CadenceAllegroPCBSI板级仿真教程 最靠谱的Cadence Allegro PCB SI 板级仿真教程欢迎来到“最靠谱的Cadence Allegro PCB SI 板级仿真教程”资源页面 项目地址: https://gitcode.com/open-source-toolkit/e…...