mapreduce打包提交执行wordcount案例
文章目录
- 一、源代码
- 1. WordCountMapper类
- 2. WordCountReducer类
- 3. WordCountDriver类
- 4. pom.xml
- 二、相关操作和配置
- 1. 项目打包
- 2. 带参测试
- 3. 上传打包后的jar包和测试文档
- 4. 增大虚拟内存
- 5.启动集群
- 6.在hdfs上创建输入文件夹和上传测试文档Hello.txt
- 7. 利用jar包在hdfs实现文本计数
- 8. 查看计算统计结果
一、源代码
1. WordCountMapper类
package org.example.wordcounttemplate;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> {//新建输出文本对象(输出的key类型)private Text text = new Text();//新建输出IntWritable对象(输出的value类型)private IntWritable intWritable = new IntWritable( 1);/*** 重写map方法* @param key 文本的索引* @param value 文本值* @param context 上下文对象* @throws IOException* @throws InterruptedException*/@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//获取拆分后的一行文本//mysql mysql value value valueString line = value.toString();//根据分隔符进行单词拆分String[] words = line.split( " ");//循环创建键值对for (String word : words){//输出key值设置text.set (word) ;//进行map输出//igeek igeek -> <igeek ,1> <igeek,1>context.write(text,intWritable);}}
}2. WordCountReducer类
package org.example.wordcounttemplate;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class WordCountReducer extends Reducer<Text, IntWritable,Text, IntWritable> {//输出value对象private IntWritable valueOut = new IntWritable();/*** 重写reduce方法* @param key 单词值* @param values 单词出现的次数集合* @param context 上下文对象* @throws IOException* @throws InterruptedException*/@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {//每个单词出现的次数int sum= 0;//<igeek,(1,1)>for (IntWritable value : values){//累计单词出现的数量sum += value.get();}//进行封装valueOut.set(sum);// reduce输出context.write(key, valueOut);}
}3. WordCountDriver类
package org.example.wordcounttemplate;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;/*** 充当mapreduce任务的客户端,用于提交任务*/public class WordCountDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1.获取配置信息,获取job对象实例Configuration conf=new Configuration();Job job=Job.getInstance(conf);// 2.关联本Driver得jar路径job.setJarByClass(WordCountDriver.class);// 3.关联map和reducejob.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReducer.class);// 4.设置map得输出kv类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);// 5.设置最终输出得kv类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);// 6.设置输入和输出路径FileInputFormat.setInputPaths(job,new Path(args[0]));FileOutputFormat.setOutputPath(job,new Path(args[1]));// 7.提交jobboolean result=job.waitForCompletion(true);System.out.println(result?"任务提交成功":"任务提交失败");}}4. pom.xml
重点是更改添加打包插件依赖
<plugins><plugin><artifactId>maven-compiler-plugin</artifactId><version>3.6.1</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin>
</plugins>
pom.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>mapreduce_demo</artifactId><version>1.0-SNAPSHOT</version><name>mapreduce_demo</name><!-- FIXME change it to the project's website --><url>http://www.example.com</url><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target></properties><dependencies><!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version></dependency></dependencies><build><plugins><plugin><artifactId>maven-compiler-plugin</artifactId><version>3.6.1</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build></project>二、相关操作和配置
1. 项目打包
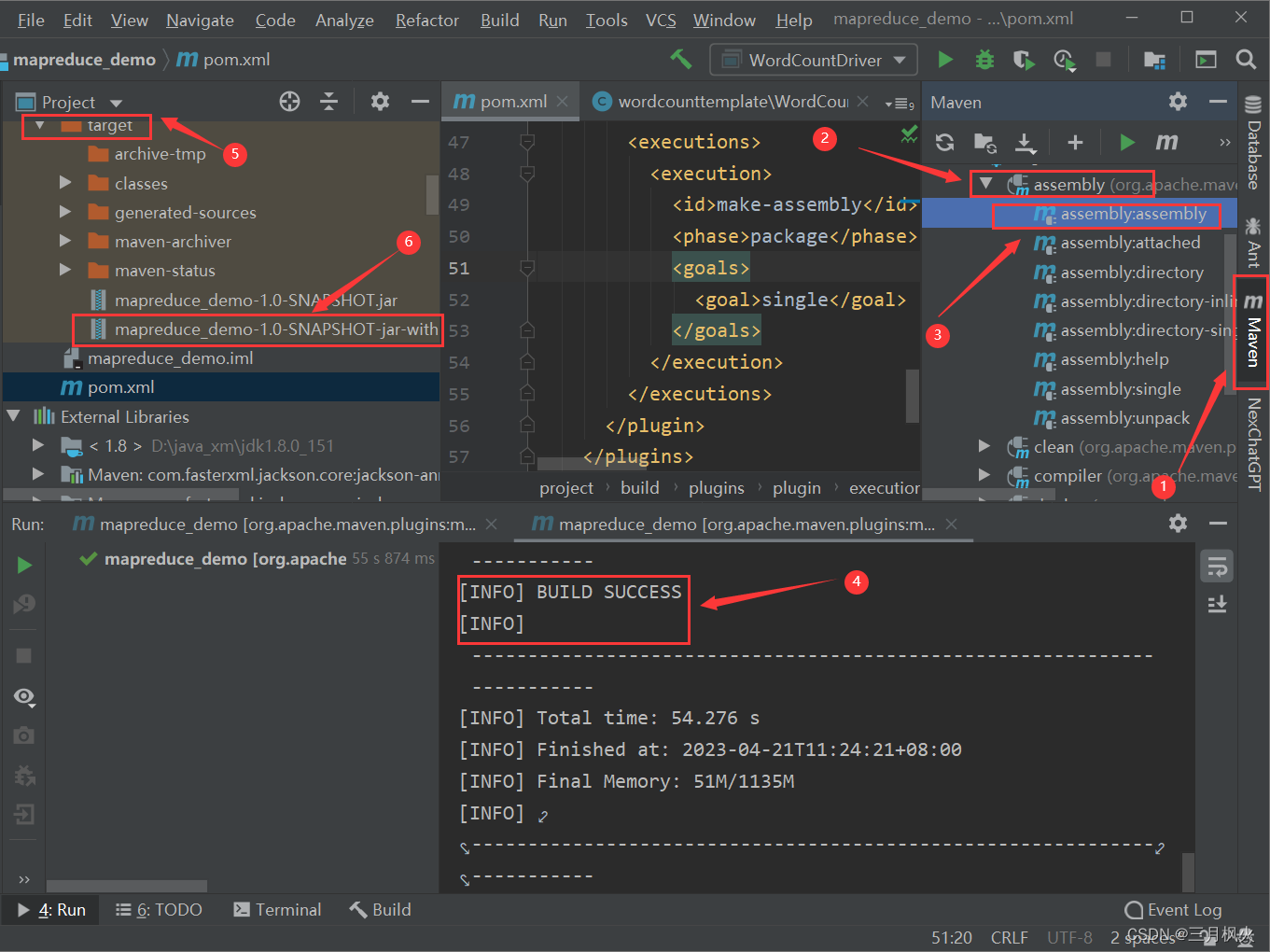
2. 带参测试
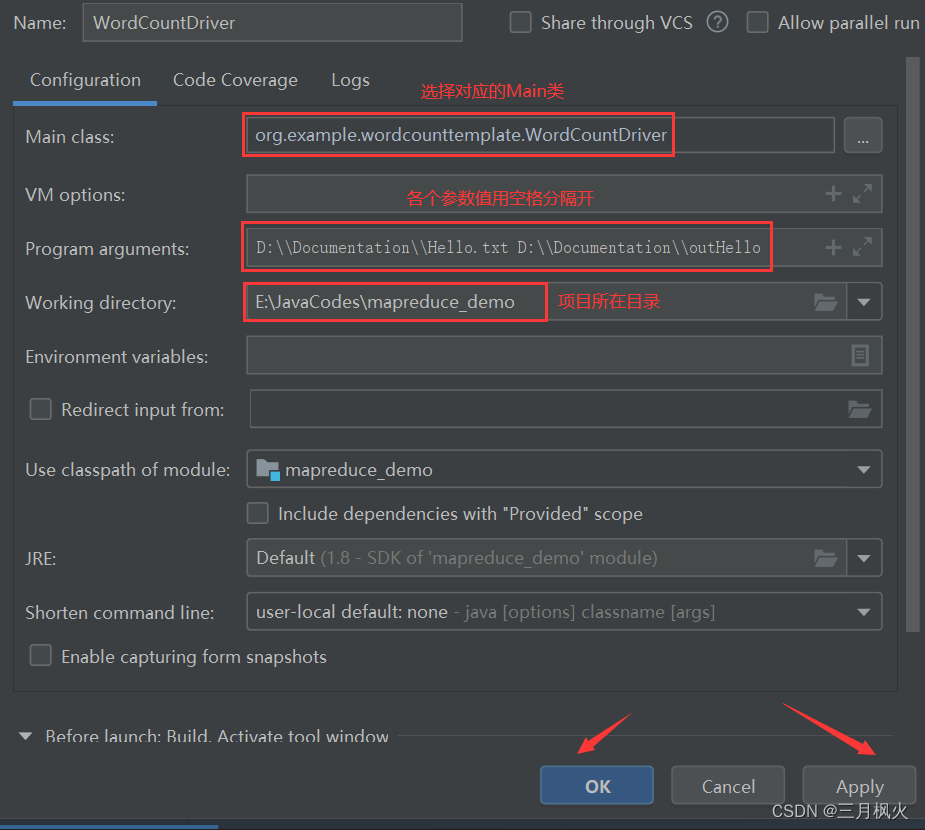
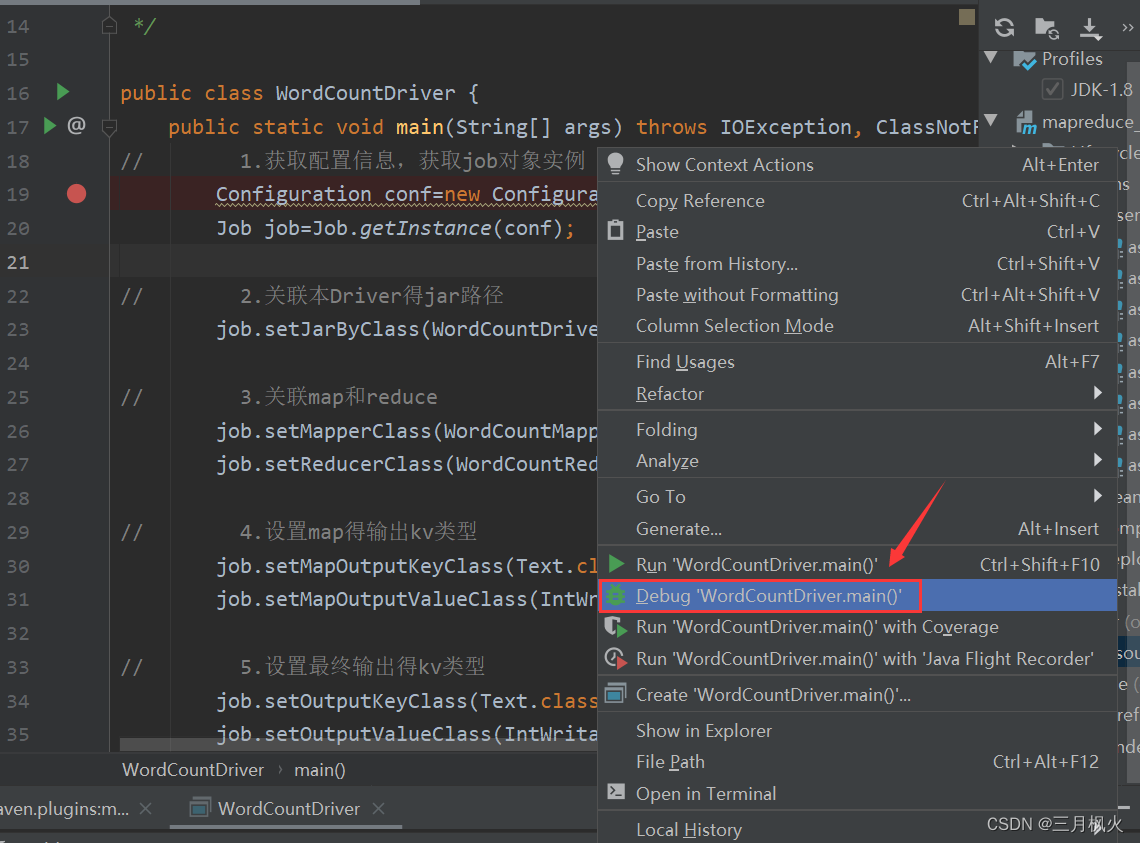
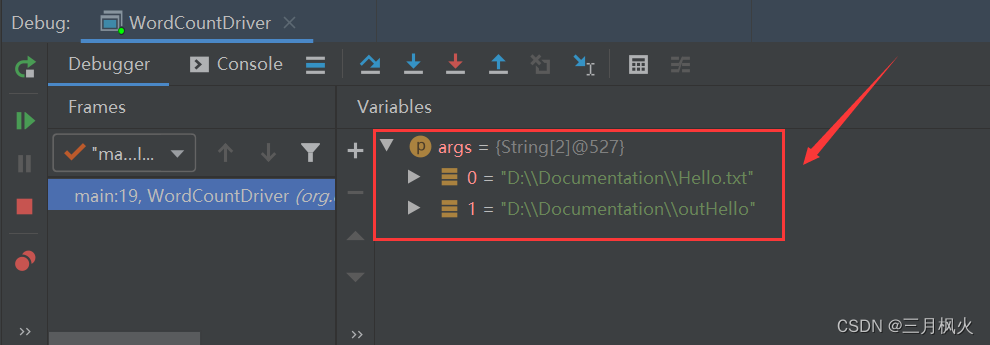
在本地执行成功:
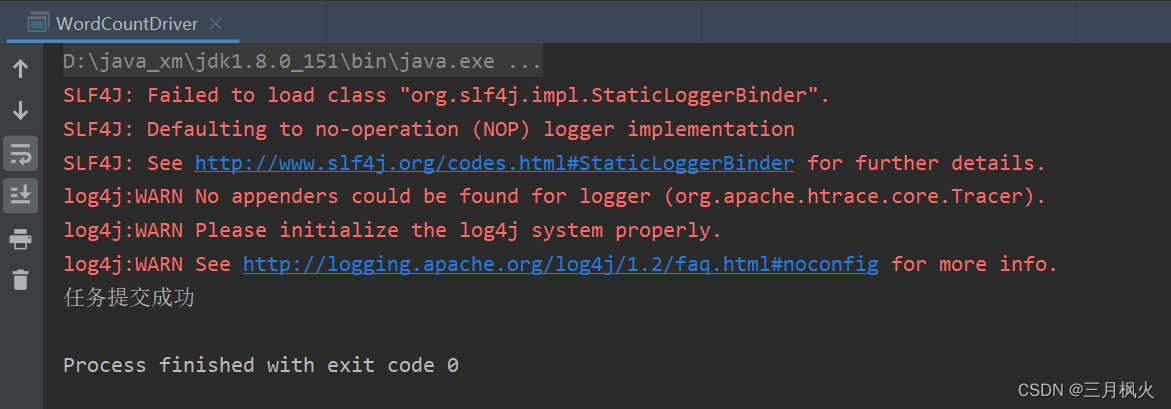
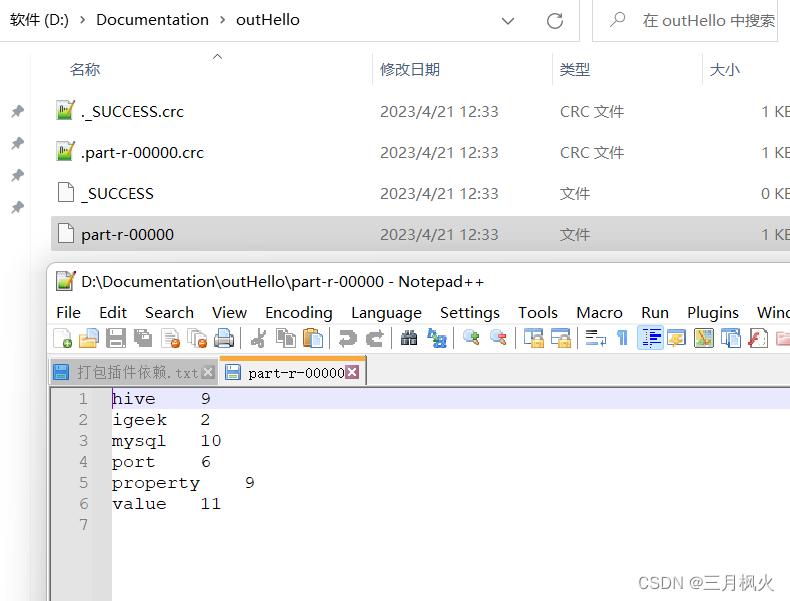
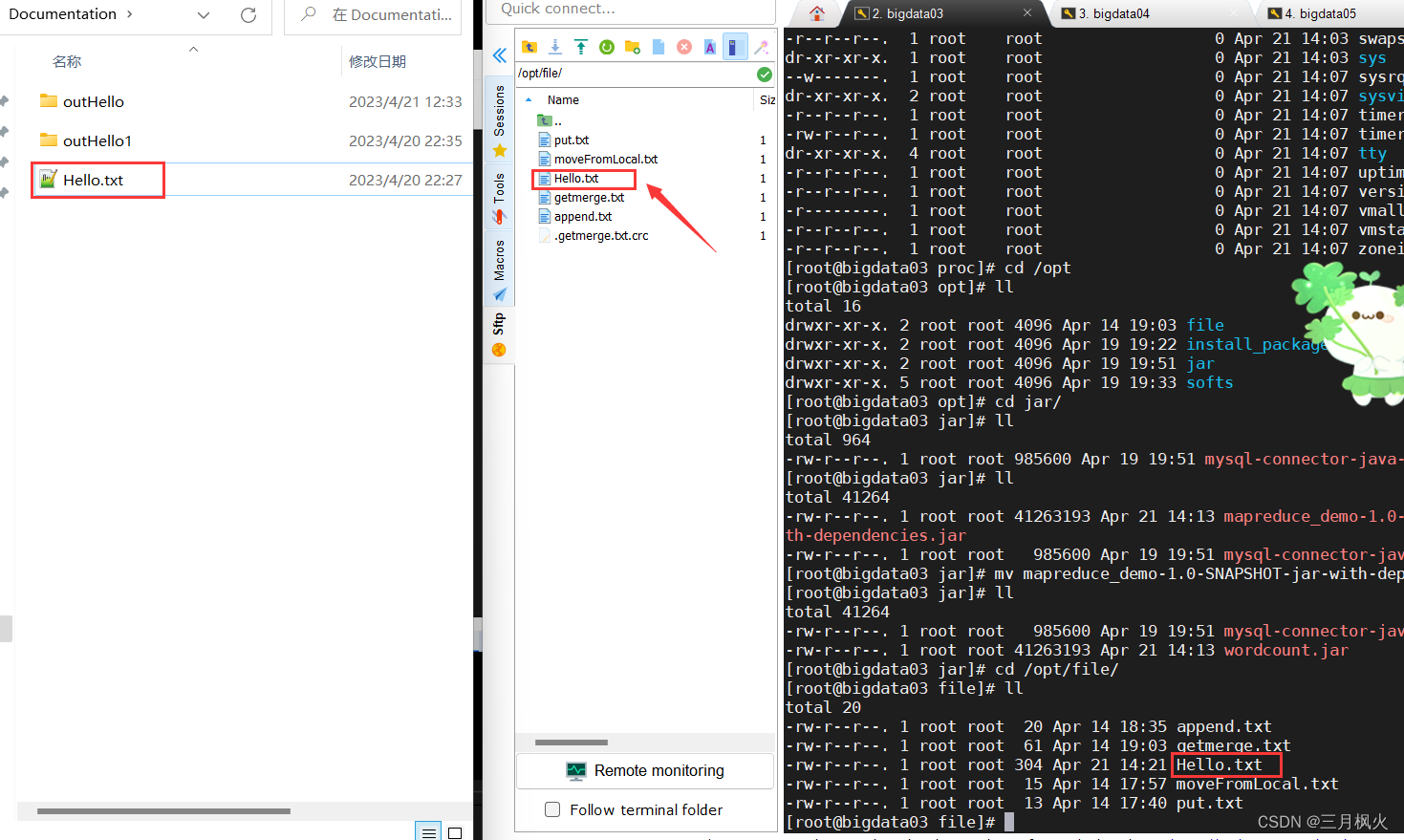
3. 上传打包后的jar包和测试文档
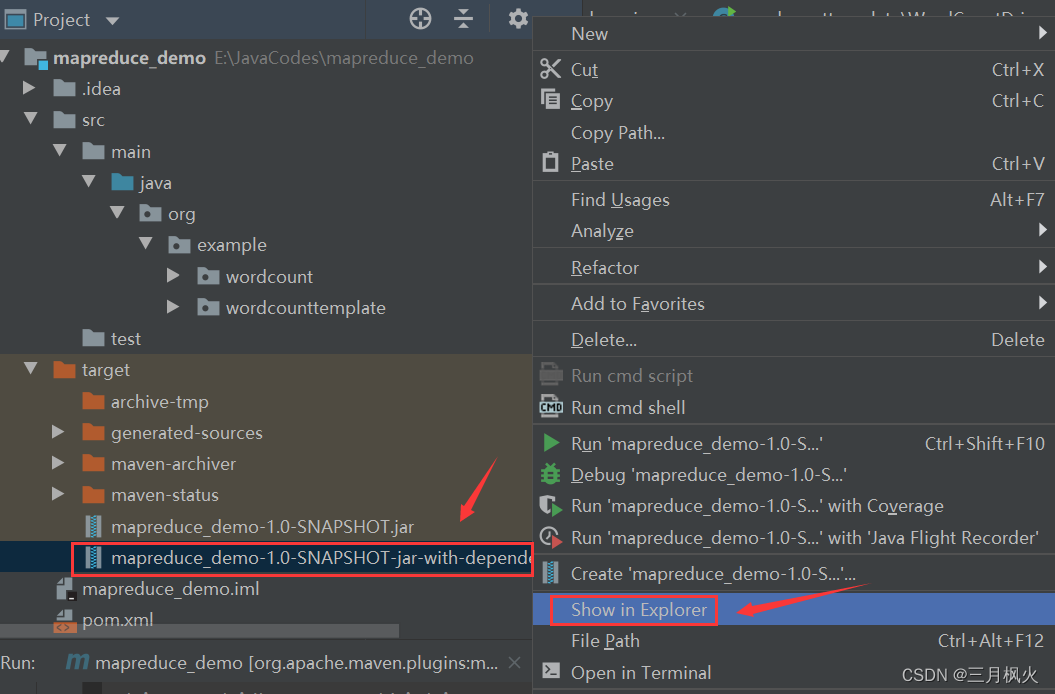
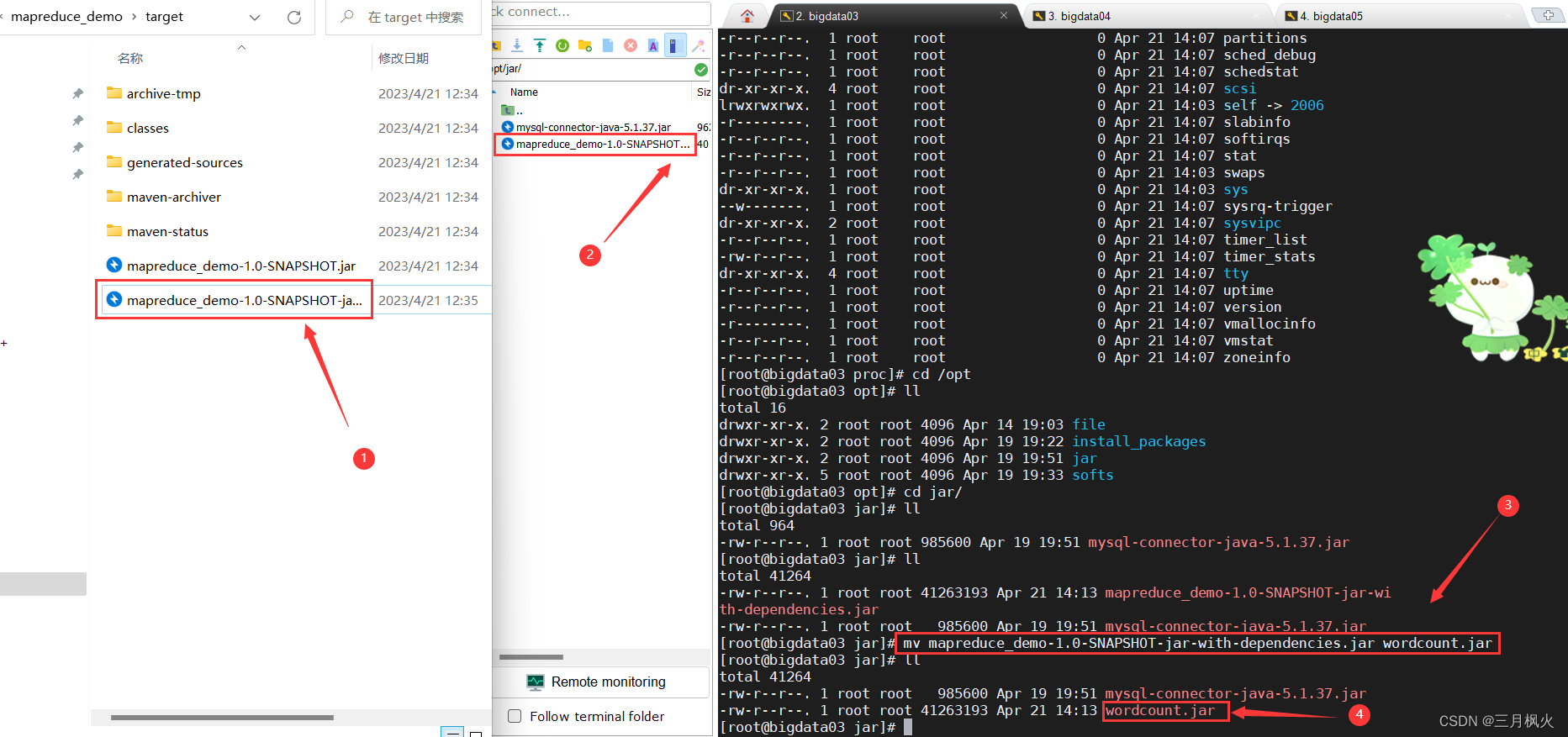
上传打包后的带依赖jar包(第二个)和测试文档Hello.txt 到linux系统及hdfs上
cd /opt/jar/
lljar包改名:
mv mapreduce_demo-1.0-SNAPSHOT-jar-with-dependencies.jar wordcount.jar
ll
cd /opt/file/ll
4. 增大虚拟内存
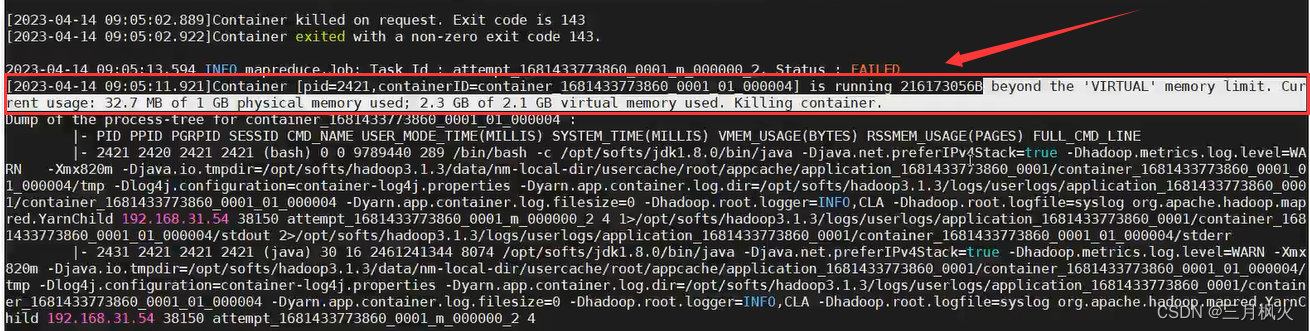
进行MapReduce操作时,可能会报溢出虚拟内存的错误
beyond the 'VIRTUAL’memory limit.
Current usage: 32.7 MB of 1 GB physical memory used;
2.3 GB of 2.1 GB virtual memory used. Killing container.
解决:
在mapred-site.xml中添加如下内容
<!-- 是否对容器强制执行虚拟内存限制 --><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value><description>Whether virtual memory limits will be enforced for containers</description></property><!-- 为容器设置内存限制时虚拟内存与物理内存之间的比率 --><property><name>yarn.nodemanager.vmem-pmem-ratio</name><value>5</value><description>Ratio between virtual memory to physical memory when setting memory limits for containers</description></property>
cd /opt/softs/hadoop3.1.3/etc/hadoop/
vim mapred-site.xml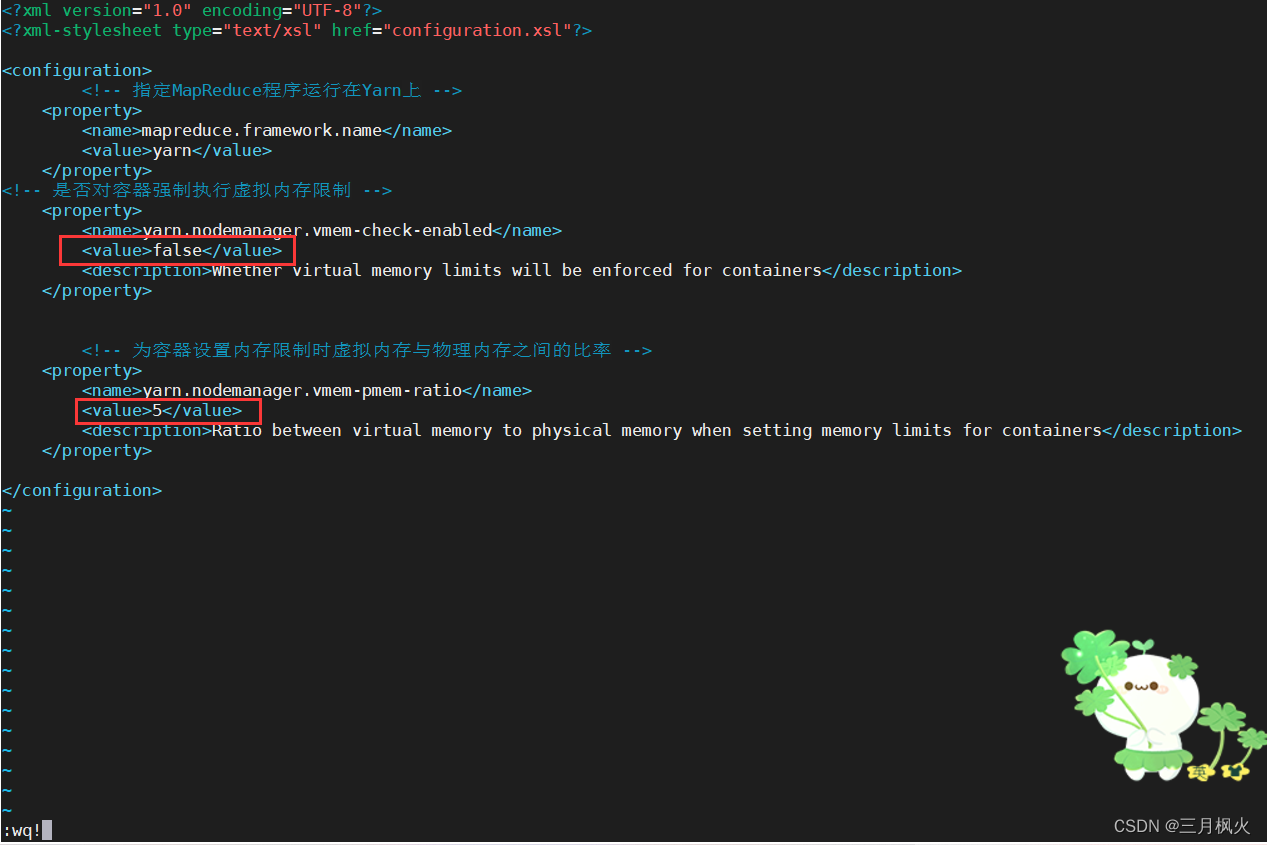
分发到另外两台服务器虚拟机
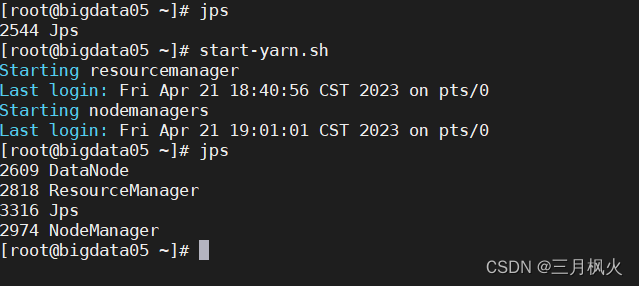
scp mapred-site.xml root@bigdata04:/opt/softs/hadoop3.1.3/etc/hadoop/scp mapred-site.xml root@bigdata05:/opt/softs/hadoop3.1.3/etc/hadoop/5.启动集群
[root@bigdata03 hadoop]# start-dfs.sh[root@bigdata05 ~]# start-yarn.sh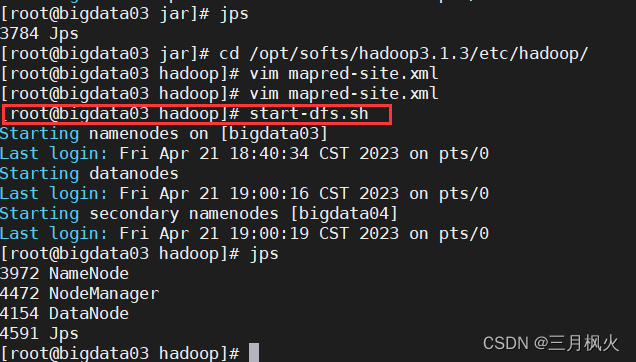
6.在hdfs上创建输入文件夹和上传测试文档Hello.txt
hadoop fs -ls /
hadoop fs -mkdir /inputhadoop fs -put Hello.txt /input
hadoop fs -ls /input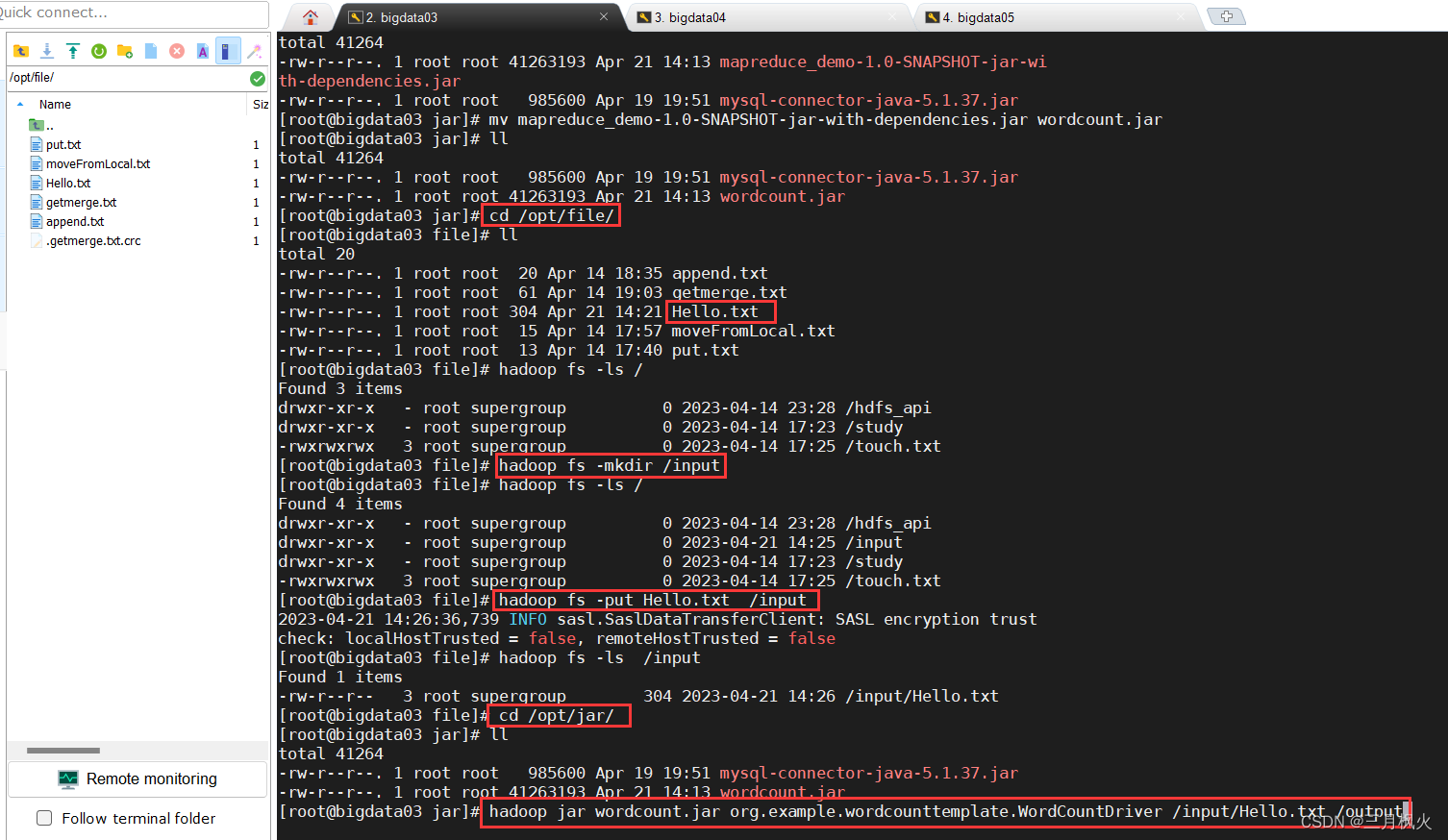
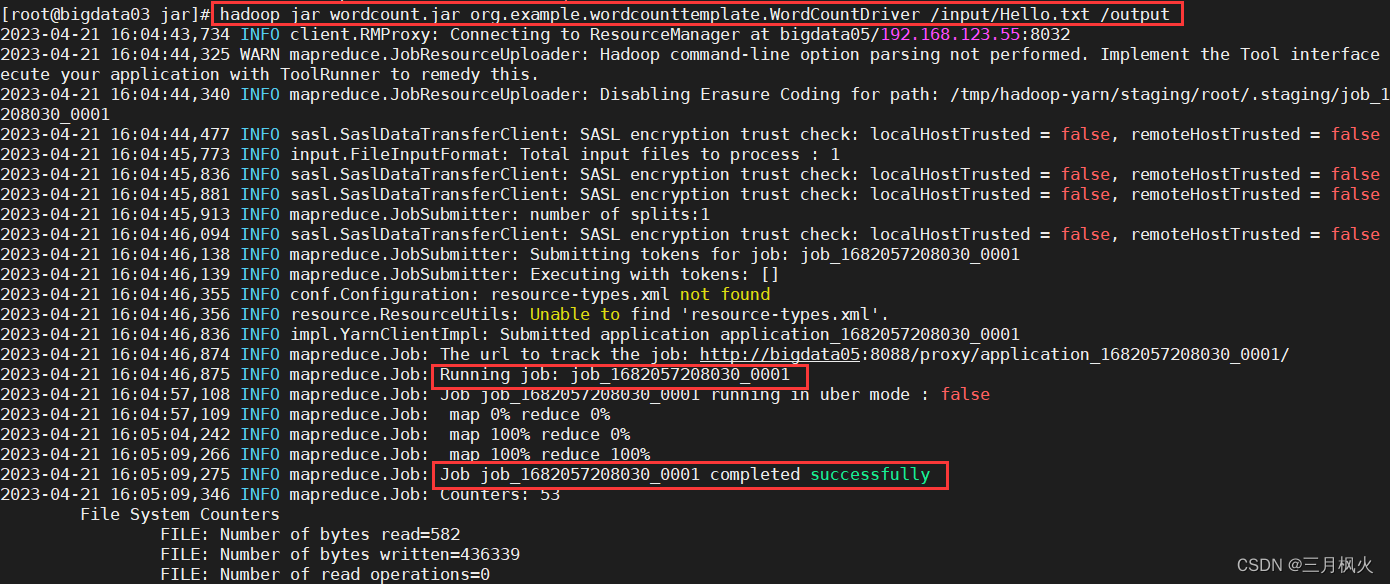
7. 利用jar包在hdfs实现文本计数
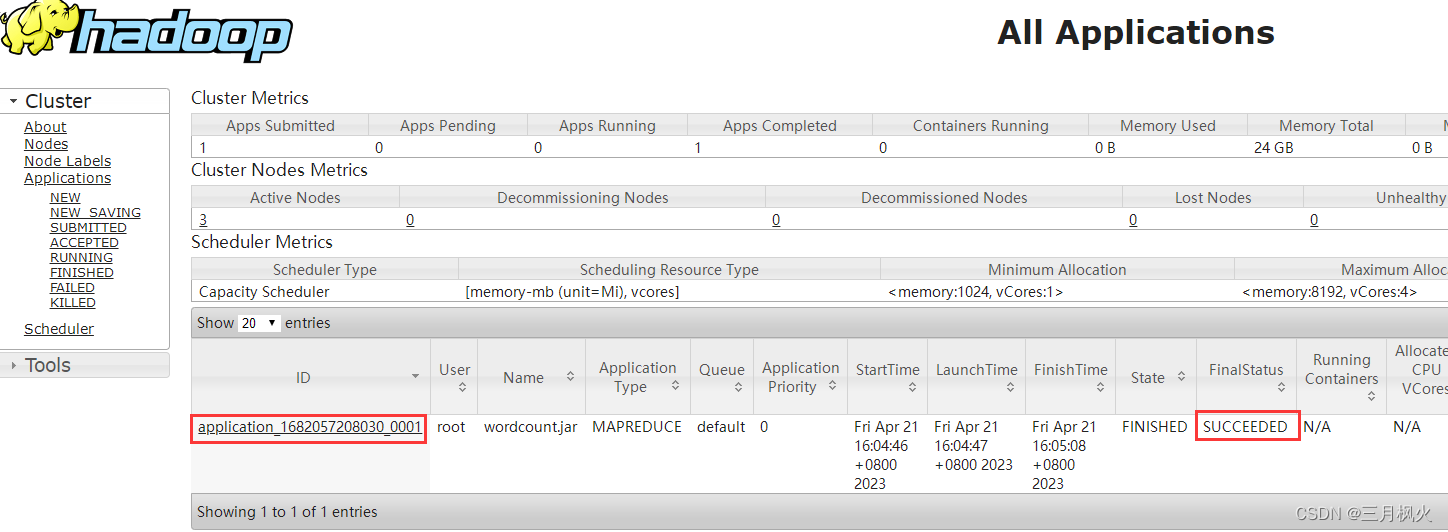
cd /opt/jar/llhadoop jar wordcount.jar org.example.wordcounttemplate.WordCountDriver /input/Hello.txt /output
注意:输出目录需不存在,让他执行命令时自行创建
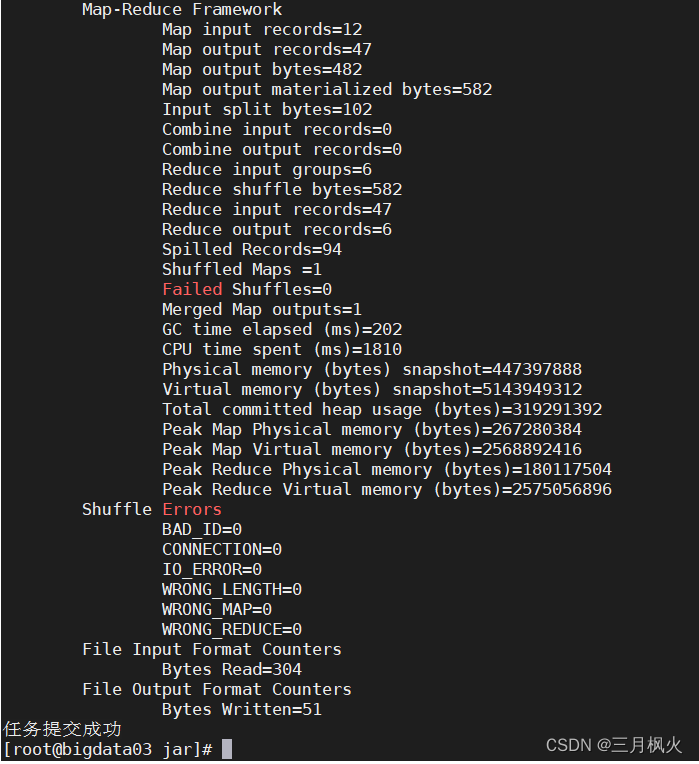
8. 查看计算统计结果
hadoop fs -ls /output
hadoop fs -cat /output/part-r-00000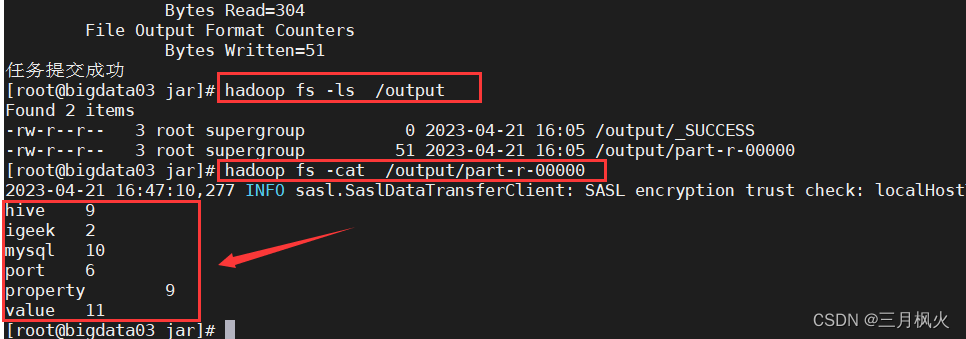
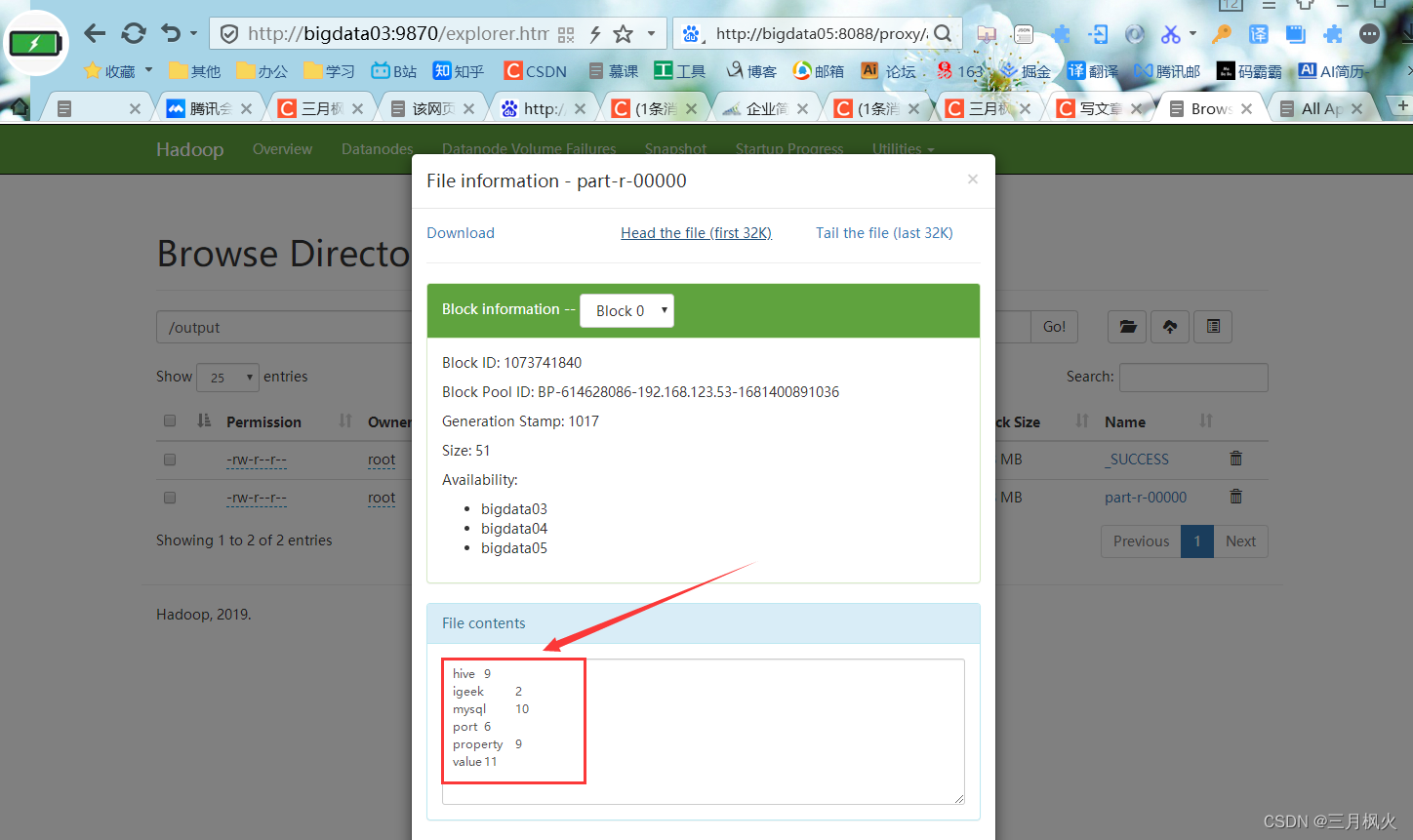
对照文章:
大数据作业4(含在本地实现wordcount案例)
https://blog.csdn.net/m0_48170265/article/details/130029532?spm=1001.2014.3001.5501
相关文章:
mapreduce打包提交执行wordcount案例
文章目录 一、源代码1. WordCountMapper类2. WordCountReducer类3. WordCountDriver类4. pom.xml 二、相关操作和配置1. 项目打包2. 带参测试3. 上传打包后的jar包和测试文档4. 增大虚拟内存5.启动集群6.在hdfs上创建输入文件夹和上传测试文档Hello.txt7. 利用jar包在hdfs实现文…...
MyBatis(十六)MyBatis使用PageHelper
一、limit分页 mysql的limit后面两个数字: 第一个数字:startIndex(起始下标。下标从0开始。) 第二个数字:pageSize(每页显示的记录条数) 假设已知页码pageNum,还有每页显示的记录…...
铁路轨道不平顺数据分析与预测
铁路轨道不平顺数据分析与预测 1.引言 铁路轨道作为铁行车的基础设施,是铁路线路的重要组成部分。随着经济和交通运输业的发展,我国的铁路运输正朝着高速和重载方向迅速发展,与此同时,轨道结构承受来自列车荷载、运行速度的冲击…...

好家伙,9:00面试,9:06就出来了,问的实在是太...
从外包出来,没想到死在另一家厂子 自从加入这家公司,每天都在加班,钱倒是给的不少,所以也就忍了。没想到2月一纸通知,所有人不许加班,薪资直降30%,顿时有吃不起饭的赶脚。 好在有个兄弟内推我去…...
【MySQL】数据库约束和聚合函数的使用
目录 上篇在这里喔~ 1.数据库约束 1.NULL约束 2.UNIQUE唯一约束 3.DEFAULT默认值约束 4.PRIMARY KEY主键约束 5.FOREIGN KEY外键约束 2.表的设计 1.设计思路编辑 2.固定套路编辑 2.1一对一关系 2.2一对多关系 编辑 2.3多对多关系 编辑编辑编辑 3.插入…...

SpringMvcFoundation
SpringMvcFoundation 一. SpringMVC简介1.1 优点二.Spring入门案例2.1 导入坐标2.2 编写SpringBoot启动类2.3 编写controller2.4 入门案例工作流程分析2.4.1 启动服务器初始化过程2.4.2 单次请求过程2.5 PostMan简介2.5.1 PostMan基本使用2.6 请求与相应2.6.1 请求映射路径2.6.…...

从零学习SDK(7)如何打包SDK
打包SDK的目的是为了方便将SDK提供给其他开发者或用户使用,以及保证SDK的兼容性和安全性。打包SDK可以有以下几个好处: 减少依赖:打包SDK可以将SDK所需的库、资源、文档等打包成一个文件或者一个目录,这样就不需要用户再去安装或…...

Python OpenCV 3.x 示例:1~5
原文:OpenCV 3.x with Python By Example 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 计算机视觉 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 当别人说你没有底线的时候,你最…...

葵铭智能面经4.18
虽然是小厂,但面的还是挺有深度的 1.自我介绍 第一个项目 2.有没有用过流协议 3.视频保存有没有切片,有没有考虑过大视频上传的性能问题 4.项目是同步的还是异步的 第二个项目 5.搜索引擎是动态的还是静态的,有没有动态的去爬取boost库…...

MyBatis 03 -MyBatis动态SQL与分页插件
动态SQL与分页插件 动态SQL与分页插件 动态SQL与分页插件1 动态SQL1.1 < sql >1.2 < if >1.3 < where >1.4 < set >1.5 < choose >1.6 < trim >1.7 < foreach > 2 mybatis缓存2.1 一级缓存2.2 二级缓存 3 分页插件3.1 概念3.2 访问与…...

4.10、字节序列转换函数
4.10、字节序列转换函数 1.字节序转换函数2.字节序转换函数有哪些3.字节序转换函数的使用 1.字节序转换函数 当格式化的数据在两台使用不同字节序的主机之间直接传递时,接收端必然错误的解释之。解决问题的方法是:发送端总是把要发送的数据转换成大端字…...
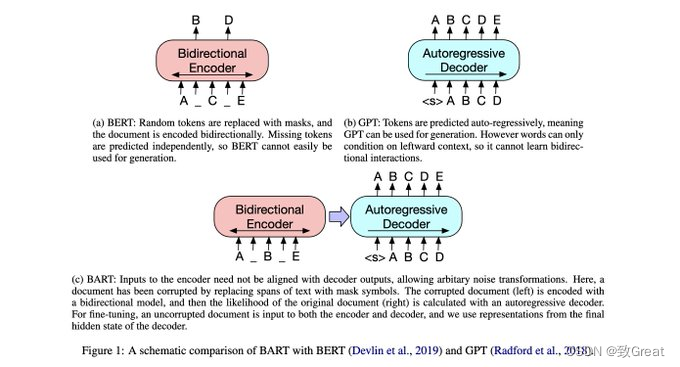
研究LLMs之前,不如先读读这五篇论文!
目标:了解 LMM 背后的主要思想 ▪️ Neural Machine Translation by Jointly Learning to Align and Translate ▪️ Attention Is All You Need ▪️ BERT ▪️ Improving Language Understanding by Generative Pre-Training ▪️ BART Neural Machine Translati…...
认识BASH这个Shell
文章目录 认识BASH这个Shell硬件、内核与shell为什么要学命令行模式的Shell?Bash Shell的功能命令与文件补全(TAB)命令别名设置(alias)历史命令(history)任务管理、前台、后台控制(jobs,fg,bg)通配符程序化脚本 查询命令是否为Bash shell 的内…...

用SQL语句操作Oracle数据库——数据更新
数据更新 数据库中的数据更新操作有3种:1)向表中添加若干行数据(增);2)删除表中的若干行数据(删);3)修改表中的数据(改)。对于这3种操作…...

二维码+互联网云技术在中建二局施工项目管理中的应用实践
中建二局(全称:中国建筑第二工程局有限公司)是世界500强企业—中国建筑股份有限公司的全资子公司,是集房建、基建、核电、火电、风电等多种建设和投资相融合的、国内最具综合实力的大型国有企业集团公司。中建二局具有土木建筑、设…...

扩散模型原理记录
1 扩散模型原理记录 参考资料: [1]【54、Probabilistic Diffusion Model概率扩散模型理论与完整PyTorch代码详细解读】 https://www.bilibili.com/video/BV1b541197HX/?share_sourcecopy_web&vd_source7771b17ae75bc5131361e81a50a0c871 [2] https://t.bili…...

Metasploit高级技术【第九章】
预计更新第一章 Metasploit的使用和配置 1.1 安装和配置Metasploit 1.2 Metasploit的基础命令和选项 1.3 高级选项和配置 第二章 渗透测试的漏洞利用和攻击方法 1.1 渗透测试中常见的漏洞类型和利用方法 1.2 Metasploit的漏洞利用模块和选项 1.3 模块编写和自定义 第三章 Met…...

RK3568平台开发系列讲解(调试篇)IS_ERR函数的使用
🚀返回专栏总目录 文章目录 一、IS_ERR函数用法二、IS_ERR函数三、内核错误码沉淀、分享、成长,让自己和他人都能有所收获!😄 📢本篇将介绍 IS_ERR 函数的使用。 一、IS_ERR函数用法 先看下用法: 二、IS_ERR函数 对于任何一个指针来说,必然存在三种情况: 一种是合…...
TouchGFX界面开发 | TouchGFX软件安装
TouchGFX软件安装 TouchGFX和STemWin类似,都是一个GUI框架,可以方便的在STM32 Cortex-M4 以及更高级别的STM32芯片上创建GUI应用程序。 本文中的TouchGFX软件安装,是基于已经安装有STM32CubeMX Keil MDK-ARM开发环境的情况下进行的&#x…...
使用 IDEA 远程 Debug 调试
背景 有时候我们需要进行远程的debug,本文研究如何进行远程debug,以及使用 IDEA 远程debug的过程中的细节。看完可以解决你的一些疑惑。 配置 远程debug的服务,以springboot微服务为例。首先,启动springboot需要加上特定的参数。…...

终极D2DX宽屏补丁:让经典暗黑破坏神2在现代PC上完美重生
终极D2DX宽屏补丁:让经典暗黑破坏神2在现代PC上完美重生 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 你是否还…...

Scarab空洞骑士模组管理器:2024年最完整的安装与使用指南
Scarab空洞骑士模组管理器:2024年最完整的安装与使用指南 【免费下载链接】Scarab An installer for Hollow Knight mods written with Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab 还在为空洞骑士模组安装的复杂流程而烦恼吗?…...

All in Token,移动,电信,联通,百度,阿里,字节,华为,Token战争,Token无用:李彦宏用DAA终结了AI的度量衡之争
今年4月,AI行业出现了一组让投资人坐立难安的数据:Anthropic年化营收突破300亿美元,正式超过OpenAI的约250亿美元。但反常的是,据第三方机构估算,Claude的月活用户仅约为ChatGPT的2.44%。以及,Anthropic的模…...

立体孪生全域可视,实现仓储人货动线全周期透明管控
立体孪生全域可视,实现仓储人货动线全周期透明管控副标题:动态三维实时还原库区人员、物资、车辆立体态势,运用库区无感定位、跨货架跨镜长距跟踪、身体指纹在岗确权,出入库、巡检、值守、调度全程透明可追溯一、方案总览现代规模…...

如何3分钟搭建智能手机号定位系统:免费归属地查询终极指南
如何3分钟搭建智能手机号定位系统:免费归属地查询终极指南 【免费下载链接】location-to-phone-number This a project to search a location of a specified phone number, and locate the map to the phone number location. 项目地址: https://gitcode.com/gh_…...

【ElevenLabs情绪模拟技术白皮书】:基于2,147小时情感语音标注数据集的11类基础情绪迁移模型验证报告
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs情绪模拟技术白皮书概述 ElevenLabs的情绪模拟技术并非简单调节音高或语速,而是基于多模态情感表征学习(Multimodal Affective Representation Learning, MARL&#x…...
,现在必须掌握的3种替代渲染方案)
像素艺术家紧急预警:Midjourney即将关闭--tile参数兼容性(倒计时14天),现在必须掌握的3种替代渲染方案
更多请点击: https://intelliparadigm.com 第一章:像素艺术家紧急预警:Midjourney即将关闭--tile参数兼容性(倒计时14天) Midjourney v6.5 已正式宣布将于 14 天后终止对 --tile 参数的原生支持,此举将直…...

结构化数字工作空间:提升创意工作效率的目录设计与自动化实践
1. 项目概述:一个为创意工作者量身定制的数字工作空间 如果你是一名设计师、开发者、内容创作者,或者任何需要处理大量数字资产、管理复杂项目流程的创意工作者,那么“Workspace-di-Yivo”这个名字可能会让你眼前一亮。这不仅仅是一个简单的文…...

83.人工智能实战:RAG 表格问答怎么做?从前期发现“表格被切碎”到结构化解析、行列索引与答案校验
人工智能实战:RAG 表格问答怎么做?从前期发现“表格被切碎”到结构化解析、行列索引与答案校验 一、问题场景:Word 文档能答,Excel 表格一问就错 很多企业知识库不只有 Word 和 PDF,还有大量表格: 1. 报销标准表 2. 产品价格表 3. 客户等级表 4. SLA 服务等级表 5. 部门…...
用户指引自助教学源码—东方仙盟)
未来之窗昭和仙君(九十四)用户指引自助教学源码—东方仙盟
软件教学引导功能说明书未来之窗昭和仙君 - cyberwin_fairyalliance_webquery一、功能概述软件教学引导功能主要用于为用户提供软件操作的引导,通过一系列步骤逐步引导用户完成软件的重要操作。该功能会创建遮罩层、高亮框和提示框,引导用户点击特定元素…...