SpringCloud:ElasticSearch之自动补全
当用户在搜索框输入字符时,我们应该提示出与该字符有关的搜索项,如图:

这种根据用户输入的字母,提示完整词条的功能,就是自动补全了。
因为需要根据拼音字母来推断,因此要用到拼音分词功能。
1.拼音分词器
要实现根据字母做补全,就必须对文档按照拼音分词。在GitHub上恰好有elasticsearch的拼音分词插件。地址:https://github.com/medcl/elasticsearch-analysis-pinyin

安装方式与iK分词器一样,分三步:
①下载解压
②上传到虚拟机中,elasticsearch的plugin目录
③重启elasticsearch
④测试
详细安装步骤可以参考IK分词器的安装过程。
测试用法如下:
POST /_analyze
{"text": "我爱北京天安门","analyzer": "pinyin"
}
结果:

2.自定义分词器
默认的拼音分词器会将每个汉字单独分为拼音,而我们希望的是每个词条形成一组拼音,需要对拼音分词器做个性化定制,形成自定义分词器。
elasticsearch中分词器(analyzer)的组成包含三部分:
character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smarttokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
文档分词时会依次由这三部分来处理文档:

声明自定义分词器的语法如下:
PUT /test
{"settings": {"analysis": {"analyzer": { // 自定义分词器"my_analyzer": { // 分词器名称"tokenizer": "ik_max_word","filter": "py"}},"filter": { // 自定义tokenizer filter"py": { // 过滤器名称"type": "pinyin", // 过滤器类型,这里是pinyin"keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"name": {"type": "text","analyzer": "my_analyzer","search_analyzer": "ik_smart"}}}
}

测试:

总结:
如何使用拼音分词器?
-
①下载
pinyin分词器 -
②解压并放到
elasticsearch的plugin目录 -
③重启即可
如何自定义分词器?
-
①创建索引库时,在
settings中配置,可以包含三部分 -
②
character filter -
③
tokenizer -
④
filter
拼音分词器注意事项?
- 为了避免搜索到同音字,搜索时不要使用拼音分词器
3.自动补全查询
elasticsearch提供了Completion Suggester查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中字段的类型有一些约束:
-
参与补全查询的字段必须是
completion类型。 -
字段的内容一般是用来补全的多个词条形成的数组。
比如,一个这样的索引库:
// 创建索引库
PUT test
{"mappings": {"properties": {"title":{"type": "completion"}}}
}
然后插入下面的数据:
// 示例数据
POST test/_doc
{"title": ["Sony", "WH-1000XM3"]
}
POST test/_doc
{"title": ["SK-II", "PITERA"]
}
POST test/_doc
{"title": ["Nintendo", "switch"]
}
查询的DSL语句如下:
// 自动补全查询
GET /test/_search
{"suggest": {"title_suggest": {"text": "s", // 关键字"completion": {"field": "title", // 补全查询的字段"skip_duplicates": true, // 跳过重复的"size": 10 // 获取前10条结果}}}
}
4.实现酒店搜索框自动补全
现在,我们的hotel索引库还没有设置拼音分词器,需要修改索引库中的配置。但是我们知道索引库是无法修改的,只能删除然后重新创建。
另外,我们需要添加一个字段,用来做自动补全,将brand、suggestion、city等都放进去,作为自动补全的提示。
因此,总结一下,我们需要做的事情包括:
-
修改
hotel索引库结构,设置自定义拼音分词器 -
修改索引库的
name、all字段,使用自定义分词器 -
索引库添加一个新字段
suggestion,类型为completion类型,使用自定义的分词器 -
给
HotelDoc类添加suggestion字段,内容包含brand、business -
重新导入数据到
hotel库
4.1.修改酒店映射结构
代码如下:
// 酒店数据索引库
PUT /hotel
{"settings": {"analysis": {"analyzer": {"text_anlyzer": {"tokenizer": "ik_max_word","filter": "py"},"completion_analyzer": {"tokenizer": "keyword","filter": "py"}},"filter": {"py": {"type": "pinyin","keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"id":{"type": "keyword"},"name":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart","copy_to": "all"},"address":{"type": "keyword","index": false},"price":{"type": "integer"},"score":{"type": "integer"},"brand":{"type": "keyword","copy_to": "all"},"city":{"type": "keyword"},"starName":{"type": "keyword"},"business":{"type": "keyword","copy_to": "all"},"location":{"type": "geo_point"},"pic":{"type": "keyword","index": false},"all":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart"},"suggestion":{"type": "completion","analyzer": "completion_analyzer"}}}
}
4.2.修改HotelDoc实体
HotelDoc中要添加一个字段,用来做自动补全,内容可以是酒店品牌、城市、商圈等信息。按照自动补全字段的要求,最好是这些字段的数组。
因此我们在HotelDoc中添加一个suggestion字段,类型为List<String>,然后将brand、city、business等信息放到里面。
代码如下:
package cn.itcast.hotel.pojo;import lombok.Data;
import lombok.NoArgsConstructor;import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;@Data
@NoArgsConstructor
public class HotelDoc {private Long id;private String name;private String address;private Integer price;private Integer score;private String brand;private String city;private String starName;private String business;private String location;private String pic;private Object distance;private Boolean isAD;private List<String> suggestion;public HotelDoc(Hotel hotel) {this.id = hotel.getId();this.name = hotel.getName();this.address = hotel.getAddress();this.price = hotel.getPrice();this.score = hotel.getScore();this.brand = hotel.getBrand();this.city = hotel.getCity();this.starName = hotel.getStarName();this.business = hotel.getBusiness();this.location = hotel.getLatitude() + ", " + hotel.getLongitude();this.pic = hotel.getPic();// 组装suggestionif(this.business.contains("/")){// business有多个值,需要切割String[] arr = this.business.split("/");// 添加元素this.suggestion = new ArrayList<>();this.suggestion.add(this.brand);Collections.addAll(this.suggestion, arr);}else {this.suggestion = Arrays.asList(this.brand, this.business);}}
}
4.3.重新导入
重新执行之前编写的导入数据功能,可以看到新的酒店数据中包含了suggestion:

4.4.自动补全查询的JavaAPI
之前自动补全查询的DSL,而没有对应的JavaAPI,这里给出一个示例:

@Testvoid testSuggest() throws IOException {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备DSLrequest.source().suggest(new SuggestBuilder().addSuggestion("suggestions",SuggestBuilders.completionSuggestion("suggestion").prefix("h").skipDuplicates(true).size(10)));// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应System.out.println("response = " + response);}

而自动补全的结果也比较特殊,解析的代码如下:

@Testvoid testSuggest() throws IOException {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备DSLrequest.source().suggest(new SuggestBuilder().addSuggestion("suggestions",SuggestBuilders.completionSuggestion("suggestion").prefix("h").skipDuplicates(true).size(10)));// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应//System.out.println("response = " + response);Suggest suggest = response.getSuggest();// 4.1 根据名称获取补全结果CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");// 4.2 获取options并遍历for (CompletionSuggestion.Entry.Option option : suggestions.getOptions()) {// 4.3 获取一个option的text,,也就是补全的词条String string = option.getText().string();System.out.println(string);}}

4.5.实现搜索框自动补全
1)在cn.itcast.hotel.web包下的HotelController中添加新接口,接收新的请求:
@GetMapping("suggestion")
public List<String> getSuggestions(@RequestParam("key") String prefix) {return hotelService.getSuggestions(prefix);
}
2)在cn.itcast.hotel.service包下的IhotelService中添加方法:
List<String> getSuggestions(String prefix);
3)在cn.itcast.hotel.service.impl.HotelService中实现该方法:
@Override
public List<String> getSuggestions(String prefix) {try {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备DSLrequest.source().suggest(new SuggestBuilder().addSuggestion("suggestions",SuggestBuilders.completionSuggestion("suggestion").prefix(prefix).skipDuplicates(true).size(10)));// 3.发起请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析结果Suggest suggest = response.getSuggest();// 4.1.根据补全查询名称,获取补全结果CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");// 4.2.获取optionsList<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();// 4.3.遍历List<String> list = new ArrayList<>(options.size());for (CompletionSuggestion.Entry.Option option : options) {String text = option.getText().toString();list.add(text);}return list;} catch (IOException e) {throw new RuntimeException(e);}
}


相关文章:
SpringCloud:ElasticSearch之自动补全
当用户在搜索框输入字符时,我们应该提示出与该字符有关的搜索项,如图: 这种根据用户输入的字母,提示完整词条的功能,就是自动补全了。 因为需要根据拼音字母来推断,因此要用到拼音分词功能。 1.拼音分词器…...
TOOM解析如何搭建一套适合自己的舆情监测系统?完整的实战指南
随着互联网的普及和社交媒体的盛行,人们在网络上的活动越来越多,同时也涌现出大量的信息和舆情。这些信息和舆情在一定程度上会影响社会和个人的发展和进步。因此,舆情监测逐渐成为一项重要的任务。在本篇文章中,我们将为大家介绍…...

技术分享 | OceanBase 手滑误删了数据文件怎么办
作者:张乾 外星人2号,现兼任六位喵星人的资深铲屎官。 本文来源:原创投稿 *爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。 手滑误删了数据文件,并且没有可替换的节点时&…...

windows上Git Bash支持常用命令gcc tree zip wget cmake ninja
windows上Git Bash支持常用命令gcc tree zip wget cmake ninja 前言 Git Bash基于MinGW64, 提供了win32下的linux命令环境,如ls、cat、tar等。 但是Git Bash还是缺少一些命令,如gcc、make、tree、zip、wget、cmake、ninja等 1. Git Bash支持其他命令…...

面试题30天打卡-day10
1、String 和 StringBuffer、StringBuilder 的区别是什么? String、StringBuffer、StringBuilder主要的区别在于执行效率和线程安全上。 String:String字符串常量,意味着它是不可变的,导致每次对String都会生成新的String对象&a…...

【python】制作一个简单的界面,有手就行的界面~
目录 前言准备工作试手小案例开始我们今天的案例教学尾语 💝 前言 嗨喽~大家好呀,这里是魔王呐 ❤ ~! ttkbootstrap 是一个基于 tkinter 的界面美化库, 使用这个工具可以开发出类似前端 bootstrap 风格的 tkinter 桌面程序。 ttkbootstrap …...

基于RK3568的Linux驱动开发—— GPIO知识点(二)
authordaisy.skye的博客_CSDN博客-嵌入式,Qt,Linux领域博主系列基于RK3568的Linux驱动开发——GPIO知识点(一)_daisy.skye的博客-CSDN博客 查看goio使用情况 cat /sys/kernel/debug/gpio 1|rk3568_r:# cat /sys/kernel/debug/gpio gpiochip0: GPIOs 0-3…...

item_get-获得aliexpress商品详情API的调用参数说明
item_get-获得aliexpress商品详情 aliexpress.item_get 公共参数 名称类型必须描述keyString是调用key(免)(测)(试)secretString是调用密钥api_nameString是API接口名称(包括在请求地址中&…...
】Scrapy框架之全局配置文件settings.py详解)
【Python_Scrapy学习笔记(三)】Scrapy框架之全局配置文件settings.py详解
Scrapy框架之全局配置文件settings.py详解 前言 settings.py 文件是 Scrapy框架下,用来进行全局配置的设置文件,可以进行 User-Agent 、请求头、最大并发数等的设置,本文中介绍 settings.py 文件下的一些常用配置 正文 1、爬虫的项目目录…...
spark读写时序数据库 TDengine 错误总结
最近在用spark读取、写入TDengine 数据库遇到了这样一个问题: JDBCDriver找不到动态链接库(no taos in java.library.path) 我本地都好好的,但是一上服务器写入就会报这个错误,看了很久没有排查出问题,后…...

Web中间件常见漏洞
一、IIS中间组件 1、PUT漏洞 原理:IIS开启了WebDAV,配置了可以写入的权限,造成了任意文件上传漏洞。 防御:关闭webDAV;关闭写入权限 2、短文件名猜解 原理: IIS的短文件名机制,可以暴力破解…...

Python Web 深度学习实用指南:第三部分
原文:Hands-On Python Deep Learning for the Web 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象,只关…...

C#基础学习--预处理指令
目录 什么是预处理指令 基本规则 #define 和 #undef 指令 条件编译 条件编译结构 诊断指令 行号指令 编辑 区域指令 #pragam warning 指令 什么是预处理指令 源代码指定了程序的定义,预处理指令指示编译器如何处理源代码 基本规则 #define 和 #undef 指令…...
Spring Boot 接口加解密
1. 介绍 在我们日常的Java开发中,免不了和其他系统的业务交互,或者微服务之间的接口调用 如果我们想保证数据传输的安全,对接口出参加密,入参解密。 但是不想写重复代码,我们可以提供一个通用starter,提…...
大公司为什么禁止SpringBoot项目使用Tomcat?
前言 在SpringBoot框架中,我们使用最多的是Tomcat,这是SpringBoot默认的容器技术,而且是内嵌式的Tomcat。同时,SpringBoot也支持Undertow容器,我们可以很方便的用Undertow替换Tomcat,而Undertow的性能和内…...

2023年第十三届MathorCup高校数学建模挑战赛|A题|量子计算机在信用评分卡组合优化中的应用
目录 题目详情 最终收入 贷款利息收入 - 坏账损失 赛题说明 1:流程简化及示例 赛题说明 2:QUBO 模型简介 赛题说明 3:赛题数据 问题 题目详情 在银行信用卡或相关的贷款等业务中,对客户授信之前,需…...
linux下搭建Hbase分布式数据库
文章目录 Hbase概念1.安装Hbase1.jdk的配置2.安装hbase 2.启动和操作1.启动服务2 **web-ui访问地址:http://node01:16010/master-status** 3.简单的操作1.连接 HBase2.帮助命令3.创建一张表 create a table4.使用查看表是否存在5.describe 查看表描述6.put命令插入数据到表7. s…...

unity,射手游戏
文章目录 介绍一,制作玩家具体函数脚本PlayerCharacter三、 制作玩家控制脚本 PlayerController,调用上面的函数方法四、 制作子弹脚本 shell五、 给玩家挂载脚本六、 制作坦克脚本七、 给坦克添加组件八、 开始游戏,播放动画九、 下载 介绍 …...

摒弃单一变现手段,开拓多元商业模式,破解场景单一APP盈利难题!
工具类APP已成为人们生活、工作中不可或缺的一部分,包括天气服务、搜索、日历等细分领域,在用户中存在巨大的市场需求。但是,这类APP也面临着一些难以避免的问题。 比如功能单一、用户停留时间较短、可替代性强等,这些问题会影响…...
JavaEE-轻松了解网络原理之TCP协议
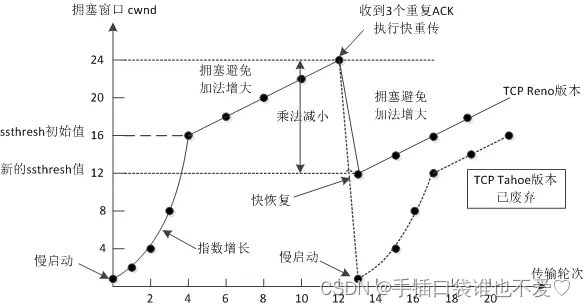
目录 TCP协议TCP协议数据格式TCP原理确认应答超时重传连接管理三次握手四次挥手 滑动窗口流量控制拥塞控制延迟应答捎带应答面向字节流异常问题 TCP协议 TCP,即Transmission Control Protocol,传输控制协议. TCP协议数据格式 16位源端口号与16位目的端…...

终极免费Switch模拟器yuzu:解决电脑玩任天堂游戏的5大痛点
终极免费Switch模拟器yuzu:解决电脑玩任天堂游戏的5大痛点 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在电脑上畅玩Switch游戏却总是遇到各种问题?yuzu模拟器作为全球最受欢迎的开源任…...

深度解析Scarab:空洞骑士模组管理器的专业实现与架构设计
深度解析Scarab:空洞骑士模组管理器的专业实现与架构设计 【免费下载链接】Scarab An installer for Hollow Knight mods written with Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab 空洞骑士模组管理器Scarab为玩家提供了高效、专业的模组…...

基于大语言模型的本地语义搜索工具LLocalSearch部署与应用指南
1. 项目概述:一个能“读懂”你电脑的本地搜索工具 如果你和我一样,电脑里塞满了各种文档、邮件、聊天记录和代码片段,那么“找东西”这件事,绝对能排进日常最耗时的任务前三。传统的文件搜索,比如Windows自带的搜索或者…...

3分钟完成30分钟任务:词达人自动化助手终极指南
3分钟完成30分钟任务:词达人自动化助手终极指南 【免费下载链接】cdr 微信词达人,高正确率,高效简洁。支持班级任务及自选任务 项目地址: https://gitcode.com/gh_mirrors/cd/cdr 你是否厌倦了每周在词达人平台上花费数小时完成枯燥的…...

Google Labs Jules Awesome List:构建与维护高质量开发者资源清单指南
1. 项目概述:一份面向开发者的“Awesome List”清单在开源社区和开发者圈子里,有一个约定俗成的传统:当某个技术领域或工具生态变得足够庞大和复杂时,总会有热心的贡献者站出来,整理一份名为“Awesome List”的清单。这…...

去中心化AI市场BloomBee:技术架构、挑战与开发者实践指南
1. 项目概述:当AI遇见去中心化,BloomBee想解决什么?最近在AI和Web3的交叉领域,一个名为BloomBee的项目引起了我的注意。它的名字很有意思,“Bloom”是开花、繁荣的意思,“Bee”是蜜蜂,合起来像是…...

OpenClaw实战教程:声明式配置驱动的高效数据抓取方案
1. 项目概述:一个关于“OpenClaw”的实战教程 最近在GitHub上看到一个挺有意思的项目,叫“OpenClawTuto”。光看名字,你可能会有点摸不着头脑,这“OpenClaw”到底是个啥?是某种开源机械爪?还是一个代号&…...

KIVI开源工具箱:模块化设计赋能开发者效率提升
1. 项目概述:一个面向开发者的开源工具箱最近在GitHub上闲逛,发现了一个挺有意思的项目,叫KIVI。第一眼看到这个名字,我以为是某种新的UI框架或者设计系统,毕竟“KIVI”听起来有点像是“Kiwi”的变体,容易联…...

柔性3D打印与生物仿生设计:从TPU材料到空气喷涂的完整实践
1. 项目概述:当柔性3D打印遇上生物仿生美学如果你和我一样,玩3D打印玩久了,总会对那些千篇一律的硬质塑料件感到一丝审美疲劳。我们总在追求更高的精度、更强的结构,却常常忽略了材料本身可以带来的、截然不同的体验。直到我开始接…...

基于HalloWing的交互式徽章:传感器融合与事件驱动编程实践
1. 项目概述:当硬件开发遇上节日创意如果你和我一样,是个喜欢在万圣节搞点“技术流”小把戏的硬件爱好者,那么手头有一块Adafruit的HalloWing开发板,绝对能让你的节日装备脱颖而出。这不仅仅是一个简单的微控制器项目,…...