必须要知道的hive调优知识(上)
Hive数据倾斜以及解决方案
1、什么是数据倾斜
数据倾斜主要表现在,map/reduce程序执行时,reduce节点大部分执行完毕,但是有一个或者几个reduce节点运行很慢,导致整个程序的处理时间很长,这是因为某一个key的条数比其他key多很多(有时是百倍或者千倍之多),这条Key所在的reduce节点所处理的数据量比其他节点就大很多,从而导致某几个节点迟迟运行不完。
2、数据倾斜的原因
一些操作有关:
| 关键词 | 情形 | 后果 |
|---|---|---|
| Join | 其中一个表较小,但是key集中 | 分发到某一个或几个Reduce上的数据远高于平均值 |
| 大表与大表,但是分桶的判断字段0值或空值过多 | 这些空值都由一个reduce处理,非常慢 | |
| group by | group by 维度过小,某值的数量过多 | 处理某值的reduce灰常耗时 |
| Count Distinct | 某特殊值过多 | 处理此特殊值的reduce耗时 |
原因归纳:
- key分布不均匀
- 业务数据本身的特性
- 建表时考虑不周
- 某些SQL语句本身就有数据倾斜
现象:
任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成。因为其处理的数据量和其他reduce差异过大。单一reduce的记录数与平均记录数差异过大,通常可能达到3倍甚至更多。 最长时长远大于平均时长。
3、数据倾斜的解决方案
1)参数调节
Map 端部分聚合,相当于Combiner
hive.map.aggr = true
有数据倾斜的时候进行负载均衡,当选项设定为true,生成的查询计划会有两个MR Job。第一个MR Job中,Map 的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MRJob再根据预处理的数据结果按照Group By Key分布到Reduce中(这个过程可以保证相同的Group By Key被分布到同一个Reduce中),最后完成最终的聚合操作。
hive.groupby.skewindata=true
2)SQL语句调节
如何join:
关于驱动表的选取,选用join key分布最均匀的表作为驱动表,做好列裁剪和filter操作,以达到两表做join的时候,数据量相对变小的效果。
大小表Join:
使用map join让小的维度表(1000条以下的记录条数)先进内存。在map端完成reduce。
大表Join大表:
把空值的key变成一个字符串加上随机数,把倾斜的数据分到不同的reduce上,由于null值关联不上,处理后并不影响最终结果。
count distinct大量相同特殊值:
count distinct时,将值为空的情况单独处理,如果是计算count distinct,可以不用处理,直接过滤,在最后结果中加1。如果还有其他计算,需要进行group by,可以先将值为空的记录单独处理,再和其他计算结果进行union。
group by维度过小:
采用sum() group by的方式来替换count(distinct)完成计算。
特殊情况特殊处理:
在业务逻辑优化效果的不大情况下,有些时候是可以将倾斜的数据单独拿出来处理。最后union回去。
4、典型的业务场景
1)空值产生的数据倾斜
场景:如日志中,常会有信息丢失的问题,比如日志中的 user_id,如果取其中的 user_id 和 用户表中的user_id 关联,会碰到数据倾斜的问题。
解决方法一:user_id为空的不参与关联
select * from log a
join users b
on a.user_id is not null
and a.user_id = b.user_id
union all
select * from log a
where a.user_id is null;
解决方法二:赋与空值分新的key值
select *
from log a
left outer join users b
on case when a.user_id is null then concat(‘hive’,rand() ) else a.user_id end =
b.user_id;
结论:
方法2比方法1效率更好,不但io少了,而且作业数也少了。解决方法一中log读取两次,jobs是2。解决方法二job数是1。这个优化适合无效id (比如 -99 , ’’, null 等) 产生的倾斜问题。把空值的key变成一个字符串加上随机数,就能把倾斜的数据分到不同的reduce上,解决数据倾斜问题。
2)不同数据类型关联产生数据倾斜
场景:用户表中user_id字段为int,log表中user_id字段既有string类型也有int类型。当按照user_id进行两个表的Join操作时,默认的Hash操作会按int型的id来进行分配,这样会导致所有string类型id的记录都分配到一个Reducer中。
解决方法:把数字类型转换成字符串类型
select * from users a
left outer join logs b
on a.usr_id = cast(b.user_id as string);
3)小表不小不大,怎么用 map join 解决倾斜问题
使用map join解决小表(记录数少)关联大表的数据倾斜问题,这个方法使用的频率非常高,但如果小表很大,大到map join会出现bug或异常,这时就需要特别的处理。
例子:
select * from log a
left outer join users b
on a.user_id = b.user_id;
users表有600w+的记录,把users分发到所有的map上也是个不小的开销,而且map join不支持这么大的小表。如果用普通的join,又会碰到数据倾斜的问题。
解决方法:
select /*+mapjoin(x)*/* from log aleft outer join (select /*+mapjoin(c)*/d.*from ( select distinct user_id from log ) cjoin users don c.user_id = d.user_id) x
on a.user_id = b.user_id;
假如,log里user_id有上百万个,这就又回到原来map join问题。所幸,每日的会员uv不会太多,有交易的会员不会太多,有点击的会员不会太多,有佣金的会员不会太多等等。所以这个方法能解决很多场景下的数据倾斜问题。
Hive数据同步到HDFS,小文件问题怎么解决的?
我们先考虑小文件的产生和影响:
1)哪里会产生小文件
- 源数据本身有很多小文件
- 动态分区会产生大量小文件
- reduce个数越多, 小文件越多
- 按分区插入数据的时候会产生大量的小文件, 文件个数 = maptask个数 * 分区数
2)小文件太多造成的影响
- 从Hive的角度看,小文件会开很多map,一个map开一个JVM去执行,所以这些任务的初始化,启动,执行会浪费大量的资源,严重影响性能。
- HDFS存储太多小文件, 会导致namenode元数据特别大, 占用太多内存, 制约了集群的扩展
小文件解决方案:
方法一:通过调整参数进行合并
1)在Map输入的时候, 把小文件合并
-- 老版本 每个Map最大输入大小,决定合并后的文件数
set mapred.max.split.size=256000000;
-- hadoop2.x 每个Map最大输入大小,决定合并后的文件数
set mapreduce.input.fileinputformat.split.maxsize=2048000000;(2G)
-- 一个节点上split的至少的大小 ,决定了多个data node上的文件是否需要合并
set mapred.min.split.size.per.node=100000000;
-- 一个交换机下split的至少的大小,决定了多个交换机上的文件是否需要合并
set mapred.min.split.size.per.rack=100000000;
-- 执行Map前进行小文件合并开关开启:true
set hive.hadoop.supports.splittable.combineinputformat = true;
-- 执行Map前进行小文件合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
2)在Reduce输出的时候, 把小文件合并
-- (和下面的2选1)在map-only job后合并文件,默认true
set hive.merge.mapfiles = true;
-- (和下面的2选1)在map-reduce job后合并文件,默认false
set hive.merge.mapredfiles = true;
-- 合并后每个文件的大小,默认256000000
set hive.merge.size.per.task = 256000000;
-- 平均文件大小,是决定是否执行合并操作的阈值,默认16000000
set hive.merge.smallfiles.avgsize = 100000000;
方法二:(Hive sql 执行完创建小文件数过多)针对按分区插入数据的时候产生大量的小文件的问题,可以使用DISTRIBUTE BY rand() 将数据随机分配给Reduce,这样可以使得每个Reduce处理的数据大体一致。
-- 设置每个reducer处理的大小为5个G
set hive.exec.reducers.bytes.per.reducer=5120000000;
-- 使用distribute by rand()将数据随机分配给reduce, 避免出现有的文件特别大, 有的文件特别小
insert overwrite table test partition(dt)
select * from iteblog_tmp
DISTRIBUTE BY rand();
方法三:使用Sequencefile作为表存储格式,不要用textfile,在一定程度上可以减少小文件
方法四:使用hadoop的archive归档
-- 用来控制归档是否可用
set hive.archive.enabled=true;
-- 通知Hive在创建归档时是否可以设置父目录
set hive.archive.har.parentdir.settable=true;
-- 控制需要归档文件的大小
set har.partfile.size=1099511627776;
-- 使用以下命令进行归档
ALTER TABLE srcpart ARCHIVE PARTITION(ds='2008-04-08', hr='12');
-- 对已归档的分区恢复为原文件
ALTER TABLE srcpart UNARCHIVE PARTITION(ds='2008-04-08', hr='12');
-- 注意,归档的分区不能够INSERT OVERWRITE,必须先unarchive
Hadoop自带的三种小文件处理方案
-
Hadoop Archive
Hadoop Archive或者HAR,是一个高效地将小文件放入HDFS块中的文件存档工具,它能够将多个小文件打包成一个HAR文件,这样在减少namenode内存使用的同时,仍然允许对文件进行透明的访问。 -
Sequence file
sequence file由一系列的二进制key/value组成,如果为key小文件名,value为文件内容,则可以将大批小文件合并成一个大文件。 -
CombineFileInputFormat
它是一种新的inputformat,用于将多个文件合并成一个单独的split,另外,它会考虑数据的存储位置。
hive 压缩
压缩Map的输出,这样做有两个好处
- a)压缩是在内存中进行,所以写入map本地磁盘的数据就会变小,大大减少了本地IO次数
- b) Reduce从每个map节点copy数据,也会明显降低网络传输的时间
# 打开job最终输出压缩的开关,设置之后必须设置下面这行,否则还是没有压缩效果
set hive.exec.compress.output=true;
# 设置压缩类型
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
# 大文件压缩仍然会耗时,而且影响mapper并行(mapper并行和文件的个数有关),
# 这个设置,使大的文件可以分割成小文件进行压缩
set mapred.output.compression.type=BLOCK;
# 中间数据map压缩,不影响最终结果。但是job中间数据输出要写在硬盘并通过网络传输到reduce,
# 传送数据量变小,因为shuffle sort(混洗排序)数据被压缩了。
set hive.exec.compress.intermediate=true;
# 为中间数据配置压锁编解码器 ,通常配置Snappy更好。
set mapred.map.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
合并分区小文件操作思路
1.创建备份表
create test.tb_name_bak like test.tb_name;

2.设置合并的相关参数并将原表的数据插入备份表中
#任务结束时合并小文件
SET hive.merge.mapfiles = true;
SET hive.merge.mapredfiles = true;
#合并文件大小256M
SET hive.merge.size.per.task = 256000000;
#当输出文件平均大小小于该值时,启用文件合并
SET hive.merge.smallfiles.avgsize = 134217728;
#压缩输出
SET hive.exec.compress.output = true;
#压缩方式:snappy
SET parquet.compression = snappy;
#默认值为srticat,nonstrict模式表示允许所有分区字段都可以使用动态分区
SET hive.exec.dynamic.partition.mode = nonstrict;
#使用动态分区
SET hive.exec.dynamic.partition = true;
#在所有执行MR的节点上,共可以创建多少个动态分区
SET hive.exec.max.dynamic.partitions=3000;
#在执行MR的单节点上,最大可以创建多少个分区
SET hive.exec.max.dynamic.partitions.pernode=500;
insert overwrite table test.tb_name_bak partition(date_str) select * from test.tb_name;
3.检查备份表和原表数据是否一致,若一致,则进行下一步操作
SELECT count(*) FROM test.tb_name;
SELECT count(*) FROM test.tb_name_bak;
数据转换操作有两种方式:
1.操作表的方式
- 删除原表
drop table test.tb_name;
- 将备份表重命名为原表
alter table test.tb_name_bak rename to test.tb_name;
2.操作hdfs文件方式
- 将原表hdfs路径下的文件移到某个备份目录,确认无误之后,再将文件移动回收站
- 将备份表hdfs路径下的文件移到原表目录下
相关文章:
必须要知道的hive调优知识(上)
Hive数据倾斜以及解决方案 1、什么是数据倾斜 数据倾斜主要表现在,map/reduce程序执行时,reduce节点大部分执行完毕,但是有一个或者几个reduce节点运行很慢,导致整个程序的处理时间很长,这是因为某一个key的条数比其…...

什么是Cache Aside Pattern与延迟双删
Cache Aside Pattern是一种常用的缓存设计模式,用于在应用程序中使用缓存提高系统性能的同时,避免缓存与数据库数据不一致的情况出现。延迟双删是Cache Aside Pattern的一种优化,可以进一步提高系统性能。 以下是关于Cache Aside Pattern和延…...
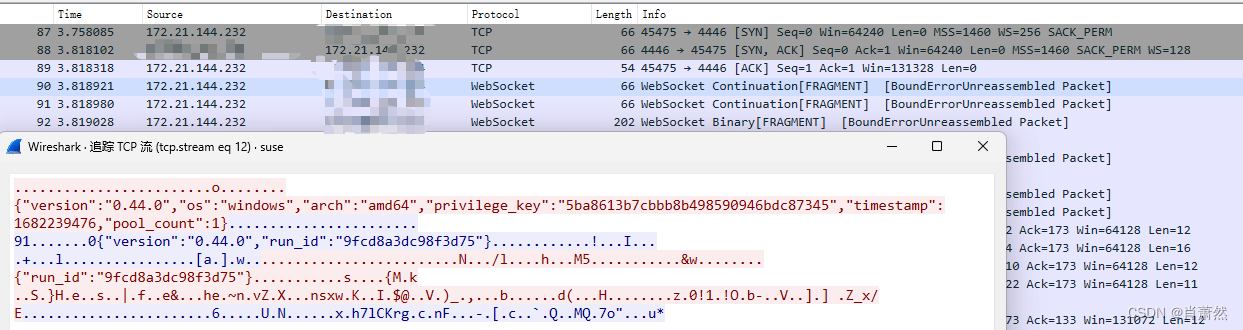
frp 流量特征
frp 流量特征 非常明显的明文流量特征...
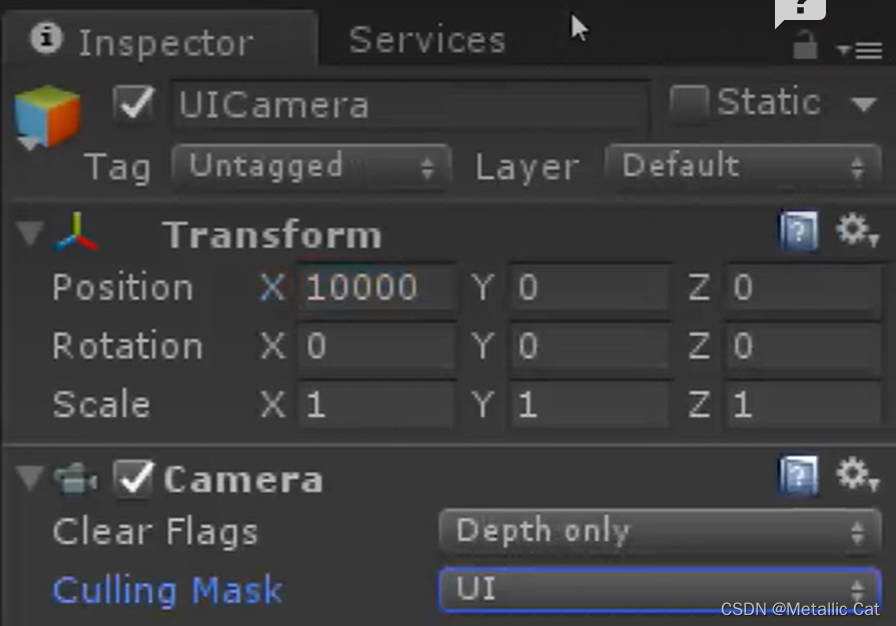
Unity --- UGUI(Unity Graphical user interface)--- Canvas画布
1.UI --- User Interface --- 使用者与机器之间的交互界面 1.所谓的自适应系统指的是分辨率的适应: 比如在一个分辨率下做的UI放到另一个分辨率下显示时,如果没有自适应系统的话就会导致UI过大,过小,被辟成一半等等情况ÿ…...
c++积累6-内联函数
1、说明 内联函数是c为提高程序运行速度所做的一项改进。 2、常规函数运行 编译的可执行程序:由一组机器语言指令组成。 程序执行: 1、操作系统将这些指令载入到内存,每条指令都有一个特定的内存地址 2、计算机逐步执行这些指令 3、如果有…...

ESP32学习笔记13-MCPWM主要用于无刷电机驱动
16.MCPWM 16.1概述 ESP32 有两个 MCPWM 单元,可用于控制不同类型的电机。每个单元都有三对PWM输出 每个 A/B 对可由三个定时器定时器 0、1 和 2 中的任何一个计时。 同一定时器可用于为多对PWM输出提供时钟。 每个单元还能够收集输入,例如,检测电机过电流或过电压,以及获得…...

MyBatis-plu 和 JPA 对比
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 MyBatis-plu 和 JPA 前言一、说下相同点二、差异点一、从实现来说:CURD实现方式不一样二、分页上三、雪花id四、伪删除五、子类排除父类的字段 总结 前言 提示&…...

一文详解Python中多进程和进程池的使用方法
这篇文章将介绍Python中多进程和进程池的使用方法,并提供一些实用的案例供大家参考,文中的示例代码讲解详细,感兴趣的小伙伴可以了解一下 目录 Python是一种高级编程语言,它在众多编程语言中,拥有极高的人气和使用率。…...

前端部署发布项目后,如何通知用户刷新页面、清除缓存
以下只是一些思路,有更好的实现方式可以留言一起交流学习 方式一:纯前端 在每次发布前端时,使用webpack构建命令生成一个json文件,json中写个随机生成的一个字符串(比如时间戳),每次打包程序都…...

项目上线|慕尚集团携手盖雅工场,用数字化推动人效持续提升
过去十年,中国零售业以前所未有的速度被颠覆、被重塑,数字化则是其中重要的推动要素。 随着数字化转型的深入,零售企业的数字化不再局限于布局线上渠道,且更关乎其背后企业核心运营能力的全链路数字化改造。而贯穿于运营全链路的…...

Java重载 与封装、继承
方法重载 在同一个类中,出现了方法名相同,参数不同的方法时 ,我们叫方法重载 作用:根据不同参数,选择不同方法 实例 public static void main(String[] args){public int add(int a,int b){return ab;}public double…...

sed正则表达式替换字符方法
在 Linux 命令行中,可以使用 sed 命令来替换指定文件中的指定字符。具体方法如下: sed -i s/<old_string>/<new_string>/g <filename>其中,<old_string> 表示要被替换的字符串,<new_string> 表示替…...

不讲废话普通人了解 ChatGPT——基础篇第一课
wx供重浩:创享日记 获取更多内容 文章目录 前言什么是 ChatGPT它是如何工作的ChatGPT 和其它机器人有什么不同 前言 不知道大家在第一次会使用 ChatGPT 并尝试和他对话时有没有感到震惊。当ChatGPT首次推出时,我立即被它的功能所吸引。 曾经在遇到繁杂…...

MATLAB计算气象干旱指标:SAPEI
MATLAB计算干旱指标:SAPEI 标准化前降水蒸散发指数(Standardized Antecedent Precipitation Evapotranspiration Index, SAPEI)1 指数简介1.1 指数计算原理步骤1:计算潜在蒸散发(potential evapotranspiration, PET)步骤2:计算降水和PET的日差1.2 数据资料1.3 拟合分布的…...

GPT对SaaS领域有什么影响?
GPT火了,Chat GPT真的火了。 突然之间,所有人都在讨论AI,最初的访客是程序员、工程师、AI从业者,从早高峰写字楼电梯里讨论声,到村里大爷们的饭后谈资,路过的狗子都要和它讨论两句GPT的程度。 革命的前夜…...
和zero_grad()在PyTorch中代表什么意思)
backward()和zero_grad()在PyTorch中代表什么意思
文章目录 问:backward()和zero_grad()是什么意思?backward()zero_grad() 问:求导和梯度什么关系问:backward不是求导吗,和梯度有什么关系(哈哈哈哈)问:你可以举一个简单的例子吗问&a…...
C++多线程编程(一) thread类初窥
多线程编程使我们的程序能够同时执行多项任务。 在C11以前,C没有标准的多线程库,只能使用C语言中的pthread,在C11之后,C标准库中增加了thread类用于多线程编程。thread类其实是对pthread的封装,不过更加好用ÿ…...

Qt QVector 详解:从底层原理到高级用法
目录标题 引言:QVector的重要性与简介QVector的常用接口QVector和std::Vector迭代器:遍历QVector 中的元素(Iterators: Traversing Elements in QVector)常规索引遍历基于范围的for循环(C11及以上)使用STL样…...
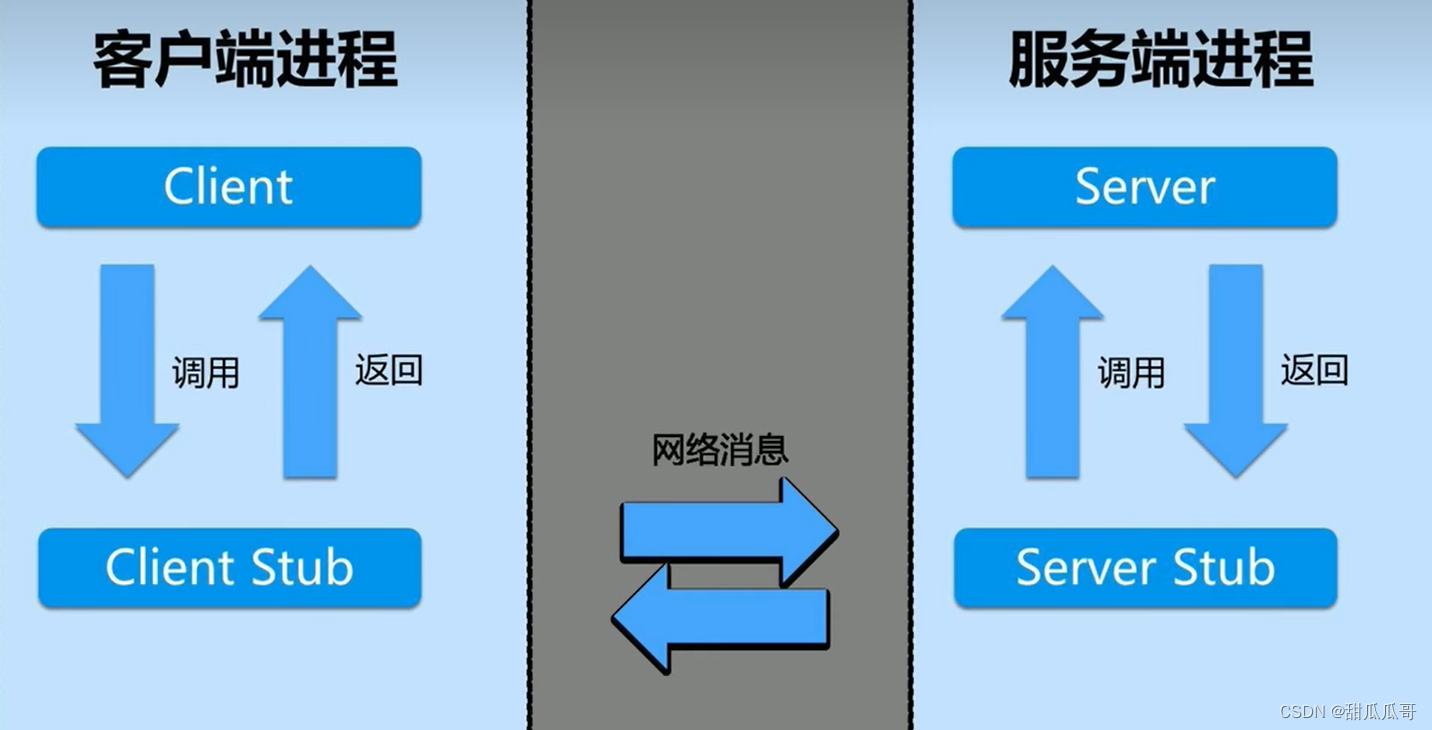
快速弄懂RPC
快速弄懂RPC 常见的远程通信方式远程调用RPC协议RPC的运用场景和优势 常见的远程通信方式 基于REST架构的HTTP协议以及基于RPC协议的RPC框架。 远程调用 是指跨进程的功能调用。 跨进程可以理解为一个计算机节点的多个进程或者多个计算机节点的多个进程。 RPC协议 远程过…...

ONVIF协议介绍
目录标题 一、 ONVIF协议简介(Introduction to ONVIF Protocol)1.1 ONVIF的发展历程(The Evolution of ONVIF)1.2 ONVIF的主要作用与优势(The Main Functions and Advantages of ONVIF) 二、 ONVIF协议的底…...

如何为你的智能体项目配置 Taotoken 作为 OpenAI 兼容后端
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何为你的智能体项目配置 Taotoken 作为 OpenAI 兼容后端 基础教程类,面向希望将 Taotoken 作为大模型服务提供商接入…...

五分钟完成python脚本配置直连taotoken多模型服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 五分钟完成 Python 脚本配置直连 Taotoken 多模型服务 基础教程类,面向刚接触 Taotoken 的 Python 开发者,…...

保姆级教程:手把手教你用‘版本降级法’搞定PyTorch 1.9.1 + CUDA 11.1环境搭建
深度学习环境搭建实战:PyTorch与CUDA版本兼容性终极指南 引言 当你第一次尝试在Windows系统上搭建PyTorch深度学习环境时,可能会遇到各种令人困惑的错误信息。其中最常见的就是"no matching distribution found"这类版本兼容性问题。本文将以一…...

HPM5361EVK深度测评:480MHz RISC-V MCU性能、外设与低功耗实战
1. 项目概述与核心价值拿到一块新的开发板,尤其是基于RISC-V这类新兴架构的MCU开发板,很多工程师的第一反应往往是:跑个分,点个灯。这没错,但如果我们止步于此,就错过了深入理解一块芯片和其生态潜力的机会…...

AI教材写作神器!低查重AI工具,一键生成符合标准的专业教材!
许多教科书编写者常常会面临这样的困扰:在认真打磨正文内容的同时,配套资源的缺乏却影响到了整体的教学效果。设计有难度的课后练习题时,脑海中却没有多样的创意;想要制作生动的教学课件,却苦于缺乏技术支持࿱…...

Coding爆发打破「AI泡沫论」,MiniMax能否卡位下一个Google?
【Coding爆发打破「AI泡沫论」】 Coding的爆发,彻底断绝了「AI泡沫论」,这已成为共识。阿里财报显示MaaS ARR超过80亿元,年底还有望再涨三倍以上,意味着只有投入没有回报的周期已过去,能开始盈利,大小玩家都…...

2026年阿里云部署OpenClaw/Hermes Agent 配置Token Plan怎么快速上手?看这
2026年阿里云部署OpenClaw/Hermes Agent 配置Token Plan怎么快速上手?看这。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token …...

终极R3nzSkin换肤工具:英雄联盟国服免费皮肤自定义完整指南
终极R3nzSkin换肤工具:英雄联盟国服免费皮肤自定义完整指南 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 你是否曾经羡慕别人拥有稀有皮肤…...

Harness Engineering 讲解
Harness 工程过去很长一段时间里,大家一提到“大模型怎么用好”,第一反应往往是:Prompt 怎么写? 于是,Prompt Engineering 成了很多人学习大模型的第一站。我们学习如何提问,如何给角色,如何写任…...

30ms低延迟投屏终极指南:用QtScrcpy实现专业级手游直播
30ms低延迟投屏终极指南:用QtScrcpy实现专业级手游直播 【免费下载链接】QtScrcpy Android实时投屏软件,此应用程序提供USB(或通过TCP/IP)连接的Android设备的显示和控制。它不需要任何root访问权限 项目地址: https://gitcode.com/barry-ran/QtScrcpy…...