【流畅的Python学习笔记】2023.4.22
此栏目记录我学习《流畅的Python》一书的学习笔记,这是一个自用笔记,所以写的比较随意
元组
元组其实是对数据的记录:元组中的每个元素都存放了记录中一个字段的数据,外加这个字段的位置。简单试试元组的特性:
chars_tuple = ("a", "b", "c", "d", "e", "f")
# 元组拆包
a, b, c, d, e, f = chars_tuple
print(a)
print(chars_tuple[0])
test_tuple = ((1, 2), (3, 4))
print(test_tuple[0][1])
print(chars_tuple[1:])
运行结果:

还可以用*将元组拆包成函数的参数
# 用*将元组拆包,作为函数的参数
number_tuple = (1, 2)
print(test_fun(*number_tuple))
运行结果:
3
元组拆包还可以让一个函数可以用元组的形式返回多个值,然后调用函数的代码就能轻松地接受这些返回值。
比如 os.path.split() 函数就会返回以路径和最后一个文件名组成的元组 (path, last_part)
import os
file = os.path.split('/home/luciano/.ssh/idrsa.pub')
print(file)
运行结果:
(‘/home/luciano/.ssh’, ‘idrsa.pub’)
挺有意思,我写个简单的例子试试
def return_a_tuple(a, b, c, d):result = (a + b, c + d)return resultprint(return_a_tuple(1, 1, 2, 2))运行结果:
(2, 4)
函数用 *args 来获取不确定数量的参数
a, b, *rest = range(5)
print(a, b, rest)运行结果:
0 1 [2, 3, 4]
在平行赋值中,* 前缀只能用在一个变量名前面,但是这个变量可以出现在赋值表达式的任意位置
a, *rest, b = range(5)
print(a, b, rest)
运行结果:
0 4 [1, 2, 3]
嵌套元组拆包
用嵌套元组拆包来打印信息
Python格式化输出
在 Python 中,格式化输出是通过字符串中的格式化字段来实现的。格式化字段以 { } 作为界定符,其中可以包括占位符和格式化标识符。常用的格式化字符串方法包括:
字符串格式化符号 ‘%’
格式化块的语法为 “%[width][.precision]specifier”,它可以用于整数、浮点数、字符串等数据类型的格式化输出。其中,width 表示输出宽度,precision 表示浮点数输出的小数位数,specifier 表示数据类型、输出格式等。例如:
name = 'Tom'
age = 25
print('My name is %s, and I am %d years old.' % (name, age))
输出结果:
My name is Tom, and I am 25 years old.
字符串的 format() 方法
可以使用 format() 方法来对字符串进行格式化输出。可以在字符串中使用占位符 {} 来表示需要替换的内容,然后通过 format() 方法传入需要替换的值。例如:
name = 'Tom'
age = 25
print('My name is {}, and I am {} years old.'.format(name, age))
输出结果:
My name is Tom, and I am 25 years old.
f-string
f-string 是从 Python3.6 开始引入的一种字符串格式化方法。它的格式为 f’字符串 {变量1} {变量2}'。通过在字符串前添加 ‘f’,然后在花括号内添加变量的名称,就可以在字符串内进行格式化输出。例如:
name = 'Tom'
age = 25
print(f'My name is {name}, and I am {age} years old.')
输出结果:
My name is Tom, and I am 25 years old.
在使用 f-string 格式化输出时,可以在花括号中使用表达式等 Python 的语法。同时,也可以使用限定符来控制输出格式,例如:
amount = 1234.5678
print(f'{amount:.2f}') # 输出两位小数
输出结果:
1234.57
模仿书中示例写一个拆包
people_info = [(1, "Tom", 25, ("A", 1)),(2, "Jack", 26, ("B", 2)),(3, "Mary", 39, ("C", 3))]# 各个元组元素的字符串长度最大值
l1_max = 0
l2_max = 0
l3_max = 0
l4_max = 0
# 一次性找到每个元组的元素拼成字符串的最大长度
for x1, x2, x3, (x4, x5) in people_info:x1_len = len(str(x1))x2_len = len(x2)x3_len = len(str(x3))x4_x5_len = len(str(x5)) + len(x4)if l1_max < x1_len:l1_max = x1_lenif l2_max < x2_len:l2_max = x2_lenif l3_max < x3_len:l3_max = x3_lenif l4_max < x4_x5_len:l4_max = x4_x5_len
# 比较表头和表中的字符串最大长度哪个大,哪个大就用哪个
l1_max = max(l1_max, len("ID"))
l2_max = max(l2_max, len("Name"))
l3_max = max(l3_max, len("Age"))
l4_max = max(l4_max, len("Address"))
# 打印表头
print("{:^{}s}|{:^{}s}|{:^{}s}|{:^{}s}".format("ID", l1_max, "Name", l2_max, "Age", l3_max, "Address", l4_max))
# 嵌套元组拆包格式化输出
for x1, x2, x3, (x4, x5) in people_info:print("{:^{}s}|{:^{}s}|{:^{}s}|{:^{}s}".format(str(x1), l1_max,x2, l2_max,str(x3), l3_max,x4 + str(x5), l4_max))
输出结果:

之前的namedtuple是具名元组,就是有名字的元组,可以当个简单的“类”,collections.namedtuple 是一个工厂函数,它可以用来构建一个带字段名的元组和一个有名字的类——这个带名字的类对调试程序有很大帮助。
元组和列表的具体方法和属性区别
| 方法 | 列表 (是否具有) | 元组 (是否具有) | 功能 |
|---|---|---|---|
| s.__add__(s2) | √ | √ | s + s2,拼接 |
| s.__iadd__(s2) | √ | × | s += s2,就地拼接 |
| s.append(e) | √ | × | 在尾部添加一个新元素 |
| s.clear() | √ | × | 删除所有元素 |
| s.__contains__(e) | √ | √ | s 是否包含 e |
| s.copy() | √ | × | 列表的浅复制 |
| s.count(e) | √ | √ | e 在 s 中出现的次数 |
| s.__delitem__(p) | √ | × | 把位于 p 的元素删除 |
| s.extend(it) | √ | × | 把可迭代对象 it 追加给 s |
| s.__getitem__(p) | √ | √ | s[p],获取下标为 p 的元素 |
| s.__getnewargs__() | × | √ | 在 pickle 中支持更加优化的序列化 |
| s.index(e) | √ | √ | 在 s 中找到元素 e 第一次出现的位置 |
| s.insert(p, e) | √ | × | 在下标 p 对应的元素之前插入元素 e |
| s.__iter__() | √ | √ | 获取 s 的迭代器 |
| s.__len__() | √ | √ | len(s),元素的数量 |
| s.__mul__(n) | √ | √ | s * n,n 个 s 的重复拼接 |
| s.__imul__(n) | √ | × | s *= n,就地重复拼接 |
| s.__rmul__(n) | √ | √ | n * s,反向拼接 |
| s.pop([p]) | √ | × | 删除最后或者是(可选的)位于 p 的元素,并返回它的值 |
| s.remove(e) | √ | × | 删除 s 中的第一次出现的 e |
| s.reverse() | √ | × | 就地把 s 的元素倒序排列 |
| s.__reversed__() | √ | × | 返回 s 的倒序迭代器 |
| s.__setitem__(p, e) | √ | × | s[p] = e,把元素 e 放在位置 p,替代已经在那个位置的元素 |
| s.sort([key], [reverse]) | √ | × | 就地对 s 中的元素进行排序,可选的参数有键(key)和是否倒序(reverse) |
试试上述操作:
先从列表开始,
# 列表的基本操作
import picklea = [1, 2, 3]
print("a=" + str(a))
b = [4, 5, 6]
print("b=" + str(b))
print()
# __add__,拼接
print("__add__拼接")
print("a+b:a+b=" + str(a + b))
print()
# __iadd__,就地拼接
print("__iadd__就地拼接")
print("a+=b:", end="")
a += b
print("a=" + str(a))
print()
# append,在尾部添加一个新元素
print("append,在尾部添加一个新元素")
a.append(7)
print("a.append(7):a=" + str(a))
print()
# clear,删除所有元素
print("clear,删除所有元素")
a.clear()
print("a.clear():a=" + str(a))
print()
# __contaions__ 是否包含
print("__contaions__ 是否包含")
print("b=" + str(b) + ", 7 in b:" + str(7 in b))
print("b=" + str(b) + ", 6 in b:" + str(6 in b))
print()
# copy,列表浅拷贝
print("copy,列表浅拷贝")
c = [0]
print("c=" + str(c))
c = b.copy()
print("c=b.copy(): c=" + str(c))
print()
# count(e),统计e在列表中出现的次数
print("count(e),统计e在列表中出现的次数")
d = [1, 1, 1, 1, 2, 2, 3]
print("d=" + str(d))
print("d.count(1):" + str(d.count(1)))
print()
# del(-1),删除末尾元素
print("del(-1),删除末尾元素")
print("d=" + str(d))
del (d[-1])
print("del(a[-1]),d=" + str(d))
print()
# extend(it),把可迭代对象it追加s
print("extend(it),把可迭代对象it追加s")
f = (6, 7, 8)
print("元组f=" + str(f))
print("列表d=" + str(d))
d.extend(f)
print("d.extend(f):d=" + str(d))
print()
# __getitem__,获取下标为p的元素
print("__getitem__,获取下标为p的元素")
print("d=" + str(d))
print("d[6]=" + str(d[6]))
print()
# 在 pickle 中支持更加优化的序列化
# pickle提供了一个简单的持久化功能。可以将对象以文件的形式存放在磁盘上。
print("在 pickle 中支持更加优化的序列化")
print("创建文件test.txt")
f = open('test.txt', 'wb')
print("d=" + str(d))
print("将列表b序列化为二进制对象写入文件test.txt")
# 将 python 对象转换(序列化)为字节(二进制)对象。
pickle.dump(d, f, 0)
f.close()
print("读取文件test.txt")
f = open('test.txt', 'rb')
print("从文件test.txt中将二进制对象读取(反序列化)为 python 对象x")
x = pickle.load(f)
f.close()
print("x=" + str(x))
print()
# index(e),找到列表中元素e第一次出现的位置
print("index(e),找到列表中元素e第一次出现的位置")
print("d=" + str(d))
print("d.index(2):" + str(d.index(2)))
print()
# insert(p,e),在下标p对应的元素插入元素e
print("insert(p,e),在下标p对应的元素插入元素e")
print("d=" + str(d))
d.insert(2, 100)
print("d.insert(100,2),d=" + str(d))
print()
# __iter__(),获取迭代器
print("__iter__(),获取迭代器")
print("d=" + str(d))
print("遍历迭代d:")
for item in d:print(item)
print()
# __len__,元素的数量
print("__len__元素的数量")
print("d=" + str(d))
print("len(d):" + str(len(d)))
print()
# __mul__,n个元素重复拼接
print("__mul__,n个元素重复拼接")
print("d=" + str(d))
x = d * 3
print("x=d*3:x=" + str(x))
print()
# __imul__,就地重复拼接
print("__imul__,就地重复拼接")
print("b=" + str(b))
b *= 3
print("b *= 3:b=" + str(b))
print()
# __rmul__,n * s,反向拼接
print("__rmul__,n * s,反向拼接")
f = [1, 2, 3]
print("f=" + str(f))
q = 3 * f
print("q = 3 * f:q=" + str(q))
print()
# pop,删除最后或者是(可选的)位于 p 的元素,并返回它的值
print("pop,删除最后或者是(可选的)位于 p 的元素,并返回它的值")
print("f=" + str(f))
f.pop()
print("f.pop():f=" + str(f))
print()
# remove(e),删除第一次出现的e
print("remove(e),删除第一次出现的e")
print("q=" + str(q))
q.remove(2)
print("q.remove(2):q=" + str(q))
print()
# reverse,就地把 s 的元素倒序排列
print("reverse,就地把 s 的元素倒序排列")
print("f=" + str(f))
f.reverse()
print("f.reverse():f=" + str(f))
print()
# __reversed__,返回 s 的倒序迭代器
print("__reversed__,返回 s 的倒序迭代器")
print("q=" + str(q))
print("倒序遍历")
for item in reversed(q):print(item)
print()
# __setitem__,s[p] = e,把元素 e 放在位置 p,替代已经在那个位置的元素
print("__setitem__,s[p] = e,把元素 e 放在位置 p,替代已经在那个位置的元素")
print("q=" + str(q))
q[0] = 100
print("q[0]=100,q=" + str(q))
print()
# sort([key], [reverse]), 就地对 s 中的元素进行排序,可选的参数有键(key)和是否倒序(reverse)
print("sort([key], [reverse]), 就地对 s 中的元素进行排序,可选的参数有键(key)和是否倒序(reverse)")
k = [1, 0, 9, 8, 7, 2, 3, 5, 4, 6]
print("k=" + str(k))
k.sort()
print("sort(k):k=" + str(k))# 偶数
def key_func(a):return a % 2# 按偶数排序
k.sort(key=key_func)
print("按偶数排序")
print("k.sort(key=key_func):k=" + str(k))# 按偶数倒着排序
k.sort(key=key_func, reverse=True)
print("按偶数排序")
print("k.sort(key=key_func):k=" + str(k))运行结果:
a=[1, 2, 3]
b=[4, 5, 6]
__add__拼接
a+b:a+b=[1, 2, 3, 4, 5, 6]
__iadd__就地拼接
a+=b:a=[1, 2, 3, 4, 5, 6]
append,在尾部添加一个新元素
a.append(7):a=[1, 2, 3, 4, 5, 6, 7]
clear,删除所有元素
a.clear():a=[]
__contaions__ 是否包含
b=[4, 5, 6], 7 in b:False
b=[4, 5, 6], 6 in b:True
copy,列表浅拷贝
c=[0]
c=b.copy(): c=[4, 5, 6]
count(e),统计e在列表中出现的次数
d=[1, 1, 1, 1, 2, 2, 3]
d.count(1):4
del(-1),删除末尾元素
d=[1, 1, 1, 1, 2, 2, 3]
del(a[-1]),d=[1, 1, 1, 1, 2, 2]
extend(it),把可迭代对象it追加s
元组f=(6, 7, 8)
列表d=[1, 1, 1, 1, 2, 2]
d.extend(f):d=[1, 1, 1, 1, 2, 2, 6, 7, 8]
__getitem__,获取下标为p的元素
d=[1, 1, 1, 1, 2, 2, 6, 7, 8]
d[6]=6
在 pickle 中支持更加优化的序列化
创建文件test.txt
d=[1, 1, 1, 1, 2, 2, 6, 7, 8]
将列表b序列化为二进制对象写入文件test.txt
读取文件test.txt
从文件test.txt中将二进制对象读取(反序列化)为 python 对象x
x=[1, 1, 1, 1, 2, 2, 6, 7, 8]
index(e),找到列表中元素e第一次出现的位置
d=[1, 1, 1, 1, 2, 2, 6, 7, 8]
d.index(2):4
insert(p,e),在下标p对应的元素插入元素e
d=[1, 1, 1, 1, 2, 2, 6, 7, 8]
d.insert(100,2),d=[1, 1, 100, 1, 1, 2, 2, 6, 7, 8]
__iter__(),获取迭代器
d=[1, 1, 100, 1, 1, 2, 2, 6, 7, 8]
遍历迭代d:
1
1
100
1
1
2
2
6
7
8
__len__元素的数量
d=[1, 1, 100, 1, 1, 2, 2, 6, 7, 8]
len(d):10
__mul__,n个元素重复拼接
d=[1, 1, 100, 1, 1, 2, 2, 6, 7, 8]
x=d*3:x=[1, 1, 100, 1, 1, 2, 2, 6, 7, 8, 1, 1, 100, 1, 1, 2, 2, 6, 7, 8, 1, 1, 100, 1, 1, 2, 2, 6, 7, 8]
__imul__,就地重复拼接
b=[4, 5, 6]
b *= 3:b=[4, 5, 6, 4, 5, 6, 4, 5, 6]
__rmul__,n * s,反向拼接
f=[1, 2, 3]
q = 3 * f:q=[1, 2, 3, 1, 2, 3, 1, 2, 3]
pop,删除最后或者是(可选的)位于 p 的元素,并返回它的值
f=[1, 2, 3]
f.pop():f=[1, 2]
remove(e),删除第一次出现的e
q=[1, 2, 3, 1, 2, 3, 1, 2, 3]
q.remove(2):q=[1, 3, 1, 2, 3, 1, 2, 3]
reverse,就地把 s 的元素倒序排列
f=[1, 2]
f.reverse():f=[2, 1]
__reversed__,返回 s 的倒序迭代器
q=[1, 3, 1, 2, 3, 1, 2, 3]
倒序遍历
3
2
1
3
2
1
3
1
__setitem__,s[p] = e,把元素 e 放在位置 p,替代已经在那个位置的元素
q=[1, 3, 1, 2, 3, 1, 2, 3]
q[0]=100,q=[100, 3, 1, 2, 3, 1, 2, 3]
sort([key], [reverse]), 就地对 s 中的元素进行排序,可选的参数有键(key)和是否倒序(reverse)
k=[1, 0, 9, 8, 7, 2, 3, 5, 4, 6]
sort(k):k=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
按偶数排序
k.sort(key=key_func):k=[0, 2, 4, 6, 8, 1, 3, 5, 7, 9]
按偶数排序
k.sort(key=key_func):k=[1, 3, 5, 7, 9, 0, 2, 4, 6, 8]
进程已结束,退出代码0
写个随笔不是写教程,下面就不仔细展开了,直接按我的风格测试一下元组的操作:
# 元组的基本操作
import pickle# 拼接
a = (1, 2, 3)
b = (4, 5, 6)
print(a + b)
print(0 in a + b)
print((a + b).count(1))
print((a + b)[4])
f = open("test1.txt", "wb")
pickle.dump(a + b, f, 0)
f.close()
f = open("test1.txt", "rb")
x = pickle.load(f)
print(x)
print(x.index(2))
for item in x:print(item)
print(len(x))
print(x * 3)
print(3 * x)
运行结果:
(1, 2, 3, 4, 5, 6)
False
1
5
(1, 2, 3, 4, 5, 6)
1
1
2
3
4
5
6
6
(1, 2, 3, 4, 5, 6, 1, 2, 3, 4, 5, 6, 1, 2, 3, 4, 5, 6)
(1, 2, 3, 4, 5, 6, 1, 2, 3, 4, 5, 6, 1, 2, 3, 4, 5, 6)
进程已结束,退出代码0
切片
写几个例子试试:
import numpy as npl = [10, 20, 30, 40, 50, 60]
print(l[:2]) # 在下标为2处切割,保留左侧
print(l[3:]) # 在下标为3处切割,保留右侧
print(l[::2]) # 在整个区间以2为间隔切片
print(l[::-1]) # 在整个区间倒着以1为间隔取(相当于倒序)
print(l[::-2]) # 在整个区间倒着以2位间隔取
print(l[1:5:2]) # 在下标1到4(5是开区间)中以2位间隔取
s1 = slice(0, 5) # 下标切片从0到4(5是开区间)
print(l[s1])
s2 = slice(0, 5, 2) # 下标切片从0到4,以2为分割取
print(l[s2])
s3 = slice(0, None) # [0, 末尾),左闭右开
print(l[s3])
m = [[[1, 2, 3], [4, 5, 6], [7, 8, 9]],[[10, 11, 12], [13, 14, 15], [16, 17, 18]],[[19, 20, 21], [22, 23, 24], [25, 26, 27]]]
m_array = np.array(m)
print(m_array[2, ...]) # 找到下标为2的第一层维度的全部元素
print(m_array[1:2:1]) # 第一层维度下标为1到1(左闭右开区间),间隔为1的
print(m_array[1:2:1, 1:2:1]) # 第一层维度下标为1到1(左闭右开区间),间隔为1的,第二层维度下标从1到2,间隔为1的
print(m_array[1:2:1, 1:2:1, 0:2:2]) # 第一层维度下标为1到1(左闭右开区间),间隔为1的,第二层维度下标从1到2,间隔为1的,第三层维度下标从0到1,间隔为2的# 给切片赋值
print(l)
l[1:3] = [3, 4]
print(l)
# 删除下标0到1
del l[0:2]
print(l)
# 从下标0开始到下标为2结束,以2为间隔赋值
l[0:3:2] = [100, 200]
print(l)
# 把下标从0到1的部分都换成一个元素
l[0:2] = [100000]
print(l)
运行结果:
[10, 20]
[40, 50, 60]
[10, 30, 50]
[60, 50, 40, 30, 20, 10]
[60, 40, 20]
[20, 40]
[10, 20, 30, 40, 50]
[10, 30, 50]
[10, 20, 30, 40, 50, 60]
[[19 20 21]
[22 23 24]
[25 26 27]]
[[[10 11 12]
[13 14 15]
[16 17 18]]]
[[[13 14 15]]]
[[[13]]]
[10, 20, 30, 40, 50, 60]
[10, 3, 4, 40, 50, 60]
[4, 40, 50, 60]
[100, 40, 200, 60]
[100000, 200, 60]
进程已结束,退出代码0
建立由列表组成的列表
# 一个包含 3 个列表的列表
board = [[1] * 3 for i in range(3)]
print(board)
board[0][1] = 0
print(board)
# 如果在 a * n 这个语句中,序列 a 里的元素是对其他可变对象的引用的话,
# 你就需要格外注意了,因为这个式子的结果可能会出乎意料。比如,你想用
# my_list = [[]] * 3 来初始化一个由列表组成的列表,但是你得到的列表里
# 包含的 3 个元素其实是 3 个引用,而且这 3 个引用指向的都是同一个列表。
# 这可能不是你想要的效果。
weird_board = [[2] * 3] * 3
print(weird_board)
weird_board[0][1] = 1
print(weird_board)
运行结果:
[[1, 1, 1], [1, 1, 1], [1, 1, 1]]
[[1, 0, 1], [1, 1, 1], [1, 1, 1]]
[[2, 2, 2], [2, 2, 2], [2, 2, 2]]
[[2, 1, 2], [2, 1, 2], [2, 1, 2]]
序列的增量赋值
不可变序列增量赋值会每次都生成一个新对象,而可变序列则不变对象,对不可变序列进行重复拼接操作的话,效率会很低,因为每次都有一个新对象,而解释器需要把原来对象中的元素先复制到新的对象里,然后再追加新的元素。用变量的ID就能看出来:
l = [1, 2, 3]
print(id(l))
l *= 2
print(id(l))
t = (1, 2, 3)
print(id(t))
t *= 2
print(id(t))
运行结果:
2178472089152
2178472089152
2178472072896
2178469543840
元组的ID变化了
P.S 不要把可变对象放在元组里面
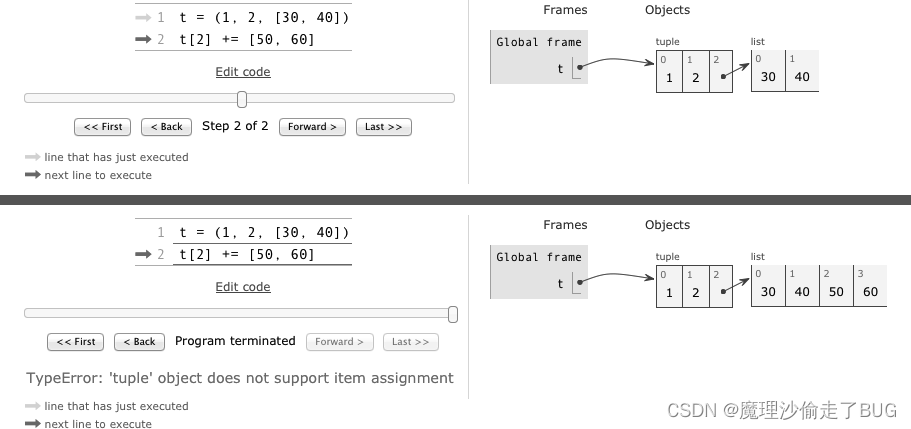
不可变对象中放入可变对象进行增量赋值操作,最后会出错
list.sort方法和内置函数sorted
list.sort 方法会就地排序列表,也就是说不会把原列表复制一份。而是内置函数 sorted,它会新建一个列表作为返回值。
num1 = [3, 1, 2, 6, 4, 5]
print(sorted(num1))
# 倒序排序
print(sorted(num1, reverse=True))
fruits = ['grape', 'raspberry', 'apple', 'banana']
# 按长度排序
print(sorted(fruits, key=len))
运行结果:
[1, 2, 3, 4, 5, 6]
[6, 5, 4, 3, 2, 1]
[‘grape’, ‘apple’, ‘banana’, ‘raspberry’]
相关文章:
【流畅的Python学习笔记】2023.4.22
此栏目记录我学习《流畅的Python》一书的学习笔记,这是一个自用笔记,所以写的比较随意 元组 元组其实是对数据的记录:元组中的每个元素都存放了记录中一个字段的数据,外加这个字段的位置。简单试试元组的特性: char…...

使用django_celery_beat在admin后台配置计划任务
一、依赖包的安装 django中使用celery做异步任务和计划任务最头疼的点就是包之间版本兼容性问题,项目一启动花花报错,大概率都是版本问题。每次都会花很大时间在版本兼容性问题上。本例使用如下版本: Django3.2 celery5.2.7 django-celery-b…...
ARP协议详解
ARP协议详解 文章目录 ARP协议详解ARP协议介绍ARP抓包ARP包解析 ARP协议介绍 ARP(Address Resolution Protocol)是一种用于将网络层地址(如IP地址)转换为数据链路层地址(如MAC地址)的协议,当一…...

不同数量的预测框和Ground Truth框计算IoU
import numpy as npdef calculate_iou(boxes1, boxes2):# 转换为 numpy 数组boxes1 np.array(boxes1)boxes2 np.array(boxes2)# 扩展维度,以便广播计算boxes1 np.expand_dims(boxes1, axis1)boxes2 np.expand_dims(boxes2, axis0)# 计算两组框的交集坐标范围x_m…...
偏好强化学习概述
文章目录 为什么需要了解偏好强化学习什么是偏好强化学习基于偏好的马尔科夫决策过程(Markov decision processes with preferences,MDPP) 反馈类型分类学习算法分类近似策略分布(Approximating the Policy Distribution)比较和排序策略(Comp…...

苹果笔到底有没有必要买?苹果平板电容笔排行榜
事实上,Apple Pencil与市场上普遍存在的电容笔最大的区别,就是两者的重量以及所具有的压感都互不相同。但是,苹果原有的电容笔因其昂贵的价格而逐步被平替电容笔所替代,而平替电容笔所具备的各种性能也在逐步提高。接下来…...
learn_C_deep_6 (布尔类型、布尔与“零值“、浮点型与“零值“、指针与“零值“的比较)
目录 语句和表达式的概念 if语句的多种语法结构 注释的便捷方法(环境vs) if语句执行的过程 逻辑与&& 逻辑或|| 运算关系的顺序 else的匹配原则 C语言有没有布尔类型 C99标准 sizeof(bool)的值为多少? _Bool原码 BOOL…...
JavaScript日期库之date-fn.js
用官网的话来说,date-fn.js 就是一个现代 JavaScript 日期实用程序库,date-fns 为在浏览器和 Node.js 中操作 JavaScript 日期提供了最全面、但最简单和一致的工具集。那实际用起来像它说的那么神奇呢,下面就一起来看看吧。 安装 安装的话就…...

五一假期出游攻略【诗与远方】
原文在:PUSDN 可以导入作为模板引用。 五一旅行计划 假期倒计时 [该类型的内容暂不支持下载] 本次目标:五一旅行计划【画饼版】 前言 任何一个地方,一个城市,都有可观赏的地方,如果没去过邢台的,建议五一去…...
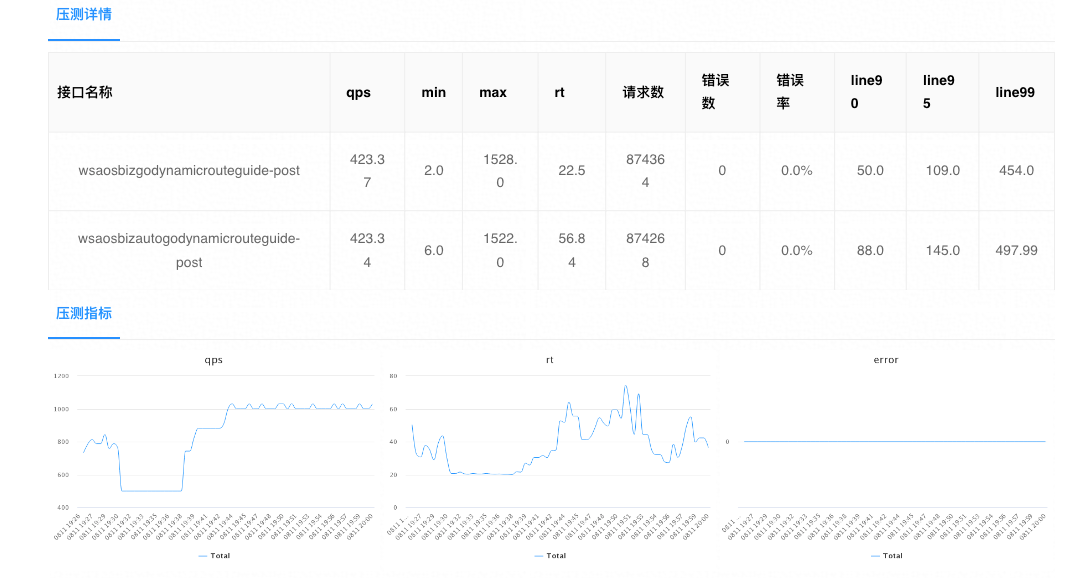
怎样正确做web应用的压力测试?
web应用,通俗来讲就是一个网站,主要依托于浏览器实现其功能。 提到压力测试,我们想到的是服务端压力测试,其实这是片面的,完整的压力测试包含服务端压力测试和前端压力测试。 下文将从以下几部分内容展开:…...

Hibernate的持久化类
Hibernate是一个开源的ORM(对象关系映射)框架,用于将Java程序中的对象映射到数据库中的关系型数据。在Hibernate中,持久化类是用来映射Java对象和关系型数据库表的类。 编写Hibernate持久化类需要遵循以下规则: 持久…...
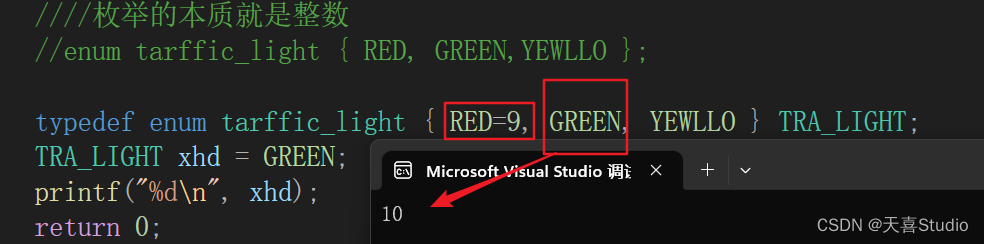
【c语言】enum枚举类型的定义格式 | 基本用法
创作不易,本篇文章如果帮助到了你,还请点赞支持一下♡>𖥦<)!! 主页专栏有更多知识,如有疑问欢迎大家指正讨论,共同进步! 给大家跳段街舞感谢支持!ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ…...

Python数据挖掘与机器学习
近年来,Python编程语言受到越来越多科研人员的喜爱,在多个编程语言排行榜中持续夺冠。同时,伴随着深度学习的快速发展,人工智能技术在各个领域中的应用越来越广泛。机器学习是人工智能的基础,因此,掌握常用…...

Java有用的书籍2
. 1.《Effective Java》是由Joshua Bloch撰写的一本Java编程规范和最佳实践指南,第三版是最新版。它涵盖了Java编程中一些常见问题和技巧,以及如何编写更加优雅、健壮和高效的Java代码。 该书共分为15章,每一章都涵盖了Java编程中的一个关键…...

CTA进网测试《5G消息 终端测试方法》标准依据:YDT 3958-2021
GB 21288-2022 强制国标要求变化 与GB 21288-2007相比, 新国标主要有以下变化: 1. 增加职业暴露定义: 2. 增加吸收功率密度定义: 3. 增加不同频率、不同人体部位适用的暴露限值: 4. 增加产品说明书的注释:…...
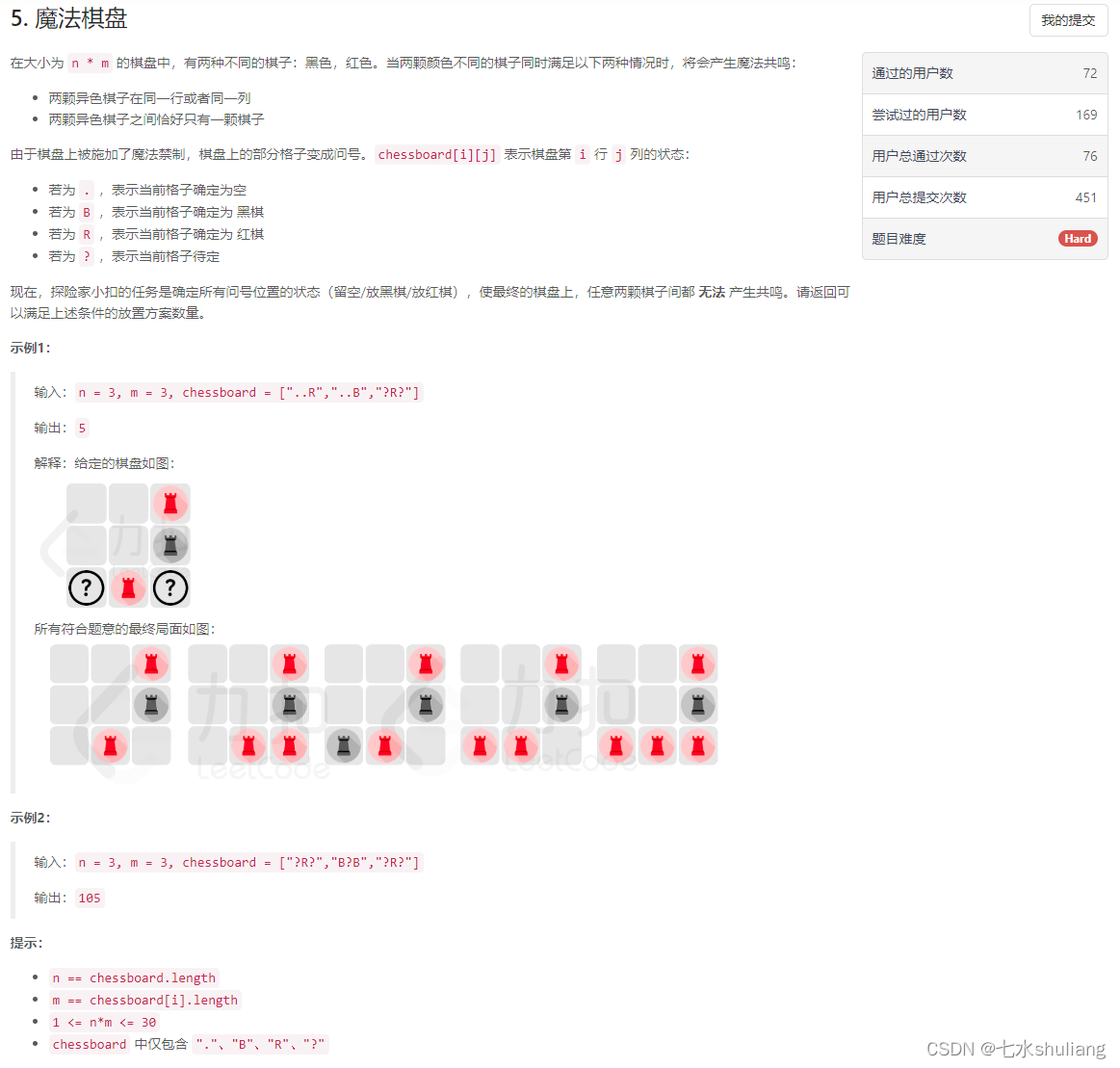
[LeetCode复盘] LCCUP‘23春季赛 20230422
[LeetCode复盘] LCCUP23春季赛 20230422 一、总结二、 1. 补给马车1. 题目描述2. 思路分析3. 代码实现 三、2. 探险营地1. 题目描述2. 思路分析3. 代码实现 四、 3. 最强祝福力场1. 题目描述2. 思路分析3. 代码实现 五、 4. 传送卷轴1. 题目描述2. 思路分析3. 代码实现 六、 5…...

传统燃油车的智控App远控响应速度优化方向几点思考
一、分析当前问题及其影响因素 网络延迟:燃油车的App远控响应速度受到网络延迟的影响。网络延迟可能是由于网络拥堵或服务器响应速度慢等原因导致的。 用户设备:用户设备的性能也会影响燃油车的App远控响应速度。例如,设备的内存不足或存在故…...
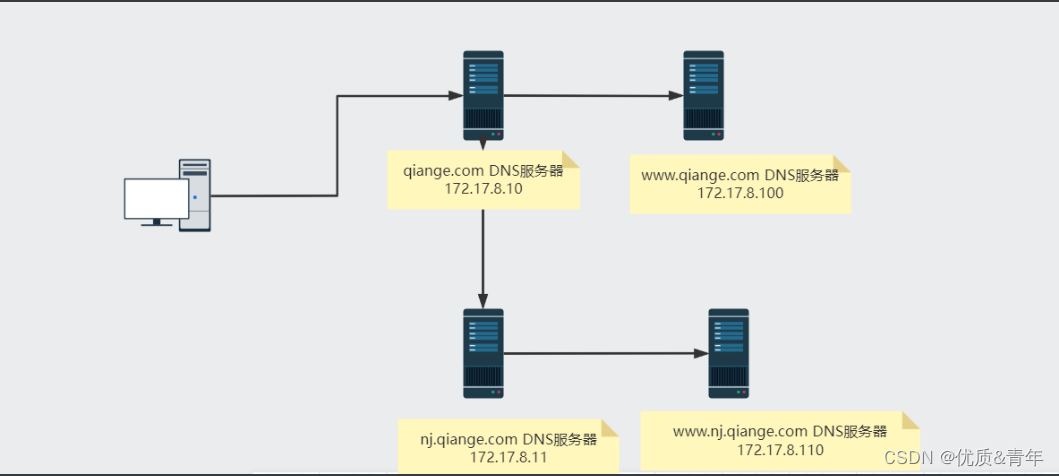
回炉重造九---DNS服务器
1、DNS服务器的相关概念和技术 1.1 DNS服务器的类型 主DNS服务器从DNS服务器缓存DNS服务器(forward DNS服务器{转发器}) 1.1.1 主DNS服务器的作用 管理和维护所负责解析的域内解析库的服务器1.1.2 从DNS服务器的作用 从主服务器或从服务器“复制”解…...
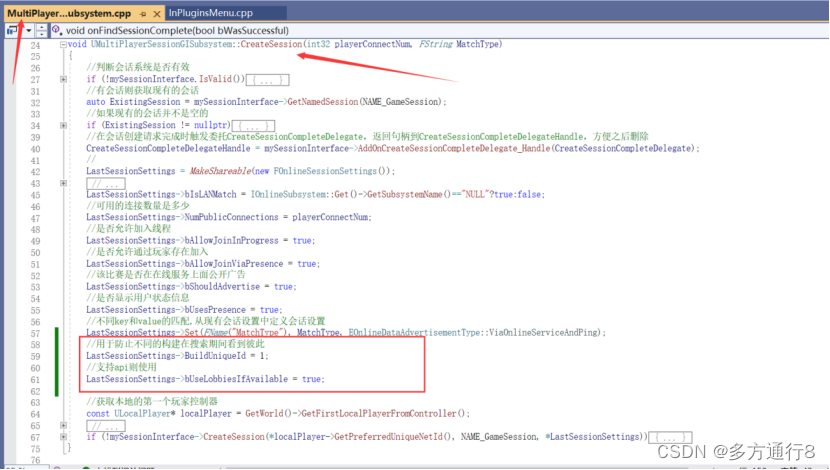
UE4/5多人游戏详解(七、自定义委托,实现寻找会话和加入会话的函数,通过Steam进行两台电脑的联机)
目录 可能出现问题(在六部分的测试可能无法连接的问题【在末尾加上了,怕有人没看见在这里写一下】) 自定义委托 调整位置 创建更多的委托和回调函数给菜单: 多播和动态多播 代码: 委托变量 代码: 回…...
【数据库多表操作】sql语句基础及进阶
常用数据库: 数据库(Database)是按照数据结构来组织、存储和管理数据的仓库,它是长期存储在计算机内、有组织、有结构的数据集合。数据库是信息系统的核心部分,现代软件系统中大量采用了数据库管理系统(DBM…...

Python数据流式处理:Streaming深度解析与实战
Python数据流式处理:Streaming深度解析与实战 引言 在Python开发中,数据流式处理是处理大数据和实时数据的关键技术。作为一名从Rust转向Python的后端开发者,我深刻体会到流式处理在处理海量数据时的优势。Python提供了多种流式处理工具&…...

[特殊字符] Windows 下 OpenClaw 快速安装与功能使用
✨ 适配系统:Windows10/11 64 位 | 当前版本:OpenClaw v2.7.5 : 🔗 下载 OpenClaw 2.7.5 ✨ 核心亮点:零代码门槛|全程可视化|内置运行依赖|快速部署上手 📢…...

ImageGlass完整指南:高效轻量的Windows图片查看神器
ImageGlass完整指南:高效轻量的Windows图片查看神器 【免费下载链接】ImageGlass 🏞 A lightweight, versatile image viewer 项目地址: https://gitcode.com/gh_mirrors/im/ImageGlass 还在为Windows系统自带的图片查看器功能单一而烦恼…...

2026年福建莆田大平层全屋高端定制选型指南
一、引言福建莆田近年来经济发展迅速,居民生活水平不断提高,大平层住宅逐渐成为高端改善型住房的热门选择。在全屋高端定制方面,消费者面临着众多品牌的选择。本指南旨在为莆田的大平层业主提供一份合规、靠谱且适配自身需求的高端定制品牌选…...

Robo 3T:原生跨平台MongoDB管理工具的架构解析与技术实践
Robo 3T:原生跨平台MongoDB管理工具的架构解析与技术实践 【免费下载链接】robomongo Native cross-platform MongoDB management tool 项目地址: https://gitcode.com/gh_mirrors/ro/robomongo Robo 3T作为一款原生跨平台的MongoDB管理工具,为开…...

十大榜单全覆盖,价值兑现引领:联想定义中国AI企业新高度
当前,全球 AI 产业已正式迈入规模化商业落地的关键周期,“技术炫技”让位于“价值兑现”,“算力筑基—技术创新—场景落地”的协同闭环成为高质量发展的核心逻辑。据《全球首席信息官(CIO)报告:企业级 AI 竞…...

UVa 259 Software Allocation
题目分析 一个计算中心有 101010 台不同的计算机(编号 000 至 999),每台计算机在同一时间只能运行一个应用程序。有 262626 种应用程序,名称分别为 A\texttt{A}A 至 Z\texttt{Z}Z。每天会有用户提交应用程序,同一个应用…...

Taotoken API Key管理与访问控制功能在团队大赛中的协作应用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken API Key管理与访问控制功能在团队大赛中的协作应用 1. 场景概述:团队协作中的API资源管理需求 当团队共同参…...

LuaJIT反编译终极解决方案:LJD工具深度解析与实战指南
LuaJIT反编译终极解决方案:LJD工具深度解析与实战指南 【免费下载链接】luajit-decompiler https://gitlab.com/znixian/luajit-decompiler 项目地址: https://gitcode.com/gh_mirrors/lu/luajit-decompiler 你是否曾面对LuaJIT编译后的字节码文件束手无策&a…...

二代壳脱壳新思路:Hook CreateFromRawDexFile捕获原始DEX
1. 为什么“二代壳”让传统脱壳方法集体失效?——从Dex加载链路说起你有没有试过用经典的dumpdex脚本在Android 10设备上跑,结果dump出来的dex文件一打开就是满屏java.lang.ClassNotFoundException?或者用dex2oat反编译出的odex,反…...