Learning Dynamic Facial Radiance Fields for Few-Shot Talking Head Synthesis 笔记
Learning Dynamic Facial Radiance Fields for Few-Shot Talking Head Synthesis 笔记
摘要
Talking head synthesis is an emerging technology with wide applications in film dubbing, virtual avatars and online education. Recent NeRF-based methods generate more natural talking videos, as they better capture the 3D structural information of faces. However, a specific model needs to be trained for each identity with a large dataset. In this paper, we propose Dynamic Facial Radiance Fields (DFRF) for few-shot talking head synthesis, which can rapidly generalize to an unseen identity with few training data. Different from the existing NeRF-based methods which directly encode the 3D geometry and appearance of a specific person into the network, our DFRF conditions face radiance field on 2D appearance images to learn the face prior. Thus the facial radiance field can be flexibly adjusted to the new identity with few reference images. Additionally, for better modeling of the facial deformations, we propose a differentiable face warping module conditioned on audio signals to deform all reference images to the query space. Extensive experiments show that with only tens of seconds of training clip available, our proposed DFRF can synthesize natural and high-quality audio-driven talking head videos for novel identities with only 40k iterations. We highly recommend readers view our supplementary video for intuitive comparisons. Code is available in https://sstzal.github.io/DFRF/.
会说话的头像合成是一项新兴的技术,在电影配音、虚拟化身和在线教育等领域有着广泛的应用。最近的基于NeRF的方法生成更自然的谈话视频,因为它们更好地捕获面部的3D结构信息。然而,需要针对具有大型数据集的每个身份训练特定模型。在本文中,我们提出了动态面部辐射场(DFRF)的几个镜头说话的头部合成,它可以快速推广到一个看不见的身份与少量的训练数据。与现有的直接将特定人的3D几何形状和外观编码到网络中的基于NeRF的方法不同,我们的DFRF条件在2D外观图像上的人脸辐射场来学习人脸先验。因此,面部辐射场可以灵活地调整到新的身份与几个参考图像。此外,为了更好地建模的面部变形,我们提出了一个可微的面部变形模块的音频信号变形的查询空间的所有参考图像。大量的实验表明,只有几十秒的训练剪辑可用,我们提出的DFRF可以合成自然和高质量的音频驱动的说话头部视频的新身份,只有40k迭代。我们强烈建议读者查看我们的补充视频,以进行直观的比较。代码可在www.example.com上获得https://sstzal.github.io/DFRF/。
GitHub:https://github.com/sstzal/DFRF
知识点
框架
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XpvxyoE0-1682325914139)(C:\Users\dell\AppData\Roaming\Typora\typora-user-images\image-20230424154122197.png)]](https://img-blog.csdnimg.cn/3323b1f80b934343bdc703a4f88a8086.png)
Overview of the proposed Dynamic Facial Radiance Fields (DFRF)所提出的动态面部辐射场(DFRF)的概述。
使用预训练的基于RNN的DeepSpeech模块来提取每帧音频特征。对于帧间一致性,进一步引入时间滤波模块[39]以计算平滑音频流图像流投影基于注意力的特征融合音频特征A,其可以表示为其相邻音频特征的基于自注意力的融合。以这些音频特征序列A为条件,我们可以学习音频-嘴唇映射。该音频驱动的面部辐射场可以表示为 ( c , σ ) = F θ ( p , d , A ) \quad(c,\sigma)=\mathcal{F}_{\theta}\left(p,d,A\right) (c,σ)=Fθ(p,d,A)。
由于身份信息被隐式编码到面部辐射场中,并且在渲染时不提供显式身份特征,因此该面部辐射场是人特定的。对于每个新身份,都需要在大型数据集上从头开始优化。这导致昂贵的计算成本并且需要长的训练视频。为了摆脱这些限制,我们设计了一个参考机制,使训练有素的基础模型能够快速泛化到新的人员类别,只有一小段目标人员可用。图2中示出了这种基于参考的架构的概述。具体地,取N个参考图像 M = { M n ∈ R H × W ∣ 1 ≤ n ≤ N } M=\left\{M_n\in\mathbb{R}^{H\times W}\text{}|1\leq n\leq N\right\} M={Mn∈RH×W∣1≤n≤N}及其对应的摄像机位置 { T n } \{T_n\} {Tn}作为输入,用一个两层卷积网络计算其像素对齐的图像特征 F = { F n ∈ R H × W × D ∣ 1 ≤ n ≤ N } F=\left\{F_n\in\mathbb{R}^{H\times W\times D}|1\leq n\leq N\right\} F={Fn∈RH×W×D∣1≤n≤N},无下采样。在本工作中,特征尺寸D被设置为128,并且H、W分别表示图像的高度和宽度。多个参考图像的使用提供了更好的多视图信息。对于一个3D查询点 p = ( x , y , z ) ∈ P p=\left(x,y,z\right)\in\mathcal{P} p=(x,y,z)∈P,我们使用本征函数 { K n } \{K_n\} {Kn}和相机姿态 { R n , T n } \{R_n,T_n\} {Rn,Tn}将其投影回这些参考的2D图像空间,并得到相应的2D坐标。使用 p n r e f = ( u n , v n ) \begin{matrix}p_n^{ref}=(u_n,v_n)\end{matrix} pnref=(un,vn)来表示第n幅参考图像中的2D坐标,该投影可以被公式化为:
p n r e f = M ( p , K n , R n , T n ) , (1) p_n^{ref}=\mathcal{M}(p,K_n,R_n,T_n),\tag1 pnref=M(p,Kn,Rn,Tn),(1)
其中 M \text{}\mathcal{M} M是从世界空间到图像空间的传统映射。然后,在舍入操作之后对来自N个参考的这些对应的像素级特征 { F n ( u n , v n ) } ∈ R N × D {\{F_n}(u_n,v_n)\}\in{\mathbb{R}^{N\times D}} {Fn(un,vn)}∈RN×D进行采样,并与基于注意力的模块融合,以获得最终特征 F ~ = A g g r e g a t i o n ( { F n ( u n , v n ) } ) ∈ R D \tilde{F}=A g g r e g a t i o n(\{F_{n}(u_{n},v_{n})\})\in\mathbb{R}^{D} F~=Aggregation({Fn(un,vn)})∈RD。这些要素网格包含有关身份和外观的丰富信息。使用它们作为我们的面部辐射场的附加条件,使得模型可以从几个观察到的帧快速概括为新的面部外观。该双驱动面部辐射场最终可以被公式化为:
( c , σ ) = F θ ( p , d , A , F ~ ) . (2) (c,\sigma)=\mathcal F_\theta\left(p,d,A,\tilde F\right).\tag2 (c,σ)=Fθ(p,d,A,F~).(2)
可微分面变形
我们将查询3D点投影回这些参考图像的2D图像空间,如等式(1)所示。(1)以得到经调节的像素特征。该操作基于NeRF中的先验知识,即从不同视点投射的相交光线应对应于相同的物理位置,从而产生相同的颜色。这种严格的空间映射关系适用于刚性场景,但说话的脸是动态的。说话时,嘴唇和其他面部肌肉会根据发音而运动。应用等式(1)直接在可变形的说话面部上可能导致关键点不匹配。例如,标准体积空间中的嘴角附近的3D点被映射回参考图像的像素空间。如果参考面示出不同的嘴部形状,则映射点可能远离期望的真实的嘴角。这种不准确的映射导致来自参考图像的不正确的像素特征条件,这进一步影响对说话嘴的变形的预测。
为了解决这个限制,我们建议一个audio-conditioned和3D逐点面变形模块 D η \mathcal{D}_{\eta} Dη。退化抵消 Δ o = ( Δ u , Δ v ) \Delta o=(\Delta u,\Delta v) Δo=(Δu,Δv)为每个投影点”在特定的变形,就像图像流图2所示。具体来说, D η \mathcal{D}_{\eta} Dη实现变形场与中长期规划三层,其中 η \eta η是可学的参数。回归抵消 Δ o \Delta o Δo,动态查询图像和参考图像之间的差异需要有效地利用。查询的音频信息反映了动态图像,而变形的参考图片可以看到通过 { F n } \{F_n\} {Fn}隐式的图像特征。因此,我们将这两个部分与查询3D点坐标P-起作为 D η \mathcal{D}_{\eta} Dη的输入。面变形的过程来预测补偿模块 D η \mathcal{D}_{\eta} Dη可以制定为:
Δ o n = D η ( p , A , F n ( u n , v n ) ) . (3) \Delta o_n=\mathcal{D}_\eta(p,A,F_n(u_n,v_n)).\tag3 Δon=Dη(p,A,Fn(un,vn)).(3)
然后,如图3所示,将预测的偏移 o n o_n on添加到 p n r e f p^{ref}_n pnref,如图3所示,以得到如图3所示的精确对应坐标 p n r e f ‘ p^{ref^{`}}_n pnref‘,以得到3D查询点 p p p,
p n r e f = p n r e f + Δ o n = ( u n ′ , v n ′ ) , ( where u n ′ = u n + Δ u n a n d v n ′ = v n + Δ v n . ) (4) p_n^{ref}=p_n^{ref}+\Delta o_n=(u_n',v_n'),(\text{where}\ \ u'_n=u_n+\varDelta u_n\mathrm{\ \ and\ \ }v'_n=v_n+\varDelta v_n.)\tag4 pnref=pnref+Δon=(un′,vn′),(where un′=un+Δun and vn′=vn+Δvn.)(4)
由于硬索引操作 F n ( u n ′ , v n ′ ) F_{n}({u_{n}}^{\prime},{v_{n}}^{\prime}) Fn(un′,vn′)不可微,因此梯度不能被反向传播到该扭曲模块。因此,我们引入了一个软指标函数来实现可微翘曲,其中每个像素的特征是通过双线性采样的特征插值其周围的点。以这种方式,可以端到端地联合优化变形场 D η \mathcal{D}_{\eta} Dη和面部辐射场 F θ \mathcal{F}_{\theta} Fθ。该软索引操作的可视化在图3中示出。对于绿点,其像素特征通过其四个最近邻居的特征通过双线性插值来计算。为了更好地约束该扭曲模块的训练过程,我们引入正则化项 L r L_r Lr以将预测偏移的值限制在合理的范围内以防止失真。
L r = 1 N ⋅ ∣ P ∣ ∑ p ∈ P ∑ n = 1 N Δ u n 2 + Δ v n 2 , (5) L_r=\dfrac{1}{N\cdot|\mathcal{P}|}\sum\limits_{p\in\mathcal{P}}\sum\limits_{n=1}^N\sqrt{\Delta u_n^2+\Delta v_n^2},\tag5 Lr=N⋅∣P∣1p∈P∑n=1∑NΔun2+Δvn2,(5)
其中 P \mathcal{P} P是体素空间中所有3D点的集合, N N N是参考图像的数量。此外,我们认为,低密度的点更有可能是背景区域,应该有低变形偏移。在这些区域中,应施加更强的正则化约束。为了更合理的约束,我们将上述 L r L_r Lr改变为:
L r ′ = ( 1 − σ ) ⋅ L r , (6) L_r{'}=(1-\sigma)\cdot L_r,\tag6 Lr′=(1−σ)⋅Lr,(6)
其中 σ \sigma σ表示这些点的密度。动态面部辐射场最终可以被公式化为:
( c , σ ) = F θ ( p , d , A , F ~ ′ ) , (7) (c,\sigma)=\mathcal F_\theta\left(p,d,A,\tilde F'\right),\tag7 (c,σ)=Fθ(p,d,A,F~′),(7)
其中 F ~ = A g g r e g a t i o n ( { F n ( u n ′ , v n ′ ) } ) \tilde{F}=A g g r e g a t i o n(\{F_{n}(u'_{n},v'_{n})\}) F~=Aggregation({Fn(un′,vn′)})。
利用该面部变形模块,可以将所有参考图像变换到查询空间,以更好地对说话面部变形进行建模。消融研究已经证明了该组件在产生更准确和音频同步的嘴部运动方面的有效性。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Q3iijfVI-1682325914139)(C:\Users\dell\AppData\Roaming\Typora\typora-user-images\image-20230424153431907.png)]](https://img-blog.csdnimg.cn/ed02e0c77ff44c5db73715d8b5e32dfc.png)
可微分面翘曲的可视化(Visualization of the differentiable face warping.)。查询3D点(紫色)被投影到参考图像空间(红色)。然后,学习偏移Δ o以将其扭曲到查询空间(绿色),其中其特征通过双线性插值来计算。
体渲染
体绘制用于对来自等式(7)的颜色c和密度σ进行积分转化成人脸图像。我们将背景、躯干和颈部部分一起作为渲染“背景”,并从原始视频中逐帧恢复。我们将每条射线的最后一个点的颜色设置为相应的背景像素,以渲染包括躯干部分的自然背景。这里,我们按照原始NeRF中的设置,在音频信号A和图像特征 F ′ ~ \tilde{F^{\prime}} F′~的条件下,相机光线 r r r的累积颜色 C C C为:
C ( r ; θ , η , R , T , A , F ~ ′ ) = ∫ z n e a r z f a r σ ( t ) ⋅ c ( t ) ⋅ T ( t ) d t , (8) C\left(r;\theta,\eta,R,T,A,\tilde{F}'\right)=\int_{z_{near}}^{z_{far}}\sigma\left(t\right)\cdot c(t)\cdot T\left(t\right)dt,\tag8 C(r;θ,η,R,T,A,F~′)=∫znearzfarσ(t)⋅c(t)⋅T(t)dt,(8)
其中 θ \theta θ和 η \eta η分别是面部辐射场 F θ \mathcal F_{\theta} Fθ和面部扭曲模块 D η \mathcal{D}_{\eta} Dη的可学习参数。 R R R是旋转矩阵, T T T是平移向量。 T ( t ) = e x p ( − ∫ z n e a r t σ ( r ( s ) ) d s ) T\left(t\right)=e x p\left(-\int_{z_{n e a r}}^{t}\sigma\left(r\left(s\right)\right)d s\right) T(t)=exp(−∫zneartσ(r(s))ds)是沿着相机光线的积分透射率,其中 z n e a r z_{near} znear和 z f a r z_{far} zfar是相机光线的近边界和远边界。我们按照NeRF设计MSE损失为 L M S E = ∥ C − I ∥ 2 L_{MSE} =\left\|C-I\right\|^{2} LMSE=∥C−I∥2,其中I是地面真值颜色。与方程中的正则化项耦合。(6),总损失函数可以公式化为:
L = L M S E + λ ⋅ L r ′ . (9) L=L_{MSE}+\lambda\cdot L_r{'}.\tag9 L=LMSE+λ⋅Lr′.(9)
效果

相关文章:
Learning Dynamic Facial Radiance Fields for Few-Shot Talking Head Synthesis 笔记
Learning Dynamic Facial Radiance Fields for Few-Shot Talking Head Synthesis 笔记 摘要 Talking head synthesis is an emerging technology with wide applications in film dubbing, virtual avatars and online education. Recent NeRF-based methods generate more n…...

SpringBoot 项目整合 Redis 教程详解
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...

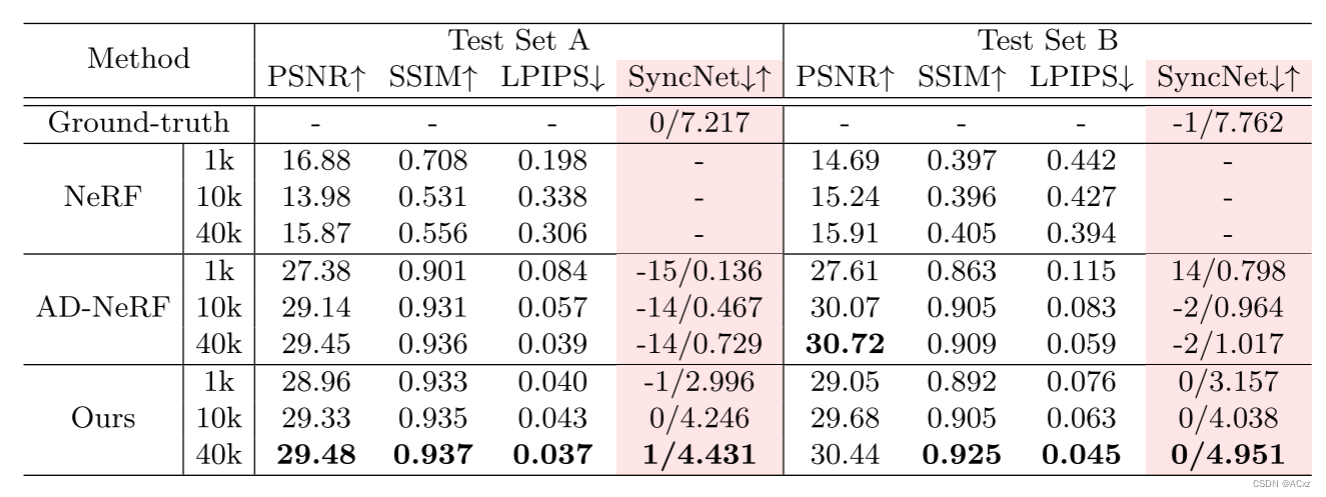
3ASC25H214 DATX130以力控制为基础的装配应用方面已经形成了一个解决方案
3ASC25H214 DATX130以力控制为基础的装配应用方面已经形成了一个解决方案 ABB的机器人解决方案最终选择了IRB6400机器人 ABB的解决方案 ABB一直都在不断地研究和开发机器人应用的新技术,有一部分研究活动是与大学进行合作的,其中一项是ABB的科学家和…...

Java的位运算
目录 1 Java中支持的位运算 2 位运算规则 3 逻辑运算 3.1 与运算(&) 3.2 或运算(|) 3.3 异或运算(^) 3.3 取反运算(~) 4 位移操作 4.1 左移(<<&#…...

FastDFS分布式文件存储
FastDFS文件上传 简介: 主要解决:大容量的文件存储和高并发访问的问题 论坛:https://bbs.chinaunix.net 下载网站:https://sourceforge.net/projects/fastdfs/files/ 安装参考:https://www.cnblogs.com/cxygg/p/1…...

Android的AAC架构
AAC Android Architecture Components的简称,是一套用来搭建具有生命周期感知架构的系列组件,在2017年 GoogleI/O大会上发布。 dependencies {def lifecycle_version "2.2.0"implementation "androidx.lifecycle:lifecycle-livedata-ktx…...

高功率激光切割中不良现象的排除技巧
高功率切割市场现状 随着激光行业的发展和下游产业需求的变化,高功率的激光切割设备已逐渐成为市场关注的热点。高功率激光切割凭着速度和厚度上无可比拟的优势,目前已获得了市场的广泛认可。 但由于高功率激光切割技术尚处于普及的初级阶段,…...

MySQL-----复合查询
文章目录 前言一、基本查询回顾二、 多表查询解决多表查询的思路 三、自连接四、子查询1. 单行子查询2. 多行子查询3. 多列子查询4. 在from子句中使用子查询5. 合并查询5.1 union5.2 unoin all 总结 前言 前面的学习中,对于mysql表的查询都是对一张表进行查询,在实际开发中这远…...
10.Yarn概述
如果说HDFS是存储,则Yarn就是cpu和内存,mapreduce就是程序。 1.基础架构 复习: 1.Container就是一个容器,其中封装了需要使用的内存与cpu 2.每当提交一个job,就会产生一个appMaster(总指挥),app Master负责其他container里面的…...

MFC实现背景透明,控件不透明的对话框,且点击图片有事件响应
最终成果:背景半透明、但是控件不透明的对话框。 对话框上用图片代表功能,当点击图片时,响应点击事件,弹出相对应的对话框。 对话框固定大小,不可放大缩小,以免影响图片的显示数量。 步骤一:背景…...

案例01-tlias智能学习辅助系统01-增删改查+参数传递
目录 1、需求说明:实现对部门表和员工表的增删改查 2、环境搭建 3、部门管理 3.1 查询部门 3.2 前后端联调 3.3 删除部门 3.4 新增部门 3.5 根据ID查询数据 3.5 修改部门 总结(Controller层参数接收): 4、员工管理 4.…...

Spring之Bean的配置与实例
Spring之Bean的配置与实例 一、Bean的基础配置1. Bean基础配置【重点】配置说明代码演示运行结果 2. Bean别名配置配置说明代码演示打印结果 3. Bean作用范围配置【重点】配置说明代码演示打印结果 二、Bean的实例化1. Bean是如何创建的2. 实例化Bean的三种方式2.1 构造方法方式…...

“不保留活动”打开,导致app返回前台崩溃问题解决
问题描述 不保留活动开关打开,把app切入后台,会导致当前展示的Activity被回收,切到前台后重建。 我们有个业务场景是,Activity里面有个ViewPager2,VP里面放Fragment,Fragment的展示需要在Activity中做一些…...
——watch)
解读vue3源码(3)——watch
Vue3的watch底层源码主要是通过使用Proxy对象来实现的。在Vue3中,每个组件实例都会有一个watcher实例,用于监听组件数据的变化。当组件数据发生变化时,watcher实例会触发回调函数,从而更新组件的视图。 Vue3的watch底层源码主要涉…...
优秀简历的HR视角:怎样打造一份称心如意的简历?
简历的排版应该简洁工整,注重细节。需要注意对齐和标点符号的使用,因为在排版上的细节需要下很大功夫。除此之外,下面重点讲述几点简历内容需要注意的地方。 要点1:不相关的不要写。 尤其是与应聘岗位毫不相关的实习经历&#x…...
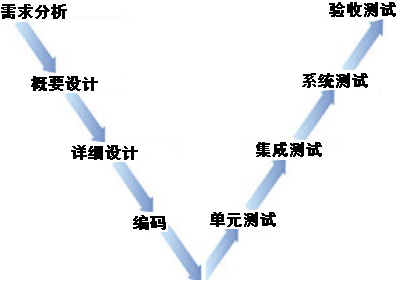
系统集成项目管理工程师——考试重点(三)项目管理一般知识
1.项目定义: 为达到特定的目的,使用一定资源,在确定的期间内,为特定发起人提供独特的产品、服务或成果而进行的一系列相互关联的活动的集合。 2.项目目标: 成果性目标:项目产品本身 约束性目标&…...

为什么医疗保健需要MFT来帮助保护EHR文件传输
毫无疑问,医疗保健行业需要EHR技术来处理患者,设施,提供者等之间的敏感患者信息。但是,如果没有安全的MFT解决方案,您将无法安全地传输患者文件,从而使您的运营面临遭受数据泄露,尴尬࿰…...

对项目总体把控不足,项目经理应该怎么办?
公司现状:项目人员紧缺,只有两人了解此项目技术细节,其中一个不常驻现场,另一个是执行项目经理李伟。 项目经理王博是公司元老,同时负责多个项目,工作比较忙,不常驻现场,没有参加过…...

【学习笔记】CF603E Pastoral Oddities
先不考虑数据结构部分,尝试猜一下结论。 结论:一个连通块有解当且仅当连通块的度数为偶数。 然后这题要你最大边权最小。最无脑的方法就是直接上 lct \text{lct} lct。真省事啊 我第一眼想到的还是整体二分。这玩意非常好写。 但是为什么也可以用线段…...
如何使用ESP32-CAM构建一个人脸识别系统
有许多人识别系统使用签名、指纹、语音、手部几何、人脸识别等来识别人,但除了人脸识别系统。 人脸识别系统不仅可以用于安全目的来识别公共场所的人员,还可以用于办公室和学校的考勤目的。 在这个项目中,我们将使用 ESP32-CAM 构建一个人脸识…...

技术人如何应对职业倦怠?这4个方法让我重燃热情
一、软件测试从业者职业倦怠的“隐形陷阱”在互联网技术高速迭代的今天,软件测试从业者正面临着前所未有的职业压力。你是否也曾有过这样的时刻:盯着满屏的测试用例,手指机械地重复着点击操作,内心却毫无波澜;面对层出…...

11 极物科技 JetLinks MQTT 直连设备功能调用完整流程与 Python 实现
1. 前言 JetLinks作为开源的IoT物联网平台,提供了完善的设备接入、物模型管理、功能调用等核心能力,其中MQTT协议是设备与平台直连的主流方式。本次测试以继电器设备为核心测试载体,继电器具备明确的“通/断”二元状态,且状态变更…...

收藏 | 零基础小白也能看懂:AI大模型应用开发入门指南
文章介绍了AI领域两大门派:传统算法工程师与大模型应用开发工程师。传统算法工程师专注于算法研发,是AI基建者;大模型应用开发工程师则侧重于将现成大模型应用于实际业务场景,是场景魔术师。文章指出,大模型应用开发工…...

dy app抓包分析
声明 本文章中所有内容仅供学习交流使用,不用于其他任何目的,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!抓包展示总结1.出于安全考虑,本章未提供…...

免费激活IDM的终极解决方案:开源脚本完整指南
免费激活IDM的终极解决方案:开源脚本完整指南 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script 你是否经常遇到IDM(Internet Download Mana…...

紧急更新!Midjourney v6.6对洛可可风格支持突降37%?立即启用这5个兼容性补丁prompt,保住你的商业项目交付期
更多请点击: https://intelliparadigm.com 第一章:Midjourney v6.6洛可可风格兼容性危机全景速览 Midjourney v6.6 发布后,大量用户在生成洛可可(Rococo)风格图像时遭遇显著退化:繁复卷曲的藤蔓纹样被简化…...

终极指南:如何使用IDM激活脚本实现永久免费下载体验
终极指南:如何使用IDM激活脚本实现永久免费下载体验 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script Internet Download Manager(IDM&…...

CompressO:你的数字瘦身专家,如何将臃肿媒体文件压缩90%而不失品质?
CompressO:你的数字瘦身专家,如何将臃肿媒体文件压缩90%而不失品质? 【免费下载链接】compressO Convert any video/image into a tiny size. 100% free & open-source. Available for Mac, Windows & Linux. 项目地址: https://gi…...
)
告别C盘爆满!VSCode插件和用户数据迁移到D盘的保姆级教程(附注册表修改)
告别C盘爆满!VSCode插件和用户数据迁移到D盘的保姆级教程 每次打开VSCode都看到C盘空间告急的红色警告?作为开发者,我们往往会在不知不觉中安装几十个甚至上百个插件,这些插件和用户数据默认都存储在C盘,日积月累就会…...

3步掌握StreamCap:开源直播录制工具的终极使用指南
3步掌握StreamCap:开源直播录制工具的终极使用指南 【免费下载链接】StreamCap Multi-Platform Live Stream Automatic Recording Tool | 多平台直播流自动录制客户端 基于FFmpeg 支持监控/定时/转码 项目地址: https://gitcode.com/gh_mirrors/st/StreamCap …...