多线程、智能指针以及工厂模式
目录
一、unique_lock
二、智能指针 (其实是一个类)
三、工厂模式
一、unique_lock
参考文章【1】,了解unique_lock与lock_guard的区别。
总结:unique_lock使用起来要比lock_guard更灵活,但是效率会第一点,内存的占用也会大一点。
1.unique_lock的定义:
std::mutex mlock;
std::unique_lock<std::mutex> munique(mlock);第二个参数可以是std::adopt_lock
std::unique_lock<std::mutex> munique(mlock,std::adopt_lock);使用unique_lock和mutex来实现互斥锁。unique_lock在构造函数中获取锁,析构函数中释放锁。adopt_lock参数告诉unique_lock构造函数,锁已经被其他线程获取,unique_lock不需要再次获取锁,而是直接将锁的所有权转移给它自己。这样做的好处是可以避免死锁,因为uniquelock的析构函数会在任何情况下都释放锁,即使在发生异常的情况下也是如此。
也可以是:std::try_to_lock
std::unique_lock<std::mutex> munique(mlock, std::try_to_lock);如果有一个线程被锁住,而且执行时间很长,那么另一个线程一般会被阻塞在那里,反而会造成时间的浪费。那么使用了try_to_lock后,如果被锁住了,它不会在那里阻塞等待,它可以先去执行其他没有被锁的代码。
也可以是std::defer_lock
std::unique_lock<std::mutex> munique(mlock, std::defer_lock);表示暂时先不lock,之后手动去lock。一般与unique_lock的成员函数搭配使用
2.unique_lock的成员函数
lock() 与 unlock()
当使用了defer_lock参数时,在创建了unique_lock的对象时就不会自动加锁,那么就需要借助lock这个成员函数来进行手动加锁,当然也有unlock来手动解锁。
try_lock():判断是否能拿到锁,如果拿不到锁,返回false,如果拿到了锁,返回true
release():解除unique_lock和mutex对象的联系,并将原mutex对象的指针返回出来。如果之前的mutex已经加锁,需在后面自己手动unlock解锁
std::unique_lock<std::mutex> munique(mlock); // 这里是自动lock
std::mutex *m = munique.release();
....
m->unlock();std::thread t1(work1, std::ref(ans));std::ref是C++标准库中的一个函数模板,用于将一个对象包装成一个引用。这个函数模板的作用是将一个对象的引用传递给一个函数,而不是将对象本身传递给函数。这样做的好处是可以避免对象的拷贝,提高程序的效率。
代码块中,std::ref被用于将ans对象包装成一个引用,并将这个引用传递给work1函数的线程。这样做的目的是让work1函数在线程中对ans对象进行操作,而不是对ans对象的拷贝进行操作。
二、智能指针 (其实是一个类)
智能指针主要用于管理在堆上分配的内存,它将普通的指针封装为一个栈对象。当栈对象的生存周期结束后,会在析构函数中释放掉申请的内存,从而防止内存泄漏。
C++ 11中最常用的智能指针类型为shared_ptr,它采用引用计数的方法,记录当前内存资源被多少个智能指针引用。该引用计数的内存在堆上分配。当新增一个时引用计数加1,当过期时引用计数减一。只有引用计数为0时,智能指针才会自动释放引用的内存资源。对shared_ptr进行初始化时不能将一个普通指针直接赋值给智能指针,因为一个是指针,一个是类。可以通过make_shared函数或者通过构造函数传入普通指针。并可以通过get函数获得普通指针。
1.unique_ptr
unique_ptr保证同一时间内只有一个智能指针可以指向该对象。它对于避免资源泄露,以new创建对象后因为发生异常而忘记调用delete特别有用。
两个unique_ptr 不能指向一个对象,即 unique_ptr 不共享它所管理的对象。它无法复制到其他 unique_ptr,无法通过值传递到函数。
#include <iostream>
#include <string>
#include <memory>
int main() {std::unique_ptr<std::string> ps1, ps2;ps1 = std::make_unique<std::string>("hello");ps2 = std::move(ps1);ps1 = std::make_unique<std::string>("alexia");std::cout << *ps2 << *ps1 << std::endl;return 0;
}2.shared_ptr
shared_ptr 允许多个指针指向同一个对象。利用引用计数的方式实现了对所管理的对象的所有权的分享,即允许多个 shared_ptr 共同管理同一个对象,当引用计数为 0 的时候,自动释放资源。
成员函数:
use_count 返回引用计数的个数
unique 返回是否是独占所有权
swap 交换两个 shared_ptr 对象(即交换所拥有的对象)
reset 放弃内部对象的所有权或拥有对象的变更, 会引起原有对象的引用计数的减少
get 返回内部对象(指针), 由于已经重载了()方法, 因此和直接使用对象是一样的.如
shared_ptr<int> sp(new int(1)); sp 与 sp.get()是等价的。
3.weak_ptr
share_ptr虽然已经很好用了,但是有一点share_ptr智能指针还是有内存泄露的情况,当两个对象相互使用一个shared_ptr成员变量指向对方,会造成循环引用,使引用计数失效,从而导致内存泄漏。
weak_ptr 被设计为与 shared_ptr 共同工作,可以从一个 shared_ptr 或者另一个 weak_ptr 对象构造而来。weak_ptr 是为了配合 shared_ptr 而引入的一种智能指针,它更像是 shared_ptr 的一个助手而不是智能指针,因为它不具有普通指针的行为,没有重载 operator* 和 operator-> ,因此取名为 weak,表明其是功能较弱的智能指针。它的最大作用在于协助 shared_ptr 工作,可获得资源的观测权,像旁观者那样观测资源的使用情况。观察者意味着 weak_ptr 只对 shared_ptr 进行引用,而不改变其引用计数,当被观察的 shared_ptr 失效后,相应的 weak_ptr 也相应失效。
使用方法:
使用 weak_ptr 的成员函数 use_count() 可以观测资源的引用计数。注意:weak_ptr不增加引用计数
另一个成员函数 expired() 的功能等价于 use_count()==0,表示被观测的资源(也就是 shared_ptr 管理的资源)已经不复存在。
weak_ptr 可以使用一个非常重要的成员函数lock(),从被观测的 shared_ptr 获得一个可用的 shared_ptr 管理的对象, 从而操作资源。但当 expired()==true 的时候,lock() 函数将返回一个存储空指针的 shared_ptr。总的来说,weak_ptr 的基本用法总结如下:
shared_ptr<int> sp(new int(1));
weak_ptr<T> w; //创建空 weak_ptr,可以指向类型为 T 的对象
weak_ptr<T> w(sp); //与 shared_ptr 指向相同的对象,shared_ptr 引用计数不变。T必须能转换为 sp 指向的类型
w=p; //p 可以是 shared_ptr 或 weak_ptr,赋值后 w 与 p 共享对象
w.reset(); //将 w 置空
w.use_count(); //返回与 w 共享对象的 shared_ptr 的数量
w.expired(); //若 w.use_count() 为 0,返回 true,否则返回 false
w.lock(); //如果 expired() 为 true,返回一个空 shared_ptr,否则返回非空 shared_ptr
#include <assert.h>#include <iostream>
#include <memory>
#include <string>using namespace std;int main() {shared_ptr<int> sp(new int(10));assert(sp.use_count() == 1);weak_ptr<int> wp(sp); // 从 shared_ptr 创建 weak_ptrassert(wp.use_count() == 1);if (!wp.expired()) { // 判断 weak_ptr 观察的对象是否失效shared_ptr<int> sp2 = wp.lock(); //使用 wp.lock() 创建一个新的 shared_ptr 时,它又增加了一次引用计数 *sp2 = 100;assert(wp.use_count() == 2);}assert(wp.use_count() == 1); //在 if 语句块之外,wp.use_count() 的值仍然是1,因为 weak_ptr 并不会增加引用计数。cout << "int:" << *sp << endl;return 0;
}
这段代码主要演示了如何使用 weak_ptr 来避免循环引用的问题。在这个例子中,我们创建了一个 shared_ptr 对象 sp,然后通过 weak_ptr 对象 wp 来观察 sp。如果 sp 被销毁了,那么 wp 也会自动失效。在代码中,我们通过 wp.expired() 来判断 wp 是否失效,如果没有失效,我们就可以通过 wp.lock() 来获得一个 shared_ptr 对象 sp2,然后修改 sp2 所指向的值。最后,我们通过 use_count() 来检查 sp 和 wp 的引用计数是否正确。
4.如何选择智能指针:
(1)如果程序要使用多个指向同一个对象的指针,应选择 shared_ptr
- 将指针作为参数或者函数的返回值进行传递的话,应该使用 shared_ptr;
- 两个对象都包含指向第三个对象的指针,此时应该使用 shared_ptr 来管理第三个对象;
- STL 容器包含指针。很多 STL 算法都支持复制和赋值操作,这些操作可用于 shared_ptr,但不能用于 unique_ptr(编译器发出 warning)和 auto_ptr(行为不确定)。如果你的编译器没有提供 shared_ptr,可使用 Boost 库提供的 shared_ptr。
(2)如果程序不需要多个指向同一个对象的指针,则可使用 unique_ptr。如果函数使用 new 分配内存,并返还指向该内存的指针,将其返回类型声明为 unique_ptr 是不错的选择。
(3)为了解决 shared_ptr 的循环引用问题,使用 weak_ptr。
参考【2】【3】
三、工厂模式
工厂模式分为简单工厂模式、工厂方法模式和抽象工厂模式。
1.简单工厂模式
简单工厂模式又叫静态方法模式(因为工厂类定义了一个静态方法)。
将“类实例化的操作”与“使用对象的操作”分开,让使用者不用知道具体参数就可以实例化出所需要的“产品”类,从而避免了在客户端代码中显式指定,实现了解耦。也就是说,使用者可直接消费产品而不需要知道其生产的细节。
模式组成:
| 组成 | 关系 | 作用 |
| 抽象产品(Product) | 具体产品的父类 | 描述产品的公共接口 |
| 具体产品(Concrete Product) | 抽象产品的子类;工厂类创建的目标类 | 描述生产的具体产品 |
| 工厂(Factor) | 被外界调用 | 根据传入不同参数从而创建不同具体产品类的实例 |
使用步骤:
- 创建抽象产品类Product :定义产品的公共接口
- 创建具体产品类(继承抽象产品类):定义生产的具体产品
- 创建工厂类:通过创建静态方法传入不同参数,从而创建不同具体产品类的实例
- 外界通过调用工厂类的静态方法,传入不同参数从而创建不同具体产品类的实例
实列:某加工厂推出三个产品,使用简单工厂模式实现三种产品的生成
①创建抽象产品类Product:
class Product
{
public:virtual void Show() = 0;
};②创建具体产品类(继承抽象产品类):
class ProductA : public Product
{
public:void Show(){cout<<"I'm ProductA"<<endl;}
};class ProductB : public Product
{
public:void Show(){cout<<"I'm ProductB"<<endl;}
};class ProductC : public Product
{
public:void Show(){cout<<"I'm ProductC"<<endl;}
};
③创建工厂类:通过创建静态方法传入不同参数,从而创建不同具体产品类的实例。
typedef enum ProductTypeTag
{TypeA,TypeB,TypeC
}PRODUCTTYPE;class Factory
{
public:static Product* CreateProduct(PRODUCTTYPE type){switch (type){case TypeA:return new ProductA();case TypeB:return new ProductB();case TypeC:return new ProductC();default:return NULL;}}
};④外界通过调用工厂类的静态方法,传入不同参数从而创建不同具体产品类的实例
int main(int argc, char *argv[])
{//创造工厂对象Factory *ProductFactory = new Factory();//从工厂对象创造产品A对象Product *productObjA = ProductFactory->CreateProduct(TypeA);if (productObjA != NULL)productObjA->Show();Product *productObjB = ProductFactory->CreateProduct(TypeB);if (productObjB != NULL)productObjB->Show();Product *productObjC = ProductFactory->CreateProduct(TypeC);if (productObjC != NULL)productObjC->Show();delete ProductFactory;ProductFactory = NULL;delete productObjA;productObjA = NULL;delete productObjB;productObjB = NULL; delete productObjC;productObjC = NULL;return 0;
}优缺点:
优点:
- 把初始化实例时的工作放到工厂里进行,使代码更容易维护。
- 将“类实例化的操作”与“使用对象的操作”分开,让使用者不用知道具体参数就可以实例化出所需要的“产品”类,
缺点:
- 工厂类集中了所有实例(产品)的创建逻辑,一旦这个工厂不能正常工作,整个系统都会受到影响;
- 违背“开放 - 关闭原则”,一旦添加新产品就不得不修改工厂类的逻辑,这样就会造成工厂逻辑过于复杂。
- 简单工厂模式由于使用了静态工厂方法,静态方法不能被继承和重写,会造成工厂角色无法形成基于继承的等级结构。
2.工厂方法模式
针对简答工厂模式问题,设计了工厂方法模式。工厂父类负责定义创建对象的公共接口,而子类则负责生成具体的对象。
将类的实例化(具体产品的创建)延迟到工厂类的子类(具体工厂)中完成,即由子类来决定应该实例化(创建)哪一个类。
之所以可以解决简单工厂的问题,是因为工厂方法模式把具体产品的创建推迟到工厂类的子类(具体工厂)中,此时工厂类不再负责所有产品的创建,而只是给出具体工厂必须实现的接口,这样工厂方法模式在添加新产品的时候就不修改工厂类逻辑而是添加新的工厂子类,符合开放封闭原则。
模式组成:
| 组成 | 关系 | 作用 |
| 抽象产品(Product) | 具体产品的父类 | 描述具体产品的公共接口 |
| 具体产品(Concrete Product) | 抽象产品的子类;工厂类创建的目标类 | 描述生产的具体产品 |
| 抽象工厂(Factor) | 具体工厂的父类 | 描述具体工厂的公共接口 |
| 具体工厂(Concrete Factor) | 抽象工厂的子类;被外界调用 | 描述具体工厂 |
使用步骤:
- 创建抽象产品类 ,定义具体产品的公共接口;
- 创建具体产品类(继承抽象产品类):定义生产的具体产品;
- 创建抽象工厂类,定义具体工厂的公共接口;
- 创建具体工厂类(继承抽象工厂类),定义创建对应具体产品实例的方法;
- 外界通过调用具体工厂类的方法,从而创建不同具体产品类的实例
实例:某加工厂原来只生产A类产品,但新的订单要求生产B类产品,由于改变原来工厂的配置比较困难,因此开设工厂B生产B类产品。
#include <iostream>
using namespace std;//1.创建抽象产品类
class Product
{
public:virtual void Show() = 0;
};
//2.创建具体产品类(继承抽象产品类)
class ProductA : public Product
{
public:void Show(){cout<< "I'm ProductA"<<endl;}
};class ProductB : public Product
{
public:void Show(){cout<< "I'm ProductB"<<endl;}
};//3.创建抽象工厂类
class Factory
{
public:virtual Product *CreateProduct() = 0;
};//4.创建具体工厂类(继承抽象工厂类),定义创建对应具体产品实例的方法;
class FactoryA : public Factory
{
public:Product *CreateProduct(){return new ProductA ();}
};class FactoryB : public Factory
{
public:Product *CreateProduct(){return new ProductB ();}
};//5.外界通过调用具体工厂类的方法,从而创建不同具体产品类的实例
int main(int argc , char *argv [])
{Factory *factoryA = new FactoryA ();Product *productA = factoryA->CreateProduct();productA->Show();Factory *factoryB = new FactoryB ();Product *productB = factoryB->CreateProduct();productB->Show();if (factoryA != NULL){delete factoryA;factoryA = NULL;}if (productA != NULL){delete productA;productA = NULL;}if (factoryB != NULL){delete factoryB;factoryB = NULL;}if (productB != NULL){delete productB;productB = NULL;}system("pause");return 0;
}优缺点:
优点:
- 符合开-闭原则。新增一种产品时,只需要增加相应的具体产品类和相应的工厂子类即可。(简单工厂模式需要修改工厂类的判断逻辑)
- 符合单一职责原则。每个具体工厂类只负责创建对应的产品。(简单工厂中的工厂类存在复杂的switch逻辑判断)
- 不使用静态工厂方法,可以形成基于继承的等级结构。(简单工厂模式的工厂类使用静态工厂方法)
缺点:
- 添加新产品时,除了增加新产品类外,还要提供与之对应的具体工厂类,系统类的个数将成对增加,在一定程度上增加了系统的复杂度
- 由于考虑到系统的可扩展性,需要引入抽象层,在客户端代码中均使用抽象层进行定义,增加了系统的抽象性和理解难度
- 一个具体工厂只能创建一种具体产品
3.抽象工厂模式
工厂方法模式存在一个严重的问题:一个具体工厂只能创建一类产品;而在实际过程中,一个工厂往往需要生产多类产品。使用了一种新的设计模式:抽象工厂模式。
定义:创建一系列相关或相互依赖对象的接口,而无须指定它们具体的类;具体的工厂负责实现具体的产品实例。
允许使用抽象的接口来创建一组相关产品,而不需要知道或关心实际生产出的具体产品是什么,这样就可以从具体产品中被解耦。
模式组成:
| 组成 | 关系 | 作用 |
| 抽象产品族(AbstractProduct | 抽象产品的父类 | 描述抽象产品的公共接口 |
| 抽象产品(Product) | 具体产品的父类 | 描述具体产品的公共接口 |
| 具体产品(Concrete Product) | 抽象产品的子类;工厂类创建的目标类 | 描述生产的具体产品 |
| 抽象工厂(Factor) | 具体工厂的父类 | 描述具体工厂的公共接口 |
| 具体工厂(Concrete Factor) | 抽象工厂的子类;被外界调用 | 描述具体工厂 |
使用步骤:
- 创建抽象产品族类 ,定义抽象产品的公共接口;
- 创建抽象产品类 (继承抽象产品族类),定义具体产品的公共接口;
- 创建具体产品类(继承抽象产品类) & 定义生产的具体产品;
- 创建抽象工厂类,定义具体工厂的公共接口;
- 创建具体工厂类(继承抽象工厂类),定义创建对应具体产品实例的方法;
- 客户端通过实例化具体的工厂类,并调用其创建不同目标产品的方法 创建不同具体产品类的实例
实例:某厂有两个加工厂A和B分别生产鞋和衣服,随着订单的增加,A厂所在地有了衣服的订单,B厂所在地有了鞋子的订单,再开新的工厂显然是不现实的,因此在原来的工厂增加生产需求的功能,即A生产鞋+衣服,B生产衣服+鞋。
#include <iostream>
using namespace std;
//这个代码没有抽象产品族类// 抽象产品A
class ProductA
{
public:virtual void Show() = 0;
};//具体的产品
class ProductA1 : public ProductA
{
public:void Show(){cout<<"I'm ProductA1"<<endl;}
};class ProductA2 : public ProductA
{
public:void Show(){cout<<"I'm ProductA2"<<endl;}
};// 抽象产品B
class ProductB
{
public:virtual void Show() = 0;
};class ProductB1 : public ProductB
{
public:void Show(){cout<<"I'm ProductB1"<<endl;}
};class ProductB2 : public ProductB
{
public:void Show(){cout<<"I'm ProductB2"<<endl;}
};// Factory
class Factory
{
public:virtual ProductA *CreateProductA() = 0;virtual ProductB *CreateProductB() = 0;
};//具体工厂A生产A1和B1
class Factory1 : public Factory
{
public:ProductA *CreateProductA(){return new ProductA1();}ProductB *CreateProductB(){return new ProductB1();}
};class Factory2 : public Factory
{ProductA *CreateProductA(){return new ProductA2();}ProductB *CreateProductB(){return new ProductB2();}
};int main(int argc, char *argv[])
{Factory *factoryObj1 = new Factory1();ProductA *productObjA1 = factoryObj1->CreateProductA();ProductB *productObjB1 = factoryObj1->CreateProductB();productObjA1->Show();productObjB1->Show();Factory *factoryObj2 = new Factory2();ProductA *productObjA2 = factoryObj2->CreateProductA();ProductB *productObjB2 = factoryObj2->CreateProductB();productObjA2->Show();productObjB2->Show();if (factoryObj1 != NULL){delete factoryObj1;factoryObj1 = NULL;}if (productObjA1 != NULL){delete productObjA1;productObjA1= NULL;}if (productObjB1 != NULL){delete productObjB1;productObjB1 = NULL;}if (factoryObj2 != NULL){delete factoryObj2;factoryObj2 = NULL;}if (productObjA2 != NULL){delete productObjA2;productObjA2 = NULL;}if (productObjB2 != NULL){delete productObjB2;productObjB2 = NULL;}system("pause");return 0;
}优缺点:
优点:
- 抽象工厂模式将具体产品的创建延迟到具体工厂的子类中,这样将对象的创建封装起来,可以减少客户端与具体产品类之间的依赖,从而使系统耦合度低,这样更有利于后期的维护和扩展;
- 新增一种产品类时,只需要增加相应的具体产品类和相应的工厂子类即可
缺点:
- 抽象工厂模式很难支持新种类产品的变化。因为抽象工厂接口中已经确定了可以被创建的产品集合,如果需要添加新产品,此时就必须去修改抽象工厂的接口,这样就涉及到抽象工厂类的以及所有子类的改变
参考【4】 【5】
相关文章:

多线程、智能指针以及工厂模式
目录 一、unique_lock 二、智能指针 (其实是一个类) 三、工厂模式 一、unique_lock 参考文章【1】,了解unique_lock与lock_guard的区别。 总结:unique_lock使用起来要比lock_guard更灵活,但是效率会第一点,内存的…...

初探 VS Code + Webview
本文作者为 360 奇舞团前端开发工程师 介绍 VSCode 是一个非常强大的代码编辑器,而它的插件也非常丰富。在开发中,我们经常需要自己编写一些插件来提高开发效率。本文将介绍如何开发一个 VSCode 插件,并在其中使用 Webview 技术。首先介绍一下…...

Codeforces Round 864 (Div. 2)(A~D)
A. Li Hua and Maze 给出两个不相邻的点,最少需要堵上几个方格,才能使得两个方格之间不能互相到达。 思路:显然,对于不邻任何边界的方格来说,最少需要的是4,即上下左右都堵上;邻一个边界就-1&a…...
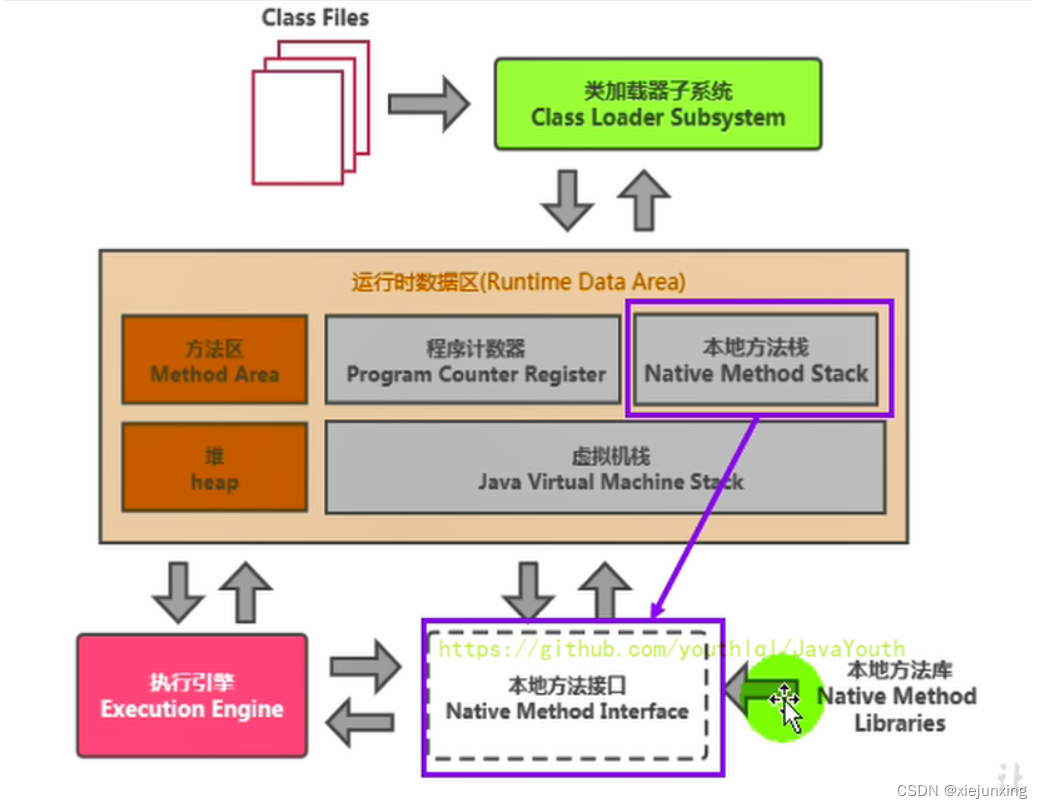
第3章-运行时数据区
此章把运行时数据区里比较少的地方讲一下。虚拟机栈,堆,方法区这些地方后续再讲。 转载https://gitee.com/youthlql/JavaYouth/tree/main/docs/JVM。 运行时数据区概述及线程 前言 本节主要讲的是运行时数据区,也就是下图这部分,…...
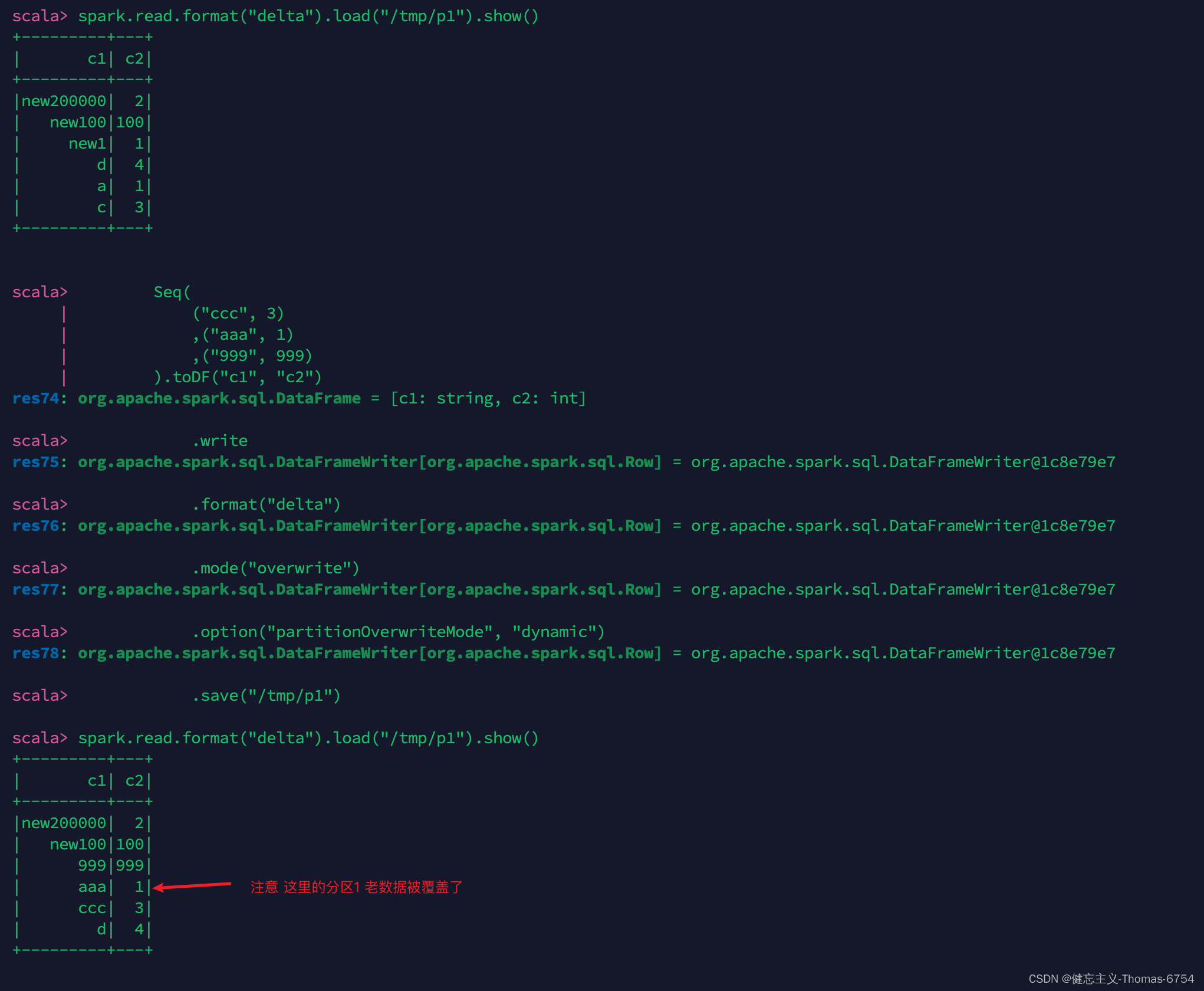
delta.io 参数 spark.databricks.delta.replaceWhere.constraintCheck.enabled
总结 默认值true 你写入的df分区字段必须全部符合覆盖条件 .option("replaceWhere", "c2 == 2") false: df1 overwrite tb1: df1中每个分区的处理逻辑: - tb1中存在(且谓词中匹配)的分区,则覆盖 - tb1中存在(谓词中不匹配)的分区,则append - tb1中不存…...

Redis知识点
1. Redis-常用数据结构 Redis提供了一些数据结构供我们往Redis中存取数据,最常用的的有5种,字符串(String)、哈希(Hash)、列表(list)、集合(set)、有序集合(zset…...
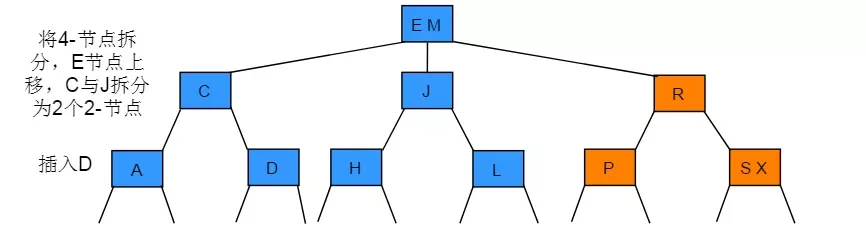
经典数据结构之2-3树
2-3树定义 2-3树,是最简单的B-树,其中2、3主要体现在每个非叶子节点都有2个或3个子节点,B-树即是平衡树,平衡树是为了解决不平衡树查询效率问题,常见的二叉平衡书有AVL树,它虽然提高了查询效率,…...

Numpy从入门到精通——节省内存|通用函数
这个专栏名为《Numpy从入门到精通》,顾名思义,是记录自己学习numpy的学习过程,也方便自己之后复盘!为深度学习的进一步学习奠定基础!希望能给大家带来帮助,爱睡觉的咋祝您生活愉快! 这一篇介绍《…...
Docker-compose 启动 lnmp 开发环境
GitHub传送阵 docker-lnmp 项目帮助开发者快速构建本地开发环境,包括Nginx、PHP、MySQL、Redis 服务镜像,支持配置文件和日志文件映射,不限操作系统;此项目适合个人开发者本机部署,可以快速切换服务版本满足学习服务新…...

《android源码阅读四》Android系统源码整编、单编并运行到虚拟机
1、编译环境 《安装Ubuntu系统》《android源码下载》 2、整编源码 进入Android源码根目录 cd AOSP初始化环境 source build/envsetup.sh清除缓存 make clobber选择编译目标 // 选择编译目标 lunch // 因为本次是在虚拟机中运行,这里使用x86 lunch aosp_x86_6…...

深度学习技巧应用8-各种数据类型的加载与处理,并输入神经网络进行训练
大家好,我是微学AI,今天给大家介绍一下深度学习技巧应用8-各种数据类型的加载与处理,并输入神经网络进行训练。在模型训练中,大家往往对各种的数据类型比较难下手,对于非结构化数据已经复杂的数据的要进行特殊处理,这里介绍一下我们如何进行数据处理才能输入到模型中,进…...

【笔试】备战秋招,每日一题|20230415携程研发岗笔试
前言 最近碰到一个专门制作大厂真题模拟题的网站 codefun2000,最近一直在上面刷题。今天来进行2023.04.15携程研发岗笔试,整理了一下自己的思路和代码。 比赛地址 A. 找到you 题意: 给定一个仅包含小写字母的 n n n\times n nn 的矩阵…...
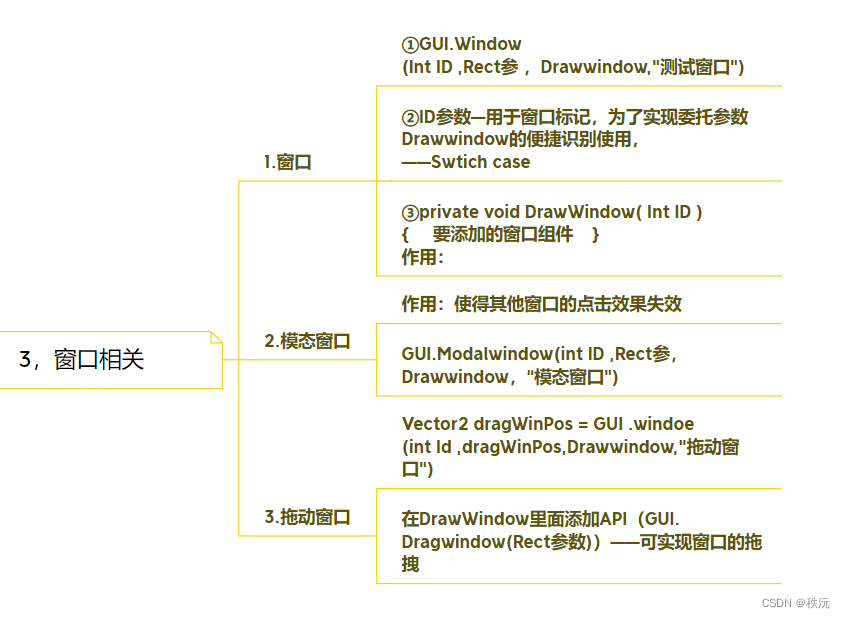
【unity专题篇】—GUI(IMGUI)思维导图详解
👨💻个人主页:元宇宙-秩沅 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 秩沅 原创 👨💻 收录于专栏:uni…...

【C++ Metaprogramming】0. 在C++中实现类似C#的泛型类
两年前,笔者因为项目原因刚开始接触C,当时就在想,如果C有类似C#中的泛型限定就好了,能让代码简单许多。我也一度认为: 虽然C有模板类,但是却没办法实现C#中泛型特有的 where 关键词: public c…...
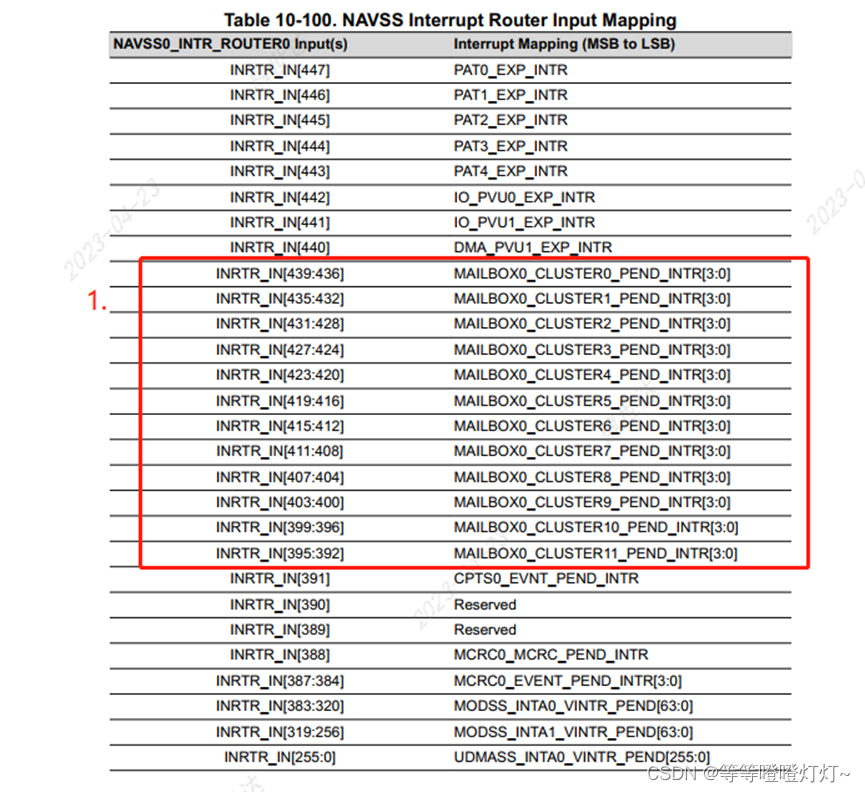
TDA4VM/VH 芯片 NAVSS0
请从官网下载 TD4VM 技术参考手册,地址如下: TDA4VM 技术参考手册地址 概述 (NAVSS0 的介绍在 TRM 的第10.2章节) NAVSS0 可以看作 MAIN 域的一个复杂外设域,实现如下功能: UDMASS: DMA 管理子系统;MODSS…...

基于springboot的前后端分离的案列(一)
SpringBootWeb案例 前面我们已经讲解了Web前端开发的基础知识,也讲解了Web后端开发的基础(HTTP协议、请求响应),并且也讲解了数据库MySQL,以及通过Mybatis框架如何来完成数据库的基本操作。 那接下来,我们就通过一个案例…...
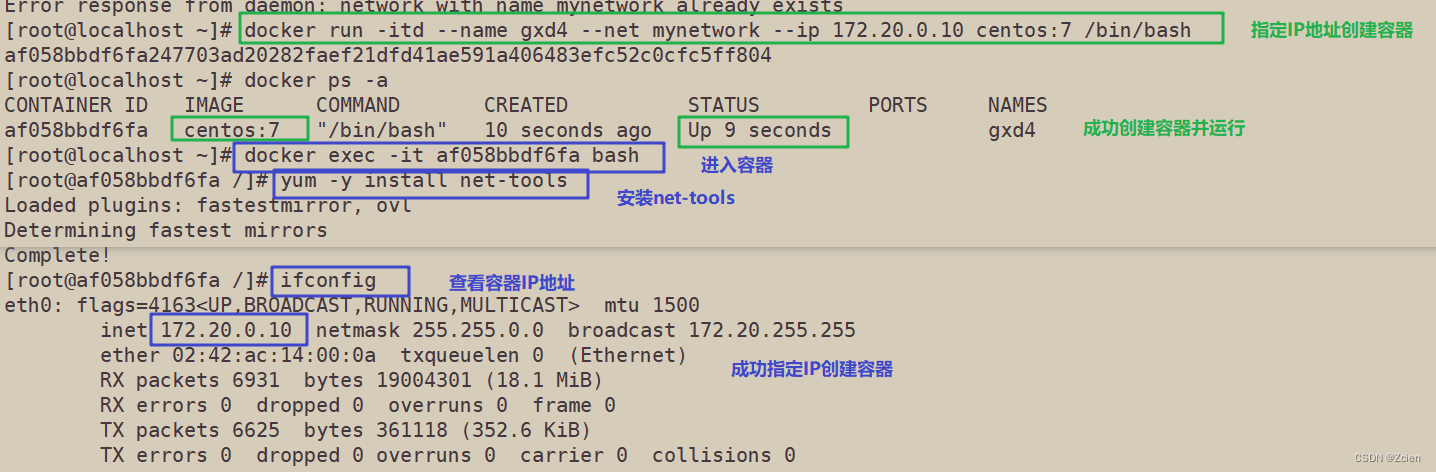
Docker网络模式详解
文章目录 一、docker网络概述1、docker网络实现的原理1.1 随机映射端口( 从32768开始)1.2 指定映射端口1.3 浏览器访问测试 二、 docker的网络模式1、默认网络2、使用docker run 创建Docker容器时,可以用--net或--network 选项指定容器的网络模式 三、docker网络模式…...
PXE高效批量网络装机
PXE 定义 PXE(预启动执行环境,在操作系统之前运行)是由Intel公司开发的网络引导技术,工作在client /server模式,允许客户机通过网络从远程服务器下载引导镜像,并加载安装文件或者整个操作系统。 具备以下三个优点 1 规模化: 同时…...

YOLOv5+双目实现三维跟踪(python)
YOLOv5双目实现三维跟踪(python) 1. 目标跟踪2. 测距模块2.1 测距原理2.2 添加测距 3. 细节修改(可忽略)4. 实验效果 相关链接 1. YOLOV5 双目测距(python) 2. YOLOV7 双目测距(python&#x…...

ESP8266使用SDK软硬件定时执行函数
1、软件定时 以下接口使用的定时器由软件实现,定时器的函数在任务中被执行。因为任务可能被中断,或者被其他高优先级的任务延迟,因此以下os_timer系列的接口并不能保证定时器精确执行。 注意: ①对于同一个 timer,os…...

非线性声学与强化学习融合的智能声学处理技术
1. 非线性声学与强化学习的融合框架解析在复杂声学环境中,传统线性声学模型往往难以应对高阶声学现象。非线性声学理论通过Westervelt方程和KZK方程等物理模型,能够准确描述声波在非线性介质中的传播特性。这些方程考虑了介质压缩性和边界反射等非线性效…...

靖江注册公司需要多少钱?2026最新费用明细与隐形消费避坑指南
对于靖江的传统小微型企业、个体工商户、夫妻店及初创公司而言,注册公司的费用多少、是否存在隐形消费,是创业初期最关心的问题。这类企业大多没有专职会计,社保参保人数通常在3人以下,注册年限多在2年内,资金预算有限…...

从理论到代码:一步步拆解单纯形法在MATLAB中的核心‘旋转运算’
从理论到代码:一步步拆解单纯形法在MATLAB中的核心‘旋转运算’ 单纯形法作为线性规划领域最经典的算法之一,其理论优雅性与计算高效性在数学优化中独树一帜。然而,当我们将教科书中的表格计算转化为编程语言实现时,往往会遇到一个…...

【网络安全】Web安全防护:从XSS到CSRF的攻防实战
【网络安全】Web安全防护:从XSS到CSRF的攻防实战 引言 Web安全是现代应用开发中不可忽视的重要环节。随着Web应用的普及,各种安全威胁也日益增多。本文将详细介绍常见的Web安全漏洞及其防护方法。 一、XSS攻击与防护 1.1 XSS类型 类型说明攻击方式存储型…...

AMD GPU本地AI模型部署终极指南:ollama-for-amd让你的Radeon显卡焕发新生
AMD GPU本地AI模型部署终极指南:ollama-for-amd让你的Radeon显卡焕发新生 【免费下载链接】ollama-for-amd Get up and running with Llama 3, Mistral, Gemma, and other large language models.by adding more amd gpu support. 项目地址: https://gitcode.com/…...

为什么所有人都在聊RAG?看这篇,小白也能彻底搞懂
你是否有过这样的经历——你满怀期待地问 AI 一个专业问题,它流畅地给了你一段"答案",引经据典、逻辑自洽。 结果一查,发现全是错的。一本正经地胡说八道。 这就是大语言模型(LLM)的致命短板:它…...
)
从Wi-Fi 6到5G:深入浅出聊聊MIMO中的CSI反馈那些事儿(PMI/RI/CQI详解)
从Wi-Fi 6到5G:深入浅出聊聊MIMO中的CSI反馈那些事儿(PMI/RI/CQI详解) 现代无线通信系统正经历着从Wi-Fi 6到5G的跨越式发展,而多天线技术(MIMO)作为提升频谱效率的核心手段,其性能很大程度上依赖于准确的信道状态信息…...

从星座图乱麻到清晰:手把手教你用OpenOFDM搞定Wi-Fi信号频偏校正
从星座图乱麻到清晰:手把手教你用OpenOFDM搞定Wi-Fi信号频偏校正 当你第一次用软件无线电(SDR)捕获Wi-Fi信号时,看到的星座图像是被猫抓过的毛线团——杂乱无章的斑点毫无规律地散布在平面上。这种令人沮丧的场景,正是…...

为什么你的 Multi-Agent 系统越加 Agent 越慢:并发与调度的反直觉陷阱
为什么你的 Multi-Agent 系统越加 Agent 越慢:并发与调度的反直觉陷阱 一、引言 钩子:90% 大模型开发者都踩过的性能悖论 你是否有过这样的经历:花了两周时间把单 Agent 的文档分析系统改造成多 Agent 协作架构,原本预期 5 个 Agent 能把处理速度提升 4 倍,结果上线后发…...
)
快速完成一篇重复率和AI率都很低的英文论文!(亲测有效)
写英文论文对于很多同学来说比较困难,今天给大家分享一下如何快速完成一篇英文论文。 直接说操作方法: 一、打开任何一个AI工具,输入指令:我是英文专业的毕业生,我的论文题目是《XXXX》,论文正文8000字&a…...