Nachos系统的上下文切换
Fork调用创建进程
在实验1中通过gdb调试初步熟悉了Nahcos上下文切换的基本流程,但这个过程还不够清晰,通过源码阅读进一步了解这个过程。
在实验1中通过执行Threadtest,Fork创建子进程,并传入SimpleThread执行currentThread->Yield()进行进程切换:
//----------------------------------------------------------------------
// SimpleThread
// Loop 5 times, yielding the CPU to another ready thread
// each iteration.
//
// "which" is simply a number identifying the thread, for debugging
// purposes.
//----------------------------------------------------------------------void
SimpleThread(_int which)
{int num;for (num = 0; num < 5; num++) {printf("*** thread %d looped %d times\n", (int) which, num);currentThread->Yield(); // 模拟时间片用完,Yield进入就绪队列}
}//----------------------------------------------------------------------
// ThreadTest
// Set up a ping-pong between two threads, by forking a thread
// to call SimpleThread, and then calling SimpleThread ourselves.
//----------------------------------------------------------------------void
ThreadTest()
{DEBUG('t', "Entering SimpleTest");Thread *t = new Thread("forked thread");t->Fork(SimpleThread, 1); // fork之后父子进程轮转协作,运行SimpleThreadSimpleThread(0);
}
在实验8中通过系统调用Exec执行Fork进行子进程的创建,传入StartProcess,与实验1不同,这个Fork是为用户程序创建进程,需要进行地址空间的拷贝,调用InitRegisters初始化CPU寄存器,调用RestoreState加载页表(在处理SC_Exec时已经分配好了用户程序的地址空间),并调用machine::run()执行。
case SC_Exec:
{printf("Execute system call of Exec()\n");// read argumentchar filename[50];int addr = machine->ReadRegister(4);int i = 0;do{// read filname from mainMemorymachine->ReadMem(addr + i, 1, (int *)&filename[i]);} while (filename[i++] != '\0');printf("Exec(%s)\n", filename);// 为halt.noff创建相应的进程以及相应的核心线程// 将该进程映射至新建的核心线程上执行beginDEBUG('x', "thread:%s\tExec(%s):\n", currentThread->getName(), filename);// if (filename[0] == 'l' && filename[1] == 's') // ls// {// DEBUG('x', "thread:%s\tFile(s) on Nachos DISK:\n", currentThread->getName());// fileSystem->List();// machine->WriteRegister(2, 127); //// AdvancePC();// return;// }// OpenFile *executable = fileSystem->OpenTest(filename);OpenFile *executable = fileSystem->Open(filename);AddrSpace *space;if (executable == NULL){printf("Unable to open file %s\n", filename);// return;ASSERT(false);}space = new AddrSpace(executable);// printf("u:Fork\n");Thread *thread = new Thread(filename);thread->Fork(StartProcess, space->getSpaceId());// end// return spaceIDmachine->WriteRegister(2, space->getSpaceId());AdvancePC();currentThread->Yield();delete executable;break;
}
Yield调度线程执行
但是Fork出的子程序并不是立即执行的!进程的调度由Scheduler负责,Fork前会将该进程加入到就绪队列中。如果我们不用任何进程调度命令,bar程序在执行完系统调用之后,会继续执行该程序剩下的指令,并不会跳转到halt程序执行,因此需要在系统调用返回前调用currentThread->Yield,切换执行halt进程,这样才是完整的Exec系统调用。
nextThread = scheduler->FindNextToRun();if (nextThread != NULL) {scheduler->ReadyToRun(this);scheduler->Run(nextThread);}
scheduler::run
Yield调用scheduler::run执行:
void
Scheduler::Run (Thread *nextThread)
{ // 运行一个新线程Thread *oldThread = currentThread;#ifdef USER_PROGRAM // ignore until running user programs // 1. 将当前CPU寄存器的内容保存到旧进程的用户寄存器中// 2. 保存用户页表if (currentThread->pcb->space != NULL) { // if this thread is a user program,currentThread->SaveUserState(); // save the user's CPU registerscurrentThread->pcb->space->SaveState();}
#endifoldThread->CheckOverflow(); // check if the old thread// had an undetected stack overflowcurrentThread = nextThread; // switch to the next threadcurrentThread->setStatus(RUNNING); // nextThread is now running// 将线程指针指向新线程DEBUG('t', "Switching from thread \"%s\" to thread \"%s\"\n",oldThread->getName(), nextThread->getName());// This is a machine-dependent assembly language routine defined // in switch.s. You may have to think// a bit to figure out what happens after this, both from the point// of view of the thread and from the perspective of the "outside world".// 从线程和外部世界的视角SWITCH(oldThread, nextThread); // 此时寄存器(非通用数据寄存器,可能是PC,SP等状态寄存器)的状态还未保存和更新DEBUG('t', "Now in thread \"%s\"\n", currentThread->getName());// If the old thread gave up the processor because it was finishing,// we need to delete its carcass. Note we cannot delete the thread// before now (for example, in Thread::Finish()), because up to this// point, we were still running on the old thread's stack!if (threadToBeDestroyed != NULL) {delete threadToBeDestroyed; // 回收旧线程的堆栈threadToBeDestroyed = NULL;}#ifdef USER_PROGRAM// 1. 如果运行用户进程,需要将当前进程的用户寄存器内存加载到CPU寄存器中// 2. 并且加载用户页表if (currentThread->pcb->space != NULL) { // if there is an address spacecurrentThread->RestoreUserState(); // to restore, do it.currentThread->pcb->space->RestoreState();}
#endif
}
①首尾两部分是用户寄存器和CPU寄存器之间的操作,将40个CPU寄存器的状态保存至用户寄存器,将新进程的用户寄存器加载至CPU寄存器,并加载用户程序页表。
②检查栈溢出。
③将currentThread指向新进程,将其状态设置为RUNNING。
④调用汇编程序SWITCH,实验1中此处的注释是该程序保存并更新寄存器的状态,可是这不是在①部分code做的事情?
⑤回收进程堆栈。
SWITCH初步探索
结合源码进行分析:
#ifdef HOST_i386
/* void SWITCH( thread *t1, thread *t2 )
**
** on entry, stack looks like this:
** 8(esp) -> thread *t2
** 4(esp) -> thread *t1
** (esp) -> return address
**
** we push the current eax on the stack so that we can use it as
** a pointer to t1, this decrements esp by 4, so when we use it
** to reference stuff on the stack, we add 4 to the offset.
*/.comm _eax_save,4.globl _SWITCH
_SWITCH:movl %eax,_eax_save # save the value of eaxmovl 4(%esp),%eax # move pointer to t1 into eaxmovl %ebx,_EBX(%eax) # save registersmovl %ecx,_ECX(%eax)movl %edx,_EDX(%eax)movl %esi,_ESI(%eax)movl %edi,_EDI(%eax)movl %ebp,_EBP(%eax)movl %esp,_ESP(%eax) # save stack pointermovl _eax_save,%ebx # get the saved value of eaxmovl %ebx,_EAX(%eax) # store itmovl 0(%esp),%ebx # get return address from stack into ebxmovl %ebx,_PC(%eax) # save it into the pc storagemovl 8(%esp),%eax # move pointer to t2 into eax......movl _eax_save,%eaxret#endif // HOST_i386
的确是寄存器的保存与加载,但这个寄存器和前面的CPU、用户寄存器有什么不同?实际上它们对应0-32(Step=4)之间数字。
#define _ESP 0
#define _EAX 4
#define _EBX 8
#define _ECX 12
#define _EDX 16
#define _EBP 20
#define _ESI 24
#define _EDI 28
#define _PC 32
StackAllocate开辟堆栈存储进程信息
关注Thread::StackAllocate,将无关部分删除。可看到该函数在StartProcess中也被调用,用于为进程创建堆栈,是的,Nachos的堆栈并不是在内存中进行创建,内存中仅仅存放了noff文件加载进来的内容。
调用AllocBoundedArray分配了StackSize 的堆栈空间,之后将stack+StackSize-4的位置设置为栈顶stackTop,之后在stack位置处设置了一个标志STACK_FENCEPOST,用于检查堆栈溢出(②),当该标志被修改,代表堆栈溢出了。也就是stack维护栈底,stackTop维护栈顶。
ASSERT((unsigned int)*stack == STACK_FENCEPOST);
void
Thread::StackAllocate (VoidFunctionPtr func, _int arg)
{ // 栈分配stack = (int *) AllocBoundedArray(StackSize * sizeof(_int));// i386 & MIPS & SPARC & ALPHA stack works from high addresses to low addressesstackTop = stack + StackSize - 4; // -4 to be on the safe side!*stack = STACK_FENCEPOST; machineState[PCState] = (_int) ThreadRoot;machineState[StartupPCState] = (_int) InterruptEnable;machineState[InitialPCState] = (_int) func;machineState[InitialArgState] = arg;machineState[WhenDonePCState] = (_int) ThreadFinish;
}
注意到Thread类将stackTop和machineState的定义提前了,而SWITCH的参数为Thread*,其操作的也是0偏移量为32以内的内存单元,因此SWITCH操作的“寄存器”就是stackTop和machineState,以及Linux系统的寄存器%ebx,%eax,%esp等等。
class Thread {private: // 特意提前,保证SWITCH例程正常// NOTE: DO NOT CHANGE the order of these first two members.// THEY MUST be in this position for SWITCH to work.int* stackTop; // the current stack pointer_int machineState[MachineStateSize]; // all registers except for stackToppublic:
结合下面宏定义,了解machineState中各个寄存器存储内容的含义。
#define PCState (_PC/4-1)
#define FPState (_EBP/4-1)
#define InitialPCState (_ESI/4-1)
#define InitialArgState (_EDX/4-1)
#define WhenDonePCState (_EDI/4-1)
#define StartupPCState (_ECX/4-1)
ThreadRoot维护进程的生命周期
那么machineState的“寄存器”存储了哪些信息?有什么作用?SWITCH之后Linux系统PC保存的应该是ThreadRoot的起始地址,因为4(%esp)是SWITCH的返回地址,它被设置为ThreadRoot的起始地址。这个函数模拟了一个进程的“一生”,初始化,执行,到终结。下面这几个调用函数的地址在StackAllocate最末尾被存储在machineState中,并在SWITCH中装载到Linux系统的寄存器中。
#define InitialPC %esi
#define InitialArg %edx
#define WhenDonePC %edi
#define StartupPC %ecx
.text.align 2.globl _ThreadRoot/* void ThreadRoot( void )
**
** expects the following registers to be initialized:
** eax points to startup function (interrupt enable)
** edx contains inital argument to thread function
** esi points to thread function
** edi point to Thread::Finish()
*/
_ThreadRoot:pushl %ebpmovl %esp,%ebppushl InitialArgcall StartupPCcall InitialPCcall WhenDonePC# NOT REACHEDmovl %ebp,%esppopl %ebpret
SWITCH更新Linux寄存器状态
现在可以回答最开始的问题了,SWITCH程序保存和更新的是Linux系统寄存器的内容,将其保存到machinState寄存器中。不同于Nachos的用户寄存器和CPU寄存器,这两者是在执行用户程序时才会使用到,用于保存用户指令和机器指令的结果和状态,前者是Nachos得以在Linux机器上运行的基础,这也是为什么它必须要通过汇编代码实现的原因,要操纵Linux系统的寄存器。
回收进程堆栈
scheduler::run最后的语句,回收线程堆栈,这时当前线程仍然在执行,它回收的肯定不是当前线程的堆栈!实际上是已经结束的线程,执行Thread::Finish,会将threadToBeDestroyed指向自己。而Finish是在进程终结之时执行,ThreadRoot中call WhenDonePC就是执行Finish。It all makes sense!
总结
之前在阅读scheduler::run的时候,有一段SWITCH注释让我很迷惑,“You may have to think a bit to figure out what happens after this, both from the point of view of the thread and from the perspective of the “outside world”.”,这个从外部世界去看是什么意思?现在,我也许有了答案。Nachos终归是运行在Linux上的操作系统,用了很多设计Timer,Scheduler,Interrupt模拟了machine,也就是硬件,但是归根结底,它只是运行在Linux系统上的一个进程,Linux系统的PC寄存器保存着Nachos“程序”正在执行的指令地址,为了实现Nachos系统的进程切换,在Linux的一个进程中的一个部分(Nachos进程)跳转到另一个部分,必须修改Linux系统的PC寄存器以及其他寄存器。为了操作Linux系统的寄存器,也就是实际物理硬件的寄存器,必须通过汇编程序进行,因此有了两个SWITCH和ThreadRoot两个汇编方法调用。在Nachos上下文切换中,前者更新Linux寄存器的内容,后者管理进程(除了在Initialize方法中创建的第一个线程main)的生命周期,通过Linux寄存器调用进程初始化StartupPC,运行InitialPC,终结WhenDonePC的3个过程。
相关文章:
Nachos系统的上下文切换
Fork调用创建进程 在实验1中通过gdb调试初步熟悉了Nahcos上下文切换的基本流程,但这个过程还不够清晰,通过源码阅读进一步了解这个过程。 在实验1中通过执行Threadtest,Fork创建子进程,并传入SimpleThread执行currentThread->…...
streamx平台部署
一. streamx介绍 StreamPark 总体组件栈架构如下, 由 streampark-core 和 streampark-console 两个大的部分组成 , streampark-console 是一个非常重要的模块, 定位是一个综合实时数据平台,流式数仓平台, 低代码 ( Low Code ), Flink & Spark 任务托…...

css中的background属性
文章目录 一:background-repeat二:background-position三:background缩写方式三:background-size四:background-origin五:background-clip 在日常前端开发中,经常需要进行背景或背景图的处理。但…...

代码评审平台Gerrit安装配置方法介绍
Gerrit是一款开源免费的基于 web 的代码审查工具,是基于 Git 的版本控制系统。在代码入库之前对开发人员的提交进行审阅,检视通过的代码才能提交入库。本文记录如何安装部署gerrit平台。 目录 Gerrit简介环境准备1. 安装Java2. 安装Git3. 安装nginx4. 安…...
一篇文章解决Mysql8
基于尚硅谷的Mysql8.0视频,修修改改。提取了一些精炼的内容。 首先需要在数据库内引入一张表。链接地址如下。 链接:https://pan.baidu.com/s/1DD83on3J1a2INI7vrqPe4A 提取码:68jy 会进行持续更新。。 1. Mysql目录结构 Mysql的目录结构…...

【Python】【进阶篇】6、Django视图函数
目录 6、Django视图函数1. 第一个视图函数1)HttpResponse视图响应类型2)视图函数参数request3)return视图响应 2. 视图函数执行过程 6、Django视图函数 视图是 MTV 设计模式中的 V 层,它是实现业务逻辑的关键层,可以用…...

Latex常用符号和功能记录
公式下括号 \underbrace & \overbrace \begin{equation} \underbrace{L_1L_2}_{loss ~ 1} \overbrace{L_3L_4}^{loss ~ 2} \end{equation}L L 1 L 2 ⏟ l o s s 1 L 3 L 4 ⏞ l o s s 2 L \underbrace{L_1L_2}_{loss ~ 1} \overbrace{L_3L_4}^{loss ~ 2} Lloss 1…...
MySQL高级篇——索引的创建与设计原则
导航: 【黑马Java笔记踩坑汇总】JavaSEJavaWebSSMSpringBoot瑞吉外卖SpringCloud黑马旅游谷粒商城学成在线牛客面试题 目录 一、索引的分类与使用 1.1 索引的分类 1.1.1. 普通索引 1.1.2. 唯一性索引 1.1.3. 主键索引(唯一非空) 1.1.4…...

王一茗: “大数据能力提升项目”与我的成长之路 | 提升之路系列(三)
导读 为了发挥清华大学多学科优势,搭建跨学科交叉融合平台,创新跨学科交叉培养模式,培养具有大数据思维和应用创新的“π”型人才,由清华大学研究生院、清华大学大数据研究中心及相关院系共同设计组织的“清华大学大数据能力提升项…...
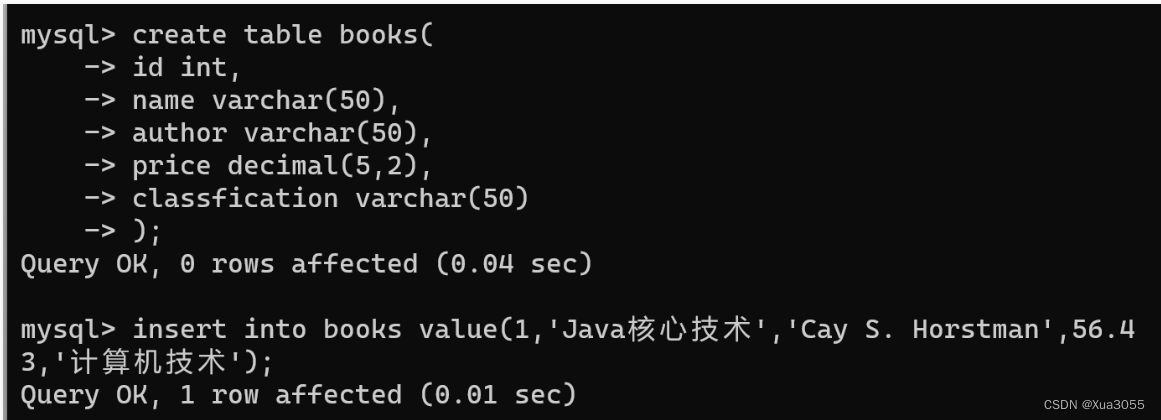
MySQL:数据库的基本操作
MySQL是一个客户端服务器结构的程序, 一.关系型数据库 关系型数据库是一个结构化的数据库,创建在关系模型(二维表格模型)基础上,一般面向于记录。 主流的关系型数据库包括 Oracle、MySQL、SQL Server、Microsoft Access、DB2 等. …...
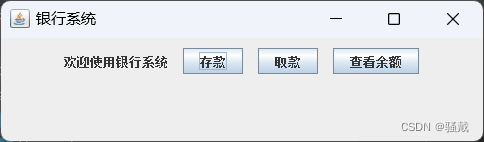
银行系统【GUI/Swing+MySQL】(Java课设)
系统类型 Swing窗口类型Mysql数据库存储数据 使用范围 适合作为Java课设!!! 部署环境 jdk1.8Mysql8.0Idea或eclipsejdbc 运行效果 本系统源码地址:https://download.csdn.net/download/qq_50954361/87708777 …...

【社区图书馆】-《科技服务与价值链》总结
【为什么研究价值链】 价值链及价值链协同体系是现代产业集群的核心枢纽,是推进城市群及产业集群化、服务化、生态化发展的纽带。因而推进价值链协同,创新发展价值链协同业务科技资源体系,既是科技服务业创新的重要方向,也是重塑生…...
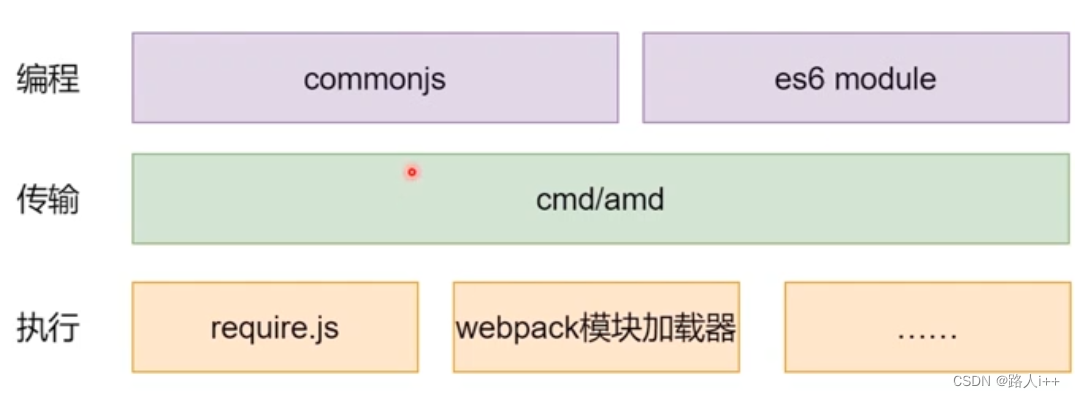
工具链和其他-异步模块加载
目录 CMD/AMD Asynchronous Module Definition(AMD异步模块定义,语法风格) Common Module Definition ES6/CommonJS CommonJS ES6 Module 加载器示例 总结 cmd和amd的区别 现在有哪些异步加载方式 整体结构 编程:commonjs es6 module (有可能解…...

第一次使用R语言
在R语言中,“<-”符号与“”意义一样。另一种奇怪的R语言的等号表示方法,是以“->”表示,但是用得少。 有些计算机语言,变量在使用前要先定义,R语言则不需先定义,可在程序中直接设定使用。 若在Con…...

《语文教学通讯》栏目 收稿范围
《语文教学通讯》创刊于1978年,是由山西师范大学主管,山西师大教育科技传媒集团主办的期刊。历年被人民大学书报资料中心转载、复印的篇幅数量均居同类报刊之首。国内刊号:CN 14-1017/G4,国际刊号:ISSN 1004-6097&…...

Towards Principled Disentanglement for Domain Generalization
本文用大量的理论论述了基于解纠缠约束优化的域泛化问题。 这篇文章认为以往的文章在解决域泛化问题时所用的方法都是non-trivial的,也就是说没有作严格的证明,是不可解释的,而本文用到大量的定理和推论证明了方法的有效性。 动机 因为域泛…...
计算机网络学习02
1、TCP 与 UDP 的区别? 是否面向连接 : UDP 在传送数据之前不需要先建立连接。而 TCP 提供面向连接的服务,在传送数据之前必须先建立连接,数据传送结束后要释放连接。是否是可靠传输: 远地主机在收到 UDP 报文后&…...

网络交换机端口管理工具
如今,企业或组织级网络使用数百个交换机端口作为其 IT 基础架构的一部分来实现网络连接。这使得交换机端口管理成为日常网络管理任务的一部分。传统上,网络管理员必须依靠手动网络交换机端口管理技术来跟踪交换机及其端口连接状态。这种手动任务弊大于利…...

redis五大命令kv设计建议内存淘汰
什么是redis?主要作用? redis(remote dictionary server)远程字典服务:是一个开源的使用ANSI C语言编写,支持网络、可基于内存可持久化的日志型、key-value数据库,并提供多种语言的api redis的数据存在内存中ÿ…...
如何真正认识 Linux 系统结构?这篇文章告诉你
Linux 系统一般有 4 个主要部分:内核、shell、文件系统和应用程序。内核、shell 和文件系统一起形成了基本的操作系统结构,它们使得用户可以运行程序、管理文件并使用系统。 Linux内核 内核是操作系统的核心,具有很多最基本功能,…...

Tycoon2FA 利用 OAuth 设备码钓鱼劫持 Microsoft 365 账户的机理与防御
摘要 以 Tycoon2FA 为代表的钓鱼即服务平台正采用基于 OAuth 2.0 设备码流程的新型钓鱼攻击,针对 Microsoft 365 账户实施高隐蔽性劫持。该攻击不窃取明文口令与传统双因素验证码,而是诱导用户在微软官方认证页面完成设备授权,使攻击者获取合…...
)
理光MP C2500扫描到共享文件夹保姆级教程(附Windows 10/11权限避坑指南)
理光MP C2500扫描到共享文件夹全流程解决方案与Windows权限深度优化 办公室里那台老当益壮的理光MP C2500复合机,至今仍是许多中小企业的生产力主力。但当IT管理员尝试配置"扫描到共享文件夹"功能时,往往会遭遇浏览网络空白、权限拒绝等"…...

百考通AI让开题报告成为研究助力,而非负担
开题报告是毕业论文或学位研究的“第一块基石”,它不仅决定你的选题能否通过,更直接影响后续研究的深度、逻辑与可行性。然而,许多学生在撰写时常常陷入困境:问题意识模糊、文献综述堆砌无主线、研究方法描述空泛、结构松散不规范…...

STM32图像识别实战:从传统CV到TinyML的边缘AI部署
1. 项目概述:当STM32遇上图像识别在嵌入式开发领域,STM32系列微控制器因其出色的性能、丰富的外设和极高的性价比,早已成为工程师和爱好者的“瑞士军刀”。从简单的LED闪烁到复杂的电机控制、通信协议栈,STM32几乎无所不能。但提到…...

ARM核心板存储选型实战:从DDR到eMMC的避坑指南
1. 项目概述:一个被低估的硬件选型难题在嵌入式系统开发,尤其是基于ARM架构的工控和核心板设计中,存储选型常常被新手甚至一些有经验的工程师视为一个“小问题”。不就是选个Flash和RAM吗?很多人会这么想。然而,在我十…...

Perplexity+本地新闻知识库构建全流程,含Geo-Tagged新闻切片、时效性分级索引、突发新闻优先推送机制
更多请点击: https://kaifayun.com 第一章:Perplexity本地新闻查询 Perplexity 是一款以实时信息检索与引用溯源见长的 AI 助手,其默认依赖联网搜索获取新闻内容。但在离线或隐私敏感场景下,用户可通过本地化部署方案构建轻量级…...
的结构、功能及医学应用研究进展)
白介素-5(IL-5)的结构、功能及医学应用研究进展
摘要白介素-5(Interleukin-5,IL-5)是一种由Th2细胞、嗜酸性粒细胞祖细胞等免疫细胞分泌的多功能细胞因子,在调节免疫反应、尤其是嗜酸性粒细胞(Eosinophil, EOS)的分化、存活及功能活化中发挥核心作用。自1…...
产业深度分析报告(附下载))
2026年人工智能(AI)产业深度分析报告(附下载)
人工智能正从“技术验证”迈向“产业化规模落地”的关键转折期。Gartner指出,AI在整个2026年将处于泡沫破灭低谷期,企业在多数情况下会选择通过现有软件供应商获取AI能力,只有当投资回报率的可预测性得到提升后,企业才能真正实现A…...

CH340G模块除了下载程序,还能这么玩?一个硬件调试小技巧分享
CH340G模块的隐藏技能:用串口调试提升硬件开发效率 当你拿到一片CH340G模块时,第一反应可能是"这是个下载程序的好工具"。确实,这个价格亲民的小模块在51单片机开发中扮演着重要角色。但今天,我要分享的是它另一个被低估…...

STM32F103C8T6的MODBUS-RTU从机实战:基于RS485的寄存器读写
1. MODBUS-RTU与STM32F103C8T6的工业应用价值 在工业自动化领域,设备间的可靠通信是系统稳定运行的基础。STM32F103C8T6作为一款性价比极高的Cortex-M3内核微控制器,配合MODBUS-RTU协议和RS485物理层,能够构建出稳定高效的设备监控网络。这种…...