本地缓存解决方案Caffeine | Spring Cloud 38
一、Caffeine简介
Caffeine是一款高性能、最优缓存库。Caffeine是受Google guava启发的本地缓存(青出于蓝而胜于蓝),在Cafeine的改进设计中借鉴了 Guava 缓存和 ConcurrentLinkedHashMap,Guava缓存可以参考上篇:本地缓存解决方案GuavaCache | Spring Cloud 37,就和Mybatis与Mybatis Plus一样。Caffeine也是Spring5.X后使用的缓存框架,作为Spring推荐的缓存框架我们有必要了解一下。
Caffeine官网地址:https://github.com/ben-manes/caffeine/wiki/Home-zh-CN
以下为截取官网的部分测试结果:
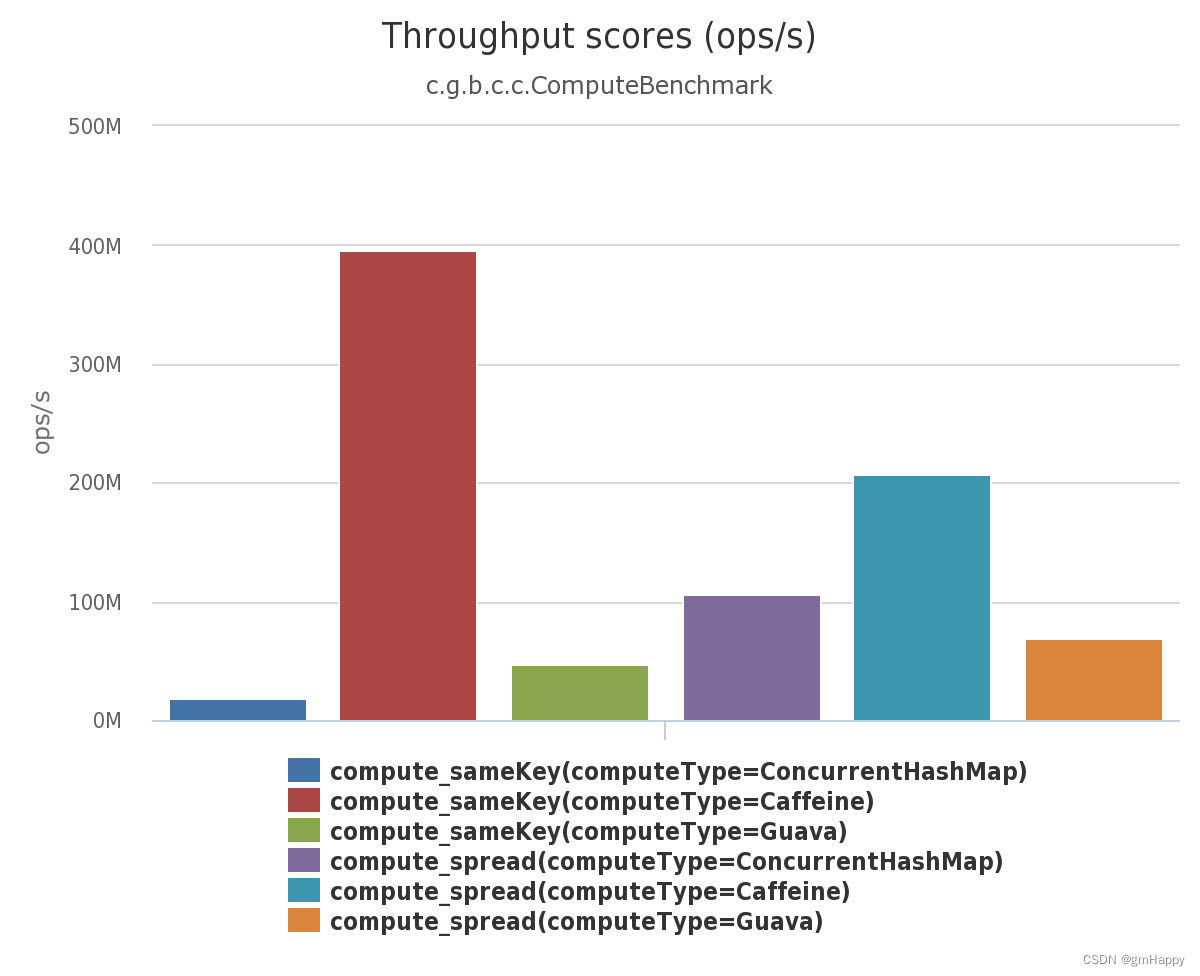
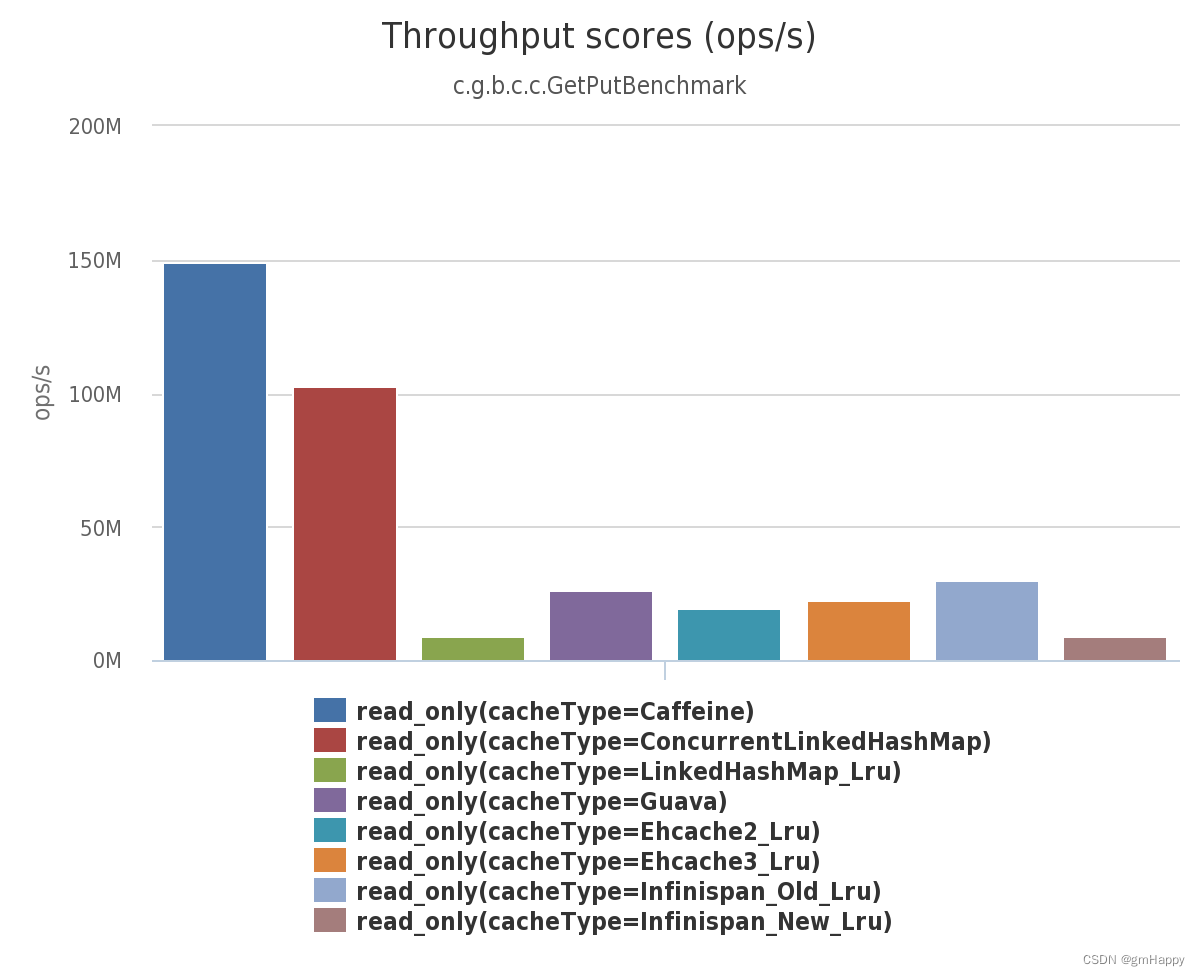
详细基准测试结果请见:https://github.com/ben-manes/caffeine/wiki/Benchmarks-zh-CN
二、应用及特性说明
2.1 Maven依赖
<dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId><version>2.9.3</version>
</dependency>
注意
Caffeine的版本需要和JDK版本对应:
2.X版本对应JDK为83.X版本对应的JDK版本为11
2.2 缓存添加
Caffeine提供了四种缓存添加策略:手动加载,自动加载,手动异步加载和自动异步加载。
2.2.1 手动加载
private static void manual() {// 构建caffeine的缓存对象,并指定在写入后的10分钟内有效,且最大允许写入的条目数为10000Cache<String, String> cache = Caffeine.newBuilder().expireAfterWrite(10, TimeUnit.MINUTES).maximumSize(10_000).build();String key = "hello";// 查找某个缓存元素,若找不到则返回nullString str = cache.getIfPresent(key);System.out.println("cache.getIfPresent(key) ---> " + str);// 查找某个缓存元素,若找不到则调用函数生成,如无法生成则返回nullstr = cache.get(key, k -> create(key));System.out.println("cache.get(key, k -> create(key)) ---> " + str);// 添加或者更新一个缓存元素cache.put(key, str);System.out.println("cache.put(key, str) ---> " + cache.getIfPresent(key));// 移除一个缓存元素cache.invalidate(key);System.out.println("cache.invalidate(key) ---> " + cache.getIfPresent(key));
}private static String create(Object key) {return key + " world";
}
Cache 接口提供了显式搜索查找、更新和移除缓存元素的能力。
缓存元素可以通过调用 cache.put(key, value)方法被加入到缓存当中。如果缓存中指定的key已经存在对应的缓存元素的话,那么先前的缓存的元素将会被直接覆盖掉。因此,通过 cache.get(key, k -> value) 的方式将要缓存的元素通过原子计算的方式 插入到缓存中,以避免和其他写入进行竞争。值得注意的是,当缓存的元素无法生成或者在生成的过程中抛出异常而导致生成元素失败,cache.get 也许会返回 null 。
当然,也可以使用Cache.asMap()所暴露出来的ConcurrentMap的方法对缓存进行操作。
2.2.2 自动加载
public static void loading() {LoadingCache<String, String> cache = Caffeine.newBuilder().maximumSize(10_000).expireAfterWrite(10, TimeUnit.MINUTES).build(key -> create(key)); // 当调用get或者getAll时,若找不到缓存元素,则会统一调用create(key)生成String key = "hello";String str = cache.get(key);System.out.println("cache.get(key) ---> " + str);List<String> keys = Arrays.asList("a", "b", "c", "d", "e");// 批量查找缓存元素,如果缓存不存在则生成缓存元素Map<String, String> maps = cache.getAll(keys);System.out.println("cache.getAll(keys) ---> " + maps);
}private static String create(Object key) {return key + " world";
}
LoadingCache是一个Cache 附加上 CacheLoader能力之后的缓存实现。
通过 getAll可以达到批量查找缓存的目的。 默认情况下,在getAll 方法中,将会对每个不存在对应缓存的key调用一次 CacheLoader.load 来生成缓存元素。 在批量检索比单个查找更有效率的场景下,你可以覆盖并开发CacheLoader.loadAll 方法来使你的缓存更有效率。
值得注意的是,你可以通过实现一个 CacheLoader.loadAll并在其中为没有在参数中请求的key也生成对应的缓存元素。打个比方,如果对应某个key生成的缓存元素与包含这个key的一组集合剩余的key所对应的元素一致,那么在loadAll中也可以同时加载剩下的key对应的元素到缓存当中。
2.2.3 手动异步加载
private static void asynchronous() {AsyncCache<String, String> cache = Caffeine.newBuilder().expireAfterWrite(10, TimeUnit.MINUTES).maximumSize(10_000).buildAsync();String key = "Hello";// 查找某个缓存元素,若找不到则返回nullCompletableFuture<String> value = cache.getIfPresent(key);// 查找某个缓存元素,若不存在则异步调用create方法生成value = cache.get(key, k -> create(key));// 添加或者更新一个缓存元素cache.put(key, value);// 移除一个缓存元素cache.synchronous().invalidate(key);
}private static String create(Object key) {return key + " world";
}
AsyncCache 是 Cache 的一个变体,AsyncCache提供了在 Executor上生成缓存元素并返回 CompletableFuture的能力。这给出了在当前流行的响应式编程模型中利用缓存的能力。
synchronous()方法给 Cache提供了阻塞直到异步缓存生成完毕的能力。
当然,也可以使用 AsyncCache.asMap()所暴露出来的ConcurrentMap的方法对缓存进行操作。
默认的线程池实现是 ForkJoinPool.commonPool() ,当然你也可以通过覆盖并实现 Caffeine.executor(Executor)方法来自定义你的线程池选择。
2.2.4 自动异步加载
private static void asynchronouslyLoading() {AsyncLoadingCache<String, String> cache = Caffeine.newBuilder().maximumSize(10_000).expireAfterWrite(10, TimeUnit.MINUTES)// 异步构建一个同步的调用方法create(key).buildAsync(key -> create(key));// 也可以使用下面的方式来异步构建缓存,并返回一个future// .buildAsync((key, executor) -> createAsync(key, executor));String key = "Hello";// 查找某个缓存元素,若找不到则会异步生成。CompletableFuture<String> value = cache.get(key);List<String> keys = Arrays.asList("a", "b", "c", "d", "e");// 批量查找某些缓存元素,若找不到则会异步生成。CompletableFuture<Map<String, String>> values = cache.getAll(keys);
}private static String create(Object key) {return key + " world";
}
AsyncLoadingCache是一个 AsyncCache 加上 AsyncCacheLoader能力的实现。
在需要同步的方式去生成缓存元素的时候,CacheLoader是合适的选择。而在异步生成缓存的场景下, AsyncCacheLoader则是更合适的选择并且它会返回一个 CompletableFuture。
通过 getAll可以达到批量查找缓存的目的。 默认情况下,在getAll 方法中,将会对每个不存在对应缓存的key调用一次 AsyncCacheLoader.asyncLoad 来生成缓存元素。 在批量检索比单个查找更有效率的场景下,你可以覆盖并开发AsyncCacheLoader.asyncLoadAll 方法来使你的缓存更有效率。
值得注意的是,你可以通过实现一个 AsyncCacheLoader.asyncLoadAll并在其中为没有在参数中请求的key也生成对应的缓存元素。打个比方,如果对应某个key生成的缓存元素与包含这个key的一组集合剩余的key所对应的元素一致,那么在asyncLoadAll中也可以同时加载剩下的key对应的元素到缓存当中。
private static void timeBased() {// 自上一次写入或者读取缓存开始,在经过指定时间之后过期。LoadingCache<String, String> fixedAccess = Caffeine.newBuilder().expireAfterAccess(5, TimeUnit.MINUTES).build(key -> create(key));// 自缓存生成后,经过指定时间或者一次替换值之后过期。LoadingCache<String, String> fixedWrite = Caffeine.newBuilder().expireAfterWrite(5, TimeUnit.MINUTES).build(key -> create(key));// 自定义缓存过期策略,可以在创建时,写入后、读取时。LoadingCache<String, String> varying = Caffeine.newBuilder().expireAfter(new Expiry<String, String>() {public long expireAfterCreate(String key, String value, long currentTime) {return currentTime;}public long expireAfterUpdate(String key, String value, long currentTime, long currentDuration) {return currentDuration;}public long expireAfterRead(String key, String value, long currentTime, long currentDuration) {return currentDuration;}}).build(key -> create(key));
}
2.3 驱逐策略
Caffeine 提供了三种驱逐策略,分别是基于容量,基于时间和基于引用三种类型。
本文重点描述时间驱逐策略,其他驱逐策略请见官网:https://github.com/ben-manes/caffeine/wiki/Eviction-zh-CN
Caffeine提供了三种方法进行基于时间的驱逐策略:
-
expireAfterAccess(long, TimeUnit): 一个元素在上一次读写操作后一段时间之后,在指定的时间后没有被再次访问将会被认定为过期项。在当被缓存的元素时被绑定在一个session上时,当session因为不活跃而使元素过期的情况下,这是理想的选择。
-
expireAfterWrite(long, TimeUnit): 一个元素将会在其创建或者最近一次被更新之后的一段时间后被认定为过期项。在对被缓存的元素的时效性存在要求的场景下,这是理想的选择。
-
expireAfter(Expiry): 一个元素将会在指定的时间后被认定为过期项。当被缓存的元素过期时间受到外部资源影响的时候,这是理想的选择。
为了使过期更有效率,可以通过在你的Cache构造器中通过Scheduler接口和Caffeine.scheduler(Scheduler) 方法去指定一个调度线程代替在缓存活动中去对过期事件进行调度。使用Java 9以上版本的用户可以选择Scheduler.systemScheduler()利用系统范围内的调度线程。
在默认情况下,当一个缓存元素过期的时候,Caffeine 不会自动立即将其清理和驱逐。而它将会在写操作之后进行少量的维护工作,在写操作较少的情况下,也偶尔会在读操作之后进行。如果你的缓存吞吐量较高,那么你不用去担心你的缓存的过期维护问题。但是如果你的缓存读写操作都很少,可以额外通过一个线程使用 Cache.cleanUp() 方法在合适的时候触发清理操作。
private static void customTime() throws InterruptedException {LoadingCache<String, String> cache = Caffeine.newBuilder().scheduler(Scheduler.forScheduledExecutorService(Executors.newScheduledThreadPool(1))).evictionListener((String key, String value, RemovalCause cause) -> {log.info("EvictionListener key {} was removed {}", key, cause);try {TimeUnit.SECONDS.sleep(2);} catch (InterruptedException e) {throw new RuntimeException(e);}}).removalListener((String key, String value, RemovalCause cause) -> {log.info("RemovalListener key {} was removed {}", key, cause);try {TimeUnit.SECONDS.sleep(2);} catch (InterruptedException e) {throw new RuntimeException(e);}}).expireAfter(new Expiry<String, String>() {@Overridepublic long expireAfterCreate(@NonNull String key, @NonNull String value, long currentTime) {// 这里的currentTime由Ticker提供,默认情况下与系统时间无关,单位为纳秒log.info("expireAfterCreate----key:{},value:{},currentTime:{}", key, value, currentTime);return TimeUnit.SECONDS.toNanos(10);}@Overridepublic long expireAfterUpdate(@NonNull String key, @NonNull String value, long currentTime, @NonNegative long currentDuration) {// 这里的currentTime由Ticker提供,默认情况下与系统时间无关,单位为纳秒log.info("expireAfterUpdate----key:{},value:{},currentTime:{},currentDuration:{}", key, value, currentTime, currentDuration);return TimeUnit.SECONDS.toNanos(5);}@Overridepublic long expireAfterRead(@NonNull String key, @NonNull String value, long currentTime, @NonNegative long currentDuration) {// 这里的currentTime由Ticker提供,默认情况下与系统时间无关,单位为纳秒log.info("expireAfterRead----key:{},value:{},currentTime:{},currentDuration:{}", key, value, currentTime, currentDuration);return TimeUnit.SECONDS.toNanos(5);}}).build(key -> create(key));String one = cache.get("one");log.info("第一次获取one:{}", one);String two = cache.get("two");log.info("第一次获取two:{}", two);cache.put("one", one + "_new");log.info("---------------开始休眠5秒---------------");Thread.sleep(5000);log.info("---------------结束休眠5秒---------------");one = cache.get("one");log.info("第二次获取one:{}", one);two = cache.get("two");log.info("第二次获取two:{}", two);log.info("---------------开始休眠10秒---------------");Thread.sleep(10000);log.info("---------------结束休眠10秒---------------");one = cache.get("one");log.info("第三次获取one:{}", one);two = cache.get("two");log.info("第三次获取two:{}", two);Thread.sleep(20000);//cache.cleanUp();Thread.sleep(20000);
}private static String create(String key) {log.info("自动加载数据:{}", key);return UUID.randomUUID().toString();
}
2.4 缓存移除
- 驱逐 缓存元素因为策略被移除
- 失效 缓存元素被手动移除
- 移除 由于驱逐或者失效而最终导致的结果
2.4.1 显式移除
在任何时候,你都可以手动去让某个缓存元素失效而不是只能等待其因为策略而被驱逐。
// 失效key
cache.invalidate(key)
// 批量失效key
cache.invalidateAll(keys)
// 失效所有的key
cache.invalidateAll()
2.4.2 移除监听器
Cache<Key, Graph> graphs = Caffeine.newBuilder().evictionListener((String key, String value, RemovalCause cause) ->log.info("EvictionListener key {} was removed {}", key, cause)).removalListener((String key, String value, RemovalCause cause) ->log.info("RemovalListener key {} was removed {}", key, cause)).build();
你可以为你的缓存通过Caffeine.removalListener(RemovalListener)方法定义一个移除监听器在一个元素被移除的时候进行相应的操作。这些操作是使用 Executor 异步执行的,其中默认的 Executor 实现是 ForkJoinPool.commonPool() 并且可以通过覆盖Caffeine.executor(Executor)方法自定义线程池的实现。
当移除之后的自定义操作必须要同步执行的时候,你需要使用 Caffeine.evictionListener(RemovalListener) 。这个监听器将在 RemovalCause.wasEvicted() 为 true 的时候被触发。
使用
Caffeine.evictionListener(RemovalListener)监听器时,因是同步执行故对缓存添加操作造成影响。详见2.3中代码说明和示例。
2.5 缓存刷新
private static String create(String key) {log.info("自动加载数据:{}", key);return UUID.randomUUID().toString();
}private static void refresh() throws InterruptedException {LoadingCache<String, String> cache = Caffeine.newBuilder().scheduler(Scheduler.forScheduledExecutorService(Executors.newScheduledThreadPool(1))).evictionListener((String key, String value, RemovalCause cause) -> {log.info("EvictionListener key {} was removed {}", key, cause);}).removalListener((String key, String value, RemovalCause cause) -> {log.info("RemovalListener key {} was removed {}", key, cause);}).expireAfterWrite(10, TimeUnit.SECONDS).build(key -> create(key));String one = cache.get("one");log.info("第一次获取one:{}", one);String two = cache.get("two");log.info("第一次获取two:{}", two);log.info("---------------开始休眠30秒---------------");Thread.sleep(30000);log.info("---------------结束休眠30秒---------------");one = cache.get("one");log.info("第二次获取one:{}", one);two = cache.get("two");log.info("第二次获取two:{}", two);
}
refresh只有在LoadingCache或者AsyncLoadingCache时才能使用,与驱逐不同之处,
异步为key对应的缓存元素刷新一个新的值。与驱逐不同的是,在刷新的时候如果查询缓存元素,其旧值将仍被返回,直到该元素的刷新完毕后结束后才会返回刷新后的新值。
与 expireAfterWrite相反,refreshAfterWrite 将会使在写操作之后的一段时间后允许key对应的缓存元素进行刷新,但是只有在这个key被真正查询到的时候才会正式进行刷新操作。所以打个比方,你可以在同一个缓存中同时用到 refreshAfterWrite和expireAfterWrite ,这样缓存元素的在被允许刷新的时候不会直接刷新使得过期时间被盲目重置。当一个元素在其被允许刷新但是没有被主动查询的时候,这个元素也会被视为过期。
一个CacheLoader可以通过覆盖重写 CacheLoader.reload(K, V) 方法使得在刷新中可以将旧值也参与到更新的过程中去,这也使得刷新操作显得更加智能。
更新操作将会异步执行在一个Executor上。默认的线程池实现是ForkJoinPool.commonPool()当然也可以通过覆盖Caffeine.executor(Executor)方法自定义线程池的实现。
2.6 Write
CacheWriter允许缓存充当一个底层资源的代理,当与CacheLoader结合使用时,所有对缓存的读写操作都可以通过Writer进行传播。Writer可以把操作缓存和操作外部资源扩展成一个同步的原子性操作。并且在缓存写入完成之前,它将会阻塞后续的更新缓存操作,但是读取(get)将直接返回原有的值。如果写入程序失败,那么原有的key和value的映射将保持不变,如果出现异常将直接抛给调用者。
CacheWriter可以同步的监听到缓存的创建、变更和删除操作。
加载(如
LoadingCache.get)、重新加载(如LoadingCache.refresh)和计算(如Map.computeIfPresent)的操作不会被CacheWriter监听到。
CacheWriter不能与weakKeys或AsyncLoadingCache结合使用。且不支持Caffeine 3.X版本。
2.6.1 可能的用例(Possible Use-Cases)
CacheWriter是复杂工作流的扩展点,需要外部资源来观察给定Key的更改顺序。Caffeine 支持这些用法,但不是内置的。
2.6.2 写模式(Write Modes)
CacheWriter可以用来实现一个直接写(write-through)或回写(write-back)缓存的操作。
-
write-through式缓存中,操作是同步执行的,只有写成功了才会去更新缓存。这避免了同时去更新资源和缓存的条件竞争。 -
write-back式缓存中,对外部资源的操作是在缓存更新后异步执行的。这样可以提高写入的吞吐量,避免数据不一致的风险,比如如果写入失败,则在缓存中保留无效的状态。这种方法可能有助于延迟写操作,直到指定的时间,限制写速率或批写操作。
通过对write-back进行扩展,我们可以实现以下特性:
- 批处理和合并操作
- 将操作延迟到一个时间窗口
- 如果超过阈值大小,则在定期刷新之前执行批处理
- 如果操作尚未刷新,则从后写缓冲区加载
- 根据外部资源的特性处理重试、速率限制和并发
2.6.3 分层(Layering)
CacheWriter可能用来集成多个缓存进而实现多级缓存。
多级缓存的加载和写入可以使用系统外部高速缓存。这允许缓存使用一个小并且快速的缓存去调用一个大的并且速度相对慢一点的缓存。典型的堆外缓存、基于文件的缓存和远程缓存。
受害者缓存是一个多级缓存的变体,其中被删除的数据被写入二级缓存。这个delete(K, V, RemovalCause) 方法允许检查为什么该数据被删除,并作出相应的操作。
2.6.4 同步监听器(Synchronous Listeners)
同步监听器会接收一个key在缓存中的进行了那些操作的通知。监听器可以阻止缓存操作,也可以将事件排队以异步的方式执行。这种类型的监听器最常用于复制或构建分布式缓存。
相关文章:
本地缓存解决方案Caffeine | Spring Cloud 38
一、Caffeine简介 Caffeine是一款高性能、最优缓存库。Caffeine是受Google guava启发的本地缓存(青出于蓝而胜于蓝),在Cafeine的改进设计中借鉴了 Guava 缓存和 ConcurrentLinkedHashMap,Guava缓存可以参考上篇:本地缓…...
Docker常用命令笔记
docker常用命令 1 基础命令 sudo docker version #查看docker的版本信息 sudo docker info #查看docker系统信息,包括镜像和容器的数量 2 镜像命令 1.sudo docker images #查看本地主机的所有主机镜像 #解释 **REPOSITORY **#镜像的仓库源TAG **** …...
Nachos系统的上下文切换
Fork调用创建进程 在实验1中通过gdb调试初步熟悉了Nahcos上下文切换的基本流程,但这个过程还不够清晰,通过源码阅读进一步了解这个过程。 在实验1中通过执行Threadtest,Fork创建子进程,并传入SimpleThread执行currentThread->…...
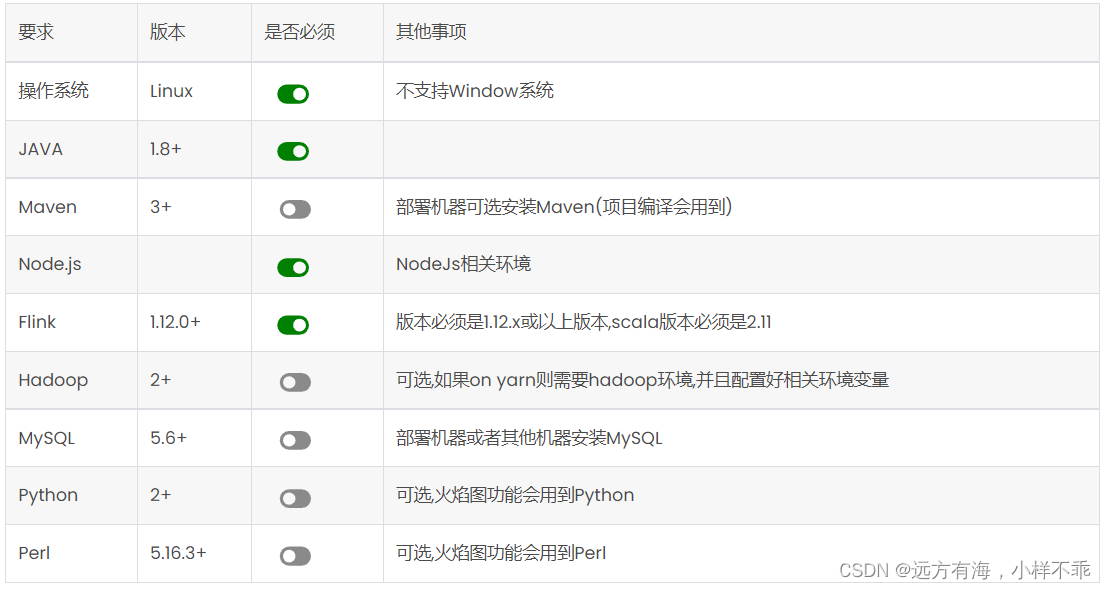
streamx平台部署
一. streamx介绍 StreamPark 总体组件栈架构如下, 由 streampark-core 和 streampark-console 两个大的部分组成 , streampark-console 是一个非常重要的模块, 定位是一个综合实时数据平台,流式数仓平台, 低代码 ( Low Code ), Flink & Spark 任务托…...

css中的background属性
文章目录 一:background-repeat二:background-position三:background缩写方式三:background-size四:background-origin五:background-clip 在日常前端开发中,经常需要进行背景或背景图的处理。但…...

代码评审平台Gerrit安装配置方法介绍
Gerrit是一款开源免费的基于 web 的代码审查工具,是基于 Git 的版本控制系统。在代码入库之前对开发人员的提交进行审阅,检视通过的代码才能提交入库。本文记录如何安装部署gerrit平台。 目录 Gerrit简介环境准备1. 安装Java2. 安装Git3. 安装nginx4. 安…...
一篇文章解决Mysql8
基于尚硅谷的Mysql8.0视频,修修改改。提取了一些精炼的内容。 首先需要在数据库内引入一张表。链接地址如下。 链接:https://pan.baidu.com/s/1DD83on3J1a2INI7vrqPe4A 提取码:68jy 会进行持续更新。。 1. Mysql目录结构 Mysql的目录结构…...

【Python】【进阶篇】6、Django视图函数
目录 6、Django视图函数1. 第一个视图函数1)HttpResponse视图响应类型2)视图函数参数request3)return视图响应 2. 视图函数执行过程 6、Django视图函数 视图是 MTV 设计模式中的 V 层,它是实现业务逻辑的关键层,可以用…...

Latex常用符号和功能记录
公式下括号 \underbrace & \overbrace \begin{equation} \underbrace{L_1L_2}_{loss ~ 1} \overbrace{L_3L_4}^{loss ~ 2} \end{equation}L L 1 L 2 ⏟ l o s s 1 L 3 L 4 ⏞ l o s s 2 L \underbrace{L_1L_2}_{loss ~ 1} \overbrace{L_3L_4}^{loss ~ 2} Lloss 1…...
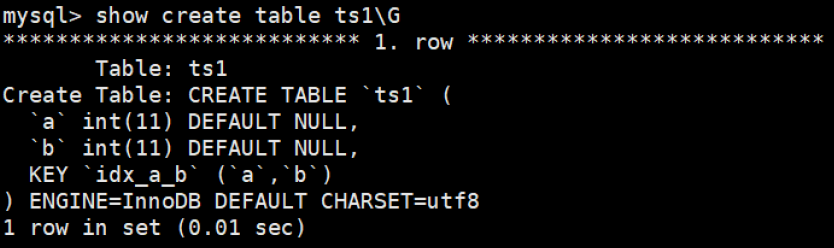
MySQL高级篇——索引的创建与设计原则
导航: 【黑马Java笔记踩坑汇总】JavaSEJavaWebSSMSpringBoot瑞吉外卖SpringCloud黑马旅游谷粒商城学成在线牛客面试题 目录 一、索引的分类与使用 1.1 索引的分类 1.1.1. 普通索引 1.1.2. 唯一性索引 1.1.3. 主键索引(唯一非空) 1.1.4…...

王一茗: “大数据能力提升项目”与我的成长之路 | 提升之路系列(三)
导读 为了发挥清华大学多学科优势,搭建跨学科交叉融合平台,创新跨学科交叉培养模式,培养具有大数据思维和应用创新的“π”型人才,由清华大学研究生院、清华大学大数据研究中心及相关院系共同设计组织的“清华大学大数据能力提升项…...
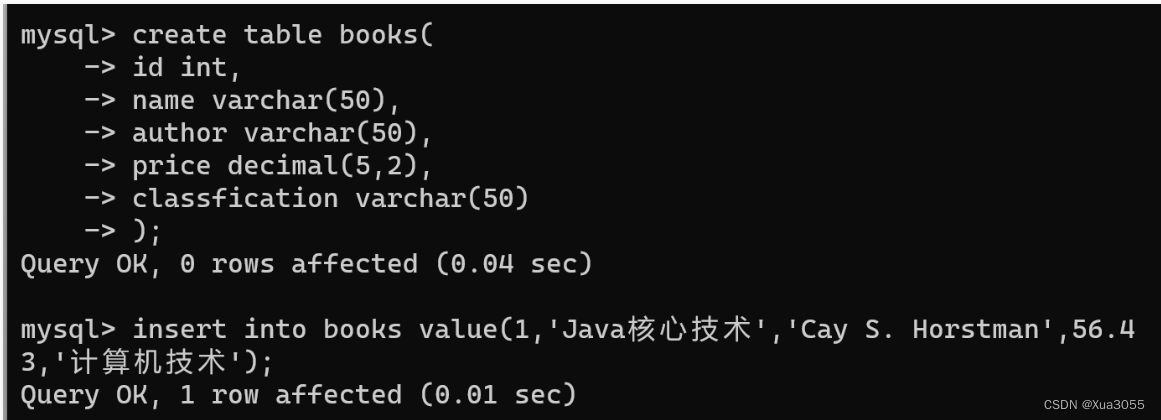
MySQL:数据库的基本操作
MySQL是一个客户端服务器结构的程序, 一.关系型数据库 关系型数据库是一个结构化的数据库,创建在关系模型(二维表格模型)基础上,一般面向于记录。 主流的关系型数据库包括 Oracle、MySQL、SQL Server、Microsoft Access、DB2 等. …...
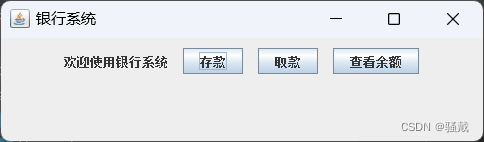
银行系统【GUI/Swing+MySQL】(Java课设)
系统类型 Swing窗口类型Mysql数据库存储数据 使用范围 适合作为Java课设!!! 部署环境 jdk1.8Mysql8.0Idea或eclipsejdbc 运行效果 本系统源码地址:https://download.csdn.net/download/qq_50954361/87708777 …...

【社区图书馆】-《科技服务与价值链》总结
【为什么研究价值链】 价值链及价值链协同体系是现代产业集群的核心枢纽,是推进城市群及产业集群化、服务化、生态化发展的纽带。因而推进价值链协同,创新发展价值链协同业务科技资源体系,既是科技服务业创新的重要方向,也是重塑生…...
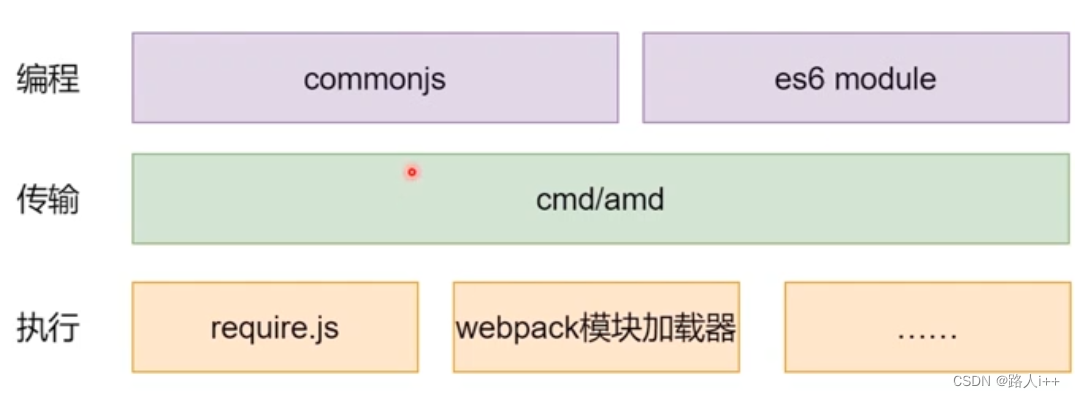
工具链和其他-异步模块加载
目录 CMD/AMD Asynchronous Module Definition(AMD异步模块定义,语法风格) Common Module Definition ES6/CommonJS CommonJS ES6 Module 加载器示例 总结 cmd和amd的区别 现在有哪些异步加载方式 整体结构 编程:commonjs es6 module (有可能解…...

第一次使用R语言
在R语言中,“<-”符号与“”意义一样。另一种奇怪的R语言的等号表示方法,是以“->”表示,但是用得少。 有些计算机语言,变量在使用前要先定义,R语言则不需先定义,可在程序中直接设定使用。 若在Con…...

《语文教学通讯》栏目 收稿范围
《语文教学通讯》创刊于1978年,是由山西师范大学主管,山西师大教育科技传媒集团主办的期刊。历年被人民大学书报资料中心转载、复印的篇幅数量均居同类报刊之首。国内刊号:CN 14-1017/G4,国际刊号:ISSN 1004-6097&…...

Towards Principled Disentanglement for Domain Generalization
本文用大量的理论论述了基于解纠缠约束优化的域泛化问题。 这篇文章认为以往的文章在解决域泛化问题时所用的方法都是non-trivial的,也就是说没有作严格的证明,是不可解释的,而本文用到大量的定理和推论证明了方法的有效性。 动机 因为域泛…...
计算机网络学习02
1、TCP 与 UDP 的区别? 是否面向连接 : UDP 在传送数据之前不需要先建立连接。而 TCP 提供面向连接的服务,在传送数据之前必须先建立连接,数据传送结束后要释放连接。是否是可靠传输: 远地主机在收到 UDP 报文后&…...

网络交换机端口管理工具
如今,企业或组织级网络使用数百个交换机端口作为其 IT 基础架构的一部分来实现网络连接。这使得交换机端口管理成为日常网络管理任务的一部分。传统上,网络管理员必须依靠手动网络交换机端口管理技术来跟踪交换机及其端口连接状态。这种手动任务弊大于利…...

录音总结会议纪要推荐,零基础新手避坑可直接上手指南
这是专为零基础新手整理的2026年录音转会议纪要避坑指南,适配喜欢尝试效率工具、想借助AI节省整理时间的朋友,所有推荐均按实际场景适配度排序,内容简洁易懂,看完可直接上手,无需自行试错踩坑。很多新手接触录音转会议…...

惠普OMEN笔记本终极性能控制:OmenSuperHub 5分钟完全指南
惠普OMEN笔记本终极性能控制:OmenSuperHub 5分钟完全指南 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 想要彻底释放惠普OMEN游戏本的性能潜…...
)
51单片机定时器生成PWM波控制电机转速,从原理到代码调试全流程(基于STC89C52)
51单片机定时器生成PWM波控制电机转速:从寄存器配置到闭环调速实战 在嵌入式控制领域,PWM(脉冲宽度调制)技术如同精准的"电子油门",通过调节脉冲占空比实现对电机转速的精细控制。STC89C52RC这颗经典的51内核…...

效率翻倍!用VSCode和SumatraPDF打造你的LaTeX论文写作‘双向传送门’
效率翻倍!用VSCode和SumatraPDF打造你的LaTeX论文写作‘双向传送门’ 学术写作从来不是一件轻松的事,尤其是当你需要处理大量公式、图表和参考文献时。传统的LaTeX写作流程往往需要在编辑器、编译器和PDF阅读器之间反复切换,这种割裂的体验让…...

GIFT高级技巧:图像组合、并行处理和性能优化的终极指南
GIFT高级技巧:图像组合、并行处理和性能优化的终极指南 【免费下载链接】gift Go Image Filtering Toolkit 项目地址: https://gitcode.com/gh_mirrors/gi/gift GIFT(Go Image Filtering Toolkit)是一个强大的Go语言图像处理库&#x…...

机器人学习快速入门指南:掌握Open X-Embodiment开源数据集
机器人学习快速入门指南:掌握Open X-Embodiment开源数据集 【免费下载链接】open_x_embodiment 项目地址: https://gitcode.com/gh_mirrors/op/open_x_embodiment 想要快速入门机器人学习领域?Open X-Embodiment为你提供了一个完整的机器人学习开…...

深度解析LevelUI:现代LevelDB可视化管理的完整实战指南
深度解析LevelUI:现代LevelDB可视化管理的完整实战指南 【免费下载链接】levelui A GUI for LevelDB management based on atom-shell. 项目地址: https://gitcode.com/gh_mirrors/le/levelui 在NoSQL数据库生态中,LevelDB以其出色的性能和简洁的…...

四旋翼无人机深度强化学习控制框架与实战优化
1. 四旋翼无人机端到端深度强化学习框架解析四旋翼无人机的自主飞行控制一直是机器人学领域的核心挑战。传统PID控制虽然稳定可靠,但在复杂动态环境中表现受限。深度强化学习(DRL)通过模拟环境交互实现智能决策,为无人机控制带来了…...

从SD销售订单到MM采购入库:一条龙打通SAP核心业务流的BAPI实战
SAP跨模块BAPI集成实战:从销售订单到采购入库的自动化业务流 当企业规模扩张到一定程度,各业务部门之间的数据孤岛问题就会成为效率提升的最大障碍。想象一下这样的场景:销售部门接单后,采购团队需要手动创建采购需求,…...

功能安全计划:从ISO 26262到IEC 61508的系统性工程实践
1. 项目概述:为什么我们需要一个“功能安全计划”?在汽车和工业领域,一个简单的软件Bug或硬件失效,其后果可能远超一次蓝屏或服务中断。想象一下,一辆高速行驶的汽车,其电子稳定程序(ESP&#x…...