[C++初阶]栈和队列_优先级队列的模拟实现 deque类 的理解
为了更好的理解优先级队列
priority_queue,这里会同时进行栈和队列的提及
文章目录
- 简要概念(栈和队列)
- 栈和队列的模拟实现与使用
- stack(栈)
- deque的理解和操作
- queue
- priority_queue(优先级队列)
- 框架
- 具体实现
- push()
- adjust_up()(向上调整)
- pop()
- adjust_down()(向下调整)
- top()
- empty()
- size()
- priority_queue 的 验证 / 使用
简要概念(栈和队列)
- 栈:后进先出的结构,通常使用数组栈的形式
- 队列:先进先出的结构,通常使用链表式的队列

- 优先级队列:优先级队列是基于堆实现的一种数据结构。在 C++ STL 中,我们将实现的priority_queue 类就是通过堆来实现的。
- 这里不再对堆进行详细介绍,具体在这:堆详解
栈和队列的模拟实现与使用
stack(栈)
模拟实现
进行stack的实现前先介绍一下deque<T>:
deque的理解和操作
概念(简单看看)
概念简单看看就行
deque是 C++ STL 中的一种双端队列(double-ended queue),它允许在队列两端高效地添加、删除元素,同时支持随机访问。- 与vector的不同:deque 具有良好的内存分配策略,可以避免 vector 扩容时带来的大量元素复制操作。此外,deque 也具有更好的迭代器安全性,因为它不能像 vector 那样通过引起扩容而使得旧迭代器失效。
- deque 内部使用了一个中央控制器,管理了一系列固定大小的连续空间块,每个块内部存储多个元素。当 deque 需要增加或删除元素时,中央控制器会根据需要进行块的扩容或收缩。
操作(重要)
这里介绍deque与stack && queue的不同处,介绍为什么要用deque实现栈和队列
- 插入和删除方式不同:栈只能在栈顶进行插入和删除元素,而队列只能在队尾插入,在队头删除;而 deque 可以在队列的两端都插入和删除元素。
- 访问方式不同:栈只能访问栈顶元素,队列只能访问队头元素;而 deque 可以随机访问任意位置的元素。
- 功能上不同:栈的主要功能是实现“后进先出”(LIFO),队列的主要功能是实现“先进先出”(FIFO),而 deque 不仅可以实现这两种功能,还能够满足双向遍历、支持随机插入和删除等操作。
继续对stack进行模拟实现:
这里需要注意的:
- 对于模板template: T 表示栈中元素的类型,Container 表示底层容器的类型,默认为
deque<T> - 成员变量: _con为Container类型,如果调用者不给Container类型,_con默认为deque,剩下的增删查改调用_con的操作函数即可
namespace aiyimu
{//Container 表示用于存储队列元素的底层容器类型,默认值为 deque<T>template<class T, class Container = deque<T>>class stack{public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_back();}T& top(){return _con.back();}const T& top() const{return _con.back();}bool empty() const{return _con.empty();}size_t size() const{return _con.size();}private:Container _con;};
}
queue
同理stack,这里不作过多赘述,使用_con的操作函数实现即可
namespace aiyimu
{template<class T, class Container = deque<T>>class queue{public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_front();}T& back(){return _con.back();}T& front(){return _con.front();}const T& back() const{return _con.back();}const T& front() const{return _con.front();}bool empty() const{return _con.empty();}size_t size() const{return _con.size();}private:Container _con;};
}
priority_queue(优先级队列)
框架
- Container:在上文stack有解,同理
- Compare:用于选择该堆为大堆还是小堆,默认为
std::less则为小堆 - std::less: 是一个函数对象,用于比较两个参数的大小关系。重载了小于运算符,用于比较两个类型为 T 的对象的大小。当 a < b 时,std::less()(a, b) 返回 true,否则返回 false。
- 构造函数,操作函数
template<class T, class Container = vector<T>, class Compare = std::less<T>>class priority_queue{public:// 默认构造priority_queue(){}// 利用迭代器构造函数template <class InputIterator>priority_queue(InputIterator first, InputIterator last){}// O(logN)// 向上调整void adjust_up(size_t child){}//向下调整void adjust_down(size_t parent){}// 其余操作函数void push(const T& x){}void pop(){}const T& top(){}bool empty() const{}size_t size() const{}private:Container _con;};
具体实现
push()
- 插入操作即为堆的插入操作,所以执行_con.push_back()后进行向上调整(从尾部
_con.size()-1进行调整)
void push(const T& x)
{_con.push_back(x);adjust_up(_con.size() - 1);
}
adjust_up()(向上调整)
- 向上调整即堆heap的操作,具体思路在上文给到的堆详解中
- 主要对if语句中的内容进行解释:
(小堆)向上调整过程中,当父节点的值小于子节点时,交换父子节点
- 原始方法直接进行
<判断:if (_con[parent] < _con[child]) - 但这种写法此时就锁定小堆了, 为了使调用者可以根据需要进行大堆小堆的更改
- 所以这里创建一个Compare对象com,将比较改写为:
if(com(_con[parent], _con[child])) - 该写法当调用者不做更改时默认为小堆(std::less),当调用者给出std::greater(比较大于),此时的
priority_queue就变为大堆
void adjust_up(size_t child)
{Compare com; // size_t parent = (child - 1) / 2;while (child > 0){//if (_con[parent] < _con[child])if(com(_con[parent], _con[child]))// 默认为less,调用者可以自行指定{std::swap(_con[parent], _con[child]);child = parent;parent = (child - 1) / 2;}else{break;}}
}
pop()
- 交换堆顶和堆底的元素,删除堆顶元素,向下调整
void pop()
{// 交换堆顶和堆底的元素,删除堆顶元素,向下调整std::swap(_con[0], _con[_con.size() - 1]);_con.pop_back();adjust_down(0);
}
adjust_down()(向下调整)
- 向下调整需要注意的仍为
com(_con[child], _con[child + 1])写法的意义 - 具体内容在adjust_up中已经提到
void adjust_down(size_t parent)
{Compare com;size_t child = parent * 2 + 1; //先假设右孩子大while (child < _con.size()){//if (child + 1 < _con.size() && _con[child] < _con[child + 1])if (child + 1 < _con.size() && com(_con[child], _con[child + 1])){++child;}//if (_con[parent] < _con[child])if(com(_con[parent], _con[child])){std::swap(_con[parent], _con[child]);parent = child;child = parent * 2 + 1;}else{break;}}
}
top()
- 返回堆顶元素,即_con[0]
const T& top()
{return _con[0];
}
empty()
- bool类型:判断堆是否为空
bool empty() const
{return _con.empty();
}
size()
- 返回堆大小(堆元素个数)
size_t size() const
{return _con.size();
}
priority_queue 的 验证 / 使用
插入元素 && 打印priority_queue
// 头文件void test_priority_queue1()
{aiyimu::priority_queue<int> pq;//priority_queue<int> pq;// 插入元素pq.push(3);pq.push(2);pq.push(5);pq.push(9);pq.push(4);pq.push(6);pq.push(1);// 打印pq的所有元素while (!pq.empty()){cout << pq.top() << " ";pq.pop();}cout << endl;
}
输出结果:

降序 / 升序
int arr[] = { 3,5,6,8,19,7,1,0,9,1,20,4,12 };// 不传入Compare类型,默认less类型:小于,即降序aiyimu::priority_queue<int> heap_less(arr, arr + sizeof(arr) / sizeof(arr[0]));// 传入Compare类型,为greater类型:大于,即升序aiyimu::priority_queue<int, vector<int>, greater<int>> heap_greater(arr, arr + sizeof(arr) / sizeof(arr[0]));while (!heap_less.empty()){cout << heap_less.top() << " ";heap_less.pop();}cout << endl;while (!heap_greater.empty()){cout << heap_greater.top() << " ";heap_greater.pop();}cout << endl;
输出结果:

由此可以看出,当使用
std::less时堆为降序,std::greater时堆为升序
相关文章:
[C++初阶]栈和队列_优先级队列的模拟实现 deque类 的理解
为了更好的理解优先级队列priority_queue,这里会同时进行栈和队列的提及 文章目录 简要概念(栈和队列)栈和队列的模拟实现与使用stack(栈)deque的理解和操作queue priority_queue(优先级队列)框…...
Spring是什么?关于Spring家族
初识Spring 什么是Spring? Spring是一个开源的Java企业级应用程序开发框架,由Rod Johnson于2003年创建,并在接下来的几年里得到了广泛的发展和应用。它提供了一系列面向对象的编程和配置模型,支持开发各种类型的应用程序&#x…...
)
自然语言处理数据集集锦(持续更新ing...)
诸神缄默不语-个人CSDN博文目录 最近更新时间:2023.4.26 最早更新时间:2023.4.25 文本摘要主题的数据集见我之前写的另一篇博文:文本摘要数据集的整理、总结及介绍(持续更新ing…) 智能司法主题的数据集我准备等项目…...

93、Dehazing-NeRF: Neural Radiance Fields from Hazy Images
简介 论文:https://arxiv.org/pdf/2304.11448.pdf 从模糊图像输入中恢复清晰NeRF 使用大气散射模型模拟有雾图像的物理成像过程,联合学习大气散射模型和干净的NeRF模型,用于图像去雾和新视图合成 通过将NeRF 3D场景的深度估计与大气散射模…...

JAVA子类与继承
目录 JAVA子类与继承 一、子类与父类: 二、子类与对象 三、成员变量的隐藏和方法重写 四、super关键字(P122) 五、final关键字 六、对象的上转型对象(P126) 七、继承与多态(P128) 八、abstract类和…...

62 openEuler 22.03-LTS 搭建MySQL数据库服务器-管理数据库
文章目录 62 openEuler 22.03-LTS 搭建MySQL数据库服务器-管理数据库62.1 创建数据库示例 62.2 查看数据库示例 62.3 选择数据库示例 62.4 删除数据库示例 62.5 备份数据库示例 62.6 恢复数据库示例 62 openEuler 22.03-LTS 搭建MySQL数据库服务器-管理数据库 62.1 创建数据库…...

【分布式搜索引擎ES01】
分布式搜索引擎ES 分布式搜索引擎ES1.elasticsearch概念1.1.ES起源1.2.倒排索引1.2.1.正向索引1.2.2.倒排索引 1.3.es的一些概念1.3.1.文档和字段1.3.2.索引和映射1.3.3.mysql与elasticsearch 1.4.1安装es、kibana、IK分词器1.4.2扩展词词典与停用词词典 2.索引库操作2.1.mappi…...
)
1.3 鞅、停时和域流-鞅(布朗运动与随机计算【习题解答】)
Let X = ( x n , F n ) , n = 1 , ⋯ , N X=\left(x_n, \mathcal{F}_n\right), n=1, \cdots, N X...
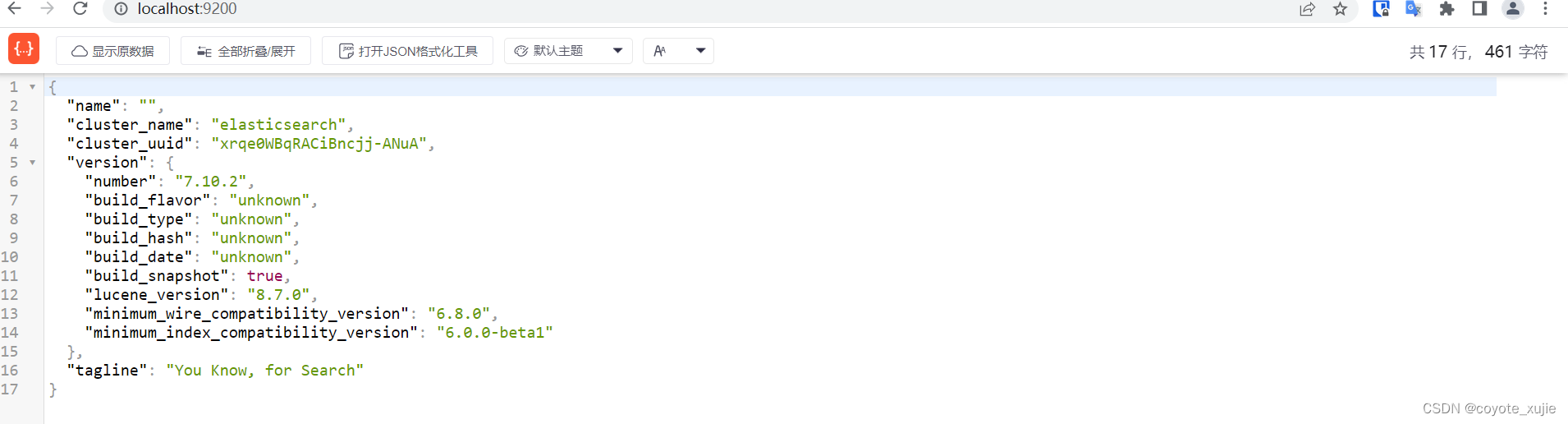
十、ElasticSearch 实战 - 源码运行
一、概述 想深入理解 Elasticsearch,了解其报错机制,并有针对性的调整参数,阅读其源码是很有必要的。此外,了解优秀开源项目的代码架构,能够提高个人的代码架构能力 阅读 Elasticsearch 源码的第一步是搭建调试环境&…...
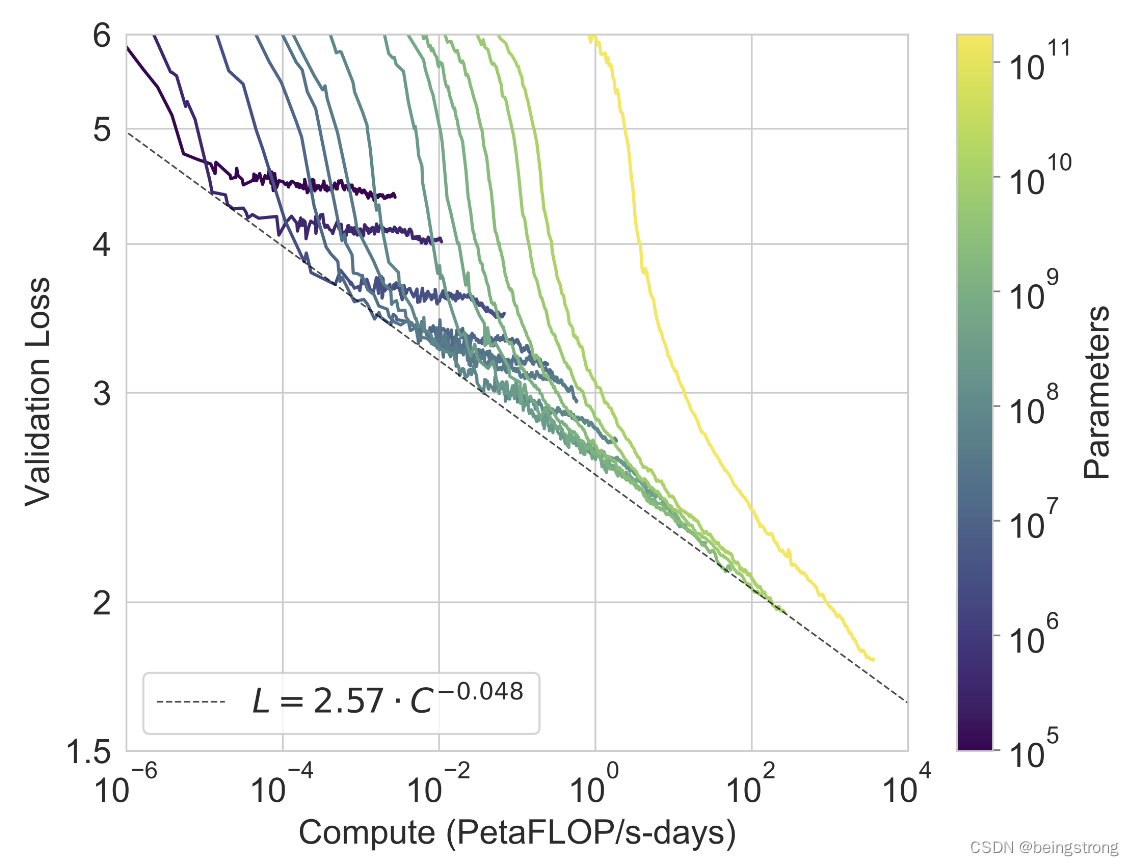
GPT-3 论文阅读笔记
GPT-3模型出自论文《Language Models are Few-Shot Learners》是OpenAI在2020年5月发布的。 论文摘要翻译:最近的工作表明,通过对大量文本进行预训练,然后对特定任务进行微调(fine-tuning),在许多NLP任务和基准测试上…...

方案解析丨数字人主播如何成为电商直播新标配
浙江省政府办公厅近日印发《关于进一步扩大消费促进高质量发展若干举措》支持电子商务直播发展。抢抓电子商务直播快速发展机遇,发展数字人虚拟主播、元宇宙新消费场景等新业态新模式。 随着电商直播快速发展,企业怎么高效地实现引流获客,成为…...

Python最全迭代器有哪些?
python中迭代器的使用是最广泛的,凡是使用for语句,其本质都是迭代器的应用。 从代码角度看,迭代器是实现了迭代器协议的对象或类。迭代器协议方法主要是两个: __iter__()__next__() __iter__()方法返回对象本身,他是…...

ESP32 网络计时器,包含自动保存
简介 本代码是基于ESP32开发板实现的一个计时器功能,具备倒计时、计时器时长选择、显示当前时间、有源蜂鸣器报警等功能。代码中使用了WiFi网络连接、NTP时间同步、EEPROM存储等功能。通过按钮控制计时器的开始、停止和计时器时长的选择。 运行原理概述 在ESP32开…...

【ChatGPT】阿里版 ChatGPT 突然官宣意味着什么?
Yan-英杰的主页 悟已往之不谏 知来者之可追 C程序员,2024届电子信息研究生 目录 阿里版 ChatGPT 突然官宣 ChatGPT 技术在 AI 领域的重要性 自然语言生成 上下文连续性 多语言支持 ChatGPT 未来可能的应用场景 社交领域 商业领域 编辑 医疗领域…...

IPEmotion控制模块-PID循环应用
IPEmotion专业版、开发版支持控制模块,并且该模块支持函数发生器、PID控制器、路由器、序列控制和序列控制块以及参考曲线生成器。本文主要针对PID(P:Proportional control 比例控制;I:Integral control 积分控制&…...
)
【元分析研究方法】学习笔记2.检索文献(含100种学术文献搜索清单链接)
检索文献 该步骤的作用该步骤中需要注意的问题该步骤中部分知识点我的收获 参考来源:库珀 (Cooper, H. M. )., 李超平, & 张昱城. (2020). 元分析研究方法: A step-by step approach. 中国人民大学出版社. 该步骤的作用 1.识别相关文献的来源; 2.识别…...

题目:16版.自由落体
1、实验要求 本实验要求:模拟物体从10000米高空掉落后的反弹行为。 1-1. 创建工程并配置环境: 1-1.1. 限制1. 工程取名:SE_JAVA_EXP_E009。 1-1.2. 限制2. 创建包,取名:cn.campsg.java.experiment。 1-1.3. 限制3. 创建…...
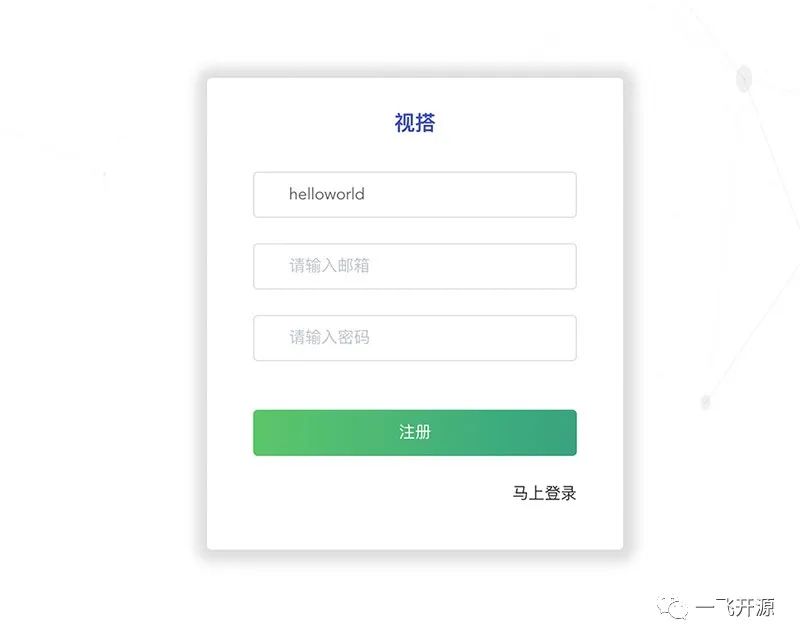
视频可视化搭建项目,通过简单拖拽方式快速生产一个短视频
一、开源项目简介 《视搭》是一个视频可视化搭建项目。您可以通过简单的拖拽方式快速生产一个短视频,使用方式就像易企秀或百度 H5 等 h5 搭建工具一样的简单。目前行业内罕有关于视频可视化搭建的开源项目,《视搭》是一个相对比较完整的开源项目&#…...

network-1 4 layer internet model
4layer model applicationtransport tcp: transmission control protocol enable correct in-order delivery of data, running on top of the network layer service.udp: user datagram protocolnetwork packet:data、from、tonetwork->linkiplink source en…...

计算机网络笔记(横向)
该笔记也是我考研期间做的整理。一般网上的笔记是按照章节纪录的,我是按照知识点分类纪录的,大纲如下: 文章目录 1. 各报文1.1 各报文头部详解1.2 相关口诀 2. 各协议2.1 各应用层协议使用的传输层协议与端口2.2 各协议的过程2.2.1 数据链路层…...

RELION 5.0完整指南:从零开始掌握冷冻电镜数据处理利器
RELION 5.0完整指南:从零开始掌握冷冻电镜数据处理利器 【免费下载链接】relion Image-processing software for cryo-electron microscopy 项目地址: https://gitcode.com/gh_mirrors/re/relion RELION 5.0(REgularised LIkelihood OptimisatioN…...

APK Installer:Windows平台上无缝安装Android应用的技术实现与实战指南
APK Installer:Windows平台上无缝安装Android应用的技术实现与实战指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾在Windows电脑上想要运行某…...

电压控制模式降压变换器环路设计与仿真实战
1. 项目概述:从理论到实践的降压电路设计在电源设计领域,降压变换器(Buck Converter)是应用最广泛的拓扑之一,它负责将较高的输入直流电压稳定地转换为较低的输出直流电压。无论是给手机充电的适配器,还是为…...

思源宋体完全指南:免费开源中文字体的终极解决方案
思源宋体完全指南:免费开源中文字体的终极解决方案 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为商业项目中的中文字体授权费用而烦恼吗?或者在不同平台…...

自动化 Vue 3 转 React 编译工具 VuReact 连续迭代,全量编译速度提升 30%-40%
近期,自动化 Vue 3 转 React 编译工具 VuReact 完成 v1.8.0、v1.8.1、v1.8.3 连续迭代,围绕性能、稳定性、开发体验深度优化,降低 Vue 项目向 React 迁移门槛。更新聚焦三大方向本轮更新围绕性能、稳定性、开发体验三大方向进行深度优化。尤其…...

面试必问:医学知识库 RAG 怎么设计?这次彻底讲透
医学知识库 RAG 怎么设计?一次讲清指南检索、文献召回、权限控制与可追溯回答 大家好,我是一名有 4 年工作经验的 Java 后端开发。 AI 医疗平台里,如果说最适合先落地的一类能力,我会优先推荐医学知识库问答。 因为它既能发挥大模…...

KMS智能激活脚本:3分钟永久激活Windows和Office的终极指南
KMS智能激活脚本:3分钟永久激活Windows和Office的终极指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Office文档突然变…...
)
Cadence SKILL脚本实战:5分钟搞定TESTKEY原理图批量创建(附完整代码)
Cadence SKILL脚本实战:5分钟搞定TESTKEY原理图批量创建(附完整代码) 在集成电路设计领域,TESTKEY(测试结构)的创建是验证工艺模型和器件特性的基础工作。传统手动放置器件的方式不仅效率低下,还…...

思源宋体TTF实战秘籍:三步搞定专业中文字体配置
思源宋体TTF实战秘籍:三步搞定专业中文字体配置 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为商业项目寻找合适的中文字体而烦恼吗?Source Han Serif C…...

政企级无人机管理系统,如何用一套方案搞定多行业巡检?
一、为什么政企客户越来越倾向私有化无人机平台?在低空经济政策收紧、数据安全要求趋严的今天,很多单位在采购无人机管理系统时,已经不再满足于 “能用就行”。公有云平台无法部署在政务内网,数据出网存在合规风险;通用…...