Apache Hudi初探(二)(与spark的结合)
背景
目前hudi的与spark的集合还是基于spark datasource V1来的,这一点可以查看hudi的source实现就可以知道:
class DefaultSource extends RelationProviderwith SchemaRelationProviderwith CreatableRelationProviderwith DataSourceRegisterwith StreamSinkProviderwith StreamSourceProviderwith SparkAdapterSupportwith Serializable {
闲说杂谈
我们先从hudi的写数据说起(毕竟没有写哪来的读),对应的流程:
createRelation||\/
HoodieSparkSqlWriter.write
具体的代码
继续上一次Apache Hudi初探(与spark的结合)的代码:
handleSaveModes(sqlContext.sparkSession, mode, basePath, tableConfig, tblName, operation, fs)val partitionColumns = SparkKeyGenUtils.getPartitionColumns(keyGenerator, toProperties(parameters))val tableMetaClient = if (tableExists) {HoodieTableMetaClient.builder.setConf(sparkContext.hadoopConfiguration).setBasePath(path).build()} else {...}val commitActionType = CommitUtils.getCommitActionType(operation, tableConfig.getTableType)if (hoodieConfig.getBoolean(ENABLE_ROW_WRITER) &&operation == WriteOperationType.BULK_INSERT) {val (success, commitTime: common.util.Option[String]) = bulkInsertAsRow(sqlContext, parameters, df, tblName,basePath, path, instantTime, partitionColumns, tableConfig.isTablePartitioned)return (success, commitTime, common.util.Option.empty(), common.util.Option.empty(), hoodieWriteClient.orNull, tableConfig)}
-
handleSaveModes 是对spark SaveMode和hoodie的hoodie.datasource.write.operation配置进行校验验证
如 如果根据现有spark.sessionState.conf.resolver配置计算出来的表名(source中配置的hoodie.table.name和tableconfig获取的hoodie.table.name)不一致则报错 -
partitionColumns 获取分区字段,一般是 “field1,field2”格式
-
val tableMetaClient =
构造tableMetaClient,如果表存在,则复用现有的,
如果不存在则会新建,主要的是新建目录以及初始化对应的目录结构:- 创建.hoodie目录
- 创建.hoodie/.schema目录
- 创建.hoodie/archived目录
- 创建.hoodie/.temp目录
- 创建.hoodie/.aux目录
- 创建.hoodie/.aux/.bootstrap目录
- 创建.hoodie/.aux/.bootstrap/.partitions目录
- 创建.hoodie/.aux/.bootstrap/.fileids目录
- 创建.hoodie/hoodie.properties文件
并向hoodie.properties写入属性值
最终会形成如下的文件目录机构:hudi_result_mor/.hoodie/.auxhudi_result_mor/.hoodie/.aux/.bootstrap/.partitionshudi_result_mor/.hoodie/.aux/.bootstrap/.fileidshudi_result_mor/.hoodie/.schemahudi_result_mor/.hoodie/.temphudi_result_mor/.hoodie/archivedhudi_result_mor/.hoodie/hoodie.propertieshudi_result_mor/.hoodie/metadata
-
val commitActionType = CommitUtils.getCommitActionType
这个决定了commit的类型,如果是COW表则是commit,如果是MOR表是deltacommit,这会在文件的后缀上有体现 -
bulkInsertAsRow
如果同时满足“hoodie.datasource.write.row.writer.enable”(默认是true)和“hoodie.datasource.write.operation”是bulk_insert,则会按照spark原生的ROW格式写入数据,否则会有额外的转换操作
bulkInsertAsRow解析
由于bulkInsertAsRow是写入数据的重点,所以逐一分析:
val sparkContext = sqlContext.sparkContextval populateMetaFields = java.lang.Boolean.parseBoolean(parameters.getOrElse(HoodieTableConfig.POPULATE_META_FIELDS.key(),String.valueOf(HoodieTableConfig.POPULATE_META_FIELDS.defaultValue())))val dropPartitionColumns = parameters.get(DataSourceWriteOptions.DROP_PARTITION_COLUMNS.key()).map(_.toBoolean).getOrElse(DataSourceWriteOptions.DROP_PARTITION_COLUMNS.defaultValue())// register classes & schemasval (structName, nameSpace) = AvroConversionUtils.getAvroRecordNameAndNamespace(tblName)sparkContext.getConf.registerKryoClasses(Array(classOf[org.apache.avro.generic.GenericData],classOf[org.apache.avro.Schema]))var schema = AvroConversionUtils.convertStructTypeToAvroSchema(df.schema, structName, nameSpace)if (dropPartitionColumns) {schema = generateSchemaWithoutPartitionColumns(partitionColumns, schema)}validateSchemaForHoodieIsDeleted(schema)sparkContext.getConf.registerAvroSchemas(schema)log.info(s"Registered avro schema : ${schema.toString(true)}")if (parameters(INSERT_DROP_DUPS.key).toBoolean) {throw new HoodieException("Dropping duplicates with bulk_insert in row writer path is not supported yet")}
- populateMetaFields= ,如果是True,会在每行记录中添加Hudi的元数据字段(如_hoodie_commit_time等),这在后面的bulkInsertPartitionerRows时候用到,默认是True
- dropPartitionColumns 是否删除分区字段,默认是否,也就是会保留分区字段
- sparkContext.getConf.registerKryoClasses 给GenericData和Schema使用Kyro序列化
- var schema = AvroConversionUtils.convertStructTypeToAvroSchema 把spark sql Schema转换为Avro Schema
- sparkContext.getConf.registerAvroSchemas 注册Avro序列化
- “hoodie.datasource.write.insert.drop.duplicates” 不允许为True
val params: mutable.Map[String, String] = collection.mutable.Map(parameters.toSeq: _*)params(HoodieWriteConfig.AVRO_SCHEMA_STRING.key) = schema.toStringval writeConfig = DataSourceUtils.createHoodieConfig(schema.toString, path, tblName, mapAsJavaMap(params))val bulkInsertPartitionerRows: BulkInsertPartitioner[Dataset[Row]] = if (populateMetaFields) {val userDefinedBulkInsertPartitionerOpt = DataSourceUtils.createUserDefinedBulkInsertPartitionerWithRows(writeConfig)if (userDefinedBulkInsertPartitionerOpt.isPresent) {userDefinedBulkInsertPartitionerOpt.get} else {BulkInsertInternalPartitionerWithRowsFactory.get(writeConfig.getBulkInsertSortMode, isTablePartitioned)}} else {// Sort modes are not yet supported when meta fields are disablednew NonSortPartitionerWithRows()}val arePartitionRecordsSorted = bulkInsertPartitionerRows.arePartitionRecordsSorted()params(HoodieInternalConfig.BULKINSERT_ARE_PARTITIONER_RECORDS_SORTED) = arePartitionRecordsSorted.toStringval isGlobalIndex = if (populateMetaFields) {SparkHoodieIndexFactory.isGlobalIndex(writeConfig)} else {false}- 注册“hoodie.avro.schema”为刚才的Avro Schema
- val writeConfig = DataSourceUtils.createHoodieConfig
创建hudiConfig对象,其中包括:- “hoodie.datasource.compaction.async.enable” 是否异步compaction,默认是true
- 如果不是异步compaction,且满足是MOR表,则表明是同步Compaction
- “hoodie.datasource.write.insert.drop.duplicates”如果是True(默认False),则会在插入记录的时候去重
- 设置“hoodie.datasource.write.payload.class”,默认是“OverwriteWithLatestAvroPayload”
- 设置“hoodie.datasource.write.precombine.field”,默认是ts字段,这个字段用在Playload的时候进行record的比较
- 这里还会在在最后的build()步骤里设置"hoodie.index.type",如果是spark引擎,则是"SIMPLE"
- bulkInsertPartitionerRows,默认是NonSortPartitionerWithRows,也就是原样输出,不做任何改动
- 设置"hoodie.bulkinsert.are.partitioner.records.sorted",默认为False
- val isGlobalIndex = 这里会根据索引类型来判断,因为默认是“SIMPLE”索引,所以是False
val hoodieDF = HoodieDatasetBulkInsertHelper.prepareForBulkInsert(df, writeConfig, bulkInsertPartitionerRows, dropPartitionColumns)if (HoodieSparkUtils.isSpark2) {hoodieDF.write.format("org.apache.hudi.internal").option(DataSourceInternalWriterHelper.INSTANT_TIME_OPT_KEY, instantTime).options(params).mode(SaveMode.Append).save()} else if (HoodieSparkUtils.isSpark3) {hoodieDF.write.format("org.apache.hudi.spark3.internal").option(DataSourceInternalWriterHelper.INSTANT_TIME_OPT_KEY, instantTime).option(HoodieInternalConfig.BULKINSERT_INPUT_DATA_SCHEMA_DDL.key, hoodieDF.schema.toDDL).options(params).mode(SaveMode.Append).save()} else {throw new HoodieException("Bulk insert using row writer is not supported with current Spark version."+ " To use row writer please switch to spark 2 or spark 3")}val syncHiveSuccess = metaSync(sqlContext.sparkSession, writeConfig, basePath, df.schema)(syncHiveSuccess, common.util.Option.ofNullable(instantTime))}
-
HoodieDatasetBulkInsertHelper.prepareForBulkInsert 这是插入数据前的准备工作
- 如果"hoodie.populate.meta.fields"是True,则增加元数据字段:
_hoodie_commit_time,_hoodie_commit_seqno,_hoodie_record_key,_hoodie_partition_path,_hoodie_file_name - “hoodie.combine.before.insert”,是否在写入存储之前,先进行数据去重处理(按照precombine的key),默认是False
- 默认走的是,只是加上元数据字段
- 如果是设置为True,则会引入额外的shuffle来进行去重处理
- 如果"hoodie.datasource.write.drop.partition.columns"为True(默认是False),去掉分区字段
- 如果"hoodie.populate.meta.fields"是True,则增加元数据字段:
-
因为这里是Spark3 所以会进入到hoodieDF.write.format(“org.apache.hudi.spark3.internal”)
这里后续再分析
相关文章:
(与spark的结合))
Apache Hudi初探(二)(与spark的结合)
背景 目前hudi的与spark的集合还是基于spark datasource V1来的,这一点可以查看hudi的source实现就可以知道: class DefaultSource extends RelationProviderwith SchemaRelationProviderwith CreatableRelationProviderwith DataSourceRegisterwith StreamSinkPr…...

颠覆世界的“数字孪生”到底是什么?这篇文章带你搞懂全部内涵!
在春节很火的电影《流浪地球2》中,已经去世的小女孩图丫丫,被她的父亲重新将其个人的信息模型导入最强大的计算机而“复活”了。屏幕中的丫丫就是一个数字孪生体。我们可以看到她的一颦一笑,听到她跟你的对话,看到她做出反应。这就…...

Vector底层结构和源码分析
Vector的基本介绍 1.Vector类的定义说明 public class Vector<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, Serializable 2)Vector底层也是一个对象数组,protected Objectl] elementData; 3)Vector是线程同步的&…...
计算卸载论文阅读01-理论梳理
标题:When Learning Joins Edge: Real-time Proportional Computation Offloading via Deep Reinforcement Learning 会议:ICPADS 2019 一、梳理 问题:在任务进行卸载时,往往忽略了任务的特定的卸载比例。 模型:针…...

Windows 11 本地 php 开发环境搭建:PHP + Apache + MySQL +VSCode 安装和环境配置
目录 前言1. PHP 的下载、安装和配置1.1 下载 php1.2 安装 php1.3 配置 php 系统变量1.4 配置 php.ini 2. Apache 的下载、安装和配置2.1 下载 Apache2.2 安装 Apache2.3 修改配置 Apache2.4 指定服务端口(非必须)2.5 配置系统变量2.6 安装服务2.7 Apach…...

15个使用率超高的Python库,下载量均过亿
今天给大家分享最近一年内PyPI上下载量最高的Python包。现在我们来看看这些包的作用,他们之间的关系,以及为什么如此流行。 1. Urllib3:8.93亿次下载 Urllib3 是 Python 的 HTTP 客户端,它提供了许多 Python 标准库没有的功能。 …...

所有知识付费都可以用 ChatGPT 再割一次?
伴随春天一起到来的,还有如雨后春笋般冒出的 ChatGPT / AI 相关的付费社群、课程训练营、知识星球等。 ChatGPT 吹来的这股 AI 热潮,这几个月想必大家多多少少都能感受到。 ▲ 图片来源:网络 这两张图是最近在圈子里看到的。 一张是国内各…...
)
Python中“is”和“==”的区别(避坑)
2.3 “is”和“”的区别 在Python编写代码时,经常会遇到需要判断2个对象是否相等的情况,这个时候一般就会想到使用is和,is和好像都可以用来判断对象是否相等,经常会傻傻分不清,但其实这其中还是有区别的。 不过在这之…...

20230426----重返学习-vue-router路由
day-058-fifty-eight-20230426-vue-router路由 vue-router路由 路由:切换页面,单页面应用上使用的 hash模式—锚点 对应vue版本 如何使用路由版本 vue2 —> router3vue3 —> router4 使用vue-router 创建项目的时候,直接选中路由…...
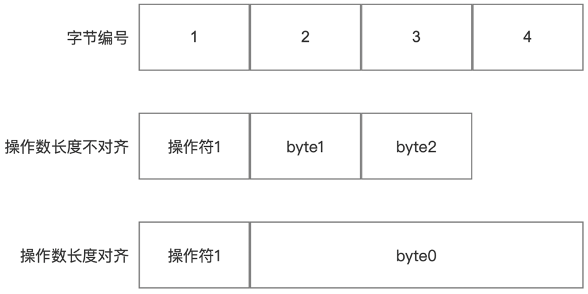
Java字节码指令
Java代码运行的过程是Java源码->字节码文件(.class)->运行结果。 Java编译器将Java源文件(.java)转换成字节码文件(.class),类加载器将字节码文件加载进内存,然后进行字节码校验,最后Java解释器翻译成机器码。 …...
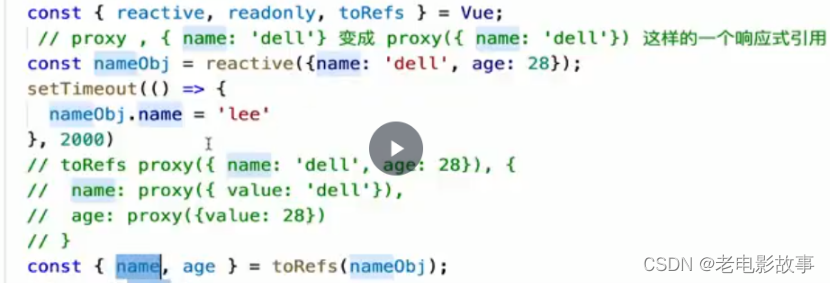
Vue3之setup参数介绍
setup(props, context) {... }一、参数 使用setup函数时,它将接受两个参数: propscontext 让我们更深入地研究如何使用每个参数 二、Props setup函数中的第一个参数是props。正如在一个标准组件中所期望的那样,setup函数中的props是响应…...

ESET NOD32 互联网安全软件和防毒软件 -简单,可靠的防护。
安全防范病毒和间谍软件,银行和网上购物更安全, 网络摄像头和家用路由器使用更安全,阻止黑客访问您的电脑, 让您的孩子网络安全;产品兑换码仅支持中国ip地址兑换,兑换后可全球通用。 简单,可靠的防护 防范黑客&#x…...

试试这几个冷门但好用的软件吧
软件一:探记 探记是一款专注于个人记录每一条记录的工具,主要特点如下: 简单易用:探记的界面设计简洁明了,操作流程简单易用,用户可以快速、方便地添加记录。 多样化记录类型:探记支持多种记…...
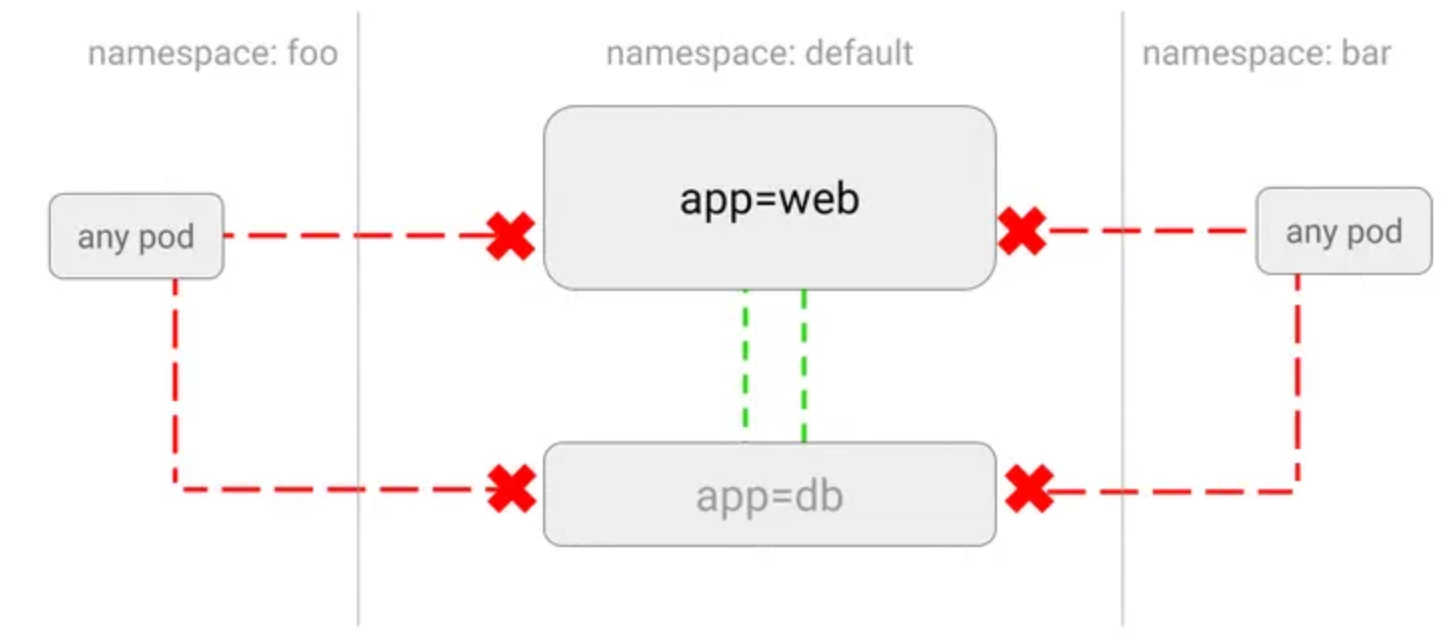
【云原生】k8s NetworkPolicy 网络策略是怎么样的
前言 随着微服务的流行,越来越多的云服务平台需要大量模块之间的网络调用。 在 Kubernetes 中,网络策略(NetworkPolicy)是一种强大的机制,可以控制 Pod 之间和 Pod 与外部网络之间的流量。 Kubernetes 中的 NetworkPolicy 定义了一组规则&…...

手把手教你用几行代码给winform多个控件(数量无上限)赋值
前言: 我们在开发winform程序的过程中,经常会遇到这样一个场景,我们设计的界面,比如主窗体有一百多个TextBox,然后初始化的时候要对这个一百多个TextBox的Text属性赋值,比如赋个1,如果是winfor…...

回炉重造十一------ansible批量安装服务
1.playbook的核心组件 Hosts 执行的远程主机列表Tasks 任务集,由多个task的元素组成的列表实现,每个task是一个字典,一个完整的代码块功能需最 少元素需包括 name 和 task,一个name只能包括一个taskVariables 内置变量或自定义变量在playbook中调用Templates 模板,…...

系统集成项目管理工程师 笔记(第20章:知识产权管理、第21章:法律法规和标准规范)
文章目录 20.1.2 知识产权的特性 58420.2.1 著作权及邻接权 58520.2.2 专利权 58920.2.3 商标权 59221.3 诉讼时效 59921.6.3 标准分级与标准类型 60321.7.2 信息系统集成项目管理常用的技术标准 6061、基础标准2、开发标准3、文档标准4、管理标准 第20章 知识产权管理 584 20.…...
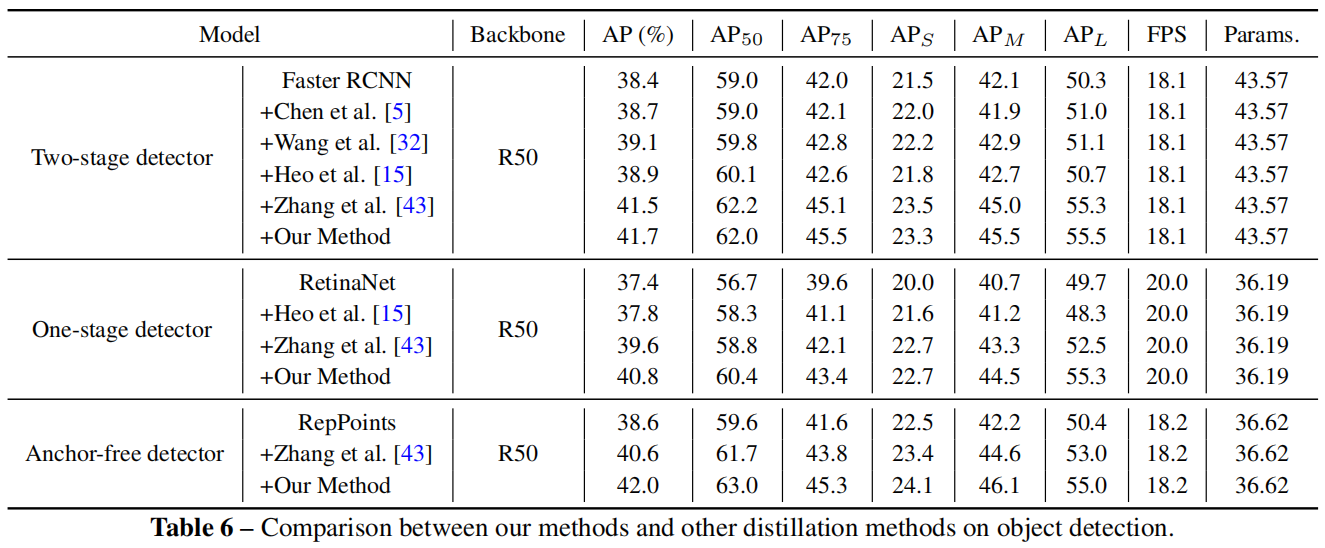
Channel-wise Knowledge Distillation for Dense Prediction(ICCV 2021)原理与代码解析
paper:Channel-wise Knowledge Distillation for Dense Prediction official implementation:https://github.com/irfanICMLL/TorchDistiller/tree/main/SemSeg-distill 摘要 之前大多数用于密集预测dense prediction任务的蒸馏方法在空间域spatial…...
No.052<软考>《(高项)备考大全》【冲刺6】《软考之 119个工具 (4)》
《软考之 119个工具 (4)》 61.人际交往:62.组织理论:63.预分派:64.谈判:65.招募:66.虚拟团队:67.多标准决策分析:68.人际关系技能:69.培训:70.团队建设活动:71.基本规则:72.集中办公:73.认可与奖励:74.人事评测工具:75.观察和交谈:76.项目绩效评估:77.冲…...
Go | 一分钟掌握Go | 9 - 通道
作者:Mars酱 声明:本文章由Mars酱编写,部分内容来源于网络,如有疑问请联系本人。 转载:欢迎转载,转载前先请联系我! 前言 在Java中,多线程之间的通信方式有哪些?记得吗&…...
定制固件)
从BetaFlight的Makefile设计,聊聊如何为你的飞控板(如STM32F7X2)定制固件
从BetaFlight的Makefile设计解析飞控固件定制之道 在无人机和航模领域,BetaFlight作为一款开源飞控软件,因其出色的性能和灵活的定制能力而广受欢迎。本文将深入探讨BetaFlight的构建系统设计,特别是其Makefile的实现哲学,并以STM…...

从EfficientNetV1到V2:我是如何用PyTorch复现Fused-MBConv模块并验证其速度优势的
从EfficientNetV1到V2:我是如何用PyTorch复现Fused-MBConv模块并验证其速度优势的 去年在优化移动端图像分类模型时,我偶然发现EfficientNetV2论文中提到的Fused-MBConv模块在浅层网络中的推理速度比传统MBConv快30%以上。这个数字让我既兴奋又怀疑——毕…...

无王无帝定乾坤,来自田间第一人 凰标重塑新风骨
一、破题:王权不是答案旧认知新真相山河气运系于帝王扭转乾坤藏于民间位高者裁定是非布衣亦可定乾坤权贵定义风骨凰标重塑精神二、旧世风骨之殇等级枷锁 王权为纲 → 尊卑为界 → 精神镣铐千年。世俗偏见 财富分贵贱 → 地位论高低 → 人心逐利忘本。结局 风骨消磨 …...

高效掌握Simscape Electrical:BLDC电机控制器设计的5大关键技术实战
高效掌握Simscape Electrical:BLDC电机控制器设计的5大关键技术实战 【免费下载链接】Design-motor-controllers-with-Simscape-Electrical This repository contains MATLAB and Simulink files used in the "How to design motor controllers using Simscape…...

VPU与NPU协同优化:边缘AI视觉处理的算力融合实践
1. 项目概述:边缘计算时代的算力融合新范式最近和几个做嵌入式AI和边缘设备的老朋友聊天,大家不约而同地都在讨论一个话题:在资源受限的边缘端,如何把有限的算力“榨干”,让模型跑得更快、更省电。聊着聊着,…...

利用 AsyncOpenAI 与 asyncio.gather 实现批量问题的高效并发处理
1. 为什么需要异步处理批量问题? 想象一下你开了一家奶茶店,顾客排着长队点单。如果每次只服务一个顾客,等做完他的奶茶才接待下一位,队伍会越排越长。这就是同步请求的困境——每个查询必须等待前一个完成才能开始。当我们需要同…...

YOLO模型如何训练救生衣检测数据集深度学习如何训练救生衣检测数据集
救生衣检测模型YOLO8-300n 提供训练好的模型文件(pt格式)、过程文件和验证图片,带对应的训练数据集10000张 1 111一、救生衣检测模型(YOLOv8-300n)完整方案1. 模型与数据集信息项目详情模型版本YOLOv8n(300…...
)
告别手动点点点:用pywinauto给微信做个自动化小助手(Python实战)
告别手动点点点:用pywinauto打造微信自动化小助手 微信作为日常高频使用的通讯工具,每天重复的"文件传输助手"转发、消息发送等操作消耗着大量时间。本文将带你用pywinauto构建一个能自动完成这些任务的Python脚本,解放双手的同时深…...

性能优化实战:在Unity项目里管理多个Video Player,如何避免内存泄漏和卡顿?
Unity多视频管理实战:规避内存泄漏与卡顿的深度优化策略 在沉浸式游戏体验和交互式AR/VR应用中,视频内容已成为提升用户参与度的关键要素。但当场景中同时存在多个Video Player组件时,开发者往往会遭遇突如其来的性能断崖——内存占用飙升、播…...

【亲测免费】 VisionPro培训文档全中文版
VisionPro培训文档全中文版 【下载地址】VisionPro培训文档全中文版 VisionPro培训文档全中文版欢迎使用VisionPro培训文档全中文版!本资源是专为机器视觉领域从业者及学习者精心准备的一套全面指南,旨在帮助您快速掌握VisionPro软件的强大功能与应用技巧…...