爬虫大全:从零开始学习爬虫的基础知识
爬虫是一种自动获取网站信息的技术,它可以帮助我们快速地抓取海量网站数据,进行统计分析、挖掘和展示。本文旨在为初学者详细介绍爬虫的基础知识,包括:爬虫原理、爬虫分类、网页结构分析、爬虫工具和技能、爬虫实践示范,以及如何绕过反爬虫机制等内容,让你轻松入门、快速提升。
一、爬虫原理
爬虫的实现原理其实很简单,就是模拟浏览器发送请求、获取响应、解析HTML代码、保存数据的过程。具体来说,可以分为以下几个步骤:
- 发送请求
我们在浏览器里输入网址访问网页时,其实就是在向服务器发送一条请求。在爬虫中,我们也需要发送类似的请求,只不过不是手动输入网址,而是通过编写代码实现。请求可以包含各种参数,比如GET请求和POST请求的区别就在于参数的传递方式不同。
import requestsresponse = requests.get('http://www.example.com')print(response.status_code) # 打印响应状态码
- 获取响应
发送完请求之后,服务器会返回一个HTML文档,里面包含了很多数据。在爬虫中,我们需要获取这个响应,并对其进行解析。
import requestsresponse = requests.get('http://www.example.com')html = response.text # 获取响应内容print(html)
- 解析HTML
HTML文档中包含了很多标签和属性,我们需要用代码把它们提取出来,才能得到我们需要的数据。常用的HTML解析库有BeautifulSoup、lxml等。
from bs4 import BeautifulSouphtml = '''Hello'''soup = BeautifulSoup(html, 'lxml')print(soup.h1.string) # 获取h1标签中的文本
- 保存数据
解析好HTML之后,我们就可以提取出所需要的数据了。一般情况下,可以把数据保存到文件或数据库中,以备后续使用。
import csvdata = [['name', 'age'], ['Tom', '18'], ['Jerry', '19']]with open('data.csv', 'w', encoding='utf-8', newline='') as f:writer = csv.writer(f)for row in data:writer.writerow(row)
以上就是一个最基本的爬虫流程,当然还有很多细节需要注意,下面我们会详细讨论。
二、爬虫分类
按照数据获取的目的,爬虫可以分为三种类型:通用型爬虫、聚焦型爬虫和增量型爬虫。
- 通用型爬虫
通用型爬虫是一种无差别抓取所有信息的爬虫,它可以从互联网上抓取尽可能多的信息,并将其存储到互联网的大型数据库中,以供其他人使用。例如,百度、Google等搜索引擎就是使用通用型爬虫实现的。
- 聚焦型爬虫
聚焦型爬虫是一种针对某个特定主题的爬虫,它只抓取与该主题相关的信息,并进行整理和归类。例如,时事新闻类网站就是使用聚焦型爬虫实现的。
- 增量型爬虫是一种具有记忆能力的爬虫,它可以对已经抓取过的网页进行更新检查,只抓取新的或更新的信息,减少重复抓取和数据处理的时间和资源消耗。例如,新闻类网站中的“今日头条”栏目就是使用增量型爬虫实现的。
除此之外,爬虫还可以按照结构、数据源、爬取频率等进行分类。例如,结构上可以分为静态爬虫和动态爬虫,数据源上可以分为单站点爬虫和分布式爬虫,爬取频率上可以分为一次性爬虫和定期更新爬虫等。
三、网页结构分析
在进行爬虫前,我们需要对要爬取的网页进行结构分析,以确定数据的位置和提取方法。一般来说,网页结构可以通过浏览器的开发者工具进行查看。
- 网页基础结构
一个网页的基础结构由HTML、CSS和JavaScript三部分组成,其中HTML负责网页内容的架构,CSS负责网页样式的设计,JavaScript则可以用来实现网页上的动态交互和事件响应。
- 网页元素定位
在爬虫中,我们需要对网页上的某个元素进行定位,以抽取其中的内容。常用的网页元素包括标签、属性、class、id等,可以通过浏览器的开发者工具进行查看和定位。
- XPath和CSS Selector
XPath和CSS Selector是两种常用的网页元素查找语言,它们可以指定网页元素的路径或规则,以便进行定位和抽取。例如,XPath可以通过“//标签名[@属性名=’属性值’]”的方式来定位元素,CSS Selector则可以通过“标签名.类名#id名”等方式来定位元素。
- JavaScript渲染问题
有些网站使用JavaScript进行局部刷新和动态渲染,此时需要注意爬虫要能够执行JavaScript才能抓取到完整的页面内容。可以使用Selenium等工具来模拟浏览器行为,或者对网页进行网络捕捉和分析以获取完整的响应数据。
四、爬虫工具和技能
在开发爬虫时,我们需要掌握一些常用的工具和技能来提高效率和质量。
- Python编程语言
Python是爬虫开发中常用的编程语言之一,它具有简洁易读、高效快速、丰富的第三方库等优点,非常适合进行数据处理和科学计算。
- Requests库
Requests是Python中的一个HTTP库,它非常方便地实现HTTP请求和响应的处理,可以进行GET、POST、Cookie、Session等操作。
- Beautiful Soup库
Beautiful Soup是Python中的一个HTML解析库,它可以方便地处理HTML标签和属性,支持XPath和CSS Selector等常用的查找方式,提供了灵活易用的API。
- Scrapy框架
Scrapy是Python中的一个爬虫框架,它提供了完整的爬虫流程和分布式架构,并支持编写爬虫中间件和管道,方便数据的处理和保存。
- 防火墙代理
有些网站可能会对爬虫进行限制或封禁,此时可以使用防火墙代理来隐藏真实IP地址,以免被封禁。
- 数据库操作
爬虫获取到的数据可以保存到各种关系型或非关系型数据库中,常用的有MySQL、MongoDB等,需要掌握相应的数据库操作技能。
五、爬虫实践示范
下面是一个简单的爬虫示例,用于抓取中国地震台网上的近期地震信息,并存储到CSV文件中。
import requests
import csv
from bs4 import BeautifulSoupurl = 'http://www.ceic.ac.cn/ajax/search?page=1'data = {'start': '2018-01-01 00:00:00','end': '2021-1 1-01 23:59:59','location': '','minmag': '','maxmag': '','mindepth': '','maxdepth': '','eventType': '地震','searchType': 'advanced','pageSize': '10000',
}response = requests.post(url, data=data)html = response.text
soup = BeautifulSoup(html, 'lxml')table = soup.find('table', class_='newlist')
rows = table.find_all('tr')data = [['time', 'latitude', 'longitude', 'depth', 'magnitude', 'location']]for row in rows[1:]:cols = row.find_all('td')time = cols[1].textlatitude = cols[4].textlongitude = cols[5].textdepth = cols[6].textmagnitude = cols[7].textlocation = cols[10].textdata.append([time, latitude, longitude, depth, magnitude, location])with open('earthquakes.csv', 'w', encoding='utf-8', newline='') as f:writer = csv.writer(f)for row in data:writer.writerow(row)
运行这段代码后,即可得到一个earthquakes.csv文件,里面包含了中国地震台网上从2018年到2021年11月的所有地震信息。
六、绕过反爬虫机制
有些网站为了防止爬虫的访问,可能会设置反爬虫机制,例如限制访问频率、验证码认证、Cookie认证等。在爬虫开发中,我们需要采取一些措施来绕过这些限制。
- 伪装请求头
有些网站会根据请求头中的参数来判断访问者是否为爬虫,此时我们可以通过设置伪装请求头来隐藏自己的身份。例如,可以修改User-Agent参数、Referer参数、Cookie参数等。
import requestsheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
}response = requests.get('http://www.example.com', headers=headers)print(response.text)
- 使用代理IP
有些网站会根据IP地址来判断访问者是否为爬虫,此时我们可以使用代理IP来隐藏真实IP地址。例如,可以使用网上购买的代理IP、TOR网络、Shadowsocks等。
import requestsproxies = {'http': 'http://username:password@ip:port','https': 'https://username:password@ip:port',
}response = requests.get('http://www.example.com', proxies=proxies)print(response.text)
- 解析验证码
有些网站会设置验证码来防止爬虫的访问,此时我们可以编写脚本来解析验证码,并进行自动化识别和提交。
- 分布式爬虫
在一些大的爬虫任务中,单机爬虫往往会面临访问频率限制和性能瓶颈等问题。此时,可以考虑使用分布式爬虫来解决这些问题。
分布式爬虫是一种将爬虫任务分配给多个节点(通常是多台机器)进行并行处理的方式。不同节点之间可以通过网络连接进行通信和数据传输,从而实现爬虫任务的加速和效率提升。
常用的分布式爬虫框架包括Scrapy-Redis、Distributed Spider等,可以配置多个爬虫节点、任务调度器、队列管理器等组件,实现高效的爬虫任务处理。此外,还需要注意分布式环境下的数据一致性、节点故障处理等问题。
七、爬虫伦理问题
在进行爬虫开发时,需要考虑一些伦理和法律问题。爬虫的滥用可能会对网站造成损害,甚至可能触犯法律。以下是一些爬虫应遵守的基本规范。
- 遵守网站协议和规定
在爬取一个网站时,爬虫应遵守该网站的协议和规定,如不得以过度频繁的方式访问网站,不得大量下载网站内容等。
- 尊重个人隐私和版权
爬虫应尊重个人隐私和版权,如不得爬取含有个人隐私信息的网页和非公开的版权内容。
- 维护数据准确性和安全性
爬虫应维护数据的准确性和安全性,如不得篡改网页内容、盗取用户数据等。
- 不损害网站正常运行
爬虫应不损害网站的正常运行,如不得进行DDOS攻击、爬取网站资源过多等。
总之,爬虫开发需要遵守伦理规范和法律法规,尊重网站的权利和用户的隐私,以合法、合理、负责的方式进行数据抓取和处理。
相关文章:

爬虫大全:从零开始学习爬虫的基础知识
爬虫是一种自动获取网站信息的技术,它可以帮助我们快速地抓取海量网站数据,进行统计分析、挖掘和展示。本文旨在为初学者详细介绍爬虫的基础知识,包括:爬虫原理、爬虫分类、网页结构分析、爬虫工具和技能、爬虫实践示范࿰…...

【Python】【进阶篇】21、Django Admin数据表可视化
目录 21、Django Admin数据表可视化1. 创建超级用户2. 将Model注册到管理后台1)在admin.py文件中声明 3. django_admin_log数据表 21、Django Admin数据表可视化 在《Django Admin后台管理系统》介绍过 Django 的后台管理系统是为了方便站点管理人员对数据表进行操作。Django …...

【MySQL约束】数据管理实用指南
1、数据库约束的认识 数据库约束的概念:数据库的约束是关系型数据库的一个重要的功能,它提供了一种“校验数据”合法性的机制,能够保证数据的“完整性”、“准确性”和“正确性” 数据库的约束: not null:不能存储 nul…...
2023年第二十届五一数学建模竞赛C题:“双碳”目标下低碳建筑研究-思路详解与代码答案
该题对于模型的考察难度较低,难度在于数据的搜集以及选取与处理。 这里推荐数据查询的网站:中国碳核算数据库(CEADs) https://www.ceads.net.cn/ 国家数据 国家数据data.stats.gov.cn/easyquery.htm?cnC01 以及各省市《统…...

Vue父组件生命周期和子组件生命周期触发顺序
加载渲染过程 父 beforeCreate -> 父 created -> 父 beforeMount -> 子 beforeCreate -> 子 created -> 子 beforeMount -> 子 mounted -> 父 mounted子组件更新过程 父 beforeUpdate -> 子 beforeUpdate -> 子 updated -> 父 updated父组件更新…...

DevOps工程师 - 面试手册
DevOps工程师 - 面试手册 岗位概述 DevOps工程师是一种专注于提高软件开发和运维团队协作、提高软件产品交付速度和质量的职位。这种角色要求具备跨领域的知识,以便在开发和运维过程中建立起稳定、可靠的基础设施和自动化流程。 常见的职位招聘描述 负责设计、实…...

Netty内存管理--内存池空间规格化SizeClasses
一、规格化 内存池类似于一个内存零售商, 从操作系统中申请一整块内存, 然后对其进行合理分割, 将分割后的小内存返回给程序。这里存在3个尺寸: 分割尺寸: 底层内存管理的基本单位, 比如常见的以页为单位分配, 但是页的大小是灵活的;申请尺寸: 内存使用者希望申请到的内存大小…...

数据结构刷题(三十):96不同的二叉搜索树、01背包问题理论、416分割等和子集
一、96. 不同的二叉搜索树 1.这个题比较难想递推公式, dp[3],就是元素1为头结点搜索树的数量 元素2为头结点BFS的数量 元素3为头结点BFS的数量 元素1为头结点搜索树的数量 右子树有2个元素的搜索树数量 * 左子树有0个元素的搜索树数量 元素2为头结…...

bash的进程与欢迎讯息自定义
在bash shell中,可以通过多种方式自定义欢迎讯息和提示符。主要有: 修改/etc/profile文件: 该文件在用户登录后执行,定义了PROMPT_COMMAND和PS1提示符。可以修改其内容实现自定义欢迎讯息和提示符。 例如,修改为: bash PROMPT_COMMANDecho -e "\nWelcome to My Bash She…...

本周大新闻|苹果首款MR没有主打卖点;Meta认为AI是AR OS的基础
本周XR大新闻,AR方面,苹果首款MR或没有主打卖点,反而尽可能支持更多App和服务;扎克伯格表示基于AI的AR眼镜操作系统是下一代计算平台的基础;微软芯片工程VP Jean Boufarhat加入Meta芯片团队;Humane展示了…...

Java中工具类Arrays、Collections、Objects
Arrays Arrays是Java中提供的一个针对数组操作的工具类,所有的方法都是静态的。 大致有这些常用的方法 sort()针对常用的基本数据类型,都能进行排序,byte、char、int、long、float、doubleparallelSort()并行排序,多线程排序&am…...

Docker安装Nginx/Python/Golang/Vscode【亲测可用】
一、docker安装nginx docker安装nginx,安装的是最新版本的:docker pull nginx:latest 创建一个容器:docker run --name my-nginx -p 80:80 -d nginx:latest 开启一个交互模式终端:docker exec -it my-nginx bash 创建django项…...

蓝桥杯2022年第十三届决赛真题-最大数字
蓝桥杯2022年第十三届决赛真题-最大数字 时间限制: 3s 内存限制: 320MB 题目描述 给定一个正整数 N。你可以对 N 的任意一位数字执行任意次以下 2 种操作: 将该位数字加 1。如果该位数字已经是 9,加 1 之后变成 0。 将该位数字减 1。如果该位数字已经…...
smbms项目搭建
目录 1.搭建一个maven web项目 2.配置Tomcat 3.测试项目是否能够跑起来 4.导入项目中会遇到的Jar包 5.项目结构搭建 6.项目实体类搭建 7.编写基础公共类 1.数据库配置文件 2.编写数据库的公共类 3.编写字符编码过滤器 3.1web配置注册 4.导入静态资源 1.搭建一个maven web项目 …...
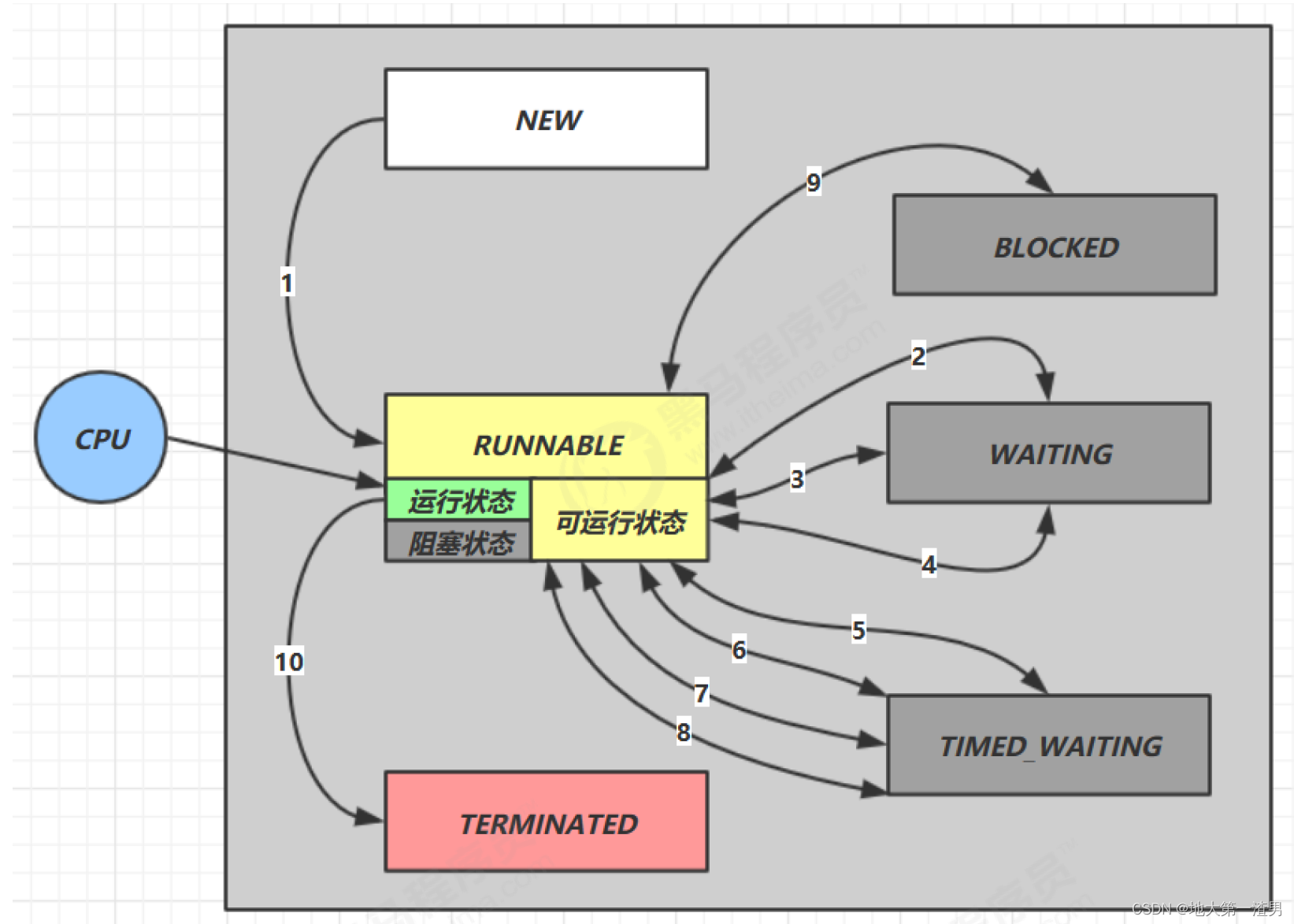
进程/线程 状态模型详解
前言:最近操作系统复习到线程的状态模型(也可以说进程的状态模型,本文直接用线程来说)时候,网上查阅资料,发现很多文章都说的很不一样,有五状态模型、六状态模型、七状态模型.......虽然都是对的…...
)
数据结构与算法之队列: Leetcode 621. 任务调度器 (Typescript版)
任务调度器 https://leetcode.cn/problems/task-scheduler/ 描述 给你一个用字符数组 tasks 表示的 CPU 需要执行的任务列表。其中每个字母表示一种不同种类的任务。任务可以以任意顺序执行,并且每个任务都可以在 1 个单位时间内执行完。在任何一个单位时间&#…...
【报错】arXiv上传文章出现XXX.sty not found
笔者在overleaf上编译文章一切正常,但上传文章到arxiv时出现类似于如下报错: 一般情况下观察arxiv的编译log,不通过的原因,很多时候都是由于某一行导入了啥package,引起的报错;但是如果没有任何一个具体的…...

项目合同管理
项目合同管理的基本概念及分类、项目合同签订、项目合同管理以及项目合同索赔处理等内容 信息系统工程的建设过程实际上就是合同的执行和监控的过程 1、项目合同的概念及分类 合同法律关系:权力和义务关系 合同可以是书面形式、口头形式和其他形式 书面形式是指…...

聊聊ClickHouse向量化执行引擎-过滤操作
俄罗斯Yandex开发的ClickHouse是一款性能黑马的OLAP数据库,其对SIMD的灵活运用给其带来了难以置信的性能。本文我们聊聊它如何对过滤操作进行SIMD优化。 基本思想 1、有一个数组data,即ColumnVector::data,存放数据 2、使用uint8类型…...
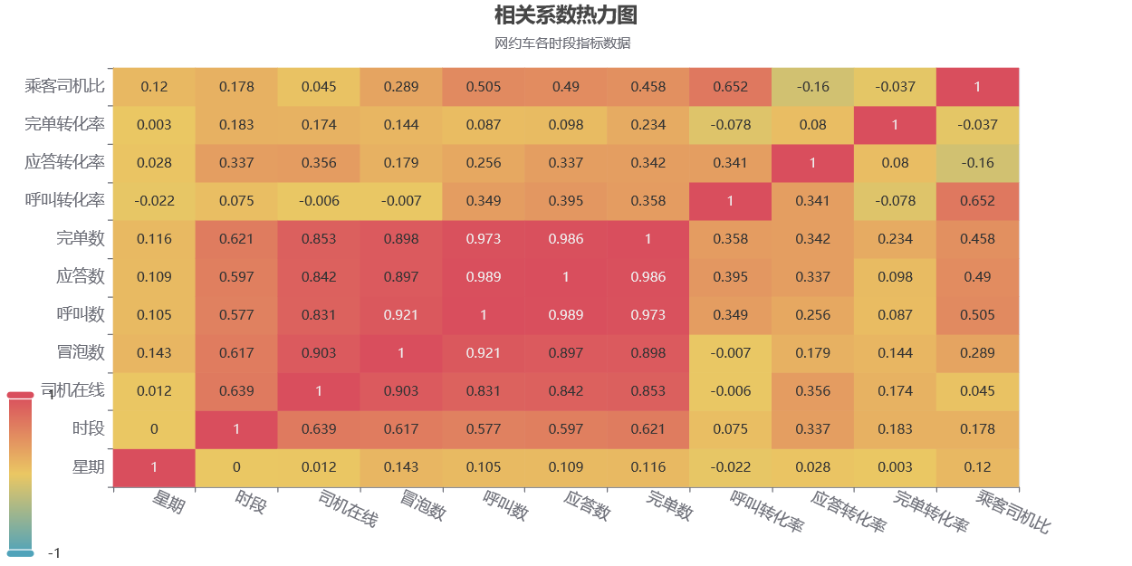
数据可视化第二版-拓展-网约车分析案例
文章目录 数据可视化第二版-拓展-网约车分析案例竞赛介绍 1等奖作品-IT从业者张某某的作品结论过程数据和思考数据处理数据探索数据分析方法选择数据分析相关性分析转化率分析分析结论 完单数量分析分析结论 司机数量分析分析结论 时间分析每日订单分析 工作日各时段分析周六日…...

基于Agent架构的轻量级自托管部署工具Ship实战指南
1. 项目概述:一个为开发者而生的轻量级部署工具最近在折腾一个前后端分离的小项目,从本地开发到服务器部署,中间那套流程真是让人头大。代码提交、构建、测试、再到服务器上拉取、重启服务,一套组合拳下来,少说也得十几…...

三步解决Zotero中文文献管理难题:茉莉花插件完整指南
三步解决Zotero中文文献管理难题:茉莉花插件完整指南 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 你是否在使用Zot…...

NotebookLM与Google Drive整合性能瓶颈实测报告:单次索引超10万页PDF时,延迟突增217%的根源与绕行方案
更多请点击: https://intelliparadigm.com 第一章:NotebookLM与Google Drive整合性能瓶颈实测报告:单次索引超10万页PDF时,延迟突增217%的根源与绕行方案 延迟突增的核心成因 实测表明,当 NotebookLM 通过 Google Dr…...

二十七、RZN2L CherryUSB移植与性能对比
一、目的/概述1、cherryusb还没有人支持瑞萨芯片,我们尝试在RZN2L CR52上移植CherryUSB协议栈2、在rzn2l芯片上实现USB CDC ACM 功能(实现cherryusb hal)3、对比CherryUSB与瑞萨原厂USB例程的性能差异4、验证全速(12Mbps)和高速(4…...

2026年AGI突围:自主智能体驱动,数字生命从架构落地到自我迭代全解析
2026年,AI行业正式告别“生成式狂欢”,迈入“自主智能体(AI Agent)规模化落地元年”。Gartner将自主智能体列为年度十大战略技术趋势之首,各大科技厂商纷纷布局,从实验室概念到产业应用,自主智能…...

RedwoodJS执行器:命令执行与进程管理的终极指南
RedwoodJS执行器:命令执行与进程管理的终极指南 【免费下载链接】redwood RedwoodGraphQL 项目地址: https://gitcode.com/gh_mirrors/re/redwood RedwoodJS是一个功能强大的全栈JavaScript框架,它提供了一套完整的工具链来简化现代web应用的开发…...

如何使用pretty-ts-errors:TypeScript错误追踪与性能优化终极指南
如何使用pretty-ts-errors:TypeScript错误追踪与性能优化终极指南 【免费下载链接】pretty-ts-errors 🔵 Make TypeScript errors prettier and human-readable in VSCode 🎀 项目地址: https://gitcode.com/gh_mirrors/pr/pretty-ts-error…...

Cadence-OS深度解析:Uber Cadence增强发行版的生产实践指南
1. 项目概述与核心价值最近在梳理工作流自动化工具时,又翻出了paulophl94/cadence-os这个项目。它不是一个全新的轮子,而是基于 Uber 开源的 Cadence 工作流引擎,进行深度定制和增强的一个发行版。如果你正在为微服务架构下的复杂业务流程编排…...

智能缓存优化LibraVDB视频数据库内存管理实战
1. 项目概述与核心价值 最近在折腾一个需要处理大量视频流和图像识别的项目,遇到了一个老生常谈但又极其棘手的问题:内存。尤其是在使用像LibraVDB这样的开源视频数据库进行帧级数据存取时,传统的缓存策略要么命中率低,要么内存占…...

加州DMV十年自动驾驶报告深度解析:从测试数据看行业格局与技术演进
1. 项目概述:一份数据,十年自动驾驶风云如果你关注自动驾驶,那你一定听说过加州车管局(DMV)的年度测试报告。这玩意儿,可以说是全球自动驾驶行业的“晴雨表”和“成绩单”。从2015年开始,加州就…...