Hive本地开发/学习环境配置
前提
hive依赖hadoop的相关组件,需要启动Hadoop的相关组件。
Hive 版本:3.1.3
Hadoop版本:3.3.4
hive-env.sh
export HADOOP_HOME=$HADOOP_HOME
export HIVE_CONF_DIR=/usr/local/Cellar/hive/3.1.3/libexec/conf
export HIVE_AUX_JARS_PATH=/usr/local/Cellar/hive/3.1.3/libexec/lib
hive-site.xml
<configuration><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value><description>JDBC connect string for a JDBC metastore</description></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value><description>Driver class name for a JDBC metastore</description></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value><description>username to use against metastore database</description></property><property><name>javax.jdo.option.ConnectionPassword</name><value>root</value><description>password to use against metastore database</description></property><property><name>hive.cli.print.header</name><value>true</value></property><property><name>hive.cli.print.current.db</name><value>true</value></property><property><name>hive.metastore.schema.verification</name><value>false</value></property><!-- hiveserver2运行绑定的host --><property><name>hive.server2.thrift.bind.host</name><value>localhost</value></property><!-- 远程模式部署metastore 的地址 --><property><name>hive.metastore.uris</name><value>thrift://localhost:9083</value></property><!-- 配置hiveserver2服务启动问题(不配置,则hiveserver无法监听服务,会导致beeline客户端无法连接) --><property><name>hive.metastore.event.db.notification.api.auth</name><value>false</value></property>
</configuration>
hive初始化
需要先启动Hadoop的相关组件服务。
schematool -dbType mysql -initSchema --verbose
注意:一定要先-dbType mysql然后才-initSchema,否则会出现连接MySQL的错误,
Metastore connection URL: jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useSSL=false
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: root
org.apache.hadoop.hive.metastore.HiveMetaException: Failed to get schema version.
Underlying cause: com.mysql.jdbc.exceptions.jdbc4.CommunicationsException : Communications link failureThe last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.
SQL Error code: 0
org.apache.hadoop.hive.metastore.HiveMetaException: Failed to get schema version.at org.apache.hadoop.hive.metastore.tools.HiveSchemaHelper.getConnectionToMetastore(HiveSchemaHelper.java:94)at org.apache.hive.beeline.HiveSchemaTool.getConnectionToMetastore(HiveSchemaTool.java:169)at org.apache.hive.beeline.HiveSchemaTool.testConnectionToMetastore(HiveSchemaTool.java:475)at org.apache.hive.beeline.HiveSchemaTool.doInit(HiveSchemaTool.java:581)at org.apache.hive.beeline.HiveSchemaTool.doInit(HiveSchemaTool.java:567)at org.apache.hive.beeline.HiveSchemaTool.main(HiveSchemaTool.java:1517)at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)at java.lang.reflect.Method.invoke(Method.java:498)at org.apache.hadoop.util.RunJar.run(RunJar.java:323)at org.apache.hadoop.util.RunJar.main(RunJar.java:236)
Caused by: com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failureThe last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)at java.lang.reflect.Constructor.newInstance(Constructor.java:423)at com.mysql.jdbc.Util.handleNewInstance(Util.java:403)at com.mysql.jdbc.SQLError.createCommunicationsException(SQLError.java:990)at com.mysql.jdbc.MysqlIO.<init>(MysqlIO.java:335)at com.mysql.jdbc.ConnectionImpl.coreConnect(ConnectionImpl.java:2187)at com.mysql.jdbc.ConnectionImpl.connectOneTryOnly(ConnectionImpl.java:2220)at com.mysql.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:2015)at com.mysql.jdbc.ConnectionImpl.<init>(ConnectionImpl.java:768)at com.mysql.jdbc.JDBC4Connection.<init>(JDBC4Connection.java:47)at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)at java.lang.reflect.Constructor.newInstance(Constructor.java:423)at com.mysql.jdbc.Util.handleNewInstance(Util.java:403)at com.mysql.jdbc.ConnectionImpl.getInstance(ConnectionImpl.java:385)at com.mysql.jdbc.NonRegisteringDriver.connect(NonRegisteringDriver.java:323)at java.sql.DriverManager.getConnection(DriverManager.java:664)at java.sql.DriverManager.getConnection(DriverManager.java:247)at org.apache.hadoop.hive.metastore.tools.HiveSchemaHelper.getConnectionToMetastore(HiveSchemaHelper.java:88)... 11 more
Caused by: java.net.ConnectException: Connection refused (Connection refused)at java.net.PlainSocketImpl.socketConnect(Native Method)at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350)at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206)at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188)at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)at java.net.Socket.connect(Socket.java:606)at com.mysql.jdbc.StandardSocketFactory.connect(StandardSocketFactory.java:211)at com.mysql.jdbc.MysqlIO.<init>(MysqlIO.java:299)... 26 more
*** schemaTool failed ***
metastore服务启动
进入hive的bin目录,执行命令hive --service metastore ,或者使用nohup命令进行后台启动,nohup hive --service metastore &,这样就启动了metastore服务,可以通过jps命令查看,是否存在RunJar的进程,存在则说明启动成功,再通过hive客户端连接即可。


hiveserver2服务启动
该服务依赖于metastore服务,所以,在启动hiveserver2之前,一定确保已经启动了metastore服务,这时,可以通过hive --service hiveserver2命令启动服务,当然同样可以通过nohup命令进行后台启动,nohup hive --service hiveserver2 &,启动后,通过jps命令查看服务进程,此时会多出一个RunJar的进程,即为hiverserver2的服务。


通过beeline客户端进行连接,此时还没有真正连接上。

还需要在当前客户端窗口输入hiveserver2的连接信息,! connect jdbc:hive2://localhost:10000,hive2默认的端口为10000,此时,会提示让你输入用户名名,然后再输入密码。
Error:Could not open client transport with JDBC Uri: jdbc:hive2://localhost:10000/default:java.net.ConnectException refused
出现上述错误
需要在hive-site。添加如下配置
<property><name>hive.metastore.event.db.notification.api.auth</name><value>false</value>
</property>

然后重新启动相关服务,再使用beeline客户端连接,出现了如下错误:
beeline> !connect jdbc:hive2://localhost:10000
Connecting to jdbc:hive2://localhost:10000
Enter username for jdbc:hive2://localhost:10000: yuxiao
Enter password for jdbc:hive2://localhost:10000:
23/05/01 18:14:01 [main]: WARN jdbc.HiveConnection: Failed to connect to localhost:10000
Error: Could not open client transport with JDBC Uri: jdbc:hive2://localhost:10000: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: yuxiao is not allowed to impersonate yuxiao (state=08S01,code=0)
这个问题是由于不允许你当前登录的用户访问hadoop,所以需要调整hadoop的core-site.xml的配置,添加相关proxuser的访问即可,
<property><name>hadoop.proxyuser.用户名.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.用户名.groups</name><value>*</value></property>
将配置文件的用户修改上hive不允许访问的用户名,配置文件修改后,重新启动hadoop的dfs服务,
再使用beeline客户端访问,用户名输入之前提示不允许访问的用户名,密码直接回车即可,这样就可以正常访问hive了,如下图所示:

查看数据库:

hive webui配置
hiveserver2服务具有可视化界面,查看相关信息,需要在hive-site.xml文件配置webui,如下所示:
<property><name>hive.server2.webui.host</name><value>127.0.0.1</value>
</property>
<property><name>hive.server2.webui.port</name><value>10002</value>
</property>
在启动hiveserver2服务后,访问10002端口查看webui,如下:

相关文章:
Hive本地开发/学习环境配置
前提 hive依赖hadoop的相关组件,需要启动Hadoop的相关组件。 Hive 版本:3.1.3 Hadoop版本:3.3.4 hive-env.sh export HADOOP_HOME$HADOOP_HOME export HIVE_CONF_DIR/usr/local/Cellar/hive/3.1.3/libexec/conf export HIVE_AUX_JARS_PATH/…...
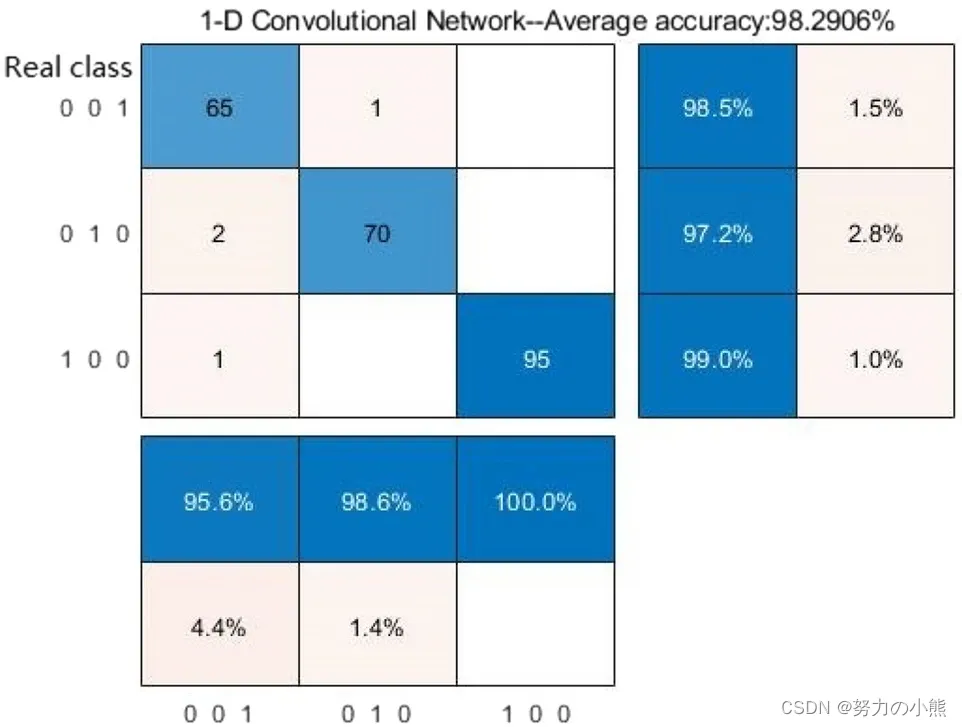
《基于EPNCC的脉搏信号特征识别与分类研究》阅读笔记
目录 一、论文摘要 二、论文十问 三、论文亮点与不足之处 四、与其他研究的比较 五、实际应用与影响 六、个人思考与启示 参考文献 一、论文摘要 为了快速获取脉搏信号的完整表征信息并验证脉搏信号在相关疾病临床诊断中的敏感性和有效性。在本文中,提出了一…...
)
Linux下解压和压缩命令大全(详解+案例)
linux常用的解压和压缩命令如下: .zip或.zipx 压缩文件.zip、.zipx:都可以使用zip命令。例如,要将目录/home/user1/mydata压缩成一个文件mydata.zip,可以使用以下命令: zip -r mydata.zip /home/user1/mydata/要解压…...

Linux的常用指令
重启 init 6或reboot 关机 init 0 或halt如果没有执行关机命令,强制断电或关闭本地虚拟机的窗口,会导致Linux操作系统文件的损坏,严重的可能导致系统无法正常启动。 清屏 clear 查看服务器的ip地址 ip addr 时间操作 普通用户可以查看时间&am…...

第 5 章 HBase 优化
5.1 RowKey 设计 一条数据的唯一标识就是 rowkey,那么这条数据存储于哪个分区,取决于 rowkey 处于 哪个一个预分区的区间内,设计 rowkey的主要目的 ,就是让数据均匀的分布于所有的 region 中,在一定程度上防止数据倾斜…...
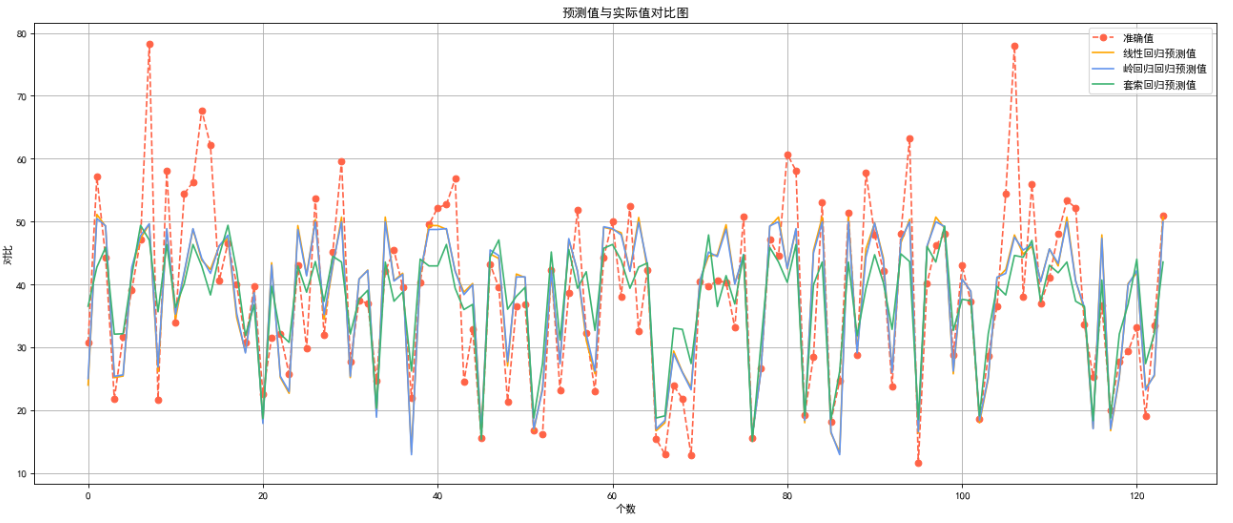
台北房价预测
目录 1.数据理解1.1分析数据集的基本结构,查询并输出数据的前 10 行和 后 10 行1.2识别并输出所有变量 2.数据清洗2.1输出所有变量折线图2.2缺失值处理2.3异常值处理 3.数据分析3.1寻找相关性3.2划分数据集 4.数据整理4.1数据标准化 5.回归预测分析5.1线性回归&…...
9:00进去,9:05就出来了,这问的也太···
从外包出来,没想到死在另一家厂子了。 自从加入这家公司,每天都在加班,钱倒是给的不少,所以也就忍了。没想到8月一纸通知,所有人不许加班,薪资直降30%,顿时有吃不起饭的赶脚。 好在有个兄弟内推…...

debootstrap 构建 RISC-V 64 Ubuntu 根文件系统
debootstrap 构建 Ubuntu RISC-V Linux 根文件系统 flyfish 主机信息 命令 lsb_release -a No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 20.04.6 LTS Release: 20.04 Codename: focal制作的根文件系统为 RISC-V 64 Ubuntu 22.04 LTS 1 主机…...
怎么样?)
腾讯云轻量应用服务器(Lighthouse)怎么样?
轻量应用服务器是否好用,小白这么多年的经验来看,跑企业站或博客都没问题,因为小流量站是可以的。但是限制流量的服务器只适合小站。超流量后是要扣费的。简而言之,超过流量是按流量计费的。如果被攻击大概率会欠费。如果是企业用…...

学习 AI 常用的一些专业词汇
学习 AI 常用的一些专业词汇 AI 词汇集 AI 词汇集 神经网络(Neural Network): 由节点(模型参数)和连接(权重)组成的网络结构,用于机器学习与深度学习。 深度学习(Deep Learning): 使用包含多隐藏层神经网络进行表征学习的机器学习方法。 机器学习(Machine Learnin…...

IP协议基础
文章目录 基本概念IP和TCP分别解决什么问题 以下过程都是在网络层完成的网段划分路由路由转发过程路由表 基本概念 主机: 配有IP地址, 但是不进行路由控制的设备。 路由器: 即配有IP地址, 又能进行路由控制。 节点: 主机和路由器的统称。 IP和TCP分别解决什么问题 TCP解决…...

Redis主从复制、哨兵实战
环境:linux centos7.x ,虚拟机3台 版本:redis-6.2.6 1.下载安转redis 下载地址 wget https://download.redis.io/releases/redis-6.2.6.tar.gz解压 tar -zxvf redis-6.2.6.tar.gz移动目录 mv redis-6.2.6 /usr/local/redis编译 cd /usr/…...

README.md编写
一、摘要 项目一般会有个描述文件,对于项目的代码来讲,这个描述就是README.md文件,可以描述各模块功能、目录结构等。该文件可以方便让人快速了解项目的代码结构和功能。当然,若要深层次的了解项目,就得看项目总体的需…...

软件设计证书倒计时28天
从一个月前的果断报考软件设计证书,我没有后悔过。 软件设计证书一个月备考情况: 现在做选择题的正确率可以达到65%。是重复做过两遍历年真题。 接下来是继续做模拟题。 大题的题型基本是都知道, 第一题数据流图,第二题er图&…...

程序员基础的硬件知识(cpu、主板、显卡、内存条等)
一、综合简介 cpu:负责运算数据,就等于你的大脑运算速度。 显卡:本来没有显卡,后来因为大家对图片要求越来越高,视频要求越来越高,啥都让cpu算太累了,于是分出来一个,专门用来计算…...
优化Google Cloud Storage大文件上传和内存溢出
背景 我们的项目每天都会并行上传好几万份文件到下游的GCP Cloud Storage,当文件比较大时,会采用GCP的可续上传方案,通过把文件切分成多个数据块,分多次HTTP请求上传到GCP Bucket,具体可参考https://cloud.google.com…...

chatGPT的prompt技巧
Prompt 公式是 Prompt 的特定格式,通常由三个主要元素组成: 任务:明确而简洁地陈述 Prompt 要求模型生成的内容。指令:模型在生成文本时应遵循的指令。角色:模型在生成文本时应扮演的角色。 指令 Prompt 技术 指令 …...
)
【华为OD机试 2023最新 】统一限载货物数最小值(C语言题解 100%)
文章目录 题目描述输入描述输出描述备注用例题目解析代码思路C语言题目描述 火车站附近的货物中转站负责将到站货物运往仓库,小明在中转站负责调度2K辆中转车(K辆干货中转车,K辆湿货中转车)。 货物由不同供货商从各地发来,各地的货物是依次进站,然后小明按照卸货顺序依…...

ios 在windows chrome 联调
必要条件 1、iOS设备、数据线 2、Node.js 环境 3、Chrome 浏览器 4、电脑登录iTunes 5、手机 Safari 浏览器环境准备 1、安装Node环境参考Node安装的教程,确保终端输入node时可正常使用 2、安装 scoope 以及相关配置为了安装后续需要用的工具 remotedebug-ios-web…...

干翻Mybatis源码系列之第六篇:Mybatis可选缓存概述
前言 一:后续Mybatis我们会研究那些内容? Mybatis核心运行源码分析(前面系列文章已经探讨过) Mybatis中缓存的使用 Mybatis与Spring集成 Mybatis 插件。 Mybatis的插件可以对Mybatis内核功能或者是业务功能进行拓展,…...

AwesomeQRCode源码阅读笔记:深入理解二维码渲染核心技术
AwesomeQRCode源码阅读笔记:深入理解二维码渲染核心技术 【免费下载链接】AwesomeQRCode An awesome QR code generator for Android. 项目地址: https://gitcode.com/gh_mirrors/aw/AwesomeQRCode 想要为你的Android应用添加炫酷的二维码生成功能吗…...

121.YOLOv8从零到一实战,猫犬检测全流程,代码带注释,零基础也能学会
摘要 YOLO(You Only Look Once)是当前工业界和学术界最主流的目标检测算法之一,其核心优势在于将目标检测任务转化为单次回归问题,实现端到端的实时检测。本文从零基础出发,系统讲解YOLO的核心原理、模型架构演进,并基于Ultralytics框架提供完整的可运行代码案例,涵盖数…...

IPBan快速入门:一键安装配置,立即阻止僵尸网络入侵
IPBan快速入门:一键安装配置,立即阻止僵尸网络入侵 【免费下载链接】IPBan Since 2011, IPBan is the worlds most trusted, free security software to block hackers and botnets. With both Windows and Linux support, IPBan has your dedicated or …...

CANN/ops-nn自适应平均池化3D反向计算
aclnnAdaptiveAvgPool3dBackward 【免费下载链接】ops-nn 本项目是CANN提供的神经网络类计算算子库,实现网络在NPU上加速计算。 项目地址: https://gitcode.com/cann/ops-nn 产品支持情况 📄 查看源码 产品是否支持Ascend 950PR/Ascend 950DT√…...
)
【2026年携程暑期实习- 5月10日-第四题-单数组交换】(题目+思路+JavaC++Python解析+在线测试)
题目内容 游游有两个长度同为 nnn 的整数数组 aaa 和 bbb。她会对数组...
架构与安全供应实战解析)
Arm生命周期管理器(LCM)架构与安全供应实战解析
1. Arm生命周期管理器(LCM)架构解析生命周期管理器(Lifecycle Manager)是Arm安全架构中的核心安全子系统,负责管理芯片从生产到报废全生命周期的安全状态。我在多个物联网安全芯片项目中验证过,LCM的设计直接影响设备的抗攻击能力和密钥管理可靠性。1.1 …...

构建LLM智能体可学习记忆系统:Membrane架构与实战指南
1. 项目概述:为LLM智能体构建一个可学习、可修正的记忆系统如果你正在构建一个长期运行的LLM智能体,或者一个需要“记住”过去经验并从中学习的AI系统,那么“记忆”问题很可能已经让你头疼不已。传统的做法,要么是把所有对话历史一…...

电子热量表设计:PIC16F913微控制器应用与热力计算
1. 电子热量表的核心原理与设计需求 在集中供暖系统中,热量表扮演着能量"会计"的角色,精确记录每户消耗的热能。其核心任务可以分解为三个关键参数的测量:进水温度、回水温度以及水流量。这三个参数通过热力学基本公式QmcpΔT相互关…...

如何用python函数制作一个计算工具
大家好,这里是junlang的python文章 今天教大家如何用python函数做一个计算器,希望大家好好学习哦 如何制作 首先我们先定义4个函数,其中除法计算代码请看下面: def add (a,b,c):return (a b - c) def sub (x,y):return(x - y) def mulpl…...

星露谷物语模组加载器SMAPI:免费开源的游戏增强终极指南
星露谷物语模组加载器SMAPI:免费开源的游戏增强终极指南 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI 星露谷物语模组加载器SMAPI是《星露谷物语》的官方模组API,为这款经典…...