2023年五一数学建模 B 题过程与结果
第一问
见 2023 年 五一杯 B 题过程 + 代码(第一问)
第二问
第二问考虑是一个时序预测问题,采用 ARIMA 模型即可
数据时序分析
对于 每一个路径,快递数时间序列,以路径 G->L 为例,其取值如下所示:
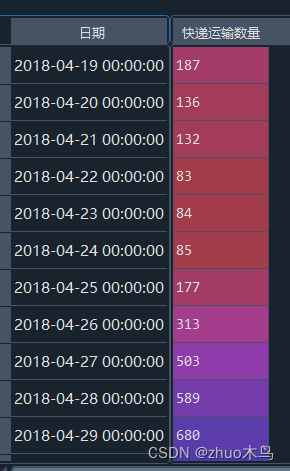
根据 ADF 检验,分析出路径 G->L 是否为稳定序列。根据 ADF 假设检验结果,由于ADF检验的 p值为: 0.002 检验统计量 ADF 为: -3.87。由于 p 值小于置信水平 0.05,因此可以认为时间序列是平稳的。
因此,采用 ARIMA(p,d,q)模型时,差分系数应为 d = 0。如果 ADF 检验的 p 值小于 0.05,则说明差分后的序列是平稳的。否则需要继续进行差分。此时差分系数 d 等于差分直至时序数据平稳时的差分次数。
绘制时序数据的自相关图,和偏自相关图,如下:
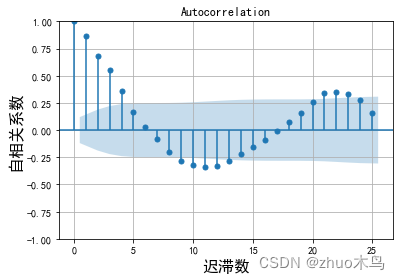
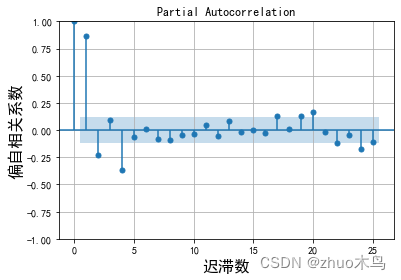
从图中可以得出,ARIMA 模型的自回归系数为 p=5(自相关系数截尾),移动平均系数 q=1(偏相关系数均衡衰减,取较小值 q)。
Auto-ARIMA
通过偏自相关系数图、自相关系数图筛选 p,q 带有主观性。因此结合 AIC 评价指标,将数据分为测试集和验证集,从而在众多(p,q)参数的组合中,筛选出最佳的 p,q 并与 ADF 检验确定的 d 值,从而得出最佳的 ARIMA 模型。
具体流程为:
- 对每一个路径,绘制偏自相关系数、自相关系数图,筛选 p,q 的最大取值 p m a x , q m a x p_{max}, q_{max} pmax,qmax。如上例 G-> L 路径可取 p m a x = 5 , q m a x = 1 p_{max}=5, q_{max}=1 pmax=5,qmax=1
- 取 p ∈ ( 0 , 1 , ⋯ , p m a x ) , q ∈ ( 0 , 1 , ⋯ , q m a x ) p\in(0,1,\cdots,p_max), q\in(0,1,\cdots,q_max) p∈(0,1,⋯,pmax),q∈(0,1,⋯,qmax),与 d 组合。d 根据 ADF 检验得来,如上例 G->L 路径可取 d = 0,构建 ARIMA 模型,同时按照 7:3 的比例将数据集切分为训练集和测试集
- 将模型在训练集中训练并计算 AIC 指标(AIC 只能在训练的过程中计算)
- 重复 2 -3 步骤,指导遍历完所有 p、d、q 组合,输出 AIC 最小(即最佳)的 ARIMA 模型作为预测模型。并采用 MAPE,即平均绝对偏差的百分数,在测试集中评价模型
- 采用该预测模型预测数据的效果。
第二问求解
就以题目中的 M->U 为例吧,绘制图像
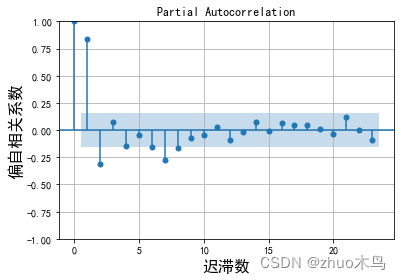
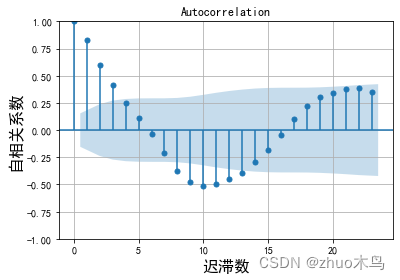
从自相关图和偏相关图可以取 p m a x = 3 , q m a x = 4 p_{max}=3, q_{max}=4 pmax=3,qmax=4,根据 ADF 的结果:
差分0次后时序稳定
ADF检验的 p值为: 2.63e-08
检验统计量 ADF 为: -6.35
取 d = 0, p m a x = 5 , q m a x = 5 p_{max}=5, q_{max}=5 pmax=5,qmax=5(考虑多种可能性)。根据网格寻优筛选出最佳模型为 p=1, d=0, q=3。
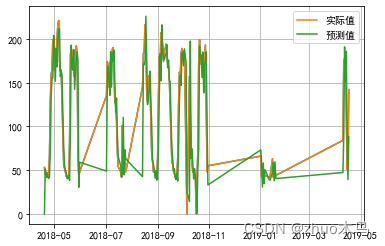
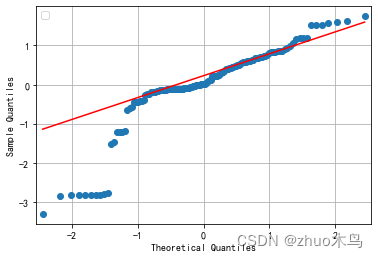
绘制出残差的 Q-Q 图,以观察残差是否服从正态分布:
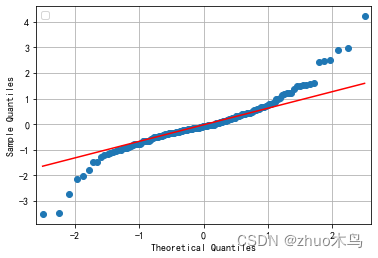
感觉还行,然后用 MAPE 数值分析他的拟合优度:
M A P E = 100 n ∑ i = 1 n ∣ y i − y i ^ ∣ y i MAPE = \frac{100}{n} \sum_{i=1}^{n} \frac{|y_i - \hat{y_i}|}{y_i} MAPE=n100i=1∑nyi∣yi−yi^∣
其中, n n n 是样本数量, y i y_i yi 是实际值, y i ^ \hat{y_i} yi^ 是预测值。可求出其值为:0.375
MAPE 的值越小,说明预测结果越准确。然而,MAPE 也有一些缺点,例如它对于实际值为 0 的样本会导致无法计算,同时它也对极端值比较敏感。因此,在使用 MAPE 作为评估指标时,需要结合实际情况进行分析。
解的情况
同理,可以求出其他模型,结论如下:
目前求解 M->U 路径
差分0次后时序稳定
ADF检验的 p值为: 0.0
检验统计量 ADF 为: -6.35
4 (根据自相关系数图像,筛选出的 p 值,下同)
3(根据偏自相关系数,筛选出的 q 值,下同)
模型的mape为: 0.38 最佳参数(p,d,q)为: (4, 0, 1)
M->U 路径中 4-18 和 4-19 的快递数量分别为:150.12 和 133.39
目前求解 Q->V 路径
差分1次后时序稳定
ADF检验的 p值为: 0.0
检验统计量 ADF 为: -8.39
8
4
模型的mape为: 46422190913933.88 最佳参数(p,d,q)为: (1, 1, 1)
Q->V 路径中 4-18 和 4-19 的快递数量分别为:48.17 和 48.17
目前求解 K->L 路径
差分0次后时序稳定
ADF检验的 p值为: 0.0
检验统计量 ADF 为: -4.4
5
3
模型的mape为: 0.26 最佳参数(p,d,q)为: (1, 0, 1)
K->L 路径中 4-18 和 4-19 的快递数量分别为:54.27 和 54.1
目前求解 G->V 路径
差分0次后时序稳定
ADF检验的 p值为: 0.0
检验统计量 ADF 为: -6.84
5
5
模型的mape为: 0.14 最佳参数(p,d,q)为: (1, 0, 1)
G->V 路径中 4-18 和 4-19 的快递数量分别为:599.71 和 552.6
目前求解 V->G 路径
差分0次后时序稳定
ADF检验的 p值为: 0.0
检验统计量 ADF 为: -6.94
5
2
模型的mape为: 0.1 最佳参数(p,d,q)为: (1, 0, 1)
V->G 路径中 4-18 和 4-19 的快递数量分别为:543.1800000000001 和 509.63
目前求解 A->Q 路径
差分0次后时序稳定
ADF检验的 p值为: 0.0
检验统计量 ADF 为: -4.65
6
3
模型的mape为: 110116766402955.56 最佳参数(p,d,q)为: (5, 0, 1)
A->Q 路径中 4-18 和 4-19 的快递数量分别为:129.09 和 119.93
目前求解 D->A 路径
差分0次后时序稳定
ADF检验的 p值为: 0.0
检验统计量 ADF 为: -5.45
4
2
模型的mape为: 1141794030037002.0 最佳参数(p,d,q)为: (1, 0, 1)
D->A 路径中 4-18 和 4-19 的快递数量分别为:43.18 和 42.47
目前求解 L->K 路径
差分0次后时序稳定
ADF检验的 p值为: 0.0
检验统计量 ADF 为: -4.16
6
2
模型的mape为: 0.15 最佳参数(p,d,q)为: (1, 0, 1)
L->K 路径中 4-18 和 4-19 的快递数量分别为:272.32 和 248.46
PS: ARIMA 效果其实也就那样,不过用 LSTM 更惨!!!,本人综合考虑了很多,最终决定采用 ARIMA 模型
D-> A,A-> Q, Q-> V, 这三个路径的 ARIMA 模型,MAPE 值太大了,预测结果不可信。应考虑采用其他办法。
我们可以画出他实际值和预测值的图像
A->Q:
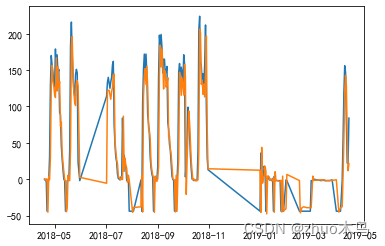
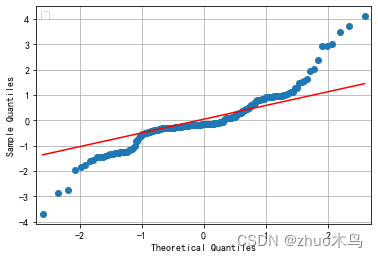
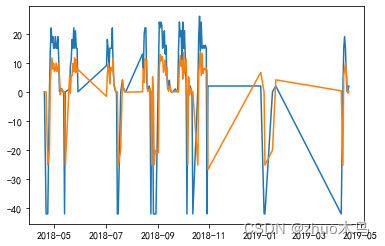
D-> A
Q-V
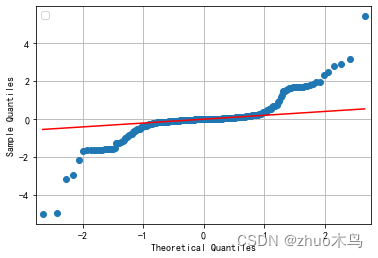
其实从图中可以看出,勉强可以用。把上述的解取整,就可以了。
总快递数
对总快递数也是一样的
差分0次后时序稳定,ADF检验的 p值为: 0.01 ,检验统计量 ADF 为: -3.56
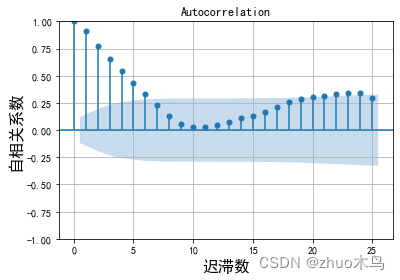
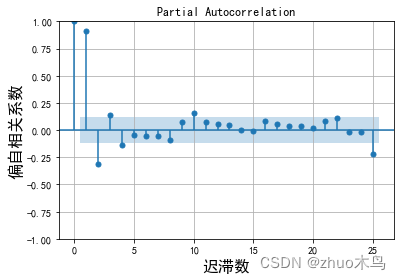
根据图片,设置 p m a x = 7 , q m a x = 5 p_{max}=7, q_{max}=5 pmax=7,qmax=5,筛选模型,从而得到最佳模型的mape为: 1.45。 最佳参数(p,d,q)为: (1, 0, 2)
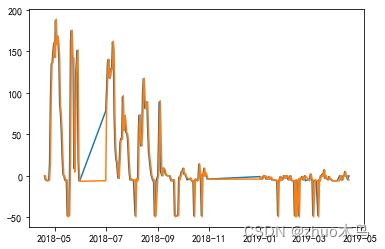
模型训练过程中的实际值和预测值如下,可以看到基本上是挺准确的。
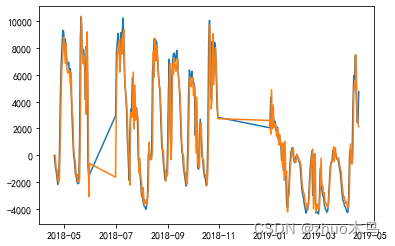
采用模型,求取4-18 和 4-19 的总快递数量分别为:10257.52 和 9473.54,然后取整就行了!
问题二解决。
第三问
首先对每一个路径数据增加一个标签列“可否正常发货”,取值为 0 和 1。1代表可以发货。若有某天缺失了数据,或该天的销售量为 0,则该行的 “可否正常发货” 为 0。
以 A->O 为例:
按照问题 2 的方法,对每一路径,按照“可否正常发货”这个时序数据,构建一个 ARIMA 模型。求解如下:
目前求取的路径是: I->S
差分0次后时序稳定
ADF检验的 p值为: 0.0
检验统计量 ADF 为: -4.18
模型的最佳参数(p,d,q)为: (3, 0, 1)
ARIMA 模型的精确度为: 0.94
I->S 路径中 4-18 和 4-19 的快递数量分别为:1 和 1
目前求取的路径是: M->G
差分0次后时序稳定
ADF检验的 p值为: 0.0
检验统计量 ADF 为: -9.79
模型的最佳参数(p,d,q)为: (1, 0, 1)
ARIMA 模型的精确度为: 0.84
M->G 路径中 4-18 和 4-19 的快递数量分别为:1 和 1
目前求取的路径是: S->Q
差分0次后时序稳定
ADF检验的 p值为: 0.0
检验统计量 ADF 为: -4.07
模型的最佳参数(p,d,q)为: (1, 0, 1)
ARIMA 模型的精确度为: 0.71
S->Q 路径中 4-18 和 4-19 的快递数量分别为:0 和 0
目前求取的路径是: V->A
差分0次后时序稳定
ADF检验的 p值为: 0.0
检验统计量 ADF 为: -4.29
模型的最佳参数(p,d,q)为: (2, 0, 2)
ARIMA 模型的精确度为: 0.88
V->A 路径中 4-18 和 4-19 的快递数量分别为:1 和 1
目前求取的路径是: Y->L
差分0次后时序稳定
ADF检验的 p值为: 0.0
检验统计量 ADF 为: -6.47
模型的最佳参数(p,d,q)为: (1, 0, 1)
ARIMA 模型的精确度为: 0.75
Y->L 路径中 4-18 和 4-19 的快递数量分别为:1 和 1
目前求取的路径是: D->R
差分0次后时序稳定
ADF检验的 p值为: 0.04
检验统计量 ADF 为: -2.99
模型的最佳参数(p,d,q)为: (2, 0, 1)
ARIMA 模型的精确度为: 0.84
D->R 路径中 4-18 和 4-19 的快递数量分别为:1 和 1
目前求取的路径是: J->K
差分0次后时序稳定
ADF检验的 p值为: 0.0
检验统计量 ADF 为: -4.27
模型的最佳参数(p,d,q)为: (1, 0, 2)
ARIMA 模型的精确度为: 0.83
J->K 路径中 4-18 和 4-19 的快递数量分别为:1 和 1
目前求取的路径是: Q->O
差分1次后时序稳定
ADF检验的 p值为: 0.0
检验统计量 ADF 为: -12.1
模型的最佳参数(p,d,q)为: (2, 1, 1)
ARIMA 模型的精确度为: 0.87
Q->O 路径中 4-18 和 4-19 的快递数量分别为:1 和 1
目前求取的路径是: U->O
差分0次后时序稳定
ADF检验的 p值为: 0.03
检验统计量 ADF 为: -3.11
模型的最佳参数(p,d,q)为: (1, 0, 2)
ARIMA 模型的精确度为: 0.86
U->O 路径中 4-18 和 4-19 的快递数量分别为:1 和 1
目前求取的路径是: Y->W
差分0次后时序稳定
ADF检验的 p值为: 0.0
检验统计量 ADF 为: -6.76
模型的最佳参数(p,d,q)为: (1, 0, 1)
ARIMA 模型的精确度为: 0.82
Y->W 路径中 4-18 和 4-19 的快递数量分别为:1 和 1
因此,对于 [‘I->S’, ‘M->G’, ‘V->A’, ‘Y->L’, ‘D->R’, ‘J->K’, ‘Q->O’, ‘U->O’, ‘Y->W’],还要继续分析。这次亦可以用问题二的方法求解。不考虑不能发货的情况,直接拟合。(当然也可以考虑进去,看那种效果好咯)
目前求解 I->S 路径
差分0次后时序稳定
ADF检验的 p值为: 0.0
检验统计量 ADF 为: -8.31
根据图像,p_max 取值为5
根据图像,q_max 取值为4
I->S 路径中 4-18 和 4-19 的快递数量分别为:46.62 和 46.23
模型的预测拟合如下:
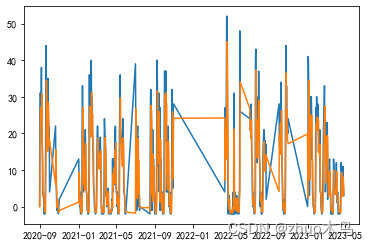
同理…
目前求解 V->A 路径
差分0次后时序稳定
ADF检验的 p值为: 0.04
检验统计量 ADF 为: -2.97
根据图像,p_max 取值为9
根据图像,q_max 取值为2
V->A 路径中 4-18 和 4-19 的快递数量分别为:51.8 和 54.17
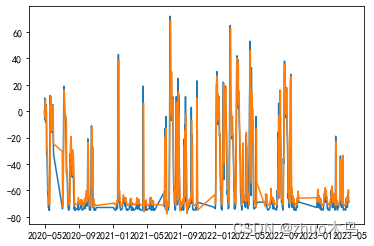
后面不再列举
第四问
以 2023年4月23日 为例,首先求出“发货-收货”站点城市(共81个)对之间使用的路径,以 ‘R->O’ 为例,有:
[[‘R’, ‘K’, ‘V’, ‘F’, ‘O’],
[‘R’, ‘K’, ‘J’, ‘X’, ‘O’],
[‘R’, ‘X’, ‘O’],
[‘R’, ‘X’, ‘I’, ‘M’, ‘O’],
[‘R’, ‘F’, ‘U’, ‘G’, ‘O’],
[‘R’, ‘F’, ‘O’]]
求出这样的 81 各矩阵,然后问题转变为,从这个 81 个矩阵 P i , i ∈ ( 1 , 2 , ⋯ , 81 ) P_i,i\in(1,2,\cdots,81) Pi,i∈(1,2,⋯,81),每个矩阵 P i P_i Pi 的 n i n_i ni 个行向量构成的 n 1 ⋅ n 2 ⋅ , ⋯ , ⋅ n 81 = N n_1 \cdot n_2 \cdot,\cdots,\cdot n_{81}= N n1⋅n2⋅,⋯,⋅n81=N 个组合中,找到其中一个组合,使得成本最小。
最简单的办法无疑是暴力求解,但是这不可取,假设每一个“发货-收货”站点城市使用的路径平均为 5 条,则 5 81 = 413590306276513837435704346034981426782906055450439453125 5^{81}= 413590306276513837435704346034981426782906055450439453125 581=413590306276513837435704346034981426782906055450439453125 不可能求解得完。因此,可以考虑采用遗传算法求解。
遗传算法求解
设置基因型为一个长度为 81 的向量。向量中的每一个元素代表着 P i P_i Pi 选择的路径。以 P R − > O P_{R->O} PR−>O为例,若该元素为 2,则表示路径 [‘R’, ‘K’, ‘J’, ‘X’, ‘O’] 。
基因的进化方式,考虑两种。一种是自进化,一种是交配。考虑产生 320 个基因型,构成 320 个个体组成的群落。将这个群落按照 8 个个体分成 40 个种群。每个种群中,挑选出最佳的 个体和次佳个体,得到 80 个个体。成本最低,则为最佳个体。
随后,保留最佳个体,然后又最佳个体随机改变其中{1,1,2,2,3,}基因,产生 5 个新的个体。再有最佳个体和次佳个体,交换基因片段产生新的 2 个个体,总共 1 + 5 + 2 = 8 个新个体进入下一代。
如是循环 200 遍,从迭代历史中,找出这 200 代,200 个群落中最佳的个体,即可成为最佳的路径设计和最低成本。
其中,自进化的方式能够加快算法的收敛,而交配的方式则提高了算法的随机性,使得不容易进入局部最优值。同时,分组的方式也能够避开局部最优的问题。
以 2023年4月23日 为例,使用遗传算法求解的最低成本的过程,如下所示。可以看出到 100 步开始就已经收敛了。
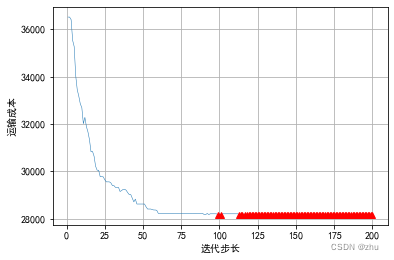
最终可得,最低的成本为 28170。
PS:有一些“发货-收货”站点城市对之间使用的路径,不会小于 5(可能是出题人出错了),所以这里用最小的路径去代替。
第五问
解决两个问题:
- 时序数据季节性规律挖掘
- 误差分布估计
SARIMA 模型拟合季节性规律
SARIMA(Seasonal Autoregressive Integrated Moving Average)模型是一种基于时间序列的预测模型,它是对ARIMA模型的一种扩展,用于处理季节性时间序列数据。SARIMA模型主要通过对时间序列数据进行差分、自回归、移动平均等处理,来描述和预测时间序列的变化趋势和季节性变化。
SARIMA模型的一般形式为SARIMA(p,d,q)(P,D,Q)s,其中:
- p:自回归项数(AR),表示当前时间点的值与前p个时间点的值之间的关系;
- d:差分阶数(I),表示对数据进行d阶差分后得到的时间序列是平稳的;
- q:移动平均项数(MA),表示当前时间点的值与前q个时间点的误差之间的关系;
- P:季节性自回归项数(SAR),表示当前时间点的值与前Ps个时间点的值之间的关系;
- D:季节性差分阶数(SI),表示对数据进行D阶差分后得到的时间序列是平稳的;
- Q:季节性移动平均项数(SMA),表示当前时间点的值与前Qs个时间点的误差之间的关系;
- s:季节周期,表示数据的季节性周期长度,比如一年有12个月,s=12。
SARIMA模型的预测公式如下:
y ^ t + h ∣ t = μ + ∑ i = 1 p φ i ( y t − i + h − μ ) + ∑ i = 1 P φ i ( y t − i s − h − μ ) + ∑ i = 1 q θ i ε t − i + h + ∑ i = 1 Q θ i ε t − i s − h \hat{y}_{t+h|t} = \mu + \sum_{i=1}^{p}\varphi_i(y_{t-i+h}-\mu) + \sum_{i=1}^{P}\varphi_i(y_{t-is-h}-\mu) + \sum_{i=1}^{q}\theta_i\varepsilon_{t-i+h} + \sum_{i=1}^{Q}\theta_i\varepsilon_{t-is-h} y^t+h∣t=μ+i=1∑pφi(yt−i+h−μ)+i=1∑Pφi(yt−is−h−μ)+i=1∑qθiεt−i+h+i=1∑Qθiεt−is−h
其中, y ^ t + h ∣ t \hat{y}_{t+h|t} y^t+h∣t 表示在时间 t t t 时刻预测 h h h 个时间点后的值, μ \mu μ 表示时间序列的均值, φ i \varphi_i φi 表示自回归系数, θ i \theta_i θi 表示移动平均系数, ε t \varepsilon_t εt 表示误差项, y t y_t yt 表示在时间 t t t 时刻的原始值。
SARIMA模型的训练过程中,需要确定模型的参数 p , d , q , P , D , Q p,d,q,P,D,Q p,d,q,P,D,Q 和季节周期 s s s。一般可以通过观察时间序列的自相关图(ACF)和偏自相关图(PACF)来初步确定参数,然后使用最大似然估计(MLE)或贝叶斯信息准则(BIC)等方法来确定最优参数组合。最后,使用确定的模型对时间序列进行预测。
相关文章:
2023年五一数学建模 B 题过程与结果
文章目录 第一问第二问数据时序分析Auto-ARIMA第二问求解解的情况A->Q:D-> AQ-V总快递数 第三问第四问遗传算法求解 第五问SARIMA 模型拟合季节性规律 第一问 见 2023 年 五一杯 B 题过程 代码(第一问) 第二问 第二问考虑是一个时序预测问题&a…...
搞懂 API ,API 中 URI 设计规范分享
API(Application Programming Interface)是现代软件开发中的一项关键技术,它为不同应用程序间提供了数据和功能交互的标准化方式。而 URI(Uniform Resource Identifier)作为 API 中的重要部分,其规范和良好…...
【DarkLabel】使用教程(标注MOT数据集)
DarkLabel 使用教程 功能部分 Open video 第 2 处的内容为数据集类型。例如:VOC、COCO、MOT、YOLO等。 第 3 处的内容为标签名称。 可在 darklabel.yml 中修改 classes_set。例如:classes_set: "mot_classes" 第 4 处的内容为两种跟踪方法…...

Python3 迭代器与生成器
Python3 中的迭代器和生成器是 Python 编程中非常重要的概念,它们可以帮助我们更高效地处理数据和管理内存。下面分别介绍一下迭代器和生成器的概念和用法。 ## 迭代器 迭代器是一个可以遍历一个容器(如列表或元组)中的所有元素的对象&…...
C++基础 类的自动转换和强制类型转换
参考 C Primer Plus (第6版) 类自动转换 接受一个参数的构造函数允许使用赋值语法将对象初始化一个值 Classname object value; 等价于 ClassName object(value); 等价于 ClassName object ClassName(value); 只有接受一个参数的构造函数才能作为转换构造函数(某类型->…...
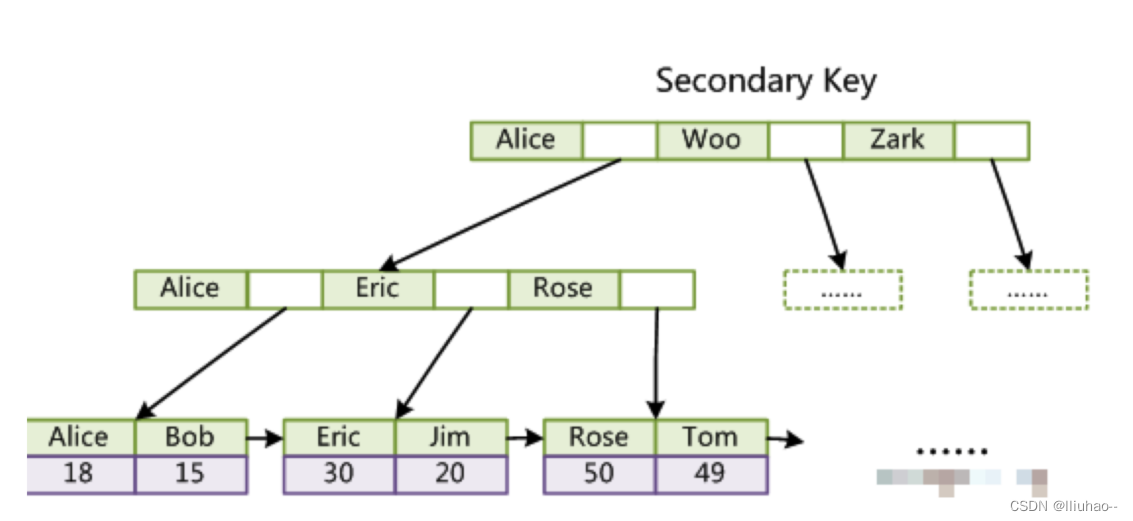
MySQL索引的底层实现原理
索引的底层实现原理 数据库索引是存储在磁盘上的,当数据量大时,就不能把整个索引全部加载到内存了,只能逐一加载每一个磁盘块(对应索引树的节点),索引树越低,越“矮胖”,磁盘IO次数…...

Linux 更新
Linux权限系统 01 只读 1 10 只写 2 100 只执行 4 11 可读写 3 101 可读执行 5 110 可写执行 6 111 可读写执行 7...
)
华为OD机试 - 端口合并(Python)
题目描述 有M个端口组(1<=M<=10), 每个端口组是长度为N的整数数组(1<=N<=100), 如果端口组间存在2个及以上不同端口相同,则认为这2个端口组互相关联,可以合并。 输入描述 第一行输入端口组个数M,再输入M行,每行逗号分割,代表端口组。 备注:端口组内数字…...

分部积分法习题
前置知识:分部积分法 例题 计算积分 I n ∫ [ ( x a ) 2 b 2 ] − k d x ( n ≥ 1 ) I_n\int [(xa)^2b^2]^{-k}dx \quad(n\geq 1) In∫[(xa)2b2]−kdx(n≥1) 解: \qquad 用分部积分法,对任何自然数 k ≥ 1 k\geq 1 k≥1,…...
C++—非递归【循环】遍历二叉树(前序,中序,后序)思路讲解+代码实现
非递归遍历二叉树 前序中序后序 接下来我们在研究如何使用循环实现遍历二叉树时,以下面的二叉树为例: 在下文的讲解中,不对如何构建这颗二叉树做讲解,直接给出代码,如果有不懂的地方欢迎私信我。 文章中的完整源代码链…...
前端002_初始化项目
1、命名和启动项目 将目录名 vue-admin-template-master 重命名为 db-manager-system 将 db-manager-system/package.json 中的 name 值改为 db-manager-system {"name": "db-manager-system","version": "1.0.1","descriptio…...

组合设计模式
组合模式 组合模式定义使用场景1、文件系统的目录结构:2、组织架构图:3、菜单和菜单项:4、使用场景总结: 角色定义Component 抽象构件角色:Leaf 叶子构件:Composite 树枝构件: 需求背景代码实现Component(抽象构件角色…...
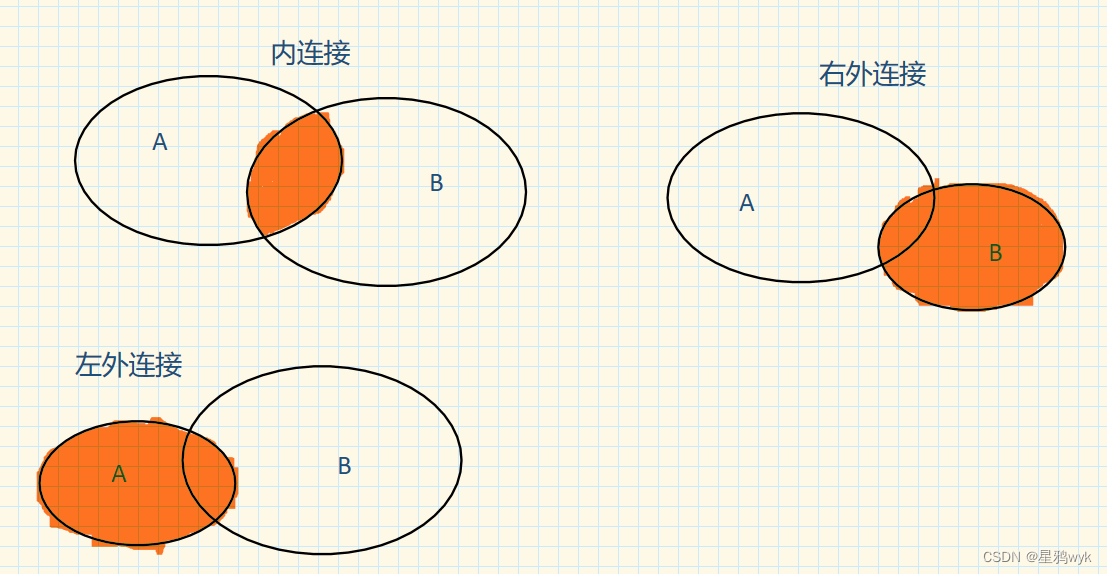
【MySQL】多表查询
上一篇介绍了外键约束,外键约束是用于连接两张数据表的,所以在此基础上就有了多表查询 之前的查询都是单表查询,这里我们会将多个数据表的数据结果返回在一张表上 文章目录 1.多表关系2.多表查询2.1 多表查询分类2.2 内连接2.3 外连接2.4 自连接2.5 联合查询2.6子查询 1.多表关…...

关于在线帮助中心你需要思考以下几个问题
搭建帮助中心是大多数企业都在尝试做的事情,它的重要性对于企业来说不言而喻。现在对于企业来说,搭建帮助中心或许不是什么难事,但是关于帮助中心,有几个问题需要思考清楚,才能让其发挥最大的价值。 一、如何让用户养成…...
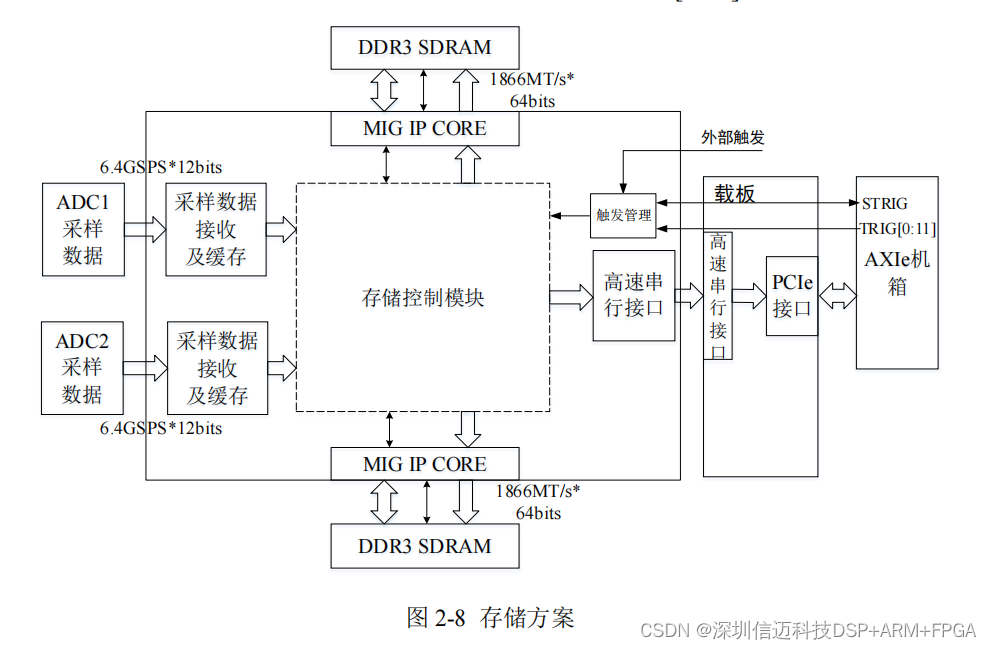
基于FPGA+JESD204B 时钟双通道 6.4GSPS 高速数据采集模块设计(一)总体方案
本章将根据高速数据采集指标要求,分析并确定高速数据采集模块的设计方 案,由此分析数据存储需求及存储速度需求给出高速大容量数据存储方案,完成 双通道高速数据采集模块总体设计方案,并综合采集、存储方案及 AXIe 接口需求 …...
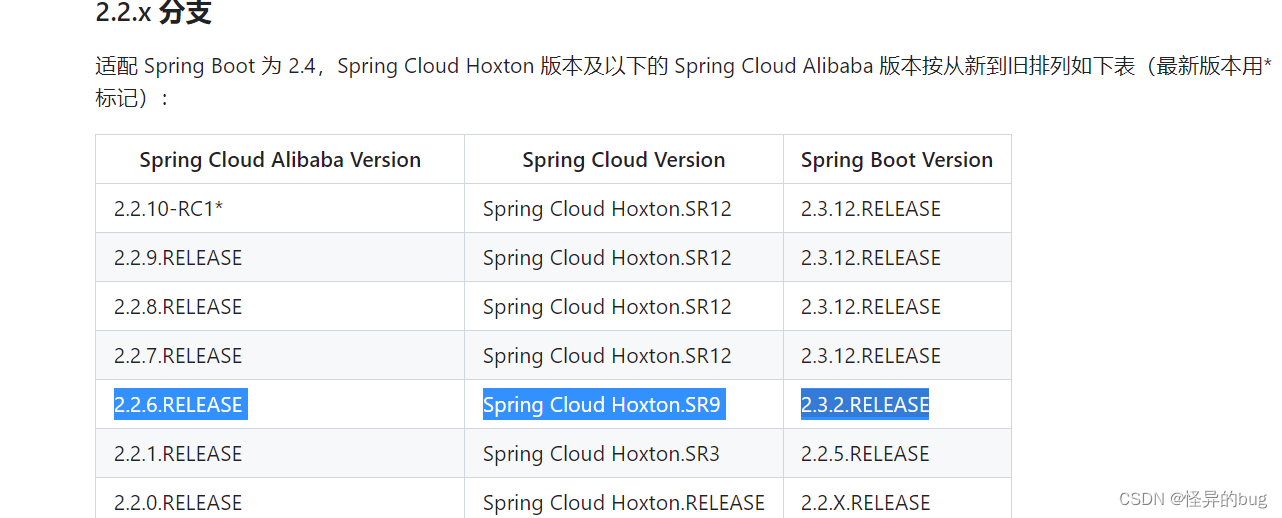
二、Spring Cloud Alibaba环境搭建
一、依赖环境 SpringCloud Alibaba 依赖 Java 环境来运行。还需要为此配置 Maven环境,请确保是在以下版本环境中安装使用。 64 bit JDK 1.8;Maven 3.2.x。 spring-cloud-alibaba相关网址: 地址:https://github.com/alibaba/spring-cloud-…...
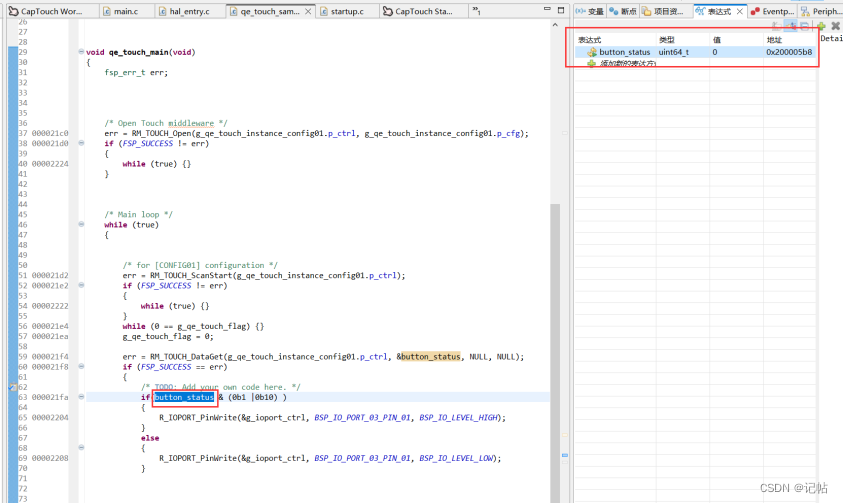
瑞萨e2studio(24)----电容触摸配置(1)
瑞萨e2studio.24--电容触摸配置1 概述硬件准备新建工程工程模板保存工程路径芯片配置工程模板选择时钟配置添加TOUCH驱动配置CapTouch开启调优界面启动 CapTouch 调优通过电容触摸点亮LED 概述 这篇文档将创建一个使用 e2 studio 集成 QE 的电容式触摸应用示例,通…...
数据开发常见问题
目录 环境变量过多或者参数值过长时,为什么提交作业失败? 为什么Shell作业状态和相关的YARN Application状态不一致? 创建作业和执行计划的区别是什么? 如何查看作业运行记录? 如何在OSS上查看日志? 读…...

Ae:橡皮擦工具
橡皮擦工具 Eraser Tool 快捷键:Ctrl B 橡皮擦工具 Eraser Tool在工作原理上同 Ae 中的其它绘画工具(画笔、仿制图章)工具基本一致,都是通过绘制路径,然后基于此路径进行描边(可统称为“绘画描边”&…...

干货 | 正确引用参考文献的6大技巧
Hello,大家好! 这里是壹脑云科研圈,我是喵君姐姐~ 对于学术研究而言,正确引用参考文献非常重要。参考文献不仅展现了自己的学术水平,同时也给研究定位,突显研究在前人研究基础上作出的贡献。 …...

【信息科学与工程学】【制造工程】【通信工程】第一百零一篇 2nm 200Tbps+核心交换机全尺度参数宇宙构建框架05
围绕芯片、单板、交换网卡等层级,重点扩展“信息处理”中的“内存/存储器”子系统相关参数,并覆盖其他关键方面。 衬底、互连、介质,但光刻胶、清洗液、研磨液、封装胶、键合线、TIM材料、探针卡、载带、保护涂层、清洗溶剂、掺杂剂、气体、抗反射涂层、对准标记、硅化物、…...

TCP专栏-3.三次握手
什么是三次握手三次握手是指,在建立TCP连接时,客户端和服务端总共会发送三个数据包。只有三个数据包都发送成功后,TCP连接才会建立成功。否则,丢失任何一个包,都会导致连接建立失败。发送三个数据包的过程,…...

RK3568金融自助终端方案:AI边缘计算与高可靠设计实践
1. 项目概述:当金融自助终端遇上RK3568最近几年,如果你留意过银行网点或者一些商业中心,会发现自助终端的形态正在发生一些微妙的变化。从传统的ATM机,到如今功能繁多的VTM(远程视频柜员机)、智能柜台、自助…...

ChatGPT对话导出工具:一键保存结构化对话记录到Markdown
1. 项目概述:一个帮你“打包”对话记录的工具如果你经常使用ChatGPT的网页版进行深度对话,无论是用它来辅助编程、学习新知识,还是进行创意写作,你可能会遇到一个共同的痛点:那些充满价值的对话记录,被“锁…...

Vue 3 Composition API驱动下的企业级日期时间选择器架构演进与实践
Vue 3 Composition API驱动下的企业级日期时间选择器架构演进与实践 【免费下载链接】vue3-date-time-picker Datepicker component for Vue 3 项目地址: https://gitcode.com/gh_mirrors/vu/vue3-date-time-picker 在现代化Web应用开发中,日期时间选择器作为…...

工业 DC-DC 性能深度对比解析|钡特电源 DF1-05D15LS 与 E0515S-1WR3 封装互通
在工业控制、仪器仪表、低功耗传感设备等场景中,1W 级隔离工业 DC-DC 模块因体积小、功率密度高、适配性强,成为硬件研发工程师常用的直流电源模块核心器件。随着国产化进程加速,国产工业 DC-DC 模块在性能、稳定性、性价比上逐步实现突破&am…...

Python高阶学习路径指南
Python是一门强大且应用广泛的高级编程语言,其学习路径可以从基础语法一直延伸到数据科学、人工智能、Web开发等多个专业领域。 一个系统、严谨且富有挑战性的学习路径(区别于简单入门教程)应遵循从基础到核心,再到专业应用与深度…...

GitHub代码仓库安全防护:基于ClamAV的PR恶意文件自动化扫描实践
1. 项目概述:一个守护代码仓库的“安全哨兵”最近在梳理团队内部的代码安全流程,发现一个挺普遍但容易被忽视的问题:我们花了很多精力在CI/CD流水线上做安全扫描,比如用SonarQube检查代码质量,用Trivy扫描容器镜像漏洞…...
)
仅限首批200名技术负责人开放|ElevenLabs中文定制音色微调手册(含v2.4.1未公开API参数表)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs中文语音生成优化的底层逻辑与适用边界 语音建模的语言适配瓶颈 ElevenLabs 原生模型基于英文语料大规模预训练,其中音素单元(phoneme)与韵律建模均以拉丁…...

ESP32-S3电源管理与CircuitPython开发实战:从硬件设计到低功耗优化
1. ESP32-S3电源管理:不只是供电,更是项目成败的关键玩嵌入式开发,尤其是物联网项目,最头疼的往往不是代码逻辑,而是“电”。一块板子,插着USB线跑得欢,一拔掉电池,没俩小时就歇菜了…...