MySQL原理(十):主从架构
前言
上一篇介绍了 MySQL 的表分区和分库分表,这一篇将介绍主从架构相关的内容。
主从架构
常见的主从架构模式有四种:
- 一主多从架构:适用于读大于写的场景,采用多个从库来分担数据库系统的读压力。
- 多主架构:适用于读写参半的场景,采用多个主库来承载数据库系统整体的读写压力。
- 多主一从架构:适用于写大于读的场景,采用多个主库分担写压力,单个从库承载读压力。
- 级联复制架构:适用于读大于写的场景,采用单个从节点来分担从库对主库造成的 I/O 压力。
接下来的讨论都是针对最常见的一主多从架构。
主从架构中必须有一个主节点,以及一个或多个从节点,所有的数据都会先写入到主,接着其他从节点会复制主节点上的增量数据,从而保证数据的最终一致性,使用主从复制方案,可以进一步提升数据库的可用性和性能:
- 在主节点宕机或故障的情况下,从节点能自动切换成主节点的身份,从而继续对外提供服务。
- 提供数据备份的功能,当主节点的数据发生损坏时,从节点中依旧保存着完整数据。
- 可以基于主从实现读写分离,主节点负责处理写请求,从节点处理读请求,进一步提升性能。
但无论任何技术栈的主从架构,都会存在致命硬伤,同时也会存在些许问题需要解决:
- 硬伤:木桶效应,一个主从集群中所有节点的容量,受限于存储容量最低的哪台服务器。
- 数据一致性问题:由于同步复制数据的过程是基于网络传输完成的,所以存储延迟性。
- 脑裂问题:从节点会通过心跳机制,发送网络包来判断主机是否存活,网络故障情况下会产生多主。
主从复制
MySQL 集群的主从复制过程梳理成 3 个阶段:
- 写入 Binlog:主库更新本地存储数据,并写 binlog 日志,然后提交事务。
- 同步 Binlog:把 binlog 复制到所有从库上,每个从库把 binlog 写到暂存日志中。
- 回放 Binlog:回放 binlog,并更新存储引擎中的数据。

具体详细过程如下:
- MySQL 主库在收到客户端提交事务的请求之后,会先更新数据;
- 数据写入完成后,再去写入 binlog,然后提交事务,返回客户端“操作成功”的响应;
- 主节点上有一条专门监听 binlog 的 log dump 线程;
- 当 log dump 线程监听到日志发生变更时,会通知从节点来拉取数据;
- 从节点有专门的 I/O 线程(io_thread)用于等待主节点的通知,当收到通知时会去请求一定范围的数据;
- 当从节点在主节点上请求到数据后,会将得到的数据写入到 relay-log 中继日志,然后返回给主库“复制成功”的响应;
- 从节点上有专门负责监听 relay-log 变更的线程(sql_thread),当日志出现变更时会开始工作;
- 中继日志出现变更后,会从中读取日志记录,然后回放 binlog 更新数据,实现主从数据一致性。
复制模式
同步复制
MySQL 主库提交事务的线程要等待所有从库的复制成功响应,才返回客户端结果。这种方式在实际项目中,基本上没法用,原因有两个:一是性能很差,因为要复制到所有节点才返回响应;二是可用性也很差,主库和所有从库任何一个数据库出问题,都会影响业务。
异步复制
是 MySQL 默认使用的复制模式,MySQL 主库提交事务的线程并不会等待 binlog 同步到各从库,就返回客户端结果。这种模式一旦主库宕机,数据就会发生丢失。
半同步复制
MySQL 5.7 版本之后增加的一种复制方式,介于两者之间,事务线程不用等待所有的从库复制成功响应,只要一部分复制成功响应回来就行,比如一主二从的集群,只要数据成功复制到任意一个从库上,主库的事务线程就可以返回给客户端。这种半同步复制的方式,兼顾了异步复制和同步复制的优点,即使出现主库宕机,至少还有一个从库有最新的数据,不存在数据丢失的风险。
增强式半同步复制
也被称为无损复制,也是 MySQL5.7 引入的。和之前传统的半同步复制区别在于:从 after-commit 变成了 after-sync ,如果将复制模式配置成半同步时,默认就会选用无损复制模式。
- after-commit:主库在未收到从库的 ACK 之前,虽然不会给客户端返回写入成功,但本质上会提交事务,也就是主库中的其他事务是可以看见对应数据的,当此时出现宕机时,就会导致旧主上能查询出的数据,在新主上无法查询出来了。
- after-sync:当主库未收到从库的 ACK 之前,也不会在主库上提交事务,也就是保证了主从节点的数据强一致性,解决了 after-commit 中存在的问题。但是相较于 after-commit,可能导致事务迟迟不提交,从而导致锁资源不释放和阻塞等待等性能问题。
延迟复制
当从库上的 I/O 线程,将主库的 binlog 请求回来后,从节点的 SQL 线程并不会立刻解析日志执行,而是等待一段时间后再解析日志执行,这个等待的时间可以配置。
延迟复制的好处是可以防止误删操作。缺点是会有很长一段时间的数据不一致,可能导致数据的丢失。一般用于仅作为备库的节点使用,不能进行读写分离。
并行复制
GTID复制
GTID,Global Transaction Identifier,用于唯一地标识一个事务。
GTID 由节点 UUID + 事务 ID 两部分组成,MySQL 在第一次启动时都会利用 UUID 随机生成一个 server_id,还会对每一个写事务都分配一个顺序递增的值作为事务 ID,GTID 的格式为 server_uuid:trx_id。
基于 GTID 的复制过程:
-
master 在更新数据时,会为每一个写事务分配一个全局的 GTID,并记录到 binlog 中。
-
slave 节点的 I/O 线程拉取数据时,会将读到的记录写到 relay-log 中,并设置 gtid_next 值。
-
slave 节点的 SQL 线程执行前,会读取 gtid_next 值得知接下来该解析哪条日志并执行。
-
slave 节点的 SQL 线程在执行时,会先比对自身的 binlog 日志中是否有对应的 GTID:
-
有:意味着该 GTID 对应的事务已经执行过了,slave 会自动忽略掉这条记录。
-
没有:SQL 解析该 GTID 对应的 relay-log 记录并执行,再将 GTID 记录到 binlog。
-
基于 GTID 的自动同步:发生主从切换时可以执行 change master to master_auto_position=1,会自动去新主库上寻找数据的同步点。
GTID 是基于事务来实现的,也就代表不支持事务的存储引擎无法使用这种机制。
组复制
GTID 复制是组复制得基础。组复制是指将一组并行执行的事务,全部放入到一个 GTID 中记录,后续从节点同步数据时,会一次性读取这一组事务解析并执行,即组提交。
组复制的 GTID 通过逗号分隔。
并行复制
并行复制是在组复制的基础上实现的。因为能够在同一时间内提交的事务,绝对是不存在锁冲突的,所以可以开启多条线程同时执行一个组中不同的事务。
并行复制能够在很大程度上提升从库复制数据的速度,也就是能够让从库的数据实时性提升。
在 MySQL5.7 中官方为这种机制命名为 enhanced multi-threaded slave,简称 MTS 机制,同时为了兼容 5.6 版本中的并行复制,又多加入了一个 slave-parallel-type 参数:
- DATABASE:默认的并行复制模式,表示基于库级别来完成并行复制。
- LOGICAL_CLOCK:表示基于组提交的方式来完成并行复制。
虽然 5.7 中的并行复制,在一定程度上解决了原有的从库延迟问题,但如果一个新的从节点加入集群时,因为要从头开始同步数据,这种并行复制的模式依旧存在效率问题,而到了 MySQL8.0 对于并行复制技术提出了真正的解决之道,也就是基于 writeset 的 MTS 技术。即多个事务之间,只要变更的数据记录没有重叠,也就是操作的数据没有冲突,无需在一个事务组内,也可以支持并发执行。
两阶段提交
2PC,two-phase commit protocol。
事务提交后,redo log 和 binlog 都要持久化到磁盘,但是这两个是独立的逻辑,可能出现半成功的状态,这样就造成两份日志之间的逻辑不一致。
- 如果在将 redo log 刷入到磁盘之后, MySQL 突然宕机了,而 binlog 还没有来得及写入。MySQL 重启后,通过 redo log 能将 Buffer Pool 中的相应数据恢复到新值,但是 binlog 里面没有记录这条更新语句,在主从架构中,binlog 会被复制到从库,由于 binlog 丢失了这条更新语句,从库的数据是旧值;
- 如果在将 binlog 刷入到磁盘之后, MySQL 突然宕机了,而 redo log 还没有来得及写入。由于 redo log 还没写,崩溃恢复以后这个事务无效,所以数据还是旧值;而 binlog 里面记录了这条更新语句,数据是新值;
在持久化 redo log 和 binlog 这两份日志的时候,如果出现半成功的状态,就会造成主从环境的数据不一致性。因为 redo log 影响主库的数据,binlog 影响从库的数据,所以 redo log 和 binlog 必须保持一致才能保证主从数据一致。
MySQL 为了避免出现两份日志之间的逻辑不一致的问题,使用了「两阶段提交」来解决,两阶段提交其实是分布式事务一致性协议,它可以保证多个逻辑操作要不全部成功,要不全部失败,不会出现半成功的状态。
当客户端执行 commit 语句或者在自动提交的情况下,MySQL 内部开启一个 XA 事务,分两阶段来完成 XA 事务的提交,分别是准备阶段和提交阶段。
- prepare 阶段:将 XID(内部 XA 事务的 ID) 写入到 redo log,同时将 redo log 对应的事务状态设置为 prepare,然后将 redo log 持久化到磁盘(innodb_flush_log_at_trx_commit = 1 的作用);
- commit 阶段:把 XID 写入到 binlog,然后将 binlog 持久化到磁盘(sync_binlog = 1 的作用),接着调用引擎的提交事务接口,将 redo log 状态设置为 commit,此时该状态并不需要持久化到磁盘,只需要 write 到文件系统的 page cache 中就够了,因为只要 binlog 写磁盘成功,就算 redo log 的状态还是 prepare 也没有关系,一样会被认为事务已经执行成功;

不管是时刻 A(redo log 已经写入磁盘, binlog 还没写入磁盘),还是时刻 B (redo log 和 binlog 都已经写入磁盘,还没写入 commit 标识)崩溃,此时的 redo log 都处于 prepare 状态。
在 MySQL 重启后会按顺序扫描 redo log 文件,碰到处于 prepare 状态的 redo log,就拿着 redo log 中的 XID 去 binlog 查看是否存在此 XID:
- 如果 binlog 中没有当前内部 XA 事务的 XID,说明 redolog 完成刷盘,但是 binlog 还没有刷盘,则回滚事务。对应时刻 A 崩溃恢复的情况。
- 如果 binlog 中有当前内部 XA 事务的 XID,说明 redolog 和 binlog 都已经完成了刷盘,则提交事务。对应时刻 B 崩溃恢复的情况。
可以看到,对于处于 prepare 阶段的 redo log,即可以提交事务,也可以回滚事务,这取决于是否能在 binlog 中查找到与 redo log 相同的 XID,如果有就提交事务,如果没有就回滚事务。这样就可以保证 redo log 和 binlog 这两份日志的一致性了。
两阶段提交是以 binlog 写成功为事务提交成功的标识。
事务没提交的时候,redo log 也是可能被持久化到磁盘。但是 binlog 必须在事务提交之后,才可以持久化到磁盘。
组提交
两阶段提交虽然保证了两个日志文件的数据一致性,但是性能很差,主要有两个方面的影响:
- 磁盘 I/O 次数高:对于“双1”配置,每个事务提交都会进行两次 fsync(刷盘),一次是 redo log 刷盘,另一次是 binlog 刷盘。
- 锁竞争激烈:两阶段提交虽然能够保证「单事务」两个日志的内容一致,但在「多事务」的情况下,却不能保证两者的提交顺序一致,因此,在两阶段提交的流程基础上,还需要加一个锁来保证提交的原子性,从而保证多事务的情况下,两个日志的提交顺序一致。
MySQL 引入了 binlog 组提交(group commit)机制,当有多个事务提交的时候,会将多个 binlog 刷盘操作合并成一个,从而减少磁盘 I/O 的次数。
MySQL 5.7 开始有 redo log 组提交。
引入了组提交机制后,prepare 阶段不变,只针对 commit 阶段,将 commit 阶段拆分为三个过程:
- flush 阶段:多个事务按进入的顺序将 binlog 从 cache 写入文件(不刷盘);
- sync 阶段:对 binlog 文件做 fsync 操作(多个事务的 binlog 合并一次刷盘);
- commit 阶段:各个事务按顺序做 InnoDB commit 操作;
上面的每个阶段都有一个队列,每个阶段有锁进行保护,因此保证了事务写入的顺序,第一个进入队列的事务会成为 leader,领导所在队列的所有事务,全权负责整队的操作,完成后通知队内其他事务操作结束。
同一时刻只允许一组事务提交。
最后
本文介绍了 MySQL 的主从架构。
至此我的 MySQL 学习笔记就全部更新完毕了。学习和使用 MySQL 陆陆续续也有两三年了,从最开始只关注如何使用,到现在为了应付面试而更多的关注原理和实现,但是很多地方都只是停留在表面,并没有自己深入源码去分析和做实验来验证,只能说希望以后有机会再次学习吧。
相关文章:
MySQL原理(十):主从架构
前言 上一篇介绍了 MySQL 的表分区和分库分表,这一篇将介绍主从架构相关的内容。 主从架构 常见的主从架构模式有四种: 一主多从架构:适用于读大于写的场景,采用多个从库来分担数据库系统的读压力。多主架构:适用于…...

一文了解Moonbeam智能合约
智能合约:区块链交易的基石 20世纪90年代,Nick Szabo首次提出智能合约的概念,这是一个建立在自动化、加密安全世界之上的数字化市场。在这种数字化市场中,交易和业务可以在无需信任的情况下进行,无需中间人。 以太坊…...
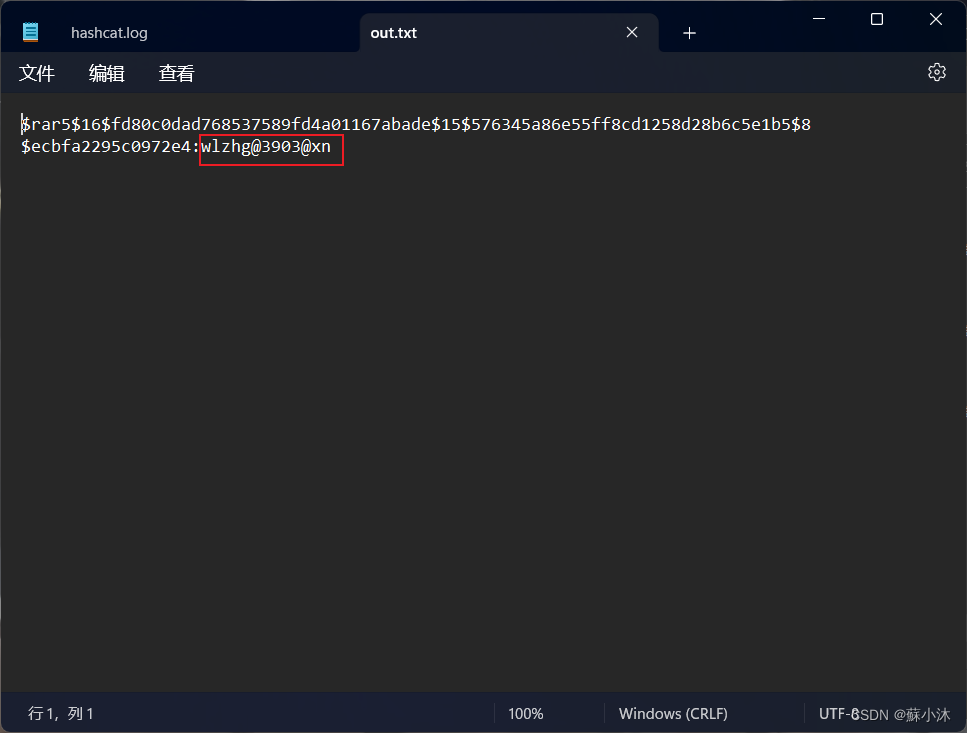
【加解密篇】利用HashCat破解RAR压缩包加密文件详细教程
【加解密篇】利用HashCat解密RAR压缩包加密文件 在取证知识里挖呀挖呀挖—【蘇小沐】 文章目录 【加解密篇】利用HashCat解密RAR压缩包加密文件1.实验环境2.RAR加密压缩包 (一)john软件1.使用CMD命令: run\rar2john.exe (二&…...
React面试题汇总1
1.React的严格模式如何使用,有什么用处? React中StrictMode严格模式_react.strictmode_前端精髓的博客-CSDN博客当我们使用 npx create-react-app my-app 创建一个项目的时候。项目中有一段如下所示的代码:ReactDOM.render( <React.Stric…...

Golang每日一练(leetDay0066) 有效电话号码、转置文件
目录 193. 有效电话号码 Valid Phone Numbers 🌟 194. 转置文件 Transpose File 🌟🌟 🌟 每日一练刷题专栏 🌟 Golang每日一练 专栏 Python每日一练 专栏 C/C每日一练 专栏 Java每日一练 专栏 193. 有效电话号…...

前端 之 FormData对象浅谈
一、简介 通常情况下,前端在使用post请求提交数据的时候,请求都是采用application/json 或 application/x-www-form-urlencoded编码类型,分别是借助JSON字符串来传递参数或者keyvalue格式字符串(多参数通过&进行连接&…...
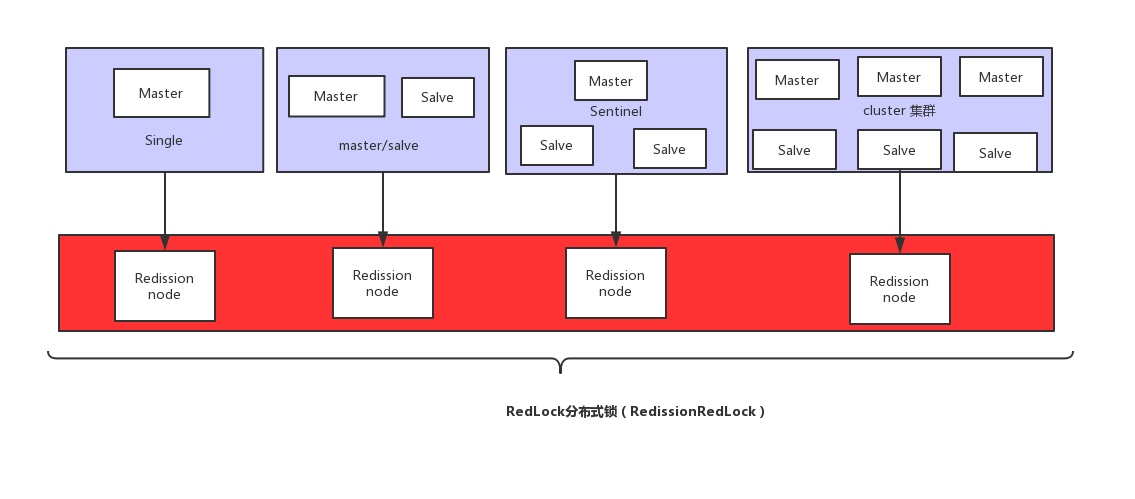
【分布式锁】Redisson分布式锁的使用(推荐使用)
文章目录 前言一、常见分布式锁方案对比二、分布式锁需满足四个条件三、什么是Redisson?官网和官方文档Redisson使用 四、Redisson 分布式重入锁用法Redisson 支持单点模式、主从模式、哨兵模式、集群模式自己先思考下,如果要手写一个分布式锁组件,怎么做ÿ…...
)
创建XML的三种方式(二)
文章目录 1 使用XmlDocument创建XML文档2 使用XmlTextWriter写XML文档3 使用LINQ to XML 的XDocument类4 小结 本文介绍了在winform中使用C#开发语言来创建XML文档的三种方式,并介绍了各自的优缺点。 方法1是使用 XmlDocument创建XML文档,方法2是使用 …...
十分钟教你搭建类似ChatGPT的安卓应用程序
大家好,我是易安! Chat GPT 是当今著名的人工智能工具,就像聊天机器人一样。Chat GPT会回答发送给它的所有查询。今天,我将通过集成 OpenAI API (ChatGPT)构建一个简单的类似 ChatGPT 的 android 应用程序,我们可以在其…...
(二分查找))
问题 E: 起止位置(C++)(二分查找)
目录 1.题目描述 2.AC 1.题目描述 问题 E: 起止位置 时间限制: 1.000 Sec 内存限制: 128 MB提交 状态 题目描述 有n位同学按照年龄从小到大排好队。 王老师想要查询,年龄为x的同学,在队伍中首次出现的位置和最后一次出现的位置;如果队…...

【sop】基于灵敏度分析的有源配电网智能软开关优化配置[升级1](Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
)
LeetCode周赛复盘(第345场周赛)
文章目录 1、找出转圈游戏输家1.1 题目链接1.2 题目描述1.3 解题代码1.4 解题思路 2、相邻值的按位异或2.1 题目链接2.2 题目描述2.3 解题代码2.4 解题思路 3、 矩阵中移动的最大次数3.1 题目链接3.2 题目描述3.3 解题代码3.4 解题思路 4、 统计完全连通分量的数量4.1 题目链接…...

Call for Papers丨第三届GLB@KDD‘23 Workshop
鉴于介绍新数据集和Benchmark研究往往需要不同于常规论文的评审标准,计算机视觉和自然语言处理领域,以及最近的NeurIPS会议,都有专门致力于建立新Benchmark数据集和任务的Conference Track。然而在图机器学习领域,我们还没有类似的…...

【多线程】单例模式
目录 饿汉模式 懒汉模式-单线程版 懒汉模式-多线程版 懒汉模式-多线程版(改进) 单例是一种设计模式。 啥是设计模式 ? 设计模式好比象棋中的 " 棋谱 ". 红方当头炮 , 黑方马来跳 . 针对红方的一些走法 , 黑方应招的时候有一些固定的套路. 按照套路来走局势…...
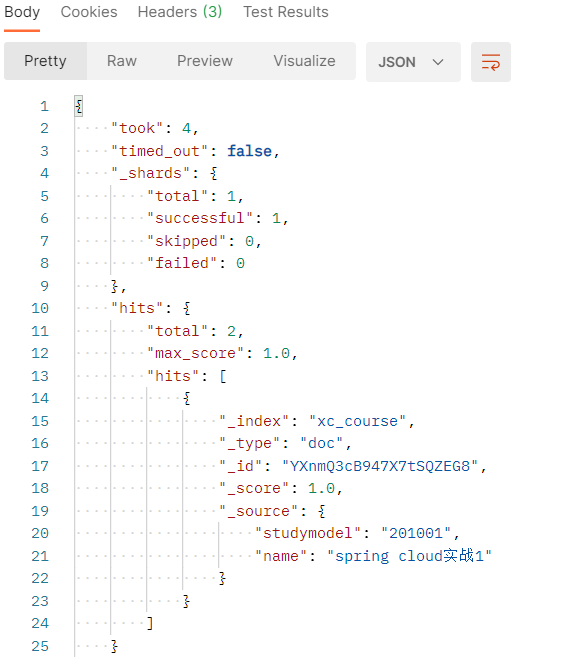
7搜索管理
7搜索管理 7.1 准备环境 7.1.1 创建映射 创建xc_course索引库。 创建如下映射 post:http://localhost:9200/xc_course/doc/_mapping 参考 “资料”–》搜索测试-初始化数据.txt { "properties": { "description": { "type": &…...

在Pytorch中使用Tensorboard
Tensorboard是一款深度学习可视化软件,目前主要使用了它的可视化模型, 可视化模型权重和可视化损失函数功能。 x.1 tensorboard初始化 tensorboard初始化需要导入SummaryWriter包并指定存储位置和开放端口号。 from torch.utils.tensorboard import SummaryWrite…...
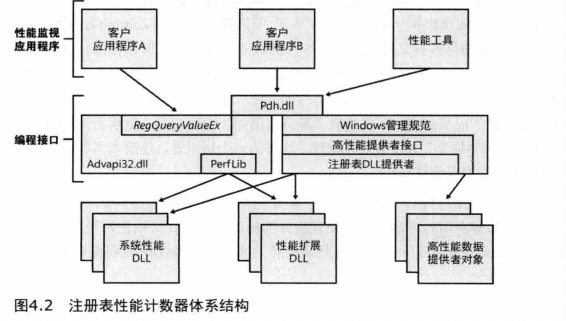
[笔记]深入解析Windows操作系统《四》管理机制
文章目录 前言4.1注册表查看和修改注册表注册表用法注册表数据类型注册表逻辑结构HKEY_CURRENT_USERHKEY_USERS 实验:观察轮廓加载和卸载HKEY_CLASSES_ROOTHKEY_LOCAL_MACHINE 实验:离线方式或远程编辑BCDHKEY_CURRENT_CONFIGHKEY_PERFORMANCE_DATA 前言 本章讲述了…...
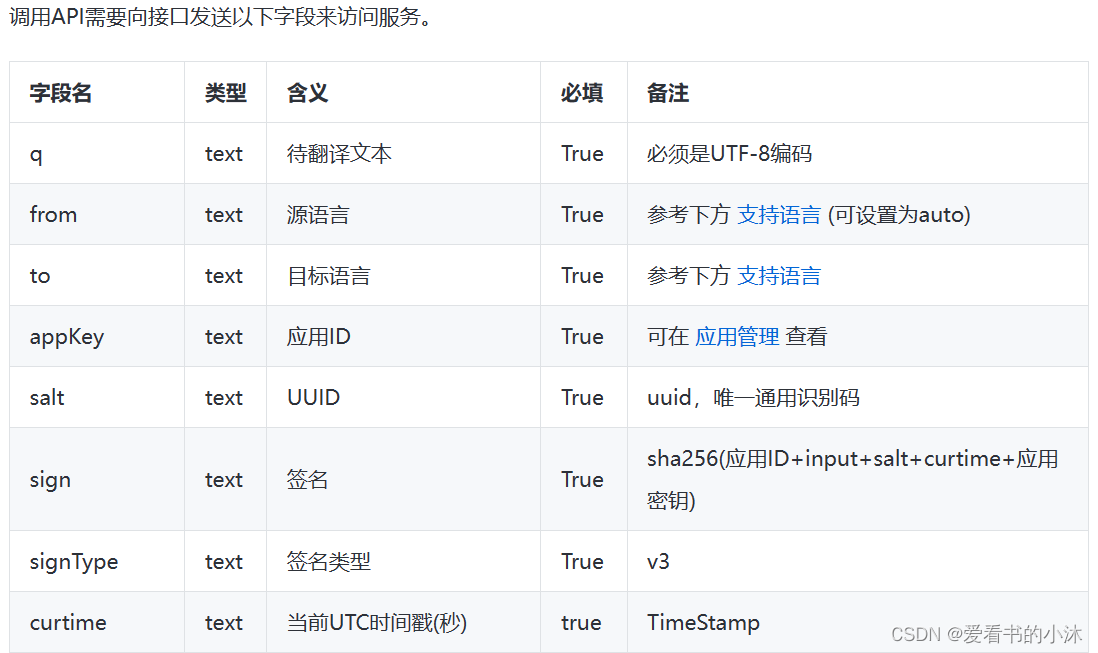
【小沐学Python】Python实现在线英语翻译功能
文章目录 1、简介2、在线翻译接口2.1 Google Translate API2.2 Microsoft Translator API2.2.1 开发简介2.2.2 开发费用2.2.3 开发API 2.3 百度翻译开放平台 API2.3.1 开发简介2.3.2 开发费用2.3.3 开发API 2.4 Tencent AI 开放平台的翻译 API2.4.1 开发简介2.4.2 开发API 2.5 …...

k8s中pod使用详解
一、前言 在之前k8s组件一篇中,我们谈到了pod这个组件,了解到pod是k8s中资源管理的最小单位,可以说Pod是整个k8s对外提供服务的最基础的个体,有必要对Pod做深入的学习和探究。 二、再看k8s架构图 为了加深对k8s中pod的理解,再来回顾下k8s的完整架构 三、pod特点 结合上面这…...
案例说明:vue中Element UI下拉列表el-option中的key、value、label含义各是什么
可以简单理解为:label 是给用户展示的东西,value是前端往后端传递的真实值 <template><div><el-page-header back"goBack" content"注册"></el-page-header><el-divider></el-divider><el-…...

为什么92%的Sora 2初学者卡在第4步?——帧一致性崩塌诊断工具包+时间轴锚点校准法
更多请点击: https://kaifayun.com 第一章:Sora 2视频生成的核心原理与环境准备 Sora 2并非OpenAI官方发布的模型,而是社区基于Sora技术理念构建的开源复现与增强框架,其核心依托于时空联合建模的扩散变换器(Spacetim…...

别再手动改路径了!用LabVIEW + MATLAB Script做自动化测试,这份环境配置指南让你效率翻倍
LabVIEW与MATLAB深度整合:构建自动化测试系统的工程实践指南在工业自动化与测试测量领域,LabVIEW和MATLAB的组合堪称黄金搭档。LabVIEW擅长硬件接口和实时控制,而MATLAB在算法开发和数据分析方面具有无可比拟的优势。本文将深入探讨如何将两者…...

2026智慧校园规划必读:如何在预算吃紧下选到高性价比方案
✅作者简介:合肥自友科技 📌核心产品:智慧校园平台(包括教工管理、学工管理、教务管理、考务管理、后勤管理、德育管理、资产管理、公寓管理、实习管理、就业管理、离校管理、科研平台、档案管理、学生平台等26个子平台) 。公司所有人员均有多…...

FeHelper前端助手:30+开发工具集,让你的浏览器变身效率神器
FeHelper前端助手:30开发工具集,让你的浏览器变身效率神器 【免费下载链接】FeHelper 😍FeHelper--Web前端助手(Awesome!Chrome & Firefox & MS-Edge Extension, All in one Toolbox!) 项目地址:…...

Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件
Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件在游戏开发中,UI交互的流畅性和多样性直接影响玩家的游戏体验。想象一下,当你在开发一个RPG游戏的背包系统时,需要实现道具的单击查看详情、双击快速使用、…...

AI算法工程师如何进行模型部署?这2个工具+3个技巧,快速上线
对于软件测试从业者来说,模型部署并不是一个陌生的概念——随着AI功能逐渐渗透到各类应用软件中,测试工程师不仅需要验证模型输出的准确性,更需要理解部署流程对模型稳定性、响应速度和结果一致性的影响。很多测试同学会有这样的困惑…...

基于Atmega 1284P的16位复古计算器:硬件设计与软件实现全解析
1. 项目概述与核心思路最近在整理工作室时,翻出了一堆老旧的7段数码管和矩阵键盘,看着这些充满复古气息的元件,一个想法冒了出来:为什么不自己动手做一台复古风格的计算器呢?不是那种用液晶屏显示的现代计算器…...

从《王者荣耀》野怪巡逻到RTS单位集结:拆解Unity Navigation系统在实战中的4种高级用法
从《王者荣耀》野怪巡逻到RTS单位集结:拆解Unity Navigation系统在实战中的4种高级用法在MOBA游戏中,野怪沿着固定路线巡逻时突然转向追击玩家;RTS战场上,上百个单位向同一目标点移动却能保持整齐队形;潜行游戏中&…...

3分钟快速解决Windows热键冲突检测难题:Hotkey Detective终极指南
3分钟快速解决Windows热键冲突检测难题:Hotkey Detective终极指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective …...

终极艾尔登法环存档迁移指南:3分钟学会角色无损转移
终极艾尔登法环存档迁移指南:3分钟学会角色无损转移 【免费下载链接】EldenRingSaveCopier 项目地址: https://gitcode.com/gh_mirrors/el/EldenRingSaveCopier 还在为《艾尔登法环》存档迁移而烦恼吗?当游戏版本更新后,你辛辛苦苦培…...