python基于LBP+SVM开发构建基于fer2013数据集的人脸表情识别模型是种什么体验,让结果告诉你...
本身LBP+SVM是比较经典的技术路线用来做图像识别、目标检测,没有什么特殊的地方
fer2013数据集在我之前的博文中也有详细的实践过,如下:
《fer2013人脸表情数据实践》 系统地基于CNN开发实现
《Python实现将人脸表情数据集fer2013转化为图像形式存储本地》 一键复制代码即可实现原始csv文件转储本地图像
LBP+SVM和fer2013组合起来去使用就出现了有意思的东西了,本身LBP提取出来的特征维度就很大一般都是将近2w维,然后fer2013数据集又有接近4w的数据量,这就导致SVM模型最终的训练极度膨胀缓慢。
我是昨天回去的时候放在云服务器上面跑的,但是隔了4个小时还没有结束就休息了,一早醒来看到结果出来了,就是觉得简单的事情做得挺波折,这个还是服务器的算力计算得到的,如果是普通的PC机估计就更慢了吧。
简单看下:

整体项目比较精简,train.json表示训练数据提取出来的LBP向量存储得到的文件,test.json表示测试数据提取出来的LBP向量存储得到的文件。mlModel.py是源代码,实现了数据加载,SVM模型训练和测试评估整套流程。results是存储下来的SVM模型和评估指标结果文件。
当我早上看到这个results体积的时候着实惊呆了,从来还没有看到过SVM模型这么这么的大,进入results目录看下,详情如下:
![]()
一个基于LBP特征训练出来的SVM模型居然达到了恐怖的3+GB。
但是从评估结果上来看结果却是比较惨淡的,如下:
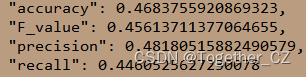
这里也统计了单个类别下的详情:
"angry": {"accuracy": 0.41541755888650969,"F_value": 0.08385562999783879,"precision": 0.14285714285714286,"recall": 0.05934536555521567},"disgust": {"accuracy": 0.3392857142857143,"F_value": 0.08444444444444444,"precision": 0.16666666666666667,"recall": 0.05654761904761905},"fear": {"accuracy": 0.37298387096774196,"F_value": 0.0776169498636459,"precision": 0.14285714285714286,"recall": 0.053283410138248849},"happy": {"accuracy": 0.646927374301676,"F_value": 0.11223105252955999,"precision": 0.14285714285714286,"recall": 0.09241819632881086},"neutral": {"accuracy": 0.41186161449752886,"F_value": 0.08334722453742291,"precision": 0.14285714285714286,"recall": 0.058837373499646978},"sad": {"accuracy": 0.27565084226646249,"F_value": 0.06173898130680843,"precision": 0.14285714285714286,"recall": 0.03937869175235178},"surprise": {"accuracy": 0.6602409638554216,"F_value": 0.11362222682977399,"precision": 0.14285714285714286,"recall": 0.09432013769363167}整体来看:效果比较一般,这个还是比较适合用深度学习去做的,感觉这样的数据体量和状态下SVM很难有较好的效果!
相关文章:
python基于LBP+SVM开发构建基于fer2013数据集的人脸表情识别模型是种什么体验,让结果告诉你...
本身LBPSVM是比较经典的技术路线用来做图像识别、目标检测,没有什么特殊的地方 fer2013数据集在我之前的博文中也有详细的实践过,如下: 《fer2013人脸表情数据实践》 系统地基于CNN开发实现 《Python实现将人脸表情数据集fer2013转化为图像…...
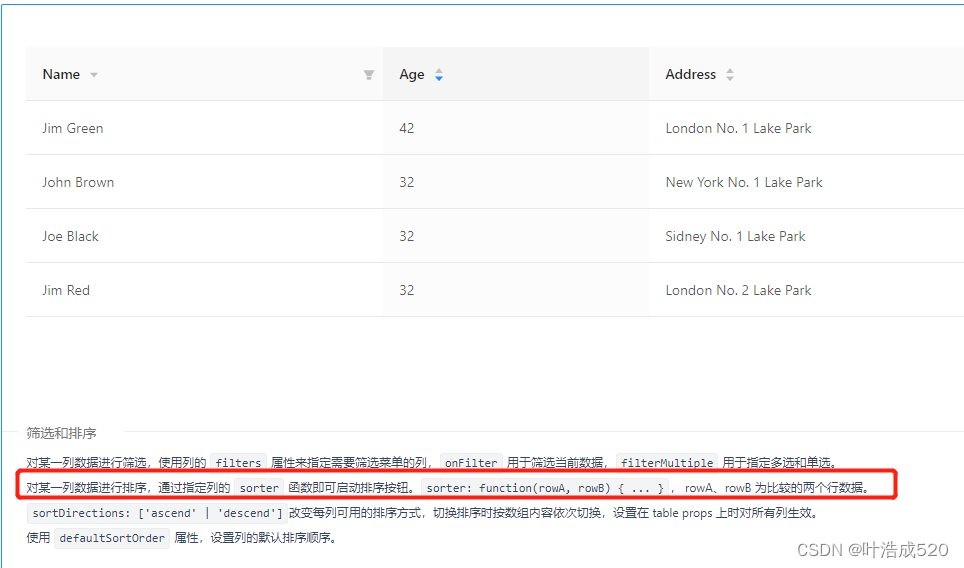
antd——实现不分页的表格前端排序功能——基础积累
最近在写后台管理系统时,遇到一个需求,就是给表格中的某些字段添加排序功能。注意该表格是不分页的,因此排序可以只通过前端处理。 如下图所示: 在antd官网上是有关于表格排序的功能的。 对某一列数据进行排序,通过…...
案例11:Java超市管理系统设计与实现开题报告
博主介绍:✌全网粉丝30W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专…...

@JsonAlias 和 @JsonProperty的使用
JsonAlias 和 JsonProperty 前言一、JsonAlias二、JsonProperty总结 前言 使用场景:主要运用于参数映射。 如:将admin_id 的值赋予adminId 常用于:接收第三方参数,并对参数进行驼峰化或别名。 一、JsonAlias 是在反序列化的时候…...
Grafana系列-统一展示-8-ElasticSearch日志快速搜索仪表板
系列文章 Grafana 系列文章 概述 我们是基于这篇文章: Grafana 系列文章(十二):如何使用 Loki 创建一个用于搜索日志的 Grafana 仪表板, 创建一个类似的, 但是基于 ElasticSearch 的日志快速搜索仪表板. 最终完整效果如下: 📝…...

【K8s】openEuler23操作系统安装Docker和Kubernetes
openEuler23操作系统安装 服务器搭建环境随手记 文章目录 openEuler23操作系统安装前言:一、前期准备(所有节点)1.1所有节点,关闭防火墙规则,关闭selinux,关闭swap交换,打通所有服务器网络&am…...

异常数据检测 | Python实现ADTK时间序列异常数据检测
文章目录 文章概述模型描述程序设计参考资料文章概述 异常数据检测 | Python实现ADTK时间序列异常数据检测 智能运维AIOps的数据基本上都是时间序列形式的,而异常检测告警是AIOps中重要组成部分。 模型描述 笔者最近在处理时间序列数据时有使用到adtk这个python库,在这里和大…...
软件测试之jmeter性能测试让你打开一个全新的世界
一、Jmeter简介 1 概述 jmeter是一个软件,使负载测试或业绩为导向的业务(功能)测试不同的协议或技术。 它是 Apache 软件基金会的Stefano Mazzocchi JMeter 最初开发的。 它主要对 Apache JServ(现在称为如 Apache Tomcat…...

Redis数据结构——动态字符串、Dict、ZipList
一、Redis数据结构-动态字符串 我们都知道Redis中保存的Key是字符串,value往往是字符串或者字符串的集合。可见字符串是Redis中最常用的一种数据结构。 不过Redis没有直接使用C语言中的字符串,因为C语言字符串存在很多问题: 获取字符串长度…...

ipad可以用别的品牌的手写笔吗?便宜的ipad电容笔
而对于那些把ipad当做学习工具的人而言,苹果Pencil就成了必备品。但因为苹果Pencil太贵了,学生们买不起。因此,最好的选择还是平替电容笔。作为一个ipad的忠实用户,同时也是一个数字热爱着,这两年来,我一直…...

【数据库】关于SQL SERVER的排序规则的问题分析
在安装报表系统,运行sql语句时候提示“无法解决 equal to 操作的排序规则冲突。”,费了半天时间才搞定,原来是因为sql语句中没有加全collate Chinese_PRC_CI_AI_WS ! 用排序规则特点计算汉字笔划和取得拼音首字母 SQL SERVER的…...

算法修炼之练气篇——练气十三层
博主:命运之光 专栏:算法修炼之练气篇 目录 题目 1023: [编程入门]选择排序 题目描述 输入格式 输出格式 样例输入 样例输出 题目 1065: 二级C语言-最小绝对值 题目描述 输入格式 输出格式 样例输入 样例输出 题目 1021: [编程入门]迭代法求…...
ChatGPT:AI不取代程序员,只取代的不掌握AI的程序员
作者:成都兰亭集势信息技术有限公司技术总监张雄 可能大家会有如下的问题,我就使用chatGPT这个AI工具的API来问一下。 问:chatGPT会替换掉程序员吗?如果能,预计好久? 答:作为一名 AI 语言模型&a…...

数字革命下的产品:百数十年变迁的启示与思考。
随着数字化时代的到来,软件开发成为各行各业不可或缺的一部分。然而,传统的软件开发方法需要长时间的开发周期,高昂的成本和大量的人力资源。因此,低代码开发平台应运而生。低代码开发平台通过简化开发人员的工作和加速软件开发流…...

部门新来一00后,给我卷崩溃了...
2022年已经结束结束了,最近内卷严重,各种跳槽裁员,相信很多小伙伴也在准备今年的金三银四的面试计划。 在此展示一套学习笔记 / 面试手册,年后跳槽的朋友可以好好刷一刷,还是挺有必要的,它几乎涵盖了所有的…...

使用Spring Boot和Docker构建可伸缩的微服务架构,应对增长的业务需求
使用Spring Boot和Docker构建可伸缩的微服务架构,应对增长的业务需求 一、简介1. 微服务架构的定义2. Spring Boot和Docker的概述 二、Spring Boot1. Spring Boot的介绍2. Spring Boot的优势3. Spring Boot的组件4. Spring Boot的应用 三、Docker1. Docker的介绍2. …...

计算机组成原理基础练习题第四章
1.下述说法中()是正确的。 A、半导体RAM信息可读可写,且断电后仍能保持记忆 B、半导体RAM是易失性RAM,而静态RAM中的存储信息是不易失的 C、半导体RAM是易失性RAM,而静态RAM只有在电源不掉电时,所存信息是不易失的 D、以上选项都不对 解析…...

浅谈Gradle构建工具
一、序言 常见的项目构建工具有Ant、Maven、Gradle,以往项目常见采用Maven进构建,但随着技术的发展,越来越多的项目采用Gradle进行构建,例如 Spring-boot。Gradle站在了Ant和Maven构建工具的肩膀上,使用强大的表达式语…...

如何获取和制作免费的icon图标素材
icon 图标在界面设计中虽然占比不大,但却是不可缺少的设计元素之一。设计师通过 icon 图标,将抽象的概念通俗化,降低用户理解某个操作的难度。而设计师也会通过改变 icon 图标的样式来展现整体界面的视觉效果。icon 图标的风格有很多…...
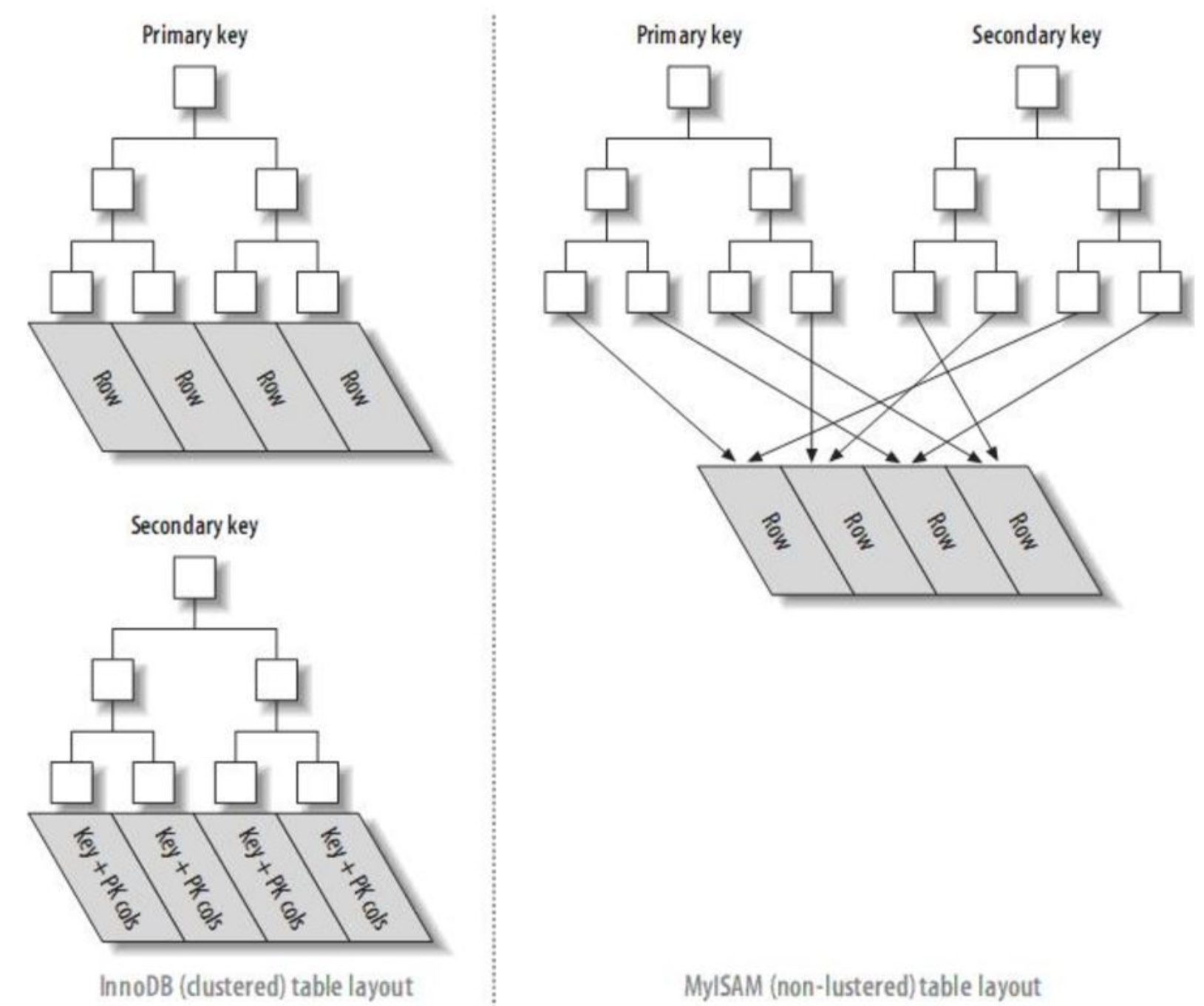
【MySQL】MySQL索引--聚簇索引和非聚簇索引的区别
文章目录 前言1.聚簇索引和非聚簇索引的概念2.两者详细介绍2.1 聚簇索引2.2 非聚簇索引 3. 两者的区别3.1 数据存储方式3.2 二级索引查询 前言 1.聚簇索引和非聚簇索引的概念 数据库表的索引从数据存储方式上可以分为聚簇索引和非聚簇索引两种。“聚簇”的意思是数据行被按照…...

BERT自然语言处理模型:从入门到实践完整指南
BERT自然语言处理模型:从入门到实践完整指南 【免费下载链接】bert TensorFlow code and pre-trained models for BERT 项目地址: https://gitcode.com/gh_mirrors/be/bert BERT(Bidirectional Encoder Representations from Transformers&#x…...

Hasklig 可变字体终极指南:单一文件实现多字重支持的完整教程
Hasklig 可变字体终极指南:单一文件实现多字重支持的完整教程 【免费下载链接】Hasklig Hasklig - a code font with monospaced ligatures 项目地址: https://gitcode.com/gh_mirrors/ha/Hasklig Hasklig 是一款专为程序员设计的开源代码字体,以…...

Simulink模型加密二选一:是选‘受保护模型’还是自己写S-Function?一份给嵌入式代码生成者的选择指南
Simulink模型加密实战:受保护模型与S-Function的深度技术选型 在嵌入式系统开发中,Simulink模型往往承载着核心算法和知识产权。当需要与团队协作或交付给客户时,如何在保证模型可用性的同时防止核心逻辑被窥探或篡改?这成为每个嵌…...

VS2019调试配置报错解析:Designtime生成失败与IntelliSense不可用的深度排查指南
1. 问题现象与初步诊断 当你打开VS2019项目时突然弹出"配置Debug|Win32的Designtime生成失败,IntelliSense可能不可用"的红色错误提示,代码编辑窗口里的智能提示全部消失,连最基本的语法高亮都失效了——这种场景我遇到过不下20次。…...

Clover Bootloader虚拟化环境部署终极指南:QEMU、KVM、Xen全平台支持
Clover Bootloader虚拟化环境部署终极指南:QEMU、KVM、Xen全平台支持 【免费下载链接】CloverBootloader Bootloader for macOS, Windows and Linux in UEFI and in legacy mode 项目地址: https://gitcode.com/gh_mirrors/cl/CloverBootloader Clover Bootl…...

SMUDebugTool终极指南:快速掌握AMD Ryzen系统调试与优化技巧
SMUDebugTool终极指南:快速掌握AMD Ryzen系统调试与优化技巧 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: http…...

s2-pro音色定制实战:为品牌IP打造专属语音形象的全流程方案
s2-pro音色定制实战:为品牌IP打造专属语音形象的全流程方案 1. 为什么品牌需要专属语音形象 在当今数字营销时代,品牌IP的语音形象已经成为品牌识别的重要组成部分。一个独特、一致的语音形象能够: 增强品牌辨识度:让用户一听到…...
)
【花雕学编程】Arduino BLDC 之 AI 迷你小龙虾 MimiClaw 自主闭环控制机器人(带传感器反馈)
从工程视角来看,基于Arduino、使用互补滤波进行姿态控制的BLDC(无刷直流电机)机器人,是一个典型的嵌入式实时闭环控制系统。它集成了传感器数据融合、控制算法和电机驱动,广泛应用于对姿态稳定性有要求的场景。关于 Mi…...

告别沉闷AI工具:像素时装锻造坊带你体验RPG游戏式图像生成
告别沉闷AI工具:像素时装锻造坊带你体验RPG游戏式图像生成 1. 引言:当AI图像生成遇上复古RPG 你是否厌倦了传统AI工具单调的黑色界面和机械化的操作流程?像素时装锻造坊(Pixel Fashion Atelier)彻底改变了这一现状。…...
)
银河麒麟V10 SP1下使用rsync实现多客户端定时数据备份(避坑指南)
银河麒麟V10 SP1多客户端数据同步全链路配置与优化实战 在IT运维工作中,数据备份如同氧气般不可或缺。想象一下,当数十台客户端设备同时运行时,如何确保关键业务数据能够安全、高效地集中备份?银河麒麟V10 SP1作为国产操作系统的…...