赫夫曼树和赫夫曼编码详解
目录
何为赫夫曼树?
赫夫曼树算法
赫夫曼编码
编程实现赫夫曼树
编程实现赫夫曼编码
编程实现WPL
总代码及分析
何为赫夫曼树?
树的路径长度:从树根到每一结点的路径长度之和
结点的带权路径长度:从树根到该结点的路径长度与结点上权的乘积
树的带权路径长度:树中所有叶子结点的带权路径长度之和

假设有n个权值(w1.w2,,,Wn),试构造一棵有n个叶子结点的二叉树,每个叶子结点带权为Wi,则其中WPL最小的二叉称做最优二叉树或赫夫曼树。
赫夫曼树算法
(1)根据给定的n个权值(w1,w2,…,Wn,)构成n棵二叉树的集合F=(T1,T2,…,Tn,其中每棵二叉树Ti中只有一个带权为wi的根结点,其左右子树均空。
(2)在F中选取两棵根结点的权值最小的树作为左右子树构造一棵新的二叉树,且置新的二叉树的根结点的权值为其左、右子树上根结点的权值之和。
(3)在F中删除这两棵树,同时将新得到的二叉树加入F中。
(4)重复(2)和(3),直到F只含一棵树为止。这棵树便是赫夫曼树。
如下图:
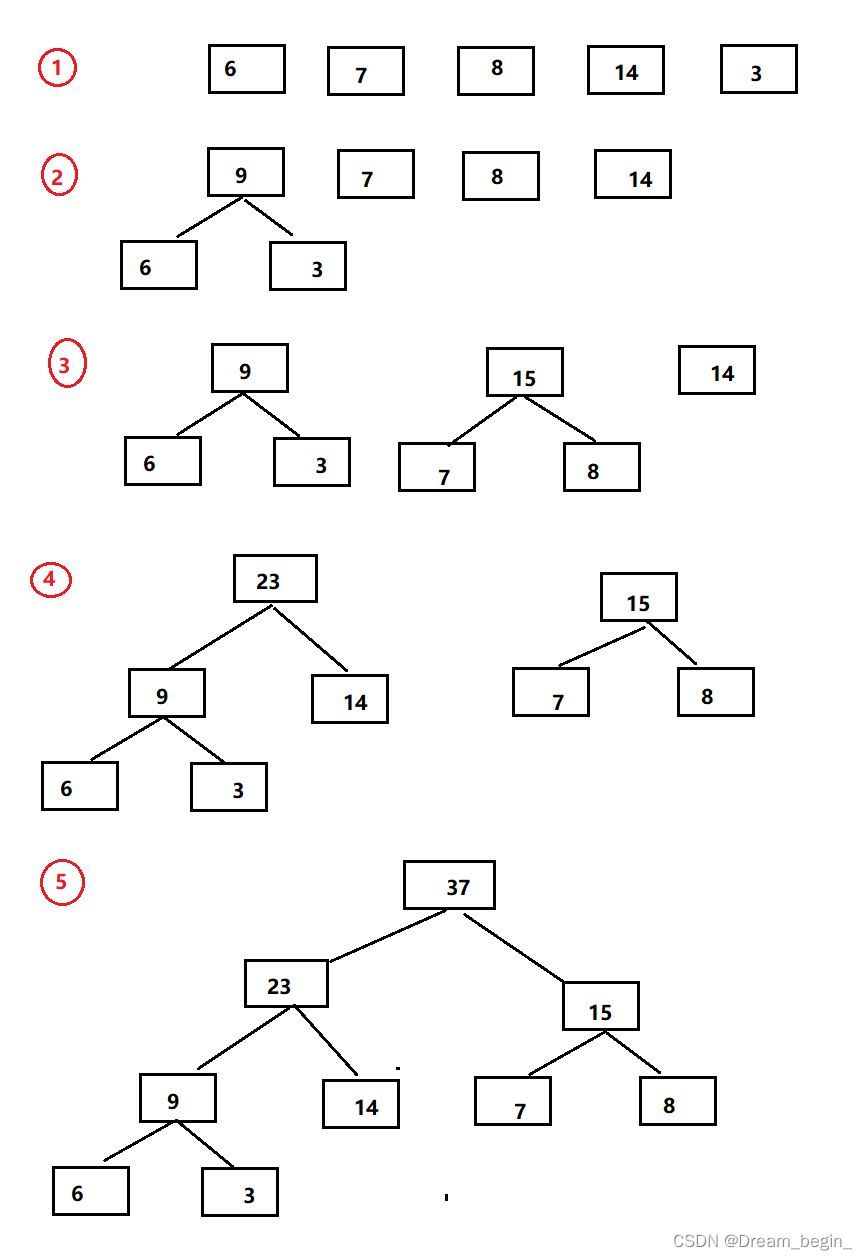
赫夫曼编码
设一课二叉树为:
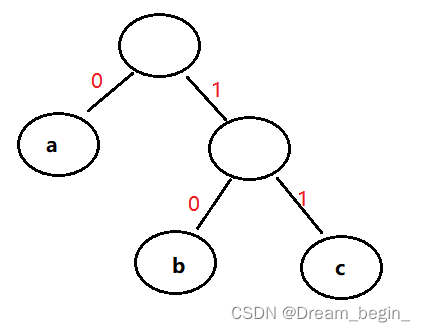
其3个叶子结点分别表示a、b、c3个字符, 约定左分支表示字符‘0’,右分支表示字符‘1’。则可以从根结点到叶子结点的路径上分支字符组成的字符串作为该叶子结点字符的编码。如上图可以得到a、b、c的二级制前缀编码分别为:0、10、11。
如何得到使电文总长最短的二级制编码?假设每种字符在电文中出现的次数为i,编码长度为j,而电文只有n种字符,则电文总长为n种i*j的和。对应到二叉树上,若i表示叶子结点的权值,j为从根到叶子的路径长度。则电文总长恰为二叉树带权路径长度。所以,设计电文总长最短的二级制前缀编码即以N种字符出现的频率作为权值,设计一颗赫夫曼树的问题
编程实现赫夫曼树
//哈夫曼树的存储表示
typedef struct
{int weight; //节点的权值int parent, lchild, rchild; //节点的双亲,左孩子和右孩子
} HTNode, * HuffmanTree;typedef char** HuffmanCode;//查权值最小且双亲为0的节点
void Select(HuffmanTree HT, int len, int& s1, int& s2)
{int i, min1 = 0x3f3f3f3f, min2 = 0x3f3f3f3f; //先赋予最大值for (i = 1; i <= len; i++){if (HT[i].weight < min1 && HT[i].parent == 0){min1 = HT[i].weight;s1 = i;}}int temp = HT[s1].weight; //将原值存放起来,然后先赋予最大值,防止s1被重复选择HT[s1].weight = 0x3f3f3f3f;for (i = 1; i <= len; i++){if (HT[i].weight < min2 && HT[i].parent == 0){min2 = HT[i].weight;s2 = i;}}HT[s1].weight = temp; //恢复原来的值
}void CreatHuffmanTree(HuffmanTree& HT, int n,int*w)
{//构造赫夫曼树HTint m, s1, s2, i;if (n <= 1)return;m = 2 * n - 1;HT = (HuffmanTree)malloc((m + 1) * sizeof(HTNode)); //0号单元未用,所以需要动态分配m+1个单元,HT[m]表示根结点for (i = 1; i <= m; ++i) //将1~m号单元中的权重、双亲、左孩子,右孩子的下标都初始化为0{HT[i].parent = 0;HT[i].lchild = 0;HT[i].rchild = 0;HT[i].weight = 0;}for (i = 1; i <= n; ++i) //输入前n个单元中叶子结点的权值{HT[i].weight = *w;w++;}/*――――――――――初始化工作结束,下面开始创建赫夫曼树――――――――――*/for (i = n + 1; i <= m; ++i){ //通过n-1次的选择、删除、合并来创建赫夫曼树Select(HT, i - 1, s1, s2);//在HT[k](1≤k≤i-1)中选择两个其双亲域为0且权值最小的结点,// 并返回它们在HT中的序号s1和s2HT[s1].parent = i;HT[s2].parent = i;//这里双亲不为0,相当于把s1和s2删除//得到新结点i,从森林中删除s1,s2,将s1和s2的双亲域由0改为iHT[i].lchild = s1;HT[i].rchild = s2; //s1,s2分别作为i的左右孩子HT[i].weight = HT[s1].weight + HT[s2].weight; //i 的权值为左右孩子权值之和}
}编程实现赫夫曼编码
/*
从叶子节点到根节点逆向求赫夫曼树HT中n个叶子节点的赫夫曼编码,并保存在HC中
*/
void HuffmanCoding(HuffmanTree&HT, HuffmanCode& HC, int n)
{//用来保存指向每个赫夫曼编码串的指针HC = (HuffmanCode)malloc((n+1) * sizeof(char*));if (!HC){exit(-1);}//临时空间,用来保存每次求得的赫夫曼编码串//对于有n个叶子节点的赫夫曼树,各叶子节点的编码长度最长不超过n-1//外加一个'\0'结束符,因此分配的数组长度最长为n即可char* code = (char*)malloc(n * sizeof(char));if (!code){printf("code malloc faild!");exit(-1);}code[n - 1] = '\0'; //编码结束符,亦是字符数组的结束标志//求每个字符的赫夫曼编码int i;for (i = 1; i <= n; i++){int current = i; //定义当前访问的节点int father = HT[i].parent; //当前节点的父节点int start = n - 1; //每次编码的位置,初始为编码结束符的位置//从叶子节点遍历赫夫曼树直到根节点while (father !=0){if (HT[father].lchild == current) //如果是左孩子,则编码为0code[--start] = '0';else //如果是右孩子,则编码为1 code[--start] = '1';current = father;father = HT[father].parent;}//为第i个字符的编码串分配存储空间HC[i] = (char*)malloc((n - start) * sizeof(char));if (!HC[i]){printf("HC[i] malloc faild!");exit(-1);}//将编码串从code复制到HCstrcpy(HC[i], code + start);}for (int i = 1; i <=n; ++i) {printf("%s\n", HC[i]);}free(code); //释放保存编码串的临时空间
}编程实现WPL
从叶子结点开始遍历二叉树直到根结点,根结点为HT[2n-1],且HT[2n-1].parent=0;
各叶子结点为HT[1]、HT[2]...HT[n]。
关键步骤是求出各个叶子结点的路径长度,用此路径长度*此结点的权值就是
此结点带权路径长度,最后将各个叶子结点的带权路径长度加起来即可。
int countWPL1(HuffmanTree HT, int n)
{int i, countRoads, WPL = 0;/*由creat_huffmanTree()函数可知,HT[1]、HT[2]...HT[n]存放的就是各个叶子结点,所以挨个求叶子结点的带权路径长度即可*/for (i = 1; i <=n; i++){int father = HT[i].parent; //当前节点的父节点countRoads = 0;//置当前路径长度为0//从叶子节点遍历赫夫曼树直到根节点while (father != 0){countRoads++;father = HT[father].parent;}WPL += countRoads * HT[i].weight;}return WPL;
}总代码及分析
#include <stdio.h>
#include<stdlib.h>
#include<string>
//哈夫曼树的存储表示
typedef struct
{int weight; //节点的权值int parent, lchild, rchild; //节点的双亲,左孩子和右孩子
} HTNode, * HuffmanTree;
typedef char** HuffmanCode;
//查权值最小且双亲为0的节点
void Select(HuffmanTree HT, int len, int& s1, int& s2)
{int i, min1 = 0x3f3f3f3f, min2 = 0x3f3f3f3f; //先赋予最大值for (i = 1; i <= len; i++){if (HT[i].weight < min1 && HT[i].parent == 0){min1 = HT[i].weight;s1 = i;}}int temp = HT[s1].weight; //将原值存放起来,然后先赋予最大值,防止s1被重复选择HT[s1].weight = 0x3f3f3f3f;for (i = 1; i <= len; i++){if (HT[i].weight < min2 && HT[i].parent == 0){min2 = HT[i].weight;s2 = i;}}HT[s1].weight = temp; //恢复原来的值
}void CreatHuffmanTree(HuffmanTree& HT, int n,int*w)
{//构造赫夫曼树HTint m, s1, s2, i;if (n <= 1)return;m = 2 * n - 1;HT = (HuffmanTree)malloc((m + 1) * sizeof(HTNode)); //0号单元未用,所以需要动态分配m+1个单元,HT[m]表示根结点for (i = 1; i <= m; ++i) //将1~m号单元中的权重、双亲、左孩子,右孩子的下标都初始化为0{HT[i].parent = 0;HT[i].lchild = 0;HT[i].rchild = 0;HT[i].weight = 0;}for (i = 1; i <= n; ++i) //输入前n个单元中叶子结点的权值{HT[i].weight = *w;w++;}/*――――――――――初始化工作结束,下面开始创建赫夫曼树――――――――――*/for (i = n + 1; i <= m; ++i){ //通过n-1次的选择、删除、合并来创建赫夫曼树Select(HT, i - 1, s1, s2);//在HT[k](1≤k≤i-1)中选择两个其双亲域为0且权值最小的结点,// 并返回它们在HT中的序号s1和s2HT[s1].parent = i;HT[s2].parent = i;//这里双亲不为0,相当于把s1和s2删除//得到新结点i,从森林中删除s1,s2,将s1和s2的双亲域由0改为iHT[i].lchild = s1;HT[i].rchild = s2; //s1,s2分别作为i的左右孩子HT[i].weight = HT[s1].weight + HT[s2].weight; //i 的权值为左右孩子权值之和}
} // CreatHuffmanTree
/*
从叶子节点到根节点逆向求赫夫曼树HT中n个叶子节点的赫夫曼编码,并保存在HC中
*/
void HuffmanCoding(HuffmanTree&HT, HuffmanCode& HC, int n)
{//用来保存指向每个赫夫曼编码串的指针HC = (HuffmanCode)malloc((n+1) * sizeof(char*));if (!HC){exit(-1);}//临时空间,用来保存每次求得的赫夫曼编码串//对于有n个叶子节点的赫夫曼树,各叶子节点的编码长度最长不超过n-1//外加一个'\0'结束符,因此分配的数组长度最长为n即可char* code = (char*)malloc(n * sizeof(char));if (!code){printf("code malloc faild!");exit(-1);}code[n - 1] = '\0'; //编码结束符,亦是字符数组的结束标志//求每个字符的赫夫曼编码int i;for (i = 1; i <= n; i++){int current = i; //定义当前访问的节点int father = HT[i].parent; //当前节点的父节点int start = n - 1; //每次编码的位置,初始为编码结束符的位置//从叶子节点遍历赫夫曼树直到根节点while (father !=0){if (HT[father].lchild == current) //如果是左孩子,则编码为0code[--start] = '0';else //如果是右孩子,则编码为1 code[--start] = '1';current = father;father = HT[father].parent;}//为第i个字符的编码串分配存储空间HC[i] = (char*)malloc((n - start) * sizeof(char));if (!HC[i]){printf("HC[i] malloc faild!");exit(-1);}//将编码串从code复制到HCstrcpy(HC[i], code + start);}for (int i = 1; i <=n; ++i) {printf("%s\n", HC[i]);}free(code); //释放保存编码串的临时空间
}
/*
从叶子结点开始遍历二叉树直到根结点,根结点为HT[2n-1],且HT[2n-1].parent=0;
各叶子结点为HT[1]、HT[2]...HT[n]。
关键步骤是求出各个叶子结点的路径长度,用此路径长度*此结点的权值就是
此结点带权路径长度,最后将各个叶子结点的带权路径长度加起来即可。
*/
int countWPL1(HuffmanTree HT, int n)
{int i, countRoads, WPL = 0;/*由creat_huffmanTree()函数可知,HT[1]、HT[2]...HT[n]存放的就是各个叶子结点,所以挨个求叶子结点的带权路径长度即可*/for (i = 1; i <=n; i++){int father = HT[i].parent; //当前节点的父节点countRoads = 0;//置当前路径长度为0//从叶子节点遍历赫夫曼树直到根节点while (father != 0){countRoads++;father = HT[father].parent;}WPL += countRoads * HT[i].weight;}return WPL;
}int main()
{HuffmanTree HT;HuffmanCode HC;int n;printf("请输入叶子结点的个数:\n");scanf("%d", &n);int w[8] = { 2, 15, 30, 8, 10, 5, 12, 18 };CreatHuffmanTree(HT, n,w);printf("哈夫曼树建立完毕!\n");printf("各字符赫夫曼编码为:\n");HuffmanCoding(HT, HC, n);printf("带权路径最小为:\n");printf("%d", countWPL1(HT, n));}测试:
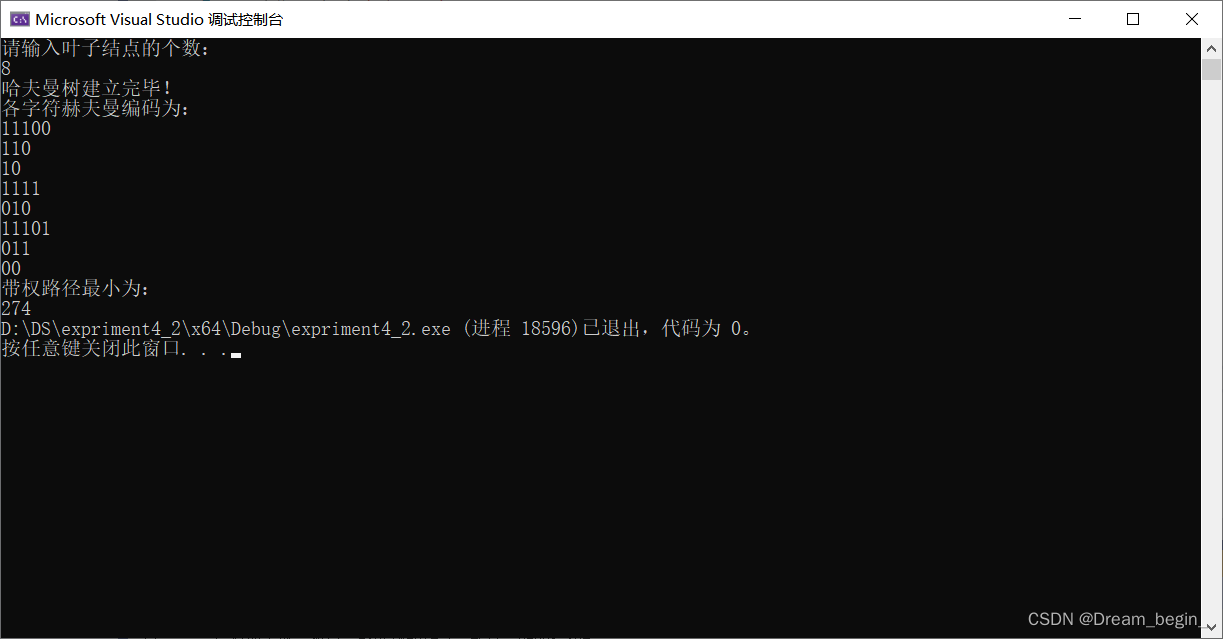
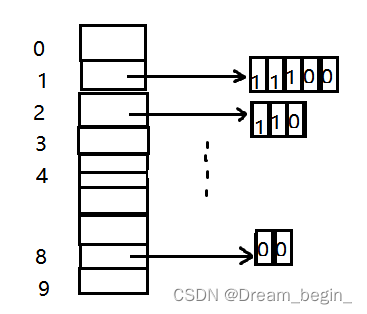
测试中的数据结构:
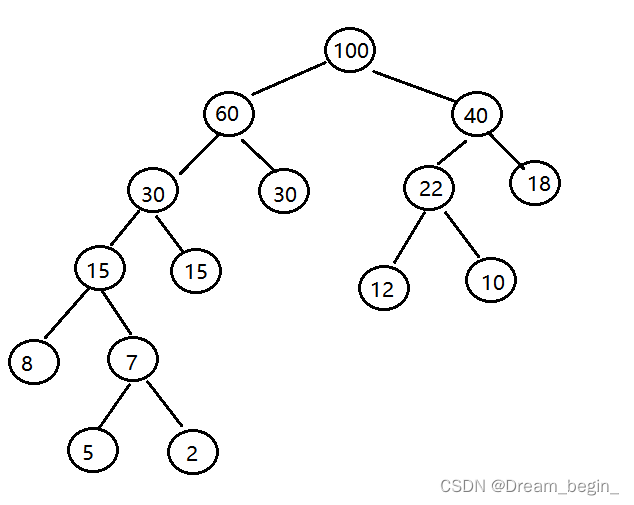
HT:
初始化后

创建后:

HC
相关文章:
赫夫曼树和赫夫曼编码详解
目录 何为赫夫曼树? 赫夫曼树算法 赫夫曼编码 编程实现赫夫曼树 编程实现赫夫曼编码 编程实现WPL 总代码及分析 何为赫夫曼树? 树的路径长度:从树根到每一结点的路径长度之和 结点的带权路径长度:从树根到该结点的路径长度…...

unity UGUI系统梳理 -交互组件
概述 unity 中的交互组件可用于处理交互,例如鼠标或触摸事件以及使用键盘或控制器进行的交互 1、按钮 (Button) Button详解 2、开关 (Toggle) Background:背景图片,控制toggle组件的背景颜色改变,从而展示此物体是否被选中的…...
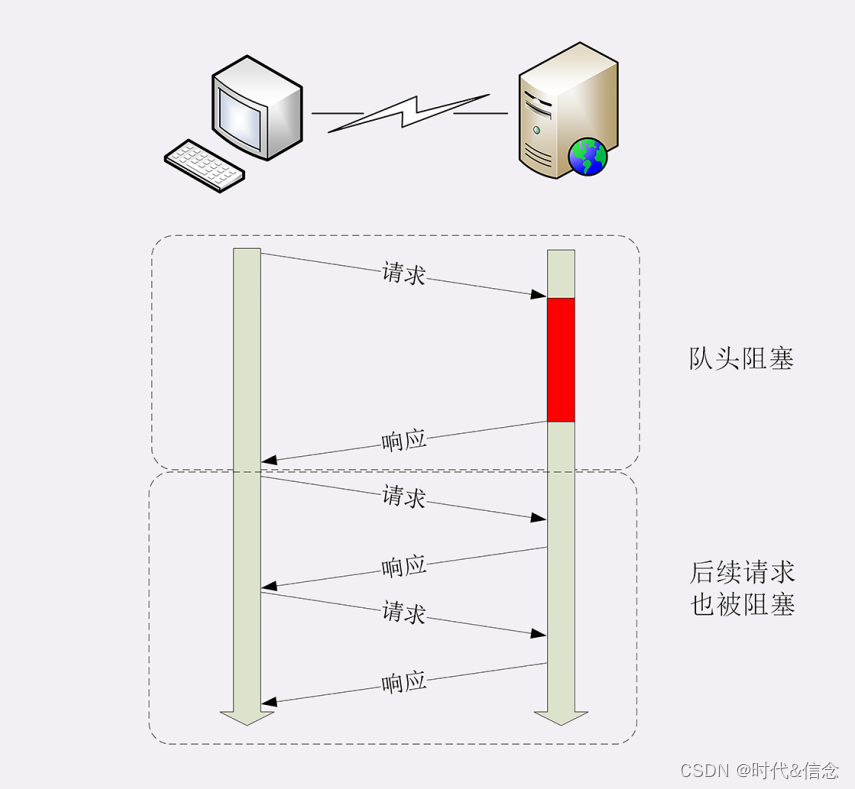
HTTP第15讲——HTTP的连接管理
短连接 HTTP 协议最初(0.9/1.0)是个非常简单的协议,通信过程也采用了简单的“请求 - 应答”方式。 它底层的数据传输基于 TCP/IP,每次发送请求前需要先与服务器建立连接,收到响应报文后会立即关闭连接。 因为客户端与…...
深度剖析Mybatis-plus Injector SQL注入器
背景 在项目中需要同时操作Sql Server 以及 MySQL 数据库,可能平时直接使用 BaseMapper中提供的方法习惯 了,不用的话总感觉影响开发效率,但是两个数据库的SQL语法稍微有点差别,有些暴露的方法并不能直接使用,所以便想…...

【Mysql实战】使用存储过程和计算同比环比
背景 同环比,是基本的数据分析方法。在各类调研表中屡见不鲜,如果人工向前追溯统计数据,可想而知工作量是非常大的。 标题复制10行,并且每行大于10个字符【源码解析】SpringBoot接口参数【Mysql实战】使用存储过程和计算同比环比…...

ChatGPT的前世今生,到如今AI领域的竞争格局,本文带你一路回看!
73年前,“机器思维”的概念第一次被计算机科学之父艾伦图灵(Alan Turing)提出,从此,通过图灵测试成为了人类在AI领域为之奋斗的里程碑目标。 73年后的今天,在AI历经了数十年的不断进化、迭代后,…...
)
如何在JavaScript中获取当前时间yyyymmddhhmmss? (六种实现方式)
## 介绍 在编写JavaScript代码时,我们经常需要获取当前日期和时间。在本文中,我们将介绍几种获取当前时间并将其格式化为 yyyymmddhhmmss 的字符串的方法。 方法一:使用Date对象 在JavaScript中,我们可以使用 Date 对象来获取当…...

一、走进easyUI的世界
1.什么是easyUI? jQuery EasyUI是一组基于jQuery的UI插件集合体,而jQuery EasyUI的目标就是帮助web开发者更轻松的打造出功能丰富并且美观的UI界面。开发者不需要编写复杂的javascript,也不需要对css样式有深入的了解,开发者需要…...

2023 上半年软件设计师知识点复习总纲
前言:全国计算机技术与软件专业技术资格(水平)考试(以下简称IT职业资格考试)是由中华人民共和国人事部主管,国家计算机网络与信息安全管理中心主办的一项国家级、权威性的计算机职业技能水平认证考试。主要…...
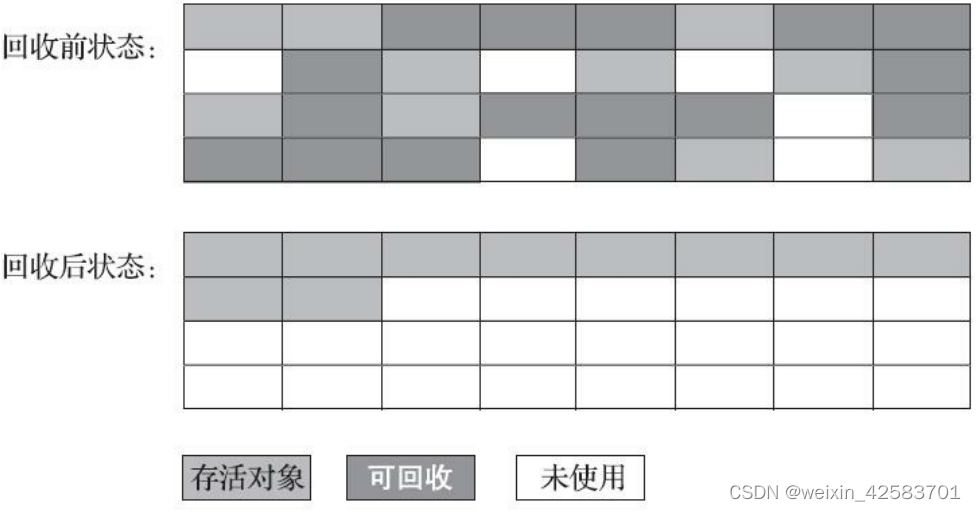
深入理解Java虚拟机:JVM高级特性与最佳实践-总结-3
深入理解Java虚拟机:JVM高级特性与最佳实践-总结-3 垃圾收集器与内存分配策略垃圾收集算法标记-清除算法标记-复制算法标记-整理算法 垃圾收集器与内存分配策略 垃圾收集算法 标记-清除算法 最基础的垃圾收集算法是“标记-清除”(Mark-Sweepÿ…...
vue3 cesium datav 可视化大屏
目录 0. 预览效果 1. 代码库包 2. 技术点 3. 一些注意事项(配置参数) 4. 相关代码详情 0. 预览效果 包含的功能: ① 地球按照一定速度自转 ② 修改加载的geojson面样式 ③ 添加 文字 标注! 1. 代码库包 直接采用vue-cli5 创建…...

python内置函数,推导式
abs:取绝对值 data abs(-10) pow:次方 data pow(2,5) sum:求和 num_list p[1,2,10,20] res sum(num_list) divmod取商和余数: v1,v2 divmod&…...

【Flink】DataStream API使用之Flink支持的数据类型
Flink的使用过程中,我们的数据都是定义好的 UserBehavior 类型,那还有没有其他更灵活的类型可以用呢?Flink 支持的数据类型到底有哪些? 1. Flink 的类型系统 Flink 作为一个分布式处理框架,处理的是以数据对象作为元…...

QT实现固高运动控制卡示波器
目录 一、固高示波器 二、基于QCustomPlot实现示波器 三、完整源码 一、固高示波器 固高运动控制卡自带的软件有一个示波器功能,可以实时显示速度的波形,可辅助分析电机的运行状态。但是我们基于sdk开发了自己的软件,无法再使用该功能&…...

洛谷P1157详解(两种解法,一看就会)
一、问题引出 组合的输出 题目描述 排列与组合是常用的数学方法,其中组合就是从 n n n 个元素中抽出 r r r 个元素(不分顺序且 r ≤ n r \le n r≤n),我们可以简单地将 n n n 个元素理解为自然数 1 , 2 , … , n 1,2,\dot…...

JavaScript异步编程和回调
目录 1、编程语言中的异步 2、JavaScript 3、回调 3.1在回调中处理错误 3.2回调的问题 3.2回调的替代方案 1、编程语言中的异步 默认情况下,JavaScript是同步的,并且是单线程…...

Qt开发笔记(Qt5.9.9下载安装环境搭建win10)
#1 Qt下载网站(国内、国外镜像) #2 Qt5.9.9安装选项 #3 配置系统环境变量 #4 创建测试项目 #1 Qt下载网站(国内、国外镜像) 官方下载地址(慢):http://download.qt.io/ 国内镜像网站 这里给大家…...
使用Plist编辑器——简单入门指南
本指南将介绍如何使用Plist编辑器。您将学习如何打开、编辑和保存plist文件,并了解plist文件的基本结构和用途。跟随这个简单的入门指南,您将掌握如何使用Plist编辑器轻松管理您的plist文件。 plist文件是一种常见的配置文件格式,用于存储应…...

Python常用的开发工具合集
Python是一种功能强大且易于学习的编程语言,被广泛应用于数据科学、机器学习、Web开发等领域。随着Python在各个领域的应用越来越广泛,越来越多的Python开发工具也涌现出来。但是,对于新手来说,选择一款合适的Python开发工具可…...

机器学习之线性回归
往期目录 python在线性规划中的应用 文章目录 一、线性回归算法概述1.1 什么是线性回归?1.2 线性回归算法原理1.3 线性回归的应用场景 二、线性回归算法Python实现2.1 导入必要的库2.2 随机生成数据集2.3 拟合模型2.4 预测结果2.5 结果可视化 三、完整代码 线性回归…...

Python的sys模块中的getsizeof函数在对象内存测量中的局限性
Python作为一门动态语言,其内存管理机制一直是开发者关注的焦点。sys模块中的getsizeof函数常被用来测量对象占用的内存大小,但这个看似简单的工具背后隐藏着诸多陷阱。本文将揭示getsizeof函数在实际使用中的局限性,帮助开发者更准确地评估程…...

曲靖房子整装推荐升卓装饰:一站式服务让新房装修省心省力更省钱
购买新房是人生大事,而新房整装是实现理想家居的关键一步。当前曲靖新房业主装修面临流程繁琐、选材头疼、增项频发、环保担忧、工期延误等诸多痛点,尤其是首次装修业主,缺乏经验更易踩坑。曲靖市麒麟区升卓装饰工程有限责任公司以中高端品质…...

10个必知的Android开源项目:从android-dev-com看Google、Square等大厂技术栈
10个必知的Android开源项目:从android-dev-com看Google、Square等大厂技术栈 【免费下载链接】android-dev-com Some Famous Android Developers Information, 微信公众号:codekk, 网站: 项目地址: https://gitcode.com/gh_mirrors/an/android-dev-com andro…...

第5章,[标签 Win32] :GDI 的其他方面的分类
专栏导航 上一篇:第5章,[标签 Win32] :GDI 的基本图形 回到目录 下一篇:无 本节前言 对于本节所讲解的知识,有可能,你会需要时不时地参考本专栏的其它文章。真的遇到了需要参考之前的文章的知识点&…...

R语言机器学习驱动生态经济研究:从CEADs数据清洗、随机森林建模到因果推断全流程
在生态文明建设与“双碳”战略目标全面推进的当下,精准量化能源与环境领域的碳排放清单、深入挖掘驱动因子并预测未来趋势,已成为环境经济学、生态学及公共政策研究的核心命题。传统的统计学方法在面对海量异构数据、非线性复杂关系及多维评价体系时&…...

AIAgent算力成本飙升?3步精准定位隐性开销并压降47%的实操指南
第一章:AIAgent算力成本飙升?3步精准定位隐性开销并压降47%的实操指南 2026奇点智能技术大会(https://ml-summit.org) 当AIAgent从原型走向生产,算力账单常以超预期50%的速度攀升——真正吞噬预算的并非大模型推理本身,而是未被…...

CTF全解析:五大核心模块+零基础学习+参赛指南
CTF全解析:五大核心模块零基础学习参赛指南 摘要:CTF(Capture The Flag,夺旗赛)作为网络安全领域最具实战性的竞赛形式,是零基础入门网络安全、锤炼技术、积累求职竞争力的最佳路径。但很多新手刚接触时&a…...

LIN一致性测试避坑指南:从电阻、电平到睡眠唤醒,实测CANoe外部设备集成那些事儿
LIN一致性测试实战避坑指南:从设备同步到脚本优化的全流程解析 当示波器波形与CANoe记录的时间轴对不上,当睡眠唤醒测试中的电源控制脚本频繁报错,当checksum错误让你在节点硬件与测试配置间反复排查——这些才是LIN一致性测试工程师的真实日…...

你项目中 RAG 的存储架构是怎么设计的?
1. 题目分析RAG 系统里最容易被低估的就是存储层。很多人把 RAG 理解成"文档切片→扔进向量库→检索→喂给 LLM"的线性流水线,存储仿佛只是中间一个"放东西的地方"。但真正做过生产级 RAG 的人都知道,存储架构的设计深度远超一个向量…...

蓝奏云直链解析终极指南:3秒获取高速下载链接
蓝奏云直链解析终极指南:3秒获取高速下载链接 【免费下载链接】LanzouAPI 蓝奏云直链,蓝奏api,蓝奏解析,蓝奏云解析API,蓝奏云带密码解析 项目地址: https://gitcode.com/gh_mirrors/la/LanzouAPI 还在为蓝奏云…...