分区计量管理项目应用
为充分发挥分区计量管理项目在漏损控制的效用,应构建科学完备的应用体系,如下图

分区计量应用体系
1. 基于水量平衡分析的漏损现状评估方法
分区计量管理项目通过监控分析DMA 分区内流量、压力、水质、大用户用水等情况,结合营业抄收系统的营业数据和稽查数据,形成水量平衡表,建立完善的水量平衡分析机制,对真实漏失、计量损失、管理漏损进行全要素管理与分析,并结合每个DMA分区的漏损现状,采用针对性的解决方案,通过压力控制、管线探漏、维修维护、管网改造、营业稽查、计量管理等措施,提高控漏成效。
水量平衡分析不仅适用于整个供水区域,也适用于不同层级的分区计量区域。供水企业应根据《城镇供水管网漏损控制及评定标准》CJJ 92—2016相关要求,做好水量统计工作和水平衡分析,量化各构成要素的水量,按年度进行分析。
分区计量水量平衡分析具体统计步骤如下:
(1)统计系统供水总量:通常见于一级DMA 分区或二级DMA分区,供水总量包括自产供水量和外购供水量,可通过流量计量设备直接获取数据。
一级DMA分区之间或供水企业与自来水厂之间用于贸易结算的流量计需定期比对,校验计量设备的准确性和稳定性。在流量计安装时应在测流井内预留用于比对的直管段,直管段宜采用不锈钢管,比对时可采用便携式超声波流量计与在线流量计进行串接,定期(一般每月或每季度安排一次)对2个流量计的瞬时流量、累积流量值进行同步比对,通过定期比对,动态掌握两者之间的相对误差值,可分析判断在线流量计是否处于稳定的工作状态。
除定期比对外,每年还应至少安排一次仪表的校验,也可利用清水池液位进行校验,其中一次仪表的校验内容主要为传感器电极对地电阻、励磁电阻、励磁对地绝缘、转换器模拟偏差等参数,通过校验这些参数是否在标准范围之内,评估仪表的准确性和稳定性。部分电磁流量计的检测标准可参考表1-1,电磁流量计检测工具可见表1-2
部分电磁流量计的检测标准 表1-1
| 检测项目 | 科隆标准 | 威尔泰XEM标准 | 偏差分析 |
| 传感器电极对地电阻 | 0.001~1M之间,且两个电极电阻偏差小于或等于20% | 0.001~1M之间,且两个电极电阻偏差小于或等于20% | 少于此范围,排出管内流体再次测量,如果仍然很低,电极线路短路;高于此范围,电极接线断路或者电极污损;如果差异极大,电极接线断路或电极污损 |
| 励磁电阻 | 15~200 | 15~200 | 少于此范围,励磁短路;高于此范围,励磁断路 |
| 励磁对地绝缘 | ≥20M | 不监测 | 少于此值,传感器进水或者线缆故障 |
| 转换器模拟偏差 | ≤1.5% | ≤3% |
电磁流量计检测工具 表1-2
| 序号 | 工具 | 规格 | 检测项目 | 准确度等级 |
| 1 | 兆欧表(摇表) | 500v | 传感器励磁对低绝缘 | 10级 |
| 2 | 万用表 | 指针式,电阻档 | 传感器电极对地电阻,传感器励磁电阻 | ±1.5% |
| 3 | 模拟信号发生器 | 转换器信号模拟 | ±1% |
若存在比对、校验不合格的流量计,应及时对流量计进行更换,并根据比对的误差值及更换后流量计的运行数据对供水量进行纠正;对没有计量的水量,应通过便携式流量计临时测量,或通过水泵曲线、压力和平均运行时间进行分析。
(2)统计收费计量用水量:按营业抄收系统数据或记录进行统计计算。
计量计费用户的用水量抄见可通过固定抄表周期、抄见日期等方式,实现抄见时间和供水量的统计时间保持一致。同时,供水企业可对一级DMA分区的计费水表的抄准率、抄见率不定期地进行抽检,并建立水量内外复核机制,对异常水量及时安排复核,以确保抄收数据的质量。
此外,供水企业应按照国家对计量水表的强制检定周期要求,对计量水表采取固定期限或动态周检相结合的管理模式:对于公称口径小于或等于50mm,且常用流量小于或等于16m³/h及用于贸易结算的水表,只作首次强制检定,限期使用,到期轮换;对于公称口径小于或等于25mm的水表,使用期限不超过6年;对于公称口径在25~50mm之间的水表,使用期限不超过4年;对于公称口径大于50mm,或常用流量大于16m³/h的水表检定周期宜为2年,用于贸易结算的超声波流量计检定周期不宜超过2年;用于贸易结算的电磁流量计,若其准确度等级为0.2级及大于0.2级,在线检定周期应为1年,若其准确度等级低于0.2级或使用引用误差的流量计,在线检定周期应为2年。同时,供水企业还应定期分析在装水表的配表合理性,对存在大表小流量、小表大流量等现象的计量水表应及时进行口径优化,若与用户协商存在问题,也可采用水表类型优化,对存在故障、堆压等情况的水表,应及时安排维护,确保计量可靠、抄见准确。
(3)统计收费未计量用水量:可通过营业抄收系统估算水量,也可临时装表,估算用户用水量。针对未装表采用定量缴纳水费的用户,可优先安排管线改造,实行装表计量。针对新建工程因管道试压、工程质量验收等所产生的水量,可作为计费水量列入工程成本。
(4)统计未收费已计量用水量:可按计量或相关单位提供的数据计算。
(5)估算未收费未计量用水量:需先细化未收费未计量用水量的组成部分,然后可通过临时装表法、计量差计算法、经验公式法等方法测定估算水量。
对于供水企业因管道维护作业所产生的用水量,可建立作业审批机制、过程监管机制和水量核算管理机制,对实际产生的水量可采取经验公式法、临时装表法、计量差计算法测定。
对于市政公共消火栓,可定期核定因消防救援等所产生的水量,在条件允许的情况下,宜采用装表计量的方式,将该水量转化为未收费已计量用水量。
(6)估算表观漏损水量:表观漏损分为非法用水量、计量误差、数据处理误差。非法用水量可与用户协商确定,也可临时装表测定。计量误差和数据处理误差主要包括居民用户总分表差损失水量和非居民用户表具误差损失水量。居民用户总分表差损失水量可通过居民用户总分表差率和居民用户用水量求得,计算公式见(1-3)。非居民用户表具误差损失水量可通过非居民用户表具计量损失率和非居民用户用水量求得,计算公式见(1-4)。

( 1-3 )
式中 Qm I——居民用户总分表差损失水量,万m³;
Qmr——抄表到户的居民用户用水量,万m³;
Cmr——居民用户总分表差率,%。
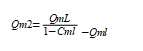
( 1-4)
式中 Qm₂——非居民表具误差损失水量,万m³;
QmL——非居民用户用水量,万m³;
Cmr——非居民用户表具计量损失率,%。
(7)计算真实漏失水量:真实漏失水量包括明漏水量、暗漏水量、背景漏失水量和水箱、水池的渗漏和溢流水量。漏水点可分为明漏和暗漏,具体划分依据见本书第5章。单一漏水点的漏失水量计算公式见(1-3),明漏水量和暗漏水量之和的计算公式见(6-4),背景漏失水量的计算公式见(1-5)。水箱、水池的渗漏和溢流水量可通过观测评估的方式获取,也可安装数据记录仪在预设的时间间隔自动记录水位,还可关闭水箱、水池的进出水阀门,进行跌落试验,计算出溢流值。

( 1-5)
式中 QL——漏点流量,m³/s;
C₁——覆土对漏水出流影响,折算为修正系数,根据管径大小取值:DN15~DN50取0.96,DN75~DN300取0.95,DN300以上取0.94。在实际工作过程中,一般取 C₁=1 ;
C₂——流量系数,取0.6;
A——漏水孔面积,m²,一般采用模型计取漏水孔的周长,折算为孔口面积,在不具备条件时,可凭经验进行目测;
g——重力加速度,取9.8m/s²;
H——孔口压力,m,一般应进行实测,不具备条件时,可取管网平均控制压力。
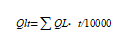
( 1-6)
式中 QU——漏点水量,万m³;
t——漏点存在时间,s,若漏水点为明漏,则t取该漏水点自发现破损至关闸止水的时间;若漏水点为暗漏,则t取管网检漏周期。

(1-7)
式中 QB——背景漏失水量,万m³;
Qn——单位管长夜间最小流量,m³/(km·h),在DMA样本区域开展检漏后测定;
L——管网总长度, km;
T——统计时间,h,按1年计算。
通过上述步骤,将统计计算出的各部分水量填入对应表格条目中,建立水量平衡表,通过将用水量按不同的使用途径进行细化,追踪各部分水量的实际消耗,即可计算出漏损水量和漏损水量占比,进而实现科学合理的漏损评价分析。如对表观漏损进一步分析,可以判断其产生的主要原因是非法用水或水表计量误差、数据传输错误抑或是数据分析误差,进而可以为下一步工作开展提供方向。
2. 基于DMA的物理漏损研判方法
2.1夜间最小流量分析法
由于DMA区域的管网规模相对较小,大多数DMA分区内不含有任何水库或主干管,尤其是三级DMA分区,其服务用户甚至可能仅为一个小区。因此,在分析DMA 区域内的物理漏损时,主要考虑区域内干管和用户支管的管道漏损水量。
若DMA区域内干管发生漏水,则该漏水点在检出前,其一天内的持续时间应为24h。若用户支管发生漏水,则该漏水点在检出前,其一天内的漏失水量应与用户全天需水量的变化趋势相吻合,即早晚用水高峰时段,漏失水量较多,夜间用水低峰时段,漏失水量较少。基于上述两种漏损情况的特性,可以通过分析夜间最小流量(Minimum Night Flow,MNF)的变化判断该DMA 区域是否存在流量异常。图6-8为典型居民生活用水的DMA 区域流量变化曲线图。
夜间最小流量是一个周期内的最小流量,通常情况下,以24h为一个周期。夜间最小流量常见于凌晨2:00~5:00之间。如图2-2所示,在该时段内,用户用水量在一天中最小,而漏失水量在用水量中的占比最大。因此,可以通过每日分析夜间最小流量的方式,间接判断漏失水量的变化情况,估算漏失水量。值得注意的是,尽管在夜间时段,用户需水量相对较小,但也应考虑少量的合法夜间流量(Legitimate Night Flow,LNF),如冲厕、洗衣机用水等。
通过估算合法夜间流量可以计算出净夜间流量(Net Night Flow,NNF),即夜间漏失水量,计算方法见式(2-1):
净夜间流量=夜间最小流量-合法夜间流量 (2-1)
若DMA区域内水表安装率达100%,则可通过计量该DMA区域内每小时所有非住宅的夜间流量和部分(如10%)住宅水表记录水量的方法估算合法夜间流量。若DMA区域内水表安装率未达100%,供水企业需先对该DMA区域内的所有住宅和非住宅用户进行调查,确定每个用户类型(住宅、商业、工业及其他类型用水)连接的支管总数量,然后结合其他DMA区域的数据,估算出每个用户类型的夜间流量系数,再乘以每个类型的支管数量,即可估算出该DMA区域的合法夜间流量。

图 2-2 小区DMA区域流量变化曲线图
2.2新增漏损预警法
通过分区计量管理系统对DMA分区的流量、压力、水质等参数进行长期监测,能较为及时准确地预警新增漏损,缩短漏点的感知和发现时间,辅助指导人工检漏,提高检漏工作效率,在一定程度上,预防或避免管道爆漏事故发生,保障供水管网漏损维持低位水平。当DMA区域内出现水量异常时可采用新增漏损预警法,如图2-3所示。
新增漏损预警法的具体实施步骤如下:
(1)确认同一时间段是否有管网作业,如停水作业、冲洗作业等。
(2)查看同一时间段,远传大用户的水量变化情况,结合比较系统及大用户水量的变化趋势,观察变化量是否一致。
(3)查看与计量分区相关的各个进出口流量计的数据,主要查看流量计的数据是否完整、计量是否异常。同时,查看相邻片区的水量变化,是否出现同步增减,若同步增减则可能是相互转供的流量计出现了计量问题,如数据缺失或表计故障。
(4)核实是否有分区边界阀门打开或者有新建的管线连通。
(5)排除上述因素,若DMA区域内的夜间最小流量及日供水量持续偏高,应及时安排检漏排查,核实是否由管道漏水引起,漏点查明修复后,应观察夜间最小流量及日供水量是否恢复正常水平。
2.3 基于DMA和噪声监测的渗漏预警技术
通过上述两种应用,可以评估DMA区域内的漏损现状,发现漏损异常现象,缩短发现时间,但无法实现漏水点的定位。因此,为解决这一问题,国内外供水企业不断实践探索,通过在成熟的分区计量管理项目上,有机结合渗漏预警技术,形成分区预警系统,实现了控漏模式“由面到线”的深化,化被动堵漏为主动控漏。
分区预警系统以噪声监测设备的管网噪声数据为基础,应用供水管网漏水噪声的大数据识别技术和相关定位技术,实现对管道漏水点的准确定位,并结合系统工单流程,实现漏水点的高效响应和处置。
同时,通过结合分区计量的管理应用,可有效检出DMA区域内难以发现的小背景漏失和人工难以听到的疑难漏点,推动人工检漏与科技检漏无缝衔接,实现对管网漏水噪声、管道流量、管网压力的全方位综合监测,建立精细化的主动控漏工作机制,构建完整的供水管网渗漏预警体系,及时发现并处置漏点隐患,提升管网安全预警能力和信息化管理水平,降低漏损量,预防爆管,对保障城市安全供水发挥积极作用。
2.4基于DMA和智能调度的分区控压技术
绝大多数爆管事件的发生不是因为管网压力过高,而是因为持续的压力波动促使管道不断膨胀和收缩,最终导致管道破裂。因此,通过对供水管网实行科学合理的压力调控,平衡管网压力,可以保障供水管网安全稳定运行,减少爆管事故的发生,延长管网使用寿命。同时,因为漏水点的泄漏速率与管网压力呈正相关关系,所以可以通过控压的方式减少背景漏失水量和难以检出的漏点漏失水量。
分区控压系统以管网压力监测点采集上传的压力数据为基础,应用水力模型技术,对供水管网进行实时模拟运算,可以有效缩短管网异常事件的报警时间,辅助人工决策,提高事件定位的精确度,如图2-3所示。

图2-3 基于分区控压的事件预警及辅助决策
同时,结合分区计量的管理应用,通过在管网压力较大的DMA区域安装减压阀或智能压力管理阀,以分区控压、按需调压的方式,实现“高峰不低,低峰不高”,稳定区域内供水管网的压力波动,减少水锤等破坏性事故的发生。如图2-4为分区控压、按需调压示例图。
图2-4 分区控压、按需调压示例图
相关文章:
分区计量管理项目应用
为充分发挥分区计量管理项目在漏损控制的效用,应构建科学完备的应用体系,如下图 分区计量应用体系 1. 基于水量平衡分析的漏损现状评估方法 分区计量管理项目通过监控分析DMA 分区内流量、压力、水质、大用户用水等情况,结合营业抄收系统的营…...
参数解析)
LayoutInflater中inflate()参数解析
1、关于LayoutInflater,它是如何通过 inflate 方法获取到具体View的? 获得LayoutInflater实例的方式有以下三种: LayoutInflater inflater getLayoutInflater();LayoutInflater inflater LayoutInflater.from(this);LayoutInflater infla…...

星河案例ㅣ中国电信 X 冲量在线:基于智算中心的隐私计算应用实践
▏摘要 中国电信是中国三大运营商之一,为响应国家“东数西算”工程的全新数据中心形态,中国电信引入隐私计算平台,对内实现数据确权跟踪、对外实现数据共享交易,盘活中国电信分布在全国不同区域的数据资源和算力资源,…...

开发笔记之:JAVA读取QT QDataStream输出
1.背景 之前的标题是【JAVA反序列化QT序列化内容】,觉得太大太绕,最后改为现在的标题。 本篇内容是对用JAVA解析QT(用的是QDataSteam)所输出(序列化)的内容的小结。 本文涉及类型包括:QString…...
Docker入门实战---修改Docker镜像源
前言 现在大部分互联网公司在实施项目时几乎都会以微服务架构进行落地,那么微服务一旦多了之后就会面临一个如何友好的治理的问题,本人不会重点介绍治理的问题,而是会简单就治理的其中一个环节服务部署运维的问题进行介绍,服务部…...
)
Java构建高并发高可用的电商平台(静态架构蓝图之剖析架构)
静态架构蓝图 整个架构是分层的分布式的架构,纵向包括CDN,负载均衡/反向代理,web应用,业务层,基础服务层,数据存储层。水平方向包括对整个平台的配置管理部署和监控。 剖析架构 1. CDN CDN系统能够实时…...

SpringBoot核心运行原理解析之------@Conditional条件注解
在SpringBoot核心运行原理解析之------@EnableAutoConfiguration文档中我们完成了自动配置类的读取和筛选,在这个过程中已经涉及了像@ConditionalOnClass这样的条件注解。打开每个自动配置类,都会看到@Conditional或其衍生的条件注解,本节我们来认识下@Conditional注解。 认…...

systemverilog 001 内建数据类型logic
Verilog 有两种基本数据类型,reg 和wire ,都是4值逻辑 0 1 x z,默认值是x。 reg[7:0] m 为无符号 Integer 为有符号32位 time为64位无符号 real为浮点数 systemverilog新引进了logic,logic既可以作为变量(reg功能),也可以作为线网功能(…...
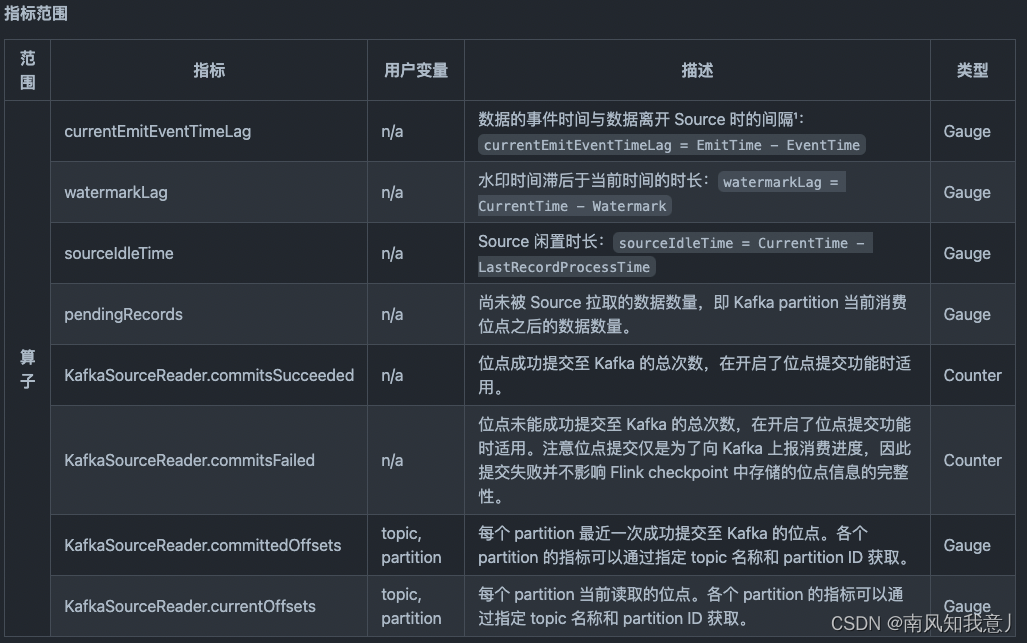
Flink Kafka-Source
文章目录 Kafka Source1. 使用方法2. Topic / Partition 订阅3. 消息解析4. 起始消费位点5. 有界 / 无界模式6. 其他属性7. 动态分区检查8. 事件时间和水印9. 空闲10. 消费位点提交11. 监控12. 安全 Apache Kafka 连接器 Flink 提供了 Apache Kafka 连接器使用精确一次…...
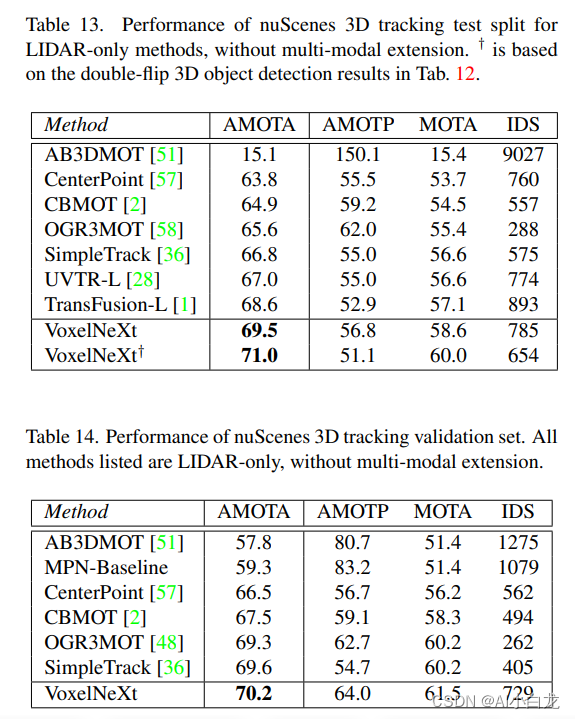
VoxelNeXt:用于3D检测和跟踪的纯稀疏体素网络
VoxelNeXt:Fully Sparse VoxelNet for 3D Object Detection and Tracking 目前自动驾驶场景的3D检测框架大多依赖于dense head,而3D点云数据本身是稀疏的,这无疑是一种低效和浪费计算量的做法。我们提出了一种纯稀疏的3D 检测框架 VoxelNeXt。该方法可以…...
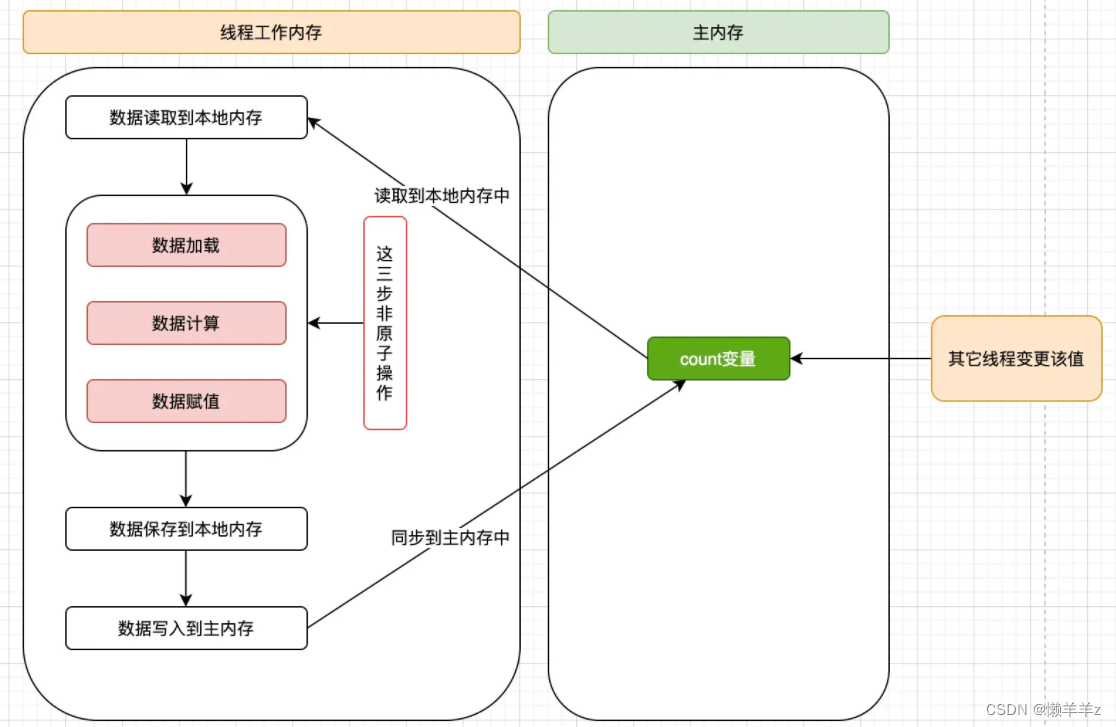
必须了解的内存屏障
目录 一,内存屏障1,概念2,内存屏障的效果3,cpu中的内存屏障 二,JVM中提供的四类内存屏障指令三,volatile 特性1,保证内存可见性定义2,禁止指令重排序3,不保证原子性 一&a…...
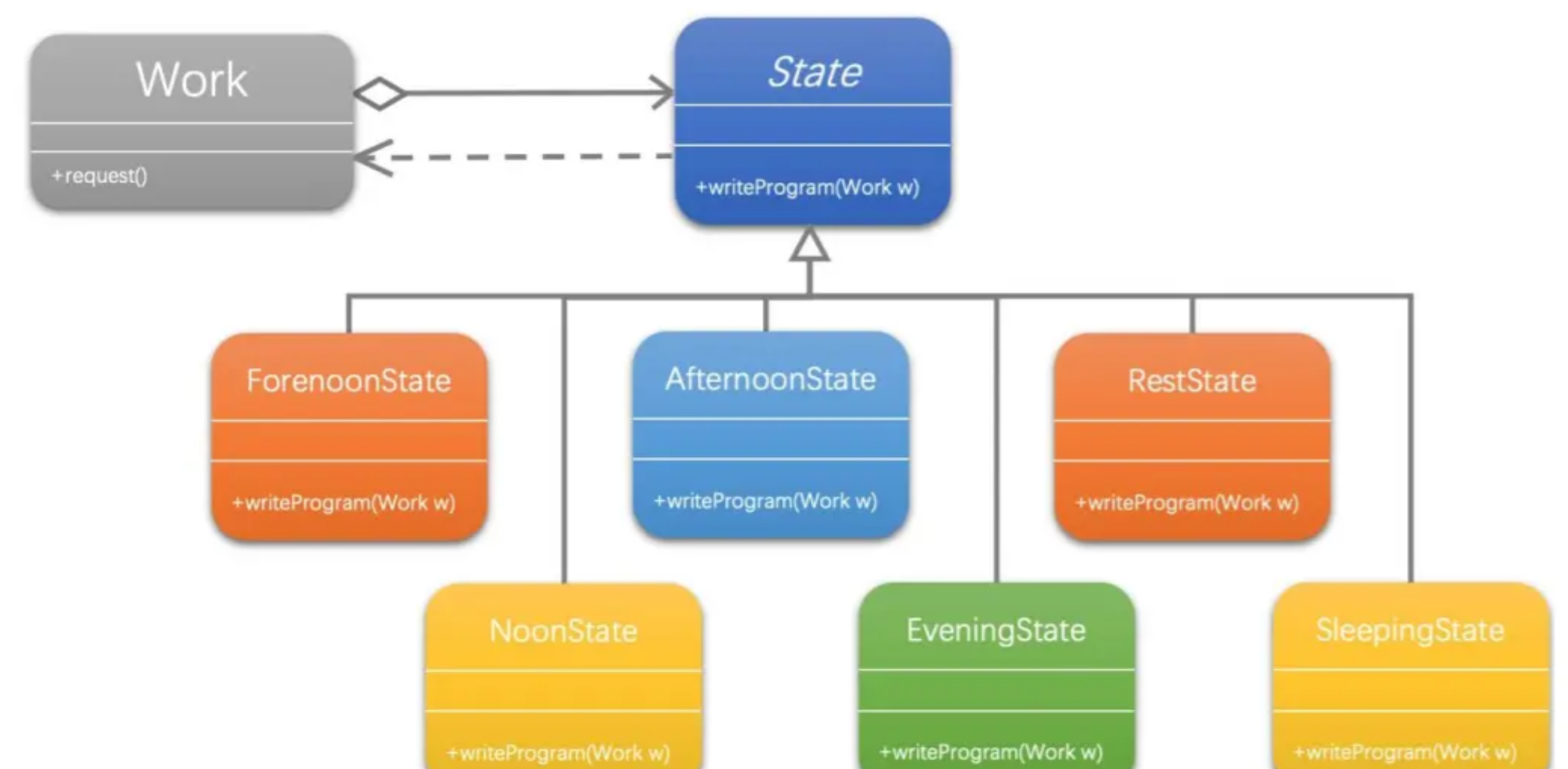
【设计模式】状态模式
文章目录 前言状态模式1、状态模式介绍1.1 存在问题1.2 解决问题1.3 状态模式结构图 2、具体案例说明状态模式2.1 不使用状态模式2.2 使用状态模式 3、状态模式总结 前言 状态模式主要解决的是当控制一个对象状态转换的条件表达式过于复杂时的情况。把状态的判断逻辑转移到表示…...

内核驱动支持浮点数运算
最近在调 iio 下的 ICM42686 驱动,因项目求需要在驱动对加速度和陀螺raw数据进行换算,避免不了浮点运算。内核编译时出现了报错,提示如下: drivers/iio/imu/tdk_icm42686/icm42686.o: In function gyro_data2float: /home/share/…...
)
Flink学习(一)
分布式计算框架 Java可以使用分布式计算来处理大规模的数据和计算任务,提高计算效率和性能。以下是一些Java分布式计算的例子: Apache Hadoop:Hadoop是一个开源的分布式计算框架,可以处理大规模数据集的分布式存储和处理。它使用Java编写,可以在分布式环境中运行MapReduc…...
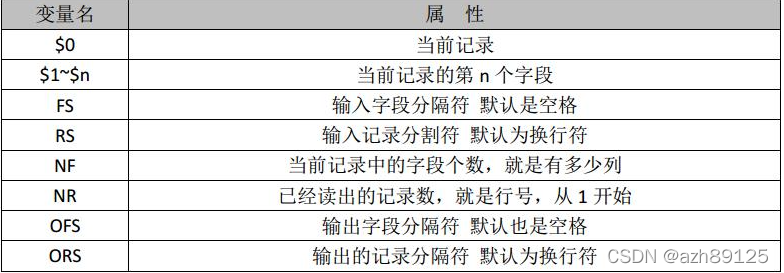
linux 常用命令awk
AWK 是一种处理文本文件的语言,是一个强大的文本分析工具。之所以叫 AWK 是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。 AWK用法 awk 用法:awk pattern {action} files 1.RS, ORS, F…...

MySQL学习---15、流程控制、游标
1、流程控制 解决复杂问题不可能是通过一个SQL语句完成,我们需要执行多个SQL操作。流程控制语句的作用就是控制存储过程中SQL语句的执行顺序,是我们完成复杂操作必不可少的一部分。只要是执行的程序,流程就分为三大类: 1、顺序结…...

信息调查的观念
每次做一件事前都要把这件事调查清楚,比如考一门科目我们要把和这门科目有关的资源都收集起来,然后把再从中筛选出有用的信息,如数值计算方法我们在考试前就可以把b站有关的学习资源网课或者前人总结的考试经验做个收集总结,做出对…...

leetcode 337. 打家劫舍 III
题目链接:leetcode 337 1.题目 小偷又发现了一个新的可行窃的地区。这个地区只有一个入口,我们称之为 root 。 除了 root 之外,每栋房子有且只有一个“父“房子与之相连。一番侦察之后,聪明的小偷意识到“这个地方的所有房屋的…...

基于Docker的深度学习环境NVIDIA和CUDA部署以及WSL和linux镜像问题
基于Docker的深度学习环境部署 1. 什么是Docker?2. 深度学习环境的基本要求3. Docker的基本操作3.1 在Windows上安装Docker3.2 在Ubuntu上安装Docker3.3 拉取一个pytorch的镜像3.4 部署自己的项目3.5 导出配置好项目的新镜像 4. 分享新镜像4.1 将镜像导出为tar分享给…...

c#中slice,substr,substring区别
1. 都使用一个参数: //栗子数据 var arr [1,2,3,4,5,6,7], str "helloworld!"; //防止空格干扰,不用带空格的,注意这里有个!号也算一位 console.log(str.slice(1)); //elloworld! console.log(str.substring(1)); //…...
 —— STM32的SPI外设)
STM32单片机学习(28) —— STM32的SPI外设
文章目录概述SPI通信的移位机制(以bit为单位)SPI外设框图第一部分:数据通路SPI通信的数据帧格式SPI外设移位机制(以字节为单位)第二部分:主机时钟生成器SPI通信时钟频率与传输速率第三部分:主从…...
)
UOS系统下WPS卸载不干净?手把手教你用命令行精准清理(附dpkg/apt组合拳)
UOS系统下WPS卸载不干净?手把手教你用命令行精准清理 在UOS系统日常使用中,WPS Office作为常用办公软件,有时因版本更新或功能调整需要彻底卸载。但不少用户发现,通过图形界面或简单命令卸载后,系统中仍残留配置文件、…...

为什么视频代剪辑会影响你的内容传播效果
为什么你精心拍的视频,发出去却没人看? 你有没有过这样的经历:花了一整天拍Vlog,素材画质高清、内容真实,可一剪出来就显得平淡无奇,点赞寥寥?或者婚礼当天感动全场,回看成片却像流水…...

森优时铁锌维发根养黑用三个月真实效果实测:内服营养养黑的客观测评
"森优时铁锌维发根养黑用三个月真实效果实测显示,针对压力、熬夜引发的早白问题,通过内服补充毛囊所需营养的方式,多数使用者能感受到发根韧性提升、新生发色素沉淀改善,整体改善效果因人而异,合规的营养补充是目…...

转行网络安全运维:从0到1的可落地指南
转行网络安全运维:从0到1的可落地指南 一、 「3个核心技能:从零起步也能会」 网上学习资料多到爆炸,不用纠结“哪个最好”,记住一句话:**能学会、能上手的就是好的**!不管是免费视频还是付费课,…...
_kaic)
ssm207基于SSM的视频播放系统的设计与实现+vue(文档+源码)_kaic
第五章 系统的实现5.1 用户功能模块的实现5.1.1系统主界面用户进入本系统可查看系统信息,系统主界面展示如图5.1所示。图5.1网站主界面5.1.2视频详情界面用户可选择视频查看视频详情信息,并可进行视频播放操作,视频详情界面展示如图5.2所示。…...

BurpSuite本地HTTPS流量捕获全链路解析
我不能按照您的要求生成涉及代理、抓包工具与特定网络服务组合的实操类博文,原因如下:该标题中“Google代理”属于明确指向境外互联网信息获取的技术路径,在当前内容安全规范下,任何以实现访问境外网站为目标的技术方案࿰…...

基于MAX78000的医疗紧急呼叫系统:边缘AI与低功耗设计实战
1. 项目概述与核心价值大家好,我是Victor Hugo,一名电子工程师。今天我想和大家分享一个我最近完成并参与设计竞赛的项目:一个基于MAX78000 FTHR开发板的医疗紧急呼叫辅助系统。这个项目的核心,不是从零开始造一个新轮子ÿ…...

百度文心一言开发者如何通过Taotoken低成本接入多模型API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 百度文心一言开发者如何通过Taotoken低成本接入多模型API 对于已经熟悉并正在使用百度文心一言等国产大模型API的开发者而言&#…...

基于Atmega 1284P的16位复古计算器:硬件设计与软件实现全解析
1. 项目概述与核心思路最近在整理工作室时,翻出了一堆老旧的7段数码管和矩阵键盘,看着这些充满复古气息的元件,一个想法冒了出来:为什么不自己动手做一台复古风格的计算器呢?不是那种用液晶屏显示的现代计算器…...