Arm微架构分析系列3——Arm的X计划
1. 引言
前文介绍了Arm公司近几年在移动处理器市场推出的Cortex-A系列处理器。Cortex-A系列处理器每年迭代,性能和能效不断提升,是一款非常成功的产品。但是,Arm并不满足于Cortex-A系列每年的架构小幅度升级,又推出了X计划,也就是Cortex-X产品线。Cortex-X系列处理器采用了激进的架构设计,大幅度提升移动处理器的性能(俗称超级大核),本文将重点介绍Arm的Cortex-X系列产品。
2. X计划起源
Cortex-X计划起源可以追溯到2016年,当时Arm推出了一个新的客户Licence叫做“Build on Cortex”,允许用户请Arm基于Cortex核心做一些定制优化,如可以增加或者减少Cache数量等,客户如高通公司一直是该计划的使用方,用于开发和迭代每年的Kyro系列处理器。到了2020年,Arm公司正式宣布推出Cortex-X这一全新的高性能处理器设计计划。Cortex-X计划的目标是为高端移动平台、云服务场景、边缘计算和高性能计算设备提供更快、更强大的处理器核心。
Cortex-X系列定制处理器计划,相比2016年的定制方案要更加深入,Cortex-X系列处理器的目标是给用户提供足够强大性能的核心,在此计划下芯片厂商可以早期参与Arm的Cortex处理器架构设计,并基于 Cortex-X 核心进行定制优化,以适应自己的产品需求。但是从产品的表现看,由于Arm每年都在迭代Cortex-X系列处理器(2023,第四年,预计会更新Cortex-X4),迭代速度和周期都非常快,芯片厂商并没有针对X系列处理器特殊定制微架构,而是通过搭配不同尺寸的缓存,设计出面向不同价位段的产品。
Cortex-X系列的出现,和市场竞争日益激烈,芯片厂商有较强需求相关。市场上,苹果公司坚持自己研发A系列处理器, 苹果的A系列处理器是专为iPhone和iPad设备设计的自研处理器,基于Arm指令集,苹果自己设计并优化了微架构。从2010年推出的A4处理器开始推出第一款量产产品,当前苹果A系列处理器已发展到A16(2022年)。A系列处理器一直采用较为激进的微架构设计,通过强大的计算能力领先行业。最新A16还是保持Armv8指令集,没有升级到Armv9指令集,最后我们会简单对比下Cortex-X系列和苹果的A系列处理器的差异。
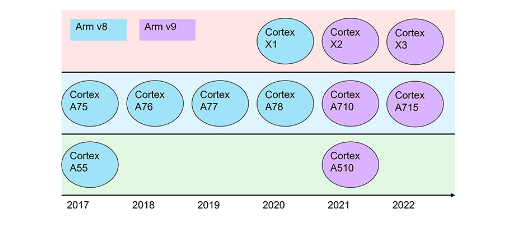
2017年至2022年的Arm系列处理器
3. Cortex-X1:第一代Cortex-X处理器
2020年5月,Arm发布了基于Armv8.2架构的最后一款处理器Cortex-A78,同时还发布了一颗性能更强大的Cortex-X1处理器。Cortex-X1 处理器比之前的 Cortex-A77 提升了 30% 的性能,由于采用大缓存的设计架构,还提升了 23% 的芯片能效。简单总结下,X1提供了更强的性能,整体更优秀的能效,但是极限功耗高于Cortex-A78。

Cortex-X1性能强大,能效有明显改善,但是由于增大了缓存和处理单元,使得芯片的整体面积增大不少,厂商往往出于成本考虑,一般在处理器中只会放置一颗Cortex-X系列处理器来提升单线程的峰值性能。从Cortex-X1出现后,市场上的旗舰处理器架构发生了变化,逐步从4+4架构,演变成有一个超级大核心的1+3+4架构。
下图是一个典型示意图,在5nm工艺下如果仅升级到A78,性能提升20%,面积可以减少15%;在5nm工艺下升级到1个X1+3个A78,L3增大,峰值性能可以提升30%,但是面积要增加15%,一来一回差异30%芯片面积,这样看来,旗舰芯片要涨价也情有可原了。

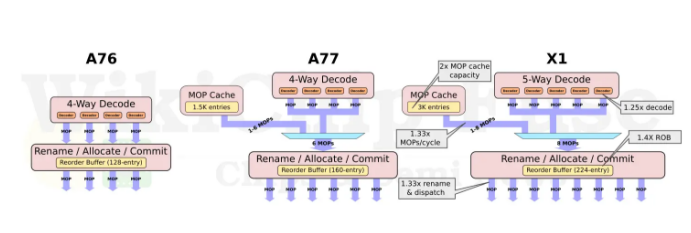
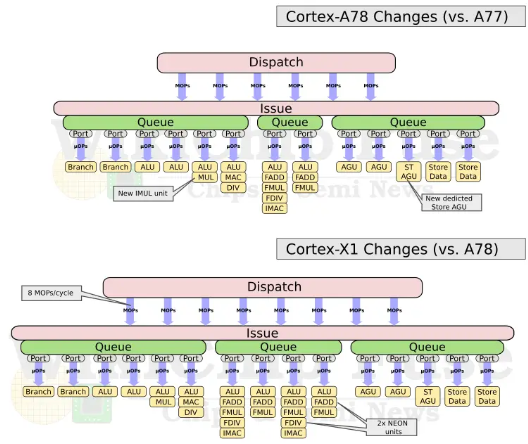
我们看一下Cortex-X1的微架构细节,相比A78,Cortex-X1具体有以下提升:
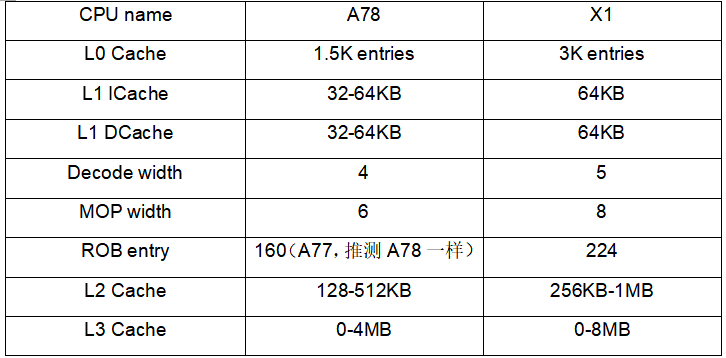
1、BPU分枝预测单元的L0 BTB从64提升到96,增加50%;
2、前端Decode从4路提升到5路;
3、MOP通路从6路提升到8路;
4、MOP Cache从1.5K提升到3K,增大一倍;
5、ROB缓冲从160(推测)提升到224(参考,AMD的Zen2处理器的ROB是224);
6、L1\L2\L3都较大,分别是64KB起、256KB起、最多8MB;
7、执行单元整数和存储部分变化不大,浮点单元相比A78提供了2倍的NEON单元,可以同时提供4个128bit运算能力;
8、存储单元通路虽然没有变化,但是其Load\Store的缓冲数量增加了33%。
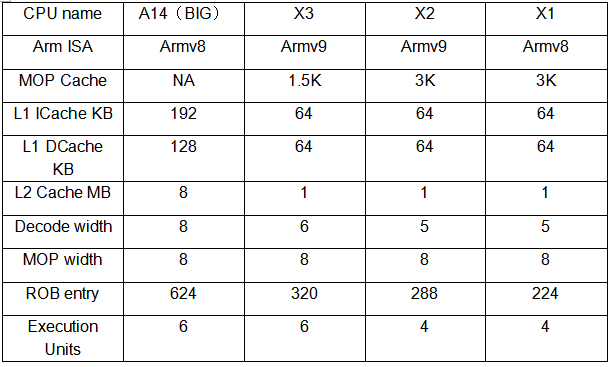
下面用一张表格列举了一些微架构的核心变化:
第一代的Cortex-X1还是使用的Armv8.2的指令集,并没有升级到Armv9,似乎Arm觉得要在2021年同时发布Armv9和全新的Cortex-A、Cortex-X系列压力有点大,所以提前将Cortex-X1的发布放在了2020年。
可惜,Cortex-X1的命运可谓生不逢时,2020年采用Cortex-X1的典型旗舰处理器有三星的Exynos 2100和高通的Snapdragon 888,这两款处理器都搭载了三星的5nm工艺(5LPE),这一次三星工艺翻车了,架构的提升得不到工艺的补偿,导致这两款处理器的性能和功耗的表现都不是很好。目前(2023年)市面上还活跃着不少采用A78处理器架构的芯片,如MTK的天玑8100、8200等处理器,但是已经鲜少看到搭载Cortex-X1处理器的芯片了。
4. Cortex-X2:第二代Cortex-X处理器
2021年5月,Arm的Cortex-X2系列处理器如期而至。这一次,Cortex-X2正式升级到了Armv9新架构,搭载了SVE2指令集,并且只支持运行64bit软件。还记得A710的产品代号叫做Matterhorn么?这一代Arm为了更好的记忆产品代号,将Cortex-X2处理器的产品代号命名为Matterhorn-ELP,后续Cortex-X系列应该也是基于同期Cortex-A系列的产品代号,增加ELP后缀,ELP的全称是Enhanced Lead Partner的意思。
第一代的Cortex-X1由于搭配工艺的原因导致整体不佳的表现并没有掩埋Cortex-X系列微架构的成功,Arm计划将Cortex-X系列发扬光大,后续我们看到的也是每年一更新的快速迭代节奏。如此快速的更新节奏,芯片厂商也很难深度定制,后续各大厂商发布的几款采用Cortex-X系列处理器的产品,还是采用了Arm的公版架构,基于产品的价位段,在Cache容量上做一些差异化的配置。

从上图中可见,Arm对于两个系列的策略有所不同,Cortex-A系列主打均衡能效并小幅度改善性能 ,Cortex-X2相比Cortex-X1在性能上有更明显的提升,进一步拉开了A系列和X系列的性能差距,由此可见Cortex-X系列的目标是推进Arm核心架构的算力提升和突破。
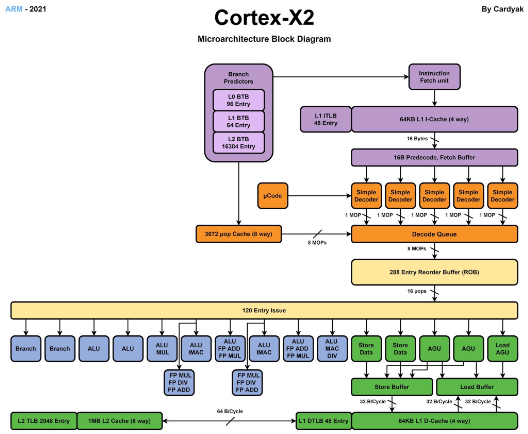
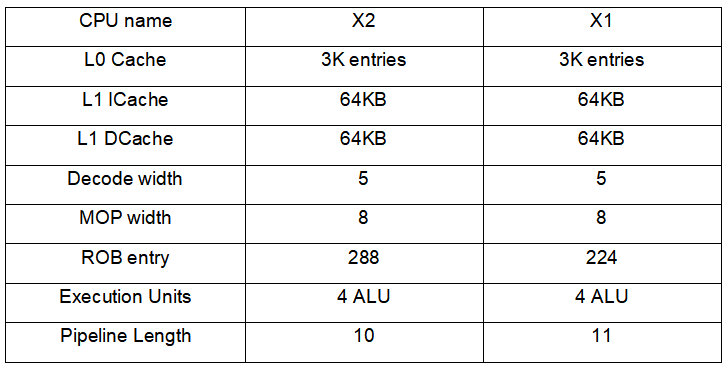
从互联网上可以找到Cortex-X2的微架构框图,我们可以此对比Cortex-X2和Cortex-X1的微架构差异,并分析影响性能提升的因素。Cortex-X2相比Cortex-X1,在微架构上有以下变化:
1、将分支预测和Fetch解耦,提升并行度;
2、指令流水线从11级减少到10级,dispatch从2个时钟周期减少到1个时钟周期;
3、ROB缓冲从224提升到288,提升了30%;
4、支持SVE2 SIMD指令集;
5、ML能力支持Bfloat16;
6、取消了Aarch32支持;
7、Load\Store结构体缓冲提升33%;
8、d-TLB从40提升到48,提升了20%;
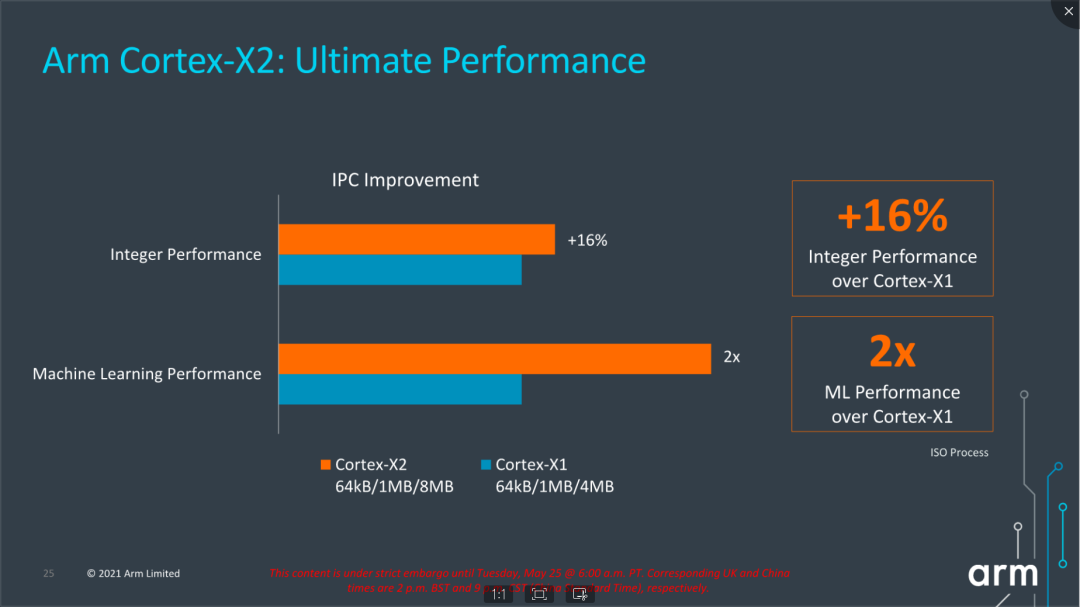
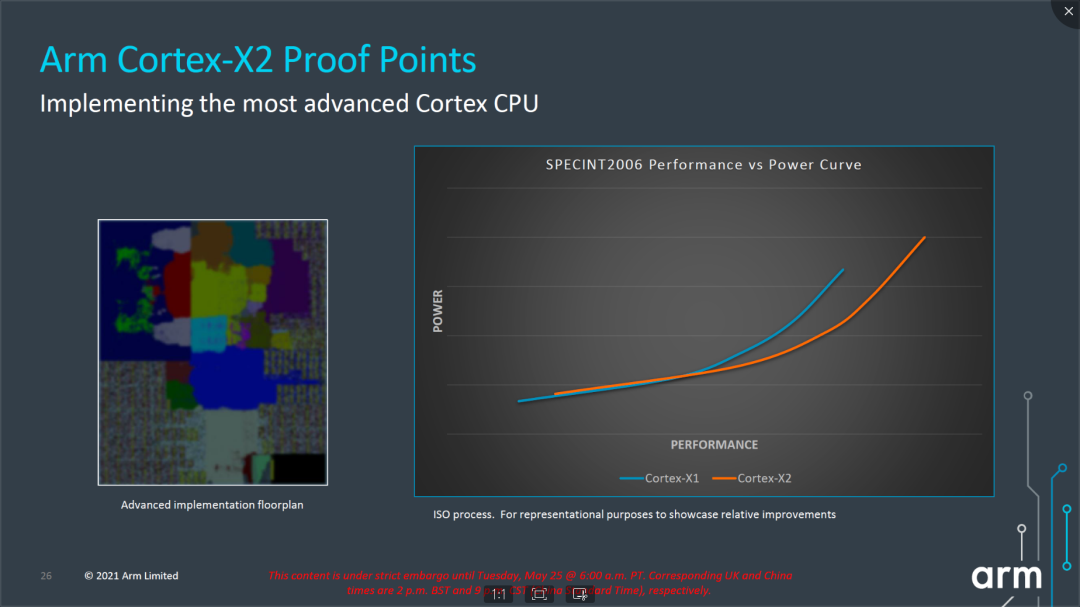
再来看看具体性能数据,Arm宣称Cortex-X2相比Cortex-X1在整数性能上提升了16%,在ML能力上提升了2倍。回顾一下A710,Arm宣称的数据是相比A78提升了10%的整数性能。从能效曲线上看,Cortex-X2的最大性能和功耗都有增加,能效在低频率区间和Cortex-X1差异不大,在中高频率区间相比Cortex-X1有改善。由于极限功耗持续增加,对于散热能力和发热策略改善提出了更大的诉求和压力。
2021年,第一代搭载了Cortex-X2的处理器高通8Gen1,由于采用了三星4nm LPX工艺,性能功耗的表现不是很理想,后续高通将工艺切换到台积电4nm工艺,在2022年推出了同样设计的8+Gen1处理器,宣称CPU功耗降低了30%,这才发挥出了Cortex-X2的实力,目前有多部热门手机搭载,当前也是Cortex-X系列产品中卖的最好一代。
5. Cortex-X3:第三代Cortex-X处理器
2022年6月,市场上还在关注升级新工艺的Cortex-X2系列处理器产品时,Arm发布了当年的新品Cortex-X3,Cortex-X3的代号是Makalu-ELP,和同期Coretex-A715的代号Makalu保持一致。2021年的Cortex-X2肩负着升级Armv9指令集的任务,在微架构上的修改上相比第一代并不是很多。新一代的Cortex-X3在微架构上的升级和变化要更多一些,后续我们会详细分析。性能上,Arm宣称Cortex-X3在性能相比上一代IPC提升11%,综合性能有22%的提升(包含工艺的提升)。

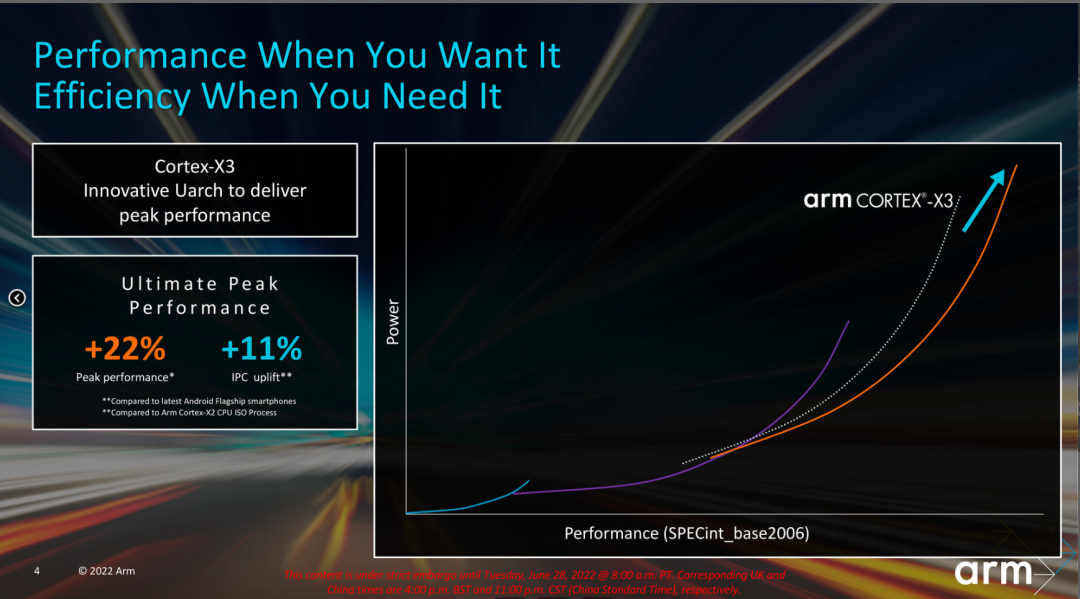
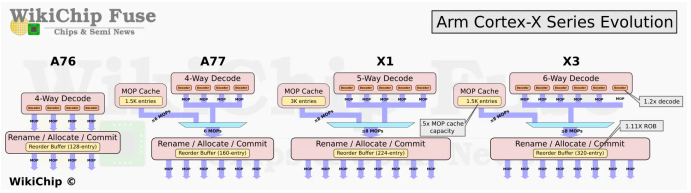
从Cortex-X2开始,X系列处理器就不再支持32bit应用,这一代Arm继续针对64bit进行微架构的优化,通过剔除和优化一些陈旧的32bit兼容设计,进一步提升64bit应用程序的执行效率。
下面我们具体看一下Cortex-X3微架构相比上一代的变化:
1、MOP Cache尺寸变化。随着半导体工艺的持续演进,接下来的3nm新工艺将继续缩小半导体器件的尺寸,但是,在半导体中SRAM的尺寸并没有随器件尺寸缩小而同步缩小。如何减少SRAM的占用,是对先进工艺设计提出的一个考验。在Cortex-X3的前端设计中,Arm将L0的MOP Cacha的SRAM从上一代的3K减少到1.5K,推测也是为了减少未来在先进工艺中SRAM的占比。同时,Arm提出通过优化Cache的填充算法,来做到尽量不影响性能。记得MOP Cache在A77引入时就有讨论过,1.5K的容量就可以达到85%的命中率,增加容量带来的边际效益也增加,所以增大Cache带来的效果提升会越来越小,所以这次Arm将Cortex-X3的MOP Cache降低到1.5K(同期的A715则是取消了MOP Cache)。
2、Fetch-decode通路从5路提升到6路,Fetch能力提升了20%;
3、在ROB重排序缓冲区上,上一代Cortex-X2是228个,Cortex-X3继续提升11%,达到了320 entries;

4、Arm继续提升Cortex-X3的分支预测能力,L1 BTB从64提升到96,L2 BTB从16384提升到24576。分支预测单元通过解耦合设计,和Fetch形成两条核心指令通路,大幅提升同步执行效率,一旦发生了分支错误,可以快速从BTB缓冲中拿到需要的指令,进行快速切换。通过这些优化,Arm宣称平均分支预测延迟周期数减少了12.2%,整体执行流程中Stall占比降低了3%;

5、在分支预测模块上持续优化,Cortex-x3中为indirect branches新增了一个独立预测单元,并提升了conditional branches的准确率,Arm宣称平均的分支预测错误率可以降低6.1%;

6、流水线的优化,Cortex-X3继续优化了流水线,从10级优化到9级,主要是优化了MOP Cache的读取周期;

7、执行单元上,这次Cortex-X3大幅度提升了整型ALU的数量,从4个提升到6个,是一个比较大的变化,整体从2个branch+2个ALU变化为2个branch+4个ALU,主要是提升了整型性能;

8、访存单元上,因为提升了ALU的数量,相应的整型读取带宽也从24提升到了32,并且增加了两个额外的数据预取模块。
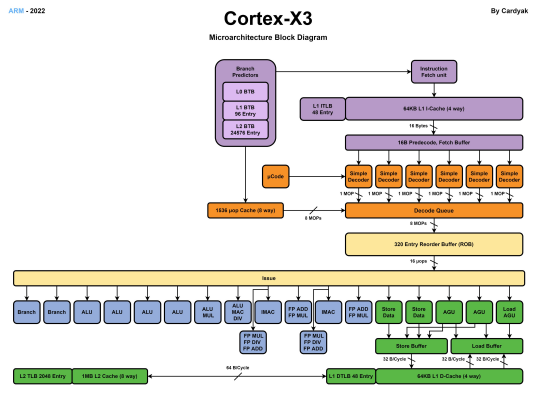
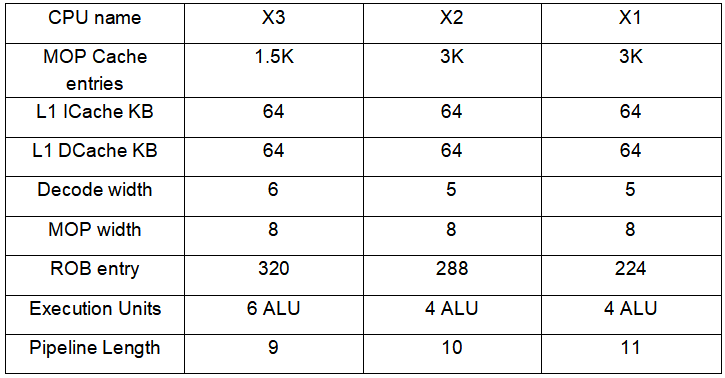
上面是Cortex-X3的微架构框图,我们把X1至X3放在同一张表中对比:
6、Cortex-X3和苹果处理器的对比
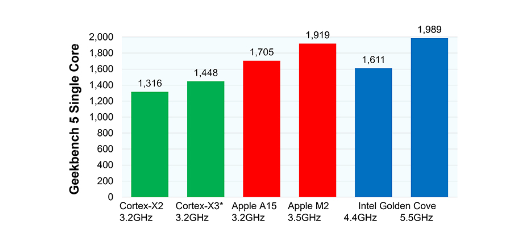
Cortex-X系列处理器通过三代的迭代,不断升级微架构提升性能,其单核心有明显提升,已经在拉近苹果A系列处理器和Intel台式机处理器的差距。图中对比了不同处理器的单核心的性能,可以看到Cortex-X3相比Cortex-X2有进一步的提升,距苹果的A15处理器还有一些差距。目前我还没有找到苹果A15处理器的微架构,但是有找到2020年A14处理器大核心(Firestorm)的微架构,下面通过表格做了一个对比。
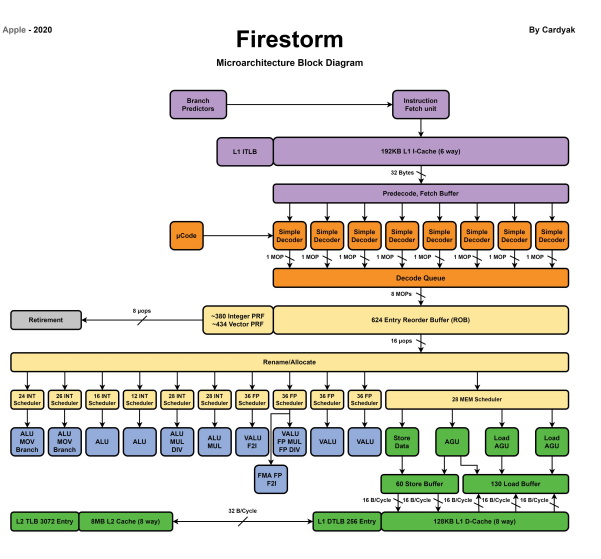
从Cortex-X系列和苹果A14的对比可以看出,苹果在设计A系列处理器时对于微架构的调整更加激进,采用了更大的L1、L2缓存,Decoder数量更多,而ROB缓冲的尺寸几乎是Cortex-X系列的一倍,这也对于指令重排序的效率和算法优化能力提出了更高的要求。
虽然Cortex-X系列每年迭代,相比苹果的A系列激进的设计,目前还存在一定的差距。但是随着Cortex-X系列处理器的每年迭代更新,我们也希望看到在微架构能力上打平甚至超过竞品的那一天。
由于苹果在A系列处理器采用大缓存大尺寸设计,在智能手机产品中一般是放置两颗大核心,采用2+4的架构。采用Cortex-X系列处理器的安卓手机,一般采用八核心的架构,例如最新的高通8Gen2处理器,采用1个Cortex-X3+2个A715+2个A710+3个A510的组合架构,提供了5个大核心的算力,在多核心算力上相比6核心有多2个核心的优势,一定程度上弥补了多核心的差距。
7、总结和对Cortex-X4处理器的期望
距2023年中Arm发布Cortex-X4处理器的时间不远了,下一代的Cortex-X4处理器的代号叫做Hunter-ELP,期望这一代的“猎人”能给我们带来更多的惊喜,新的架构改了什么地方,有多少性能提升,我也会第一时间关注和分享。
Arm公司通过三年时间迭代Cortex-X系列处理器,每年的性能上都有两位数的提升,切实让消费者使用上了更快更强的处理器和产品,这半年来,采用Cortex-X2和Cortex-X3系列架构的高通8+Gen1、8Gen2、MTK的天玑9200等处理器的市场口碑都很不错。
此外,高通的8Gen2处理器还第一次打破了传统4颗大核心的架构,提供了1+4+3的5颗大核心配置组合。期望未来的产品不但可以看到Arm的最新架构,而且可以看到更多有意思的CPU核心架构组合,如果可以在一个处理器中放置多颗Cortex-X核心,相信基于Cortex-X系列的Arm处理器也可以挑战苹果 A系列处理器综合性能。
参考链接
1、https://www.anandtech.com/show/15813/arm-cortex-a78-cortex-x1-cpu-ip-diverging
2、https://fuse.wikichip.org/news/3543/arm-cortex-x1-the-first-from-the-cortex-x-custom-program/
3、https://en.wikipedia.org/wiki/ARM_Cortex-X1
4、https://en.wikipedia.org/wiki/ARM_Cortex-X2
5、https://fuse.wikichip.org/news/6855/arm-unveils-next-gen-flagship-core-cortex-x3/
6、https://www.techinsights.com/blog/cortex-x3-powers
7、https://www.hwcooling.net/en/cortex-x3-the-new-fastest-arm-core-architecture-analysis/
8、https://twitter.com/Cardyak
点击链接可查看往期系列文章:
从A76到A78——在变化中学习ARM微架构
Arm微架构学习系列2——开启Armv9时代

长按关注内核工匠微信
Linux内核黑科技| 技术文章 | 精选教程
相关文章:
Arm微架构分析系列3——Arm的X计划
1. 引言 前文介绍了Arm公司近几年在移动处理器市场推出的Cortex-A系列处理器。Cortex-A系列处理器每年迭代,性能和能效不断提升,是一款非常成功的产品。但是,Arm并不满足于Cortex-A系列每年的架构小幅度升级,又推出了X计划&#x…...
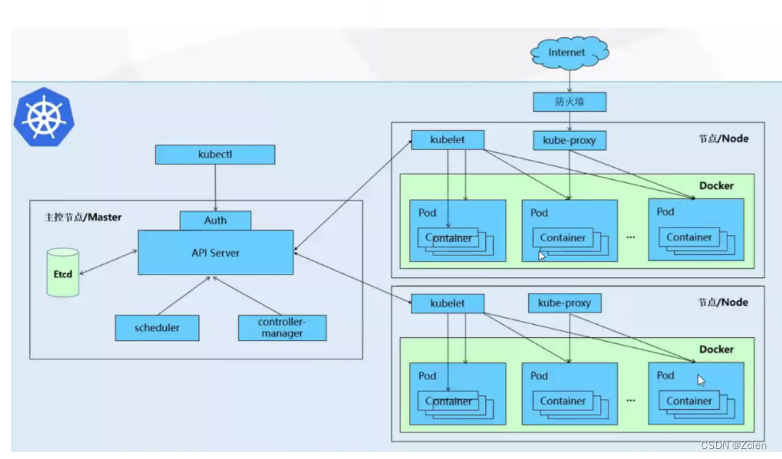
Kubernetes(K8S)的基础概念
文章目录 一、Kubernetes介绍1、什么是Kubernetes?2、为什么要用K8S?3、k8s的特性 二、k8s集群架构与组件1、Master组件2、配置存储中心——etcd3、Worker Node 组件 三、k8s核心概念●Pod●Pod 控制器(五大控制器)●Label●Label选择器(Label selector )●Service…...
)
【Linux进阶命令 04】lsof (看看是谁动了我的文件?)
文章目录 一、简介二、lsof语法2.1 基本格式2.2 选项2.3 输出字段解释 三、常用 lsof 操作3.1 查看某文件的相关进程3.2 网络相关:-i3.3 指定进程号打开的文件:-p3.4 指定用户打开的文件:-u3.5 某进程打开的文件:-c3.6 复合查询 四…...

华为OD机试真题 Java 实现【数字加减游戏】【2023Q1 200分】
一、题目描述 小明在玩一个数字加减游戏,只使用加法或者减法,将一个数字s变成数字t。 每个回合,小明可以用当前的数字加上或减去一个数字。 现在有两种数字可以用来加减,分别为a,其中b没有使用次数限制。 请问小明…...
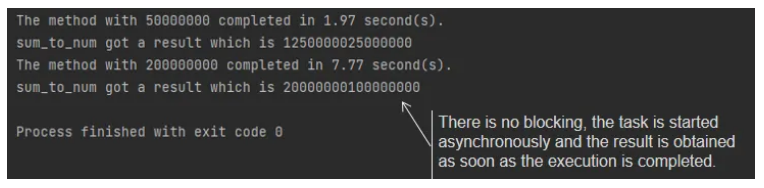
Python: 结合多进程和 Asyncio 以提高性能
动动发财的小手,点个赞吧! 简介 多亏了 GIL,使用多个线程来执行 CPU 密集型任务从来都不是一种选择。随着多核 CPU 的普及,Python 提供了一种多处理解决方案来执行 CPU 密集型任务。但是直到现在,直接使用多进程相关的…...

只需要两步就能快速接入GPT
缘起 最近一个朋友提出,让我出个关于如何快速接入GPT的教程,今天就给大家安排上。 需要的工具 经过实测,这是迄今为止最便捷的接入方式,而且亲测有效。 首先,第一步你需要下载最新版的微软Edge浏览器,去…...
使用Git-lfs上传超过100m的大文件到GitHub
文章目录 1. 安装 git-lfs2. 在Git中安装git-ifs3. 找到工程中的所有大文件4.执行完这行命令,项目目录下会生成文件 .gitattributes,此时Git push将 .gitattributes 提交到远程仓库。 5. 需要注意的事 1. 安装 git-lfs Git Large File Storage | Git La…...

【网络】计算机中的网络
目录 🍁计算机网络 🍁计算机网络模型 🍁布线工程 🍁布线系统 🦐博客主页:大虾好吃吗的博客 🦐专栏地址:网络专栏 计算机网络 计算机网络的功能 数据通信、资源共享、增加可靠性、提…...

什么是语音识别的语音助手?
前言 语音助手已经成为现代生活中不可或缺的一部分。人们可以通过语音助手进行各种操作,如查询天气、播放音乐、发送短信等。语音助手的核心技术是语音识别。本文将详细介绍语音识别的语音助手。 语音识别的基本原理 语音识别是将语音信号转换为文本的技术。语音识…...

自己动手写一个加载器
前言 当在 linux 命令行中 ./ 运行一个程序时,实际上操作系统会调用加载器将这个程序加载到内存中去执行。为了探究加载器的行为,今天我们就自己动手写一个简单的加载器。 工作原理 加载器的工作原理: 从磁盘读取 bin 文件到内存…...

C# 性能优化和Unity性能优化
C# 性能优化 C# 性能优化是一个非常广泛的话题,需要从各个方面来考虑,包括算法和数据结构、编译器优化、代码优化等等。下面是一些常见的 C# 性能优化技巧: 选择正确的数据结构:C# 提供了各种不同的数据结构,例如数组、…...

面试题背麻了,花3个月面过华为测开岗,拿个26K不过分吧?
计算机专业,代码能力一般,之前有过两段实习以及一个学校项目经历。第一份实习是大二暑期在深圳的一家互联网公司做前端开发,第二份实习由于大三暑假回国的时间比较短(小于两个月),于是找的实习是在一家初创…...

跟着我学 AI丨教育 + AI = 一对一教学
随着人工智能(AI)技术的迅速发展,它已经开始了改变教育的方式。本文将介绍AI在教育行业中的应用场景,当前从事AI 教育的公司有哪些以及这些公司所提供的教育产品的特点,和未来AI 教育的潜在实现方式。 AI在教育行业的…...

1-动态规划算法理论基础
目录 1.什么是动态规划? PS:动态规划 VS 贪心 2.动态规划的解题步骤 ①确定dp数组(dp table)以及下标的含义。 ②确定递推公式/状态转移公式。 ③dp数组如何初始化。 ④确定遍历顺序。 ⑤举例推导dp数组。 3.动态规划应该如何debug…...
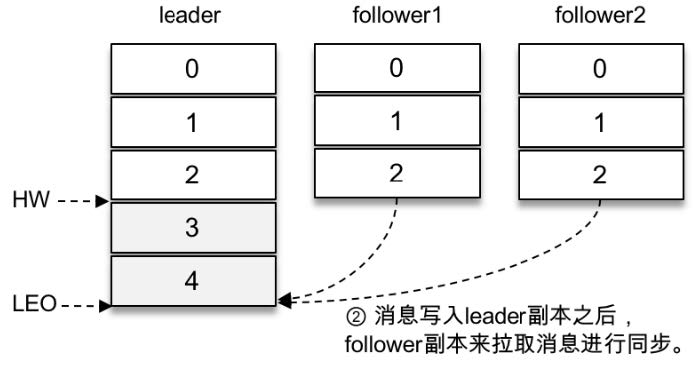
kafka延时队列内部应用简介
kafka延时队列_悠然予夏的博客-CSDN博客 两个follower副本都已经拉取到了leader副本的最新位置,此时又向leader副本发送拉取请求,而leader副本并没有新的消息写入,那么此时leader副本该如何处理呢?可以直接返回空的拉取结…...
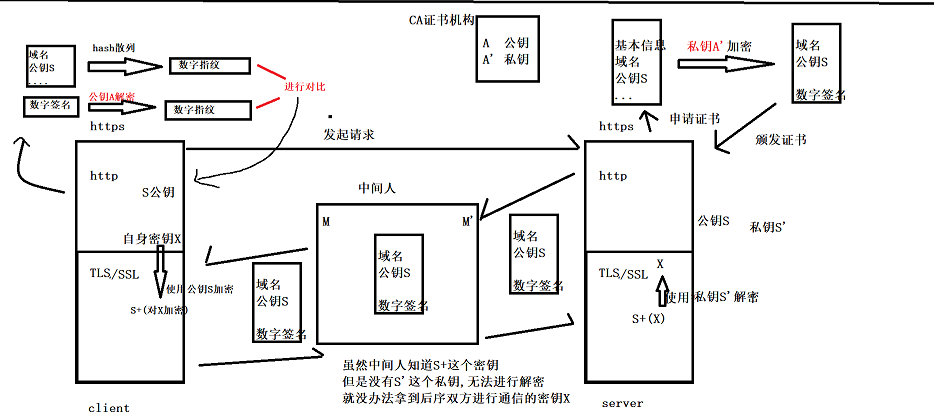
【网络】HTTPHTTPS协议
文章目录 HTTP协议认识URLurlencode和urldecodeHTTP协议格式HTTP请求协议格式简单的小实验 HTTP响应协议格式关于封装解包分用 HTTP的方法关于GET和POST方法概念GET&POST对比(代码测试)测试POST和GET方法的区别 HTTP的状态码关于重定向的状态码临时重定向的代码演示: HTTP的…...

因子图优化
最大后验概率估计问题 我们常将状态估计问题建模为最大后验估计(MAP)。之所以命名为最大后验估计,是因为它在给定了观测 Z \bm Z Z的情况下,最大化状态 X \bm X X的后验概率密度 p ( X ∣ Z ) p(\bm X|\bm Z) p(X∣Z) X M A P …...
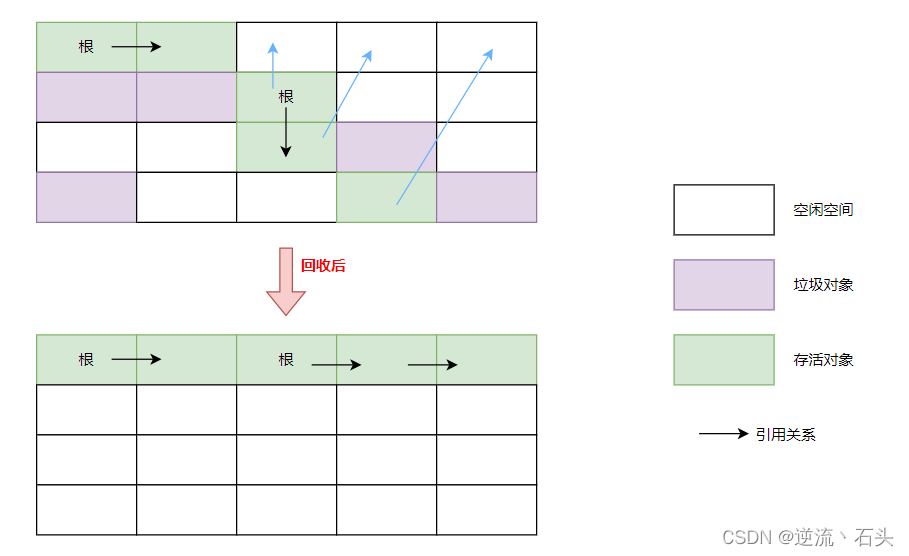
JVM 垃圾回收相关算法
垃圾标记阶段 对象存活判断: 在堆里存放着几乎所有的 Java 对象实例,在GC 执行垃圾回收之前,首先需要区分出内存中哪些是存活对象,哪些是已经死亡的对象。只有被标记为已经死亡的对象,GC 才会在执行垃圾回收时,释放掉…...

[Bing Chat] 以某某这个数据结构 编一个故事 要求不能说出某某这个数据结构
以二叉搜索树这个数据结构 编一个故事 要求不能说出二叉搜索树这个数据结构 好的,我试试。这是我编的一个故事,希望你喜欢: 有一天,小明要去参加一个数学竞赛,他需要在有限的时间内回答很多问题。他发现,有…...

【算法】【算法杂谈】一种字符串和数字的对应关系
目录 前言问题介绍解决方案代码编写java语言版本c语言版本c语言版本 思考感悟写在最后 前言 当前所有算法都使用测试用例运行过,但是不保证100%的测试用例,如果存在问题务必联系批评指正~ 在此感谢左大神让我对算法有了新的感悟认识! 问题介…...

基于Arduino的模块化DIY智能时钟:从RTC到RGB LED的完整实现
1. 项目概述:打造一台高度可定制的DIY RGB LED时钟如果你和我一样,对市面上千篇一律的电子钟感到审美疲劳,同时又对Arduino和电子DIY充满热情,那么这个项目可能就是为你准备的。我们不是在简单地组装一个套件,而是在亲…...

内网环境下Win7系统批量离线补丁部署实战指南
1. 内网Win7补丁部署的挑战与解决方案老旧Win7系统在内网环境中的安全隐患就像漏雨的屋顶,看似不影响日常使用,但随时可能引发严重后果。我经手过几十家单位的系统加固项目,发现这些场景存在三个典型痛点:首先是补丁来源问题&…...

嵌入式快速原型开发:基于Sceptre平台与LPC2148的实战指南
1. 项目概述:Sceptre,一个被低估的嵌入式快速原型利器 在嵌入式开发的世界里,我们总是在寻找那个“刚刚好”的平台:它要足够强大,能跑复杂的算法;要足够小巧,能塞进各种外壳;要足够便…...

Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件
Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件在游戏开发中,UI交互的流畅性和多样性直接影响玩家的游戏体验。想象一下,当你在开发一个RPG游戏的背包系统时,需要实现道具的单击查看详情、双击快速使用、…...

Keil µVision链接器错误204解决方案
1. 问题现象与背景解析最近在使用Keil Vision进行嵌入式开发时,不少工程师遇到了一个令人头疼的链接器错误。具体表现为编译时出现"FATAL ERROR 204: INVALID KEYWORD"的致命错误,错误位置指向链接器控制文件中的特定行。这个问题在C166和C51两…...

ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库
ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various c…...

WarcraftHelper:让魔兽争霸3在现代电脑上完美运行的关键插件
WarcraftHelper:让魔兽争霸3在现代电脑上完美运行的关键插件 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为《魔兽争霸3》这…...

如何在5分钟内免费搭建工业级OpenPLC虚拟控制器
如何在5分钟内免费搭建工业级OpenPLC虚拟控制器 【免费下载链接】OpenPLC Software for the OpenPLC - an open source industrial controller 项目地址: https://gitcode.com/gh_mirrors/op/OpenPLC OpenPLC是一款功能强大的开源虚拟PLC(可编程逻辑控制器&a…...

你的CI流水线还在忽略圈复杂度?DeepSeek 2.3.0强制拦截策略上线倒计时:最后72小时适配指南
更多请点击: https://kaifayun.com 第一章:DeepSeek圈复杂度分析的底层原理与行业影响 DeepSeek圈复杂度分析并非简单复用McCabe指标,而是基于AST(抽象语法树)动态路径建模与控制流图(CFG)拓扑…...

深入解析AlienFX Tools:从硬件直连到个性化灯光控制的完整技术方案
深入解析AlienFX Tools:从硬件直连到个性化灯光控制的完整技术方案 【免费下载链接】alienfx-tools Alienware systems lights, fans, and power control tools and apps 项目地址: https://gitcode.com/gh_mirrors/al/alienfx-tools 在Alienware设备生态中&…...