【spark】
实验5 Spark Structured Streaming编程实践
实验内容和要求
0.结构化流练习任务
0.1 讲义文件源-json数据任务。按照讲义中json数据的生成及分析,复现实验,并适当分析。
- (1)创建程序生成JSON格式的File源测试数据
import osimport shutilimport randomimport time
TEST_DATA_TEMP_DIR = '/tmp/'
TEST_DATA_DIR = '/tmp/testdata/'ACTION_DEF = ['login', 'logout', 'purchase']
DISTRICT_DEF = ['fujian', 'beijing', 'shanghai', 'guangzhou']
JSON_LINE_PATTERN = '{{"eventTime": {}, "action": "{}", "district": "{}"}}\n‘# 测试的环境搭建,判断文件夹是否存在,如果存在则删除旧数据,并建立文件夹
def test_setUp():if os.path.exists(TEST_DATA_DIR):shutil.rmtree(TEST_DATA_DIR, ignore_errors=True)os.mkdir(TEST_DATA_DIR)
# 测试环境的恢复,对文件夹进行清理
def test_tearDown():if os.path.exists(TEST_DATA_DIR):shutil.rmtree(TEST_DATA_DIR, ignore_errors=True)# 生成测试文件
def write_and_move(filename, data):with open(TEST_DATA_TEMP_DIR + filename,"wt", encoding="utf-8") as f:f.write(data)shutil.move(TEST_DATA_TEMP_DIR + filename,TEST_DATA_DIR + filename)if __name__ == "__main__":test_setUp()# 这里生成200个文件for i in range(200):filename = 'e-mall-{}.json'.format(i)content = ''rndcount = list(range(100))random.shuffle(rndcount)for _ in rndcount:content += JSON_LINE_PATTERN.format(str(int(time.time())),random.choice(ACTION_DEF),random .choice(DISTRICT_DEF))write_and_move(filename, content)time.sleep(1)test_tearDown()
- (2)创建程序对数据进行统计
# 导入需要用到的模块
import os
import shutil
from pprint import pprintfrom pyspark.sql import SparkSession
from pyspark.sql.functions import window, asc
from pyspark.sql.types import StructType, StructField
from pyspark.sql.types import TimestampType, StringType
# 定义JSON文件的路径常量(此为本地路径)
TEST_DATA_DIR_SPARK = '/tmp/testdata/'
if __name__ == "__main__":# 定义模式,为时间戳类型的eventTime、字符串类型的操作和省份组成schema = StructType([StructField("eventTime", TimestampType(), True),StructField("action", StringType(), True),StructField("district", StringType(), True)])spark = SparkSession \.builder \.appName("StructuredEMallPurchaseCount") \.getOrCreate()spark.sparkContext.setLogLevel('WARN')lines = spark \.readStream \.format("json") \.schema(schema) \.option("maxFilesPerTrigger", 100) \.load(TEST_DATA_DIR_SPARK)# 定义窗口windowDuration = '1 minutes'windowedCounts = lines \.filter("action = 'purchase'") \.groupBy('district', window('eventTime', windowDuration)) \.count() \.sort(asc('window')) query = windowedCounts \.writeStream \.outputMode("complete") \.format("console") \.option('truncate', 'false') \.trigger(processingTime="10 seconds") \.start()query.awaitTermination()- (3)测试运行程序
0.2 讲义kafka源,2字母单词分析任务按照讲义要求,复现kafka源实验。
- 1.启动Kafka
- 在Linux系统中新建一个终端(记作“Zookeeper终端”),输入下面命令启动Zookeeper服务:
cd /usr/local/kafkabin/zookeeper-server-start.sh config/zookeeper.properties
- 新建第二个终端(记作“Kafka终端”),然后输入下面命令启动Kafka服务:
cd /usr/local/kafkabin/kafka-server-start.sh config/server.properties
- 新建第三个终端(记作“监控输入终端”),执行如下命令监控Kafka收到的文本:
cd /usr/local/kafkabin/kafka-console-consumer.sh > --bootstrap-server localhost:9092 --topic wordcount-topic
- 新建第四个终端(记作“监控输出终端”),执行如下命令监控输出的结果文本:
cd /usr/local/kafkabin/kafka-console-consumer.sh > --bootstrap-server localhost:9092 --topic wordcount-result-topic
- 在Linux系统中新建一个终端(记作“Zookeeper终端”),输入下面命令启动Zookeeper服务:
- 2.编写生产者(Producer)程序
# spark_ss_kafka_producer.pyimport string
import random
import timefrom kafka import KafkaProducerif __name__ == "__main__":producer = KafkaProducer(bootstrap_servers=['localhost:9092'])while True:s2 = (random.choice(string.ascii_lowercase) for _ in range(2))word = ''.join(s2)value = bytearray(word, 'utf-8')producer.send('wordcount-topic', value=value) \.get(timeout=10)time.sleep(0.1)- 3.编写消费者(Consumer)程序
# spark_ss_kafka_consumer.pyfrom pyspark.sql import SparkSessionif __name__ == "__main__":spark = SparkSession \.builder \.appName("StructuredKafkaWordCount") \.getOrCreate()spark.sparkContext.setLogLevel('WARN') lines = spark \.readStream \.format("kafka") \.option("kafka.bootstrap.servers", "localhost:9092") \.option("subscribe", 'wordcount-topic') \.load() \.selectExpr("CAST(value AS STRING)")wordCounts = lines.groupBy("value").count()query = wordCounts \.selectExpr("CAST(value AS STRING) as key", "CONCAT(CAST(value AS STRING), ':', CAST(count AS STRING)) as value") \.writeStream \.outputMode("complete") \.format("kafka") \.option("kafka.bootstrap.servers", "localhost:9092") \.option("topic", "wordcount-result-topic") \.option("checkpointLocation", "file:///tmp/kafka-sink-cp") \.trigger(processingTime="8 seconds") \.start()query.awaitTermination()- 在终端中执行如下命令运行消费者程序:
0.3 讲义socket源,结构化流实现词频统计。按照讲义要求,复现socket源实验。
- 代码文件spark_ss_rate.py
# spark_ss_rate.pyfrom pyspark.sql import SparkSessionif __name__ == "__main__":spark = SparkSession \.builder \.appName("TestRateStreamSource") \.getOrCreate()spark.sparkContext.setLogLevel('WARN')lines = spark \.readStream \.format("rate") \.option('rowsPerSecond', 5) \.load()print(lines.schema)query = lines \.writeStream \.outputMode("update") \.format("console") \.option('truncate', 'false') \.start()query.awaitTermination()- 在Linux终端中执行spark_ss_rate.py
0.4(不选)使用rate源,评估系统性能。
1.日志分析任务
1.1通过Socket传送Syslog到Spark日志分析是一个大数据分析中较为常见的场景。
- 实验原理:
- 在Unix类操作系统里,Syslog广泛被应用于系统或者应用的日志记录中。
- Syslog通常被记录在本地文件内,比如Ubuntu内为/var/log/syslog文件名,也可以被发送给远程Syslog服务器。
- Syslog日志内一般包括产生日志的时间、主机名、程序模块、进程名、进程ID、严重性和日志内容。
- 日志一般会通过Kafka等有容错保障的源发送,本实验为了简化,直接将Syslog通过Socket源发送。
- 实验过程:
- 新建一个终端,执行如下命令:
tail -n+1 -f /var/log/syslog | nc -lk 9988“tail -n+1 -f /var/log/syslog”- 表示从第一行开始打印文件syslog的内容
- “-f”表示如果文件有增加则持续输出最新的内容。
- 然后,通过管道把文件内容发送到nc程序(nc程序可以进一步把数据发送给Spark)。
- 如果/var/log/syslog内的内容增长速度较慢,可以再新开一个终端(计作“手动发送日志终端”),手动在终端输入如下内容来增加日志信息到/var/log/syslog内:
logger ‘I am a test error log message.
from pyspark import SparkContext
from pyspark.streaming import StreamingContext# 创建SparkContext和StreamingContext
sc = SparkContext(appName="SyslogAnalysis")
ssc = StreamingContext(sc, 1)# 创建一个DStream,接收来自Socket的数据流
lines = ssc.socketTextStream("localhost", 9988)# 在数据流上应用转换和操作
word_counts = lines.flatMap(lambda line: line.split(" ")) \.map(lambda word: (word, 1)) \.reduceByKey(lambda x, y: x + y)# 输出结果到控制台
word_counts.pprint()# 启动StreamingContext
ssc.start()
ssc.awaitTermination()1.2对Syslog进行查询
- 由Spark接收nc程序发送过来的日志信息,然后完成以下任务:
- 统计CRON这个进程每小时生成的日志数,并以时间顺序排列,水印设置为1分钟。
- 统计每小时的每个进程或者服务分别产生的日志总数,水印设置为1分钟。
- 输出所有日志内容带error的日志。
from pyspark.sql.functions import window
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
from pyspark.sql.types import StructType, StructField, StringType, TimestampType# 创建SparkSession
spark = SparkSession.builder \.appName("LogAnalysis") \.getOrCreate()# 定义日志数据的模式
schema = StructType([StructField("timestamp", TimestampType(), True),StructField("message", StringType(), True)
])# 从socket接收日志数据流
logs = spark.readStream \.format("socket") \.option("host", "localhost") \.option("port", 9988) \.load()# 将接收到的日志数据流应用模式
logs = logs.selectExpr("CAST(value AS STRING)") \.selectExpr("to_timestamp(value, 'yyyy-MM-dd HH:mm:ss') AS timestamp", "value AS message") \.select(col("timestamp"), col("message").alias("log_message"))# 统计CRON进程每小时生成的日志数,并按时间顺序排列
cron_logs = logs.filter(col("log_message").contains("CRON")) \.groupBy(window("timestamp", "1 hour")) \.count() \.orderBy("window")# 统计每小时每个进程或服务产生的日志总数
service_logs = logs.groupBy(window("timestamp", "1 hour"), "log_message") \.count() \.orderBy("window")# 输出所有带有"error"的日志内容
error_logs = logs.filter(col("log_message").contains("error"))# 设置水印为1分钟
cron_logs = cron_logs.withWatermark("window", "1 minute")
service_logs = service_logs.withWatermark("window", "1 minute")
error_logs = error_logs.withWatermark("timestamp", "1 minute")# 启动流式处理并输出结果
query_cron_logs = cron_logs.writeStream \.outputMode("complete") \.format("console") \.start()query_service_logs = service_logs.writeStream \.outputMode("complete") \.format("console") \.start()query_error_logs = error_logs.writeStream \.outputMode("append") \.format("console") \.start()# 等待流式处理完成
query_cron_logs.awaitTermination()
query_service_logs.awaitTermination()
query_error_logs.awaitTermination()2.股市分析任务(进阶任务)
- 数据集采用dj30数据集,见教学平台。
- 实验说明:
- 本实验将使用两个移动均线策略,短期移动均线为10天,长期移动均线为40天。
- 当短期移动均线越过长期移动均线时,这是一个买入信号,因为它表明趋势正在向上移动。这就是所谓的黄金交叉。
- 同时,当短期移动均线穿过长期移动均线下方时,这是一个卖出信号,因为它表明趋势正在向下移动。这就是所谓的死亡交叉。
- 两种叉形如下图所示:dj30.csv包含了道琼斯工业平均指数25年的价格历史。
- 实验要求:
- 1.设置流以将数据输入structed streaming。
- 2.使用structed streaming窗口累计 dj30sum和dj30ct,分别为价格的总和和计数。
- 3.将这两个structed streaming (dj30sum和dj30ct)分开产生dj30avg,从而创建10天MA和40天MA的移动平均值。
- 4.比较两个移动平均线(短期移动平均线和长期移动平均线)来指示买入和卖出信号。
- 您的输出[dj30-feeder只有一个符号的数据:DJI,这是隐含的。
- 这个问题的输出将是[(<日期>买入DJI),(<日期>卖出DJI),等等]。
- 应该是[(<日期>买入<符号>),(<日期>卖出<符号>),等等]的形式。
1.设置流以将数据输入structed streaming。
from pyspark.sql import SparkSession
from pyspark.sql.functions import *# 创建一个SparkSession对象:
spark = SparkSession.builder \.appName("StructuredStreamingExample") \.getOrCreate()
inputPath = "path_to_dj30.csv"# 读取dj30.csv文件并创建一个输入流:
df = spark.readStream \.format("csv") \.option("header", "true") \.load(inputPath)# 对数据进行处理和转换:
df = df.withColumn("timestamp", to_timestamp(col("date"), "yyyy-MM-dd"))# 定义输出操作:
agg_df = df.groupBy(window("timestamp", "1 hour")).agg(sum("price").alias("dj30sum"), count("price").alias("dj30ct"))# 启动流式处理:
query = agg_df.writeStream \.outputMode("complete") \.format("console") \.start()# 等待流式处理完成:
query.awaitTermination()from pyspark.sql import SparkSession
from pyspark.sql.functions import colspark = SparkSession.builder \.appName("DJ30 Structured Streaming") \.getOrCreate()dj30_data = spark.read.csv("path/to/dj30.csv", header=True)streaming_data = dj30_data.select(col("Long Date").alias("date"), col("Close").cast("float").alias("close"))streaming_data.createOrReplaceTempView("dj30_stream")streaming_df = spark.sql("SELECT * FROM dj30_stream")2.使用structed streaming窗口累计 dj30sum和dj30ct,分别为价格的总和和计数
3.将这两个structed streaming (dj30sum和dj30ct)分开产生dj30avg,从而创建10天MA和40天MA的移动平均值
4.比较两个移动平均线(短期移动平均线和长期移动平均线)来指示买入和卖出信号。
相关文章:

【spark】
实验5 Spark Structured Streaming编程实践 实验内容和要求 0.结构化流练习任务 0.1 讲义文件源-json数据任务。按照讲义中json数据的生成及分析,复现实验,并适当分析。 (1)创建程序生成JSON格式的File源测试数据 import osimp…...

ADO.NET 面试题
这里写自定义目录标题 什么是 ADO.NET?ADO.NET 的主要特点有哪些?ADO.NET 的四个组件分别是什么?什么是 Connection 串?Connection 的状态有哪些?什么是 DataAdapter?DataAdapter 的作用是什么?…...

第三篇、基于Arduino uno,用oled0.96寸屏幕显示dht11温湿度传感器的温度和湿度信息——结果导向
0、结果 说明:先来看看拍摄的显示结果,如果是你想要的,可以接着往下看。 1、外观 说明:本次使用的oled是0.96寸的,别的规格的屏幕不一定适用本教程,一般而言有显示白色、蓝色和蓝黄一起显示的࿰…...

什么是npu算力盒子,算力是越大越好吗?
一、什么是npu算力盒子?该怎么选? NPU(神经处理单元)算力盒子是一种专门用于进行人工智能计算的硬件设备,其中集成了高性能的NPU芯片。NPU是一种针对深度学习任务进行优化的处理器,具备高度并行计算和低功…...

后端返回文件流时,前端如何处理并成功下载流文件以及解决下载后打开显示不支持此文件格式
一、文件和流的关系 文件(File)和流(Stream)是既有区别又有联系的两个概念。 文件 是计算机管理数据的基本单位,同时也是应用程序保存和读取数据的一个重要场所。 存储介质:文件是指在各种存储介质上(如硬盘、可…...

Ansible的脚本-playbook 剧本
目录 1.剧本(playbook) 1.playbook介绍 2. playbooks 的组成 3.案例:编写httpd的playbook 4.定义、引用变量 5.指定远程主机sudo切换用户 6.when条件判断 7.迭代 2.playbook的模块 1.Templates 模块 2.tags 模块 3.Roles 模块 1.…...

python lambda表达式表达式详解及应用
目录 Python Lambda表达式的优势 Lambda表达式用法 1. 当作参数传递 2. 使用Lambda表达式过滤列表 3. 使用Lambda表达式计算数学表达式 4. 使用Lambda表达式作为返回值 5. 实现匿名回调函数 Lambda表达式注意事项 总结 Lambda表达式是Python中的一种匿名函数ÿ…...

Windows 10计算机性能优化:让你的电脑更流畅
Windows 10是目前最流行的操作系统之一,但在长期使用过程中,可能会出现一些性能方面的问题。本文将为你介绍如何选择合适的Windows 10版本,并提供一些优化技巧,使你的电脑性能更加流畅。此外,还将特别关注游戏用户和工…...

SpringMVC底层原理源码解析
SpringMVC的作用毋庸置疑,虽然我们现在都是用SpringBoot,但是SpringBoot中仍然是在使用SpringMVC来处理请求。 我们在使用SpringMVC时,传统的方式是通过定义web.xml,比如: <web-app><servlet><servle…...

【CSS系列】第八章 · CSS浮动
写在前面 Hello大家好, 我是【麟-小白】,一位软件工程专业的学生,喜好计算机知识。希望大家能够一起学习进步呀!本人是一名在读大学生,专业水平有限,如发现错误或不足之处,请多多指正࿰…...

janus videoroom 对接freeswitch conference 篇1
janus videoroom 实时性非常好, freeswitch conference的功能也很多 ,有没办法集成到一块呢 让很多sip 视频终端也能显示到videoroom 里面, 实现方式要不两种 1.改源码实现 (本文忽略 难度高) 2.找一个videoroom管…...
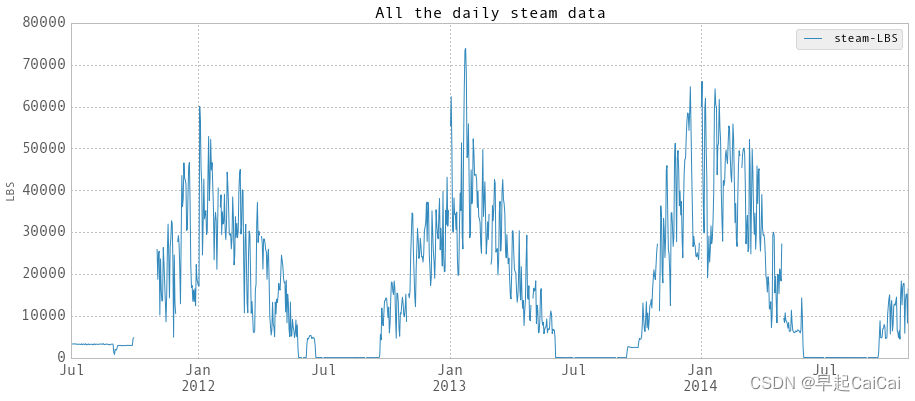
cs109-energy+哈佛大学能源探索项目 Part-2.1(Data Wrangling)
博主前期相关的博客见下: cs109-energy哈佛大学能源探索项目 Part-1(项目背景) 这次主要讲数据的整理。 Data Wrangling 数据整理 在哈佛的一些大型建筑中,有三种类型的能源消耗,电力,冷冻水和蒸汽。 冷冻…...
__101对称二叉树------进阶:你可以运用递归和迭代两种方法解决这个问题吗?---本题还没用【迭代】去实现
101对称二叉树 原题链接:完成情况:解题思路:参考代码: 原题链接: 101. 对称二叉树 https://leetcode.cn/problems/symmetric-tree/ 完成情况: 解题思路: 递归的难点在于:找到可以…...
怎么取消只读模式?硬盘进入只读模式怎么办?
案例:电脑磁盘数据不能修改怎么办? 【今天工作的时候,我想把最近的更新的资料同步到电脑上的工作磁盘,但是发现我无法进行此操作,也不能对磁盘里的数据进行改动。有没有小伙伴知道这是怎么一回事?】 在使…...

如何使用Java生成Web项目验证码
使用Java编写Web项目验证码 验证码是Web开发中常用的一种验证方式,可以防止机器恶意攻击。本文将介绍如何使用Java编写Web项目验证码,包括步骤、示例和测试。 步骤 1. 添加依赖 首先需要在项目中添加以下依赖: <dependency><groupId>com.google.code.kaptc…...

【读书笔记】《亲密关系》
作者:美国的罗兰米勒 刚拿到这本书的时候,就被最后将近100页的参考文献折服了,让我认为这本书极具专业性。 作者使用了14章,从人与人之间是如何相互吸引的,讲到如何相处与沟通,后又讲到如何面对冲突与解决矛…...

面试季,真的太狠了...
金三银四面试季的复盘,真的太狠了… 面试感受 先说一个字 是真的 “ 累 ” 安排的太满的后果可能就是一天只吃一顿饭,一直奔波在路上 不扯这个了,给大家说说面试吧,我工作大概两年多的时间,大家可以参考下 在整个面…...

2023年十大最佳黑客工具!
用心做分享,只为给您最好的学习教程 如果您觉得文章不错,欢迎持续学习 在今年根据实际情况,结合全球黑客共同推崇,选出了2023年十大最佳黑客工具。 每一年,我都会持续更新,并根据实际现实情况随时更改…...

每日练习---C语言
目录 前言: 1.打印菱形 1.1补充练习 2.打印水仙花 2.1补充训练 前言: 记录博主做题的收获,以及提升自己的代码能力,今天写的题目是:打印菱形、打印水仙花数。 1.打印菱形 我们先看到牛客网的题:OJ链…...

边缘计算如何推动物联网的发展
随着物联网(IoT)的快速发展,物联网设备数量呈现爆炸性增长,这给网络带来了巨大的压力和挑战。边缘计算作为一种新兴的计算模式,旨在解决数据处理和通信在网络传输中的延迟和带宽限制问题,从而提高数据处理效…...

Godot PCK解包原理与专业逆向实践指南
1. 这不是“解压软件”,而是Godot游戏逆向工程的第一把手术刀你刚下载了一款用Godot引擎开发的独立游戏,想研究它的UI动效逻辑,或者复刻一段粒子特效,又或者只是单纯好奇——那个让你反复通关三次的像素风过场动画,图层…...

微信小程序3D开发框架技术对比:XR-Frame与threejs-miniprogram
随着微信小程序逐步支持3D渲染与AR能力,开发者面临两个主要官方方案:自研的XR-Frame和适配Three.js的threejs-miniprogram。本文将从架构设计、渲染机制、功能集成、开发模式及适用场景等维度进行技术分析,为技术选型提供参考。一、XR-Frame&…...

【紧急预警】92%的DeepSeek测试用例生成失败源于这4个隐性配置缺陷——资深SDET连夜整理修复清单
更多请点击: https://codechina.net 第一章:DeepSeek测试用例生成的现状与危机本质 当前,DeepSeek系列大模型(如DeepSeek-Coder、DeepSeek-VL)在代码生成与理解任务中展现出强大能力,但其测试用例自动生成…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...

pan-baidu-download:百度网盘多线程下载加速器架构解析与性能优化指南
pan-baidu-download:百度网盘多线程下载加速器架构解析与性能优化指南 【免费下载链接】pan-baidu-download 百度网盘下载脚本 项目地址: https://gitcode.com/gh_mirrors/pa/pan-baidu-download pan-baidu-download是一款基于Python开发的百度网盘命令行下载…...

荣耀出征官方网站下载正版手游 翅膀养成细节玩法全方位讲解
玩荣耀出征的玩家都清楚,翅膀不仅是角色的颜值象征,更是提升整体战力的核心途径。很多新手玩家只顾着升级、刷装备,完全忽略翅膀养成,导致等级很高但战力始终上不去。还有不少玩家胡乱合成、盲目进阶,浪费了大量稀有翅…...

差分隐私GDP机制紧密度量化:从隐私剖面到∆度量的实践指南
1. 差分隐私GDP机制:从理论到实践,如何量化隐私保护紧密度在差分隐私(Differential Privacy, DP)的实际部署中,尤其是在机器学习的隐私保护训练(如DP-SGD)场景里,我们常常面临一个核…...

DIY四路自动音频源切换器:从信号检测到继电器隔离的完整设计
1. 项目概述与核心需求解析作为一个喜欢在工作室里捣鼓各种音频设备的玩家,我经常遇到一个挺烦人的问题:我的功放只有一组输入,但我想接的设备却有好几个——台式电脑、平板、蓝牙接收模块,还有一台树莓派。每次想切换音源&#x…...

如何用WaveTools终极优化《鸣潮》游戏性能:从卡顿到丝滑的完整指南
如何用WaveTools终极优化《鸣潮》游戏性能:从卡顿到丝滑的完整指南 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 如果你正在玩《鸣潮》却频繁遭遇帧率波动、画面卡顿或操作延迟,那…...
)
微信聊天图片丢了别慌!保姆级教程:找回并解密DAT文件(支持新旧版微信路径)
微信DAT图片恢复实战:从文件定位到批量解密的完整指南 微信聊天记录中的图片突然消失?别急着放弃!那些看似无法打开的DAT文件里,可能藏着您的重要回忆或工作资料。本文将带您深入微信存储机制,手把手完成从文件定位到…...