大数据框架之Hadoop:HDFS(五)NameNode和SecondaryNameNode(面试开发重点)
5.1NN和2NN工作机制
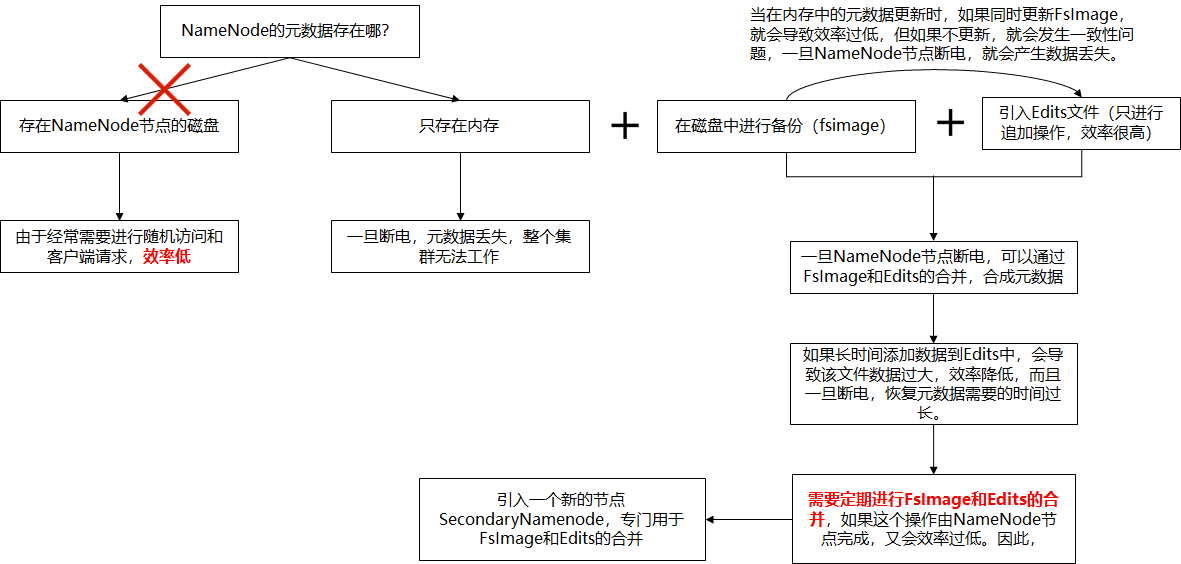
5.1.1思考:NameNode中的元数据是存储在哪里的?
首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。因此,元数据需要存放在内存中。但如果只存在内存中,一旦断电,元数据丢失,整个集群就无法工作了。因此产生在磁盘中备份元数据的FsImage。
这样又会带来新的问题,当在内存中的元数据更新时,如果同时更新FsImage,就会导致效率过低,但如果不更新,就会发生一致性问题,一旦NameNode节点断电,就会产生数据丢失。因此,引入Edits文件(只进行追加操作,效率很高)。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到Edits中。这样,一旦NameNode节点断电,可以通过FsImage和Edits的合并,合成元数据。
但是,如果长时间添加数据到Edits中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行FsImage和Edits的合并,如果这个操作由NameNode节点完成,又会效率过低。因此,引入一个新的节点SecondaryNamenode,专门用于FsImage和Edits的合并。
5.1.2NameNode工作机制
NN和2NN工作机制,如下图所示。

- 第一阶段:NameNode启动
(1)第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode记录操作日志,更新滚动日志。
(4)NameNode在内存中对数据进行增删改。
- 第二阶段:Secondary NameNode工作
(1)Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。
(2)Secondary NameNode请求执行CheckPoint。
(3)NameNode滚动正在写的Edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。
5.1.3NN和2NN工作机制详解
Fsimage:NameNode内存中元数据序列化后形成的文件。
Edits:记录客户端更新元数据信息的每一步操作(可通过Edits运算出元数据)。
NameNode启动时,先滚动Edits并生成一个空的edits.inprogress,然后加载Edits和Fsimage到内存中,此时NameNode内存就持有最新的元数据信息。Client开始对NameNode发送元数据的增删改的请求,这些请求的操作首先会被记录到edits.inprogress中(查询元数据的操作不会被记录在Edits中,因为查询操作不会更改元数据信息),如果此时NameNode挂掉,重启后会从Edits中读取元数据的信息。然后,NameNode会在内存中执行元数据的增删改的操作。
由于Edits中记录的操作会越来越多,Edits文件会越来越大,导致NameNode在启动加载Edits时会很慢,所以需要对Edits和Fsimage进行合并(所谓合并,就是将Edits和Fsimage加载到内存中,照着Edits中的操作一步步执行,最终形成新的Fsimage)。SecondaryNameNode的作用就是帮助NameNode进行Edits和Fsimage的合并工作。
SecondaryNameNode首先会询问NameNode是否需要CheckPoint(触发CheckPoint需要满足两个条件中的任意一个,定时时间到和Edits中数据写满了)。直接带回NameNode是否检查结果。SecondaryNameNode执行CheckPoint操作,首先会让NameNode滚动Edits并生成一个空的edits.inprogress,滚动Edits的目的是给Edits打个标记,以后所有新的操作都写入edits.inprogress,其他未合并的Edits和Fsimage会拷贝到SecondaryNameNode的本地,然后将拷贝的Edits和Fsimage加载到内存中进行合并,生成fsimage.chkpoint,然后将fsimage.chkpoint拷贝给NameNode,重命名为Fsimage后替换掉原来的Fsimage。NameNode在启动时就只需要加载之前未合并的Edits和Fsimage即可,因为合并过的Edits中的元数据信息已经被记录在Fsimage中。
5.2 Fsimage和Edits解析
- 概念
NameNode被格式化之后,将在/opt/modult/hadoop-2.7.7/data/tmp/dfs/name/current目录中产生如下文件
edits_inprogress_0000000000000004969
fsimage_0000000000000004966
seen_txid
VERSION
(1)fsimage文件:HDFS文件系统元数据的一个永久性检查点,其中包含HDFS文件系统的所有目录和文件inode的序列化信息。
(2)edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到edits文件中。
(3)seen_txid文件:存放最后一个edits的数字。
(4)每次NameNode启动的时候都会将fsimage文件读入内存,加载edits里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成NameNode启动的时候就将fsimage文件进行了合并。
- oiv查看Fsimage文件
(1)查看oiv和oev命令
[root@hdp101 current]# hdfs
oiv apply the offline fsimage viewer to an fsimage
oev apply the offline edits viewer to an edits file
(2)基本语法
hdfs oiv -p 文件类型 -i镜像文件 -o 转换后文件输出路径
(3)案例实操
[root@hdp101 current]# pwd
/opt/module/hadoop-2.7.7/data/tmp/dfs/name/current
[root@hdp101 current]# hdfs oiv -p XML -i fsimage_0000000000000000025 -o /opt/module/hadoop-2.7.7/fsimage.xml
[root@hdp101 current]# cat /opt/module/hadoop-2.7.7/fsimage.xml
将显示的xml文件内容拷贝到Eclipse中创建的xml文件中,并格式化。
思考:可以看出,Fsimage中没有记录块所对应DataNode,为什么?
在集群启动后,要求DataNode上报数据块信息,并间隔一段时间后再次上报。
- oev查看Edits文件
(1)基本语法
hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径
(2)案例实操
[root@hdp101 current]# hdfs oev -p XML -i edits_0000000000000000012-0000000000000000013 -o /opt/module/hadoop-2.7.7/edits.xml[root@hdp101 current]# cat /opt/module/hadoop-2.7.7/edits.xml
将显示的xml文件内容拷贝到Eclipse中创建的xml文件中,并格式化。
5.3CheckPoint时间设置
(1)通常情况下,SecondaryNameNode每隔一小时执行一次。
[hdfs-default.xml]
<property><name>dfs.namenode.checkpoint.period</name><value>3600</value>
</property>
(2)一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次。
<property><name>dfs.namenode.checkpoint.txns</name><value>1000000</value><description>操作动作次数</description>
</property><property><name>dfs.namenode.checkpoint.check.period</name><value>60</value><description> 1分钟检查一次操作次数</description>
</property >
5.4NameNode故障处理
NameNode故障后,可以采用如下两种方法恢复数据。
方法一:将SecondaryNameNode中数据拷贝到NameNode存储数据的目录;
- kill -9 NameNode进程
- 删除NameNode存储的数据(/opt/module/hadoop-2.7.7/data/tmp/dfs/name)
[root@hdp101 hadoop-2.7.7]# rm -rf /opt/module/hadoop-2.7.7/data/tmp/dfs/name/*
- 拷贝SecondaryNameNode中数据到原NameNode存储数据目录
[root@hdp101 dfs]# scp -r root@hdp103:/opt/module/hadoop-2.7.7/data/tmp/dfs/namesecondary/* ./name/
- 重新启动NameNode
[root@hdp101 hadoop-2.7.7]# sbin/hadoop-daemon.sh start namenode
方法二:使用-importCheckpoint选项启动NameNode守护进程,从而将SecondaryNameNode中数据拷贝到NameNode目录中。
- 修改hdfs-site.xml中的
<property><name>dfs.namenode.checkpoint.period</name><value>120</value>
</property><property><name>dfs.namenode.name.dir</name><value>/opt/module/hadoop-2.7.7/data/tmp/dfs/name</value>
</property>
-
kill -9 NameNode进程
-
删除NameNode存储的数据(/opt/module/hadoop-2.7.7/data/tmp/dfs/name)
[root@hdp101 hadoop-2.7.7]# rm -rf /opt/module/hadoop-2.7.7/data/tmp/dfs/name/*
- 如果SecondaryNameNode不和NameNode在一个主机节点上,需要将SecondaryNameNode存储数据的目录拷贝到NameNode存储数据的平级目录,并删除in_use.lock文件
[root@hdp101 dfs]# scp -r root@hdp103:/opt/module/hadoop-2.7.7/data/tmp/dfs/namesecondary ./[root@hdp101 namesecondary]# rm -rf in_use.lock[root@hdp101 dfs]# pwd
/opt/module/hadoop-2.7.7/data/tmp/dfs
[root@hdp101 dfs]# ls
data name namesecondary
- 导入检查点数据(等待一会ctrl+c结束掉)
[root@hdp101 hadoop-2.7.7]# bin/hdfs namenode -importCheckpoint
- 启动NameNode
[root@hdp101 hadoop-2.7.7]# sbin/hadoop-daemon.sh start namenode
5.5 集群安全模式
5.5.1概述
1、NameNode启动
NameNode启动时,首先将镜像文件(Fsimage)载入内存,并执行编辑日志(Edits)中的各项操作。一旦在内存中成功建立文件系统元数据的映像,则闯将一个新的Fsimage文件和一个空的编辑日志。此时,NameNode开始监听DataNode的请求。这个过程期间,NameNode一直运行在安全模式,即NameNode的文件系统对于客户端来说是只读的。
2、DataNode启动
系统中的数据块的位置并不是由NameNode维护的,而是以块列表的形式存储在DataNode中。在系统正常操作期间,NameNode会在内存中保留所有块位置的映射信息。在安全模式下,各个DataNode会向NameNode发送最新的块列表信息,NameNode了解到足够多的块信息之后,即可高效运行文件系统。
3、安全模式退出判断
如果满足“最小副本条件”,NameNode会在30s之后就退出安全模式。所谓的最小副本条件指的是在整个文件系统中99.99%的块满足最小副本级别(默认值:dfs.replication.min=1)。在启动一个刚刚格式化的HDFS集群时,因为系统中还没有任何块,所以NameNode不会进入安全模式。
5.5.2基本语法
集群处于安全模式,不能执行重要操作(写操作)。集群启动完成后,自动退出安全模式。
(1)bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式状态)
(2)bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态)
(3)bin/hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态)
(4)bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式状态)
5.5.3案例
模拟等待安全模式
(1)查看当前模式
[root@hdp101 hadoop-2.7.7]# hdfs dfsadmin -safemode get
Safe mode is OFF
(2)先进入安全模式
[root@hdp101 hadoop-2.7.7]# bin/hdfs dfsadmin -safemode enter
(3)创建并执行下面的脚本
在/opt/module/hadoop-2.7.7路径上,编辑一个脚本safemode.sh
[root@hdp101 hadoop-2.7.7]# touch safemode.sh
[root@hdp101 hadoop-2.7.7]# vim safemode.sh#!/bin/bash
hdfs dfsadmin -safemode wait
hdfs dfs -put /opt/module/hadoop-2.7.7/README.txt /
[root@hdp101 hadoop-2.7.7]# chmod 777 safemode.sh
[root@hdp101 hadoop-2.7.7]# ./safemode.sh
(4)再打开一个窗口,执行
[root@hdp101 hadoop-2.7.7]# bin/hdfs dfsadmin -safemode leave
(5)观察
(a)再观察上一个窗口
Safe mode is OFF
(b)HDFS集群上已经有上传的数据了。
5.6 NameNode多目录配置
- NameNode的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性
- 具体配置如下
(1)在hdfs-site.xml文件中增加如下内容
<property><name>dfs.namenode.name.dir</name><value>file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2</value>
</property>
(2)停止集群,集群中删除data和logs中所有数据。
[root@hdp101 hadoop-2.7.7]$ rm -rf data/ logs/
[root@hadoop103 hadoop-2.7.7]$ rm -rf data/ logs/
[root@hadoop104 hadoop-2.7.7]$ rm -rf data/ logs/
(3)格式化集群并启动。
[root@hdp101 hadoop-2.7.7]$ bin/hdfs namenode –format
[root@hdp101 hadoop-2.7.7]$ sbin/start-dfs.sh
(4)查看结果
[root@hdp101 dfs]$ ll
总用量 12
drwx------. 3 root root 4096 12月 11 08:03 data
drwxrwxr-x. 3 root root 4096 12月 11 08:03 name1
drwxrwxr-x. 3 root root 4096 12月 11 08:03 name2
相关文章:
大数据框架之Hadoop:HDFS(五)NameNode和SecondaryNameNode(面试开发重点)
5.1NN和2NN工作机制 5.1.1思考:NameNode中的元数据是存储在哪里的? 首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。因此&am…...

计算机网络 - 1. 体系结构
目录概念、功能、组成、分类概念功能组成分类分层结构概念总结OSI 七层模型应用层表示层会话层传输层网络层数据链路层物理层TCP/IP 四层模型OSI 与 TCP/IP 相同点OSI 与 TCP/IP 不同点为什么 TCP/IP 去除了表示层和会话层五层参考模型概念、功能、组成、分类 概念 …...

银行业上云进行时,OLAP 云服务如何解决传统数仓之痛?
本文节选自《中国金融科技发展概览:创新与应用前沿》,从某国有大行构建大数据云平台的实践出发,解读了 OLAP 云服务如何助力银行实现技术平台化、组件化和云服务化,降低技术应用门槛,赋能业务创新。此外,本…...

特定领域知识图谱融合方案:文本匹配算法之预训练Simbert、ERNIE-Gram单塔模型等诸多模型【三】
特定领域知识图谱融合方案:文本匹配算法之预训练模型SimBert、ERNIE-Gram 文本匹配任务在自然语言处理中是非常重要的基础任务之一,一般研究两段文本之间的关系。有很多应用场景;如信息检索、问答系统、智能对话、文本鉴别、智能推荐、文本数据去重、文本相似度计算、自然语…...

【2023最新教程】从0到1开发自动化测试框架(0基础也能看懂)
一、序言 随着项目版本的快速迭代、APP测试有以下几个特点: 首先,功能点多且细,测试工作量大,容易遗漏;其次,代码模块常改动,回归测试很频繁,测试重复低效;最后&#x…...

linux备份命令小记 —— 筑梦之路
Linux dump命令用于备份文件系统。 dump为备份工具程序,可将目录或整个文件系统备份至指定的设备,或备份成一个大文件。 dump命令只可以备份ext2/3/4格式的文件系统, centos7默认未安装dump命令,可以使用yum install -y dump安…...
配置环境变量和打包时区分开发、测试、生产环境)
vue项目(vue-cli)配置环境变量和打包时区分开发、测试、生产环境
1.打包时区分不同环境在自定义配置Vue-cli 的过程中,想分别通过.env.development .env.test .env.production 来代表开发、测试、生产环境。NODE_ENVdevelopment NODE_ENVtest NODE_ENVproduction本来想使用上面三种配置来区分三个环境,但是发现使用test…...

Python 命名规范
Python 命名规范 基本规范 类型公有内部备注Packagepackage_namenone全小写下划线式驼峰Modulemodule_name_module_name全小写下划线式驼峰ClassClassName_ClassName首字母大写式驼峰Methodmethod_nameprotected: _method_name private: __method_name全小写下划线式驼峰Exce…...
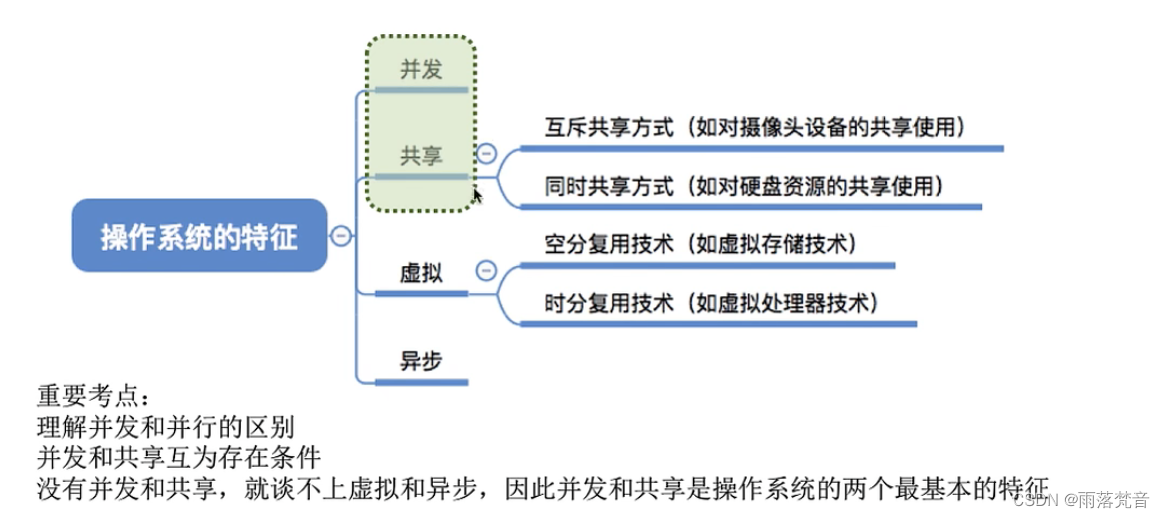
操作系统——2.操作系统的特征
这篇文章,我们来讲一讲操作系统的特征 目录 1.概述 2.并发 2.1并发概念 2.1.1操作系统的并发性 3.共享 3.1共享的概念 3.2共享的方式 4.并发和共享的关系 5.虚拟 5.1虚拟的概念 5.2虚拟小结 6.异步 6.1异步概念 7.小结 1.概述 上一篇文章,我们…...
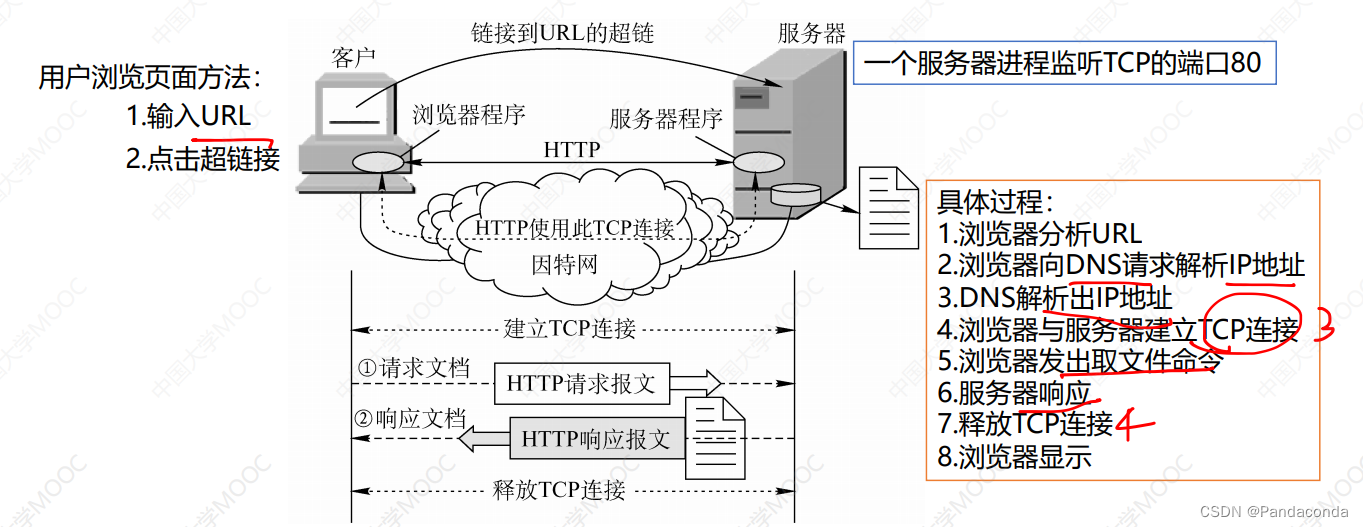
【计算机网络期末复习】第六章 应用层
✍个人博客:https://blog.csdn.net/Newin2020?spm1011.2415.3001.5343 📣专栏定位:为想复习学校计算机网络课程的同学提供重点大纲,帮助大家渡过期末考~ 📚专栏地址:https://blog.csdn.net/Newin2020/arti…...

TypeScript基本教程
TS是JS的超集,所以JS基础的类型都包含在内 起步安装 npm install typescript -g运行tsc 文件名 基础类型 Boolean、Number、String、null、undefined 以及 ES6 的 Symbol 和 ES10 的 BigInt。 1 字符串类型 字符串是使用string定义的 let a: string 123 //普…...

使用Windows API实现本地音频采集
Windows API提供了Winmm(Windows多媒体)库,其中包括了音频设备相关的函数,可以用来实现音频设备的枚举和测试。 下面是一个简单的示例代码,演示了如何使用Winmm库中的waveInGetNumDevs()函数来枚举计算机上的音频输入…...

实用的费曼学习法 | 一些思考
文章目录 一、前言二、费曼学习法CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 大数据与人工智能背景下,最重要的是:捕捉机会和快速学习的能力 一、前言 费曼学习法是美国著名的物理学家,理查德 ∙ \bullet ∙ 费曼总结出来的学习方法。 这个方法的核心是:当你学习了…...

Linux安装Docker配置docker-compose 编排工具【超详细】
一、介绍Docker Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Linux或Windows操作系统的机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有…...

iTerm2 + Oh My Zsh 打造舒适终端体验
最终效果图: 因为powerline以及homebrew均需要安装command line tool,网络条件优越的同学在执行本文下面内容之前,可以先安装XCode并打开运行一次(会初始化安装components),省去以后在iterm2中的等待时间。…...
和dia_matrix()的区别)
【scipy.sparse】diags()和dia_matrix()的区别
【scipy.sparse】diags()和dia_matrix()的区别 文章目录【scipy.sparse】diags()和dia_matrix()的区别1. 介绍2. 代码示例2.1 sp.diags()2.1.1 第一种用法(dataoffsets)2.1.2 广播(需要指定shape)2.1.3 只有一条对角线2.2 sp.dia_…...
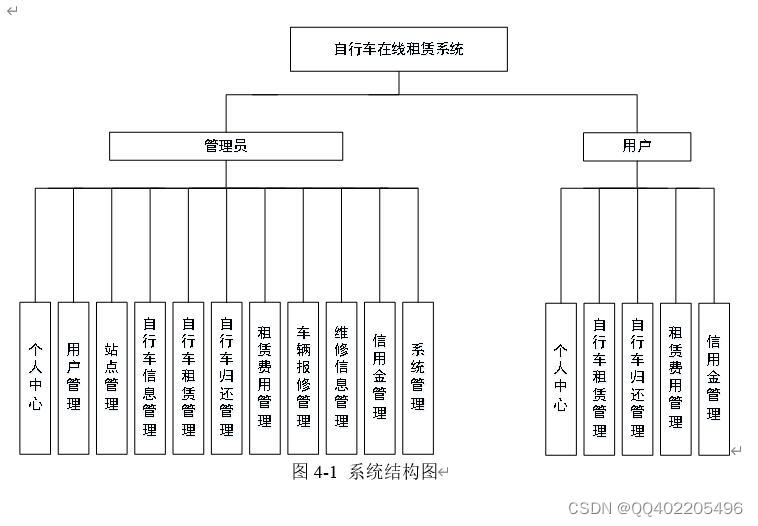
java ssm自行车在线租赁系统idea
当前自行车在社会上广泛使用,但自行车的短距离仍旧不能完全满足广大用户的需求。自行车在线租赁系统可以为用户提供租赁用车等功能,拥有较好的用户体验.能实时在线租赁提供更加快捷方便的租车方式,解决了常见自行车在线租赁系统较为局限的自行车归还功能。 通过使用本系统&…...

GAN和CycleGAN
文章目录1. GAN 《Generative Adversarial Nets》1.1 相关概念1.2 公式理解1.3 图片理解1.4 熵、交叉熵、KL散度、JS散度1.5 其他相关(正在补充!)2. Cycle GAN 《Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Ne…...
源码项目中常见设计模式及实现
原文https://mp.weixin.qq.com/s/K8yesHkTCerRhS0HfB0LeA 单例模式 单例模式是指一个类在一个进程中只有一个实例对象(但也不一定,比如Spring中的Bean的单例是指在一个容器中是单例的) 单例模式创建分为饿汉式和懒汉式,总共大概…...
KDNM5000-10A-2剩余电流保护器测试仪
一、产品概述 KDNM5000-10A-2型剩余电流保护器测试仪(以下简称测试仪),是本公司改进产品,是符合国家标准《剩余电流动作保护器》(GB6829—95)中第8.3条和GB16917.1—1997中第9.9条验证AC型交流脱扣器动作特性要求的专用测试仪器。…...

全平台数据采集工具:BarrageGrab直播弹幕实时抓取解决方案
全平台数据采集工具:BarrageGrab直播弹幕实时抓取解决方案 【免费下载链接】BarrageGrab 抖音快手bilibili直播弹幕wss直连,非系统代理方式,无需多开浏览器窗口 项目地址: https://gitcode.com/gh_mirrors/ba/BarrageGrab 在数字直播时…...

【Simulink】双矢量调制MPC在并网逆变器中的实现:从理论到仿真
1. 双矢量MPC为什么更适合并网逆变器控制 我第一次接触双矢量模型预测控制(MPC)是在调试一个光伏并网项目时。当时单矢量MPC的电流纹波始终达不到设计要求,直到看到郭磊磊老师那篇经典论文才恍然大悟——原来矢量组合方式才是破局关键。相比传…...

数据库课程设计实战:构建文本分割结果的管理系统
数据库课程设计实战:构建文本分割结果的管理系统 每次做数据库课程设计,你是不是也头疼?选题要么太简单,像学生信息管理,做出来感觉没深度;要么太复杂,比如电商系统,光表关系就画晕…...

OpenClaw本地知识图谱:GLM-4.7-Flash构建个人关系网络
OpenClaw本地知识图谱:GLM-4.7-Flash构建个人关系网络 1. 为什么需要个人知识图谱 去年整理项目资料时,我发现自己收藏的200多篇技术文章和50多个开源项目早已形成"信息孤岛"。当需要跨领域参考时,只能靠模糊记忆在文件夹里大海捞…...

OpenClaw技能扩展:基于nanobot实现Markdown自动转换
OpenClaw技能扩展:基于nanobot实现Markdown自动转换 1. 为什么需要文档自动化转换 在日常工作中,我们经常需要处理各种格式的文档——Word、PDF、PPT、Excel甚至网页内容。手动将这些文档转换为Markdown格式不仅耗时,还容易出错。作为一名技…...

3个高效功能让Maccy成为macOS必备剪贴板管理器
3个高效功能让Maccy成为macOS必备剪贴板管理器 【免费下载链接】Maccy Lightweight clipboard manager for macOS 项目地址: https://gitcode.com/gh_mirrors/ma/Maccy Maccy是一款专为macOS设计的轻量级剪贴板管理器,能够记录复制历史,让用户轻松…...

YALMIP求解器报错看不懂?从verbose到debug,教你快速定位并解决优化问题
YALMIP求解器报错看不懂?从verbose到debug,教你快速定位并解决优化问题 当你满怀期待地运行YALMIP优化代码,却看到命令行突然跳出一片红色报错信息时,那种挫败感每个优化工程师都深有体会。"No feasible solution found"…...

Qwen3-Reranker-0.6B效果展示:代码搜索Query ‘Python list to dict‘重排
Qwen3-Reranker-0.6B效果展示:代码搜索Query Python list to dict重排 今天咱们来聊聊一个特别实用的AI工具——Qwen3-Reranker-0.6B。你可能听说过各种大语言模型,但这个模型有点不一样,它专门干一件事:帮你从一堆文本里找出最相…...

YOLO X Layout中小企业应用:无需训练,开箱即用的文档结构理解AI工具
YOLO X Layout中小企业应用:无需训练,开箱即用的文档结构理解AI工具 1. 引言:让文档理解变得简单高效 在日常办公中,我们经常需要处理各种文档——扫描的合同、拍摄的表格、电子版报告。传统方式需要人工逐个识别文档中的文字、…...

VRRP配置里这个‘坑’你踩过吗?详解track监视上行链路与流量黑洞问题
VRRP高可用架构中的隐形陷阱:深度解析上行链路监控与流量黑洞解决方案 当企业核心网络的网关设备突然"失联",但设备状态灯却依然闪烁着健康的绿色,这种看似矛盾的故障场景往往让运维团队陷入困境。上周深夜,某金融公司就…...