RabbitMQ相关概念介绍
这篇文章主要介绍RabbitMQ中几个重要的概念,对于初学者来说,概念性的东西可能比较难以理解,但是对于理解和使用RabbitMQ却必不可少,初学阶段,现在脑海里留有印象,随着后续更加深入的学习,就会很容易理解。对于消息队列的高手,这篇文章如有阐述不到位的,可以一起交流。
RabbitMQ整体上是一个生产者和消费者模型,如下图。
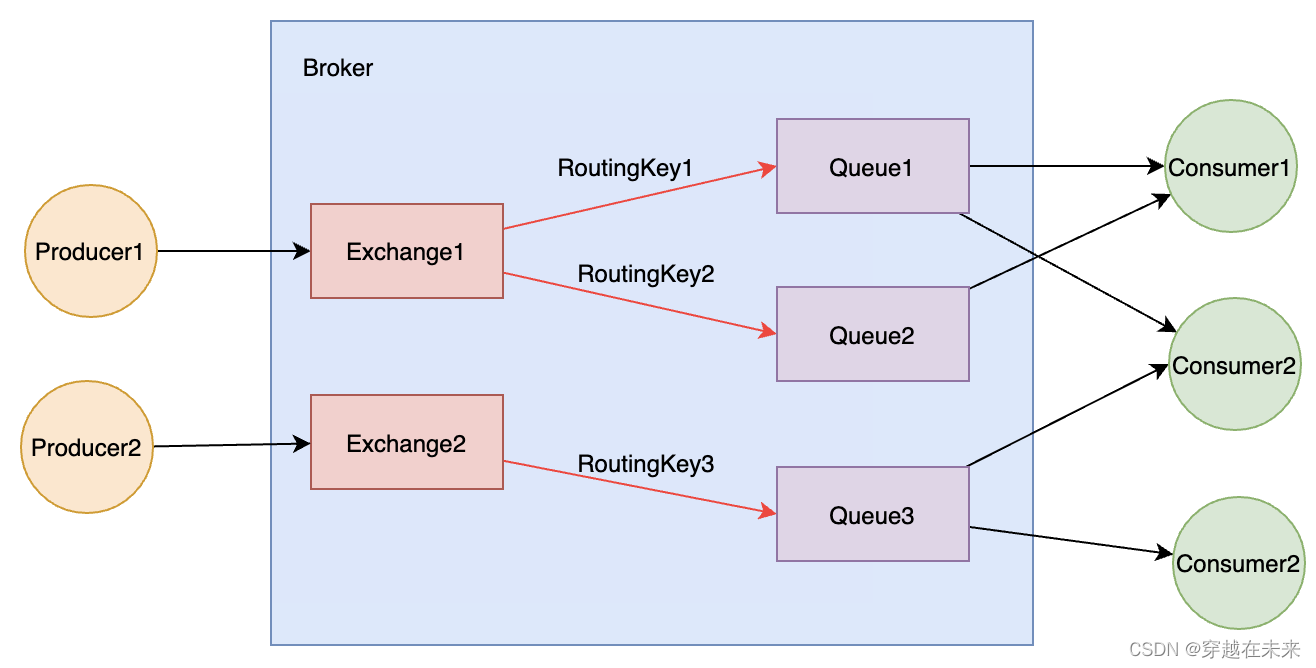
生产者和消费者
RabbitMQ的Producer和其他消息队列的Producer没有什么不同,都是用来将消息发送到服务器,只是在实现上有所区别,关于RabbitMQ客户端的实现,包括API和网络模型等,后面会专门有文章介绍。
RabbitMQ Consumer连接Broker,并订阅它关注的队列,只要队列上有消息,Consumer就会接收到消息并开始消费消息。RabbitMQ的消费端默认是推模型。
有Producer、Consumer,那么就会有一个地方来存储、转发消息,RabbitMQ Broker完成这项工作,在这里,可以先简单的把一个Broker理解为一个RabbitMQ 节点或实例。
队列
Queue是RabbitMQ的内部对象,是实际存储Producer发送的消息的地方,这点和Kafka存储消息的模型不一样。
Producer发送消息并不是直接发送到Queue,而是在发送消息的请求中声明Exchange(交换器) 和 RoutingKey(绑定键),Broker会根据Exchange 和 RoutingKey找到相应的Queue,并保存消息内容到Queue。
Consumer订阅的是Queue,所有直接从Queue上消费消息。RabbitMQ支持多个Consumer同时订阅一个Queue,这时Broker会轮询Consumer,把Queue中的消息均摊到所有订阅次Queue的Consumer。但是RabbitMQ不支持队列层面的广播消费。
交换器、路由键、绑定
下面介绍的是RabbitMQ中非常重要的概念,生产和消费消息都是以此为基础,也是对AMQP协议的具体实现。
交换器(Exchange)负责按照一定的规则分发消息,Producer发送的消息实际上是到Exchange,由Exchange将消息路由到一个或多个Queue,如果找不到Queue,则根据客户端配置,要么返回给Producer,要么直接丢弃。
路由键(RoutingKey)指定了路由规则,在Producer发送消息的时候,一般会指定RoutingKey,这样就知道消息需要路由到哪里。
绑定(BingKey)将Exchange和Queue关联起来,这样,RabbitMQ就知道如何正确的将消息路由到队列了。
关于路由键和绑定键,对于初学者可能有点混淆,这里分享下我的理解:路由键是在客户端发送消息的时候,告诉服务器,我发送的消息根据我指定的路由键去找队列;而绑定键,是在创建的时候使用的,告诉服务器,交换器是如何与队列关联的。具体可以对照下面的代码示例来理解可能容易点。
交换器类型
RabbitMQ提供了多个交换器类型来满足不同的需求:fanout、direct、topic、headers。
fanout
fanout exchange会把消息发送到所有与该交换器绑定的队列中,会忽略Procuder发送消息时申明的RoutingKey。如下图,Producer发送message给fanout_exchange,并制定了routing key 为 info,最终queue1和queue2都收到了这条消息。

public void testFanoutExchange() throws IOException, TimeoutException {// fanout类型的 exchange, 在server端忽略 routing key,只要发送到 exchange,任何和这个 exchange 绑定的 queue都会收到这条消息String exchangeName = "fanout_exchange";String queue1 = "queue1";String queue2 = "queue2";String warning = "warning";String info = "info";ConnectionFactory factory = new ConnectionFactory();factory.setHost("localhost");factory.setPort(5672);factory.setUsername("root");factory.setPassword("root");Connection connection = factory.newConnection();Channel channel = connection.createChannel();channel.exchangeDeclare(exchangeName, BuiltinExchangeType.FANOUT, true, false, null);channel.queueDeclare(queue1, true, false, false, null);channel.queueDeclare(queue2, true, false, false, null);channel.queueBind(queue1, exchangeName, warning);channel.queueBind(queue2, exchangeName, warning);channel.queueBind(queue2, exchangeName, info);String message = "info";channel.basicPublish(exchangeName, info, MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes());channel.close();connection.close();}
direct
direct exchange也是一种比较简单的exchange,在路由的时候,只有routing key 和binding key完全匹配的时候,才会路由到queue。如下图,Producer发送消息到direct_exchange,routing_key 是info,只有queue2才会收到消息。

public void testDirectExchange() throws IOException, TimeoutException {String exchangeName = "direct_exchange";String queue1 = "direct_queue1";String queue2 = "direct_queue2";String warning = "warning";String info = "info";ConnectionFactory factory = new ConnectionFactory();factory.setHost("localhost");factory.setPort(5672);factory.setUsername("root");factory.setPassword("root");Connection connection = factory.newConnection();Channel channel = connection.createChannel();channel.exchangeDeclare(exchangeName, BuiltinExchangeType.DIRECT, true, false, null);channel.queueDeclare(queue1, true, false, false, null);channel.queueDeclare(queue2, true, false, false, null);channel.queueBind(queue1, exchangeName, warning);channel.queueBind(queue2, exchangeName, warning);channel.queueBind(queue2, exchangeName, info);String message = "direct exchange";channel.basicPublish(exchangeName, info, MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes());channel.close();connection.close();}
topic
topic exchange 是比较灵活,实际项目中用的比较多的一种,它也是将消息路由到 routing key 和 binding key 匹配的队列中,匹配规则如下:
- routing key 和 binding key 以点(.)为分隔符,被点号分割的字符串为一个独立的匹配单元,如com.rabbitmq.client,com.java.util 等等。
- ‘#’ 和 ‘*’ 用于做模糊匹配,‘#’ 匹配0个或多个词,‘*’ 匹配0个词。
下图中topic_exchange绑定了两个queue,*.rabbitmq.* 绑定颅queue1, *.*.client 、 com.# 都绑定了queue2,当binding key 为 com.rabbitmq.client,匹配queue1和queue2,因此都会收到消息;当binding key 为 org.rabbitmq.server 时,只有queue1匹配,当 binding key 为 com.hidden.demo 时,只有queue2匹配,当bingding key 为 aaa 时,queue1 和 queue2 都不匹配。

public void testTopicExchange() throws IOException, TimeoutException {// * 匹配一个单词,# 匹配0个或多个单词String exchangeName = "topic_exchange";String queue1 = "topic_queue1";String queue2 = "topic_queue2";String routing1 = "*.rabbitmq.*";String routing2 = "*.*.client";String routing3 = "com.#";ConnectionFactory factory = new ConnectionFactory();factory.setHost("localhost");factory.setPort(5672);factory.setUsername("guest");factory.setPassword("guest");Connection connection = factory.newConnection();Channel channel = connection.createChannel();channel.exchangeDeclare(exchangeName, BuiltinExchangeType.TOPIC, true, false, null);channel.queueDeclare(queue1, true, false, false, null);channel.queueDeclare(queue2, true, false, false, null);channel.queueBind(queue1, exchangeName, routing1);channel.queueBind(queue2, exchangeName, routing2);channel.queueBind(queue2, exchangeName, routing3);String message = "topic exchange";// queue1, queue2channel.basicPublish(exchangeName, "com.rabbitmq.client", MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes());// queue1channel.basicPublish(exchangeName, "org.rabbitmq.server", MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes());// queue2channel.basicPublish(exchangeName, "com.hidden.demo", MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes());// NONEchannel.basicPublish(exchangeName, "aaaa", MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes());}
headers
headers exchange 不依赖路由键的匹配规则来路由消息,而是根据消息的headers属性值,RabbitMQ收到消息后,对比消息的headers中的属性值是否与queue、exchange绑定时指定的属性值一致,如果完全匹配,则路由消息到队列。由于headers exchange 性能很差,所以这里不做代码演示,感兴趣的小伙伴可以实验一下。
以上就是对RabbitMQ中的一些概念做了一下介绍,小伙伴们可以多做实验加深理解,我也是在写了几个UnitTest之后,才理解这些概念,尤其是Exchange、RoutingKey 和 BindingKey。
感谢各位小伙伴的阅览,也很高兴能和各位小伙伴一起钻研探讨技术问题。
相关文章:
RabbitMQ相关概念介绍
这篇文章主要介绍RabbitMQ中几个重要的概念,对于初学者来说,概念性的东西可能比较难以理解,但是对于理解和使用RabbitMQ却必不可少,初学阶段,现在脑海里留有印象,随着后续更加深入的学习,就会很…...

在jenkins容器内部使用docker
在jenkins容器内部使用docker 1.使用本地的docker 进入/var/run,找到docker.sock [rootnpy run]# ls auditd.pid containerd cryptsetup dmeventd-client docker.pid initramfs lvm netreport sepermit sudo tmpfiles.d user chro…...

分布式事务解决方案
数据不会无缘无故丢失,也不会莫名其妙增加 一、概述 1、曾几何时,知了在一家小公司做项目的时候,都是一个服务打天下,所以涉及到数据一致性的问题,都是直接用本地事务处理。 2、随着时间的推移,用户量增…...

2022黑马Redis跟学笔记.实战篇(三)
2022黑马Redis跟学笔记.实战篇 三4.2.商家查询的缓存功能4.3.1.认识缓存4.3.1.1.什么是缓存4.3.1.2.缓存的作用1.为什么要使用缓存2.如何使用缓存3. 添加商户缓存4. 缓存模型和思路4.3.1.3.缓存的成本4.3.2.添加redis缓存4.3.3.缓存更新策略4.3.3.1.三种策略(1).内存淘汰:Redis…...
hadoop环境新手安装教程
1、资源准备: (1)jdk安装包:我的是1.8.0_202 (2)hadoop安装包:我的是hadoop-3.3.1 注意这里不要下载成下面这个安装包了,我就一开始下载错了 错误示例: 2、主机网络相…...
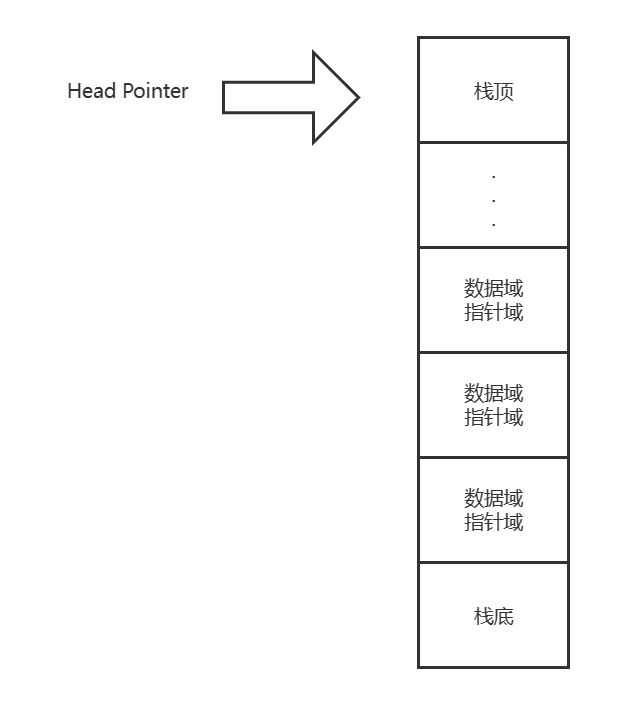
数据结构与算法基础-学习-11-线性表之链栈的初始化、判断非空、压栈、获取栈长度、弹栈、获取栈顶元素
一、个人理解链栈相较于顺序栈不存在上溢(数据满)的情况,除非内存不足,但存储密度会低于顺序栈,因为会多存一个指针域,其他逻辑和顺序表一致。总结如下:头指针指向栈顶。链栈没有头节点直接就是…...

Hive内置函数
文章目录Hive内置函数字符串函数时间类型函数数学函数集合函数条件函数类型转换函数数据脱敏函数其他函数用户自定义函数Hive内置函数 查询内置函数用法: DESCRIBE FUNCTION EXTENDED 函数名;字符串函数 字符串连接函数:concat带分隔符字符串连接函数…...
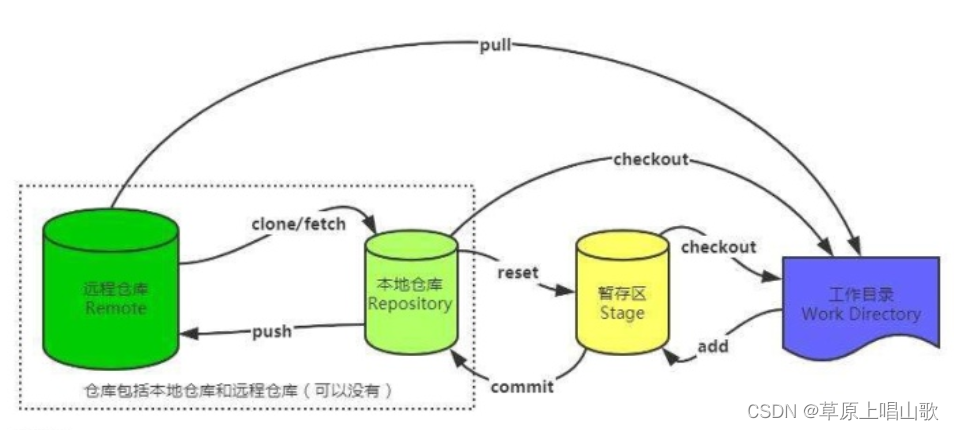
Git如何快速入门
什么是Git?我们开发的项目,也需要一个合适的版本控制系统来协助我们更好地管理版本迭代,而Git正是因此而诞生的(有关Git的历史,这里就不多做阐述了,感兴趣的小伙伴可以自行了解,是一位顶级大佬在…...
netcore构建webservice以及调用的完整流程
目录构建前置准备编写服务挂载服务处理SoapHeader调用添加服务调用服务补充内容构建 前置准备 框架版本要求:netcore3.1以上 引入nuget包 SoapCore 编写服务 1.编写服务接口 示例 using System.ServiceModel;namespace Services;[ServiceContract(Namespace &…...
)
Mysql事务基础(解析)
并发事务带来的问题A和B是并发事务脏写(A被B覆盖)两个事务。B事务覆盖了A事务。解决:应该事务并行脏读(B读到了A的执行中间结果)A修改了东西。B看到了他的中间状态。解决:读写冲突。加锁,改完再…...

2023 年首轮土地销售活动来了 与 The Sandbox 一起体验「体素狂热」!
2 月 14 日晚上 11 点,开始你的体素冒险。 The Sandbox 很高兴推出 2023 年的第一次土地销售活动。欢迎来到「体素狂热 (Voxel Madness)」! 简要概括 土地销售抽奖活动将于北京时间 2 月 14 日星期二晚上 11 点开始 「体素狂热」 土地销售活动将于 2 月…...

vue AntD中栅格布局的四种大小xs,sm,md,lg
cssBootstrap栅格布局的四种大小xs,sm,md,lg前端为了页面在不同大小的设备上也能够正常显示,通常会使用栅格布局的方式来实现。使用bootStrap的网格系统时,常见到一下格式的类名col-*-*visible-*-*hidden_*_* 中间可为xs,xsm,md,lg等表示大小的单词的缩写…...
打开窗口全屏)
window.open()打开窗口全屏
window.open (page.html, page, height100, width400, top0, left0, toolbarno, menubarno, scrollbarsno, resizableno,locationn o, statusno, fullscreenyes); 参数解释: window.open() 弹出新窗口的命令; ‘page.html’ 弹出窗口的文件名ÿ…...
VFIO软件依赖——VFIO协议
文章目录背景PCI设备模拟PCI设备抽象VFIO协议实验Q&A背景 在虚拟化应用场景中,虚拟机想要在访问PCI设备时达到IO性能最优,最直接的方法就是将物理设备暴露给虚拟机,虚拟机对设备的访问不经过任何中间层的转换,没有虚拟化的损…...

C/C++【内存管理】
✨个人主页: Yohifo 🎉所属专栏: C修行之路 🎊每篇一句: 图片来源 Love is a choice. It is a conscious commitment. It is something you choose to make work every day with a person who has chosen the same thi…...

第8篇:Java编程语言的8大优势
目录 1、简单性 2、面向对象 3、编译解释性 4、稳健性 5、安全性 6、跨平台性...

STM32定时器实现红外接收与解码
1.NEC协议 红外遥控是一种比较常用的通讯方式,目前红外遥控的编码方式中,应用比较广泛的是NEC协议。NEC协议的特点如下: 载波频率为 38KHz8位地址和 8位指令长度地址和命令2次传输(确保可靠性)PWM 脉冲位置调制&#…...
18- Adaboost梯度提升树 (集成算法) (算法)
Adaboost 梯度提升树: from sklearn.ensemble import AdaBoostClassifier model AdaBoostClassifier(n_estimators500) model.fit(X_train,y_train) 1、Adaboost算法介绍 1.1、算法引出 AI 39年(公元1995年),扁鹊成立了一家专治某疑难杂症…...
zlink 介绍
zlink 是一个基于 flink 开发的分布式数据开发工具,提供简单的易用的操作界面,降低用户学习 flink 的成本,缩短任务配置时间,避免配置过程中出现错误。用户可以通过拖拉拽的方式实现数据的实时同步,支持多数据源之间的…...

C++之std::string的resize与reverse
std::string的resize与reverse前言1.resize2.reserve前言 在C中我们经常用std::string 来保存字符串,其中有两个比较常用但是却平时容易被搞混的两个函数,分别是resize和reserve,模糊意识里,这两个方法都是对std::string的容量或元…...

探索照片转3D模型:用Meshroom实现7步从2D到3D的蜕变
探索照片转3D模型:用Meshroom实现7步从2D到3D的蜕变 【免费下载链接】Meshroom 3D Reconstruction Software 项目地址: https://gitcode.com/gh_mirrors/me/Meshroom 定位3D重建价值:打破技术壁垒的开源方案 在数字创作领域,3D模型一…...

FPGA时序优化全攻略:Vivado 2019.2中的建立与保持时间问题解决
FPGA时序优化全攻略:Vivado 2019.2中的建立与保持时间问题解决 在高速FPGA设计中,时序问题往往是工程师面临的最大挑战之一。当设计频率提升到200MHz甚至更高时,建立时间和保持时间的违例会频繁出现,导致设计无法正常工作。本文将…...

GIL已死,但并发未生:从字节码级剖析无锁Python的7类竞态陷阱与4种Lock-Free算法选型矩阵
第一章:GIL已死,但并发未生:无锁Python并发范式的认知重构Python的全局解释器锁(GIL)长期被视为并发编程的“原罪”,但自CPython 3.13起,GIL在I/O密集型路径中已被条件性移除,而3.14…...

VMware虚拟机体验FLUX.1:Windows系统免环境配置方案
VMware虚拟机体验FLUX.1:Windows系统免环境配置方案 想快速体验最新的AI绘画技术却苦于环境配置?FLUX.1作为当前最强的开源文生图模型之一,让很多Windows用户望而却步。本文介绍一种零门槛的解决方案——通过VMware虚拟机一键体验,…...

中文医疗大模型避坑指南:从MedBench评测看5大常见训练误区
中文医疗大模型实战避坑手册:从MedBench看模型训练的5个致命盲区 当ChatGPT掀起通用大模型的热潮时,医疗领域正在经历一场更为严谨的技术革命。不同于开放域的对话生成,医疗大模型的每个输出都可能直接影响临床决策——这要求开发者必须跨越专…...

星穹铁道自动化解决方案:用March7thAssistant释放游戏时间价值
星穹铁道自动化解决方案:用March7thAssistant释放游戏时间价值 【免费下载链接】March7thAssistant 🎉 崩坏:星穹铁道全自动 Honkai Star Rail 🎉 项目地址: https://gitcode.com/gh_mirrors/ma/March7thAssistant 副标题&…...

为什么你的Pyd文件在Windows上总报“DLL加载失败”?系统级依赖扫描、Manifest嵌入与UCRT版本对齐终极方案
第一章:Pyd文件在Windows上的本质与加载机制Pyd 文件是 Windows 平台上 Python 的 C 扩展模块的二进制格式,其本质是遵循特定 ABI 约束的动态链接库(DLL),但被 Python 解释器以特殊方式识别和加载。它并非普通 DLL&…...

B站视频下载终极指南:DownKyi高效工具完整使用教程
B站视频下载终极指南:DownKyi高效工具完整使用教程 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等ÿ…...

别再瞎找了!盘点2026年顶流之选的AI论文写作软件
一天写完毕业论文在2026年已不再是天方夜谭。2026年最炸裂的AI论文写作软件来了,实测提速效果惊人,覆盖选题、撰写、查重、排版全流程,让你高效搞定论文不再难。 一、全流程王者:一站式搞定论文全链路(一天定稿首选&am…...

在六亩半,春天不是日历上的数字,而是泥土间的青草香
当城市里的春天还停留在气温起伏的天气预报里,六亩半手作文创园的春意,早已从土地深处探出头来。那是荠菜嫩芽拱开泥土的力道,是柳条抽出新绿的柔软,是孩子们蹲在田埂上、指尖沾满青草汁液的鲜活记忆。在这里,春天不是…...