【Calcite源码学习】ImmutableBitSet介绍
Calcite中实现了一个ImmutableBitSet类,用于保存bit集合。在很多优化规则和物化视图相关的类中都使用了ImmutableBitSet来保存group by字段或者聚合函数参数字段对应的index,例如:
//MaterializedViewAggregateRule#compensateViewPartial()
ImmutableBitSet.Builder groupSet = ImmutableBitSet.builder();
groupSet.addAll(aggregateViewNode.getGroupSet());
groupSet.addAll(ImmutableBitSet.range(aggregateViewNode.getInput().getRowType().getFieldCount(),aggregateViewNode.getInput().getRowType().getFieldCount() + offset));
因此,本文我们就来看一看这个ImmutableBitSet一些核心的操作函数。
使用示例
这里我们介绍一个ImmutableBitSet使用的例子,后续相关的函数操作说明会使用这个例子:
ImmutableBitSet.Builder builder = ImmutableBitSet.builder();
builder.set(3);
builder.set(5);
builder.set(67);
builder.set(70);
builder.set(129);
ImmutableBitSet bitSet = builder.build();
System.out.println(bitSet.cardinality());
System.out.println(bitSet.nth(1));
如上所示,通常先构造一个Builder,然后set指定的bit位,最终构造生成ImmutableBitSet。下面来看一下主要的成员和关键函数。
主要成员
ImmutableBitSet中比较重要的几个成员变量如下所示:
private static final int ADDRESS_BITS_PER_WORD = 6;
private static final int BITS_PER_WORD = 1 << ADDRESS_BITS_PER_WORD;private static final long[] EMPTY_LONGS = new long[0];private static final ImmutableBitSet EMPTY = new ImmutableBitSet(EMPTY_LONGS);private final long[] words;
这些变量含义如下:
- 这里最主要的变量就是words,这是一个long类型的数组,实际存储设置的bit位;
- Long是64位,使用6个bit就可以表示,因此ADDRESS_BITS_PER_WORD设置为6,用来进行一些二进制的左移和右移的运算;
- BITS_PER_WORD表示将1左移6位,结果就是64。当words数组中存在多个成员的时候,取指定long成员对应的bit位时会用到,后面会详细介绍,这里不再赘述。
Builder相关函数
要使用ImmutableBitSet,我们首先需要构造一个ImmutableBitSet.Builder,因此先看一下这个Builder的关键函数。
set(int i)
set函数是最常用的,将指定位的bit设置为true,表示该位上面有值,对应的函数代码如下所示:
public Builder set(int bit) {if (words == null) {throw new IllegalArgumentException("can only use builder once");}int wordIndex = wordIndex(bit);if (wordIndex >= words.length) {words = Arrays.copyOf(words, wordIndex + 1);}words[wordIndex] |= 1L << bit;return this;
}private static int wordIndex(int bitIndex) {return bitIndex >> ADDRESS_BITS_PER_WORD;
}
通过这个函数,就可以往Builder里面设置对应的bit位,上述代码主要处理逻辑如下:
- 通过传入的bit位,获取在words中的索引,即数组的下标,通过wordIndex函数来实现。这个函数只有一行代码,即将传入的bit右移6位。其效果是:0~63会返回0,表示存储在words中的第一个long成员;64~127返回1,表示存储在words中的第二个long成员,以此类推;
- 如果word索引大于当前数组的长度,则会扩容,数组长度+1;
- 将1L左移bit位,并与指定index的数组成员,即words[wordIndex]进行或操作,并更新到当前数组成员,然后返回。
这里我们结合上述的例子来看一下:
//3 >> 6 = 0,表示wordIndex是0,存储在第一个long成员;1L << 3,得到的结果是0000 1000
builder.set(3);
//5 >> 6 = 0,表示wordIndex是0,存储在第一个long成员;1L << 5,得到的结果是0010 0000
builder.set(5);
//67 >> 6 = 1,表示wordIndex是1,存储在第二个long成员;1L << 67,得到的结果是0000 1000
builder.set(67);
//70 >> 6 = 1,表示wordIndex是1,存储在第二个long成员;1L << 70,得到的结果是0100 1000
builder.set(70);
//129 >> 6 = 2,表示wordIndex是2,存储在第三个long成员;1L << 129,得到的结果是0000 0010
builder.set(129);
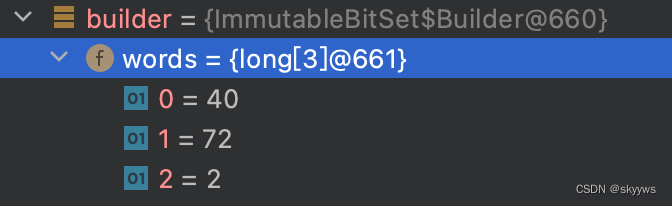
这里我们只展示了二进制的最后8位,前面56位都是0,因此省略。此时,words包含3个long成员,分别是:
- 第一个long成员的值就是0000 1000 | 0010 0000 = 0010 1000,十进制是40;
- 第二个long成员的值就是0000 1000 | 0100 0000 = 0100 1000,十进制是72;
- 第三个long成员的值就是0000 0010,十进制是2;
我们通过debug可以进行验证:
需要注意的是,在对1L进行左移操作时,由于long是64位的,因此我们需要先对bit进行64取余操作,因此上面大于64的左移操作实际效果如下:
1L << 67 => 1L << (67 % 64) => 1L << 3 => 0000 1000
1L << 70 => 1L << (70 % 64) => 1L << 6 => 0100 0000
1L << 129 => 1L << (129 % 64) => 1L << 1 => 0000 0010
build()
Builder填充完成之后,就可以通过build()方法来生成ImmutableBitSet对象了。这个函数比较简单,就是将words成员作为参数来构造ImmutableBitSet,同时将words成员本身置空。也就是说,Builder只能调用一次build(),这点需要注意。
addAll(ImmutableBitSet bitSet)
set方法只能设置单个bit位,如果想要批量设置的话,可以调用addAll()函数。这个函数有三个重载方法,这里我们看一下与ImmutableBitSet相关的:
public Builder addAll(ImmutableBitSet bitSet) {for (Integer bit : bitSet) {set(bit);}return this;
}
该方法比较简单,就是通过ImmutableBitSet的iterator()方法来获取每一个bit,然后set到当前的Builder中。关于iterator()处理逻辑,我们下面再介绍。
ImmutableBitSet相关函数
看完Builder常用的几个函数后,我们再来看一下ImmutableBitSet相关的函数。
cardinality()
这个函数会返回当前ImmutableBitSet包含的所有bit位,相关代码如下所示:
public int cardinality() {return countBits(words);
}private static int countBits(long[] words) {int sum = 0;for (long word : words) {sum += Long.bitCount(word);}return sum;
}
可以看到,实际是通过countBits函数来进行统计的。该函数会遍历words数组所有的成员,依次统计每个成员包含的bit位,然后累计求和。在上述例子中,对应的cardinality就是5,表示一共有5个bit位被设置为true,前面两个成员分别包含2个为true的bit位,第三个成员包含1个。
nth(int)
该函数是Calcite中也会经常用到的。该函数的功能是取第n位对应的值,代码如下所示:
public int nth(int n) {int start = 0;for (long word : words) {final int bitCount = Long.bitCount(word);if (n < bitCount) {while (word != 0) {if ((word & 1) == 1) {if (n == 0) {return start;}--n;}word >>= 1;++start;}}start += 64;n -= bitCount;}throw new IndexOutOfBoundsException("index out of range: " + n);
}
代码对应的主要处理逻辑如下:
- 遍历words数组,通过每个成员包含的bit位数量,来确定第n个bit位于哪个数组成员;
- 遍历的同时,更新每个数组成员对应的起始值start,第一个成员是0,第二个成员是64,第三个成员是128,依次类推;
- 定位到对应的数组成员之后,循环处理这个long,每次右移1位,然后start加1;
- 右移1位之后,判断long的最后一位是否为1;是的话,则表示该bit位被set过,然后再判断是否为第n个bit,是的话,则直接返回start。否则继续右移long,然后更新start。
我们结合上述示例来看一下这个处理过程。n=3时,整个流程如下所示:

iterator()
上面我们提到,Builder.addAll()函数主要就是通过ImmutableBitSet的迭代器iterator()来实现批量set的,这里我们就来看一下ImmutableBitSet是如何实现的。当我们使用for循环取ImmutableBitSet的成员时,会自动调用迭代器的next()函数不断获取下一个成员,next()函数实现:
//ImmutableBitSet#iterator()
@Override public Integer next() {int prev = i;i = nextSetBit(i + 1);return prev;
}
可以看到,这里主要是通过nextSetBit()函数来取下一个bit位的,下面我们看下这个函数的实现逻辑。
nextSetBit(int fromIndex)
这个函数是用来取给定bit位以及其之后的,下一个被set的bit位(包含fromIndex对应的bit位本身),函数代码如下所示:
public int nextSetBit(int fromIndex) {if (fromIndex < 0) {throw new IndexOutOfBoundsException("fromIndex < 0: " + fromIndex);}int u = wordIndex(fromIndex);if (u >= words.length) {return -1;}long word = words[u] & (WORD_MASK << fromIndex);while (true) {if (word != 0) {return (u * BITS_PER_WORD) + Long.numberOfTrailingZeros(word);}if (++u == words.length) {return -1;}word = words[u];}
}
函数代码主要的处理逻辑如下:
- 获取传入index所在的数组成员下标,即位于第几个数组成员中;
- 将word mask右移index位,例如index为3,则结果是1111 1000(省略mask前面的1),然后将该结果与对应的数组成员进行与操作,得到一个新的word。这行代码的目的是为了屏蔽index前面的成员,进行后续的比较。例如数组成员是1111 1111,与操作的结果则是1111 1000。那么word最后三个1(对应十进制的1、2、4)都被屏蔽;
- 如果word为空,表示传入的index,不在当前这个word中,对应的bit没有被set,此时更新word为下一个数组成员。由于下一个数组成员的起始index是必定大于传入index的,因此word不需要进行上面的左移和与操作;
- word不为空,先获取trailing zero数量,然后加上实际的offset即可(数组成员每往后移动一个,index起始offset就要加64)。
我们同样使用上述的例子来看一下。fromIndex设置为6时,整个流程如下所示:

get(int bitIndex)
该函数是用来判断bit set的指定bit位是否被set为true,函数代码如下:
public boolean get(int bitIndex) {if (bitIndex < 0) {throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);}int wordIndex = wordIndex(bitIndex);return (wordIndex < words.length)&& ((words[wordIndex] & (1L << bitIndex)) != 0);
}
核心的代码逻辑就是words[wordIndex] & (1L << bitIndex),如果为0,表示对应bit没有被set,即为0。这里我们仍然结合上述例子来看:
//假设bitIndex为69,此时位于words的第二个数组成员,范围为64~127
1L << 69 => 1L << (75 % 69) => 1L << 6 => 0100 0000
0100 1000 & 0100 0000 = 0100 0000
//假设bitIndex为75,此时位于words的第二个数组成员,范围为64~127
1L << 75 => 1L << (75 % 64) => 1L << 11 => 1000 0000 0000
0000 0100 1000 & 1000 0000 0000 = 0
因此,get(69)返回true,对应上述示例的set(70);get(75)则返回false。
小结
本文主要介绍了Builder和ImmutableBitSet中的一些关键函数的处理逻辑,并结合示例展示了具体的用法。ImmutableBitSet还有不少其他的函数,其中大多都是基于上述的函数进行实现或者本身实现比较简单,这里不再一一介绍,有兴趣的同学可以自行阅读源码。
关于Calcite为什么要开发一个这样的bit set,笔者猜测应该是跟逻辑执行计划有关。使用ImmutableBitSet可以通过与操作快速判断字段对应的index是否在bit set中,效率比较高。后续阅读到planner优化相关的代码时,再做分享。
相关文章:
【Calcite源码学习】ImmutableBitSet介绍
Calcite中实现了一个ImmutableBitSet类,用于保存bit集合。在很多优化规则和物化视图相关的类中都使用了ImmutableBitSet来保存group by字段或者聚合函数参数字段对应的index,例如: //MaterializedViewAggregateRule#compensateViewPartial()…...

RabbitMQ相关概念介绍
这篇文章主要介绍RabbitMQ中几个重要的概念,对于初学者来说,概念性的东西可能比较难以理解,但是对于理解和使用RabbitMQ却必不可少,初学阶段,现在脑海里留有印象,随着后续更加深入的学习,就会很…...

在jenkins容器内部使用docker
在jenkins容器内部使用docker 1.使用本地的docker 进入/var/run,找到docker.sock [rootnpy run]# ls auditd.pid containerd cryptsetup dmeventd-client docker.pid initramfs lvm netreport sepermit sudo tmpfiles.d user chro…...

分布式事务解决方案
数据不会无缘无故丢失,也不会莫名其妙增加 一、概述 1、曾几何时,知了在一家小公司做项目的时候,都是一个服务打天下,所以涉及到数据一致性的问题,都是直接用本地事务处理。 2、随着时间的推移,用户量增…...

2022黑马Redis跟学笔记.实战篇(三)
2022黑马Redis跟学笔记.实战篇 三4.2.商家查询的缓存功能4.3.1.认识缓存4.3.1.1.什么是缓存4.3.1.2.缓存的作用1.为什么要使用缓存2.如何使用缓存3. 添加商户缓存4. 缓存模型和思路4.3.1.3.缓存的成本4.3.2.添加redis缓存4.3.3.缓存更新策略4.3.3.1.三种策略(1).内存淘汰:Redis…...
hadoop环境新手安装教程
1、资源准备: (1)jdk安装包:我的是1.8.0_202 (2)hadoop安装包:我的是hadoop-3.3.1 注意这里不要下载成下面这个安装包了,我就一开始下载错了 错误示例: 2、主机网络相…...
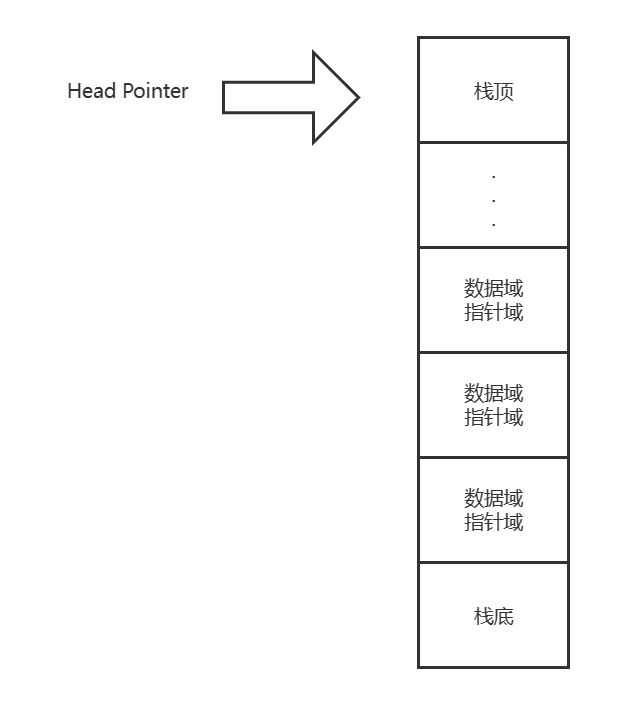
数据结构与算法基础-学习-11-线性表之链栈的初始化、判断非空、压栈、获取栈长度、弹栈、获取栈顶元素
一、个人理解链栈相较于顺序栈不存在上溢(数据满)的情况,除非内存不足,但存储密度会低于顺序栈,因为会多存一个指针域,其他逻辑和顺序表一致。总结如下:头指针指向栈顶。链栈没有头节点直接就是…...

Hive内置函数
文章目录Hive内置函数字符串函数时间类型函数数学函数集合函数条件函数类型转换函数数据脱敏函数其他函数用户自定义函数Hive内置函数 查询内置函数用法: DESCRIBE FUNCTION EXTENDED 函数名;字符串函数 字符串连接函数:concat带分隔符字符串连接函数…...
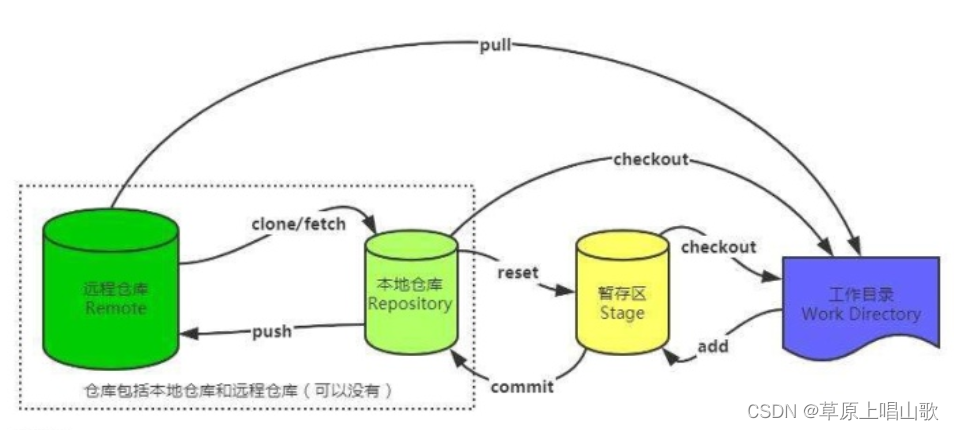
Git如何快速入门
什么是Git?我们开发的项目,也需要一个合适的版本控制系统来协助我们更好地管理版本迭代,而Git正是因此而诞生的(有关Git的历史,这里就不多做阐述了,感兴趣的小伙伴可以自行了解,是一位顶级大佬在…...
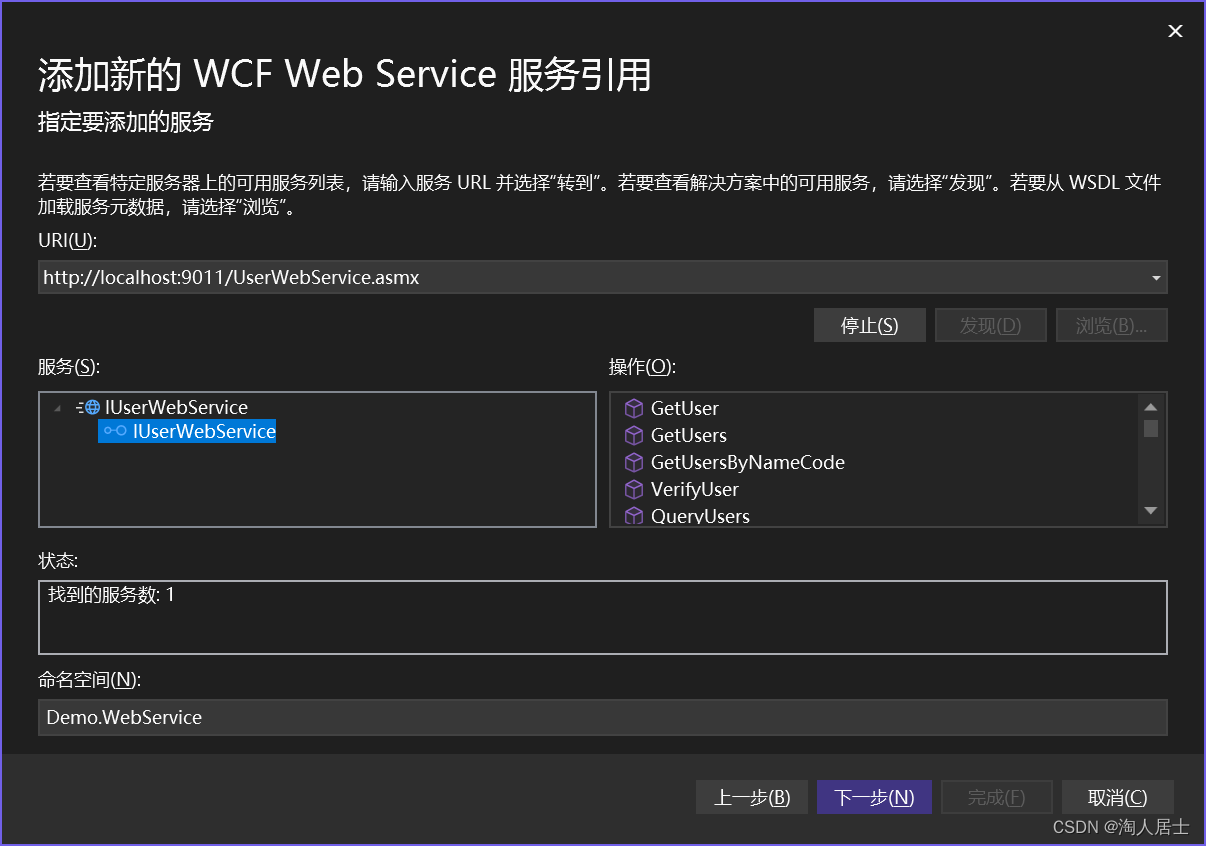
netcore构建webservice以及调用的完整流程
目录构建前置准备编写服务挂载服务处理SoapHeader调用添加服务调用服务补充内容构建 前置准备 框架版本要求:netcore3.1以上 引入nuget包 SoapCore 编写服务 1.编写服务接口 示例 using System.ServiceModel;namespace Services;[ServiceContract(Namespace &…...
)
Mysql事务基础(解析)
并发事务带来的问题A和B是并发事务脏写(A被B覆盖)两个事务。B事务覆盖了A事务。解决:应该事务并行脏读(B读到了A的执行中间结果)A修改了东西。B看到了他的中间状态。解决:读写冲突。加锁,改完再…...

2023 年首轮土地销售活动来了 与 The Sandbox 一起体验「体素狂热」!
2 月 14 日晚上 11 点,开始你的体素冒险。 The Sandbox 很高兴推出 2023 年的第一次土地销售活动。欢迎来到「体素狂热 (Voxel Madness)」! 简要概括 土地销售抽奖活动将于北京时间 2 月 14 日星期二晚上 11 点开始 「体素狂热」 土地销售活动将于 2 月…...

vue AntD中栅格布局的四种大小xs,sm,md,lg
cssBootstrap栅格布局的四种大小xs,sm,md,lg前端为了页面在不同大小的设备上也能够正常显示,通常会使用栅格布局的方式来实现。使用bootStrap的网格系统时,常见到一下格式的类名col-*-*visible-*-*hidden_*_* 中间可为xs,xsm,md,lg等表示大小的单词的缩写…...
打开窗口全屏)
window.open()打开窗口全屏
window.open (page.html, page, height100, width400, top0, left0, toolbarno, menubarno, scrollbarsno, resizableno,locationn o, statusno, fullscreenyes); 参数解释: window.open() 弹出新窗口的命令; ‘page.html’ 弹出窗口的文件名ÿ…...
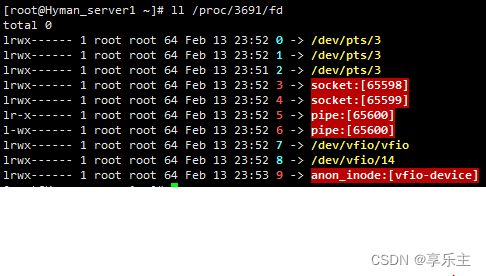
VFIO软件依赖——VFIO协议
文章目录背景PCI设备模拟PCI设备抽象VFIO协议实验Q&A背景 在虚拟化应用场景中,虚拟机想要在访问PCI设备时达到IO性能最优,最直接的方法就是将物理设备暴露给虚拟机,虚拟机对设备的访问不经过任何中间层的转换,没有虚拟化的损…...

C/C++【内存管理】
✨个人主页: Yohifo 🎉所属专栏: C修行之路 🎊每篇一句: 图片来源 Love is a choice. It is a conscious commitment. It is something you choose to make work every day with a person who has chosen the same thi…...

第8篇:Java编程语言的8大优势
目录 1、简单性 2、面向对象 3、编译解释性 4、稳健性 5、安全性 6、跨平台性...

STM32定时器实现红外接收与解码
1.NEC协议 红外遥控是一种比较常用的通讯方式,目前红外遥控的编码方式中,应用比较广泛的是NEC协议。NEC协议的特点如下: 载波频率为 38KHz8位地址和 8位指令长度地址和命令2次传输(确保可靠性)PWM 脉冲位置调制&#…...
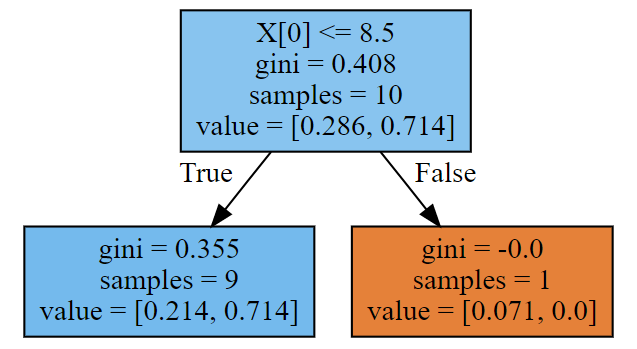
18- Adaboost梯度提升树 (集成算法) (算法)
Adaboost 梯度提升树: from sklearn.ensemble import AdaBoostClassifier model AdaBoostClassifier(n_estimators500) model.fit(X_train,y_train) 1、Adaboost算法介绍 1.1、算法引出 AI 39年(公元1995年),扁鹊成立了一家专治某疑难杂症…...
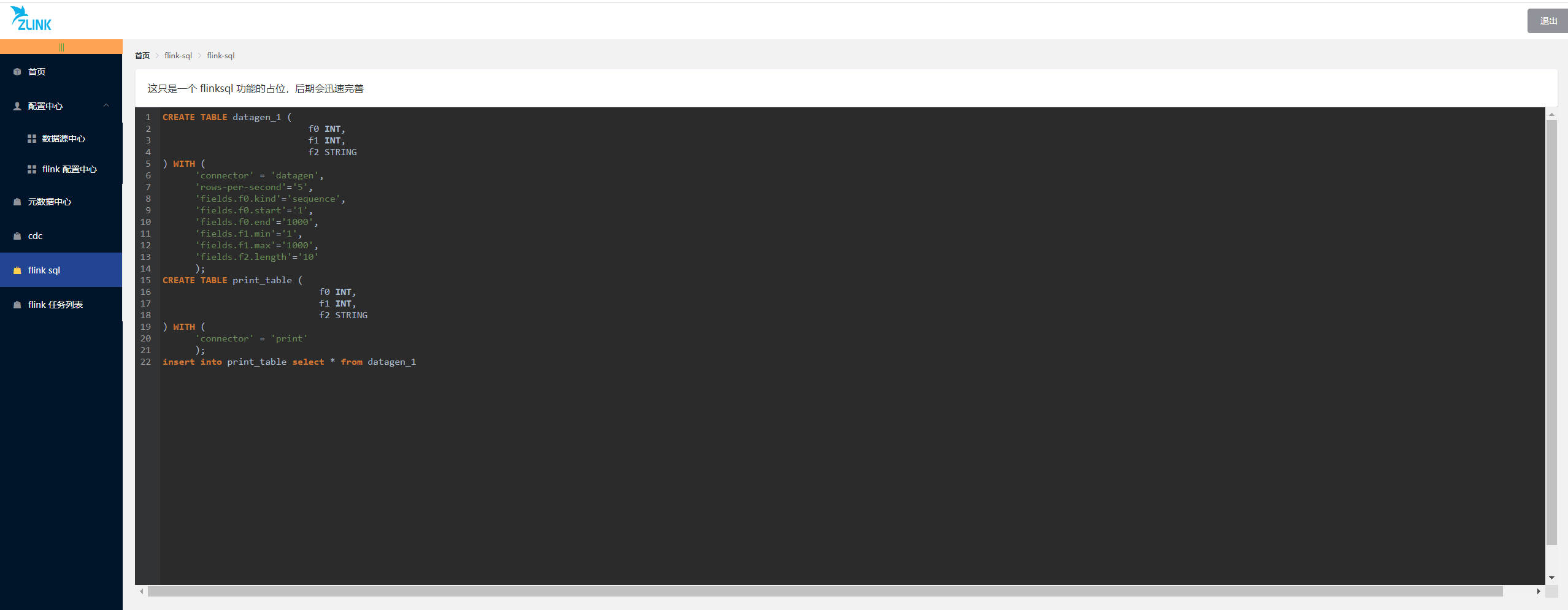
zlink 介绍
zlink 是一个基于 flink 开发的分布式数据开发工具,提供简单的易用的操作界面,降低用户学习 flink 的成本,缩短任务配置时间,避免配置过程中出现错误。用户可以通过拖拉拽的方式实现数据的实时同步,支持多数据源之间的…...

Tiled2Unity:解决Tiled地图与Unity引擎无缝集成的自动化转换方案
Tiled2Unity:解决Tiled地图与Unity引擎无缝集成的自动化转换方案 【免费下载链接】Tiled2Unity Export Tiled Map Editor (TMX) files into Unity 项目地址: https://gitcode.com/gh_mirrors/ti/Tiled2Unity Tiled2Unity是一款开源工具,核心功能是…...

Go 并发编程的常见陷阱
Go语言凭借轻量级协程和高效的并发模型,成为高并发场景的热门选择。其简洁的并发语法背后隐藏着诸多陷阱,稍有不慎就会引发数据竞争、死锁等问题。本文将剖析三个典型并发陷阱,帮助开发者避开暗礁,写出健壮的并发程序。**共享变量…...

Wandb账号串线了?手把手教你排查和修复‘实验记录跑到别人账户’的坑
Wandb账号串线排查指南:如何避免实验记录跑到他人账户 实验室的GPU服务器指示灯闪烁着,你刚提交的模型训练任务在终端显示"Run completed successfully",但刷新了十几次Wandb面板——那些期待中的损失曲线和评估指标依然不见踪影。…...

Redis集群模式下如何高效模糊匹配Key?RedisTemplate+Scan全节点遍历实战
Redis集群环境下高效模糊匹配Key的工程实践 Redis作为高性能缓存数据库,在分布式系统中扮演着重要角色。当系统规模扩大,单节点Redis无法满足需求时,集群模式成为必然选择。但在集群环境下,如何高效地进行模糊Key匹配却成为开发者…...

别再死记公式!一张图带你理清随机过程家族:从泊松、马尔可夫到维纳过程
随机过程家族图谱:用生活场景破解泊松、马尔可夫与维纳过程 想象一下午后的咖啡馆,顾客推门的间隔时间、咖啡师制作饮品的速度、甚至窗外飘落的樱花轨迹——这些看似无关的现象,背后都藏着随机过程的精妙规律。对于学习《随机过程》的同学们来…...

OpenClaw技能市场盘点:10个适配Qwen3.5-4B-Claude的实用模块
OpenClaw技能市场盘点:10个适配Qwen3.5-4B-Claude的实用模块 1. 为什么需要关注技能市场? 去年冬天,当我第一次在本地部署OpenClaw时,最让我惊喜的不是框架本身,而是它背后那个不断生长的技能市场。作为一个长期被重…...

回溯法与剪枝优化:高效求解n位逐位整除数的实战解析
1. 什么是n位逐位整除数? n位逐位整除数是一种特殊的数字序列,它满足从最高位开始,前k位组成的数字必须能被k整除(k从1到n)。举个例子,数字102450就是一个6位整除数: 第1位1能被1整除前2位10能被…...

Android日志记录终极指南:如何用Timber提升开发效率
Android日志记录终极指南:如何用Timber提升开发效率 【免费下载链接】timber JakeWharton/timber: 是一个 Android Log 框架,提供简单易用的 API,适合用于 Android 开发中的日志记录和调试。 项目地址: https://gitcode.com/gh_mirrors/ti/…...

【PolarCTF2026年春季挑战赛】GET
直接上传一个php试试文件名后缀双写可以绕过可以解析,我们上传一句话木马提示出现了$_POST[cmd]那么用下面的webshell,避免POST和cmd一起出现<?php $x $_POST; eval($x[cmd]); ?>上传成功,访问一下得到flag{73121d2832f501293a2e661…...

单目双目相机精准标定与IMU联合校准技术
单目双目相机标定。 相机、imu联合标定。标定这玩意儿说难不难,说简单吧又总有几个坑等着你跳。搞视觉的兄弟们肯定都懂,传感器不准的时候那真是两眼一抹黑。咱们今天直接上干货,聊聊单目双目相机标定,顺带把相机和IMU的联合标定也…...