《Hadoop篇》------大数据及Hadoop入门
目录
一、大数据及Hadoop入门
1.1 单节点、分布式、集群
1.1.1 大数据的概念
1.1.2 大数据的本质
二、HDFS Shell命令
2.1、常用相关命令
2.2、上传文件
2.2.1、上传文件介绍
2.2.2上传文件操作
2.3、下载文件
2.4、删除文件
2.5、创建目录
2.6、查看文件系统
2.7、拷贝文件
三、分布式系统原理
3.1、数据块
四、HDFS架构
五、Datanode服役(上线)和退役(下线)
5.1分发到其他节点
5.2、格式化并启动HDFS
5.3、更新hdfs
六、Centos权限管理
6.1、权限介绍
6.2、修改权限
七、HDFS进程启动流程
八、Hadoop配置文件解释
8.1 hadoop内核和环境配置
8.2、mapreduce配置
8.3、yarn配置
8.4、slaves配置
九、hdfs及yarn启动验证:进程启动命令
一、大数据及Hadoop入门
1.1 单节点、分布式、集群
1.1.1 大数据的概念
大数据的5v特点
Volume:大量
Velocity:高速
Variety:多样
Value:价值
Veracity:真实性
1.1.2 大数据的本质
大数据的本质就是利用计算机集群来处理大批量的数据,大数据的技术关注点在于如何将数据分发给不同的计算机进行存储和处理。
✳ 1)单台计算机存储这些数据都是很困难的,那怎么办?
答:分发到不同的计算机存储。
✳ 2)只存储有没有意义?
答:无意义,存储是需要投入场地,投入服务器硬件设施,都需要钱维护。
✳ 3)那存储后需要什么?怎么样让存储变得有意义?
答:认真分析,真正地把数据转换成有价值的虚拟产品。
二、HDFS Shell命令
2.1、常用相关命令
hdfs dfs-cat //查看
hdfs dfs-copyFromLocal //从本地复制
hdfs dfs-copyToLocal //复制至本地
hdfs dfs-cp //复制
hdfs dfs-get //获取
hdfs dfs-ls //查看
hdfs dfs-mkdir //创建文件
hdfs dfs-put //传输
hdfs dfs-rm //删除2.2、上传文件
2.2.1、上传文件介绍
(1)全称形式
hdfs dfs-put ./file hdfs://hadoop1:9000/
hdfs dfs-copyfromlocal ./file hdfs://hadoop1:9000/
(2)省略写法
hdfs dfs-put ./file /
hdfs dfs-copyfromlocal ./file /
问题:为什么能够省略具体hdfs对应ip地址呢?
答:配置了core-site.xml
2.2.2上传文件操作
-put方式上传
[root@hadoop1 ~]# cd /home/java
[root@hadoop1 java]# ls
jdk jdk_1.8.0_131.tar.gz
[root@hadoop1 java]# hdfs dfs -put ./jdk_1.8.0_131.tar.gz hdfs://hadoop1:9000/
-copyFromLocal方式上传
[root@hadoop1 ~]# cd /home/java
[root@hadoop1 java]# ls
jdk jdk_1.8.0_131.tar.gz
[root@hadoop1 java]# hdfs dfs -put ./jdk_1.8.0_131.tar.gz hdfs://hadoop1:9000/
2.3、下载文件
hdfs dfs -get HDFS的根路径下的文件 本地的文件系统
hdfs dfs -get hdfs://hadoop1:9000/hadoop-2.6.1.tar.gz ./
hdfs dfs -copyToLocal /jdk_1.8.0_131.tar.gz ./
前面一个/代表HDFS的根路径,后面一个/代表Linux的根路径
2.4、删除文件
rm -rf dir 删除Linux本地文件系统中对应目录
hdfs dfs -rm /hadoop-2.6.1.tar.gz 删除hdfs文件系统中的内容
hdfs dfs -rm -r /dir 删除目录和子目录
2.5、创建目录
hdfs dfs -mkdir /dir 一个目录,不是递归目录
hdfs dfs -mkdir -p /dir1/dir2 递归目录
2.6、查看文件系统
hdfs dfs -ls /
2.7、拷贝文件
cp jdk_1.8.0_131.tar.gz jdk_1 将后者拷贝到前者所在的文件夹中 Linux本地执行
hdfs dfs -cp /jdk_1.8.0_131.tar.gz /jdk1 HDFS文件系统中
三、分布式系统原理
3.1、数据块
把数据切分成一个个固定大小的块(物理切分,不是逻辑切分),将这些块存储到分布式文件系统上
四、HDFS架构
HDFS的文件是在物理上分块存储的 (hadoop2.x版本它的默认blocksize大小128M)
五、Datanode服役(上线)和退役(下线)
5.1分发到其他节点
scp /home/hadoop/hadoop-2.6.1/etc/hadoop/slaves hadoop2:/home/hadoop/hadoop-2.6.1/etc/hadoop/ 分发到其他节点
5.2、格式化并启动HDFS
hdfs namenode -format
start-dfs.sh
格式化,并启动HDFS
5.3、更新hdfs
hdfs dfsadmin -refreshNodes
六、Centos权限管理
6.1、权限介绍
每一组信息如“rwx”,每一个字符都有它自己的特定含义且先后位置是固定的,其中r是读权限、w是写权限、x是可执行权限、-没有对应字符的权限
Linux里面对这些字符设置对应的数值,r是4,w是2,x是1,-是0。“rwx”则是7(=4+2+1)
6.2、修改权限
修改文件夹及子文件夹所有文件
chown 或 chomd -R “权限”或“名:组” 文件夹名称
七、HDFS进程启动流程
DataNode:负责数据块的存储,它是HDFS的小弟
Namenode:负责元数据的存储,接收客户端的请求,维护整个HDFS集群的目录树
Secondary:辅助namenode管理,分担namenode压力
八、Hadoop配置文件解释
8.1 hadoop内核和环境配置
(1)hadoop-env.sh:配置JDK的路径
(2)core-site.xml:配置Hadoop集群的元数据存储路径,配置主节点在哪一台机器上
<configuration><property><name>fs.defaultFS</name><value>hdfs://hadoop1:9000</value>指定namenode将来在哪一台节点启动,通信端口是9000,是fileSystem默认的端口号</property><property><name>hadoop.tmp.dir </name><value>/usr/hadoop-2.6.1/hdpdata</value>指定元数据存储的路径,hdpdata是在执行 hdfs namenode -format后才会自动生成</property></configuration>
8.2、mapreduce配置
主要配置mapred-site.xml
MR资源调度用Yarn
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
8.3、yarn配置
配置yarn-site.xml
<configuration><property><name>yarn.resourceManager.hostname</name><value>hadoop1</value>配置Yarn老大【resourceManager】将来在哪一台节点启动,注意是自己的master</property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>yarn的子服务,必须使用mapreduce_shuffle</property></configuration
8.4、slaves配置
[root@hadoop1 hadoop]# cat /home/hadoop/hadoop-2.6.1/etc/hadoop/slaveshadoop1hadoop2hadoop3指定datanode将来在哪台节点启动
注:在一台节点上的相关配置修改,要分发到全部集群上
例:
[root@hadoop1 hadoop]#scp mapred-site.xml hadoop2:/home/hadoop/hadoop-2.6.1/etc/hadoop
九、hdfs及yarn启动验证:进程启动命令
namenode -format
格式化HDFS的作用是初始化集群
(1)HDFS的相关进程:
Namenode(老大)
Datanode(小弟)
SecondaryNameNode(checkpoint节点)
(2)Yarn相关进程
Resourcemanager(老大)
Nodemanager(小弟)
hdfs和yarn相关进程都启动后,hdfs集群管理页面和yarn管理界面才可访问成功
start-dfs.sh
start-yarn.sh
这两个命令等效于start-all.sh
kill - 9
强制杀死该进程
hadoop-daemon.sh start namenode
单独启动HDFS相关的进程
相关文章:

《Hadoop篇》------大数据及Hadoop入门
目录 一、大数据及Hadoop入门 1.1 单节点、分布式、集群 1.1.1 大数据的概念 1.1.2 大数据的本质 二、HDFS Shell命令 2.1、常用相关命令 2.2、上传文件 2.2.1、上传文件介绍 2.2.2上传文件操作 2.3、下载文件 2.4、删除文件 2.5、创建目录 2.6、查看文件系统 2.…...
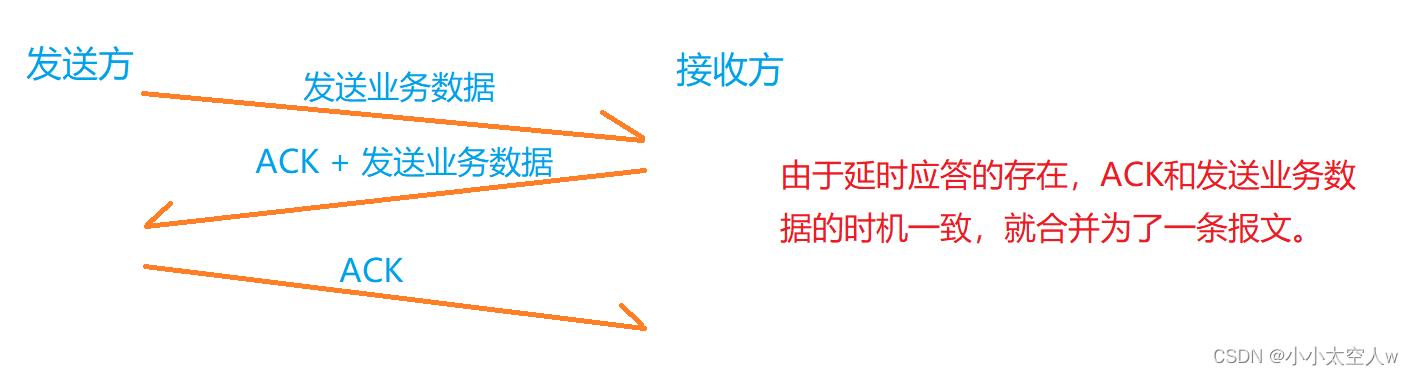
TCP核心机制详解(三)
目录 前言: 滑动窗口 滑动窗口处理丢包问题 流量控制 拥塞控制 延时应答 捎带应答 面向字节流 异常情况 小结: 前言: 前两篇文章讲述了,TCP十种核心机制的前三种。这篇文章详细介绍其他的一些核心机制,让我们…...
)
最易上手的爬虫请求库:Requests核心功能速览(下)
上一个章节我们讲了如何快速使用Requests发送网络请求、处理URL参数和提取响应内容,这些是最基本的操作。 然而还有很多场景下,我们的网络请求更加复杂。比如我们必须要定制请求头来假装成浏览器,不然可能会被网站识别为机器并且被屏蔽;又比如我们需要在发送请求时以表单形…...
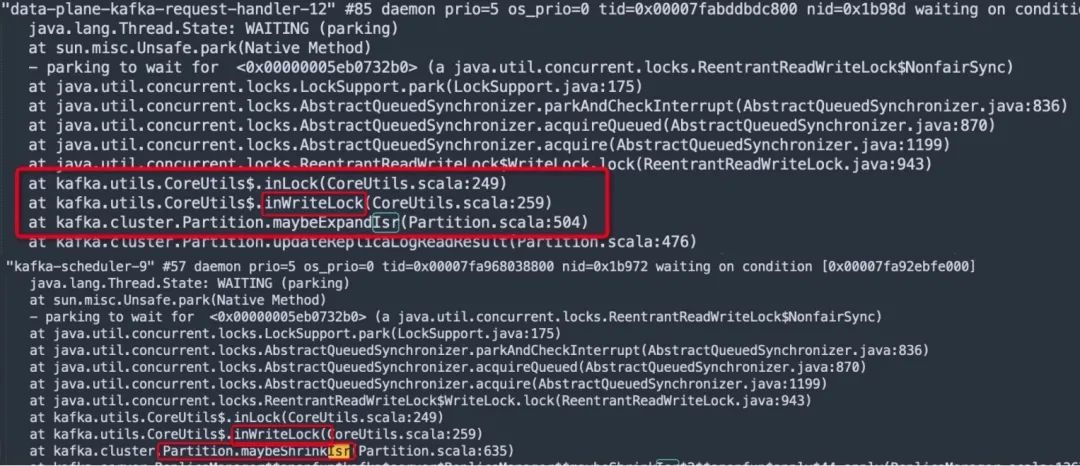
生产故障|Kafka ISR频繁伸缩引发性能急剧下降
生产故障|Kafka ISR频繁伸缩引发性能急剧下降-阿里云开发者社区 本文是笔者双十一系列第二弹,源于一个双十一期间一个让笔者猝不及防的生产故障,本文将详细剖析Kafka的副本机制,以及ISR频繁变更(扩张与伸缩)为什么会导致集群不可…...
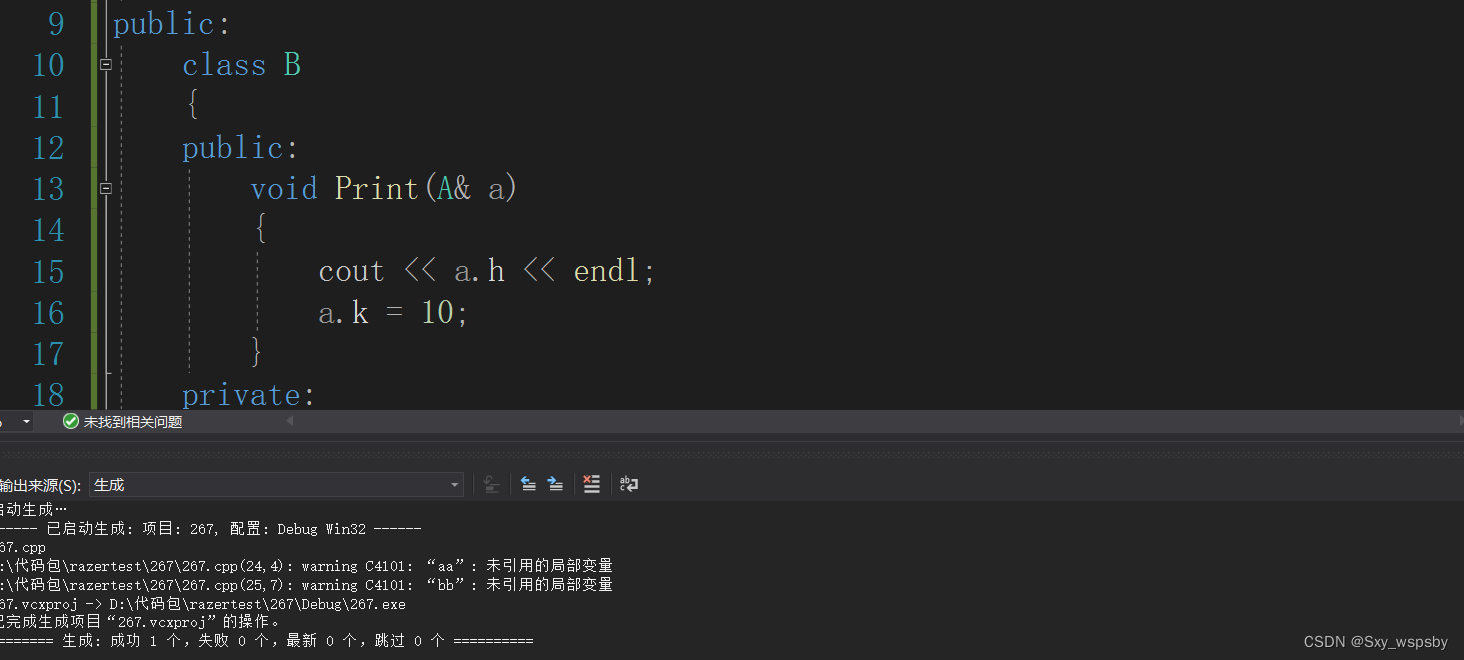
c++终极螺旋丸:₍˄·͈༝·͈˄*₎◞ ̑̑“类与对象的结束“是结束也是开始
文章目录 前言一.构造函数中的初始化列表 拷贝对象时的一些编译器优化二.static成员三.友元四.内部类总结前言 前两期我们将类和对象的重点讲的差不多了,这一篇文章主要进行收尾工作将类和对象其他的知识点拉出来梳理一遍,并且补充前两篇没有讲过的…...
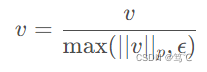
【Python--torch.nn.functional】F.normalize用法 + 代码说明
【Python–torch.nn.functional】F.normalize介绍 代码说明 文章目录【Python--torch.nn.functional】F.normalize介绍 代码说明1. 介绍2. 代码说明2.1 一维Tensor2.2 二维Tensor2.3 三维Tensor3. 总结1. 介绍 import torch.nn.functional as F F.normalize(input: Tensor, …...

【算法题】1887. 使数组元素相等的减少操作次数
插: 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 坚持不懈,越努力越幸运,大家一起学习鸭~~~ 题目: 给你一个整数数组 nums ࿰…...

GD库图片裁剪指定形状解决办法(PHP GD库 海报)
需求描述:需要把图片裁剪成一个指定的平行四边形,目的是使用GD库,把裁剪后的图片放在底图上面,使最终合成的图片看起来是一个底图平行四边形的样子提示:可以结合本作者的其他文章,来生成一个定制化的海报&a…...

redis的简介及应用场景
1、基本信息 Redis英文官网介绍: Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker. It supports data structures such as strings, hashes, lists, sets, sorted sets with range queri…...
实现时间计数戳)
2、HAL库利用滴答定时器systick(1ms中断)实现时间计数戳
文档说明:通过滴答定时器的1ms中断实现时间计数,标记需要的时间标志,在主函数中查询标志,避免延时函数消耗CPU 1、HAL库systick定时器说明 在CubeMx生成的代码main()函数首先执行的函数为HAL_Init();里面会进行滴答定时器初始化…...

Spring入门学习
Spring入门学习 文章目录Spring入门学习Spring概述Spring FrameworkIOCIOC容器DIIOC容器的实现类①FileSystemXmlApplicationContext②ClassPathXmlApplicationContext基于XML管理bean入门案例创建类创建xml在Spring配置文件中配置bean测试Spring概述 Spring 是最受欢迎的企业级…...
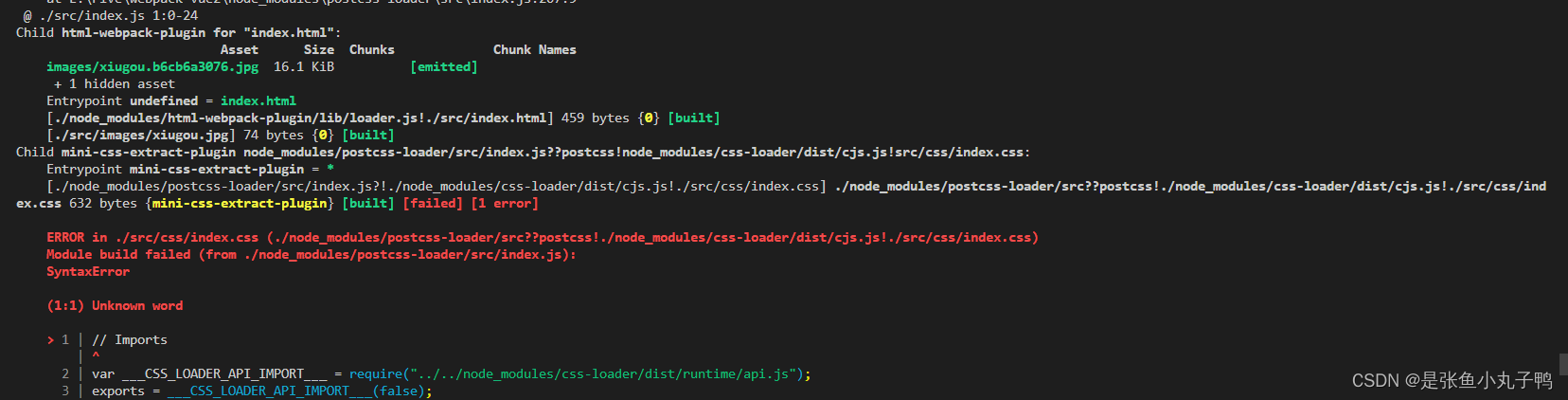
webpack(4版本)使用
webpack简介:webpack 是一种前端资源构建工具,一个静态模块打包器(module bundler)。在 webpack 看来, 前端的所有资源文件(js/json/css/img/less/...)都会作为模块处理。它将根据模块的依赖关系进行静态分析,打包生成对应的静态资源(bundle)…...

Linux安装ElasticSearch
下载地址:https://www.elastic.co/cn/downloads/past-releases#elasticsearch 1 版本选择 ElasticSearch 7 及以上版本都是自带的 jdk,假如需要配置指定的 jdk 版本的话,可以在 es 的 bin 目录下找到elasticsearch-env.bat 这个文件&#x…...

Linux中C语言编程经验总结
修改记录 版本号日期更改理由V1.02022-03-15MD化 总则 仅总结一些常用且实用的编程规范和技巧,且避免记忆负担,聚焦影响比较大的20% ! 编译器 打开全warning编译器开关 正例 gcc -W -Wall -g -o someProc main.c反例 gcc -g -o someProc main…...
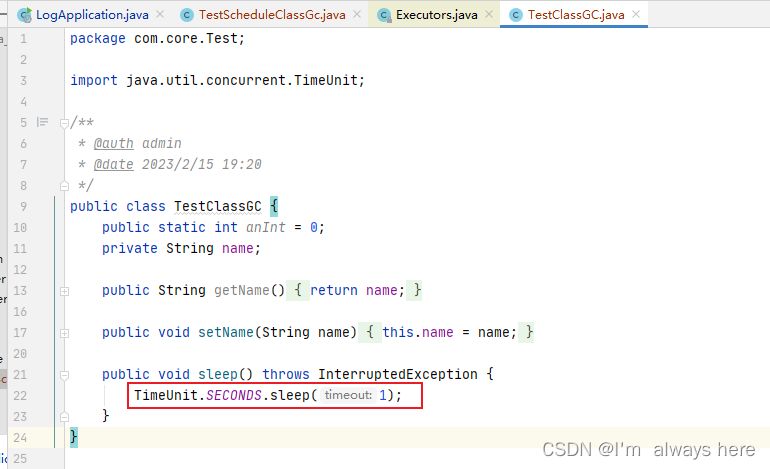
jvisualvm工具使用
jdk自带的工具jvisualvm,可以分析java内存使用情况,jvm相关的信息。 1、设置jvm启动参数 设置jvm参数**-Xms20m -Xmx20m -XX:PrintGCDetails** 最小和最大堆内存,打印gc详情 2、测试代码 TestScheduleClassGc package com.core.schedule;…...
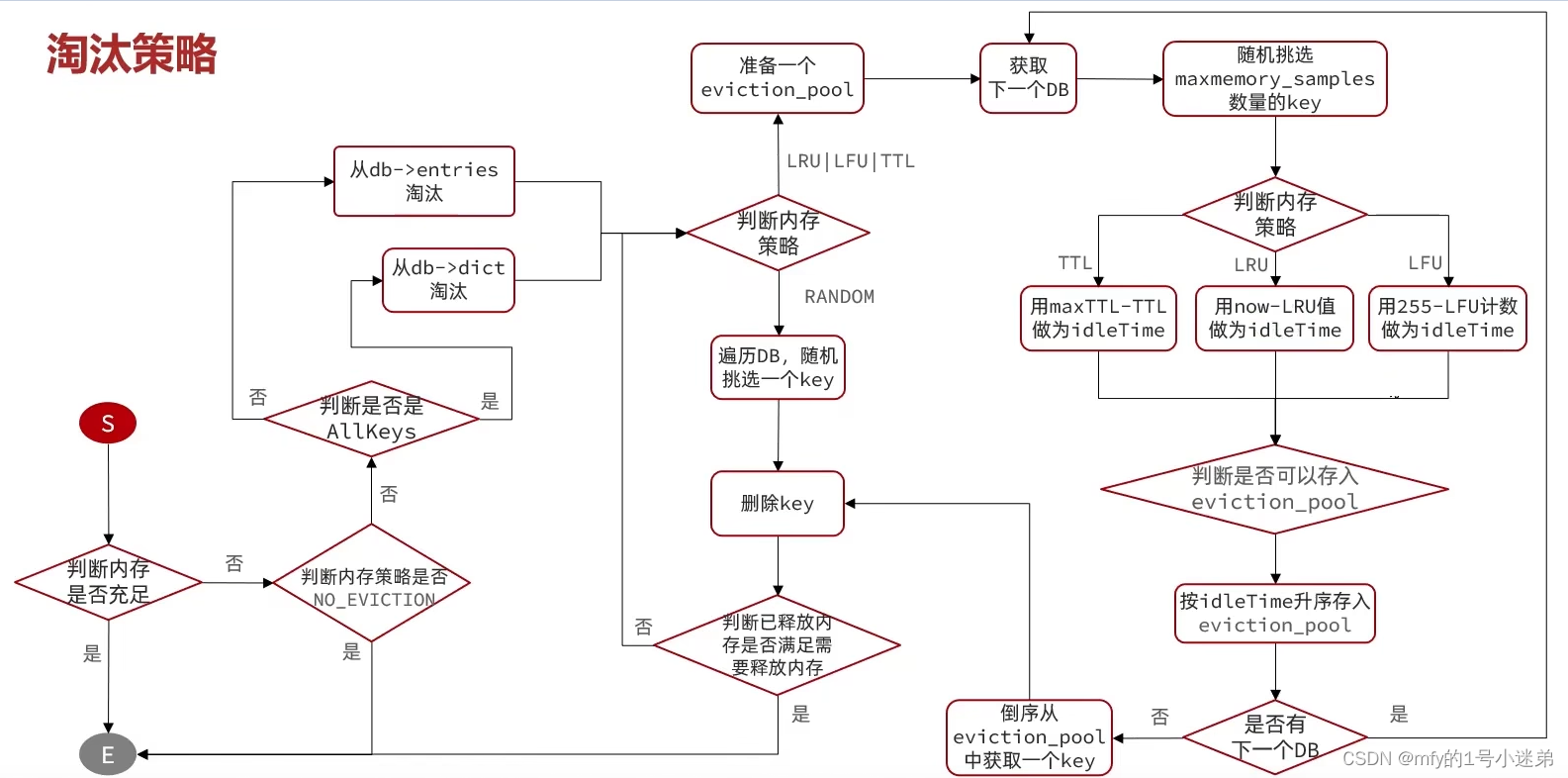
redis五大IO网络模型、内存回收
目录1.0用户空间和内核态空间1.1 网络模型-阻塞IO1.2 网络模型-非阻塞IO1.3 网络模型-IO多路复用1.3.1 网络模型-IO多路复用-select方式1.3.2 网络模型-IO多路复用模型-poll模式1.3.3 网络模型-IO多路复用模型-epoll函数1.3.4 网络模型-epoll中的ET和LT1.3.5 网络模型-基于epol…...

【C/C++】内存管理详解
目录内存布局思维导图1.C/C内存分布数据段:栈:代码段:堆:2.C语言中动态内存管理方式3.C内存管理方式3.1new/delete操作内置类型3.2new和delete操作自定义类型4.operator new 与 operator delete函数5.new和delete的实现原理5.1内置类型5.2自定…...

Android ProcessLifecycleOwner 观察进程生命周期
文章目录简介使用依赖用法1,结合 LiveData用法2,获取 owner的 lifecycle 实例,并对 lifecycle 添加观察者简介 ProcessLifecycleOwner 直译,就是,进程生命周期所有者。 通过 DOC 注释了解到: Lifecycle.E…...
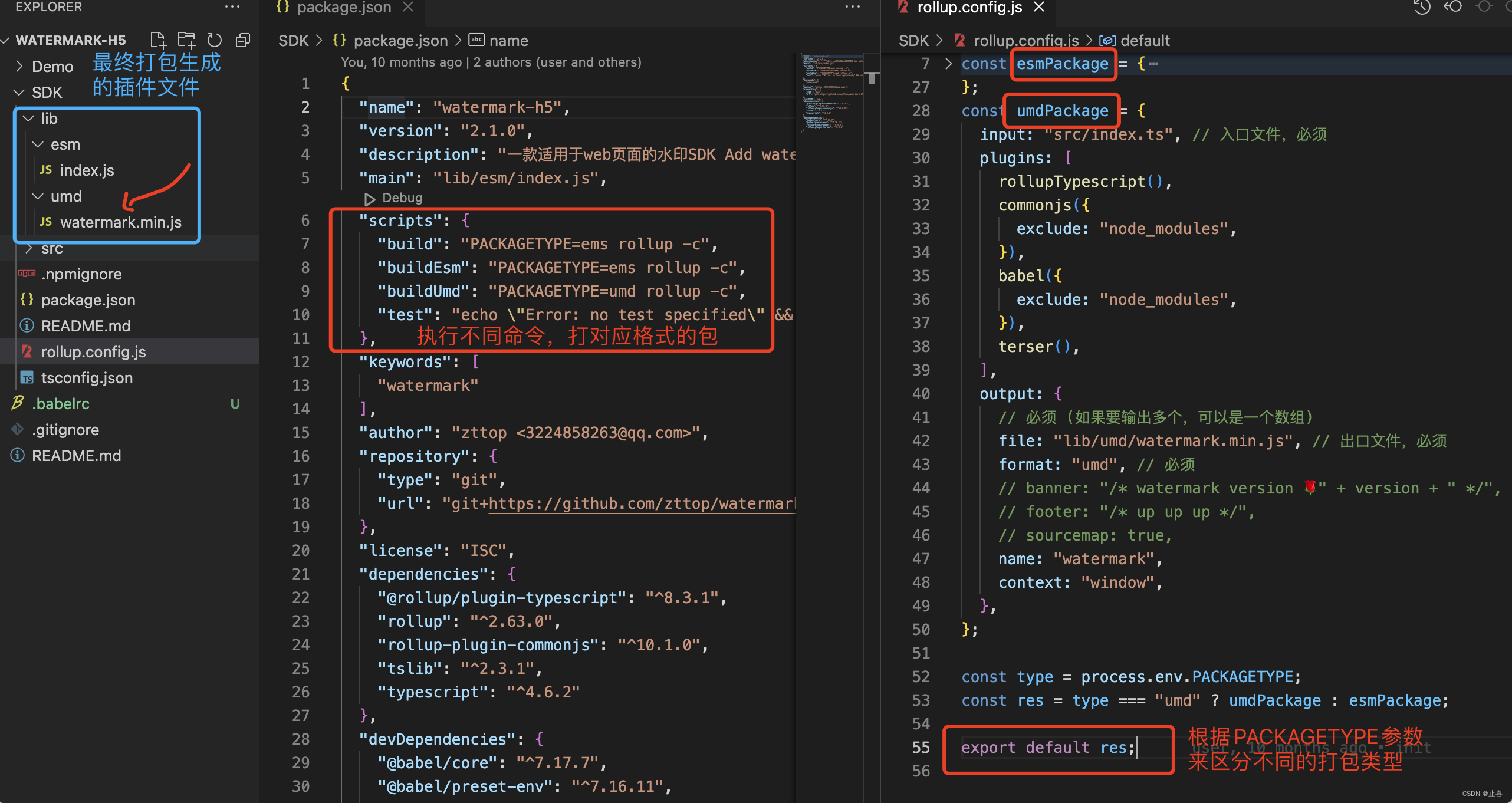
如何编写一个 npm 插件?
提到写 npm 插件,很多没搞过的可能第一感觉觉得很难,无从下手,其实不然。 我们甚至写个简单的 console.log(hello word),都是可以当成一个插件发布上去的。 其实无从下手的主要难点还是在于你的具体要做的功能逻辑,这…...

mapstruct- 让VO,DTO,ENTITY转换更加便捷
mapstruct- 让VO,DTO,ENTITY转换更加便捷 1. 简介 MapStruct是一个代码生成器,简化了不同的Java Bean之间映射的处理,所谓映射指的就是从一个实体变化成一个实体。例如我们在实际开发中,DAO层的实体和一些数据传输对…...

从 Token 消耗到 AI 资产:企业如何把一次调用沉淀成模板、流程、知识库和制度
关键词:Token 管理、AI 资产、模板库、流程化、知识库、制度化、投入产出比 开篇:企业真正要管的不是 Token,而是 Token 之后留下了什么 很多企业开始使用 AI 以后,第一反应是看成本:这个月用了多少 Token,哪个部门调用最多,哪个模型最贵,哪些场景消耗最高。 这当然重…...

Avogadro 2:3分钟掌握跨平台分子建模的5大核心价值
Avogadro 2:3分钟掌握跨平台分子建模的5大核心价值 【免费下载链接】avogadroapp Avogadro is an advanced molecular editor designed for cross-platform use in computational chemistry, molecular modeling, bioinformatics, materials science, and related a…...
)
Acrylic Paint风格在Midjourney中失效的5大隐性陷阱(附官方未公开的--s 700+--style raw协同调参公式)
更多请点击: https://intelliparadigm.com 第一章:Acrylic Paint风格在Midjourney中的本质定义与失效现象全景图 Acrylic Paint(丙烯画)风格在Midjourney中并非原生语义标签,而是一种通过视觉特征逆向建模的提示工程产…...

新媒体编辑提效:OpenClaw批量剪辑短视频、生成文案字幕,适配多平台发布规则
新媒体编辑效率革命:OpenClaw赋能短视频批量剪辑、智能文案生成与多平台适配在信息爆炸、注意力稀缺的移动互联网时代,短视频已成为内容传播的绝对主力军。对于新媒体运营团队而言,高效地产出高质量、符合各平台调性且能快速发布的短视频内容…...

开源密钥管理器VSV:一个加密文件搞定多环境密钥管理
1. 项目概述:一个面向开发者的加密密钥管理器最近在折腾一个内部项目,需要管理不同环境(开发、测试、生产)的数据库密码、API密钥这些敏感信息。一开始图省事,直接写在了.env文件里,结果在代码评审时被同事…...

百度文库文档免费下载终极指南:3步快速获取纯净PDF
百度文库文档免费下载终极指南:3步快速获取纯净PDF 【免费下载链接】baidu-wenku fetch the document for free 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wenku 你是否曾在百度文库找到心仪的文档,却被烦人的广告、付费提示和杂乱页面…...

通过curl命令直接测试Taotoken聊天补全接口的配置与排错方法
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令直接测试Taotoken聊天补全接口的配置与排错方法 对于开发者而言,在集成大模型API时,直接使用c…...

Hermes Agent 可视化监控与文档生成工具 hermes-dashboard 详解
1. 项目概述与核心价值如果你正在使用 Hermes Agent 进行 AI 智能体开发,或者对 Agent 的内部运行状态感到好奇,那么你很可能需要一个“上帝视角”。hermes-dashboard正是这样一个工具,它为你提供了一个实时的监控仪表盘和一个自动生成的、可…...

教育资源共享新范式:智能解析技术如何重塑教材获取体验
教育资源共享新范式:智能解析技术如何重塑教材获取体验 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具,帮助您从智慧教育平台中获取电子课本的 PDF 文件网址并进行下载,让您更方便地获取课本内容。 项目地址…...

告别环境报错!保姆级教程:从JRE到STM32CubeMX 6.10.0的完整安装与配置
从零搭建STM32开发环境:CubeMX 6.10.0避坑全指南 刚拿到STM32开发板时的兴奋,往往在环境配置阶段就被各种报错消磨殆尽。作为过来人,我深刻理解那种看着红色错误提示却无从下手的挫败感。本文将带你用最稳妥的方式完成从Java环境到CubeMX的全…...