生产故障|Kafka ISR频繁伸缩引发性能急剧下降
生产故障|Kafka ISR频繁伸缩引发性能急剧下降-阿里云开发者社区
本文是笔者双十一系列第二弹,源于一个双十一期间一个让笔者猝不及防的生产故障,本文将详细剖析Kafka的副本机制,以及ISR频繁变更(扩张与伸缩)为什么会导致集群不可用。
1、Kafka副本机制
Kafka数据组织方式是topic-parition的结构,每一个topic可以设置多个分区,各个分区的数据是topic数据的一部分(数据分片),为了保证单个分区的高可用行,又引入了副本机制,即一个分区的数据会存储多份,避免单点故障.
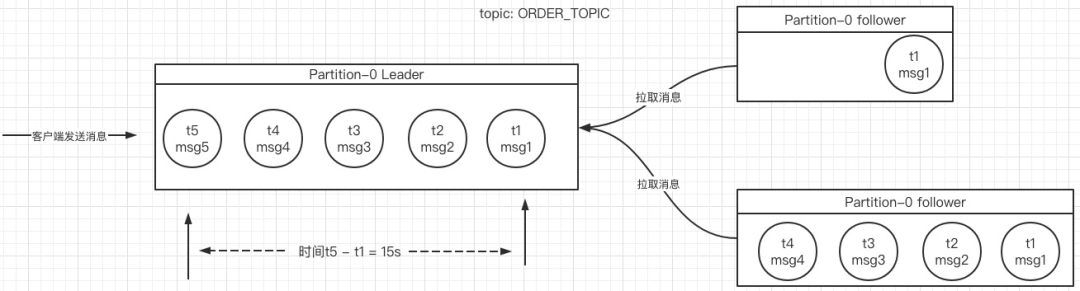
一个3节点的Broker集群,每一个Toipic的副本因子设置为3,则对于其中一个Topic,其存储结构如下图所示:

正如上图所示:一个Topic有三个分区,p0,p1,p2,其中每一个分区有3个副本(3份相同的数据),其与客户端交互的关键点如下:
- 每一个分区的Leader负责该分区的读写
- 分一个分区的follower从Leader节点复制数据
- 如果leader分区所在的broker宕机,会触发leader选举
上述的模型,满足高可用的诉求,但同时会带来一个设计难题:如何保证同一个分区中Leader与follwer节点数据的一致性。
Kafka副本之间的数据复制模型如下图所示:
Kafka复制模型采取的是拉模型,即follower节点主动向leader拉取数据,leader节点可用根据从节点发起的拉起请求的消息偏移量,从而得知从节点当前复制数据的位置。
Kafka在数据副本一致性方面并没有采取诸如raft协议之列的,而是之间基于最高水位线与leader_epoch机制,本文不深入探讨在一致性方面的知识,这些后续会一一剖析。
在Kafka中,引入了一个概念:副本同步集,即ISR集合。
所谓的副本同步集,表示这个集合中的副本能跟上Leader的从节点,判断的规则:两者之间同步消息的时间间隔不能超过设置的阔值,该值由参数 replica.lag.time.max.ms 来控制,默认为10s。
例如上图中,分区p0的leader节点成功写入了5条消息,两者在服务端存储的时间间隔为15s,而其中一个从节点只复制了t1,与最新的t5消息间隔15s,超过了replica.lag.time.max.ms设置的10s,则Leader会将该节点从ISR集合中剔除;而另外一个从节点尽管只复制了4条消息,但落户Leader副本的时间间隔小于10s,则该节点会作为ISR集合中的一员。
ISR集合与副本数的关系如下图所示:

那这个ISR集合的作用是什么呢?
一个非常重要的作用:可以用来实现消息发送阶段消息不丢失。
构建KafkaProducer对象时可以设置acks=all或者-1表示必须ISR集合中的副本全部成功写入消息才会向客户端返回成功,注意:这里并不是说所有副本写入成功。
并且对ISR集合中的副本的个数也有要求,可以在topic级别的配置参数:
min.insync.replicas进行设置,该值默认为2。
例如将topic的副本因子设置为3,表示有三个副本,只要ISR集合中的数量不少于2个,将acks设置为all时才能正常写入成功,如果ISR集合中的副本数量小于min.insync.replicas,则消息发送会失败。
以上就是Kafka ISR集合的一些基本介绍,该专栏后续会继续深入探讨kafka的日志存储、高低水位线、Leader epoch等机制。
在探究ISR伸缩与扩张会引发消息发送、消息消费性能急剧下降原因之前,想提出一个思考题
思考题:从上文中可知,ISR集合中各个副本虽然是同步集合,但判断是否同步的规则确实从节点不落后Leader节点多少数据,那这些副本之间的数据并不是完全同步的,如果在Leader切换过程中,会丢失消息吗?
2、ISR频繁伸缩缩引发性能急剧下降
双十一期间一个Kafka集群频繁发生ISR,读写性能急剧下降,监控图如下所示:

起初一个topic的写入tps达到了25W每秒,当出现ISR收缩与扩张后,断崖式下降,与此同时,服务端会有大量的日志:

为什么会ISR频繁收缩与扩张,为导致性能急剧下降呢?
当然,首先如果acks设置为all,消息写入下降这个是必然的,因为ISR集合中的数量会低于min.insync.replicas,导致消息无法写入,但这个topic是用于同步数据库binlog,如果出现集群等原因导致消息丢失,完全可以回放binlog进行数据补推,故消息发送时是将acks设置为1(Leader节点写入成功即返回成功)。
那又是为什么呢?
通过系统相关的监控发现发生问题时的CPU、磁盘都没有瓶颈,故优先排查Kafka的线程堆栈信息。
关键信息一:Kafka Broker在处理消息写入时需更新Kafka高水位线,需要申请leaderIsrUpdateLock的读锁,如下图所示:

原来消息写入时需要加读锁,但由于读锁与读锁之间时相容的,并不影响消息发送的并发度。
关键信息二:Kafka Broker在处理消息拉起请求时(消费端、从节点都会发fetch请求)需同样需要更新Kafka高水位线,需要申请leaderIsrUpdateLock的读锁,如下图所示:

消息发送、消息写入都需要申请读写锁leaderIsrUpdateLock中的读锁,并不会影响并发度。
关键信息三:Kafka Broker在ISR发生扩张与伸缩时需要申请leaderIsrUpdateLock的写锁,如下图所示:
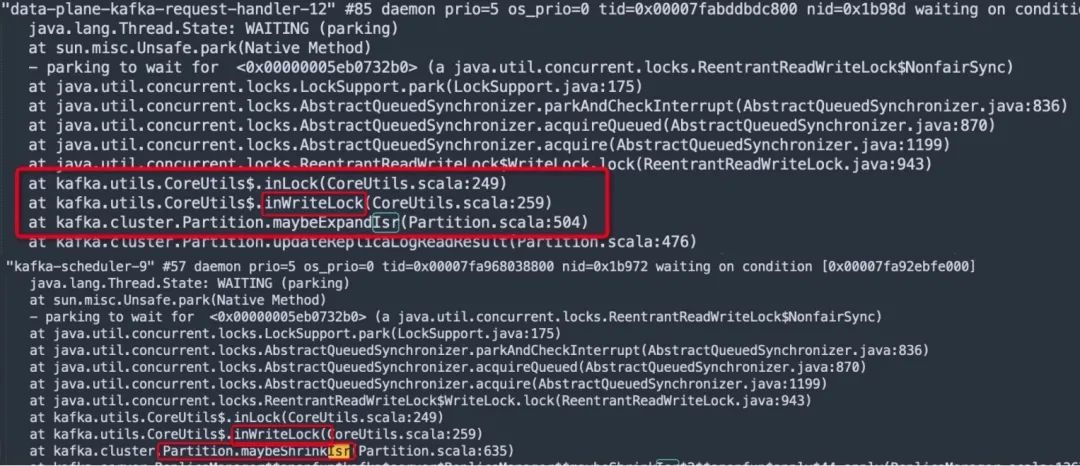
在ISR集合发生变更时,对高水位线的的更新需要加写锁,此时会与消息发送、消费客户端消费消息、分区副本消息复制发送锁竞争,并发度急剧下降,这样就解释了为什么ISR收缩与扩张会导致TPS急剧下降。
令人比较“无语”的是,这里会有一个连锁反应,因为会影响副本分区从其Leader节点拉取消息的速率,容易加剧ISR的扩张与收缩,从而使问题越来越严重。
3、解决方案
经过上述分析,ISR的频繁扩张与收缩,其最直观的原因是:follower副本从Leader副本复制数据,由于复制跟不上,导致两者之间数据同步的差距超过了replica.lag.time.max.ms,导致Leader分区会将跟不上进度的副本剔除ISR,然后当follwer分区跟上后,又能加入ISR。
故可以通过调整Kafka相关的参数,来减少ISR发生的几率:
- replica.lag.time.max.ms从默认10s,调整为30s
- num.replica.fetchers从默认值1调整为10,该参数的主要作用是设置Follower节点用于从服务端复制数据的线程数量,调整该参数可以加大并发,在线程堆栈线程名称为:ReplicaFetcherThread线程,注意,这个是控制一个节点到集群单个Broker的链接数,例如一集群有8个节点,该值设置为10,那一个节点就会创建 (8-1)* 10 共70个ReplicaFetcher线程。
本文就到介绍到这里里,其实ISR频发扩张后,还会引发更加严重的问题,最后竟然引发了整个集群无法写入消息,无法消费消息,这些将在后续文章中发布
相关文章:
生产故障|Kafka ISR频繁伸缩引发性能急剧下降
生产故障|Kafka ISR频繁伸缩引发性能急剧下降-阿里云开发者社区 本文是笔者双十一系列第二弹,源于一个双十一期间一个让笔者猝不及防的生产故障,本文将详细剖析Kafka的副本机制,以及ISR频繁变更(扩张与伸缩)为什么会导致集群不可…...
c++终极螺旋丸:₍˄·͈༝·͈˄*₎◞ ̑̑“类与对象的结束“是结束也是开始
文章目录 前言一.构造函数中的初始化列表 拷贝对象时的一些编译器优化二.static成员三.友元四.内部类总结前言 前两期我们将类和对象的重点讲的差不多了,这一篇文章主要进行收尾工作将类和对象其他的知识点拉出来梳理一遍,并且补充前两篇没有讲过的…...
【Python--torch.nn.functional】F.normalize用法 + 代码说明
【Python–torch.nn.functional】F.normalize介绍 代码说明 文章目录【Python--torch.nn.functional】F.normalize介绍 代码说明1. 介绍2. 代码说明2.1 一维Tensor2.2 二维Tensor2.3 三维Tensor3. 总结1. 介绍 import torch.nn.functional as F F.normalize(input: Tensor, …...

【算法题】1887. 使数组元素相等的减少操作次数
插: 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 坚持不懈,越努力越幸运,大家一起学习鸭~~~ 题目: 给你一个整数数组 nums ࿰…...

GD库图片裁剪指定形状解决办法(PHP GD库 海报)
需求描述:需要把图片裁剪成一个指定的平行四边形,目的是使用GD库,把裁剪后的图片放在底图上面,使最终合成的图片看起来是一个底图平行四边形的样子提示:可以结合本作者的其他文章,来生成一个定制化的海报&a…...

redis的简介及应用场景
1、基本信息 Redis英文官网介绍: Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker. It supports data structures such as strings, hashes, lists, sets, sorted sets with range queri…...
实现时间计数戳)
2、HAL库利用滴答定时器systick(1ms中断)实现时间计数戳
文档说明:通过滴答定时器的1ms中断实现时间计数,标记需要的时间标志,在主函数中查询标志,避免延时函数消耗CPU 1、HAL库systick定时器说明 在CubeMx生成的代码main()函数首先执行的函数为HAL_Init();里面会进行滴答定时器初始化…...

Spring入门学习
Spring入门学习 文章目录Spring入门学习Spring概述Spring FrameworkIOCIOC容器DIIOC容器的实现类①FileSystemXmlApplicationContext②ClassPathXmlApplicationContext基于XML管理bean入门案例创建类创建xml在Spring配置文件中配置bean测试Spring概述 Spring 是最受欢迎的企业级…...
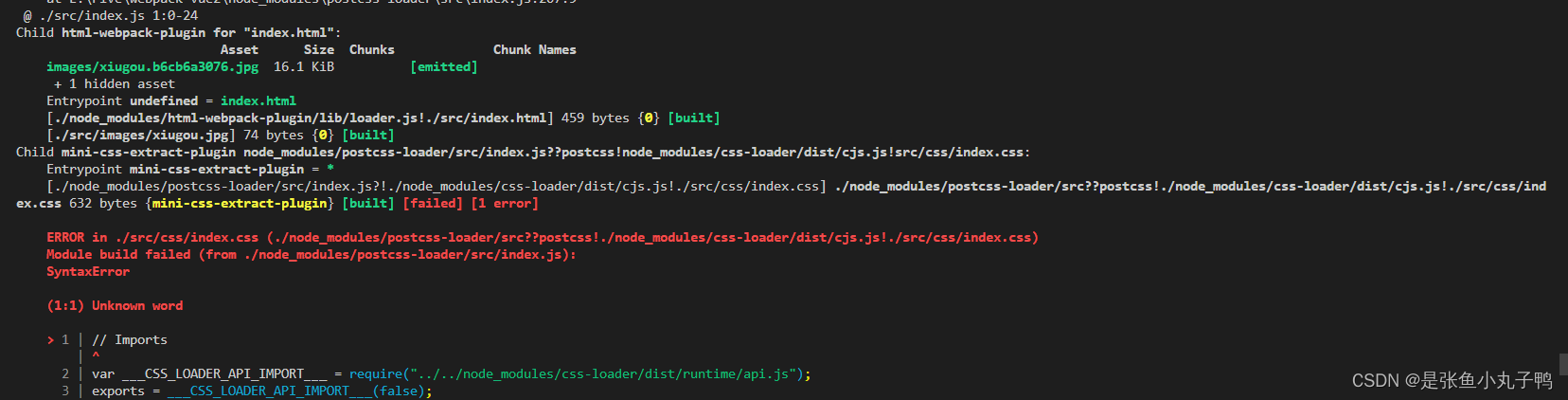
webpack(4版本)使用
webpack简介:webpack 是一种前端资源构建工具,一个静态模块打包器(module bundler)。在 webpack 看来, 前端的所有资源文件(js/json/css/img/less/...)都会作为模块处理。它将根据模块的依赖关系进行静态分析,打包生成对应的静态资源(bundle)…...

Linux安装ElasticSearch
下载地址:https://www.elastic.co/cn/downloads/past-releases#elasticsearch 1 版本选择 ElasticSearch 7 及以上版本都是自带的 jdk,假如需要配置指定的 jdk 版本的话,可以在 es 的 bin 目录下找到elasticsearch-env.bat 这个文件&#x…...

Linux中C语言编程经验总结
修改记录 版本号日期更改理由V1.02022-03-15MD化 总则 仅总结一些常用且实用的编程规范和技巧,且避免记忆负担,聚焦影响比较大的20% ! 编译器 打开全warning编译器开关 正例 gcc -W -Wall -g -o someProc main.c反例 gcc -g -o someProc main…...
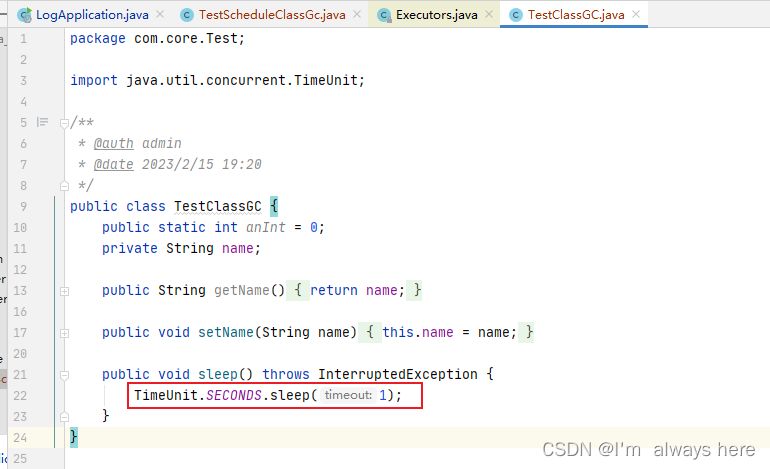
jvisualvm工具使用
jdk自带的工具jvisualvm,可以分析java内存使用情况,jvm相关的信息。 1、设置jvm启动参数 设置jvm参数**-Xms20m -Xmx20m -XX:PrintGCDetails** 最小和最大堆内存,打印gc详情 2、测试代码 TestScheduleClassGc package com.core.schedule;…...
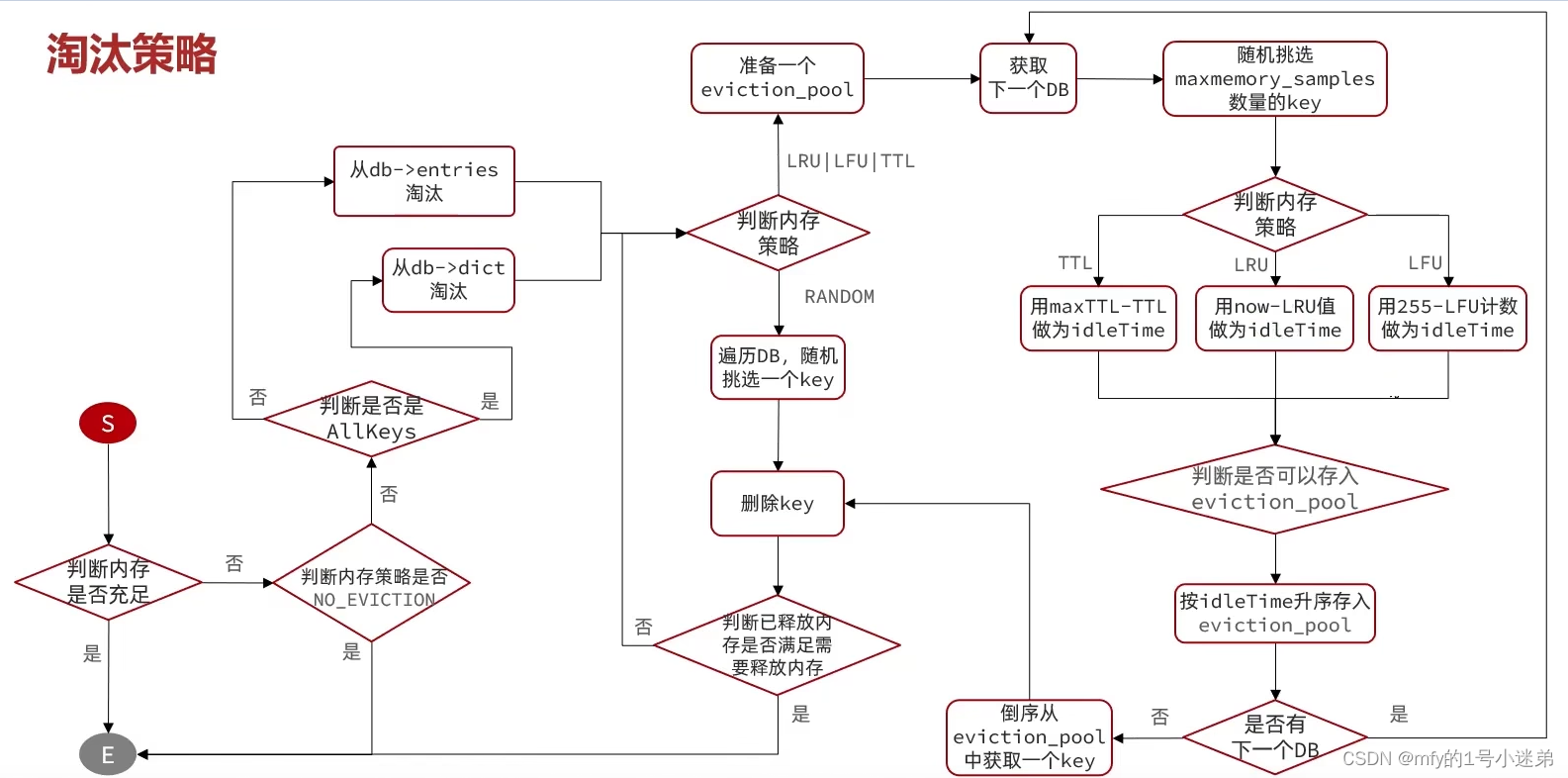
redis五大IO网络模型、内存回收
目录1.0用户空间和内核态空间1.1 网络模型-阻塞IO1.2 网络模型-非阻塞IO1.3 网络模型-IO多路复用1.3.1 网络模型-IO多路复用-select方式1.3.2 网络模型-IO多路复用模型-poll模式1.3.3 网络模型-IO多路复用模型-epoll函数1.3.4 网络模型-epoll中的ET和LT1.3.5 网络模型-基于epol…...

【C/C++】内存管理详解
目录内存布局思维导图1.C/C内存分布数据段:栈:代码段:堆:2.C语言中动态内存管理方式3.C内存管理方式3.1new/delete操作内置类型3.2new和delete操作自定义类型4.operator new 与 operator delete函数5.new和delete的实现原理5.1内置类型5.2自定…...

Android ProcessLifecycleOwner 观察进程生命周期
文章目录简介使用依赖用法1,结合 LiveData用法2,获取 owner的 lifecycle 实例,并对 lifecycle 添加观察者简介 ProcessLifecycleOwner 直译,就是,进程生命周期所有者。 通过 DOC 注释了解到: Lifecycle.E…...
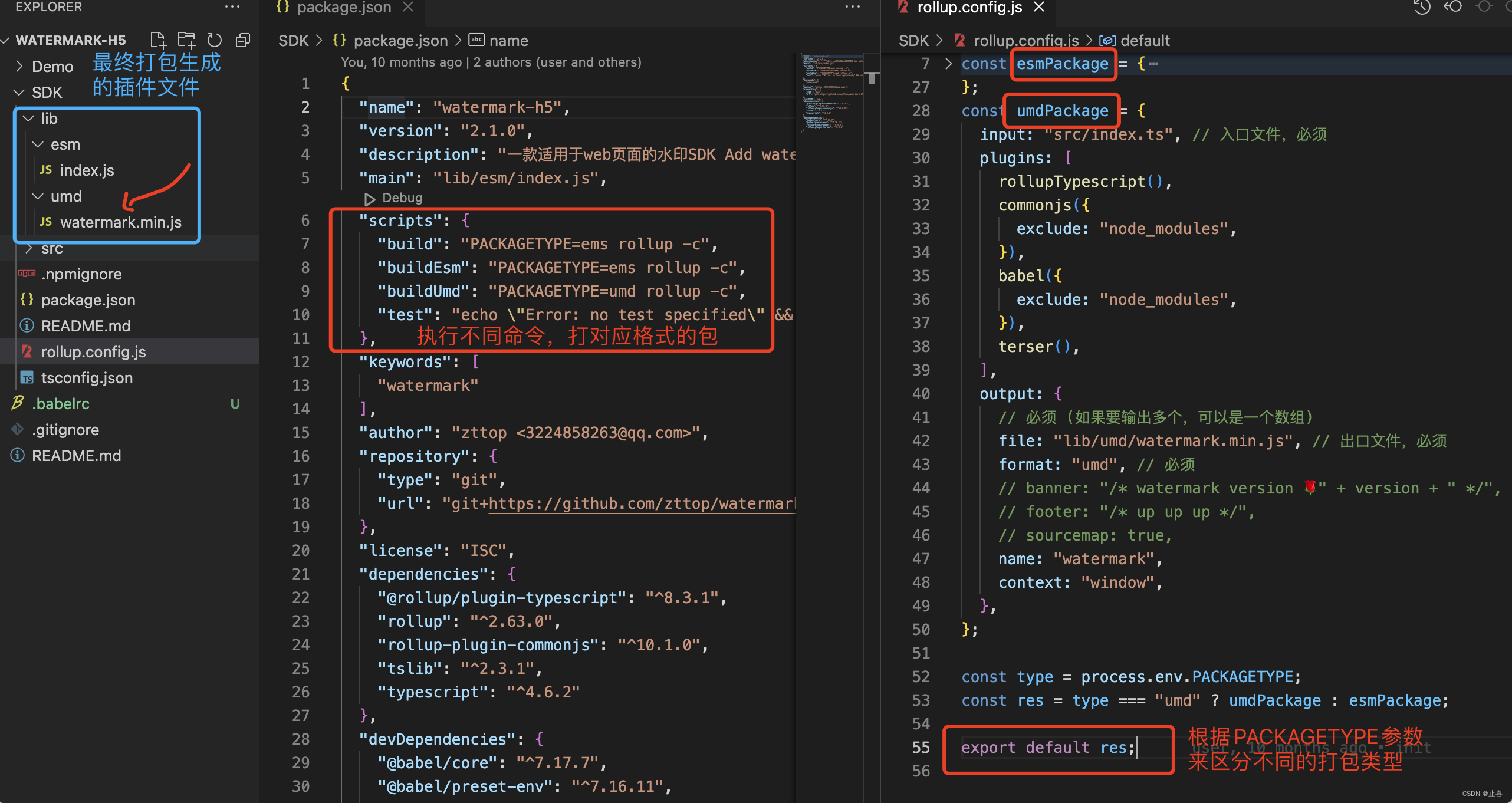
如何编写一个 npm 插件?
提到写 npm 插件,很多没搞过的可能第一感觉觉得很难,无从下手,其实不然。 我们甚至写个简单的 console.log(hello word),都是可以当成一个插件发布上去的。 其实无从下手的主要难点还是在于你的具体要做的功能逻辑,这…...

mapstruct- 让VO,DTO,ENTITY转换更加便捷
mapstruct- 让VO,DTO,ENTITY转换更加便捷 1. 简介 MapStruct是一个代码生成器,简化了不同的Java Bean之间映射的处理,所谓映射指的就是从一个实体变化成一个实体。例如我们在实际开发中,DAO层的实体和一些数据传输对…...
IAR警告抑制及还原
工作中需要临时抑制 警告 Pa084,源代码如下: sy_errno_t sy_memset_s(void *dest, sy_rsize_t dmax, int value, sy_rsize_t n) { sy_errno_t err; if (dest NULL) { return SY_ESNULLP; } if (dmax > SY_RSIZE…...
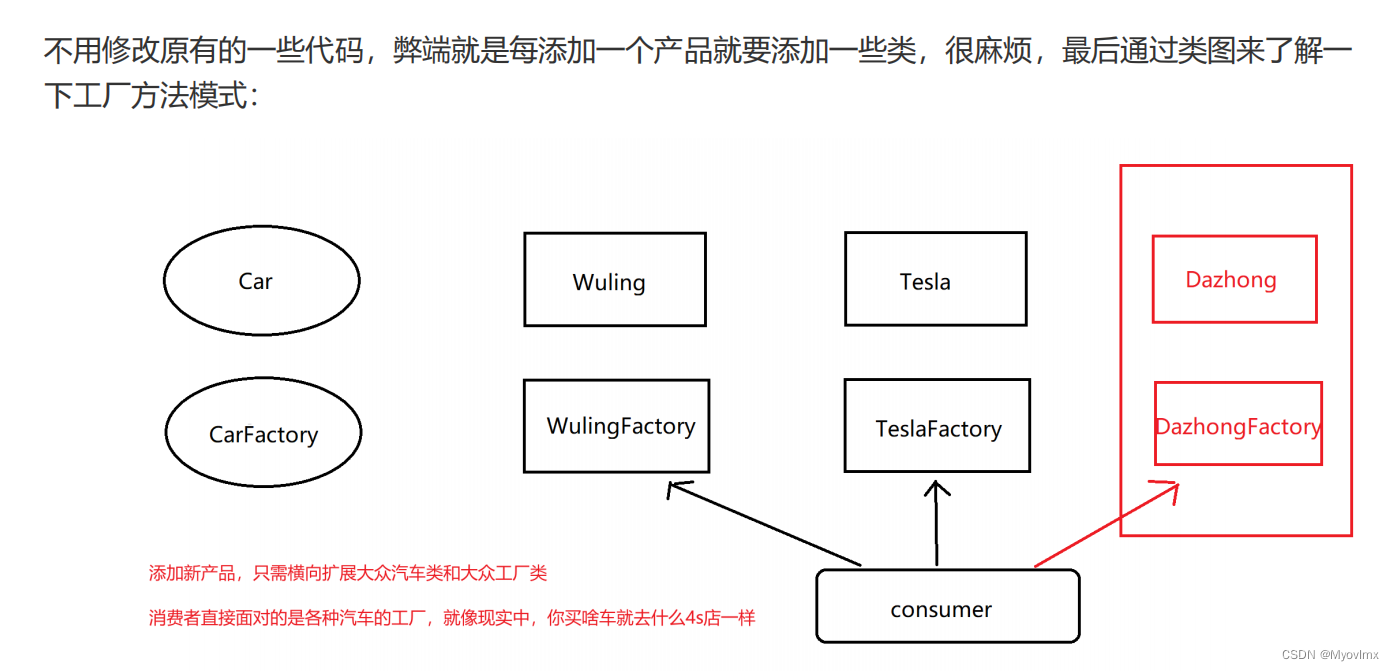
工厂模式(Factory Pattern)
1.什么是工厂模式 定义一个创建对象的接口,让其子类自己决定实例化哪一个工厂类,工厂模式使其创建过程延迟到子类进行。 2.工厂模式的作用 实现创建者和调用者的分离 3.工厂模式的分类 简单工厂模式工厂方法模式抽象工厂模式 4.工厂模式的优缺点 优…...

JavaScript语法学习--《JavaScript编程全解》
《JavaScript编程全解》 JavaScript琐碎基础 0.前言 1.RN: react native是Facebook于2015年4月开源的跨平台移动应用开发框架,是Facebook早先开源的JS框架 React 在原生移动应用平台的衍生产物,支持iOS和安卓两大平台。 2.ts与js js:是弱…...

基于MCP协议与FFmpeg构建AI视频处理服务器:原理、部署与实战
1. 项目概述:一个面向视频处理的MCP服务器 最近在折腾一些AI应用,发现很多工具在处理视频内容时,总感觉差了那么一口气。要么是功能太单一,只能做简单的剪辑或转码;要么就是流程太复杂,需要把视频下载、处…...

AI Agent 的难点,不在搭 Demo,而在让人敢交任务
Agent难在让人敢托付 很多团队做 Agent 的误会,是把跑通一次当成好用。 现在搭一个 Demo 确实不难。一个大模型,几段提示词,接几个搜索、表格、浏览器或数据库工具,很快就能演示一个会拆任务、会调用工具、会输出结果的流程。看起…...

技术生态依赖的实质与破局:从Android到自主可控的实践路径
1. 项目背景与核心议题解析最近在整理行业资料时,翻到一篇2013年的旧文,讨论的是当时中国工信部对国内移动产业过度依赖Android系统的担忧。虽然时过境迁,但文中提到的“技术自主可控”与“全球生态融入”之间的张力,在今天看来依…...

南京彩钢瓦屋面防水供应商
在南京,彩钢瓦屋面广泛应用于各类建筑,然而其防水问题一直是困扰众多业主的难题。选择一家靠谱的彩钢瓦屋面防水供应商至关重要。今天就为大家详细介绍雨中行修缮工程有限公司,同时也对比其他一些大厂,看看雨中行修缮为何能在市场…...

三维动画课程期末复盘:从零搭建我的马卡龙童话游乐场✨
当我按下 3ds Max 的渲染按钮,看着浅蓝的摩天轮缓缓转动、粉白的旋转木马跟着节奏起舞、淡紫色热气球轻轻飘动时,我才真正意识到:为期一学期的三维动画课程,就这样在我的指尖落下了帷幕。从刚打开软件连工具栏都认不全的 “小白”…...

从等待到掌控:构建个人化网盘下载工作流的3个关键步骤
从等待到掌控:构建个人化网盘下载工作流的3个关键步骤 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼…...

CPT Markets:国际监管框架下的稳健运营
在评估金融服务平台时,监管合规、技术能力、客户服务等维度构成了重要的观察方向。CPT Markets作为业内较为活跃的服务机构,其在这些方面的实践具有一定的参考价值。本文将围绕评测视角,对其综合表现进行系统性的呈现,希望为读者提…...

.NET 10 + CQRS + MediatR 一个跨平台文档管理系统
前言基于 .NET 10 打造的跨平台文档管理系统,才真正感受到了什么叫"专业级"的开源力量。它不仅仅是一个简单的文件存储工具,更是一个集成了 CQRS 架构、实时通信、版本控制等高级特性的现代化应用示例。项目介绍一款标准的前后端分离项目&…...

对比官方价格体验Taotoken活动价带来的直接成本节省
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比官方价格体验 Taotoken 活动价带来的直接成本节省 在开发与使用大模型 API 的过程中,成本是每个开发者与团队都需要…...

基于LangGraph与MCP构建Farcaster AI智能体:从架构到DeFi集成实战
1. 项目概述:一个面向Farcaster生态的AI智能体最近在探索SocialFi和AI Agent的结合点,发现了一个挺有意思的项目:oceantruong/farcaster-agent。简单来说,这是一个专门为Farcaster社交网络设计的AI智能体框架。Farcaster本身是一个…...