GAMES202作业1
目录
- Shadow Map
- CalcLightMVP函数
- useShadowMap函数
- Bias函数
- 最终效果
- PCF
- 两个采样函数
- PCF函数
- 最终效果
- PCSS
- findBlocker函数
- PCSS函数
- 最终效果
- 参考
先放上公式:

后面的积分项是我们在作业0中就做好的blinnphong项,我们要求的就是积分项前,等号后的可见项。
最终体现在代码中便是
- gl_FragColor = vec4(visibility * phongColor, 1.0);
这部分代码在homework1\src\shaders\phongShader\phongFragment.glsl中
Shadow Map
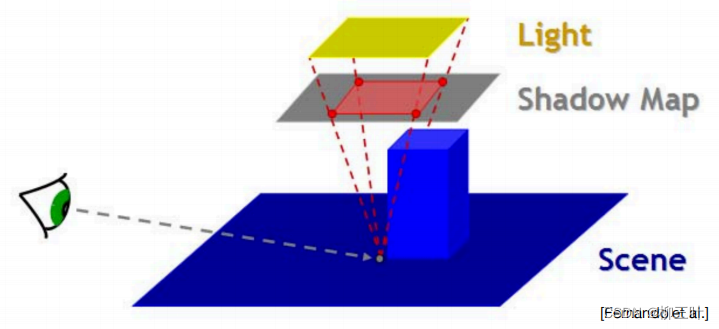
第一部分是使用Shadow Map的方法来渲染阴影,也就是渲染硬阴影,经典的Two Pass Shadow Map方法。


简单来说,shadow map主要分为两步操作:
- 第一部分,我们需要将摄像机移动到光源的位置,从光源视角出发看向场景。视线能看到的各最小深度就是光源能直接照射到的物体深度,获得这个视角下的场景深度图。(记录场景中距离光源最近的每一点,形成一张图)
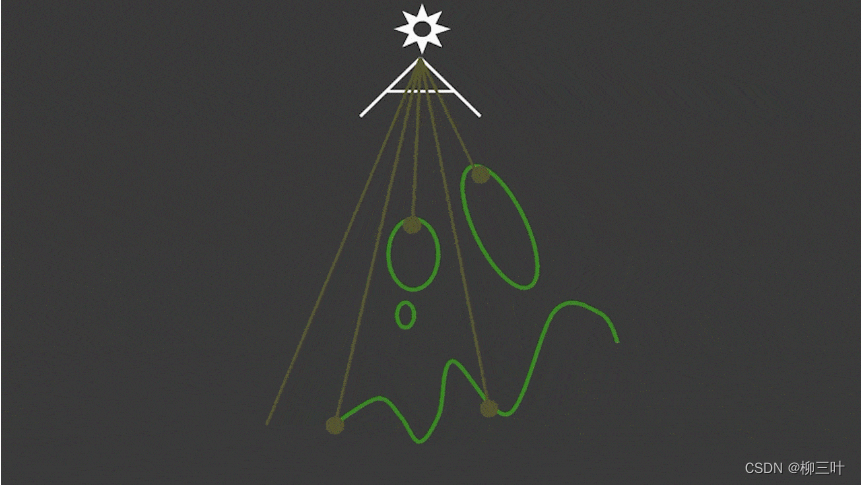
- 第二部分,绘制时需要将相机挪到眼睛的位置再观测,得到视线与物体交点,再将该点的深度,如下图中深黄色所示,与第一趟绘制得到的该点的深度比较,如果此次得到的深度更深(或者说值更大),则判断为阴影,如果相比更浅(或者说值更小或相等),则判断为非阴影可直接着色。
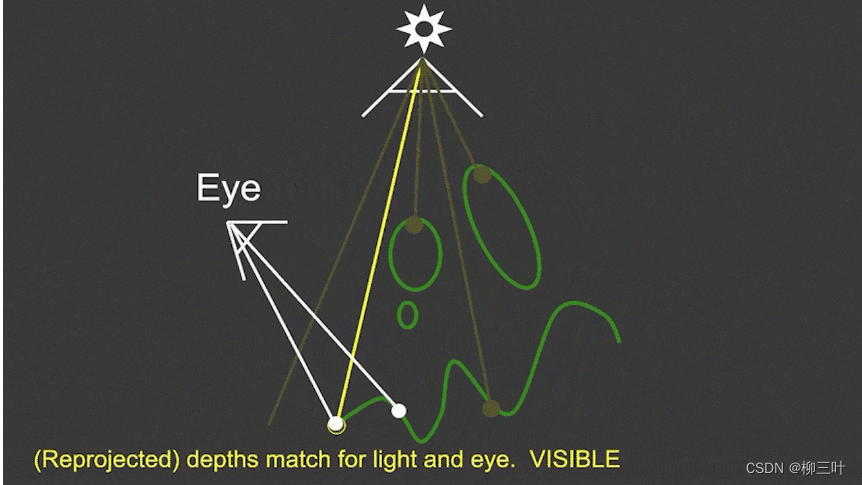
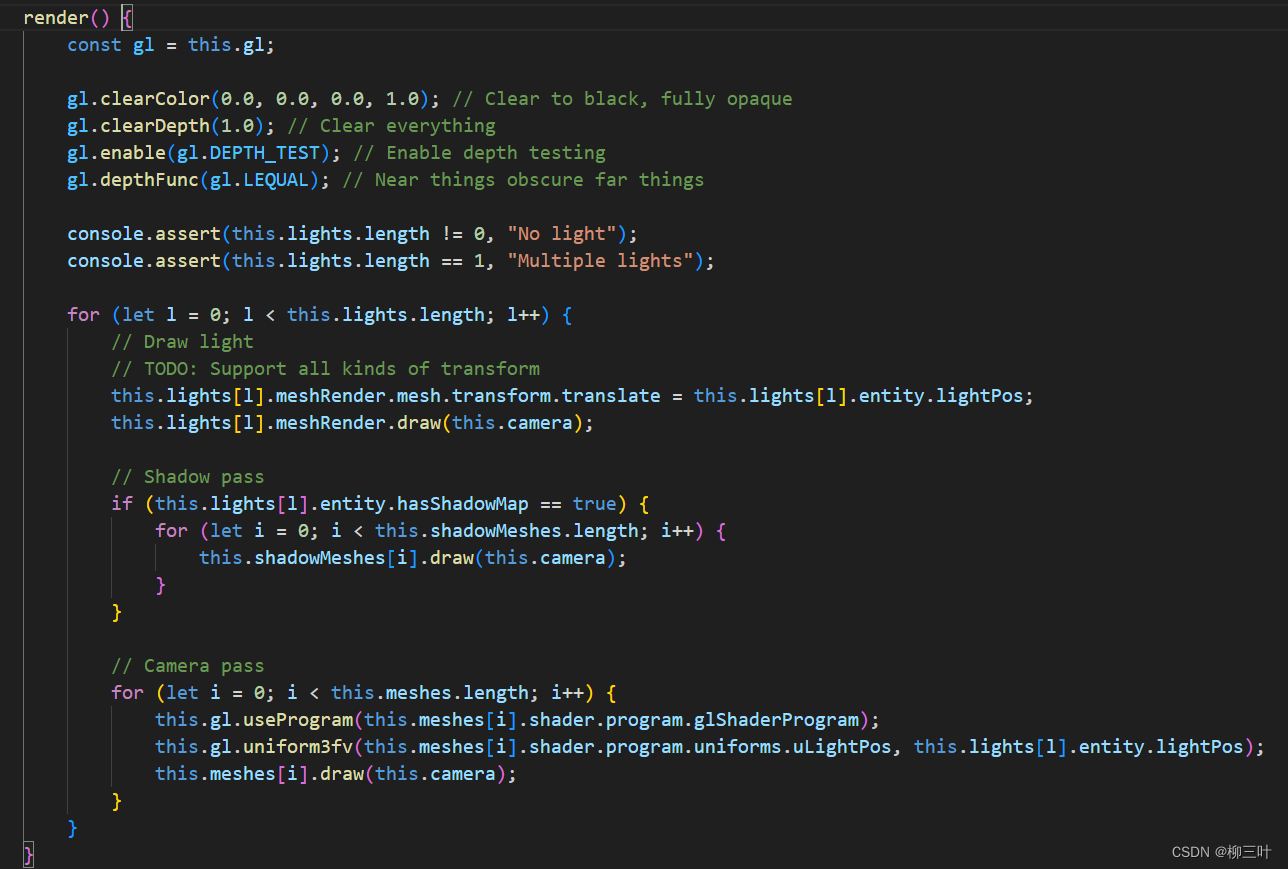
先看src\renderers\WebGLRenderer.js,两次Pass计算阴影的主要代码:
CalcLightMVP函数
首先是src/lights/DirectionalLight.js的矩阵变换部分,该矩阵参与了第一步从光源处渲染场景从而构造 ShadowMap 的过程。
CalcLightMVP(translate, scale) {let lightMVP = mat4.create();let modelMatrix = mat4.create();let viewMatrix = mat4.create();let projectionMatrix = mat4.create();// Model transform 模型矩阵,对相机先平移,再缩放mat4.translate(modelMatrix,modelMatrix,translate);mat4.scale(modelMatrix,modelMatrix,scale);// View transform 视图矩阵mat4.lookAt(viewMatrix,this.lightPos,this.focalPoint,this.lightUp);// Projection transform 投影矩阵mat4.ortho(projectionMatrix,-100,100,-100,100,1e-2,400);mat4.multiply(lightMVP, projectionMatrix, viewMatrix);mat4.multiply(lightMVP, lightMVP, modelMatrix);return lightMVP;}
- 因为我们需要获取从光源处看世界的坐标。所以在直射光中需要补充一个获得转换到光源处空间的矩阵。我们可以调用API来快速生成translate和scale矩阵。
- 再调用lookAt函数得到viewMatrix矩阵。关于lookAt()函数可以参考:learnopengl教程
- 最后使用projectionMatrix正交投影矩阵得到Shadow Map。关于正交矩阵和透视矩阵的选取:投影矩阵,由于透视投影会产生深度精度问题,因此作业中选择正交投影。
完成该矩阵的输出后,我们就可以在片元着色器中获取到Shadow Map:

useShadowMap函数
src\shaders\phongShader\phongFragment.glsl

- shadowCoord —— 纹理图片上像素对应的坐标
- 在着色时我们使用了可见项对blinnPhong得到的颜色进行一个可见性衰减。
- 我们在useShadowMap函数中可以看到我们需要使用到当前着色片元在光源坐标系下的坐标shadowCoord,这个坐标是在片元着色器前插值生成的。为了在贴图采样中使用该坐标,我们需要将向量的各个分量从( -1 , 1 ),强制转化到( 0 , 1 )(uv坐标的范围都是0-1)。
在代码里发现是调用了useShadowMap方法,
float useShadowMap(sampler2D shadowMap, vec4 shadowCoord){float mapDepth = unpack(texture2D(shadowMap,shadowCoord.xy));//shadow map中各点的最小深度,unpack将RGBA值转换成[0,1]的floatfloat shadingDepth = shadowCoord.z; //当前着色点的深度float visibility1 = ((mapDepth + EPS) < shadingDepth) ? 0.0 : 1.0; return visibility1;
}
- 先获取第一步已经获取到的shadow map中的深度。unpack()用来将RGBA值转换成在范围[0,1]的float值。
- 再获取第二次从相机出发观察到的点离光源的深度。
- 然后进行比较,EPS考虑精度问题。
- 返回visibility。
效果:

Bias函数
放大之后会发现会有很多锯齿,因为发生了自遮挡现象:
-
其一是处理器的数值精度的限制
-
还有一个原因是因为shadow map本身保存的值是离散值,也就是说shadow map上每个采样点都代表着一块范围内图元的深度值,因此在第二个pass比较深度的时候,shadow map中的深度可能会略低于物体表面的深度,部分片元就会被误计算为阴影,导致自遮挡。该现象在光源与平面趋于平行时(掠射)尤为严重。


-
为了解决这个问题,课上也说了,使用bias(偏移值)方法。
-
在shadow map中引入一个偏移值(bias),使得每次在比较深度大小的时候,都将一定区间内的shadow map深度认作与屏幕空间深度相等,强行减弱阴影判定。
-
但这样做又会引入一个新的问题——detached shadow,或者说,peter panning(阴影悬浮)——即丢失部分原本可能发生遮挡的阴影

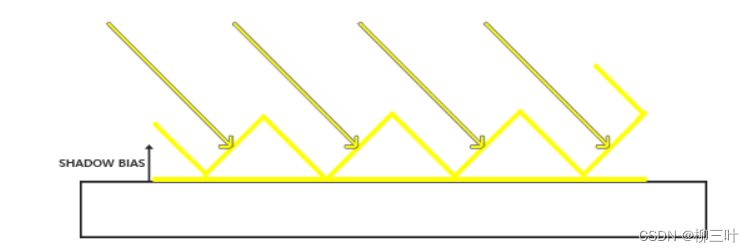
那来看一下怎么做这个bias,还是在src\shaders\phongShader\phongFragment.glsl中直接添加一个Bias方法:

放两个,其实没多大区别,差别在于这个阴影的出现程度,第二个的阴影区域会比第一个小:
float Bias(float CDepth){vec3 lightDir1 = normalize(uLightPos);vec3 normal1 = normalize(vNormal);float m = 200.0 / 2048.0 / 2.0; // 正交矩阵宽高/shadowmap分辨率/2float bias1 = max(m * (1.0-dot(normal1,lightDir1)),m) * CDepth;return bias1;
}float Bias1(){vec3 lightDir1 = normalize(uLightPos);vec3 normal1 = normalize(vNormal);float bias1 = max(0.08 * (1.0-dot(normal1,lightDir1)),0.08);return bias1;
}
然后修改useShadowMap方法:
float useShadowMap(sampler2D shadowMap, vec4 shadowCoord){float mapDepth = unpack(texture2D(shadowMap,shadowCoord.xy));//shadow map中各点的最小深度,unpack将RGBA值转换成[0,1]的floatfloat shadingDepth = shadowCoord.z; //当前着色点的深度//float visibility1 = ((mapDepth + EPS) < shadingDepth) ? 0.0 : 1.0;float bias = Bias(1.4);float visibility1 = ((mapDepth + EPS) <= (shadingDepth - bias)) ? 0.2 : 0.9;return visibility1;
}
最终效果
采用Bias方法后的效果:

放大之后,虽然不会产生严重的锯齿现象,但还是有锯齿:

但很明显,腿部的阴影没有了,因为发生了我们上面说的阴影悬浮现象,这就可以通过修改bias方法来改善,但不可避免。
完成了硬阴影的two pass shadow map方法后,在实际生活中我们更希望我们得到的是软阴影,接下来就是写软阴影部分的代码,软阴影又分为PCF和PCSS两种。
PCF



我们通过SM生成了一个硬阴影,但是在实际生活中我们希望我们得到的是软阴影,而在我们刚才的硬阴影的计算中我们得到的visibility项非0即1.如果我们着色点周围的一圈像素进行一个加权平均,我们就可以得到一个相对来说较软的阴影——visibility项不再是非0即1。
请注意,这个过程发生在采样过程中:
-
- 滤波对象既不是Shadow Map自身(对shadow map滤完波再做深度测试,结果仍是二值化数据,相当于什么都没做);
-
- 也不是深度测试结束后得到的阴影图(非但不会消除锯齿,还会让阴影变糊,在101中有提到过);
-
- 而是找我们选定的点对应于shadow map中周围一圈邻域的点,将领域中的每个点与我们选定的点进行比较,进行一个二值化处理。比较完成之后,对这一圈邻域内的二值化数据进行求和平均(也就是filter,其实叫filter不够准确,就是做一个求和平均罢了)。
两个采样函数
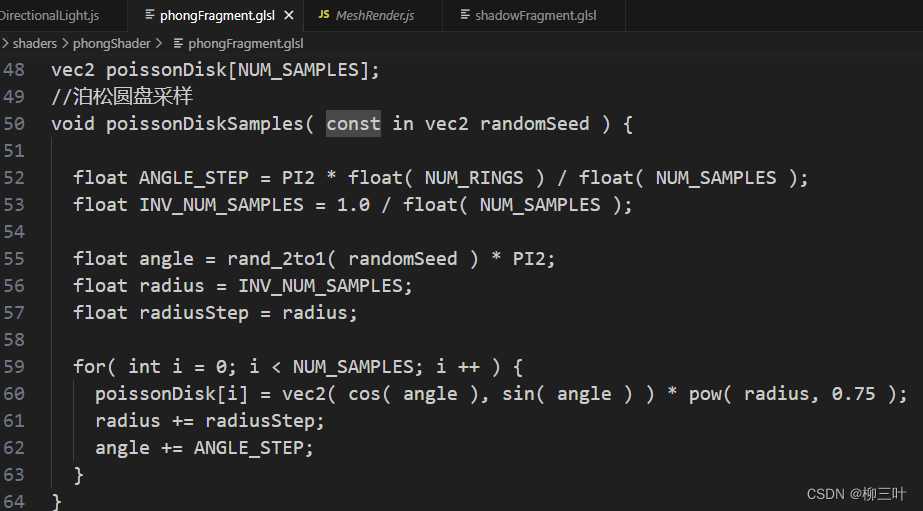
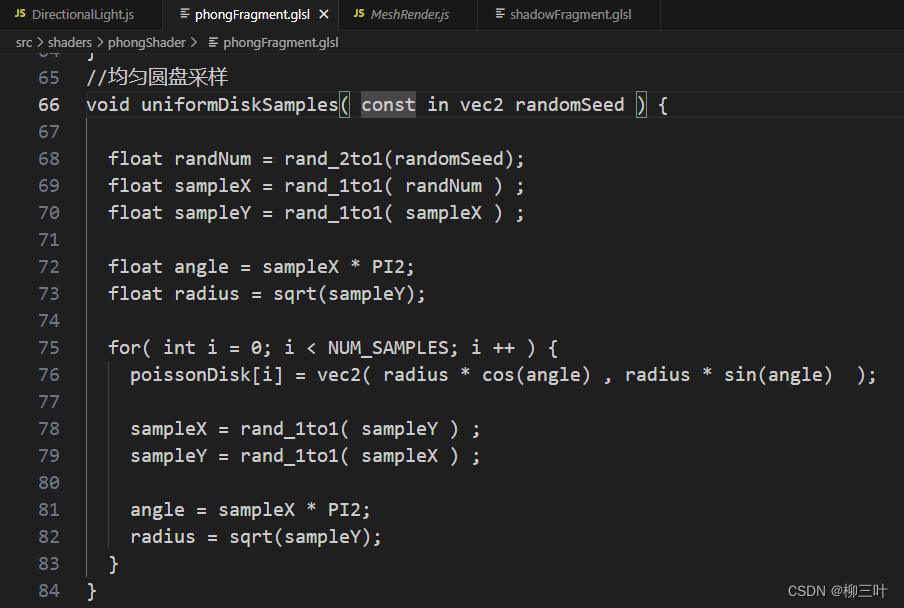
作业中建议用泊松圆盘采样和均匀圆盘采样,代码里都给出来了:
-
泊松圆盘

-
均匀圆盘

实话说没看懂哈,会用就行了,要是有小伙伴感兴趣的可以看下面的链接:
- 三维点云泊松圆盘采样(Poisson-Disk Sampling)
- 泊松盘采样(Poisson Disk Sampling)生成均匀随机点
- 需要注意的是,两个采样方法都把数据存储到了下面这个数组中:

所以不管我们用哪个方法,都可以直接使用这个数组来取数据。
PCF函数
课上老师也提到过,PCF其实是基于shadow map做AA(Anti-Aliasing,即反走样)。PCF就是在做卷积,把卷积核也叫做过滤器,也就是filter。
卷积原理看这个:卷积 (Convolution) 填充 (Padding) 步长 (Stride)
在进行shading point的深度与shadowmap比较时,不只比较一个方向的值,而是与周围像素做卷积,在周围采样多个点的深度值,逐一比较之后求平均值,就能得到一个[0,1]的连续分布,可以表示不同明暗程度的阴影,不再是硬阴影那样非0即1对比强烈的感觉,阴影就变得柔和起来,也就实现了人工软阴影化。
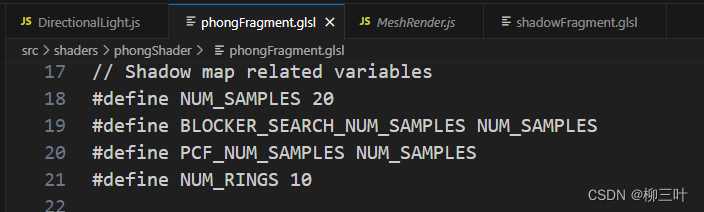
- filter size 卷积核大小
- 作业1中filter的大小由采样数量决定,也就是一开始给定的NUM_SAMPLES,初始值设置成了20。
- filter的大小、个数一般都是先设定一个初始值,再根据实验效果进行调整。
- 在进行卷积时,在输出要求相同的情况下,filter越大参与计算的参数越多,那么对于作业1来说达到的阴影柔和的效果越明显。
float PCF(sampler2D shadowMap, vec4 coords) {float stride = 2.0; //定义步长float shadowMapSize = 2048.0; //shadowmap分辨率float visibility1 = 0.0; //初始可见项float cur_depth = coords.z; //卷积范围内当前点的深度float filterRange = stride / shadowMapSize; //滤波窗口的范围//泊松圆盘采样得到采样点poissonDiskSamples(coords.xy);//均匀圆盘采样得到采样点//uniformDiskSamples(coords.xy);//对每个点进行比较深度值并累加for(int i = 0; i < NUM_SAMPLES; i++){float shadow_depth = unpack(texture2D(shadowMap,coords.xy + poissonDisk[i] * filterRange));float res = (cur_depth < shadow_depth + EPS) ? 1.0 : 0.0;visibility1 += res;}//返回均值float avgVisibility = visibility1 / float(NUM_SAMPLES);return avgVisibility;
}
- 采样偏移值 -> 与步长Sride关系
- 在卷积过程中,将每次卷积核滑动的行数/列数称为Stride(步长)。有时需要在卷积时通过设置的Stride来压缩一部分信息,成倍缩小尺寸。
- 对于作业1而言,由于PCF输入的坐标coords归一到了[0,1]的范围,那么给定采样点的偏移值poissonDiskSamples[i]也需要缩小一定范围以迎合coords坐标的尺寸,因此需要给定Stride以缩小尺寸。缩小比例当然是stride/shaodowMapSize,框架中shadowMapSize=2048,Stride可以给定一个初始值1,根据效果进行调整。
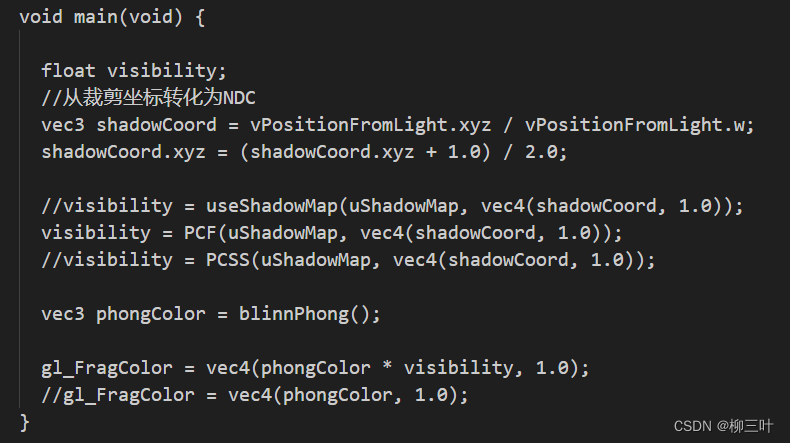
额,最后别忘了在main函数里改一下:
最终效果
用泊松圆盘采样的结果:
NUM_SAMPLES=80,stride=10:

要是更改一下参数:NUM_SAMPLES=80,stride=2:

用均匀圆盘采样的结果:
NUM_SAMPLES=80,stride=2:

NUM_SAMPLES=80,stride=2:

- 可以发现NUM_SAMPLES越小或者stride越大 阴影边缘噪点越多,有兴趣可以自己试试调整这两个参数值。
PCSS
然后就是最后的PCSS方法了。为了达到前实后虚的软阴影效果,就可以采用PCSS(Percentage Closer Soft Shadow),通过计算投影平面与遮挡物之间的距离,来确定滤波范围的大小(自适应的filter size)。
算法的整体思路是:
- 首先将shading point点x投应到shadow map上,找到其对应的像素点p。
- 在点p附近取一个范围(这个范围是自己定义或动态计算的),将范围内各像素的最小深度与x的实际深度比较,从而判断哪些像素是遮挡物,把所有遮挡物的深度记下来取个平均值作为blocker distance。(Blocker search)
- 第二步:用取得的遮挡物深度距离来算在PCF中filtering的范围。
- 第三步:进行pcf操作。
这里有个问题,filter size可以按上述方法确定了,那么计算filter size时需要用到的d(blocker)同样需要在一定范围内做平均,这个范围又怎么确定呢?我们可以认为规定一个固定的大小,如4 * 4,16 * 16等,但这么做绝对不是最优解,更好的方法是在光源处设置一个视锥,将shadow map置于近平面上,接着连接着色点和光源,以其在shadow map上所截得的范围作为样本,来计算平均深度。
这么做有一个非常大的好处,就是计算d(blocker)也采用了自适应的方法,离光源越远,遮挡物越多,计算blocker所用的样本范围就越小;而离光源越近,遮挡物越少,计算blocker所用的样本空间就越大,非常合理。


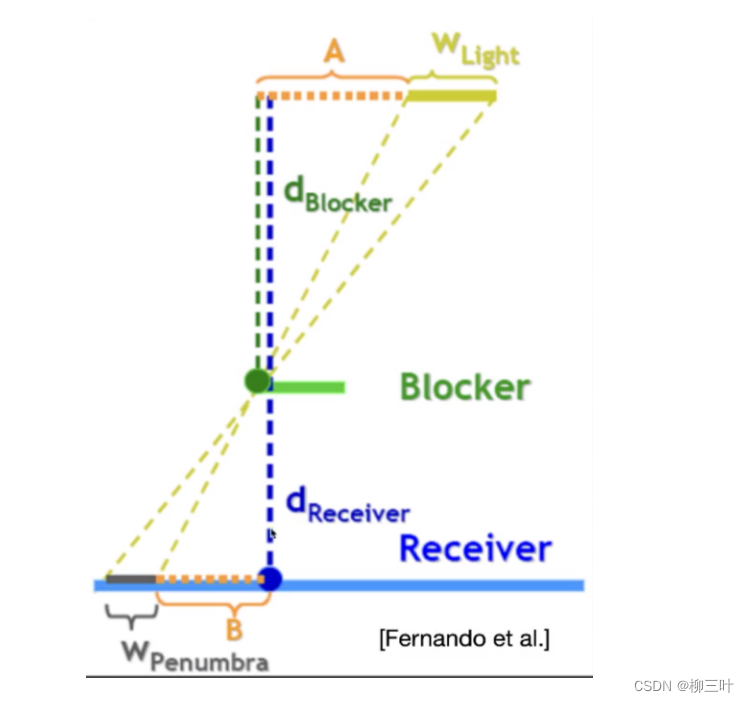
- W(Light)是光源的大小。
- W(Penumbra)是filter的大小,某种程度算是阴影软硬程度的表现,该值越大,阴影就越软。
- d(Receiver)是阴影接受物的深度。
- d(Blocker)是遮挡物,也就是阴影投射物的深度。
- 遮挡物Blocker越接近接受物Receiver,W(Penumbra)越小,阴影越硬;
- 遮挡物Blocker越接近光源Light,W(Penumbra)越大,阴影越软;
由相似三角形就能得到:
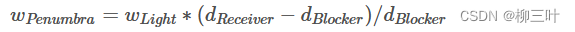
所以PCSS的具体步骤为:
- 首先依据着色点选择一块范围,对Shadow Map做一次局部深度测试,找到范围内的blocker并计算其平均深度(计算平均深度的目的是减小遮挡物自身的几何影响,避免漏光)。
- 得到d(blocker)后代入公式计算滤波范围, d(blocker)越小, [d(receiver)-d(blocker)] 越大,卷积核越大,得到的阴影就越软。
- 重新进行深度测试,继续完成PCF的过程。
那作业需要我们完成findBlocker(sampler2D shadowMap,vec2 uv, float zReceiver) 和 PCSS(sampler2D shadowMap, vec4 shadowCoord)函数。
findBlocker函数
看一下findBlocker函数,需要完成对遮挡物平均深度的计算,也就是上面的d(Blocker)。
- 首先给定基数BlockerNum和总的Block_depth。
- 从当前的shading point连向方向光源light,方向上击中位于shadow map上的一点P,取点P周围的一个区域(利用到了泊松圆盘采样),判断区域里的点是否在阴影里,如果在则BlockerNum加一、Block_depth加上cur_depth;如果不在,则不纳入计算。
以发现这个判断过程跟前面的shadowmap和PCF都是一样的,但是目的不同,这里是在求blocker的深度!
float findBlocker( sampler2D shadowMap, vec2 uv, float zReceiver ) {int blockerNum = 0; //着色点对应到shadow map中后,周围一圈邻域内为blocker的点的数量float blocker_depth = 0.0; //blocker的深度float shadowMapSize = 2048.0; //shadow map的分辨率float stride = 50.0; //采样的步长float filterRange = stride / shadowMapSize; //滤波窗口的范围//泊松圆盘采样得到采样点poissonDiskSamples(uv);//均匀圆盘采样得到采样点//uniformDiskSamples(uv);//判断着色点对应到shadow map中后,邻域中的点是否为blocker,如果是就累加for(int i = 0; i < NUM_SAMPLES; i++){float shadow_depth = unpack(texture2D(shadowMap,uv+ poissonDisk[i] * filterRange)); if(zReceiver > shadow_depth + 0.01){blockerNum++;blocker_depth += shadow_depth;}}if(blockerNum == 0){return 1.0;}blocker_depth = blocker_depth / float(blockerNum);return blocker_depth;
}
PCSS函数
float PCSS(sampler2D shadowMap, vec4 coords){// STEP 1: avgblocker depthfloat avgBlocker_depth = findBlocker(shadowMap,coords.xy,coords.z); //在这步里我们已经做好了采样,后面就能直接调用数据float wLight = 1.0; //光源大小float dReceiver = coords.z;// STEP 2: penumbra sizefloat wPenumbra = wLight * (dReceiver - avgBlocker_depth) / avgBlocker_depth;// STEP 3: filtering 就是做PCF,不过加入了wPenumra的影响//首先定义变量float stride = 10.0;float shadowMapSize = 2048.0;float visibility1 = 0.0;float cur_depth = coords.z;float filterRange = stride / shadowMapSize;//做采样,前面已经做好了//poissonDiskSamples(coords.xy);//然后循环比较for(int i = 0; i < NUM_SAMPLES; i++){float shadow_depth = unpack(texture2D(shadowMap,coords.xy + poissonDisk[i] * filterRange * wPenumbra));float res = cur_depth < shadow_depth+0.01 ? 1.0 : 0.0;visibility1 += res;}//求平均visibility1 /= float(NUM_SAMPLES);return visibility1;
}
最终效果
最后main函数改一下记得,结果图:
下面这个是NUM_SAMPLES=80

这个是让cur_depth < shadow_depth+EPS,NUM_SAMPLES=20的结果:


也可以加bias,但是得调…
参考
- GAMES202作业1-实现过程详细步骤
- GAMES202 作业1解答
- GAMES202作业1-万字分析代码框架
- GAMES202高质量实时渲染-个人笔记:实时阴影
- GAMES202 Real-Time High Quality Rendrting 高质量实时渲染课程笔记Lecture 4: Shadow 02
- GAMES202-高质量实时渲染
相关文章:
GAMES202作业1
目录 Shadow MapCalcLightMVP函数useShadowMap函数Bias函数 最终效果 PCF两个采样函数PCF函数最终效果 PCSSfindBlocker函数PCSS函数最终效果 参考 先放上公式: 后面的积分项是我们在作业0中就做好的blinnphong项,我们要求的就是积分项前,等…...

Android 12.0状态栏居中显示时间和修改时间显示样式
1.概述 在12.0的系统rom定制化开发中,在systemui状态栏系统时间默认显示在左边和通知显示在一起,但是客户想修改显示位置,想显示在中间,所以就要修改SystemUI 的Clock.java 文件这个就是管理显示时间的,居中显示的话就得修改布局文件了 效果图如下: 在这里插入图片描述 …...

湍流的数值模拟方法概述
湍流,又称紊流,是一种极其复杂、极不规则、极不稳定的三维流动。湍流场内充满着尺度大小不同的旋涡,大旋涡尺度可以与整个流畅区域相当,而小漩涡尺度往往只有流场尺度千分之一的数量级,最小尺度旋涡的尺度通过其耗散掉…...
openFast中的陆上风电机组5MW_Land_DLL_WTurb参数详解
文章目录 一、openFAST是什么?二、参数截图三、参数详解 一、openFAST是什么? openFAST是一种开放源代码的工具,为风能工程师提供了用于模拟和设计风力涡轮机的框架。它可以计算风力涡轮机在各种环境条件下的性能,并提供对风力涡…...
“卷”还是“躺平”?职场人如何在工作中找到价值感?
今天不谈技术,只谈进步。 曾经看过一个回答说“职场人最好的姿势是仰卧起坐”。 卷累的就躺,休息好了再继续卷,卷是常态,“仰卧起坐”也好,“卷的姿势”也好,都是在反复“卷起”的过程中寻找一些舒适和平衡…...
《Opencv3编程入门》学习笔记—第二章
《Opencv3编程入门》学习笔记 记录一下在学习《Opencv3编程入门》这本书时遇到的问题或重要的知识点。 第二章 OpenCV 官方例程引导与赏析 openv官方提供的示例程序:具体位于..\opencv\sources\samples\cpp ..\opencv\sources\samples\cpp\tutorial_code路径下存…...

ABP VNext种子数据按顺序插入
ABP VNext种子数据按顺序插入 1.Domain层1.1 新加Author和Book实体1.2 CustomDataSeedDbMigrationService新加方法1.3新加ISowSeed接口1.4 作者和图书种子数据逻辑1.5 新加CustomDataSeedDataSeederContributor 2.EntityFrameworkCore2.1 CustomDataSeedDbContext2.2 生成迁移脚…...
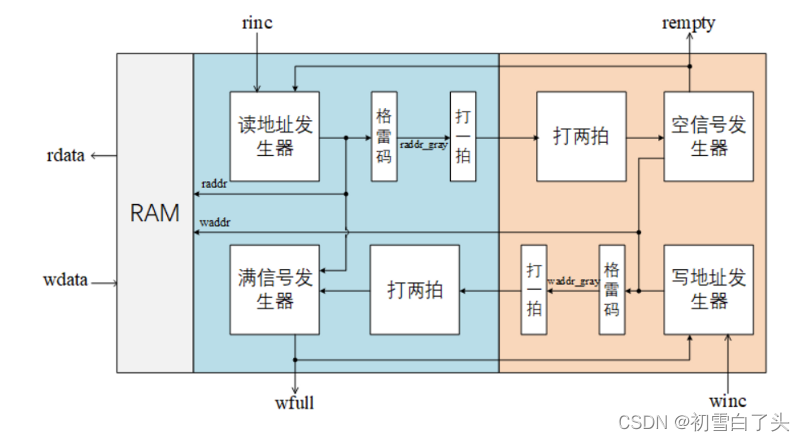
Verilog | FIFO简单实现
FIFO( First Input First Output)简单说就是指先进先出,也是缓存机制的一种,下面是我总结的 FIFO 的三大用途: 1)提高传输效率,增加 DDR 带宽的利用率。比如我们有 4 路视频数据缓存到 DDR 中去,比较笨的方法是&#x…...

设计模式应用场景
设计模式简介 工厂模式(Factory Pattern):使用工厂方法创建对象,而不是使用new关键字直接实例化对象。 抽象工厂模式(Abstract Factory Pattern):提供一个创建一系列相关对象的接口,…...

还在老一套?STM32使用新KEIL5的IDE,全新开发模式RTE介绍及使用
Keil新版本出来了,推出了一种全新开发模式RTE框架( Run-Time Environment),更好用了。然而网上的教程资料竟还都是把Keil5当成Keil4来用,直接不使用这个功能。当前正点原子或野火的教程提供的例程虽有提到Keil5,但也是基本上当Kei…...
Java时间类(十一) -- Date类工具类 -- Java获取当天、本周、本月、本年 开始及结束时间
目录 1. 今天的日期如下: 2. DateUtils工具类的源代码: 3. 测试类 1. 今天的日期如下:...

Alma Linux 9.2、Rocky Linux 9.2现在是RHEL 9.2的替代品
随着Red Hat Enterprise Linux (RHEL) 9.2的发布,Alma Linux 9.2和Rocky Linux 9.2成为了RHEL 9.2的备选替代品。这两个Linux发行版旨在提供与RHEL兼容的功能和稳定性,以满足那些需要企业级操作系统的用户需求。本文将详细介绍Alma Linux 9.2和Rocky Lin…...

推荐5款提高生活和工作效率的好帮手
在这个数字化时代,软件工具已经深深地影响和改变了我们的生活和工作。有着各种各样的软件工具,它们都可以在特定的领域内让我们变得更加高效,完成复杂的任务。选择一款适合你的软件工具,不但可以极大地释放生产力,也可以让生活变得更加便捷。 1.桌面图标管理工具——TileIconi…...

美团小组长薪资被应届生员工倒挂7K,不把老员工当人?
一位美团的小管理爆出,无意中看到了整个部门薪资,本以为自己算比较高的,但看完之后整个人都傻眼了。小组长的职位月薪28K,而手下组员却是35K,当天晚上抽了一包烟也没想明白是为什么。 楼主表示,自己是美团的…...

【Java多线程案例】使用阻塞队列实现生产者消费者模型
前言 本篇文章讲解多线程案例之阻塞队列。主要讲解阻塞队列的特性、实际开发中常用的到的生产者消费者模型,以及生产者消费者模型解耦合、削峰填谷的好处。并且使用 Java 多线程模拟实现一个生产者消费者模型、阻塞队列版的生产者消费者模型。 文章从什么是阻塞队列…...

Spark 3:Spark Core RDD持久化
RDD 的数据是过程数据 RDD 的缓存 # coding:utf8 import timefrom pyspark import SparkConf, SparkContext from pyspark.storagelevel import StorageLevelif __name__ __main__:conf SparkConf().setAppName("test").setMaster("local[*]")sc SparkC…...

字节跳动五面都过了,结果被刷了,问了hr原因竟说是...
摘要 说在前面,面试时最好不要虚报工资。本来字节跳动是很想去的,几轮面试也通过了,最后没offer,自己只想到几个原因:1、虚报工资,比实际高30%;2、有更好的人选,这个可能性不大&…...
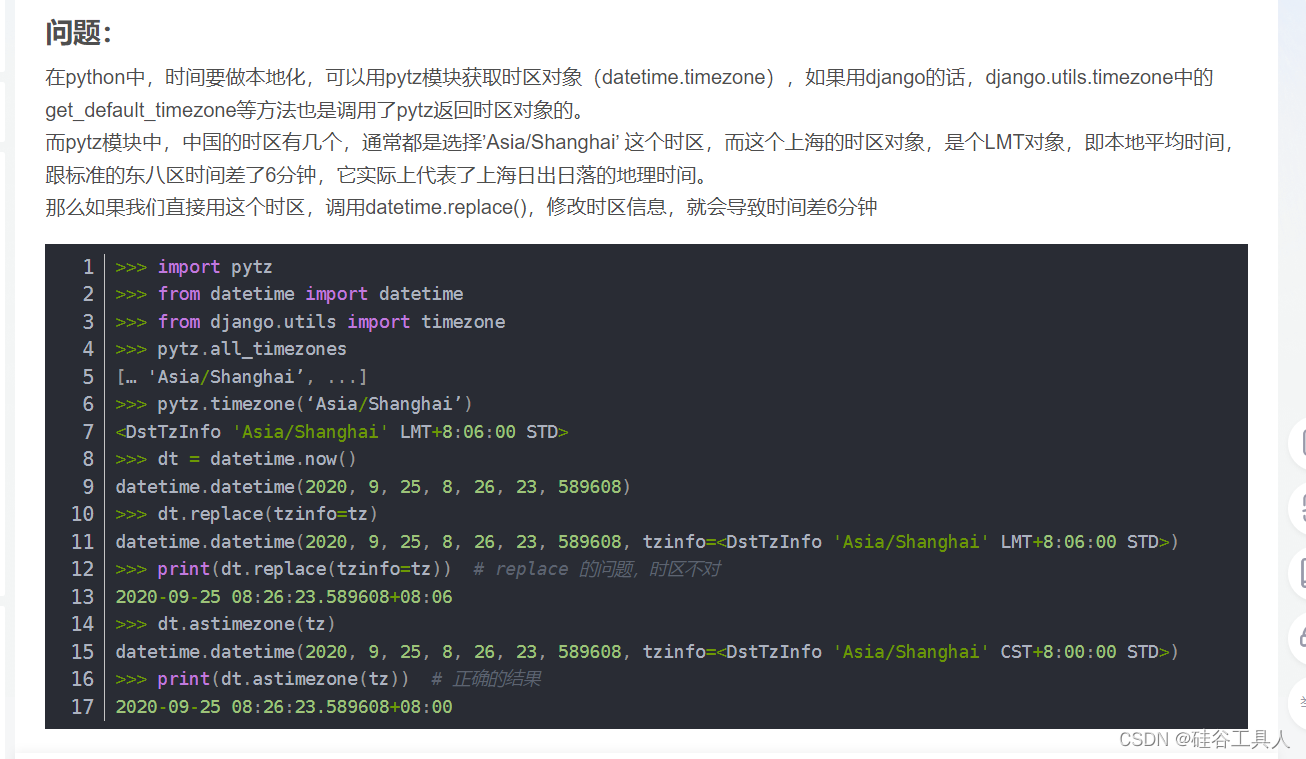
Python日期带时区转换工具类总结
文章目录 1.背景2. 遇到的坑3. 一些小案例3.1 当前日期、日期时间、UTC日期时间3.2 昨天、昨天UTC日期、昨天现在这个时间点的时间戳3.3 日期转时间戳3.4 时间戳转日期3.5 日期加减、小时的加减 4. 总结5. 完整的编码 1.背景 最近项目是国际项目,所以需要经常需要用…...
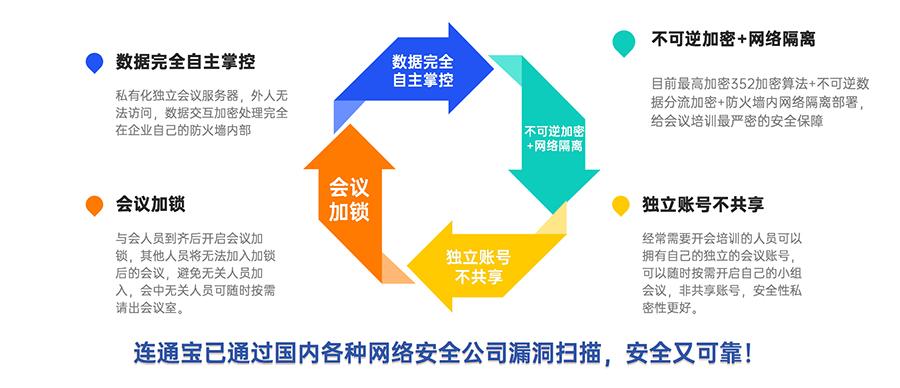
视频会议产品对比分析
内网视频会议系统如何选择?有很多单位为了保密,只能使用内部网络,无法连接互联网,那些SaaS视频会议就无法使用。在内网的优秀视频会议也有很多可供选择,以下是几个常用的: 1. 宝利通:它支持多种…...

每日一练 | 华为认证真题练习Day47
1、某台路由器输出信息如下,下列说法错误的是?(多选) A. 本路由器开启了区域认证 B. 本设备出现故障,配置的Router Id和实际生效的Router ID不一致 C. 本设备生效的Router Id为10.0.12.1 D. 本设备生效的Router Id为…...

LLM在硬件验证中的应用与FLAG框架解析
1. 硬件验证中的LLM应用现状 在芯片设计领域,形式化验证是确保设计正确性的关键环节。传统上,工程师需要手动编写SystemVerilog断言(SVA)来描述信号间的时序关系,这个过程既耗时又容易出错。以AXI总线协议为例,一个完整验证套件可…...

机器学习求解流体PDE:警惕弱基准与报告偏误导致的效率高估
1. 机器学习求解流体PDE:一场被高估的效率革命? 在计算物理和工程仿真领域,求解偏微分方程(PDE)是模拟从空气动力学到气候预测等无数自然现象的核心。几十年来,科学家和工程师们开发了诸如有限差分、有限体…...
)
告别文件重命名!统信UOS 1060开启长文件名支持的保姆级图文教程(UDOM工具箱版)
统信UOS 1060长文件名支持全攻略:UDOM工具箱图形化操作指南从Windows切换到国产操作系统的用户,最常遇到的困扰之一就是文件命名限制。想象一下,当你精心整理的"2023年度市场营销策划案最终修订版V3.5-包含所有渠道投放预算与ROI分析.xl…...
)
【2026年阿里巴巴集团暑期实习- 5月23日-算法岗-第一题- 荆棘林的最优砍断计划】(题目+思路+JavaC++Python解析+在线测试)
题目内容 林中共有 n n n 株荆棘,第 i i i 株的坚硬度为 a i a_i...
)
告别TeamViewer!在Ubuntu 22.04上安装向日葵远程控制的保姆级教程(附依赖问题解决)
在Ubuntu 22.04上无缝迁移至向日葵远程控制的完整指南当TeamViewer开始频繁弹出商业使用警告或连接不稳定时,许多Linux用户开始寻找更友好的替代方案。向日葵作为国产远程控制工具的后起之秀,不仅完全免费,还针对Linux环境做了深度优化。本文…...

JWT签名机制与常见攻击实战:从PortSwigger靶场12关学透算法混淆、密钥混淆与JWKS劫持
1. 为什么JWT不是“加密令牌”,而是“签名凭证”——从PortSwigger靶场第一关开始讲起很多人一看到JWT就下意识觉得:“这是个加密的token,只要我拿到它,就等于拿到了用户密码或者敏感密钥。”这种误解直接导致他们在实战中反复碰壁…...

云原生监控体系建设:打造全方位的可观测性平台
云原生监控体系建设:打造全方位的可观测性平台 引言 在云原生时代,监控是保障系统稳定运行的关键。一个完善的监控体系可以帮助我们及时发现问题、定位问题、解决问题。 今天就来分享一下云原生监控体系的建设经验。 监控体系概述 可观测性三支柱 监控体…...

RuoYi接口调试:Postman作为Spring Boot权限系统可信信使
1. 为什么RuoYi项目里Postman不是“配角”,而是调试生命线在RuoYi开发实战中,很多人把Postman当成一个“临时工具”——写完接口顺手点一下,成功了就扔一边,失败了就切回IDE疯狂加日志、重启服务、反复试错。我带过三届实习生&…...

Harness与Agent SDK的边界划分:最佳实践
Harness与Agent SDK的边界划分:最佳实践 引言 在云原生软件交付的下半场,企业面临的核心矛盾已经从「有没有工具链」变成了「能不能把工具链用出价值」。作为全球领先的软件交付平台(SDP),Harness凭借开箱即用的CI/CD、Feature Flag、混沌工程、合规治理等能力,已经成为…...

CSS Grid布局深入解析:掌握现代布局技术
CSS Grid布局深入解析:掌握现代布局技术 引言 CSS Grid布局是CSS3引入的强大布局系统,它提供了一种二维网格布局方式,可以轻松实现复杂的页面布局。本文将深入探讨Grid布局的核心概念、高级技巧和最佳实践。 一、Grid布局基础 1.1 Grid容器与…...